Dual Attention Network for Scene Segmentation--2019.Jun Fu
- 1、引言
- 2、DANet
-
- 2.1 Channel attention module
- 2.2 Position attention module
- 2.3 输出部分的操作
- 3、官方代码
- 4、结论
以往的工作是通过多尺度特征融合来捕获丰富的特征,但是本文通过self-attention机制来捕获丰富的上下文依赖。提出了基于self-attention的通道注意力和空间注意力,能够自适应整合局部特征的全局依赖,借助并行的方式集成这两种注意力,提出了Dual Attention Network (DANet)。
空间注意力模块通过所有像素位置特征的加权和来选择性(加权和就具有了选择性或者自适应)聚合每个位置特征。同样的通道注意力模块也是聚合所有通道来选择性强调通道间的依赖。
(本文是为场景分割提出的)
1、引言
在场景分各中,需要确认每个像素的归属,但是某单个像素点的归属又和它周围的像素有关(比如它周围的像素都属于同一类,这个像素很有可能也属于这一类)。所以在决定该像素点的命运时,最好参考下它周围的像素特征,但是这个范围可以扩大到全局范围,也就是局部特征和全局特征的依赖关系。
虽然卷积操作通过堆叠可以扩大这种感受范围,但是对于距离较远位置的恐怕很难顾及到。比如两个点在对角线上的两头。而DANet的设计使得任意两点的像素(或任意两个通道间)都能产生关系。
在场景分割中,增强特征表征的辨别能力是必须的。一种方法是多尺度内容融合、增大kernel size和encoder-decoder结构混合中间级和高级语义特征。另一种是使用RNN来探索long-range依赖,不好。
为了解决这种long-range dependencies问题,本文提出了DANet,如图2所示。关于详细的介绍在后面。
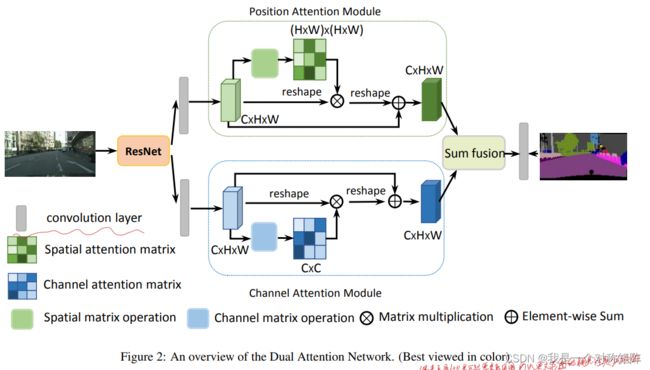
2、DANet
2.1 Channel attention module
首先来看Channel attention module。
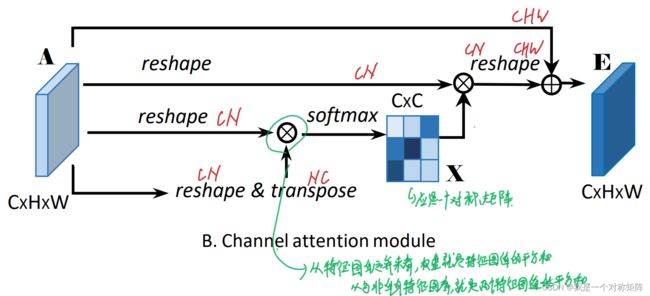
对于输入特征A,首先通过reshape将其转为CxN(文中写为Cx(HW),为了方便表示这里记N=HW),另一分支reshape&transpose得到NxC,将CxN和NxC矩阵乘法得到CxC矩阵X。这个X代表什么?对于X左上角第一个位置,是A第一个通道和第一个通道对应像素的乘积和。
公式为:
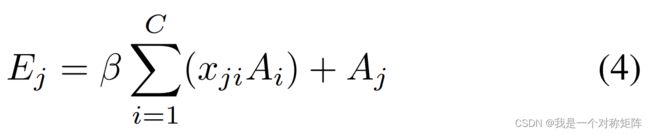
其中 A j A_j Aj代表输入特征图,求和部分就是通道注意力的结果,β是一个控制系数,被设定为可训练的参数,在开始的时候为0,
比如A是一个3通道2x2的特征图,那么通道注意力的结构如下图所示。

2.2 Position attention module
空间注意力大致类似:
对于输入特征A,使用卷积(Conv+BN+activate)产生B、C、D三个特征图待用。图像各张量的shape已用红色笔迹标注,其中N=HxW。
首先将B进行reshape操作,shape从(CxHxW)变为(CxN),转置后就变成(NxC)。
而C仅经过reshape操作,shape变成(CxN),于是(NxC)x(CxN)就得到(NxN)的矩阵S。
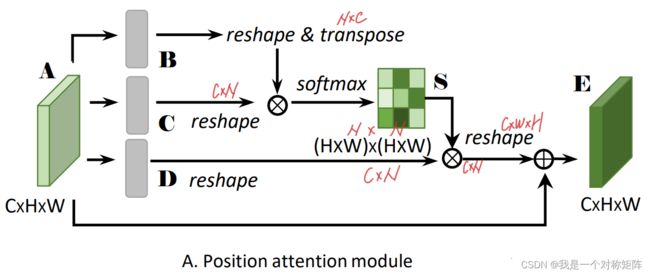
公式为:
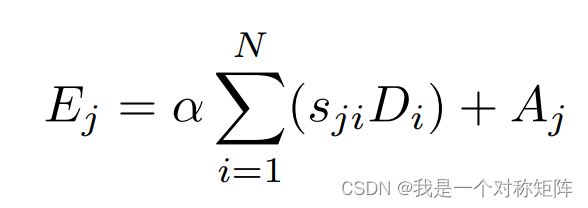
同理 A j A_j Aj为输入特征图,求和为空间注意力的输出,α也是一个可学习的参数,最开始被设定为0。
2.3 输出部分的操作
从上图看好像进行sum fusion后有卷积操作,但是论文中又说“Specifically, we transform the outputs of two attention modules by a convolution layer and perform an element-wise sum to accomplish feature fusion. At last a convolution layer is followed to generate the final prediction map.”似乎是说先卷积后sum?
3、官方代码
更详细的直接看官方代码:DANet/encoding/models/sseg/danet.py
4、结论
DANet本身是为场景分割设计的,所以实验都是和场景分割相关的,不做过多阐述。
总之DANet注意力的思想就是让每个通道(或像素)与所有其他通道(像素)都建立关系,实际上和Transformer很相似。Transformer也是将一个词使用三个矩阵分解为Q、K、V,由QK产生的权重乘以V,你会发现Position attention module也是通过三个卷积产生B、C、D,BC产生权重乘以D。
总之按实验来看想过不错,不知道在分类等任务上怎么样。但是明显计算量等会大于ECA或SENet等注意力。