Pandas中,使用reindex方法报错:index must be monotonic increasing or decreasing的分析
Pandas中,使用reindex方法报错:index must be monotonic increasing or decreasing的分析
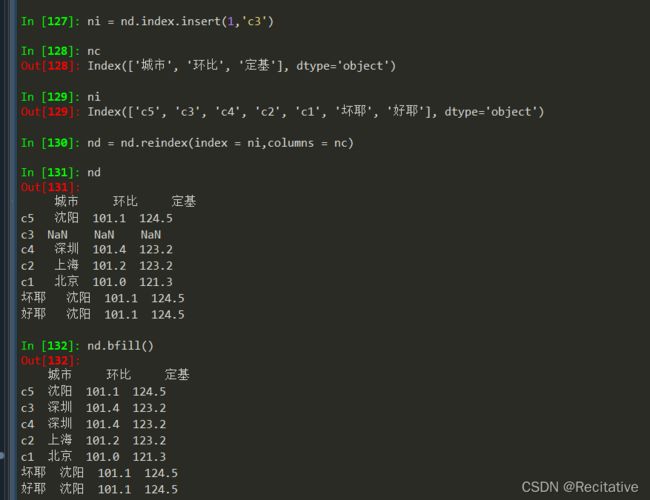
今天在用pandas的时候,写了这一段语句 nd = d.reindex(index = ni,columns = nc,method = 'bfill')
其中nc,ni和d


其他博客中的解决方案是,把method字段提出来单独调用,但没有说明为什么报错,于是自己推了一下。
怀疑columns = nc 和 index = ni不能同用,分别删掉


这样将范围限制在了columns和method上。
看一下源码,报错的是这里
def _searchsorted_monotonic(self, label, side: str_t = "left"):
if self.is_monotonic_increasing:
return self.searchsorted(label, side=side)
elif self.is_monotonic_decreasing:
# np.searchsorted expects ascending sort order, have to reverse
# everything for it to work (element ordering, search side and
# resulting value).
pos = self[::-1].searchsorted(
label, side="right" if side == "left" else "left"
)
return len(self) - pos
raise ValueError("index must be monotonic increasing or decreasing")
注释写的挺清楚了,np.searchsorted需要的是升序排序,如果不是升序就要反转。如果既不是升序也不是降序就报错。
其中调用的searchsorted()
@doc(_shared_docs["searchsorted"], klass="Index")
def searchsorted(self, value, side="left", sorter=None) -> np.ndarray:
return algorithms.searchsorted(self._values, value, side=side, sorter=sorter)
使用了numpy.searchsorted()
往上找:
@final
def _get_fill_indexer_searchsorted(
self, target: Index, method: str_t, limit: int | None = None
) -> np.ndarray:
"""
Fallback pad/backfill get_indexer that works for monotonic decreasing
indexes and non-monotonic targets.
"""
if limit is not None:
raise ValueError(
f"limit argument for {repr(method)} method only well-defined "
"if index and target are monotonic"
)
side = "left" if method == "pad" else "right"
# find exact matches first (this simplifies the algorithm)
indexer = self.get_indexer(target)
nonexact = indexer == -1
indexer[nonexact] = self._searchsorted_monotonic(target[nonexact], side)
if side == "left":
