知识图谱03:知识图谱的构建方法
1.构建方法
知识图谱的构建方法有三种: 自底向上、自顶向下和二者混合的方法.
1.1 自底向上法
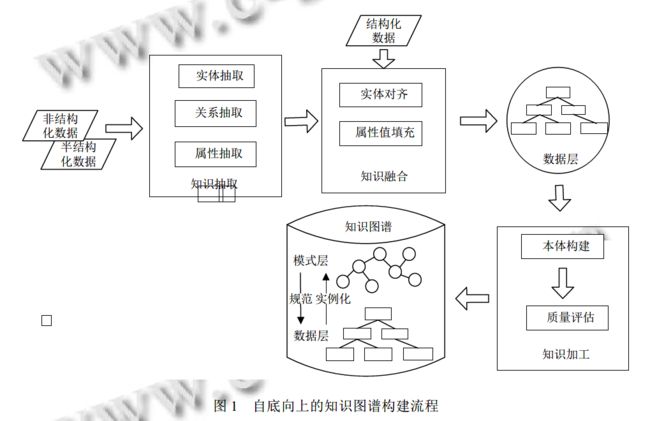
自底向上的构建方法, 从开放链接的数据源中提取实体、属性和关系, 加入到知识图谱的数据层;然后将这些知识要素进行归纳组织, 逐步往上抽象为概念, 最后形成模式层. 自底向上法的流程如图1所示.
-
知识抽取
知识抽取, 类似于本体学习, 采用机器学习技术自动或半自动地从一些开放的多源数据中提取知识图谱的实体、关系、属性等要素. 知识抽取包含实体抽取、关系抽取和属性抽取. 实体抽取自动发现具体的人名、组织机构名、地名、日期、时间等实体,也称为命名实体学习或命名实体识别. 实体抽取的准确率和召回率将直接影响到知识图谱的质量. 关系抽取是指利用语言学、统计学、信息科学等学科的方法技术, 从文本中发现实体间的语义关系. 属性抽取是针对实体而言的, 实体属性的抽取问题可转化为关系抽取问题.
-
知识融合
知识融合, 类似于本体集成. 由于知识图谱在进行知识抽取工作时所使用的数据源是多样化的, 因此可能产生知识重复、知识间关系不明确等问题. 知识融合可消除实体、关系、属性等指称项与事实对象之间的歧义, 使不同来源的知识能够得到规范化整合. 知识融合分为: (1)实体对齐: 可用于判断相同或不同数据集中的多个实体是否指向客观世界同一实体, 解决一个实体对应多个名称的问题. (2)属性值填充: 针对同一属性出现不同值的情况, 根据数据源的数量和可靠度进行决策, 给出较为准确的属性值.
-
知识加工
对已构建好的数据层进行概念抽象,即构建知识图谱的模式层. 知识加工包括本体构建和质量评估. 基于本体形成的知识库不仅层次结构较强,并且冗余程度较小. 由于技术的限制, 得到的知识元素可能存在错误, 因此在将知识加入知识库以前, 需要有一个评估过程. 通过对已有知识的可信度进行量化, 保留置信度高的知识来确保知识库的准确性.
1.2 自顶向下
-
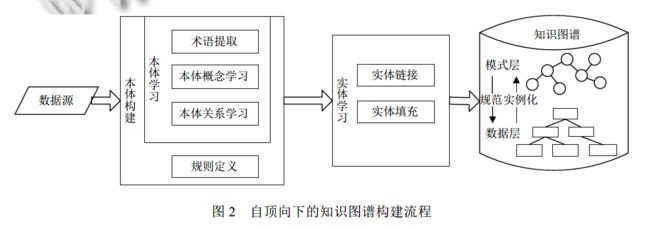
本体构建, 构建知识图谱的模式层.
从最顶层的概念开始构建顶层本体, 然后细化概念和关系, 形成结构良好的概念层次树. 需要利用一些数据源提取本体, 即本体学习。
-
实体学习
将知识抽取得到的实体匹配填充到所构建的模式层本体中.
