深入浅出计算机组成原理04:存储和IO系统
目录
1. 存储器层次结构全景
1.1 关于Cache
1.2 访问层次
1.3 不同存储器访问延时与成本
2. 局部性原理
2.1 时间局部性
2.2 空间局部性
2.3 局部性原理使用实例
3. 高速缓存
3.1 引入Cache的原因
3.2 Cache的管理策略
3.2.1 访问方式
3.2.2 直接映射Cache策略
3.2.3 直接映射Cache数据结构
3.2.4 CPU访问内存步骤
3.3 CPU Cache的写入
3.3.1 写直达(Write-Through)策略
3.3.2 写回(Write-Back)策略
3.4 缓存一致性问题
3.4.1 问题原因
3.4.2 问题场景示例
3.5 缓存一致性解决方案概述
3.5.1 写传播(Write)
3.5.2 事务串行化(Transaction Serialization)
3.6 MESI协议
3.6.1 协议分类
3.6.2 MESI协议
4. 虚拟内存和内存保护
4.1 简单页表
4.1.1 简单页表的实现
4.1.2 地址转换步骤
4.1.3 简单页表的问题
4.2 多级页表(Multi-Level Page Table)
4.2.1 进程地址空间布局
4.2.2 4级页表示例
4.2.3 多级页表的优点
4.2.4 多级页表的缺点
5. 解析TLB和内存保护
5.1 解析TLB
5.1.1 TLB工作原理
5.1.2 TLB存在形式
5.2 内存保护机制
5.2.1 可执行空间保护(Executable Space Protection)
5.2.2 地址空间布局随机化(Address Space Layout Randomization)
6. 总线
6.1 总线设计思路
6.2 总线架构
6.2.1 后端总线与前端总线
6.2.2 前端总线与系统总线
6.2.3 总线线路种类
6.2.4 总线裁决(Bus Arbitration)
7. 输入输出设备
7.1 接口与设备:经典的适配器模式
7.2 CPU如何控制IO设备
7.3 信号和地址:发挥总线的价值
7.3.1 内存映射IO
7.3.2 端口映射IO
8. 理解IO_WAIT
8.1 硬盘IO性能
8.1.1 性能指标实例
8.1.2 IOPS指标
8.2 如何定位IO_WAIT问题
8.2.1 使用top命令查看io_wait消耗的CPU
8.2.2 使用iostat命令查看硬盘读写情况
8.2.3 使用iotop命令查看进程IO操作情况
9. 机械硬盘
9.1 机械硬盘的组成
9.2 机械硬盘的读操作
9.2.1 操作步骤
9.2.2 操作耗时
9.3 机械硬盘性能提升
9.3.1 减少平均延时
9.3.2 减少平均寻道时间
10. SSD硬盘
10.1 SSD & HDD硬盘对比
10.2 SSD读写原理
10.2.1 基本原理
10.2.2 SLC / MLC / TLC / QLC
10.2.3 硬盘结构
10.3 SSD擦写问题
10.3.1 读写与擦除单位
10.3.2 SSD读写生命周期
10.3.3 SSD预留空间
10.4 FTL与磨损均衡问题
10.4.1 磨损均衡问题
10.4.2 FTL的作用
10.5 TRIM指令的引入
10.5.1 操作系统删除文件操作
10.5.2 删除文件导致状态不匹配问题
10.5.3 TRIM命令
10.6 写入放大问题
11. DMA
11.1 DMA原理
11.1.1 DMA的引入
11.1.2 DMAC的角色
11.1.3 DMA传输流程
11.2 零拷贝传输
11.2.1 零拷贝传输原理
12. 数据完整性
12.1 单比特翻转
12.2 奇偶校验
12.3 海明码
12.3.1 概述
12.3.2 海明码冗余信息
12.3.3 海明码纠错原理
12.3.4 海明码编码方式
13. 分布式计算
1. 存储器层次结构全景
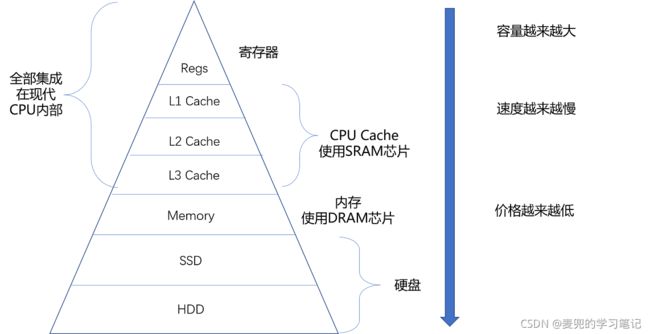
1.1 关于Cache
1. Cache由SRAM构成
2. L1 Cache一般位于CPU核心内部,每个CPU核心都有属于自己的L1 Cache,通常分为指令缓存和数据缓存
3. L2 Cache同样每个CPU核心都有,不过通常不在CPU核心内部,所以L2 Cache的访问速度比L1 Cache稍慢(如果仅有L1 & L2两层,则L2 Cache一般是共享的)
4. L3 Cache通常是多个CPU核心共用,尺寸更大,但访问速度也更慢
说明:在Linux中可以通过lscpu命令查看Cache的层次结构

1.2 访问层次
1. CPU并不直接访问每种存储设备,而是每种存储设备只和他相邻的存储设备交互
2. 各个存储器只和相邻一层的存储设备交互,并随着一层层向下,存储器的容量逐层增大,访问速度逐层减慢,而单位存储成本也逐层下降,这就构成了存储器的层次结构
