开源啦!首个多感官数据训练平台;斯坦福CS224W·图机器学习课程;ThinkX系列新作,更易编程的贝叶斯思维;前沿论文 | ShowMeAI资讯日报

日报合辑 | 电子月刊 | 公众号下载资料 | @韩信子
博文&分享
『ThinkBayes2』 贝叶斯思维(第二版) · 文本&代码
https://github.com/AllenDowney/ThinkBayes2
http://allendowney.github.io/ThinkBayes2/
大多数关于贝叶斯统计的书籍都使用数学符号,并使用微积分等数学概念来表达想法。然而本书使用 Python 代码和离散近似(而不是连续数学)。因此,本书中的积分变成了求和,概率分布的大多数运算都是循环或数组运算。
这种呈现形式对于有编程技能的人来说更容易理解,也更通用——因为当我们做出建模决策时,我们可以选择最合适的模型,而不必过多担心模型是否适合数学分析。
本书的原始形式是一系列 Jupyter 笔记本。阅读完每一章后,建议运行代码并进行练习,完成从理论到解决实际问题的过渡。阅读本书前需要熟悉 Python,并对 NumPy 和 Pandas 有所了解。不需要知道微积分或线性代数。不需要任何统计学的先验知识。
- Probability(概率)
- Bayes’s Theorem(贝叶斯定理)
- Distributions(概率分布)
- Estimating Proportions(估计比例)
- Estimating Counts(估计计数)
- Odds and Addends(奇数和偶数)
- Minimum, Maximum, and Mixture(最小、最大和混合)
- Poisson Processes(泊松过程)
- Decision Analysis(决策分析)
- Testing(测试)
- Comparison(比较)
- Classification(分类)
- Inference(推理)
- Survival Analysis(生存分析)
- Mark and Recapture(标记再捕法)
- Logistic Regression(逻辑回归)
- Regression(回归)
- Conjugate Priors(共轭先验)
- MCMC(马尔可夫链蒙特卡洛,Markov chain Monte Carlo)
- Approximate Bayesian Computation(近似贝叶斯计算)

『(CS224W) Machine Learning with Graphs』Stanford斯坦福 · 图机器学习课程
https://www.showmeai.tech/article-detail/352
CS224W 是顶级院校斯坦福出品的图机器学习方向专业课程,对于graph方向的数据挖掘和机器学习(神经网络)有全面的知识覆盖和很高的权威度。如果大家想学习非结构化的图数据上的各类算法,本课程是最适合的课程之一。

- Machine Learning for Graphs(基于图的机器学习)
- Traditional Methods for ML on Graphs(图数据上的传统方法)
- Node Embeddings(节点嵌入)
- Link Analysis: PageRank(PageRank)
- Label Propagation for Node Classification(用于节点分类的标签传播)
- Graph Neural Networks(图神经网络)
- Knowledge Graph Embeddings(知识图谱嵌入)
- Reasoning over Knowledge Graphs(基于知识图的推理)
- Frequent Subgraph Mining with GNNs(使用GNN进行频繁子图挖掘)
- Community Structure in Networks(网络中的社区结构)
- Traditional Generative Models for Graphs(图数据的传统生成模型)
- Deep Generative Models for Graphs(图数据的深度生成模型)
- Advanced Topics on GNNs(GNN 进阶专题)
- Scaling Up GNNs(大规模GNN)
- Guest Lecture: GNNs for Computational Biology(GNNs在计算生物学的应用)
- Guest Lecture: Industrial Applications of GNNs(GNNs的工业应用)
- GNNs for Science(用于科学的 GNN)

ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包(点击 这里 获取这份资料包):
课件(PDF)。Lecture 1~20所有章节,图文结合的呈现,对于理解很有帮助。
代码及作业参考解答(.ipynb)。Colab 0~4代码,Homework 0~3作业答案。
拓展阅读 & 知识图谱资源大全。课程推荐的相关学习资源、清单。

『(6.036) Introduction to Machine Learning』MIT麻省理工 · 机器学习导论课程
https://www.showmeai.tech/article-detail/353
MIT 6.036是全球顶校麻省理工开设的机器学习入门课程,课程系统分版块地讲解了机器学习核心模型算法与解决问题思路。课程内容覆盖:传统机器学习模型(树模型、集成模型、聚类算法、逻辑回归),深度学习典型模型(感知器、神经网络、CNN、RNN),以及强化学习的部分算法。