# searchsorted returns "indices into a sorted array such that,
# if the corresponding elements in v were inserted before the
# indices, the order of a would be preserved".
# Thus, we need to subtract 1 to find values to the left.
indexer[nonexact] -= 1
# This also mapped not found values (values of 0 from
# np.searchsorted) to -1, which conveniently is also our
# sentinel for missing values
else:
# Mark indices to the right of the largest value as not found
indexer[indexer == len(self)] = -1
return indexer
注释说这个方法用于处理pad/backfill的get_indexer
继续看下面的注释,下面说,当 side == "left" 的时候,searchsorted方法返回“对应于排序好的数组的下标,我们将v中的元素插入到这个下标前面,数组的有序性不变;因此需要-1来找到左值”;当np.searchsorted返回的值为0,也就是没有找到值的时候,赋值将会是-1,可以作为哨兵值。
前面我们知道side要么是"left",要么是"right",要么报错,而当是”right"时,就把最大值右边设为-1(not found)
再往上:
@final
def _get_fill_indexer(
self, target: Index, method: str_t, limit: int | None = None, tolerance=None
) -> np.ndarray:
target_values = target._get_engine_target()
if self.is_monotonic_increasing and target.is_monotonic_increasing:
engine_method = (
self._engine.get_pad_indexer
if method == "pad"
else self._engine.get_backfill_indexer
)
indexer = engine_method(target_values, limit)
else:
indexer = self._get_fill_indexer_searchsorted(target, method, limit)
if tolerance is not None and len(self):
indexer = self._filter_indexer_tolerance(target_values, indexer, tolerance)
return indexer
方法说当self是单调递增且target是单调递增的时候,就根据method值调用get_pad_indexer或者get_backfill_indexer;而当它不递增的时候,就要调用上面的_get_fill_indexer_searchsorted()
再往上找就清晰起来了:
def _get_indexer(
self,
target: Index,
method: str_t | None = None,
limit: int | None = None,
tolerance=None,
) -> np.ndarray:
if tolerance is not None:
tolerance = self._convert_tolerance(tolerance, target)
if not is_dtype_equal(self.dtype, target.dtype):
dtype = self._find_common_type_compat(target)
this = self.astype(dtype, copy=False)
target = target.astype(dtype, copy=False)
return this.get_indexer(
target, method=method, limit=limit, tolerance=tolerance
)
if method in ["pad", "backfill"]:
indexer = self._get_fill_indexer(target, method, limit, tolerance)
elif method == "nearest":
indexer = self._get_nearest_indexer(target, limit, tolerance)
else:
indexer = self._engine.get_indexer(target._get_engine_target())
return ensure_platform_int(indexer)
这一段处理公差,类型均一,调用我们方法的是对method的分支语句
继续往上找:
@Appender(_index_shared_docs["get_indexer"] % _index_doc_kwargs)
@final
def get_indexer(
self,
target,
method: str_t | None = None,
limit: int | None = None,
tolerance=None,
) -> np.ndarray:
# returned ndarray is np.intp
method = missing.clean_reindex_fill_method(method)
target = self._maybe_cast_listlike_indexer(target)
self._check_indexing_method(method, limit, tolerance)
if not self._index_as_unique:
raise InvalidIndexError(self._requires_unique_msg)
if not self._should_compare(target) and not is_interval_dtype(self.dtype):
# IntervalIndex get special treatment bc numeric scalars can be
# matched to Interval scalars
return self._get_indexer_non_comparable(target, method=method, unique=True)
if is_categorical_dtype(self.dtype):
# _maybe_cast_listlike_indexer ensures target has our dtype
# (could improve perf by doing _should_compare check earlier?)
assert is_dtype_equal(self.dtype, target.dtype)
indexer = self._engine.get_indexer(target.codes)
if self.hasnans and target.hasnans:
loc = self.get_loc(np.nan)
mask = target.isna()
indexer[mask] = loc
return indexer
if is_categorical_dtype(target.dtype):
# potential fastpath
# get an indexer for unique categories then propagate to codes via take_nd
# get_indexer instead of _get_indexer needed for MultiIndex cases
# e.g. test_append_different_columns_types
categories_indexer = self.get_indexer(target.categories)
indexer = algos.take_nd(categories_indexer, target.codes, fill_value=-1)
if (not self._is_multi and self.hasnans) and target.hasnans:
# Exclude MultiIndex because hasnans raises NotImplementedError
# we should only get here if we are unique, so loc is an integer
# GH#41934
loc = self.get_loc(np.nan)
mask = target.isna()
indexer[mask] = loc
return ensure_platform_int(indexer)
pself, ptarget = self._maybe_promote(target)
if pself is not self or ptarget is not target:
return pself.get_indexer(
ptarget, method=method, limit=limit, tolerance=tolerance
)
return self._get_indexer(target, method, limit, tolerance)
前面的处理其实都不用太在意,我们知道它会调用_get_indexer就可以
继续:
def reindex(
self, target, method=None, level=None, limit=None, tolerance=None
) -> tuple[Index, np.ndarray | None]:
"""
Create index with target's values.
Parameters
----------
target : an iterable
Returns
-------
new_index : pd.Index
Resulting index.
indexer : np.ndarray[np.intp] or None
Indices of output values in original index.
"""
# GH6552: preserve names when reindexing to non-named target
# (i.e. neither Index nor Series).
preserve_names = not hasattr(target, "name")
