1.Hadoop3.x 环境搭建
文章目录
- Hadoop3.x 环境搭建
-
- 流程一 : 虚拟机软件安装
- 流程二 : 模板虚拟机系统硬件配置
- 流程三 : 模板虚拟机系统软件配置
- 流程四 : 模板虚拟机系统网络配置
- 流程五 : 模板虚拟机与主机互传配置
- 流程六 : 模板虚拟机所需环境配置
- 流程七 : 模板虚拟机克隆集群配置
- 流程八 : 集群虚拟机安装软件配置
- 流程九 : 集群虚拟机安装软件分发
- 流程十 : 集群虚拟机分发脚本配置
- 流程十一 : 集群虚拟机ssh免密登录配置
- 流程十二 : 三台主机的集群配置
- 流程十三 : 群起集群
- 流程十四 : 集群程序历史服务器配置
- 流程十五 : 集群日志聚集功能配置
- 流程十六 : 集群常用脚本编写
- 流程十七 : 集群时间同步配置
- 流程十八 : HDFS API 环境配置
- 流程十九 : MapReduce WordCount 环境配置
Hadoop3.x 环境搭建
流程一 : 虚拟机软件安装
-
1.模板虚拟机软件及版本:
- VMware Workstation15.5
-
2.模板虚拟机获取地址:
- 官网下载地址:https://customerconnect.vmware.com/cn/downloads/info/slug/desktop_end_user_computing/vmware_workstation_pro/15_0
-
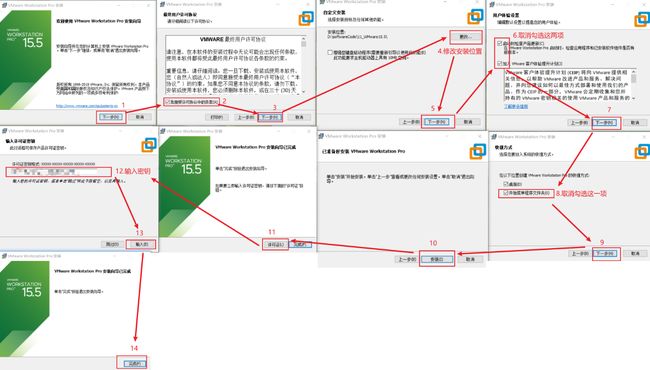
3.模板虚拟机安装步骤:
流程二 : 模板虚拟机系统硬件配置
-
1.模板虚拟机系统及版本
- CentOS7.5
-
2.模板虚拟机系统获取地址
- 网盘链接:https://pan.baidu.com/s/1XbUuY7L2krWFpM9sCzj31A?pwd=voj8
- 提取码:voj8
-
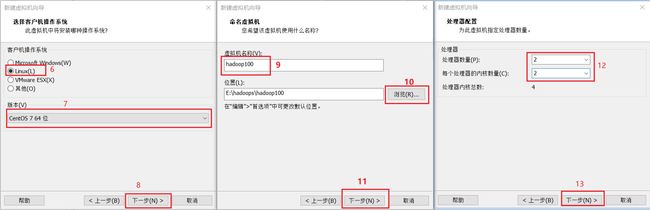
3.模板虚拟机系统硬件配置步骤






- 拍摄快照的目的是为了防止我们在操作时出现失误而能够让系统返回到之前的状态而让我们有机会进行重新操作
流程三 : 模板虚拟机系统软件配置
-
1.模板虚拟机系统及版本
- CentOS7.5
-
2.模板虚拟机系统软件配置步骤