1.3自顶向下和自底向上结合
首先, 在知识抽取的基础上归纳构建模式层, 之后可对新到的知识和数据进行归纳总结, 从而迭代更新模式层, 并基于更新后的模式层进行新一轮的实体填充. 如百度知识图谱, 就是利用内外部以及用户数据采用混合方法构建所得。
自顶向下法较好体现概念间层次, 但人工依赖性强、模式层更新受限, 仅适用于数据量小的知识图谱构建; 自底向上法更新快、支持大数据量的知识图谱构建, 但知识噪音大、准确性不高; 混合方法灵活性强, 但模式层构建难度大
2. 数据源
构建知识图谱的数据源主要有: 百科类半结构化的网页、结构化程度较低的普通网页、语料库、已构建好的知识库等. 所用的数据源影响知识图谱的质量,也影响构建过程.
2.1 百科网站
百科网站有固定的页面模版, 每一页面都针对某一概念或实体进行详细的介绍. 这样的半结构化形式,更易于实施知识抽取. 并且, 大多数百科网站知识质量高, 权威性强, 出错率较低, 抽取所得知识的质量更高.广义来讲, 符合这些特征的网站都可视为百科网站, 如购物网站、电影、音乐网站等, 也可以通过相似的方法构建相关领域的知识图谱。
基于百科网站的知识图谱构建又可分为两类:(1) 单百科网站的深度知识抽取, 典型代表有Dbpedia、Yago和CN-DBpedia. Dbpedia和Yago以维基百科作为数据源; CN-Dbpedia以百度百科作为数据源. (2) 多百科网站的知识融合, 典型代表有zhishi.me和XLore.Zhishi.me融合了百度百科、互动百科以及中文维基百科. XLore融合了百度百科、互动百科以及英文维基百科. 这两类构建过程中的侧重点也不同, 前者更侧重于抽取, 后者不仅需要知识抽取还注重融合.
2.2 普通网页
尽管百科网站包含了大量的常见知识, 但其所覆盖的知识范围有限, 不能满足通用知识图谱和专业知识图谱的构建需求. 因此, 结构化程度较低的普通网页是知识图谱的另一大数据来源. 普通网页数据的格式丰富多样, 没有较为一致的规范, 且包含的知识可能存在大量的冗余和错误, 准确率较低. 因此, 基于普通网页的知识抽取工作的复杂度较高, 知识融合的难度更大. 此类知识图谱的构建工作重点在于知识抽取与知识融合. 卡内基梅隆大学的——“永不停止的语言学习”项目(Never-Ending Language Learning, NELL), 就是从上亿个网页中进行知识的抽取。
3. 知识更新
随着人们对客观世界的认知加深, 信息与知识量不断增加, 知识图谱的内容也需要与时俱进, 迭代更新,增加新的知识, 删除过时的知识.
根据知识图谱的逻辑结构, 知识图谱的更新可分
为模式层更新和数据层更新. 模式层更新是指本体中元素的更新, 包括概念的增加、修改、删除, 概念属性的更新以及概念之间关系的更新等. 其中, 概念属性的更新操作会直接影响到所有与其直接或间接相关的子概念和实体. 因此, 模式层更新多数情况下是在人工干预的情况下完成的, 需要人工定义规则, 人工处理冲突等, 实施起来有一定的复杂度. 数据层更新指的是实体元素的更新, 包括实体以及实体间关系和属性值的增加、修改、删除. 由于数据层的更新对知识图谱的整体架构影响较小, 通过在可靠数据源(如百科类网站)自动抽取的方式即可完成.
根据更新的方式, 知识图谱的更新可分为增量更新和完全更新. 增量更新是以知识图谱数据源(维基百科等)发布出的更新内容为基础对知识图谱进行部分更新. 也可以基于用户在语义搜索平台上的行为, 如反馈信息过时或搜索了一个知识图谱中没有的新词而进行相应的更新. 完全更新是指间隔一定的周期, 重新将知识图谱数据源的全部数据进行一次抽取解析. 完全更新的优点在于: 能较大程度保证知识图谱更新过程中的逻辑一致性, 适用于模式层的更新. 但该方法代价昂贵, 且耗时长, 不能保证时效性.
参考:
[1]黄恒琪,于娟,廖晓,席运江.知识图谱研究综述.计算机系统应用,2019,28(6):1–12. http://www.c-s-a.org.cn/1003-3254/6915.html