- Basics(基础知识)
- Perceptrons(感知器)
- Features(特征)
- Logistic regression, a.k.a. linear logistic classification(逻辑回归(对数几率回归))
- Regression(回归建模)
- Neural networks(神经网络)
- Convolutional neural networks(卷积神经网络)
- State machines and Markov decision processes(状态机与马尔可夫决策过程)
- Reinforcement learning(强化学习)
- Recurrent neural networks(循环神经网络)
- Decision trees and random forests(决策树与随机森林)
- Clustering(聚类算法)

ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包(点击 这里 获取这份资料包):
课件。PDF文件。覆盖Lecture 1~13(说明:L7是休息;官方未发布L14讲座的课件)。
作业&答案。.ipynb文件。覆盖 Homework 1~11 的全部作业。

工具&框架
『Blender Labelling Tool』基于Blender的图像标注工具
https://github.com/Dene33/Blender-Labelling-Tool
Blender Labelling Tool 是一个在 Blender(3+)基础上制作的注释工具,它是完全免费和开源的。它可以在视频上标注边界框并以 YOLO 格式导出。

『MASR』流式与非流式语音识别项目
https://github.com/yeyupiaoling/MASR
MASR 全称是神奇的自动语音识别框架(Magical Automatic Speech Recognition),是一款基于 Pytorch 实现的自动语音识别框架。MASR 致力于简单、实用的语音识别项目,可部署在服务器、Nvidia Jetson设备(未来还计划支持 Android 等移动设备),同时兼容在线和离线识别。目前支持DeepSpeech2模型,支持多种数据增强方法。

『embetter』嵌入工具
https://github.com/koaning/embetter
https://koaning.github.io/embetter/
Embetter 实现了 Scikit-Learn 兼容的计算机视觉和文本的嵌入。它使应用 Scikit-Learn 管道快速建立概念证明变得非常简单。

『Xtreme1』数据管理平台
https://github.com/basicai/xtreme1
BasicAI 推出了世界上第一个多感官训练数据的开源平台 Xtreme1,它提供了对数据注释、数据整理和本体管理的功能,以解决 2D 图像和 3D 点云数据集的ML挑战。内置的人工智能辅助工具使你的注释工作在 2D/3D 物体检测、3D 实例分割和 LiDAR-Camera 融合项目中的效率提高到新的水平。



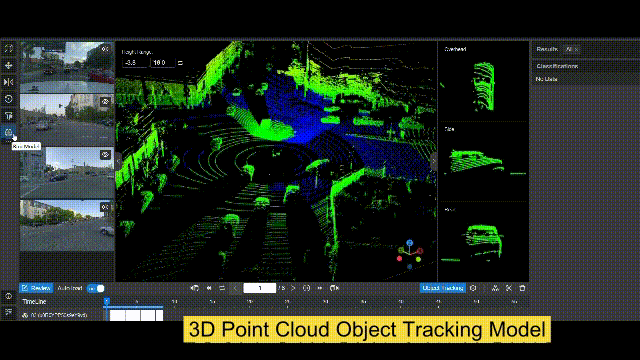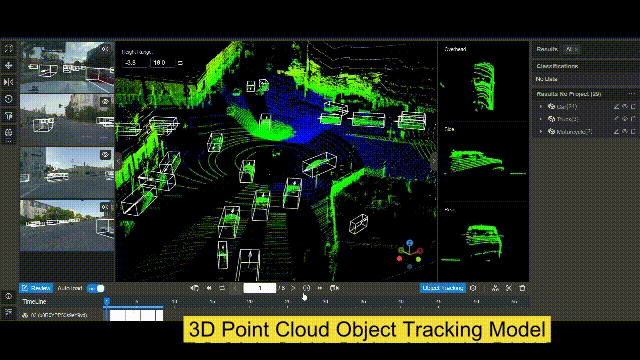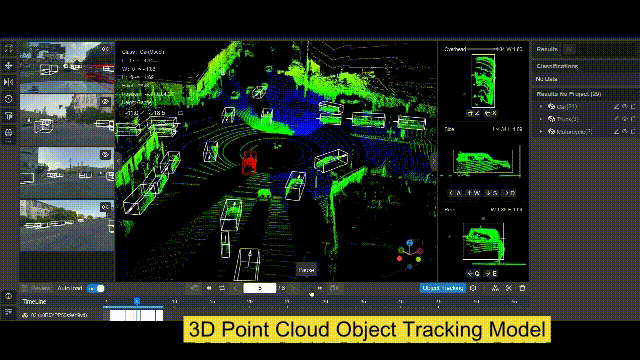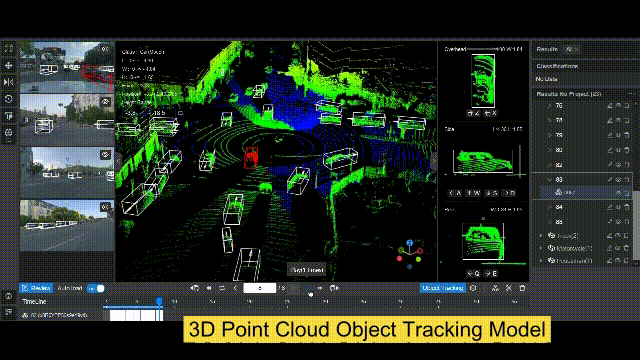
『Datasets server』数据集服务器
https://github.com/huggingface/datasets-server
https://huggingface.co/docs/datasets-server/index
Datasets server 是一个轻量级的网络 API,用于可视化和探索所有类型的数据集–计算机视觉、语音、文本和表格–存储在Hugging Face Hub上。随着数据集规模的扩大和数据类型的丰富,预处理(存储和计算)这些数据集的成本可能具有挑战性和耗费时间。为了帮助用户访问这些现代数据集,Datasets Server在后台运行一个服务器,提前生成API响应,并将其存储在数据库中,这样当你通过API进行查询时,它们就会立即返回。