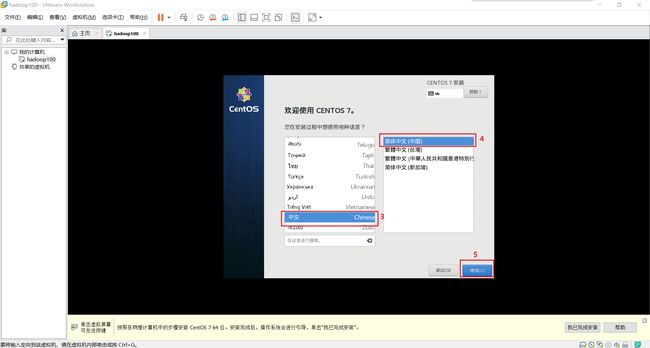

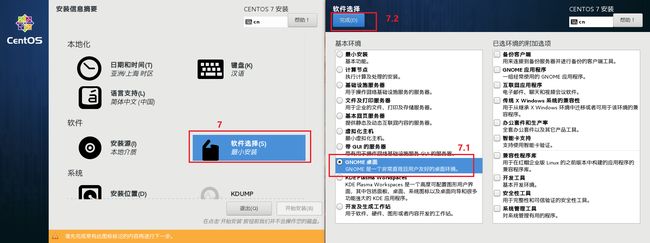






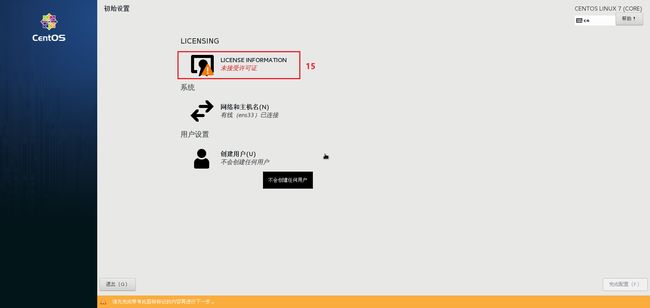
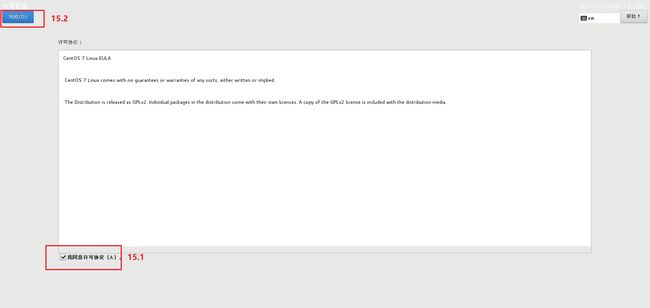
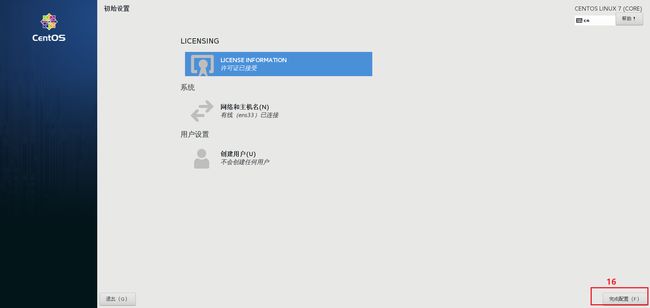









流程四 : 模板虚拟机系统网络配置
-
1.模板虚拟机系统及版本
- CentOS7.5
-
2.模板虚拟机系统网络配置步骤

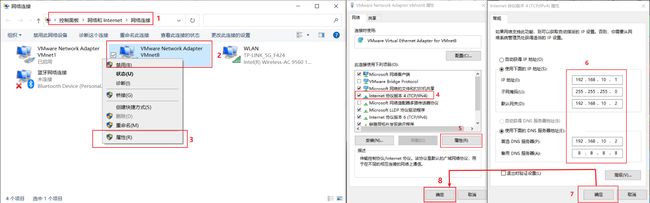



192.168.10.100 hadoop100 192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104 192.168.10.105 hadoop105 192.168.10.106 hadoop106 192.168.10.107 hadoop107 192.168.10.108 hadoop108



192.168.10.100 hadoop100 192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104 192.168.10.105 hadoop105 192.168.10.106 hadoop106 192.168.10.107 hadoop107 192.168.10.108 hadoop108
流程五 : 模板虚拟机与主机互传配置
-
1.互传所需软件及版本
- Xshell 7 一一 主要负责连接主机和虚拟机
- Xftp 7 一一 主要负责主机和虚拟机的文件互传
-
2.模板虚拟机与主机互传思路
- 安装 Xshell7 连接虚拟机,通过 Xftp7 将本地文件发送到虚拟机上 (先连上 Xshell7, 然后才能用Xftp7 发文件)
-
3.互传所需软件下载地址
- 官网免费申请: https://www.xshell.com/zh/free-for-home-school/
注意 : 可能需要挂VPN,不然的话可能会提示响应时间过长,用是绝对能用的。
- 官网免费申请: https://www.xshell.com/zh/free-for-home-school/
-
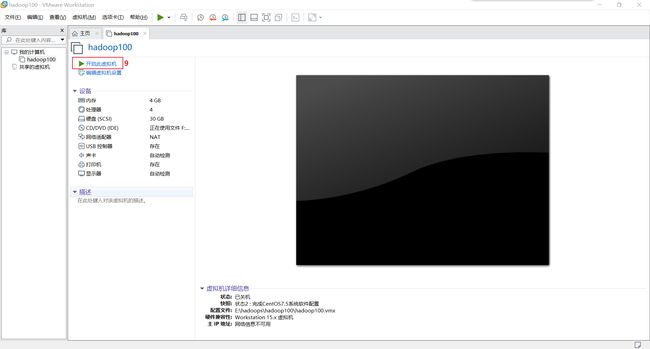
4.互传所需软件安装步骤
- 3.1 安装 Xshell 7
图片/Hadoop3.x 环境搭建45.png
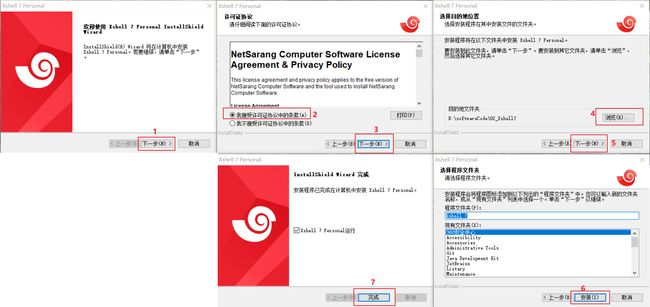
- 3.2 安装 Xftp7