# GH7774: preserve dtype/tz if target is empty and not an Index.
target = ensure_has_len(target) # target may be an iterator
if not isinstance(target, Index) and len(target) == 0:
target = self[:0]
else:
target = ensure_index(target)
if level is not None:
if method is not None:
raise TypeError("Fill method not supported if level passed")
_, indexer, _ = self._join_level(target, level, how="right")
else:
if self.equals(target):
indexer = None
else:
if self._index_as_unique:
indexer = self.get_indexer(
target, method=method, limit=limit, tolerance=tolerance
)
else:
if method is not None or limit is not None:
raise ValueError(
"cannot reindex a non-unique index "
"with a method or limit"
)
indexer, _ = self.get_indexer_non_unique(target)
if preserve_names and target.nlevels == 1 and target.name != self.name:
target = target.copy()
target.name = self.name
return target, indexer
看函数说明,使用target的值创建一个index,参数 就是可迭代的target,返回值是结果new_index和indexer(output values在index的索引)
这之后的两个:
def _reindex_columns(
self,
new_columns,
method,
copy: bool,
level: Level,
fill_value=None,
limit=None,
tolerance=None,
):
new_columns, indexer = self.columns.reindex(
new_columns, method=method, level=level, limit=limit, tolerance=tolerance
)
return self._reindex_with_indexers(
{1: [new_columns, indexer]},
copy=copy,
fill_value=fill_value,
allow_dups=False,
)
def _reindex_axes(self, axes, level, limit, tolerance, method, fill_value, copy):
frame = self
columns = axes["columns"]
if columns is not None:
frame = frame._reindex_columns(
columns, method, copy, level, fill_value, limit, tolerance
)
index = axes["index"]
if index is not None:
frame = frame._reindex_index(
index, method, copy, level, fill_value, limit, tolerance
)
return frame
最后回到reindex本体(很长的注释)
def reindex(self: FrameOrSeries, *args, **kwargs) -> FrameOrSeries:
"""
Conform {klass} to new index with optional filling logic.
Places NA/NaN in locations having no value in the previous index. A new object
is produced unless the new index is equivalent to the current one and
``copy=False``.
Parameters
----------
{optional_labels}
{axes} : array-like, optional
New labels / index to conform to, should be specified using
keywords. Preferably an Index object to avoid duplicating data.
{optional_axis}
method : {{None, 'backfill'/'bfill', 'pad'/'ffill', 'nearest'}}
Method to use for filling holes in reindexed DataFrame.
Please note: this is only applicable to DataFrames/Series with a
monotonically increasing/decreasing index.
* None (default): don't fill gaps
* pad / ffill: Propagate last valid observation forward to next
valid.
* backfill / bfill: Use next valid observation to fill gap.
* nearest: Use nearest valid observations to fill gap.
copy : bool, default True
Return a new object, even if the passed indexes are the same.
level : int or name
Broadcast across a level, matching Index values on the
passed MultiIndex level.
fill_value : scalar, default np.NaN
Value to use for missing values. Defaults to NaN, but can be any
"compatible" value.
limit : int, default None
Maximum number of consecutive elements to forward or backward fill.
tolerance : optional
Maximum distance between original and new labels for inexact
matches. The values of the index at the matching locations most
satisfy the equation ``abs(index[indexer] - target) <= tolerance``.
Tolerance may be a scalar value, which applies the same tolerance
to all values, or list-like, which applies variable tolerance per
element. List-like includes list, tuple, array, Series, and must be
the same size as the index and its dtype must exactly match the
index's type.
Returns
-------
{klass} with changed index.
See Also
--------
DataFrame.set_index : Set row labels.
DataFrame.reset_index : Remove row labels or move them to new columns.
DataFrame.reindex_like : Change to same indices as other DataFrame.
Examples
--------
``DataFrame.reindex`` supports two calling conventions
* ``(index=index_labels, columns=column_labels, ...)``
* ``(labels, axis={{'index', 'columns'}}, ...)``
We *highly* recommend using keyword arguments to clarify your
intent.
Create a dataframe with some fictional data.
>>> index = ['Firefox', 'Chrome', 'Safari', 'IE10', 'Konqueror']
>>> df = pd.DataFrame({{'http_status': [200, 200, 404, 404, 301],
... 'response_time': [0.04, 0.02, 0.07, 0.08, 1.0]}},
... index=index)
>>> df
http_status response_time
Firefox 200 0.04
Chrome 200 0.02
Safari 404 0.07
IE10 404 0.08
Konqueror 301 1.00
Create a new index and reindex the dataframe. By default
values in the new index that do not have corresponding
records in the dataframe are assigned ``NaN``.
>>> new_index = ['Safari', 'Iceweasel', 'Comodo Dragon', 'IE10',
... 'Chrome']
>>> df.reindex(new_index)
http_status response_time
Safari 404.0 0.07
Iceweasel NaN NaN
Comodo Dragon NaN NaN
IE10 404.0 0.08
Chrome 200.0 0.02
We can fill in the missing values by passing a value to
the keyword ``fill_value``. Because the index is not monotonically
increasing or decreasing, we cannot use arguments to the keyword
``method`` to fill the ``NaN`` values.
>>> df.reindex(new_index, fill_value=0)
http_status response_time
Safari 404 0.07
Iceweasel 0 0.00
Comodo Dragon 0 0.00
IE10 404 0.08
Chrome 200 0.02
>>> df.reindex(new_index, fill_value='missing')
http_status response_time
Safari 404 0.07
Iceweasel missing missing
Comodo Dragon missing missing
IE10 404 0.08
Chrome 200 0.02
We can also reindex the columns.