1.3 不同存储器访问延时与成本
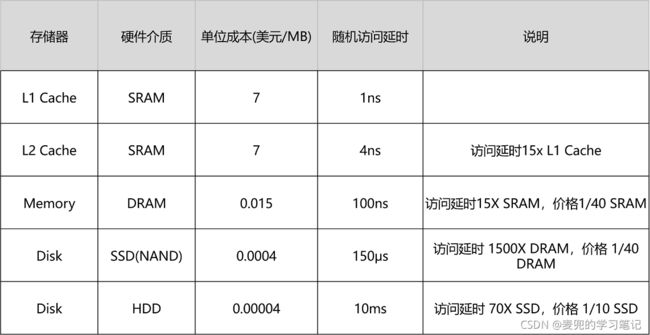
说明:存储器层次结构就是要解决性能、容量和成本的矛盾,使得我们既能享受Cache的速度,又能享受内存 & 硬盘巨大的容量和低廉的价格
这就要求我们能利用好不同层次的存储器的访问原理和特性
2. 局部性原理
为了既能享受Cache的速度,又能享受内存 & 硬盘巨大的容量和低廉的价格,就需要根据局部性原理(Principle of Locality)来指定管理和访问数据的策略
而局部性原理包括时间局部性(temporal locality)和空间局部性(spatial locality)
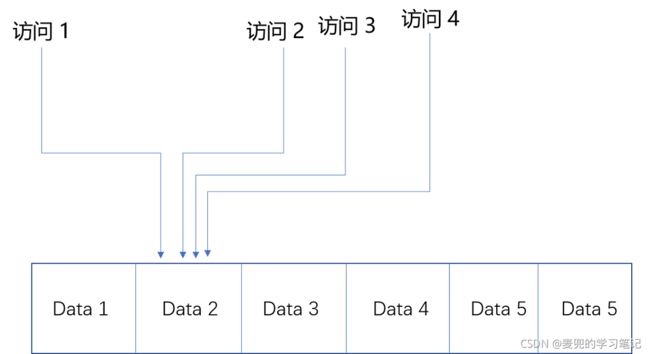
2.1 时间局部性
时间局部性是指如果一个数据被访问了,那么他在短时间内还会被再次访问
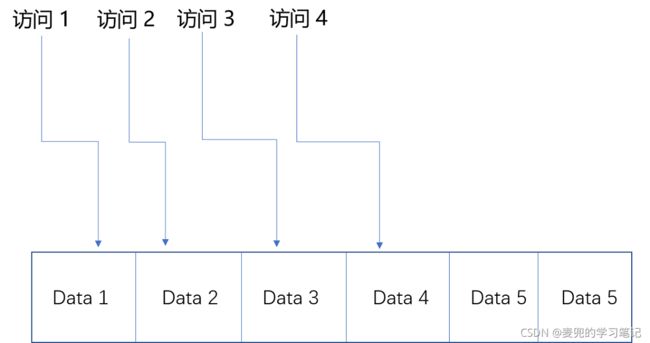
2.2 空间局部性
空间局部性是指如果一个数据被访问了,那么和他相邻的数据也会很快被访问
2.3 局部性原理使用实例
根据局部性原理,可以将访问次数多的数据放在贵但是快的内存中,将访问次数少的数据放在慢但是大的硬盘中
在服务端软件开发中,通常将数据放在数据库中,而服务端系统遇到的第一个性能瓶颈,往往就发生在访问数据库时。此时可以通过Redis或Memcache在数据库之前提供一层缓存的数据,来缓解数据库面临的压力,提升服务端的程序性能
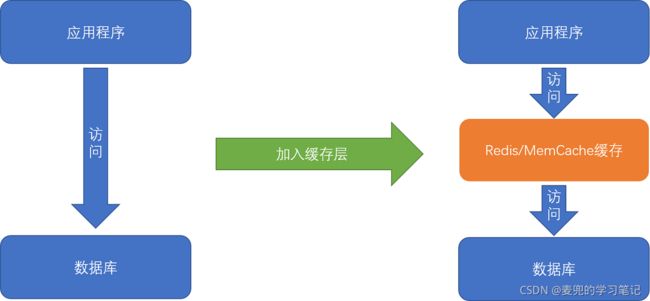
说明1:LRU缓存算法的使用
根据局部性原理,我们将用户访问过的数据加载到内存中,一旦内存已满,就需要将最长时间没有在内存中被访问过的数据从内存中移走,此时使用的就是LRU(Least Recently Used)缓存算法
说明2:LRU缓存命中率
访问的数据中,可以在内存缓存中找到的比例,是缓存策略的重要指标
3. 高速缓存
3.1 引入Cache的原因
1. 引入Cache是为了弥补CPU性能和内存访问性能越来越大的差距
2. 根据摩尔定律,CPU的速度每年增长60%,而内存的速度每年只增长7%,目前一次内存访问大约需要120个CPU cycle,即CPU和内存的访问速度有120倍的差距
3. 因此CPU需要执行的指令、需要访问的数据都在速度不到自身1%的内存中,所以无法实际使用CPU的性能
4. 引入Cache后,内存中的指令 & 数据会被加载到L1 ~ L3 Cache中。在各类基准测试(Benchmark)和实际应用场景中,CPU Cache的命中率通常能达到95%以上。即在95%的情况下,CPU只需访问L1 ~ L3 Cache获取指令和数据,而无需访问内存
3.2 Cache的管理策略
3.2.1 访问方式
1. 现代CPU进行数据读取时,无论数据是否已经存储在Cache中,都会首先访问Cache。只有当CPU在Cache中找不到数据时,才会去访问内存,并将读取到的数据写入Cache
2. 当时间局部性原理起作用后,这个最近刚被访问的数据会很快再次被访问,此时Cache中已有该数据,CPU则无需花费时间访问内存
3. CPU从内存中读取数据到Cache是以Cache Line为单位,在日常使用的Intel PC中,Cache Line通常是64B
3.2.2 直接映射Cache策略
直接映射Cache(Direct Mapped Cache)是最简单的Cache管理策略,他确保任何一个内存块(block)的地址始终映射到一个固定的CPU Cache Line
这种映射关系,通常用求余运算来实现。假设有0 ~ 31号共32个内存块,同时有0 ~ 7号共8个Cache Line,我们通过对8求余的方式,将32个内存块映射到固定的Cache Line中
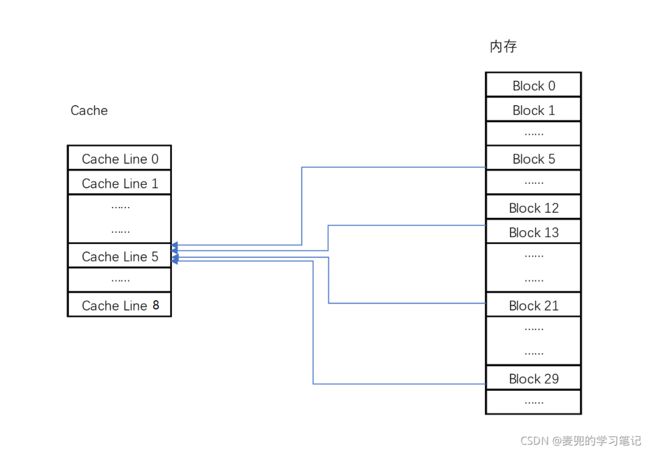
上图中,Block 5 / 13 / 21 / 29均会被映射到Cache Line 5
说明1:CPU访问内存数据,是一小块一小块数据来读取的,而不是按字节
说明2:实际计算中,通常将Cache Line的个数设置为2的N次方,这样在计算取模时,可以直接取地址的低N位
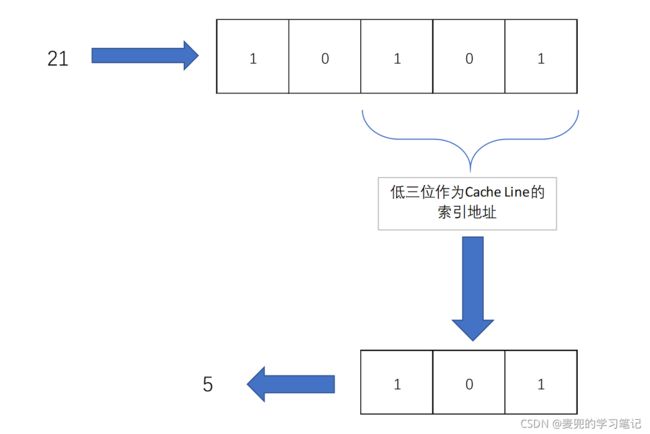
以上图为例,因为共有8(2^3)个Cache Line,直接取出第21号内存块的低3位,即可得到对应的Cache Line索引
说明3:除了直接映射Cache,还有全相连Cache(Fully Associative Cache)和组相连Cache(Set Associative Cache)策略,现代CPU通常使用组相连Cache策略
3.2.3 直接映射Cache数据结构
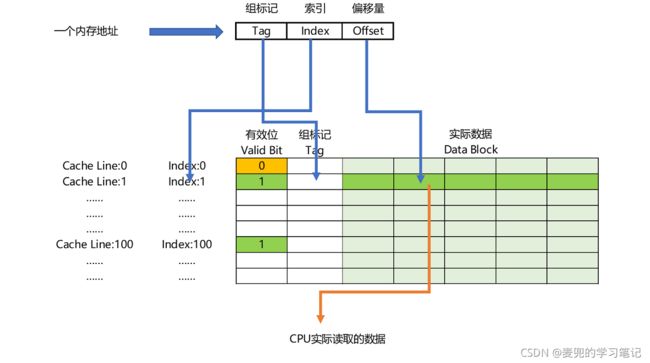
