Pandas 模块 - 读写(2)-Excel 表格及其他-read_excel/to_excel
目录
2. 利用 .read_excel() 和 .to_excel() 从外部读取或者写入数据
2.1 .read_excel() 语法
2.2 .read_excel() 范例
2.2.1 最简单的 io 参数
2.2.2 read_csv() 没有的 sheet_name
2.2.3 相似的参数 header,names ,index_col ,usecols
2.2.4 和 .read_csv() 含义不一样的 engine
2.3 .to_excel() 语法
2.4 .to_excel() 范例
2.4.1 最简单的 excel_writer
2.4.2 指定工作表名 sheet_name
2.4.3 类似的参数 columns、header、index、index_label
2.4.4 好理解的 startrow 、startcol
2.4.5 可选的 NaN参数 na_rep
2.4.6 可选的浮点数格式参数 float_format
.read_excel() 和 .to_excel() 是一对,恰如 .read_csv() 和 .to_csv() 一样,甚至很多参数都是雷同的。
2. 利用 .read_excel() 和 .to_excel() 从外部读取或者写入数据
2.1 .read_excel() 语法
网上有很多 .read_excel() 语法结构,但是最权威的还是写在代码里面的。具体每个参数的用法,就在范例里面一一说明吧。
Help on function read_excel in module pandas.io.excel._base:
read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=True, mangle_dupe_cols=True, storage_options: Union[Dict[str, Any], NoneType] = None)
Read an Excel file into a pandas DataFrame.
Supports `xls`, `xlsx`, `xlsm`, `xlsb`, `odf`, `ods` and `odt` file extensions
read from a local filesystem or URL. Supports an option to read
a single sheet or a list of sheets.
Parameters
----------
io : str, bytes, ExcelFile, xlrd.Book, path object, or file-like object
Any valid string path is acceptable. The string could be a URL. Valid
URL schemes include http, ftp, s3, and file. For file URLs, a host is
expected. A local file could be: ``file://localhost/path/to/table.xlsx``.
If you want to pass in a path object, pandas accepts any ``os.PathLike``.
By file-like object, we refer to objects with a ``read()`` method,
such as a file handle (e.g. via builtin ``open`` function)
or ``StringIO``.
sheet_name : str, int, list, or None, default 0
Strings are used for sheet names. Integers are used in zero-indexed
sheet positions. Lists of strings/integers are used to request
multiple sheets. Specify None to get all sheets.
Available cases:
* Defaults to ``0``: 1st sheet as a `DataFrame`
* ``1``: 2nd sheet as a `DataFrame`
* ``"Sheet1"``: Load sheet with name "Sheet1"
* ``[0, 1, "Sheet5"]``: Load first, second and sheet named "Sheet5"
as a dict of `DataFrame`
* None: All sheets.
header : int, list of int, default 0
Row (0-indexed) to use for the column labels of the parsed
DataFrame. If a list of integers is passed those row positions will
be combined into a ``MultiIndex``. Use None if there is no header.
names : array-like, default None
List of column names to use. If file contains no header row,
then you should explicitly pass header=None.
index_col : int, list of int, default None
Column (0-indexed) to use as the row labels of the DataFrame.
Pass None if there is no such column. If a list is passed,
those columns will be combined into a ``MultiIndex``. If a
subset of data is selected with ``usecols``, index_col
is based on the subset.
usecols : int, str, list-like, or callable default None
* If None, then parse all columns.
* If str, then indicates comma separated list of Excel column letters
and column ranges (e.g. "A:E" or "A,C,E:F"). Ranges are inclusive of
both sides.
* If list of int, then indicates list of column numbers to be parsed.
* If list of string, then indicates list of column names to be parsed.
.. versionadded:: 0.24.0
* If callable, then evaluate each column name against it and parse the
column if the callable returns ``True``.
Returns a subset of the columns according to behavior above.
.. versionadded:: 0.24.0
squeeze : bool, default False
If the parsed data only contains one column then return a Series.
dtype : Type name or dict of column -> type, default None
Data type for data or columns. E.g. {'a': np.float64, 'b': np.int32}
Use `object` to preserve data as stored in Excel and not interpret dtype.
If converters are specified, they will be applied INSTEAD
of dtype conversion.
engine : str, default None
If io is not a buffer or path, this must be set to identify io.
Supported engines: "xlrd", "openpyxl", "odf", "pyxlsb".
Engine compatibility :
- "xlrd" supports old-style Excel files (.xls).
- "openpyxl" supports newer Excel file formats.
- "odf" supports OpenDocument file formats (.odf, .ods, .odt).
- "pyxlsb" supports Binary Excel files.
.. versionchanged:: 1.2.0
The engine `xlrd ', 'N/A', 'NA', 'NULL', 'NaN', 'n/a',
'nan', 'null'.