-
4.xshell连接到模板虚拟机步骤

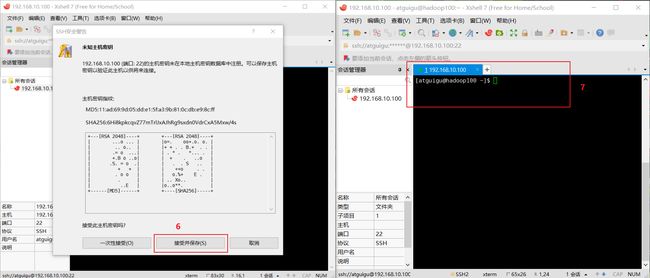
注意: 当我们需要用Xshell7从主机连接到虚拟机时, 虚拟机必须是启动的, 不然任凭怎么连接都不会连通.
-
5.xftp7连接到模板虚拟机步骤

流程六 : 模板虚拟机所需环境配置
-
1.模板虚拟机系统及版本
- CentOS7.5
-
2.模板虚拟机所需环境配置步骤
-
① 使用ping命令测试下虚拟机联网情况,如下图所示为网络连接正常
[atguigu@hadoop100 ~]$ su 密码: [root@hadoop100 atguigu]# cd [root@hadoop100 ~]# ping www.baidu.com
-
② 安装epel-release(相当于是安装了一个软件仓库,因为大多数rpm包都不在官方repository中)
[root@hadoop100 ~]# yum install -y epel-release
-
③ 关闭防火墙,并设置关闭防火墙选项开机自启
[root@hadoop100 ~]# systemctl stop firewalld [root@hadoop100 ~]# systemctl disable firewalld.service
-
④ 给 atguigu 用户赋予 root 权限 (方便后期加 sudo 执行 root 权限的命令)
[root@hadoop100 ~]# vim /etc/sudoers ------------------------------------------ atguigu ALL=(ALL) NOPASSWD:ALL ------------------------------------------ :wq!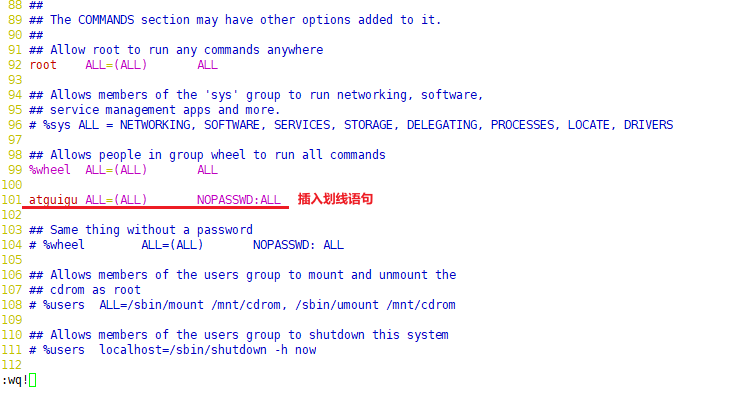
-
⑤ 在 /opt 目录下创建文件夹,并修改所属主和所属组
[root@hadoop100 ~]# mkdir /opt/module [root@hadoop100 ~]# mkdir /opt/software [root@hadoop100 ~]# chown atguigu:atguigu /opt/module [root@hadoop100 ~]# chown atguigu:atguigu /opt/software
-
⑥ 卸载虚拟机自带的 JDK
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
-
⑦ 重启虚拟机
[root@hadoop100 ~]# reboot
-
流程七 : 模板虚拟机克隆集群配置
-
1.模板虚拟机系统及版本
- CentOS7.5
-
2.模板虚拟机克隆集群配置步骤


重复上述 1~11 步从模板机hadoop100中克隆出集群组机hadoop103、hadoop104




重复上述 15~18 步完成集群hadoop103、hadoop104组机的配置
流程八 : 集群虚拟机安装软件配置
-
1.集群虚拟机安装的软件
- JDK1.8
- Hadoop3.1.3
-
2.软件安装包获取地址
- 链接:https://pan.baidu.com/s/1-0gMqKEOibTqILCizHDt0w?pwd=zt5m
- 提取码:zt5m
-
3.软件安装的集群虚拟机
- hadoop102
-
4.集群虚拟机安装软件配置步骤
-
① 使用Xshell将hadoop安装包,jdk安装包传入到/opt/software路径下