Cache数据结构同时涉及内存地址的划分和Cache Line中存储的内容,下面逐一说明
注意:这里的内存地址是一个物理地址,虚拟地址仅在软件层面存在,是由各级页表索引与最后一级的offset构成
3.2.3.1 索引(Index)
1. 只有内存地址划分中有
2. 内存地址中的索引字段用于将内存块映射到Cache Line
3.2.3.2 组标记(Tag)
1. 内存地址中的高位作为组标记使用,可标识出映射到同一个Cache Line中的不同内存块
2. Cache Line中存储组标记是为了标识当前在Cache Line中的是哪个内存块的数据
3. 参考上文的示例,由于索引本身反映了地址低位信息,所以组标记只需要记录地址的高位(e.g. 10101中的低3位为Index,高2位位Tag)
3.2.3.3 有效位(Valid Bit)
1. 只有Cache Line中存储
2. 用于标识Cache Line中的数据是否有效,如果有效位为0,则无论其中的组标记和实际数据是什么,CPU都会访问内存,重新加载数据
3.2.3.4 实际数据(Date Block)
1. 只有Cache Line中存储
2. 就是从内存块中读取的数据
3.2.3.5 偏移量(offset)
1. 只有内存地址划分中有
2. CPU在读取数据时,并不是读取一整个内存块,而是读取一个他需要的数据片段,这样的数据,称作CPU中的一个字(Word)
3. 内存地址中的偏移量用于在Data Block中索引对应的字
说明:此处可见CPU读取内存都是按字对齐的
3.2.4 CPU访问内存步骤
假设内存中的数据已经在Cache中
1. 根据内存地址的低位,计算在Cache中的索引
2. 判断Cache Line的有效位,确认Cache中的数据是有效的
3. 对比内存地址的高位和Cache Line中的组标记,确认Cache Line中的数据就是要访问的内存数据
4. 根据内存地址的偏移量,从Data Block中读取希望读到的字
说明:如果CPU发现Cache中的数据是无效的,或者不是要访问的内存块,则会访问内存,并将对应的内存块数据更新到Cache Line中,同时更新Cache Line的有效位和组标记
3.3 CPU Cache的写入
3.3.1 写直达(Write-Through)策略
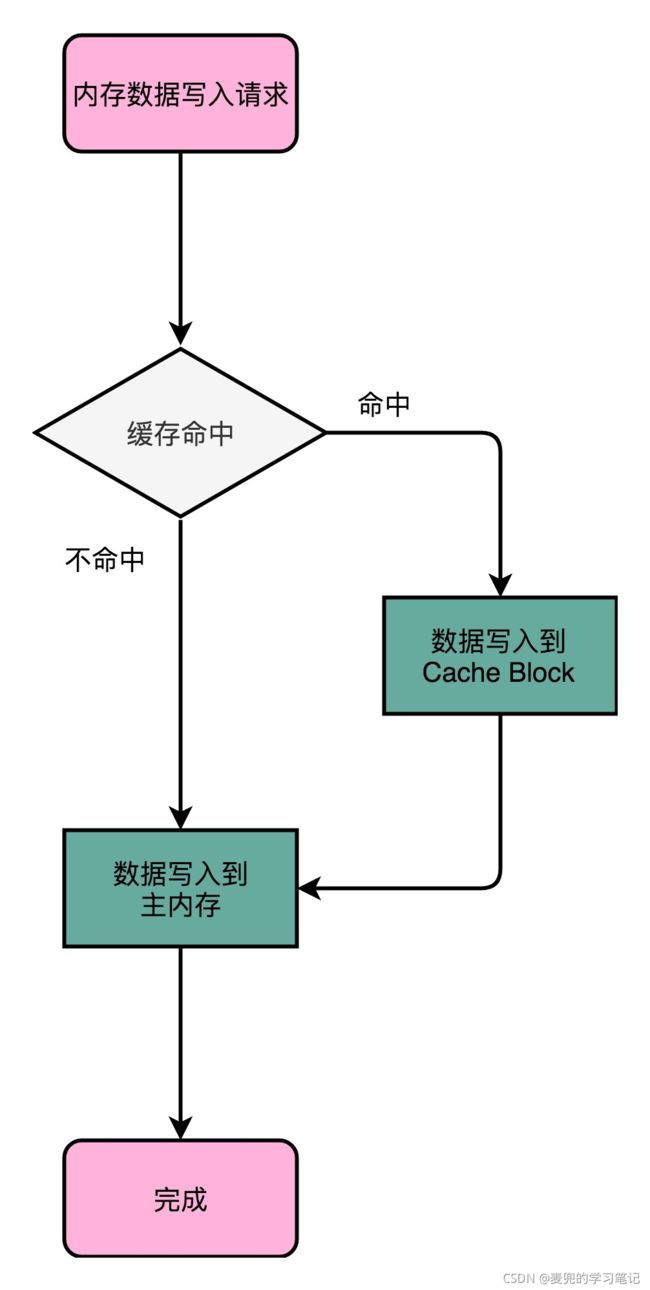
3.3.1.1 写入流程
1. 在write-through策略中,每次数据都要写入到主内存中
2. 写入前,先判断数据是否已经存在Cache中,如果数据已存在Cache中,则将数据写入Cache再写入内存;如果数据不在Cache中,则只写入内存
3.3.1.2 特性
1. write-through策略非常直观
2. 因为始终要将数据写入内存,所以速度慢
3.3.2 写回(Write-Back)策略
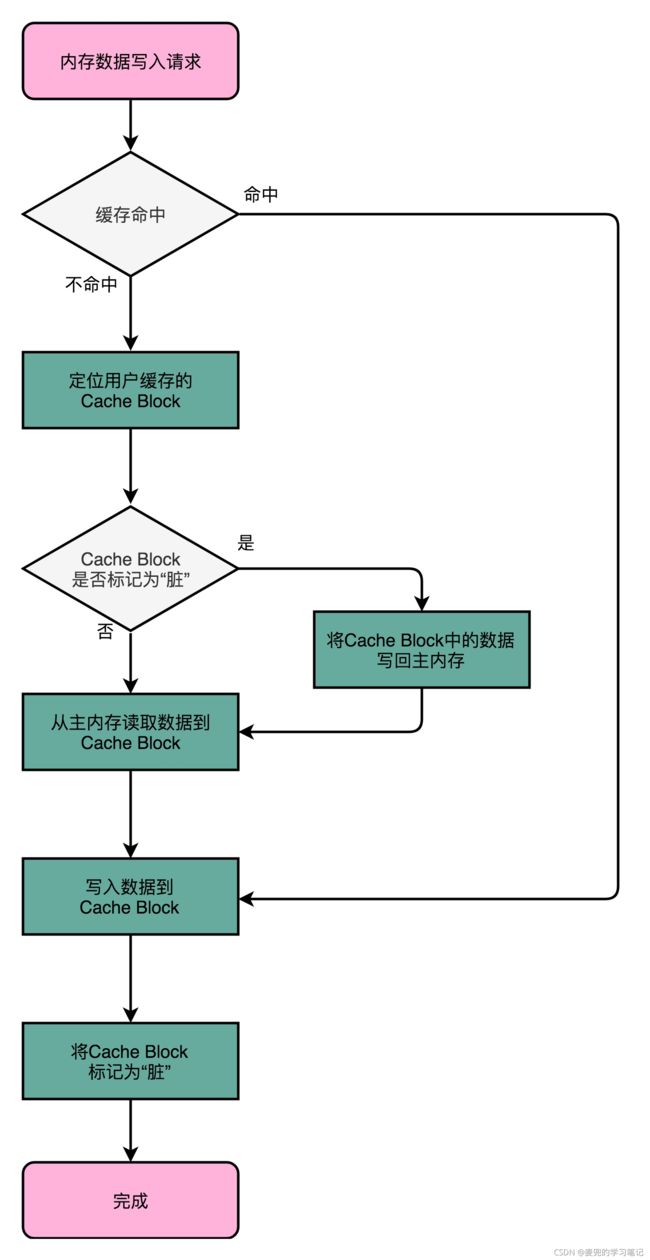
3.3.2.1 写入流程
1. 通常只更新Cache,只有在需要把Cache中的脏数据交换出去时,才将数据同步到内存中
2. 如果发现要写入的数据在Cache中,则只更新Cache,同时将Cache标记为脏(Dirty)。所谓脏,就是指此时Cache中的数据和内存不一致
3. 如果发现要写入的数据对应的Cache中当前存储的是其他内存块的数据,则判断该Cache是否为脏
① 如果是脏的,则先将该Cache中的数据写回内存,然后将当前要写入数据对应的内存数据加载到Cache中,之后将修改写入Cache,并将其标记为脏
② 如果不是脏的,说明对应内存块的数据被加载到Cache后没有被修改过,此时直接放弃Cache中的数据即可,直接进行后续的内存加载与写入Cache操作
4.1.2.2 特性
1. 在缓存经常会命中的情况下,性能更好
2. 使用write-back策略后,在加载内存数据到Cache时,也要多出同步脏Cache的操作。如果在加载内存数据到Cache时,发现该Cache为脏,则需要先将当前Cache中的数据写回到内存,之后才能加载数据覆盖掉Cache
说明:在上述需要写回的场景中,都是脏的且有效的Cache Line,如果Cache Line本身是无效的,则无需写回
3.4 缓存一致性问题
3.4.1 问题原因
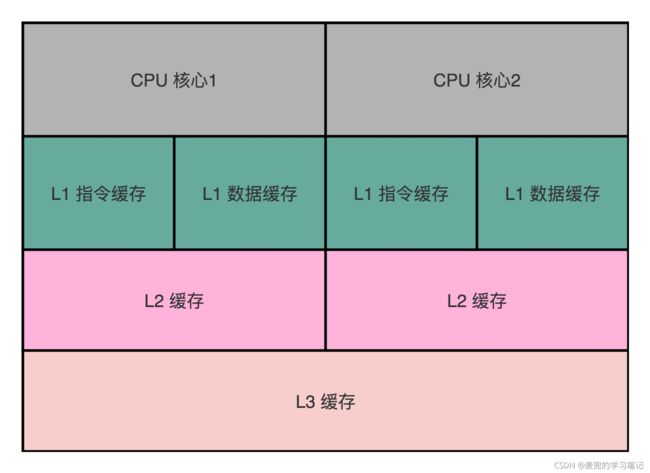
因为CPU的每个核有各自的Cache,互相之间的操作又是各自独立的,所以会带来缓存一致性问题(Cache Coherence)
3.4.2 问题场景示例
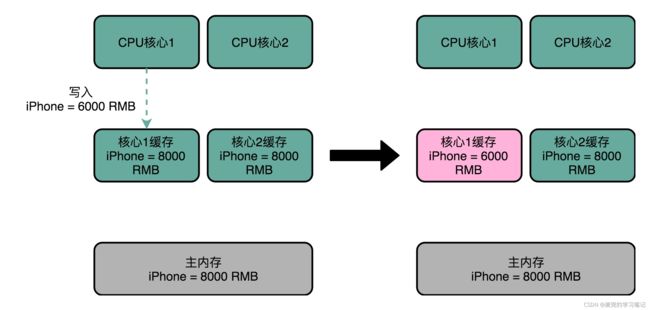
1. 假设出于性能考虑,对Cache的写操作使用写回策略
2. CPU1将修改的数据写入CPU1的Cache Line,并将其标记为dirty,但是这个更新的信息只出现在CPU1的Cache中,并没有同步到CPU2的Cache中,此时就出现了缓存一致性问题