keep_default_na : bool, default True
Whether or not to include the default NaN values when parsing the data.
Depending on whether `na_values` is passed in, the behavior is as follows:
* If `keep_default_na` is True, and `na_values` are specified, `na_values`
is appended to the default NaN values used for parsing.
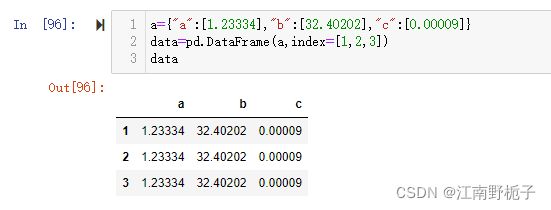
* If `keep_default_na` is True, and `na_values` are not specified, only
the default NaN values are used for parsing.
* If `keep_default_na` is False, and `na_values` are specified, only
the NaN values specified `na_values` are used for parsing.
* If `keep_default_na` is False, and `na_values` are not specified, no
strings will be parsed as NaN.
Note that if `na_filter` is passed in as False, the `keep_default_na` and
`na_values` parameters will be ignored.
na_filter : bool, default True
Detect missing value markers (empty strings and the value of na_values). In
data without any NAs, passing na_filter=False can improve the performance
of reading a large file.
verbose : bool, default False
Indicate number of NA values placed in non-numeric columns.
parse_dates : bool, list-like, or dict, default False
The behavior is as follows:
* bool. If True -> try parsing the index.
* list of int or names. e.g. If [1, 2, 3] -> try parsing columns 1, 2, 3
each as a separate date column.
* list of lists. e.g. If [[1, 3]] -> combine columns 1 and 3 and parse as
a single date column.
* dict, e.g. {'foo' : [1, 3]} -> parse columns 1, 3 as date and call
result 'foo'
If a column or index contains an unparseable date, the entire column or
index will be returned unaltered as an object data type. If you don`t want to
parse some cells as date just change their type in Excel to "Text".
For non-standard datetime parsing, use ``pd.to_datetime`` after ``pd.read_excel``.
Note: A fast-path exists for iso8601-formatted dates.
date_parser : function, optional
Function to use for converting a sequence of string columns to an array of
datetime instances. The default uses ``dateutil.parser.parser`` to do the
conversion. Pandas will try to call `date_parser` in three different ways,
advancing to the next if an exception occurs: 1) Pass one or more arrays
(as defined by `parse_dates`) as arguments; 2) concatenate (row-wise) the
string values from the columns defined by `parse_dates` into a single array
and pass that; and 3) call `date_parser` once for each row using one or
more strings (corresponding to the columns defined by `parse_dates`) as
arguments.
thousands : str, default None
Thousands separator for parsing string columns to numeric. Note that
this parameter is only necessary for columns stored as TEXT in Excel,
any numeric columns will automatically be parsed, regardless of display
format.
comment : str, default None
Comments out remainder of line. Pass a character or characters to this
argument to indicate comments in the input file. Any data between the
comment string and the end of the current line is ignored.
skipfooter : int, default 0
Rows at the end to skip (0-indexed).
convert_float : bool, default True
Convert integral floats to int (i.e., 1.0 --> 1). If False, all numeric
data will be read in as floats: Excel stores all numbers as floats
internally.
mangle_dupe_cols : bool, default True
Duplicate columns will be specified as 'X', 'X.1', ...'X.N', rather than
'X'...'X'. Passing in False will cause data to be overwritten if there
are duplicate names in the columns.
storage_options : dict, optional
Extra options that make sense for a particular storage connection, e.g.
host, port, username, password, etc., if using a URL that will
be parsed by ``fsspec``, e.g., starting "s3://", "gcs://". An error
will be raised if providing this argument with a local path or
a file-like buffer. See the fsspec and backend storage implementation
docs for the set of allowed keys and values.
.. versionadded:: 1.2.0
2.2 .read_excel() 范例
2.2.1 最简单的 io 参数
io:str、bytes、ExcelFile、xlrd.Book、path对象或类似文件的对象任何有效的字符串路径都是可以接受的。字符串可以是URL。有效的URL方案包括http、ftp、s3和文件。对于文件URL,需要一个主机。本地文件可以是:``file://localhost/path/to/table.xlsx``. 如果要传入路径对象,pandas会接受任何``os.PathLike``。对于类文件对象,我们使用“read()”方法引用对象,例如文件句柄(例如,通过内置的“open”函数)或“StringIO”。
代码如下
data02=pd.read_excel(r"D:\pandas\Excel file.xlsx")
data02运行结果