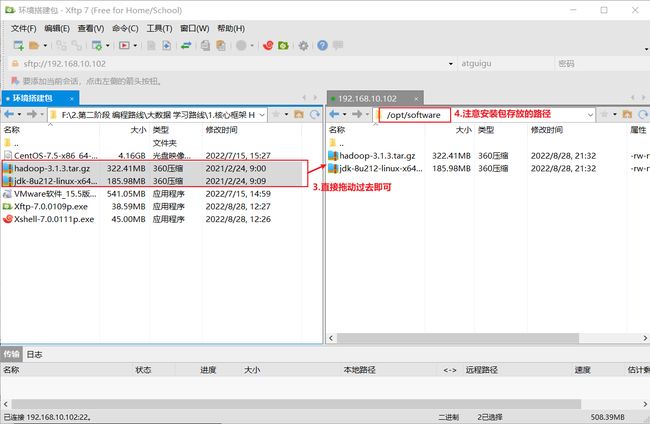
-
② 安装jdk及其配置
[atguigu@hadoop102 ~]$ cd /opt/software/ [atguigu@hadoop102 software]$ll [atguigu@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/ --解压 JDK 到/opt/module 目录下 [atguigu@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh --配置 JDK 环境变量 添加如下内容: ------------------------------------------ #JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin ------------------------------------------ [atguigu@hadoop102 ~]$ source /etc/profile --让新的环境变量 PATH 生效 [atguigu@hadoop102 ~]$ java -version --测试 JDK 是否安装成功
-
③ 安装hadoop及其配置
[atguigu@hadoop102 ~]$ cd /opt/software/ [atguigu@hadoop102 software]$ll [atguigu@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ [atguigu@hadoop102 software]$ ls /opt/module/hadoop-3.1.3 --查看解压是否成功 [atguigu@hadoop102 hadoop-3.1.3]$ sudo vim /etc/profile.d/my_env.sh 添加追加如下内容: ------------------------------------------ #HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin ------------------------------------------ [atguigu@hadoop102 hadoop-3.1.3]$ source /etc/profile [atguigu@hadoop102 hadoop-3.1.3]$ hadoop version
-
流程九 : 集群虚拟机安装软件分发
-
1.集群虚拟机需要分发的软件
- JDK1.8
- Hadoop3.1.3
-
2.集群虚拟机分发软件的思路
-
使用命令将配置好的软件JDK和Hadoop从hadoop102主机通过拷贝命令分发到hadoop103主机和hadoop104主机
注意 : scp 命令可以实现服务器与服务器之间的数据拷贝.
-
-
3.集群虚拟机分发软件的步骤
-
① 在102主机上通过scp命令将102主机上的JDK拷贝到103主机指定位置.
[atguigu@hadoop102 ~]$ scp -r /opt/module/jdk1.8.0_212 atguigu@hadoop103:/opt/module [atguigu@hadoop102 ~]$传输时有两个操作需要进行(第②③步操作时同理):
- 1.“Are you sure you want to continue connecting (yes/no)?” 输入yes即可
- 2."atguigu@hadoop103’s password: " 输入103主机的登录密码即可
-
② 在103主机上通过scp命令将102主机上的hadoop拷贝到103主机指定位置.
[atguigu@hadoop103 ~]$ scp -r atguigu@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/ [atguigu@hadoop103 ~]$
-
-
③ 在103主机上通过scp命令将102主机上的JDK和hadoop拷贝到104主机指定位置.
[atguigu@hadoop103 ~]$ cd /opt/ [atguigu@hadoop103 opt]$ scp -r atguigu@hadoop102:/opt/module/* atguigu@hadoop104:/opt/module [atguigu@hadoop103 opt]$
流程十 : 集群虚拟机分发脚本配置
-
1.集群虚拟机分发脚本的作用
- 比如在hadoop102主机配置完的文件就不用再重复的在hadoop103和hadoop104主机上再去配一次, 而是通过脚本分发到hadoop103和hadoop104主机即可.
-
2.配置虚拟机分发脚本的步骤
-
① 在/home/atguigu/bin 目录下创建 xsync 文件
[atguigu@hadoop102 opt]$ cd /home/atguigu [atguigu@hadoop102 ~]$ mkdir bin [atguigu@hadoop102 ~]$ cd bin [atguigu@hadoop102 bin]$ vim xsync -
② 在xsync文件中插入如下内容
#!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in hadoop102 hadoop103 hadoop104 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done -
③ 修改脚本 xsync 具有完全权限
[atguigu@hadoop102 bin]$ chmod 777 xsync -
④ 测试脚本
[atguigu@hadoop102 ~]$ xsync /home/atguigu/bin -
⑤ 将脚本复制到/bin中,以便全局调用
[atguigu@hadoop102 bin]$ sudo cp xsync /bin/ -
⑥ 同步环境变量配置(root 所有者)并检查是否生效
[atguigu@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh [atguigu@hadoop103 bin]$ sudo vim /etc/profile.d/my_env.sh [atguigu@hadoop104 bin]$ sudo vim /etc/profile.d/my_env.sh -
⑦ 环境变量生效
[atguigu@hadoop103 bin]$ source /etc/profile [atguigu@hadoop103 bin]$ java [atguigu@hadoop104 bin]$ source /etc/profile [atguigu@hadoop104 bin]$ java注意1 : xsync 集群分发脚本用来实现循环复制文件到所有节点的相同目录下.
注意2 : 改文件名称命令 mv+旧名+新名
注意3 : 如果用了 sudo,那么 xsync 一定要给它的路径补全.
-
流程十一 : 集群虚拟机ssh免密登录配置
-
1.集群虚拟机ssh免密登录的作用
- 因为集群分发文件或是互传数据的频率比较高, 而每次都要输入密码进行验证就较为繁琐, 所以干脆直接设置一个集群中的虚拟机互相之间都免密登录, 免去繁琐验证的步骤.
-
2.配置集群虚拟机ssh免密登录的步骤
(这里只以102主机普通用户免密登录到103、104主机为例.如果想在103,104主机上实现对其他两个主机的免密登录,重复下述操作即可) (atguigu用户配置了ssh免密登录,但是当我们切换到root用户想要用ssh登录其他两台主机时则还是需要输入密码,因为root用户没有 配置ssh免密登录,登录到root用户按上述步骤配置一遍即可(root用户输入的密码应为root).) 配置: [atguigu@hadoop102 ~]$ ls -la [atguigu@hadoop102 ~]$ cd ./.ssh/ [atguigu@hadoop102 .ssh]$ cat known_hosts [atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa(三次enter回车即可) [atguigu@hadoop102 .ssh]$ ll [atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102 [atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103 [atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104 验证: [atguigu@hadoop102 .ssh]$ ssh hadoop102 [atguigu@hadoop102 .ssh]$ ssh hadoop103 [atguigu@hadoop102 .ssh]$ ssh hadoop104注意1 : 密钥对(ssh-key-gen)即公钥和私钥,私钥保存,发送公钥,其他服务器得到公钥授权后不用密码验证登录则可以访问我们的服务器数据.