3.5 缓存一致性解决方案概述
为了解决缓存不一致问题,就需要一种机制来同步不同核心之间的缓存数据,这种机制至少要满足写传播和事务串行化两个条件
3.5.1 写传播(Write)
写传播是指一个CPU核心更新了自己的Cache,必须能够传播到其他节点的Cache Line中
3.5.2 事务串行化(Transaction Serialization)
事务串行化是指一个CPU核心里面的读取和写入操作,在其他节点看来,顺序是一样的。要在CPU Cache中实现事务串行化,需要做到如下2点,
1. 一个CPU核心对于数据的操作,需要同步通信给其他CPU核心(即先要满足写传播)
2. 如果两个CPU核心里有同一个数据的Cache,那么对于这个Cache数据的更新,需要有一个"锁"的概念,只有拿到了对应Cache Block的"锁"之后,才能进行对应数据更新
说明:事务串行化示例
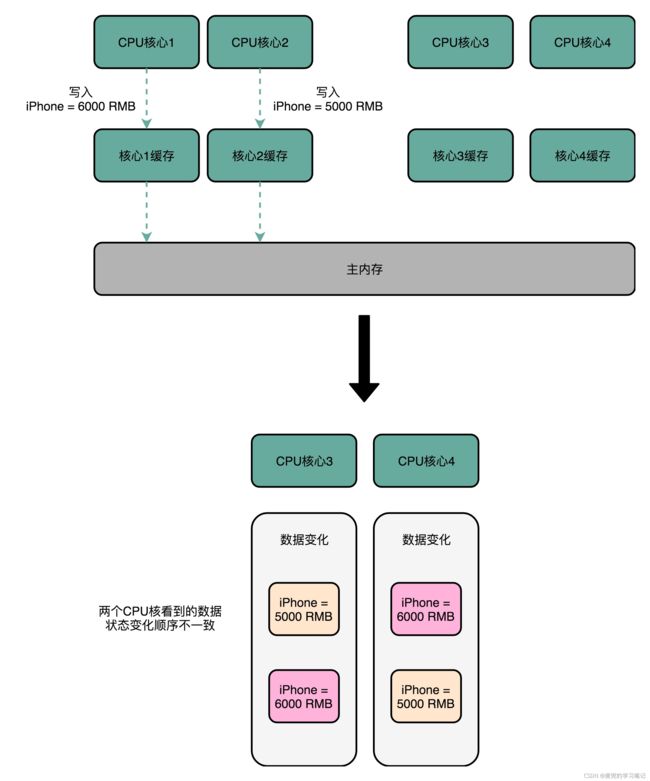
假设CPU1想将变量的值改为6000,而CPU2在稍后差不多的时间想将变量值改为5000,如果只有写传播而没有事务串行化,CPU3和CPU4看到的变化顺序就可能不一致
而满足事务串行化时,CPU1先获得Cache Block的锁进行操作,CPU2后操作,所以所有核心(包括发起操作的CPU1 & 2)看到的变化都是变量值先变成6000,后变成5000
说明:总线嗅探(Bus Snooping)机制
① 要解决缓存一致性问题,首先要解决多个CPU核心之间的数据传播问题,其中最常见的解决方案是总线嗅探
② 总线嗅探机制就是把所有读写请求都通过总线(Bus)广播给所有的CPU核心,然后让各个核心去嗅探这些请求,并根据本地的情况进行响应
3.6 MESI协议
3.6.1 协议分类
3.6.1.1 写失效(Write Invalidate)协议
1. 在写失效协议中,只有一个CPU核心负责写入数据,其他核心只是同步读取到这个写入。写入的核心在将数据写入Cache之后,会通过总线广播一个失效请求给其他所有CPU核心
2. 其他的CPU核心会根据该请求判断自己是否有对应的Cache Line,如果有的话,将其标记为失效
3.6.1.2 写广播(Write Broad case)协议
1. 在写广播协议中,一个写入请求广播到所有的CPU核心,同时更新各个核心中的Cache
2. 因为不仅需要在总线上传输操作信号和地址信号,还要传输数据内容,所以写广播需要占用更多的总线带宽
3.6.2 MESI协议
3.6.2.1 概述
1. MESI协议是基于写失效的、支持写回策略的缓存一致性协议
2. MESI协议不仅可以用在CPU Cache之间,也可以广泛用于各种需要使用缓存,同时缓存之间需要同步的场景下
3.6.2.2 4种Cache Line状态
MESI协议就是得名于增加的4种Cache Line标记(需要额外的2bit存储),
1. M(Modified):已修改
该Cache Line被加载到CPU的Cache中,并且被修改过(dirty),即与内存中的数据不一致,该Cache Line中的数据需要在未来的某个时间点写回(write-back)内存
2. E(Exclusive):独占
① 该Cache Line只被加载到当前CPU的Cache中,且是干净的
② 由于其他的CPU核心并没有加载对应的数据到自己的Cache中,此时向独占的Cache Block写入数据无需通知其他核
3. S(Shared):共享
① 在独占状态下的Cache Line如果收到一个来自于总线的读取对应Cache的请求,就会转换为共享状态,此时另一个CPU核心也将对应的Cache Block从内存加载到自己的Cache中
② 在共享状态下,因为同样的数据在多个CPU核心的Cache中都有,当某个核想要更新Cache时就不能直接修改,而是要先向所有的其他CPU核心广播一个请求,要求先把其他CPU核心里面的Cache都变成无效状态,让后再更新当前Cache中的数据
③ 这个广播动作一般称作RFO(Request For Ownership),也就是获取当前对应Cache Block数据的所有权
4. I(Invalidated):失效
该Cache Line无效
3.6.2.3 MESI状态转换
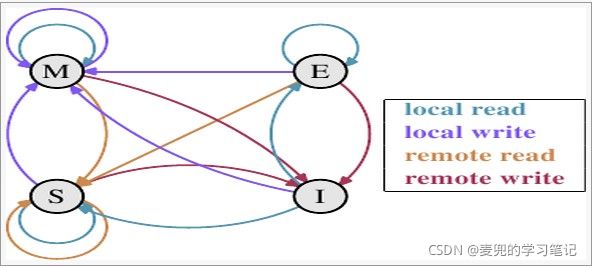
下面列表说明上面的状态机如何转换,
| 当前状态 |
事件 |
行为 |
下一个状态 |
| I(Invalid) |
Local Read |