数据&资源
『Awesome talking face generation』说话脸生成相关文献资源集
https://github.com/YunjinPark/awesome_talking_face_generation

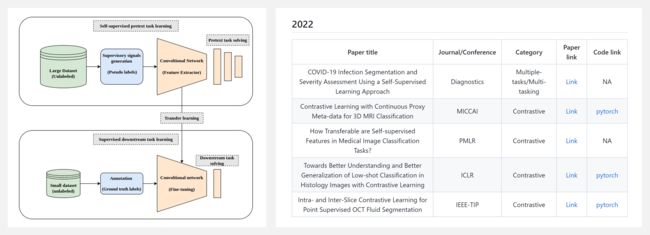
『Awesome Self-Supervised Learning in Medical Imaging』医学影像自监督学习相关文献资源列表
https://github.com/SaeedShurrab/awesome-self-supervised-learning-in-medical-imaging
自监督学习 (SSL) 是一种混合学习方法,它同时结合了监督学习和无监督学习。更清楚地说,SSL 是一种旨在通过从未标记数据池中生成监督信号,而不需要人工注释来为特定任务学习语义有用特征的方法。然后,将这些表示用于标记数据量有限的后续任务。
为什么要在医学成像中进行自我监督学习?① 未标记的医学影像数据很丰富,但人工标注的数据却很少。② 构建足够大的人类注释医学成像数据集是:昂贵的、耗时的、需要有经验的人员。③ 容易出现患者隐私保护问题。
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.10.04 『分子对接』 DiffDock: Diffusion Steps, Twists, and Turns for Molecular Docking
- 2022.10.03 『梯度策略方法』 Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization
- 2022.09.30 『蛋白质结构预测』 Protein structure generation via folding diffusion
⚡ 论文:DiffDock: Diffusion Steps, Twists, and Turns for Molecular Docking
论文时间:4 Oct 2022
领域任务:Blind Docking,分子对接
论文地址:https://arxiv.org/abs/2210.01776
代码实现:https://github.com/gcorso/diffdock
论文作者:Gabriele Corso, Hannes Stärk, Bowen Jing, Regina Barzilay, Tommi Jaakkola
论文简介:Predicting the binding structure of a small molecule ligand to a protein – a task known as molecular docking – is critical to drug design./预测小分子配体与蛋白质的结合结构–一项被称为分子对接的任务–对于药物设计至关重要。
论文摘要:预测小分子配体与蛋白质的结合结构–一项被称为分子对接的任务–对于药物设计至关重要。与传统的基于搜索的方法相比,最近将对接视为回归问题的深度学习方法减少了运行时间,但在准确性方面还没有实质性的改善。我们把分子对接看作是一个生成性建模问题,并开发了DiffDock,一个在配体姿势的非欧几里德流形上的扩散生成模型。为此,我们将这个流形映射到对接中涉及的自由度(平移、旋转和扭转)的乘积空间,并在这个空间上开发了一个有效的扩散过程。根据经验,DiffDock在PDBBind上获得了38%的顶级1级成功率(RMSD<2A),大大超过了以前传统对接(23%)和深度学习(20%)方法的最先进水平。此外,DiffDock具有快速的推理时间,并提供具有高选择性精度的置信度估计。