注意2 : id_rsa(私钥)、id_rsa.pub(公钥)
流程十二 : 三台主机的集群配置
-
1.三台主机的集群配置的作用
- 因为现在三台主机还没有配置集群相关的文件, 而只是三台独立的虚拟机, 我们接下来把相关的配置文件配了就将三台主机联系成了一个真正的集群.
-
2.三台主机的集群配置的步骤
-
① 在102主机上配置核心配置文件 core-site.xml
[atguigu@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop [atguigu@hadoop102 hadoop]$ vim core-site.xml 插入内容如下: ------------------------------------------ <configuration> <property> <name>fs.defaultFSname> <value>hdfs://hadoop102:8020value> property> <property> <name>hadoop.tmp.dirname> <value>/opt/module/hadoop-3.1.3/datavalue> property> <property> <name>hadoop.http.staticuser.username> <value>atguiguvalue> property> configuration> ------------------------------------------ :wq注意 : 是插入到 中.
-
② 在102主机上配置HDFS配置文件 hdfs-site.xml
[atguigu@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop [atguigu@hadoop102 hadoop]$ vim hdfs-site.xml 插入内容如下: ------------------------------------------ <configuration> <property> <name>dfs.namenode.http-addressname> <value>hadoop102:9870value> property> <property> <name>dfs.namenode.secondary.http-addressname> <value>hadoop104:9868value> property> configuration> ------------------------------------------ :wq -
③ 在102主机上配置YARN配置文件 yarn-site.xml
[atguigu@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop [atguigu@hadoop102 hadoop]$ vim yarn-site.xml 插入内容如下: ------------------------------------------ <configuration> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.resourcemanager.hostnamename> <value>hadoop103value> property> <property> <name>yarn.nodemanager.env-whitelistname> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue> property> configuration> ------------------------------------------ :wq -
④ 在102主机上配置MapReduce配置文件 mapred-site.xml
[atguigu@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop [atguigu@hadoop102 hadoop]$ vim mapred-site.xml 插入内容如下: ------------------------------------------ <configuration> <property> <name>mapreduce.framework.namename> <value>yarnvalue> property> configuration> ------------------------------------------ :wq -
⑤ 在102主机上分发配置好的Hadoop配置文件给103,104主机并查看情况
[atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/ [atguigu@hadoop103 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml [atguigu@hadoop104 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
-
流程十三 : 群起集群
-
1.群起集群需要启动的组件
- NameNode
- HDFS
- YARN
-
2.群起集群的步骤
-
① 在102主机上配置 workers文件
[atguigu@hadoop102 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers 删除localhost后插入如下内容: ------------------------------------------ hadoop102 hadoop103 hadoop104 ------------------------------------------ :wq [atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc -
② 在102主机上格式化NameNode(第一次启动时用)
[atguigu@hadoop102 hadoop]$ cd /opt/module/hadoop-3.1.3/ [atguigu@hadoop102 hadoop-3.1.3]$ hdfs namenode -format [atguigu@hadoop102 current]$ pwd /opt/module/hadoop-3.1.3/data/dfs/name/current [atguigu@hadoop102 current]$ ll 总用量 16 -rw-rw-r--. 1 atguigu atguigu 394 5月 13 21:55 fsimage_0000000000000000000 -rw-rw-r--. 1 atguigu atguigu 62 5月 13 21:55 fsimage_0000000000000000000.md5 -rw-rw-r--. 1 atguigu atguigu 2 5月 13 21:55 seen_txid -rw-rw-r--. 1 atguigu atguigu 219 5月 13 21:55 VERSION [atguigu@hadoop102 current]$ cat VERSION #Fri May 13 21:55:43 CST 2022 namespaceID=2071359521 clusterID=CID-8808cb0b-a47c-405b-95f9-d26408372a72 cTime=1652450143404 storageType=NAME_NODE blockpoolID=BP-1330503042-192.168.10.102-1652450143404 layoutVersion=-64注意1 : 格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化.
-
③ 在102主机上启动HDFS