1. 如果其他Cache没有这份数据,本Cache从内存中加载数据,Cache Line状态变为E 2. 如果其他Cache有这份数据,且状态为M,则将数据写回内存,本Cache再从内存中取数据,两个Cache Line的状态都变为S 3. 如果其他Cache有这份数据,且状态为S或者E,本Cache从内存中取数据,这些Cache Line状态均变为S |
E / S |
| Local Write |
从内存中取数据,在Cache中修改,Cache Line状态变为M;如果其他Cache有这份数据且状态为M,则先要将数据更新到内存(也就是写回) 如果其他Cache有这份数据,则其他Cache的Cache Line状态变为I |
M |
|
| Remote Read |
既然是Invalid,其他核的操作与其无关 |
I |
|
| Remote Write |
既然是Invalid,其他核的操作与其无关 |
I |
|
| E(Exclusive) |
Local Read |
从Cache中取数据,状态不变 |
E |
| Local Write |
修改Cache的数据,状态变为M |
M |
|
| Remote Read |
数据和其他CPU核共用,状态变为S |
S |
|
| Remote Write |
数据被修改,本Cache Line不能再使用,状态变为I |
I |
|
| S(Shared) |
Local Read |
从Cache中取数据,状态不变 |
S |
| Local Write |
修改Cache中的数据,状态变为M,其他核共享的Cache Line状态变为I |
M |
|
| Remote Read |
状态不变 |
S |
|
| Remote Write |
数据被修改,本地Cache Line不能再使用,状态变为I |
I |
|
| M(Modified) |
Local Read |
从Cache读取数据,状态不变 |
M |
| Local Write |
修改Cache中的数据,状态不变 |
M |
|
| Remote Read |
本地Cache Line中的数据被写入内存,使其他核能使用到最新的数据,状态变为S |
S |
|
| Remote Write |
本地Cache Line中的数据被写入内存,使其他核能使用到最新的数据,由于其他核会修改这行数据,本地Cache Line状态变为I |
I |
说明:分析MESI状态转换时一定要注意多CPU视角,要区分local和remote两个操作来源,以及不同CPU Cache Line的状态(对应同一个Cache Block的Cache Line)
参考资料:
【并发编程】MESI--CPU缓存一致性协议
4. 虚拟内存和内存保护
4.1 简单页表
4.1.1 简单页表的实现
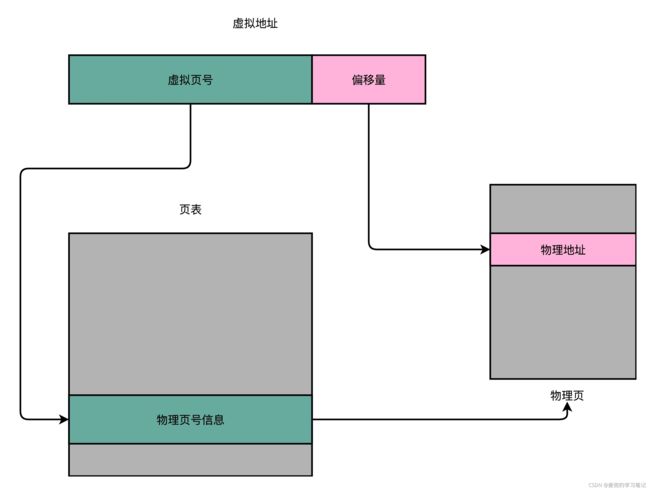
1. 页表(Page Table)用来实现虚拟页到物理页的映射
2. 引入分页机制后,内存地址被划分为页号(Directory)和偏移量(Offset),页表保存的就是虚拟页号和物理页号之间的映射关系
3. 同一个页中的内存,在物理上是连续的
4. 以32位系统中,页大小4KB为例,高20位作为虚拟页号,即页表索引;低12位作为页内偏移
4.1.2 地址转换步骤
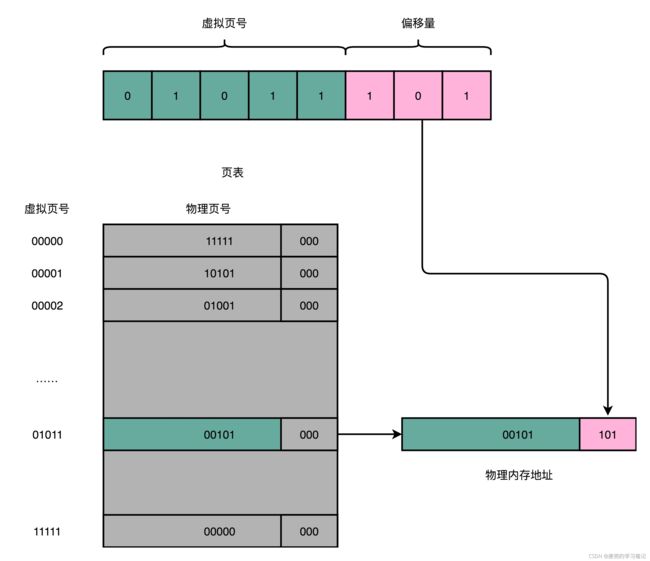
1. 将虚拟内存地址划分为页号和偏移量的组合
2. 从页表中查询出虚拟页号对应的物理页号
3. 使用物理页号加上偏移量,就得到了物理内存地址
4.1.3 简单页表的问题
简单页表虽然逻辑简单很好理解,但是会占用大量内存。仍然以32位系统 + 4KB页为例,每个页表需要占用2^20(页表项个数) * 4(每个页表项大小) = 4MB内存
考虑到每个进程都有自己的页表,随着进程数量的增加,使用简单页表方案消耗的内存将急剧增加
说明:为何每个页表都要映射完整的4GB空间 ?
你可能会有疑问,很多进程使用的地址空间并没有4GB,为何页表要完整映射整个地址空间 ?
这个其实和进程的地址空间布局有关,在Linux中,进程的代码段、数据段、堆从进程地址空间的低地址处开始;而栈从进程地址空间的高地址处开始,所以即使地址空间中间未使用的部分也占据了页表空间,即使不建立页表
只有进程地址空间完全从低地址用起,才可能省去高地址页表所占据的内存
4.2 多级页表(Multi-Level Page Table)
4.2.1 进程地址空间布局
1. 整个进程的地址空间通常是"两头实、中间空",在程序运行时,栈的空间从高地址向低地址发展;而堆的空间从低地址向高地址发展
2. 因此虚拟内存占用的地址空间通常是两段连续的空间,而不是完全随机散落的内存地址,而多级页表特别适合这样的内存地址分布
4.2.2 4级页表示例
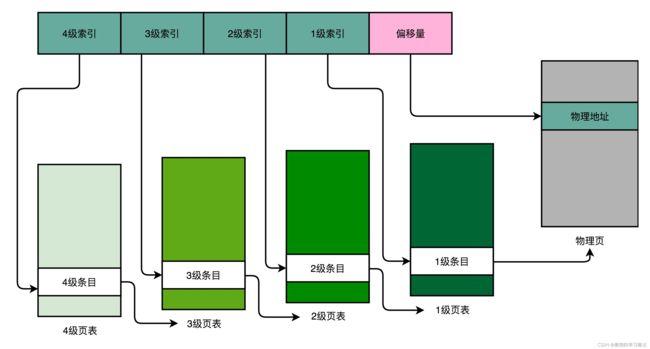
1. 多级页表将简单级页表的页号部分拆分为多个索引字段,分别用于索引各级页表
