【目标检测 论文泛读】-----FPN------(Feature Pyramid Networks for Object Detection)
文章目录
- R-CNN模型系列回顾
- FPN模型提出的背景
- 前人做的工作
-
- 各种金字塔模型
- 作者提出的改进方法
-
- FPN模型:
-
- Bottom-up
- Top-down
- Lateral Connection
- FPN 应用在Faster R-CNN上
- 小总结
R-CNN系列推演:
- R-CNN 论文解读
- SSPnet 论文解读
- Fast R-CNN 论文解读
- Faster R-CNN 论文解读
- FPN 论文解读
- Mask R-CNN 论文解读
每一篇都是前一篇或者前几篇的改造版,所以按顺序看会比较好。
今天看一下 FPN。
论文题目:Feature Pyramid Networks for Object Detection
论文地址:http://cn.arxiv.org/abs/1612.03144
这是R-CNN系列的第五篇要读的论文。
R-CNN模型系列回顾
老规矩,先大概回顾一下之前的几个模型。
| R-CNN | SPP | Fast R-CNN |
|---|---|---|
| 一张图片提取2000个候选框 ,并强制缩放到固定尺寸后送给CNN | 整张图片直接送给CNN | 整张图片+一组候选框送给CNN |
| CNN提取每个候选框的feature map | CNN得到整张图的feature map,通过SS得到候选区域与feature map直接映射得到特征向量 | CNN得到feature map 通过ROI池化层得到特征向量 |
| 将CNN提取的feature map 送给SVM分类,送给BB回归进行定位修复 | 映射的特征向量给SSP,SSP输出固定大小的特征向量,再给 FC,再SVM+回归 | 特征向量送入FC 再接 一个合并网络(softmax分类+BB回归) |
| Faster R-CNN |
|---|
| 整张图片给CNN,提取出feature map |
| feature map送给RPN模块,RPN内部: 滑窗生成anchors,然后分类(背景还是物体)+回归修正 得到精准的候选框。 |
| 精准候选框+第一步整张图的feature map送给ROI池化,生成候选框的feature map,最后分类(物体的分类)+回归。 |
FPN模型提出的背景
在日常操作中,图片的输入尺寸大小不一是普遍的,并且全连接层需要固定的输入,R-CNN提出的方法是直接固定图片尺寸给CNN,但这样是有缺陷的,通过缩放变形固定尺寸,必然使得CNN提取特征不那么高效。SPPnet针对这一点提出了金字塔池化模型SPP,使得让输入不再固定尺寸,让CNN充分提取原图特征后再通过SPP输出固定尺寸给全连接层。Fast R-CNN直接提出ROI池化代替了SPP。
作者在论文开头就说,金字塔结构是针对不同尺寸的输入所必须的,但是由于他非常占用显存和计算量,所以逐步被各种方法所代替,在此,作者想到一个特殊的构造金字塔的方法,他可以减少显存占用和计算量。
前人做的工作
各种金字塔模型
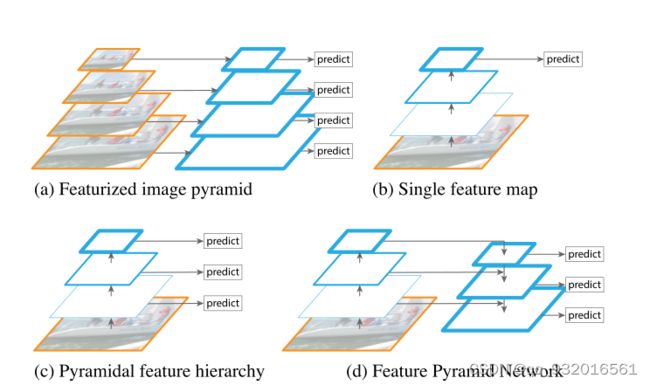
这张图是论文给出的 前人的金字塔模型。
- A:最基础的金字塔,将image缩放成四种或多种不同尺寸,然后分别进行目标检测,这样做毫无疑问,内存,计算量,时间等等都将成倍增加(传统的机器视觉算法那边用这个的多)。
- B:在CNN的结束时,也就是只在最后一层的feature map上进行检测,这其实相当于已经抛弃金字塔结构了。比如之前的SPPnet,Fast R-CNN ,Faster R-CNN等都是这样做的。
- C:着就是在卷积的过程中进行操作,卷积池化等本身就是个金字塔结构,缺点:高层损失了浅层信息,浅层损失了语义信息(语义鸿沟问题),这块可以通俗的理解,底层网络对图片的定位比较好,语义比较差,高层则相反(因为底层下采样次数少,所以定位效果好)。
- D:算是C的改进,融合了低级和高级的特征信息,在最底下那一层进行检测。
作者提出的改进方法
FPN模型:
FPN:Feature Pyramid Network
基于CNN固有的pyramid hierarchy,通过skip connection构建一个从上到下的通道(top-down path), 仅需要少量成本生成特征金字塔 feature pyramid,并且对于每一层的 不同尺寸的 feature pyramid都进行目标检测。
实际上就是D的改进版,D是只在最下面一层进行检测,而FPN是在每一层进行检测。

