FPN笔记
论文:Feature Pyramid Networks for Object Detection
Motivation
许多图像识别的检测算法都考虑到不同尺寸图片(multi-scale)对算法的影响。下图是几种利用不同尺寸特征的策略。
a. 图像金字塔,生成不同尺寸的图片,每张图片生成不同的特征,分别进行预测,最后统计所有尺寸的预测结果。这种方法最大的缺点是运算时间长,很难用于训练,在测试的时候可能会用一下。
b. 使用单一feature map进行预测,一般是网络最后一层feature map。Fast R-CNN、Faster R-CNN采用这种方法。顶层的feature map包含粗略的位置信息,导致预测的bbox不精确。而且高层的feature map会忽略小物体信息。
c. 使用金字塔特征结构,使用不同层次的金字塔层feature map进行预测。SSD就是采用这种多尺度特征融合方法,从网络不同层抽取不同尺寸的特征做预测,没有增加额外的计算量。但是SSD没有使用足够底层的特征,SSD使用最底层的特征是VGG的conv4_3。
d. 特征金字塔网络。作者使用这种方法,对顶层特征进行向上采样,并与底层特征进行融合,得到高分辨率,强语义的特征。

作者这篇论文的目标是自然地利用ConvNet特征层次结构的金字塔形状,同时创建一个在所有尺度上都具有强大语义的特征金字塔。作者提出了一个网络架构,把低分辨率、强语义特征(高层特征)和高分辨率、低语义特征(底层特征)通过一个自顶向下的路径和横向连接结合起来。如下图所示

上半部分在特征金字塔的最底层进行预测,下半部分在特征金字塔的所有层单独预测,论文主要使用后者。
Feature Pyramid Networks
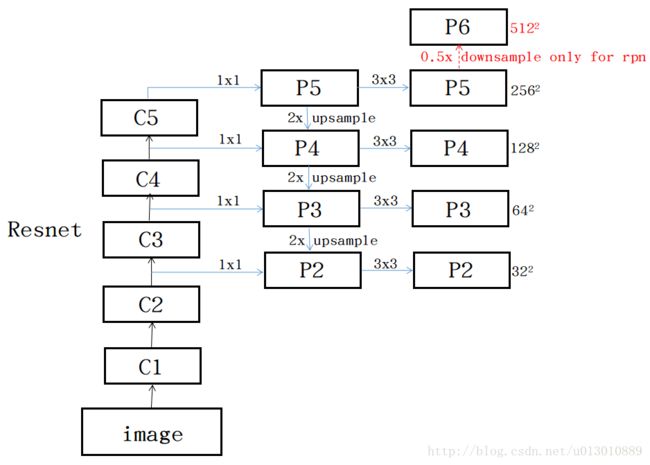
特征金字塔使用的网络骨架backbone是ResNet。特征金字塔网络包括自底向上、自顶向下和横向连接。特征金字塔的横向连接和自顶向下的连接示意图如下

