猿创征文|一文带你了解国产TiDB数据库
写在前面
很多小伙伴在日常接触中接触国产数据库很少,大部分在开发应用上使用的是由甲骨文,微软等公司提供了MySQL,SQLserver。普通程序员很少能用到newSQl数据库,TiDB就是一种newSQL数据库,在大趋势下,向国际对接是避免不了的,但也存在一个问题,近期看到新闻国外某知名数据库厂商宣布称“暂停在俄罗斯的所有业务”,相信很多国内小伙伴的心情,绝不是隔岸观火,而是细思恐极。数据库产品一直都是国内人员的焦点话题,面对现如今全球的“非常时期”,国产数据库到底能不能支棱起来呢?今天呢我就带领大家认识国产数据库TiDB数据库。为什么要介绍TiDB呢,看图说话。


通过上面的俩张图,我们可以很明显的看到TiDB在国内是霸主的地位,加上近些年分布式架构越来越活跃,NewSQL 提供了与 noSQL 相同的可扩展性,而且仍基于关系模型,还保留了极其成熟的 SQL 作为查询语言,保证了ACID事务特性。简单来讲,NewSQL 就是在传统关系型数据库上集成了 NoSQL 强大的可扩展性。 传统的SQL架构设计基因中是没有分布式的,而 NewSQL 生于云时代,天生就是分布式架构。TiDB更是如鱼得水。
不理解的朋友可以看看下面图的对比

发展历史
2015
9月
TiDB 在 GitHub 上开源,一个月 Star 数超过 2700
4月获得天使轮投资、PingCAP 成立

2016
12月
TiDB RC1 发版
8月
- 获得云启资本领投的 A 轮融资
- 第一家客户在生产环境中使用

2017
10月TiDB 1.0 GA 发版
6月宣布获得华创资本领投的 1500 万美元 B 轮融资

2018
11月
Cloud TiDB 公测
9月
宣布获得复星、晨兴资本领投的 5000 万美元的 C 轮融资
8月
- TiDB Operator 开源
- CNCF 接纳 TiKV 作为 CNCF Sandbox 的云原生项目4月
TiDB 2.0 GA 发版

2019
12月
云原生的混沌工程 Chaos Mesh 正式开源
9月
一体化数据同步平台 TiDB Data Migration 1.0 GA 发版
8月
TiDB 用户问答论坛 AskTUG 正式上线
6月
- TiDB 3.0 GA 发版
- TiDB User Group 正式成立5月
CNCF宣布正式将 TiKV 从沙箱项目晋级至孵化项目
1月
TiDB Lightning Toolset & TiDB Data Migration 正式开源
2020
12月
TiDB 通过信通院分布式数据库性能与基础能力两项评测
11月
宣布完成 2.7 亿美元的 D 轮融资
9月
- PingCAP 团队的论文《TiDB: A Raft-based HTAP Database 》入选 VLDB 2020 ,成为业界第一篇 Real-time HTAP 分布式数据库工业实现的论文
- CNCF 宣布 TiKV 正式从 CNCF 毕业7月
CNCF 宣布云原生的混沌工程 Chaos Mesh 正式进入 CNCF 沙箱托管项目
5月
TiDB 4.0 GA 发版

2021
12月
TiDB 连续 24 个月在墨天轮国产数据库流行度排行榜上排行第一
11月
TiDB Cloud Developer Tier 发布,向开发者提供为期一年的免费试用
7月
Chaos Mesh 2.0 正式 GA
5月
PingCAP 携手 CCF,成为 VLDB Summer School 独家协办单位
4月
- PingCAP 加入 CNCF,成为银牌会员
- 面向企业级核心场景的 TiDB 5.0 GA 发版1月
PingCAP 连续两年在 CNCF 全球贡献排行榜中位列中国企业第一位,全球排名第 6 位