左侧模型叫bottom-up,右侧模型叫top-down,横向的箭头叫横向连接lateral connections。
这样连接就解决了高底层之间的语义鸿沟问题。
Bottom-up
Bottom-up就是图片输入到网络中后,通过backbone网络(VGG ResNet这些)来提取特征的过程(前向传播),每在同样大小的feature上卷积几次才进行一次池化操作,我们把在同样大小feature上的卷积称之为一个stage。d图这里画的蓝框图是每个stage的最后一个卷积层,因为每个stage的最后一层feature语义信息最多。
这里有个注意的点,图中的蓝框叫做stage,虽然只用一个蓝色框代表一个stage,但其实他是很多层的集合,这些层有一个共同点就是输出的特征图的大小相同。
相邻的stage之间的下采样比例为2。
Top-down
Top-down是将高层的feature map经过上采样从上往下传递,高层的特征具有丰富的语义信息,这样从上往下传播就能融合高低层的特征信息,解决语义鸿沟问题,原论文中采用的是最近邻插值方法,使特征图尺寸扩大为原来的两倍。
Lateral Connection
中间横向连接的这一块放大就是论文给出的下面这张图。

过程分为三步:
- 对于左边Bottom-up的每个stage输出的feature map 先进行1 * 1 卷积降维。
- 然后再将得到的特征和上一层特征上采样(右侧)得到特征图进行融合,就是相加 add(两者size和channel相同)。
- 相加完再经过一个3 * 3 卷积(无激活函数)得到本层的特征输出,每个层级共享分类/回归器,这些3 * 3 输出通道为256。使用 3 * 3卷积的目的是为了消除混叠效应。
关于混叠效应:
混叠效应:在统计、信号处理和相关领域中,混叠是指取样信号被还原成连续信号时产生彼此交叠而失真的现象。当混叠发生时,原始信号无法从取样信号还原。而混叠可能发生在时域上,称做时间混叠,或是发生在频域上,被称作空间混叠。在视觉影像的模拟数字转换或音乐信号领域,混叠都是相当重要的议题。因为在做模拟-数字转换时若取样频率选取不当将造成高频信号和低频信号混叠在一起,因此无法完美地重建出原始的信号。为了避免此情形发生,取样前必须先做滤波的操作。
在视频信号处理过程中,有两种方法可以消除混叠现象:
1.直接提高采样频率,但是采样频率不能无限提高;
2.在采样频率固定的情况下,可通过低通滤波器消除大于尼奎斯特频率的高频信号,从而消除混叠现象;
所以这边使用一个3∗3卷积核来卷积特征图来产生最后的参考特征图。
参考博客:知乎
FPN 应用在Faster R-CNN上
Faster R-CNN里面有一个RPN模型。
可以去看一下前两天的Faster R-CNN论文解读
简单回顾一下RPN做的事:CNN输出的feature map给到RPN,然后通过anchors生成预测框(256D),将预测框再交给两部分,一部分是判断他是目标物体还是背景(左分支,叫做目标分数),另一部分就是做回归修正框的位置(右分支)。
以ResNet50为例的backbone,五个特征层{P2,P3,P4,P5,P6}分别对应尺寸为{ 3 2 2 32^2 322, 6 4 2 , 64^2, 642, , 12 8 2 128^2 1282, 25 6 2 256^2 2562, 51 2 2 512^2 5122}的anchor,因为使用FPN金字塔结构本身就有不同尺度了,所以不再使用RPN中的3种尺度变换,但保留长宽比的变换,且比例与RPN相同,所以每层上就有3 * 5 = 15种anchor。
看一下FPN和RPN的组合流程:
还是看这张图。

FPN和RPN的组合步骤:
- 1.将需要处理的图片送入bottom-up(左侧),通常就是ResNet,VGG这种backbone;
- 2.构建对应的top-down网络(即对层4进行上采样操作,先用1x1的卷积对层2进行降维处理,然后将两者相加(对应元素相加),最后进行3x3的卷积操作);
- 3.在图中的4、5、6层上面分别进行RPN操作,即一个3x3的卷积后面分两路,分别分类和回归操作,这里的分类就是背景和目标的分类;
- 4.将上一步获得的候选ROI分别输入到4、5、6层上面分别进行ROI Pool操作(输出固定尺寸特征);
- 5.在上一步的基础上面连接两个全连接网络层,然后分两个支路,连接对应的分类层和回归层;
小总结
- FPN 构架了一个可以进行端到端训练的特征金字塔;
- 在每一层特征上都进行了计算,有效提升准确率,但也加大了内存等计算成本;
- 提出结合bottom-up与top-down方法获得较强的语义特征,解决了语义鸿沟问题;
- FPN这种架构属于小模块类型,他与主网络backbone解耦,可以应用到各种任务中去。