2.2.2 read_csv() 没有的 sheet_name
sheet_name :str、int、list或None,默认值为0;字符串用于图纸名称。整数用于索引
工作表位置,从 0 开始。字符串/整数列表用于请求多个工作表。指定“None”以获取所有sheet。
现有案例:
*默认为``0``:作为`数据帧的第一个工作表`
*``1``:作为`DataFrame`的第二张工作表`
*`“Sheet1``:加载名为“Sheet1”的工作表
*`[0,1,“Sheet5”]``:加载第一张、第二张和名为“Sheet5”的图纸,结果为`DataFrame`类型的字典结构
*None:所有工作表。
以上面的例子为例,其实 "D:\pandas\Excel file.xlsx" 中有两个工作表,但是只读了第一个工作表。

如果我想读第二个工作表,有两种效果等同的代码:
sheet_name=1
data02=pd.read_excel(r"D:\pandas\Excel file.xlsx",sheet_name=1)
data02
或者 sheet_name=“Sheet2”
data02=pd.read_excel(r"D:\pandas\Excel file.xlsx",sheet_name="Sheet2")
data02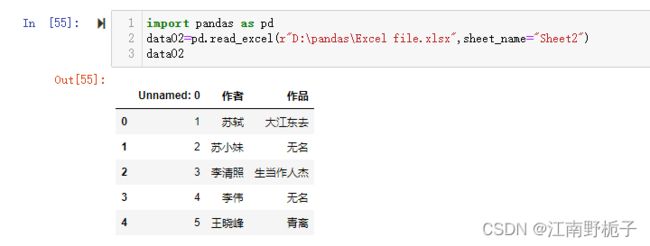
如果我想两张表都读取: sheet_name=None,此时返回的就是一个 ”DataFrame“ 结构的字典,
data02=pd.read_excel(r"D:\pandas\Excel file.xlsx",sheet_name=None)
data02
如果想依次读取这两个工作表的信息
for tmp in data02:
print("*"*30)
print(tmp)
print(data02[tmp])
2.2.3 相似的参数 header,names ,index_col ,usecols
对 Sheet1 稍作修改

Sheet2 保留原貌

代码1)
data02=pd.read_excel(r"D:\pandas\Excel file.xlsx",sheet_name=None,
index_col=0,# 设置第一列为行名
skiprows=[0,None], #设置 sheet1 过滤第一行,sheet 2 不需要
names=["id","Name","Birthday"] #名字改为 "id","Name","Birthday"
)
data02运行结果

代码2)
data02=pd.read_excel(r"D:\pandas\Excel file.xlsx",sheet_name="Sheet2",
index_col=0,
usecols = ['作者']
)
data02运行结果

大家可能会问,为什么我没有把 header,names ,index_col ,usecols 用一个例子来表达
嗯呢,我试过,但是反复出错。
例如下面的代码 3),我只是在 代码 1)上加了 usecols=["Name"],就反复报错
“
ValueError: Number of passed names did not match number of header fields in the file
”
我对此的解释只能是,Pandas 还不完美。
data02=pd.read_excel(r"D:\pandas\Excel file.xlsx",sheet_name=None,
index_col=0,# 设置第一列为行名
skiprows=[0,None], #设置 sheet1 过滤第一行,sheet 2 不需要
names=["id","Name","Birthday"], #名字改为 "id","Name","Birthday"
usecols=["Name"]
)
data02结果报错

