本教程对操作系统没有特殊要求,但是应该熟悉创建文件和目录的机制。建议使用 XML 编辑器或者集成开发环境(IDE)。
对于本教程后半部分的 EPUB 创建自动化内容,需要读者了解基本的 XML 处理技巧 — XSLT、 DOM 或者基于 SAX 的解析 — 并熟悉使用 XML 原生 API 构造 XML 文档。
阅读本教程不需要熟悉 EPUB 文件格式。
系统需求
尝试本教程中的例子,需要一个 Java 解释器(1.5 或更高版本)和 Python 解释器(2.4 或更高版本)以及相应的 XML 库。不过,有经验的 XML 开发人员很容易将这些例子修改为适合任何编程语言和 XML 库。
回页首
关于 EPUB 格式
了解 EPUB 的背景,EPUB 最适合做什么,以及 EPUB 和便携式文档格式(PDF)的区别。
什么是 EPUB?
EPUB 是可逆的数字图书和出版物 XML 格式,数字出版业商业和标准协会 International Digital Publishing Forum (IDPF) 制定的标准。IDPF 于 2007 年 10 月正式采用 EPUB,随后被主流出版商迅速采用。可以使用各种开放源代码或者商业软件在所有主流操作系统、Sony PRS 之类的 e-ink 设备或者 Apple iPhone 之类的小型设备上阅读 EPUB 格式。
xml version="1.0"?><containerversion="1.0"xmlns="urn:oasis:names:tc:opendocument:xmlns:container"><rootfiles><rootfilefull-path="OEBPS/content.opf"media-type="application/oebps-package+xml" />rootfiles>container>
xml version='1.0' encoding='utf-8'?><packagexmlns="http://www.idpf.org/2007/opf"xmlns:dc="http://purl.org/dc/elements/1.1/"unique-identifier="bookid"version="2.0"><metadata><dc:title>Hello World: My First EPUBdc:title><dc:creator>My Namedc:creator><dc:identifierid="bookid">urn:uuid:12345dc:identifier><metaname="cover"content="cover-image" />metadata><manifest><itemid="ncx"href="toc.ncx"media-type="text/xml"/><itemid="cover"href="title.html"media-type="application/xhtml+xml"/><itemid="content"href="content.html"media-type="application/xhtml+xml"/><itemid="cover-image"href="images/cover.png"media-type="image/png"/><itemid="css"href="stylesheet.css"media-type="text/css"/>manifest><spinetoc="ncx"><itemrefidref="cover"linear="no"/><itemrefidref="content"/>spine><guide><referencehref="cover.html"type="cover"title="Cover"/>guide>package>
...
<metadata><dc:title>Hello World: My First EPUBdc:title><dc:creator>My Namedc:creator><dc:identifierid="bookid">urn:uuid:12345</dc:identifier><metaname="cover"content="cover-image" />metadata>
...
有两个术语是必须的,即 title 和 identifier。按照 EPUB 规范,标识符必须 是惟一的,但是这个惟一的值要靠数字图书的创建者来定义。对于图书出版商来说,这个字段一般包含 ISBN 或者 Library of Congress 编号。对于其他 EPUB 创建者,可以考虑使用 URL 或者很大的随机生成的惟一用户 ID(UUID)。要注意,属性 unique-identifier 的值必须和 dc:identifier 元素的 ID 属性匹配。
xml version='1.0' encoding='utf-8'?><ncxxmlns="http://www.daisy.org/z3986/2005/ncx/"version="2005-1"><head><metaname="dtb:uid"content="urn:uuid:12345"/><metaname="dtb:depth"content="1"/><metaname="dtb:totalPageCount"content="0"/><metaname="dtb:maxPageNumber"content="0"/>head><docTitle><text>Hello World: My First EPUBtext>docTitle><navMap><navPointid="navpoint-1"playOrder="1"><navLabel><text>Book covertext>navLabel><contentsrc="title.html"/>navPoint><navPointid="navpoint-2"playOrder="2"><navLabel><text>Contentstext>navLabel><contentsrc="content.html"/>navPoint>navMap>ncx>
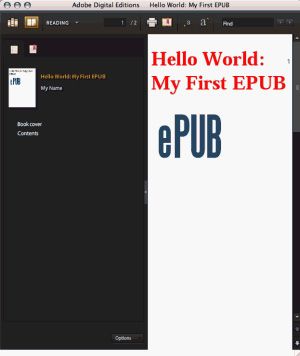
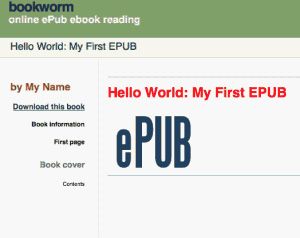
<htmlxmlns="http://www.w3.org/1999/xhtml"><head><title>Hello World: My First EPUBtitle><linktype="text/css"rel="stylesheet"href="stylesheet.css" />head><body><h1>Hello World: My First EPUBh1><div><imgsrc="images/cover.png"alt="Title page"/>div>body>html>
EPUB 的 XHTML 需要符合几条要求,和一般的 Web 开发不同:
内容必须是有效的 XHTML 1.1:XHTML 1.0 Strict 和 XHTML 1.1 的主要区别是去掉了 name 属性(使用 ID 引用锚元素)。
my-book.epub: image file OEBPS/images/cover.png is missing
my-book.epub: resource OEBPS/stylesheet.css is missing
my-book.epub/OEBPS/title.html(7): 'OEBPS/images/cover.png':
referenced resource missing in the package
Check finished with warnings or errors!