2. 4 / 3 / 2级索引寻址到的都是一张页表的起始地址,供下级索引使用
3. 1级页索引寻址到的则是物理页起始地址,偏移量就是在该页中寻址
4. 多级页表相当于一个多叉树的数据结构,所以也称之为页表树(Page Table Tree),因为虚拟内存地址分布的连续性,树的很多第一层节点的指针就是空的,也就是不需要对应的3 / 2 / 1级页表,也就节省了页表占用的内存
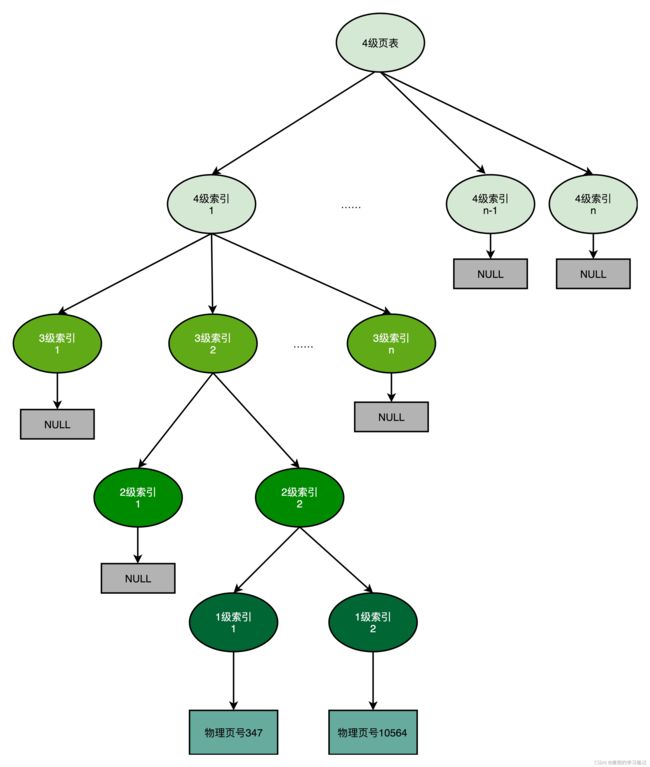
4.2.3 多级页表的优点
多级页表最大的好处就是可以减少页表占用的内存,下面给出一个示例,假设场景如下,
1. 32位系统 + 4KB页
2. 4级页表索引,每级5bit
3. 使用从0地址开始的4MB和最高地址的4MB内存
分析:根据上述假设,每个4级页表项可以映射128MB空间(2^27),每个3级页表项可以映射4MB空间(2^22),每个2级页表项可以映射128KB空间(2^17),每个1级页表项可以映射4KB空间(1页);而每张页表需要占用128B(2^5 * 4B)
由于需要占用最高和最低的2个4MB空间,所以需要消耗如下页表,
1. 1个4级页表(填充其中最高和最低2个页表项,每个进程都需要一个4级页表)
2. 2个3级页表(最高地址和最低地址范围各一张)
3. 每个3级页表项能映射4MB空间,也就是需要1个2级页表 + 32(2^5)个1级页表
所以总页表需要(1 + 2 + 2 * (1 + 32)) = 69个页表,总计69 * 128 = 8832B内存,相较于简单页表的4MB内存大为减少
说明1:在计算页表消耗量时,只要需要占用页表中的一个表项,就需要这张页表,但是只是需要这部分内存,并不是每个表项都要填充
说明2:其实如果填满整个进程地址空间,多级页表需要的内存比简单页表还多(因为多了上级页表),只是绝大多数进程都不会占用如此多的空间
4.2.4 多级页表的缺点
1. 使用多级页表后,每次地址转换需要多次访问内存中的页表,增加了访问内存的开销,而访问内存比访问Cache慢很多
2. 多级页表虽然节约了内存空间,但是带来了时间上的开销,是一种以时间换空间的策略
3. 解决该问题就需要引入TLB,用于加速地址转换
5. 解析TLB和内存保护
5.1 解析TLB
5.1.1 TLB工作原理
TLB也是利用局部性原理进行工作,刚完成的虚拟页到物理页的转换关系可能很快就会用到,所以我们将地址转换信息缓存下来。下次进行地址转换时,先查找缓存中是否存在对应的地址转换信息,如果有的话,则无需反复访问内存中的页表进行地址转换
5.1.2 TLB存在形式
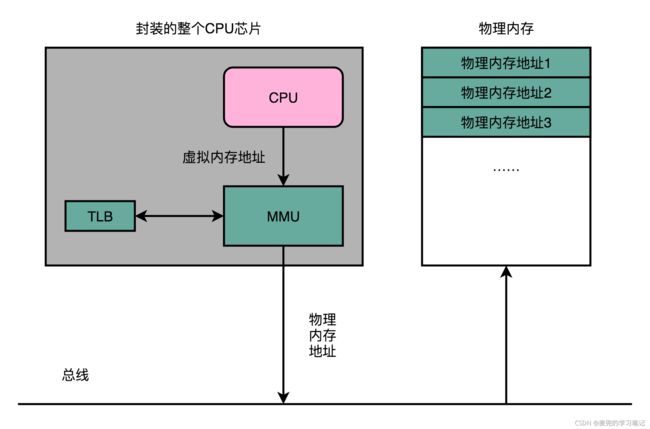
1. TLB的全称为地址变换高速缓冲(Translation-Look Buffer),这块缓存存放了之前已经进行过地址转换的查询结果。这样当同样的虚拟地址需要进行地址转换时,可以直接在TLB中查询结果
2. TLB和Cache类似,可以分为指令TLB(ITLB)和数据TLB(DTLB)。同时也可以根据大小进行分级,变成L1、L2这样多层的TLB
3. TLB和Cache一样,也需要脏标记这样的标志位来实现写回策略
5.2 内存保护机制
5.2.1 可执行空间保护(Executable Space Protection)
可执行空间保护就是对于一个进程使用的内存,只把其中的指令部分设置为可执行的,其他部分,比如数据部分,不给予可执行权限
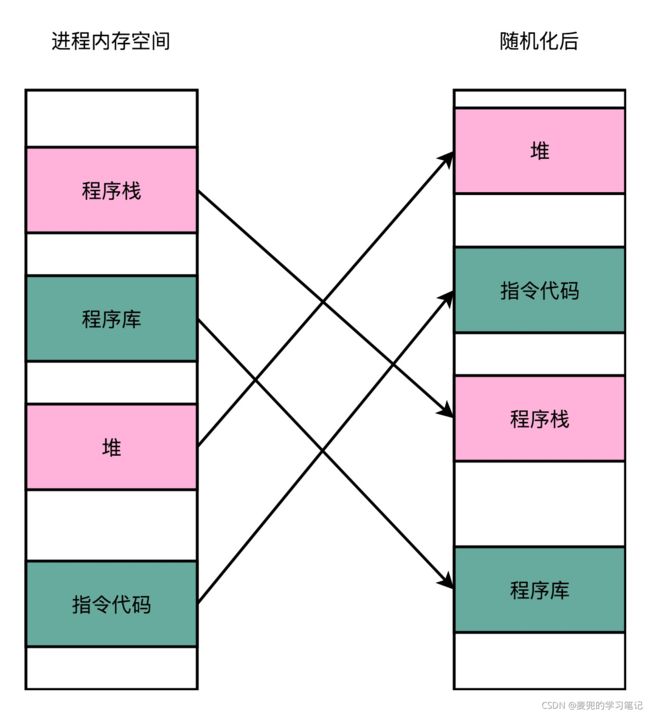
5.2.2 地址空间布局随机化(Address Space Layout Randomization)
原先的进程内存布局是固定的,任何第三方很容易知道指令 / 数据 / 堆 / 栈的位置。而地址空间布局随机化,就是让这些区域的位置不再固定,在内存空间中随机分配这些进程不同部分所在的内存空间地址
6. 总线
6.1 总线设计思路
1. 总线设计思路的核心是为了减少多个模块之间交互的复杂性和耦合度,以下图为例,要通信的设备之间不再两两建立通路,而是通过公用的总线发送信息
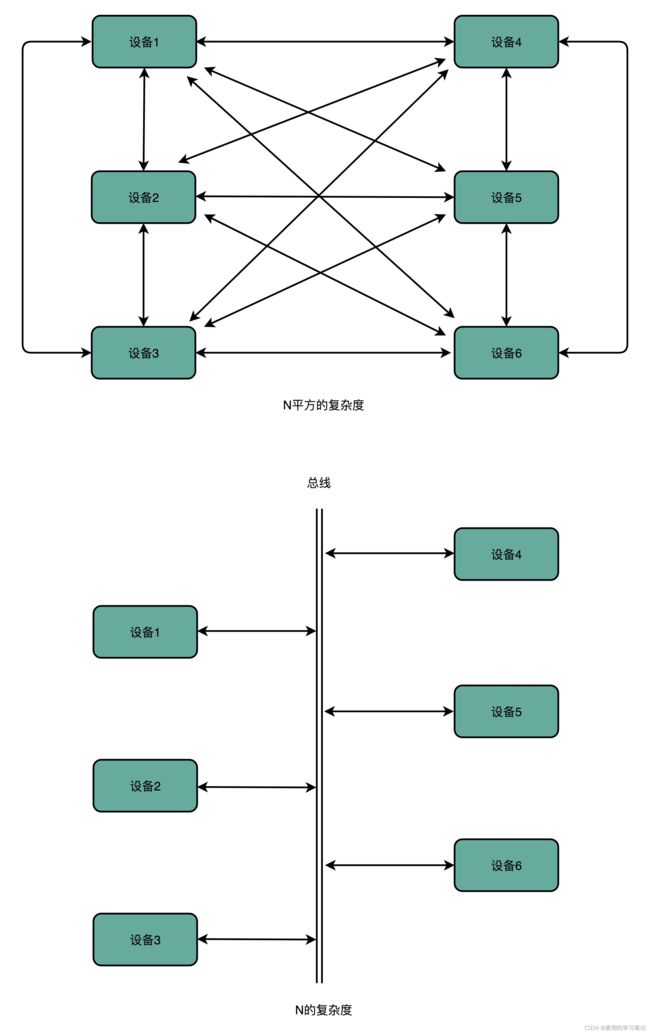
2. 总线就是一组线路,CPU、内存以及输入输出设备都通过这组线路进行相互通信
6.2 总线架构
6.2.1 后端总线与前端总线
1. CPU中有一个快速的本地总线(Local Bus)和一个速度相对较慢的前端总线(Front-side Bus),我们称之为双独立总线(Dual Independent Bus,DIB)
2. 本地总线用来和高速缓存通信
3. 前端总线用来和内存以及输入输出设备通信
4. 有时会将本地总线称作后端总线(Back-side Bus),用于和前端总线对应起来
6.2.2 前端总线与系统总线
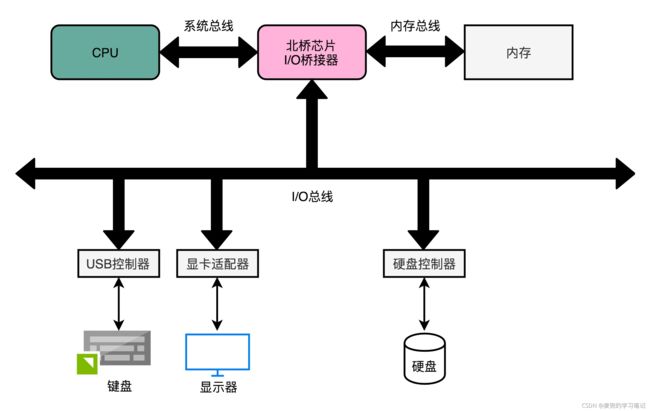