***********************************************************************************************************
此外,还想给大家一个建议,如果每个工作表的结构是不一致的,建议不要一次性读取所有的表格,而是一张张读取的,毕竟针对不同的工作表结构,代码实现不完全一样,非要整在一行代码里面完全没有必要。
通过对不同结构的工作表的轮询,用不同的代码去实现,准确性会更高。
***********************************************************************************************************
2.2.4 和 .read_csv() 含义不一样的 engine
在 .read_csv() 函数里面支持 engine 为{"C","python"},但是在.read_excel() 里面,engine 默认为None,可以接受的参数有“ xlrd”,“ openpyxl”或“ odf”,用于使用第三方的库去解析excel文件。
- 如果io不是缓冲区或路径,则必须将其设置为标识 io。
- 支持的引擎:“xlrd”、“openpyxl”、“odf”、“pyxlsb”。
- engine 兼容性:
- -“xlrd”支持旧式Excel文件(.xls)。
- -“openpyxl”支持更新的Excel文件格式。
- -“odf”支持OpenDocument文件格式(.odf、.ods、.odt)。
- -“pyxlsb”支持二进制Excel文件。
例如要支持 OpenDocument文件,engine 使用 odf 时候,要先导入第三方库 odfpy,否则会报错
”
ImportError: Missing optional dependency 'odfpy'. Use pip or conda to install odfpy.
“
导入第三方库 odfpy 方法如下:

代码
import pandas as pd
data02=pd.read_excel(r"D:\pandas\openDoc.ods",sheet_name="Sheet2",
index_col=0,# 设置第一列为行名
names=["id","Name","Birthday"],#名字改为 "id","Name","Birthday"
engine="odf"
)
data02运行结果

2.3 .to_excel() 语法
还是直接看代码里面的注释吧,这里绝大多数都在 .to_csv() 函数里面聊过,用途是雷同的。
Help on function to_excel in module pandas.core.generic:
to_excel(self, excel_writer, sheet_name: 'str' = 'Sheet1', na_rep: 'str' = '', float_format: 'Optional[str]' = None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None, storage_options: 'StorageOptions' = None) -> 'None'
Write object to an Excel sheet.
To write a single object to an Excel .xlsx file it is only necessary to
specify a target file name. To write to multiple sheets it is necessary to
create an `ExcelWriter` object with a target file name, and specify a sheet
in the file to write to.
Multiple sheets may be written to by specifying unique `sheet_name`.
With all data written to the file it is necessary to save the changes.
Note that creating an `ExcelWriter` object with a file name that already
exists will result in the contents of the existing file being erased.
Parameters
----------
excel_writer : path-like, file-like, or ExcelWriter object
File path or existing ExcelWriter.
sheet_name : str, default 'Sheet1'
Name of sheet which will contain DataFrame.
na_rep : str, default ''
Missing data representation.
float_format : str, optional
Format string for floating point numbers. For example
``float_format="%.2f"`` will format 0.1234 to 0.12.
columns : sequence or list of str, optional
Columns to write.
header : bool or list of str, default True
Write out the column names. If a list of string is given it is
assumed to be aliases for the column names.
index : bool, default True
Write row names (index).
index_label : str or sequence, optional
Column label for index column(s) if desired. If not specified, and
`header` and `index` are True, then the index names are used. A
sequence should be given if the DataFrame uses MultiIndex.
startrow : int, default 0
Upper left cell row to dump data frame.
startcol : int, default 0
Upper left cell column to dump data frame.
engine : str, optional
Write engine to use, 'openpyxl' or 'xlsxwriter'. You can also set this
via the options ``io.excel.xlsx.writer``, ``io.excel.xls.writer``, and
``io.excel.xlsm.writer``.
.. deprecated:: 1.2.0
As the `xlwt
2.4 .to_excel() 范例
先准备数据

2.4.1 最简单的 excel_writer
excel_writer : path-like, file-like, or ExcelWriter object File path or existing ExcelWriter.
代码
data02.to_excel(r"D:\pandas\Save Excel.xlsx")运行结果