>>> df.reindex(columns=['http_status', 'user_agent'])
http_status user_agent
Firefox 200 NaN
Chrome 200 NaN
Safari 404 NaN
IE10 404 NaN
Konqueror 301 NaN
Or we can use "axis-style" keyword arguments
>>> df.reindex(['http_status', 'user_agent'], axis="columns")
http_status user_agent
Firefox 200 NaN
Chrome 200 NaN
Safari 404 NaN
IE10 404 NaN
Konqueror 301 NaN
To further illustrate the filling functionality in
``reindex``, we will create a dataframe with a
monotonically increasing index (for example, a sequence
of dates).
>>> date_index = pd.date_range('1/1/2010', periods=6, freq='D')
>>> df2 = pd.DataFrame({{"prices": [100, 101, np.nan, 100, 89, 88]}},
... index=date_index)
>>> df2
prices
2010-01-01 100.0
2010-01-02 101.0
2010-01-03 NaN
2010-01-04 100.0
2010-01-05 89.0
2010-01-06 88.0
Suppose we decide to expand the dataframe to cover a wider
date range.
>>> date_index2 = pd.date_range('12/29/2009', periods=10, freq='D')
>>> df2.reindex(date_index2)
prices
2009-12-29 NaN
2009-12-30 NaN
2009-12-31 NaN
2010-01-01 100.0
2010-01-02 101.0
2010-01-03 NaN
2010-01-04 100.0
2010-01-05 89.0
2010-01-06 88.0
2010-01-07 NaN
The index entries that did not have a value in the original data frame
(for example, '2009-12-29') are by default filled with ``NaN``.
If desired, we can fill in the missing values using one of several
options.
For example, to back-propagate the last valid value to fill the ``NaN``
values, pass ``bfill`` as an argument to the ``method`` keyword.
>>> df2.reindex(date_index2, method='bfill')
prices
2009-12-29 100.0
2009-12-30 100.0
2009-12-31 100.0
2010-01-01 100.0
2010-01-02 101.0
2010-01-03 NaN
2010-01-04 100.0
2010-01-05 89.0
2010-01-06 88.0
2010-01-07 NaN
Please note that the ``NaN`` value present in the original dataframe
(at index value 2010-01-03) will not be filled by any of the
value propagation schemes. This is because filling while reindexing
does not look at dataframe values, but only compares the original and
desired indexes. If you do want to fill in the ``NaN`` values present
in the original dataframe, use the ``fillna()`` method.
See the :ref:`user guide ` for more.
"""
# TODO: Decide if we care about having different examples for different
# kinds
# construct the args
axes, kwargs = self._construct_axes_from_arguments(args, kwargs)
method = missing.clean_reindex_fill_method(kwargs.pop("method", None))
level = kwargs.pop("level", None)
copy = kwargs.pop("copy", True)
limit = kwargs.pop("limit", None)
tolerance = kwargs.pop("tolerance", None)
fill_value = kwargs.pop("fill_value", None)
# Series.reindex doesn't use / need the axis kwarg
# We pop and ignore it here, to make writing Series/Frame generic code
# easier
kwargs.pop("axis", None)
if kwargs:
raise TypeError(
"reindex() got an unexpected keyword "
f'argument "{list(kwargs.keys())[0]}"'
)
self._consolidate_inplace()
# if all axes that are requested to reindex are equal, then only copy
# if indicated must have index names equal here as well as values
if all(
self._get_axis(axis).identical(ax)
for axis, ax in axes.items()
if ax is not None
):
if copy:
return self.copy()
return self
# check if we are a multi reindex
if self._needs_reindex_multi(axes, method, level):
return self._reindex_multi(axes, copy, fill_value)
# perform the reindex on the axes
return self._reindex_axes(
axes, level, limit, tolerance, method, fill_value, copy
).__finalize__(self, method="reindex")
我们发现方法注释的method参数部分,已经提醒过了,该参数只适用于单调的DataFrame/Series
method : {{None, 'backfill'/'bfill', 'pad'/'ffill', 'nearest'}}
Method to use for filling holes in reindexed DataFrame.
Please note: this is only applicable to DataFrames/Series with a
monotonically increasing/decreasing index.
* None (default): don't fill gaps
* pad / ffill: Propagate last valid observation forward to next
valid.
* backfill / bfill: Use next valid observation to fill gap.
* nearest: Use nearest valid observations to fill gap.
也就是说,我们的columns不单调所以出错了
那么为什么不单调呢?可能是中文字符的问题,测试一下

看来不是。
那会不会是删除操作导致的呢?


破案了,删除导致索引不单调了,所以同步使用method来填充的时候就会出错。
具体的解决可以像其他博客中讲的那样,先进行删除,再调用.ffill()或.bfill()