1. 前端总线就是系统总线
2. 系统总线在接入一个IO桥接器(IO Bridge)之后,一边接入内存总线,用于CPU和内存通信;一边接入IO总线,用来连接IO设备
3. 在真实的计算机中,总线层次更加复杂,根据不同的设备,还会分成独立的PCI总线、ISA总线等
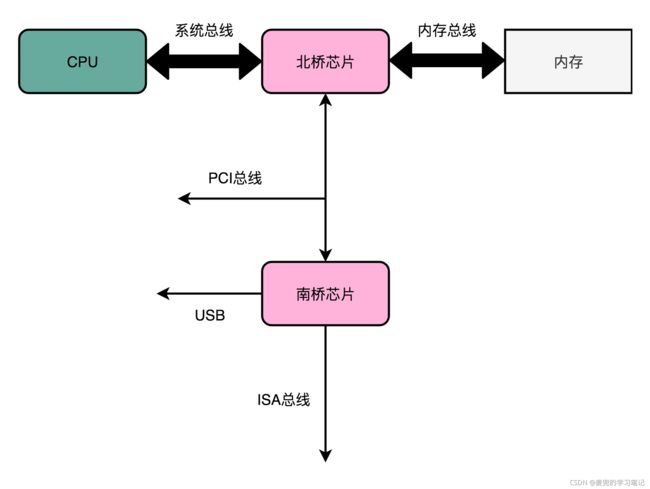
6.2.3 总线线路种类
1. 数据线(Data Bus)
用来传输实际的数据信息
2. 地址线(Address Bus)
用来确定数据传输的目的地,是内存的某个位置,还是某个IO设备
3. 控制线(Control Bus)
用来控制总线的访问
6.2.4 总线裁决(Bus Arbitration)
1. 尽管总线减少了设备之间的耦合,降低了系统设计的复杂度,但是总线不能同时给多个设备提供通信功能
2. 而总线是多个设备公用的,因此需要一个机制,用于决定总线的使用权,这种机制就是总线裁决
7. 输入输出设备
7.1 接口与设备:经典的适配器模式
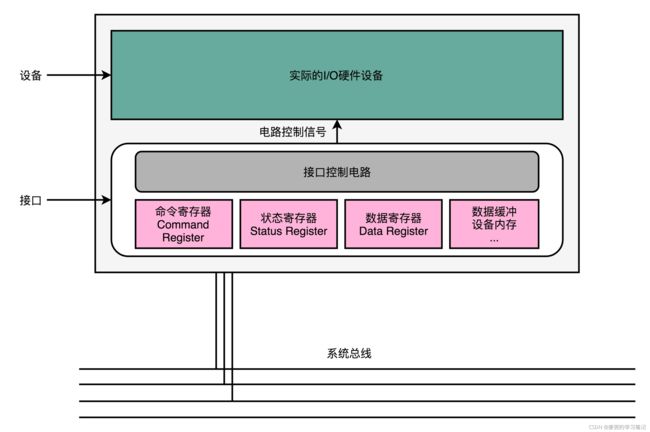
1. 大部分的输入输出设备都由两个部分组成,第一个是他的接口(Interface),第二个才是实际的IO设备(Actual IO device)。输入输出设备并不是直接接入到总线上和CPU通信,而是通过接口,用接口连接到总线上,再通过总线和CPU通信
2. 接口电路中有对应的状态寄存器、命令寄存器、数据寄存器、数据缓冲区和设备内存等。接口电路通过总线和CPU通信,接收来自CPU的命令(操作命令寄存器)和数据(操作数据寄存器)
而接口电路中的控制电路,再解码接收到的命令,实际去操作对应的硬件设备
3. 在CPU一侧,看到的并不是一个个特定的设备,而是一个个内存地址或端口地址,CPU只是向这些地址传输数据或读取数据,所需要的指令和操作内存地址的指令没有本质区别
通过软件层面对于传输的命令数据的定义,而不是提供特殊的指令,来实际操作对应的IO设备
说明1:除了内置在主板上的接口之外,有些接口可以集成在设备上。例如IDE硬盘,设备的接口电路在设备上,而不在主板上,需要通过一个线缆把集成了接口的设备连接到主板上去
说明2:将接口和实际设备分离,有利于计算机走向开放架构。例如用户可以单独升级IO设备,而无需更换整台计算机;设备制造商也只需要根据接口的控制协议来设计各种外设
7.2 CPU如何控制IO设备
无论是内置在主板上的接口,还是集成在设备上的接口,除了三类寄存器之外,还有对应的控制电路。正是通过这个控制电路,CPU才能通过向接口电路传输信号,来控制实际的硬件
7.3 信号和地址:发挥总线的价值
7.3.1 内存映射IO
1. 内存映射IO(Memory-Mapped IO,MMIO)
2. 在MMIO模式中,计算机会将IO设备的各个寄存器以及IO设备内部的内存地址都映射到主内存地址空间。主内存地址空间中,会给不同的IO设备预留内存地址
3. CPU想要和这些IO设备通信时,就向这些地址发送数据,之后地址信息和数据信息就会通过总线发送到IO设备接口
4. IO设备接口通过监控总线,将CPU发送来的信息接入设备中相应的寄存器或内存
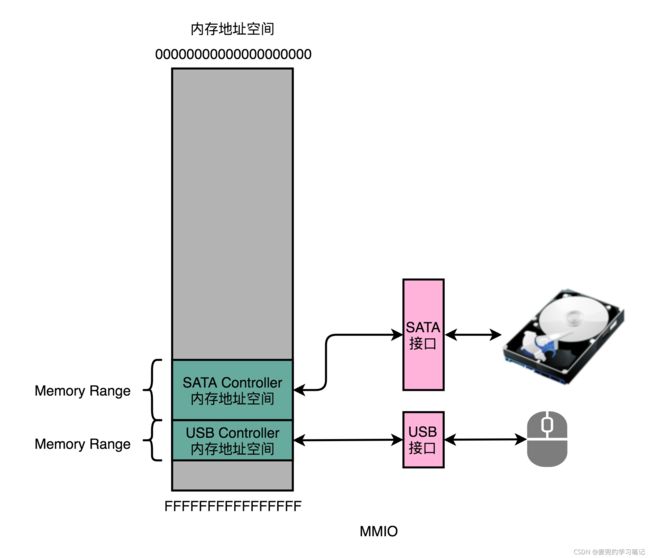
7.3.2 端口映射IO
1. 端口映射IO(Port-Mapped IO,PMIO)
2. PMIO的通信方式与MMIO的区别在于,PMIO访问的设备地址不在内存地址空间中,而是一个专门的端口,这个端口就是和CPU通信的一个抽象概念
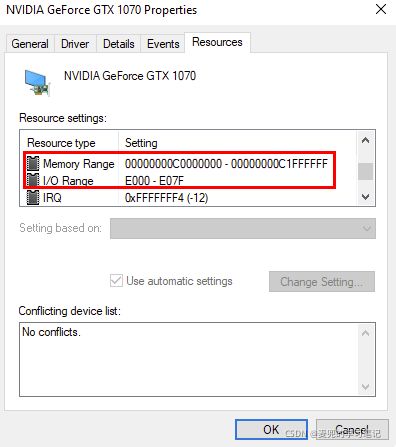
3. 使用PMIO需要专门的IO设备通信指令,RISC架构一般只支持MMIO;X86架构同时支持MMIO和PMIO,下图中显卡资源的示例中,就同时包含了MMIO和PMIO的访问方式
8. 理解IO_WAIT
8.1 硬盘IO性能
8.1.1 性能指标实例
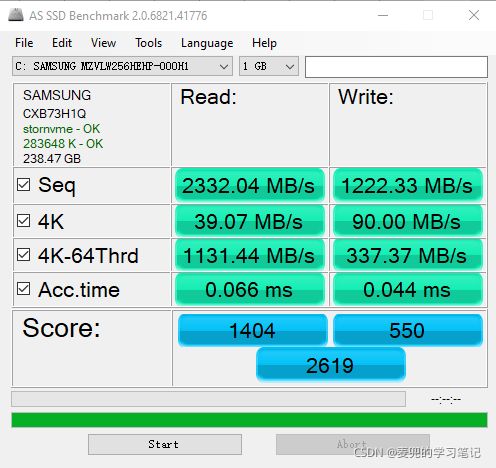
上图为一块PCIE接口的三星SSD硬盘的AS SSD测试结果,我们借此说明2个硬盘IO性能指标,
1. 响应时间(Response Time)
即上图中的Acc.time,表示程序发起一个硬盘的操作请求,到这个请求返回的时间
2. 数据传输率(Data Transfer Rate)
在上图中Seq为连续读写的数据传输率,4K为随机读写4KB大小数据的数据传输率,可见二者差别非常大
在实际的应用开发中,服务器承受的并发访问,更多的是随机读写,而不是顺序读写
8.1.2 IOPS指标
1. IOPS指每秒读写的次数,也就是每秒输入输出操作的次数
2. 以上节硬盘的随机读取为例,假设每次读取4KB数据,则每秒可以支持约10000次随机读取