⚡ 论文:Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization
论文时间:3 Oct 2022
领域任务:Decision Making, Policy Gradient Methods, 决策制定,梯度策略方法
论文地址:https://arxiv.org/abs/2210.01241
代码实现:https://github.com/allenai/rl4lms
论文作者:Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
论文简介:To help answer this, we first introduce an open-source modular library, RL4LMs (Reinforcement Learning for Language Models), for optimizing language generators with RL./为了帮助回答这个问题,我们首先介绍了一个开源的模块化库,RL4LMs(语言模型强化学习),用于用RL优化语言生成器。
论文摘要:我们解决了将预训练的大型语言模型(LMs)与人类的偏好相一致的问题。如果我们将文本生成视为一个连续的决策问题,强化学习(RL)似乎是一个自然的概念框架。然而,将RL用于基于LM的生成面临着经验上的挑战,包括由于组合行动空间造成的训练不稳定,以及缺乏为LM对齐而定制的开源库和基准。因此,研究界出现了一个问题:RL是NLP的一个实用范式吗?为了帮助回答这个问题,我们首先介绍了一个开源的模块库,RL4LMs(语言模型强化学习),用于用RL优化语言生成器。该库由on-policy RL算法组成,可用于训练HuggingFace库(Wolf等人,2020)中的任何编码器或编码器-解码器LM,具有任意的奖励函数。接下来,我们介绍了GRUE(通用强化语言理解评估)基准,这是一组6个语言生成任务,这些任务不是由目标字符串监督的,而是由奖励函数监督的,这些奖励函数捕捉了人类偏好的自动化措施。GRUE是第一个针对NLP任务的RL算法的排行榜式评估。最后,我们介绍了一种易于使用、性能良好的RL算法,NLPO(自然语言策略优化),该算法可以学习有效地减少语言生成中的组合动作空间。我们表明:1)RL技术在使LM与人类偏好相一致方面通常比监督方法更好;2)根据自动和人类评估,NLPO比以前的政策梯度方法(如PPO(Schulman等人,2017))表现出更大的稳定性和性能。

⚡ 论文:Protein structure generation via folding diffusion
论文时间:30 Sep 2022
领域任务:Denoising, Protein Structure Prediction, 去噪,蛋白质结构预测
论文地址:https://arxiv.org/abs/2209.15611
代码实现:https://github.com/microsoft/foldingdiff
论文作者:Kevin E. Wu, Kevin K. Yang, Rianne van den Berg, James Y. Zou, Alex X. Lu, Ava P. Amini
论文简介:The ability to computationally generate novel yet physically foldable protein structures could lead to new biological discoveries and new treatments targeting yet incurable diseases./通过计算产生新的但物理上可折叠的蛋白质结构的能力可能加速新的生物发现和针对尚未治愈的疾病的新疗法。
论文摘要:通过计算生成新的但在物理上可折叠的蛋白质结构的能力可能加速新的生物发现和针对尚未治愈的疾病的新疗法。尽管最近在蛋白质结构预测方面取得了进展,但从神经网络中直接生成多样化的新型蛋白质结构仍然很困难。在这项工作中,我们提出了一个新的基于扩散的生成模型,通过一个反映本地折叠过程的程序来设计蛋白质骨架结构。我们将蛋白质主干结构描述为一系列捕捉组成氨基酸残基的相对方向的连续角度,并通过从随机的、未折叠的状态到稳定的折叠结构的去噪产生新的结构。这不仅反映了蛋白质在生物学上是如何扭曲成能量上有利的构象的,而且这种表示方法固有的移位和旋转不变性大大减轻了对复杂的等价网络的需要。我们用一个简单的transformer骨架训练了一个去噪扩散概率模型,并证明我们所得到的模型无条件地生成了高度现实的蛋白质结构,其复杂性和结构模式与自然存在的蛋白质相似。作为一种有用的资源,我们发布了第一个开源的代码库和训练有素的蛋白质结构扩散模型。


我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。