2.4.2 指定工作表名 sheet_name
sheet_name : str, default 'Sheet1' Name of sheet which will contain DataFrame.
在 2.4.1 小节中,生成的默认工作表名就是“Sheet1”,现在我们给它设定我们自己想要的
data02.to_excel(r"D:\pandas\Save Excel.xlsx",sheet_name=r"随笔记录")2.4.3 类似的参数 columns、header、index、index_label
columns : sequence or list of str, optional Columns to write.序列或者字符串的列表,用于写入的可选择的列
header : bool or list of str, default True Write out the column names. If a list of string is given it is assumed to be aliases for the column names.
布尔值,或者字符串的列表,默认为True,即写入列名字。如果给了一个字符串列表,则被认为是列的别名。
index : bool, default True Write row names (index).
布尔值,默认为True,即写入行名
index_label : str or sequence, optional Column label for index column(s) if desired. If not specified, and `header` and `index` are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex.
字符串或者序列号,即 index 列的标识。如果没有指定,且`header` 和`index` 都是True,则使用 index 名字。如果 DataFrame 使用了多个Index,那么要给一个序列。
先看第一段代码
data02.to_excel(r"D:\pandas\Save Excel.xlsx",
sheet_name=r"随笔记录",
columns=["Birthday"],#只选择 Birthaday
header=False,#不写入列名
index_label="IndexLabel"
)运行结果
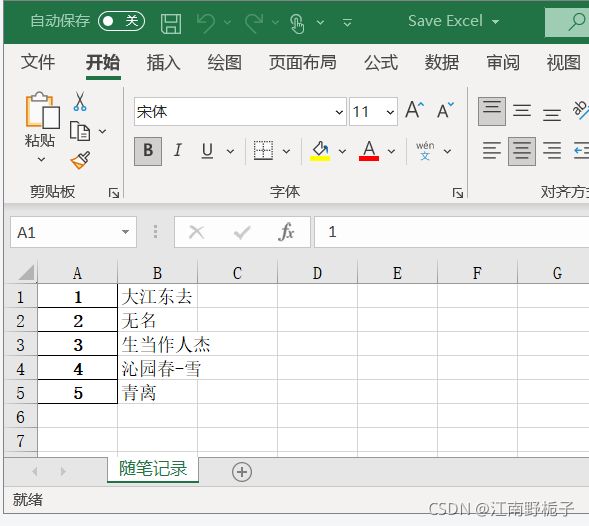
再看第二段代码
data02.to_excel(r"D:\pandas\Save Excel.xlsx",
sheet_name=r"随笔记录",
columns=["Birthday"],#只选择 Birthaday
header=True,#即默认这种形式,只不过我写明白了
index_label="IndexLabel"
)运行结果

大家可以看到,当 header = True 时候,index_label 才起作用。除了header ,index 也会影响index_label 的作用。上面两段代码中 index 都是默认为 True 的情况。
下面看看第三段代码
data02.to_excel(r"D:\pandas\Save Excel.xlsx",
sheet_name=r"随笔记录",
columns=["Birthday"],#只选择 Birthaday
header=True,#即默认这种形式,只不过我写明白了
index_label="IndexLabel",
index=False
)运行结果
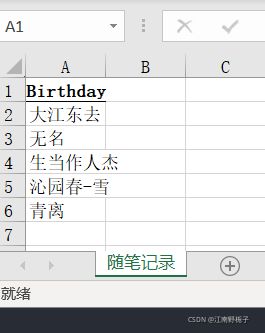
可以看到 index = False 时候,既然都不写入 index 了,index_label 自然也就没有意义了。
2.4.4 好理解的 startrow 、startcol
startrow : int, default 0 Upper left cell row to dump data frame.
startcol : int, default 0 Upper left cell column to dump data frame.
startrow 和 startcol 分别指定数据放置的起始行和起始列,默认是 0,工作表序号从 0 开始。
data02=data02.to_excel(r"D:\pandas\Save Excel.xlsx",
sheet_name="NewSheet",
startrow=1,
startcol=2
)
data02运行结果


2.4.5 可选的 NaN参数 na_rep
na_rep : str, default '' Missing data representation.
当我们的数据存在 NaN时候
如果使用默认的“”,结果如下


如果我们设置 na_rep = "暂时不知道"
代码如下:
data02.to_excel(r"D:\pandas\Save Excel2.xlsx",na_rep = "暂时不知道")运行结果如下

2.4.6 可选的浮点数格式参数 float_format
float_format : str, optional Format string for floating point numbers. For example ``float_format="%.2f"`` will format 0.1234 to 0.12.
这个也比较好理解,不赘述。
代码如下
data.to_excel(r"D:\pandas\Save Excel4.xlsx",float_format='%.4f')运行结果

其余的参数就大家自行专研吧,等我有空再写。
'''
要是大家觉得写得还行,麻烦点个赞或者收藏吧,想给博客涨涨人气,非常感谢!
'''