[atguigu@hadoop102 sbin]$ pwd /opt/module/hadoop-3.1.3/sbin [atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh Starting namenodes on [hadoop102] Starting datanodes hadoop104: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating. hadoop103: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating. Starting secondary namenodes [hadoop104] [atguigu@hadoop102 hadoop-3.1.3]$ jps 8709 Jps 8281 NameNode 8412 DataNode [atguigu@hadoop103 ~]$ jps 8064 DataNode 8171 Jps [atguigu@hadoop104 ~]$ jps 8150 SecondaryNameNode 8279 Jps 8078 DataNode注意 : 登录Web端查看HDFS的NameNode: http://hadoop102:9870/explorer.html#/
-
④ 在103主机上启动YARN
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh Starting resourcemanager Starting nodemanagers [atguigu@hadoop103 hadoop-3.1.3]$ jps 8064 DataNode 8321 ResourceManager 8801 Jps 8442 NodeManager [atguigu@hadoop102 hadoop-3.1.3]$ jps 8930 Jps 8281 NameNode 8412 DataNode 8813 NodeManager [atguigu@hadoop104 ~]$ jps 8501 Jps 8150 SecondaryNameNode 8377 NodeManager 8078 DataNode注意 : 登录Web端查看YARN的ResourceManager: http://hadoop103:8088/cluster
-
流程十四 : 集群程序历史服务器配置
-
1.配置历史服务器的作用
- 为了查看程序的历史运行情况,需要在102主机上配置一下历史服务器。
-
2.配置历史服务器的步骤
[atguigu@hadoop102 hadoop]$ pwd 查看当前命令执行路径 /opt/module/hadoop-3.1.3/etc/hadoop [atguigu@hadoop102 hadoop]$ vim mapred-site.xml 配置mapred-site.xml 插入内容如下: ------------------------------------------ <property> <name>mapreduce.jobhistory.addressname> <value>hadoop102:10020value> property> <property> <name>mapreduce.jobhistory.webapp.addressname> <value>hadoop102:19888value> property> ------------------------------------------ :wq [atguigu@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml 分发配置 ... [atguigu@hadoop102 hadoop]$ mapred --daemon start historyserver 在hadoop102启动历史服务器 [atguigu@hadoop102 hadoop]$ jps 查看历史服务器是否启动 3332 Jps 2534 NodeManager 3270 JobHistoryServer 2059 NameNode 2188 DataNode注意1 : 登录Web端查看JobHistory http://hadoop102:19888/jobhistory
流程十五 : 集群日志聚集功能配置
-
1.日志聚集概念的解释
- 日志聚集 : 应用运行完成以后,将程序运行日志信息上传到HDFS系统上
-
2.配置日志聚集功能的作用
- 可以方便的查看到程序运行详情,方便开发调试,需要我们在hadoop102主机上进行配置.
-
3.配置日志聚集功能的步骤
[atguigu@hadoop102 hadoop]$ pwd 查看当前命令执行路径 /opt/module/hadoop-3.1.3/etc/hadoop [atguigu@hadoop102 hadoop]$ vim yarn-site.xml 配置yarn-site.xml 插入内容如下: ------------------------------------------ <property> <name>yarn.log-aggregation-enablename> <value>truevalue> property> <property> <name>yarn.log.server.urlname> <value>http://hadoop102:19888/jobhistory/logsvalue> property> <property> <name>yarn.log-aggregation.retain-secondsname> <value>604800value> property> ------------------------------------------ :wq [atguigu@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml 分发配置 ... [atguigu@hadoop104 hadoop]$ cd /opt/module/hadoop-3.1.3/ [atguigu@hadoop102 hadoop-3.1.3]$ mapred --daemon stop historyserver 单节点停止一个进程 [atguigu@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh [atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh [atguigu@hadoop102 hadoop-3.1.3]$ mapred --daemon start historyserver 单节点开启一个进程 [atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /output2注意 : 登录Web端查看日志: http://hadoop102:19888/jobhistory
流程十六 : 集群常用脚本编写
① 编写Hadoop集群启停脚本
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 bin]$ vim myhadoop.sh
插入内容如下:
------------------------------------------
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
------------------------------------------
:wq
[atguigu@hadoop102 bin]$ chmod 777 myhadoop.sh 赋予脚本执行权限
[atguigu@hadoop102 bin]$ myhadoop.sh stop
[atguigu@hadoop102 bin]$ jps
[atguigu@hadoop103 hadoop-3.1.3]$ jps
[atguigu@hadoop104 hadoop-3.1.3]$ jps
[atguigu@hadoop102 bin]$ myhadoop.sh start
[atguigu@hadoop102 bin]$ jps
[atguigu@hadoop103 hadoop-3.1.3]$ jps
[atguigu@hadoop104 hadoop-3.1.3]$ jps
② 查看所有主机的jps运行情况脚本
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 bin]$ vim jpsall
插入内容如下:
------------------------------------------
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
------------------------------------------
:wq
[atguigu@hadoop102 bin]$ chmod 777 jpsall 赋予脚本执行权限
[atguigu@hadoop102 bin]$ jpsall
[atguigu@hadoop102 ~]$ xsync /home/atguigu/bin/ 分发/home/atguigu/bin目录,保证自定义脚本在三台机器上都可以使用
流程十七 : 集群时间同步配置
-
1.集群时间同步作用图解