2022
4月
TiFlash 开源
2月
云原生混沌工程测试平台 Chaos Mesh 升级成为 CNCF 孵化项目

是什么?
TiDB 是一个分布式 NewSQL 数据库。它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景还适OLAP 场景的混合数据库。
怎么来的?
开源分布式缓存服务 Codis 的作者,PingCAP 联合创始人& CTO ,资深 infrastructure 工程师的黄东旭,擅长分布式存储系统的设计与实现,开源狂热分子的技术大神级别人物。即使在互联网如此繁荣的今天,在数据库这片边界模糊且不确定地带,他还在努力寻找确定性的实践方向。
2012 年底,他看到 Google 发布的两篇论文,得到了很大的触动,这两篇论文描述了 Google 内部使用的一个海量关系型数据库 F1/Spanner ,解决了关系型数据库、弹性扩展以及全球分布的问题,并在生产中大规模使用。“如果这个能实现,对数据存储领域来说将是颠覆性的”,黄东旭为完美方案的出现而兴奋, PingCAP 的 TiDB 在此基础上诞生了。
TIDB核心特性
水平弹性扩展
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景
得益于 TiDB 存储计算分离的架构的设计,可按需对计算、存储分别进行在线扩容或者缩容,扩容或者缩容过程中对应用运维人员透明。
分布式事务支持
TiDB 100% 支持标准的 ACID 事务
金融级高可用
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入
数据采用多副本存储,数据副本通过 Multi-Raft 协议同步事务日志,多数派写入成功事务才能提交,确保数据强一致性且少数副本发生故障时不影响数据的可用性。可按需配置副本地理位置、副本数量等策略满足不同容灾级别的要求。
实时 HTAP
TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP 无需传统繁琐的 ETL 过程
提供行存储引擎 TiKV、列存储引擎 TiFlash 两款存储引擎,TiFlash 通过 Multi-Raft Learner 协议实时从 TiKV 复制数据,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。TiKV、TiFlash 可按需部署在不同的机器,解决 HTAP 资源隔离的问题。
云原生的分布式数据库
TiDB 是为云而设计的数据库,同 Kubernetes 深度耦合,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景,更复杂的 OLAP 分析可以通过 TiSpark 项目来完成。
TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力
高度兼容 MySQL
兼容 MySQL 5.7 协议、MySQL 常用的功能、MySQL 生态,应用无需或者修改少量代码即可从 MySQL 迁移到 TiDB。
提供丰富的数据迁移工具帮助应用便捷完成数据迁移,大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移
OLTP(联机事务处理)
OLTP(Online Transactional Processing) 即联机事务处理,OLTP 是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,记录即时的增、删、改、查,比如在银行存取一笔款,就是一个事务交易
联机事务处理是事务性非常高的系统,一般都是高可用的在线系统,以小的事务以及小的查询为主,评估其系统的时候,一般看其每秒执行的Transaction以及Execute SQL的数量。在这样的系统中,单个数据库每秒处理的Transaction往往超过几百个,或者是几千个,Select 语句的执行量每秒几千甚至几万个。典型的OLTP系统有电子商务系统、银行、证券等,如美国eBay的业务数据库,就是很典型的OLTP数据库。
OLAP(联机分析处理)
OLAP(Online Analytical Processing) 即联机分析处理,是数据仓库的核心部心,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。典型的应用就是复杂的动态报表系统
在这样的系统中,语句的执行量不是考核标准,因为一条语句的执行时间可能会非常长,读取的数据也非常多。所以,在这样的系统中,考核的标准往往是磁盘子系统的吞吐量(带宽),如能达到多少MB/s的流量。
TiDB 整体架构
TiDB的优势
与传统的单机数据库相比,TiDB 具有以下优势:
- 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
- 支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
- 支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
TiDB的组件
要深入了解 TiDB 的水平扩展和高可用特点,首先需要了解 TiDB 的整体架构。TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server,此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件。
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:

应用场景
MySQL分片与合并

TiDB 应用的第一类场景是 MySQL 的分片与合并。对于已经在用 MySQL 的业务,分库、分表、分片、中间件是常用手段,随着分片的增多,跨分片查询是一大难题。TiDB 在业务层兼容 MySQL 的访问协议,PingCAP 做了一个数据同步的工具——Syncer,它可以把黄东旭 TiDB 作为一个 MySQL Slave,将 TiDB 作为现有数据库的从库接在主 MySQL 库的后方,在这一层将数据打通,可以直接进行复杂的跨库、跨表、跨业务的实时 SQL 查询。
黄东旭提到,“过去的数据库都是一主多从,有了 TiDB 以后,可以反过来做到多主一从。”
直接替换MySQL
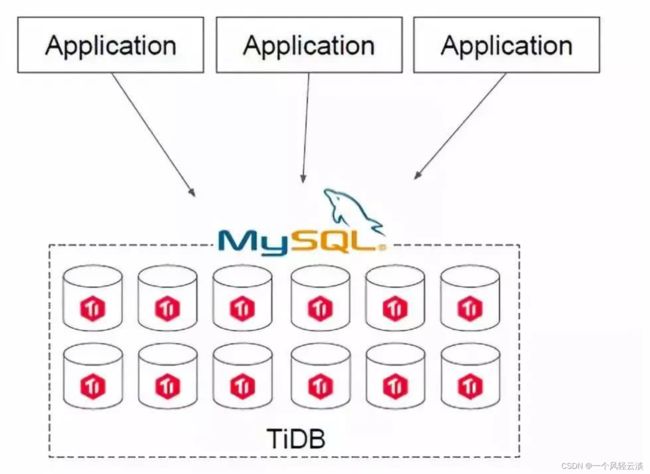
第二类场景是用 TiDB 直接去替换 MySQL。如果你的IT架构在搭建之初并未考虑分库分表的问题,全部用了 MySQL,随着业务的快速增长,海量高并发的 OLTP 场景越来越多,如何解决架构上的弊端呢?
在一个 TiDB 的数据库上,所有业务场景不需要做分库分表,所有的分布式工作都由数据库层完成。TiDB 兼容 MySQL 协议,所以可以直接替换 MySQL,而且基本做到了开箱即用,完全不用担心传统分库分表方案带来繁重的工作负担和复杂的维护成本,友好的用户界面让常规的技术人员可以高效地进行维护和管理。
另外,TiDB 具有 NoSQL 类似的扩容能力,在数据量和访问流量持续增长的情况下能够通过水平扩容提高系统的业务支撑能力,并且响应延迟稳定。
数据仓库
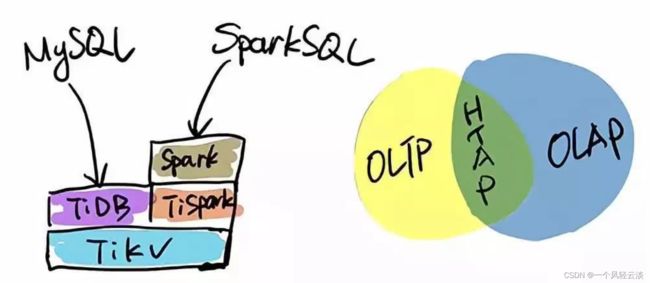
TiDB 本身是一个分布式系统,第三种使用场景是将 TiDB 当作数据仓库使用。TPC-H 是数据分析领域的一个测试集,TiDB 2.0 在 OLAP 场景下的性能有了大幅提升,原来只能在数据仓库里面跑的一些复杂的 Query,在 TiDB 2.0 里面跑,时间基本都能控制在 10 秒以内。
当然,因为 OLAP 的范畴非常大,TiDB 的 SQL 也有搞不定的情况,为此 PingCAP 开源了 TiSpark,TiSpark 是一个 Spark 插件,用户可以直接用 Spark SQL 实时地在 TiKV 上做大数据分析。
作为其他系统的模块

TiDB 是一个传统的存储跟计算分离的项目,其底层的 Key-Value 层,可以单独作为一个 HBase 的 Replacement 来用,它同时支持跨行事务。TiDB 对外提供两个 API 接口,一个是 ACID Transaction 的 API,用于支持跨行事务;另一个是 Raw API,它可以做单行的事务,换来的是整个性能的提升,但不提供跨行事务的 ACID 支持。用户可以根据自身的需求在两个 API 之间自行选择。例如有一些用户直接在 TiKV 之上实现了 Redis 协议,将 TiKV 替换一些大容量,对延迟要求不高的 Redis 场景。
应用案例