$ xsltproc /path/to/docbook-xsl-1.74.0/epub/docbook.xsl docbook.xml
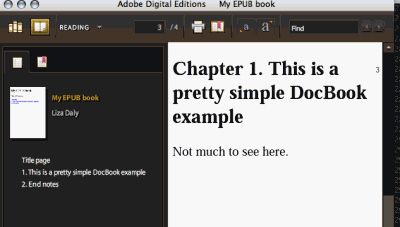
Writing OEBPS/bk01-toc.html for book
Writing OEBPS/pr01.html for preface(preface)
Writing OEBPS/ch01.html for chapter(chapter1)
Writing OEBPS/ch02.html for chapter(end-notes)
Writing OEBPS/index.html for book
Writing OEBPS/toc.ncx
Writing OEBPS/content.opf
Writing META-INF/container.xml
import os.path, shutil
from lxml import etree
deffind_resources(path='/path/to/our/epub/directory'):
opf = etree.parse(os.path.join(path, 'OEBPS', 'content.opf'))
# All the opf:item elements are resourcesfor item in opf.xpath('//opf:item',
namespaces= { 'opf': 'http://www.idpf.org/2007/opf' }):
# If the resource was not already created by DocBook XSL itself, # copy it into the OEBPS folder
href = item.attrib['href']
referenced_file = os.path.join(path, 'OEBPS', href):
ifnot os.path.exists(referenced_file):
shutil.copy(href, os.path.join(path, 'OEBPS'))
defcreate_mimetype(path='/path/to/our/epub/directory'):
f = '%s/%s' % (path, 'mimetype')
f = open(f, 'w')
# Be careful not to add a newline here
f.write('application/epub+zip')
f.close()
用 Python 创建 EPUB 包
现在只需要将文件打包成有效的 EPUB ZIP 包。需要分两步:将未经压缩的 mimetype 文件作为第一个文件加进去,然后添加其他目录。如 清单 20 所示。
清单 20. 使用 Python zipfile 模块创建 EPUB 包
import zipfile, os
defcreate_archive(path='/path/to/our/epub/directory'):'''Create the ZIP archive. The mimetype must be the first file in the archive
and it must not be compressed.'''
epub_name = '%s.epub' % os.path.basename(path)
# The EPUB must contain the META-INF and mimetype files at the root, so # we'll create the archive in the working directory first and move it later
os.chdir(path)
# Open a new zipfile for writing
epub = zipfile.ZipFile(epub_name, 'w')
# Add the mimetype file first and set it to be uncompressed
epub.write(MIMETYPE, compress_type=zipfile.ZIP_STORED)
# For the remaining paths in the EPUB, add all of their files# using normal ZIP compressionfor p in os.listdir('.'):
for f in os.listdir(p):
epub.write(os.path.join(p, f)), compress_type=zipfile.ZIP_DEFLATED)
epub.close()
Enum是计算机编程语言中的一种数据类型---枚举类型。 在实际问题中,有些变量的取值被限定在一个有限的范围内。 例如,一个星期内只有七天 我们通常这样实现上面的定义:
public String monday;
public String tuesday;
public String wensday;
public String thursday
java.lang.IllegalStateException: No matching PlatformTransactionManager bean found for qualifier 'add' - neither qualifier match nor bean name match!
网上找了好多的资料没能解决,后来发现:项目中使用的是xml配置的方式配置事务,但是
原文:http://stackoverflow.com/questions/15585602/change-limit-for-mysql-row-size-too-large
异常信息:
Row size too large (> 8126). Changing some columns to TEXT or BLOB or using ROW_FORMAT=DYNAM
/**
* 格式化时间 2013/6/13 by 半仙 [email protected]
* 需要 pad 函数
* 接收可用的时间值.
* 返回替换时间占位符后的字符串
*
* 时间占位符:年 Y 月 M 日 D 小时 h 分 m 秒 s 重复次数表示占位数
* 如 YYYY 4占4位 YY 占2位<p></p>
* MM DD hh mm
在使用下面的命令是可以通过--help来获取更多的信息1,查询当前目录文件列表:ls
ls命令默认状态下将按首字母升序列出你当前文件夹下面的所有内容,但这样直接运行所得到的信息也是比较少的,通常它可以结合以下这些参数运行以查询更多的信息:
ls / 显示/.下的所有文件和目录
ls -l 给出文件或者文件夹的详细信息
ls -a 显示所有文件,包括隐藏文
Spring Tool Suite(简称STS)是基于Eclipse,专门针对Spring开发者提供大量的便捷功能的优秀开发工具。
在3.7.0版本主要做了如下的更新:
将eclipse版本更新至Eclipse Mars 4.5 GA
Spring Boot(JavaEE开发的颠覆者集大成者,推荐大家学习)的配置语言YAML编辑器的支持(包含自动提示,