-
2.集群时间同步配置的步骤
[atguigu@hadoop102 ~]$ su 时间服务器配必须用root用户 [root@hadoop102 atguigu]# systemctl status ntpd 查看所有节点ntpd服务状态 [root@hadoop102 atguigu]# systemctl start ntpd 开启ntpd服务 [root@hadoop102 atguigu]# systemctl is-enabled ntpd 设置ntpd服务开机自启动 disabled [root@hadoop102 atguigu]# vim /etc/ntp.conf 修改102主机的ntp.conf配置文件 修改内容如下: ------------------------------------------ 17 restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap 21 # server 0.centos.pool.ntp.org iburst 22 # server 1.centos.pool.ntp.org iburst 23 # server 2.centos.pool.ntp.org iburst 24 # server 3.centos.pool.ntp.org iburst 60 server 127.127.1.0 61 fudge 127.127.1.0 stratum 10 ------------------------------------------ :set number :wq [root@hadoop102 atguigu]# vim /etc/sysconfig/ntpd 插入内容如下: ------------------------------------------ SYNC_HWCLOCK=yes 让硬件时间与系统时间一起同步 ------------------------------------------ :wq [root@hadoop102 atguigu]# systemctl start ntpd 重新启动ntpd服务 [root@hadoop102 atguigu]# systemctl enable ntpd 设置ntpd服务开机启动 Created symlink from /etc/systemd/system/multi-user.target.wants/ntpd.service to /usr/lib/systemd/system/ntpd.service. [atguigu@hadoop103 ~]$ sudo systemctl stop ntpd [atguigu@hadoop103 ~]$ sudo systemctl disable ntpd [atguigu@hadoop104 ~]$ sudo systemctl stop ntpd [atguigu@hadoop104 ~]$ sudo systemctl disable ntpd 关闭所有节点上ntp服务和自启动 [atguigu@hadoop103 ~]$ sudo crontab -e 配置1分钟与时间服务器(102主机)同步一次 编写定时任务如下:如下: ------------------------------------------ */1 * * * * /usr/sbin/ntpdate hadoop102 ------------------------------------------ :wq [atguigu@hadoop103 ~]$ sudo date -s "2021-9-11 11:11:11" 修改103主机时间 [atguigu@hadoop103 ~]$ date 2021年 09月 11日 星期六 11:11:25 CST [atguigu@hadoop103 ~]$ sudo date 1分钟后查看机器是否与时间服务器同步
流程十八 : HDFS API 环境配置
-
1.拷贝hadoop-3.1.0到非中文路径(比如E:\hadoops\software\hadoop-3.1.0)
- 链接:https://pan.baidu.com/s/1wjvVQpMdlcSDkB-Wr-zCXQ?pwd=s9q2
- 提取码:s9q2