Bottom-up pathway
自底向上结构就是网络的前向传播的过程。在backbone网络中,有许多网络层的输出大小都是一样,这些网络层就在同一阶段,每个特征金字塔层就对应一个阶段。每个阶段的最后一个feature map关联到对应的特征金字塔层,因为每个阶段的最后一个feature map有语义最强的特征。
对ResNet具体地说,ResNet有5个阶段,把conv2,conv3,conv4,conv5对应为特征金字塔的 { C 2 , C 3 , C 4 , C 5 } \{C_2, C_3, C_4, C_5\} {C2,C3,C4,C5}层。不考虑conv1的原因是conv1需要太大的内存。对于每个特征金字塔层,对应于输入图片的步长分别是 { 4 , 8 , 16 , 32 } \{4, 8, 16, 32\} {4,8,16,32}像素。
Top-down pathway and lateral connections
自顶向下结构通过对特征金字塔高层向上采样生成更高分辨率特征。每个横向连接合并自顶向下结构和自底向上结构相同大小的feature map。上图虚线框表示一个横向连接,首先对上一层的特征金字塔层向上采样,扩大两倍。对应的自底向上的feature map进行1×1卷积,然后两者逐元素相加。之后,为了减低向上采样的混淆效应,对得到的feature map进行3×3卷积。最顶层的特征金字塔通过对 C 5 C_5 C5进行1×1卷积得到。得到的特征金字塔层为 { P 2 , P 3 , P 4 , P 5 } \{P_2, P_3, P_4, P_5\} {P2,P3,P4,P5},分别对应 { C 2 , C 3 , C 4 , C 5 } \{C_2, C_3, C_4, C_5\} {C2,C3,C4,C5}。
因为传统的图像金字塔的所有金字塔层使用共享的分类器或回归器,所以作者设置所有特征金字塔层的feature map的通道数为d,所以横向连接的1*1卷积是为了把feature map的通道数转成d。在论文中作者设置 d = 256 d=256 d=256。特征金字塔的feature map都没有使用激活函数,因为添加激活函数的效果没有太大的作用。
Application
作者把特征金字塔应用到RPN网络和Fast R-CNN网络中。
Feature Pyramid Networks for RPN
RPN是在Faster R-CNN中提出的,RPN主要是在feature map中提取出region proposal。RPN在卷积网络中的最后一个单一尺寸的feature map上有3*3的滑动窗体,滑动窗体后面接着一个分类器和回归器,用来预测是region proposal的anchor box。anchor box有不同预定义的尺寸和不同长宽比,可以覆盖不同形状的物体。
应用了特征金字塔的RPN网络不再是在最后一个单一尺寸的feature map上搜索region proposal,而是在特征金字塔的每个特征层上搜索region proposal。而每个特征金字塔层都代表一个尺度,所以在当个尺度上的anchor box只有一个特征尺度。文中定义anchor box在 { P 2 , P 3 , P 4 , P 5 , P 6 } \{ P_2, P_3, P_4, P_5, P_6 \} {P2,P3,P4,P5,P6}的面积分别为 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 {32^2,64^2,128^2,256^2,512^2} 322,642,1282,2562,5122。其中 P 6 P_6 P6层是为了对应 51 2 2 512^2 5122而增加的特征层,通过对 P 5 P_5 P5层进行二次采样得到。对于每个层的anchor box,有3中不同的长宽比 { 1 : 2 , 1 : 1 , 2 : 1 } \{1:2, 1:1, 2:1\} {1:2,1:1,2:1},这样,整个使用特征金字塔的RPN有15中不同的anchor box。下图来自这篇博客,可以很好地说明使用特征金字塔的RPN结构
关于RPN的其他内容和Faster R-CNN中描述一样。
Feature Pyramid Networks for Fast R-CNN
Fast R-CNN主要内容是使用RoI pooling从feature map中池化region proposal的区域成固定大小的特征向量,然后传到分类器和回归器中获得物体的类别和在原图的精确的bounding box。在Fast R-CNN中应用特征金字塔,类似于RPN,就是从特征金字塔的feature map中获取region proposal的区域特征。
这里的问题是RoI区域的特征从哪个feature map中获取。作者是这样选择的,设RoI在原图的宽和高是w和h,它从金字塔的 P k P_k Pk层选取特征,k与w和h的关系为
k = ⌊ k 0 + l o g 2 ( w h / 224 ) ⌋ k = \lfloor k_0 + log_2 (\sqrt{wh} / 224) \rfloor k=⌊k0+log2(wh/224)⌋
这里224是预训练时输入图片的大小, k 0 k_0 k0是目标层,作者设定 k 0 = 4 k_0=4 k0=4,即默认是从 P 4 P_4 P4中提取特征。上述公式的意义是,当RoI的大小变小时,那么就应该从更大分辨率的特征层提取特征。比如面积变为224的1/2,那么 k = 3 k=3 k=3。