-
2.配置HADOOP_HOME环境变量

-
3.将HADOOP_HOME添加到Path变量中

注意 : 如果环境变量不起作用,可以重启电脑尝试。
-
4.验证Hadoop环境变量是否正常

注意 : 双击后有一个窗口一闪而过即表示Hadoop环境变量配置正常, 但是如果报如下错误则说明缺少微软运行库(正版系统往往有这个问题)下载对应的微软运行库安装包双击安装即可。
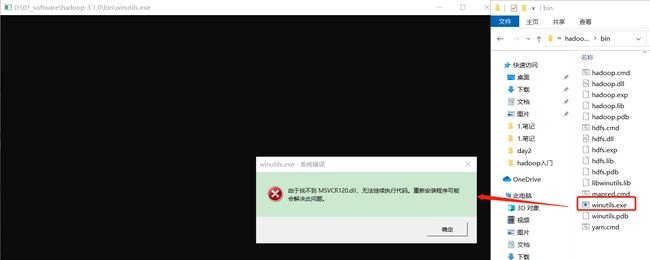
微软运行库安装包:
链接:https://pan.baidu.com/s/173mAjgX8NkbB5vMVgR_VWg?pwd=sx4k
提取码:sx4k -
5.在 IDEA 中新建一个 Maven 项目 HDFSClient

-
6.配置 HDFSClient 项目的 maven 路径

注意 : 没有搭建过Maven环境的请参考我写的这一篇文章 Maven环境搭建。
-
7.配置 Maven 项目 pom.xml 文件
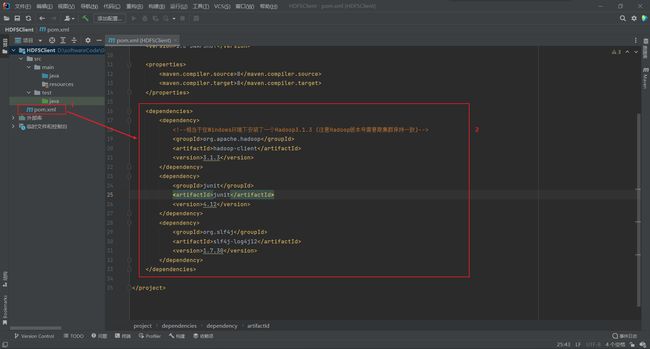
<dependencies> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-clientartifactId> <version>3.1.3version> dependency> <dependency> <groupId>junitgroupId> <artifactId>junitartifactId> <version>4.12version> dependency> <dependency> <groupId>org.slf4jgroupId> <artifactId>slf4j-log4j12artifactId> <version>1.7.30version> dependency> dependencies> -
8.在项目的src/main/resources目录下新建一个 “log4j.properties” 文件并写入内容

log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n -
9.在src/main/java目录下新建一个包名 com.atguigu.hdfs,并创建一个HdfsClient类

-
10.在src/main/resources目录下新建一个hdfs-site.xml文件并写入内容

流程十九 : MapReduce WordCount 环境配置
-
1.在 IDEA 中新建一个 Maven 项目MapReduceDemo

-
2.配置 MapReduceDemo 项目的 maven 路径

-
3.配置 Maven 项目 pom.xml 文件

<dependencies> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-clientartifactId> <version>3.1.3version> dependency> <dependency> <groupId>junitgroupId> <artifactId>junitartifactId> <version>4.12version> dependency> <dependency> <groupId>org.slf4jgroupId> <artifactId>slf4j-log4j12artifactId> <version>1.7.30version> dependency> dependencies> <build> <plugins> <plugin> <artifactId>maven-compiler-pluginartifactId> <version>3.6.1version> <configuration> <source>1.8source> <target>1.8target> configuration> plugin> <plugin> <artifactId>maven-assembly-pluginartifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependenciesdescriptorRef> descriptorRefs> configuration> <executions> <execution> <id>make-assemblyid> <phase>packagephase> <goals> <goal>singlegoal> goals> execution> executions> plugin> plugins> build> -
4.在项目的src/main/resources目录下新建一个 “log4j.properties” 文件并写入内容

log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n -
5.在src/main/java目录下新建一个包名 com.atguigu.mapreduce.wordcount,并分别创建WordCountMapper.java、WordCountReducer.java 和 WordCountDriver.java 三个类