3. 由于硬盘实际支持的随机读写IOPS与CPU主频差距悬殊,所以会存在IO_WAIT问题,也就是CPU需要等待IO操作完成才能进行下一步的操作
8.2 如何定位IO_WAIT问题
8.2.1 使用top命令查看io_wait消耗的CPU
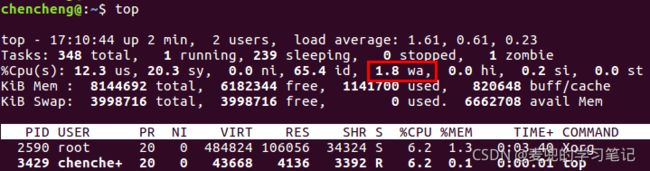
top命令输出中的wa指标表示CPU等待IO完成操作花费的时间占CPU的百分比
8.2.2 使用iostat命令查看硬盘读写情况
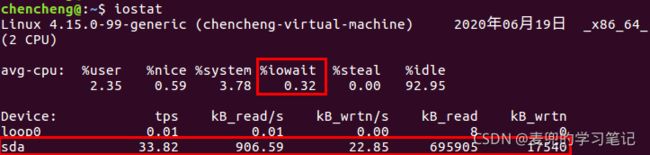
iostat命令除了显示io_wait占用CPU时间的百分比,还显示了硬盘的读写情况,其中的tps就是上文所说的IOPS指标,而KB_read/s和KB_wrtn/s则对应了数据传输率指标
8.2.3 使用iotop命令查看进程IO操作情况
注意:使用iotop命令需要sudo权限
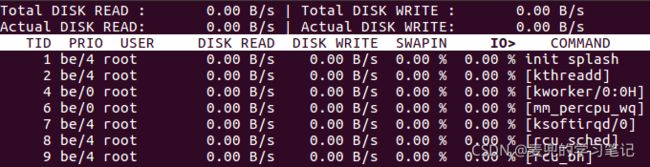
iotop命令可以显示不同进程的IO使用情况
9. 机械硬盘
9.1 机械硬盘的组成
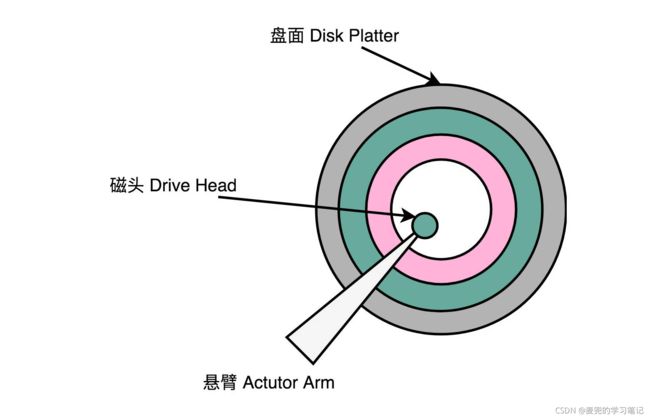
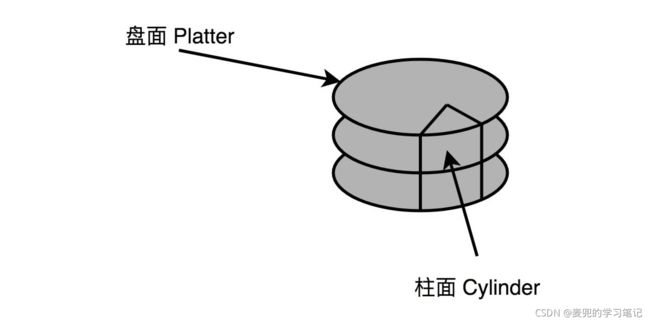
1. 盘面(Disk Platter)
实际存储数据的盘片,数据存储在盘面的磁性涂层上
2. 磁头(Drive Head)
① 磁头从盘面读取数据,然后通过电信号传输给控制电路与接口
② 通常一个盘面上会有2个磁头,分别在盘面的正反面;而一块硬盘也不止一个盘面,而是上写堆叠了多个盘面
3. 悬臂(Actuator Arm)
在一定范围内,将磁头定位到盘面上的某个特定磁道
4. 磁道(Track)
磁道是盘面上不同半径的同心圆,悬臂只是控制读取哪个磁道上的数据
5. 扇区(Sector)和柱面(Cylinder)
磁道被划分为一个个扇区,上下平行的盘面的相同扇区构成一个柱面
说明:机械硬盘转速
机械硬盘转速的单位为RPM,也就是每分钟旋转圈数(Rotations Per Minute),常见的机械硬盘转速为5400 / 7200 / 10000 / 15000转
9.2 机械硬盘的读操作
9.2.1 操作步骤
从机械硬盘读取数据分为2个步骤,
1. 将盘面旋转到某个位置,在这个位置上,悬臂可以定位到整个盘面的某个子区间,一般将这个区间称作几何扇区(Geometrical Sector),即在集合位置上,所有扇区都可以被悬臂访问到
2. 将悬臂移动到特定磁道的特定扇区,读取数据
9.2.2 操作耗时
对机械硬盘的一次随机访问,需要的时间由2个部分构成
1. 平均延时(Average Latency)
旋转盘面,将几何扇区对准悬臂位置的时间。在随机情况下,平均找到一个几何扇区需要旋转半圈盘面
以7200转的机械硬盘为例,每秒可以旋转240个半圈,所以平均延时为,
1s / 240 = 4.17ms
2. 平均寻道时间(Average Seek Time)
在盘面旋转之后,悬臂定位到扇区的时间,目前机械硬盘的平均寻道时间为4 ~ 10ms
所以7200转机械硬盘一次随机访问的耗时为8 ~ 14ms,据此可计算出IOPS,
1s / 8ms = 125 IOPS或1s / 14ms = 71 IOPS
说明:顺序存放数据可以提升读写性能
如果尽可能将数据存放在一个柱面上,则只需要旋转一次盘面,进行一次寻道,就可以读写同一个垂直空间上的多个盘面的数据
9.3 机械硬盘性能提升
9.3.1 减少平均延时
1. 平均延时与机械硬盘转速相关,所以提升转速即可减少平均延时
2. 高转速(10000或15000转)的机械硬盘更加昂贵
9.3.2 减少平均寻道时间
1. 通过软件格式化,只使用1/2或1/4的磁道,也就是只使用1/2或1/4的存储容量,就可以将平均寻道时间变为原来的1/2或1/4
2. 仍以上文中的7200转机械硬盘为例,如果只使用1/4的磁道,IOPS如下,
1s / (4.17ms + 9ms / 4) = 155.8 IOPS
可见IOPS提升了1倍,与15000转的机械硬盘性能相当。虽然此时可用容量只有原来的1/4,但是相同容量的的15000转机械硬盘贵了不止4倍,所以还是划算的
10. SSD硬盘
10.1 SSD & HDD硬盘对比
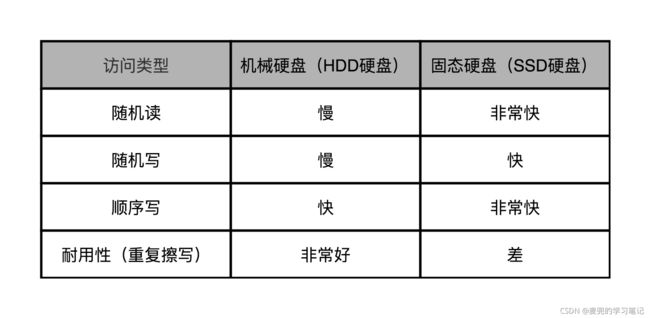
1. SSD硬盘各项读写性能均优于HDD硬盘
2. SSD硬盘的最大缺点在于耐用性差,如果需要频繁地重复写入删除数据,HDD硬盘的性价比就比SSD硬盘高很多
而SSD硬盘的耐用性差,又与他的工作原理相关
10.2 SSD读写原理
10.2.1 基本原理
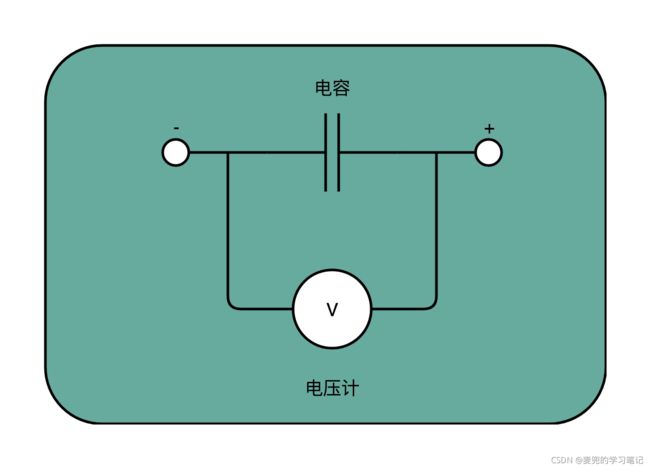
SSD硬盘的存储原理可以抽象为电容 + 电压计,通过向电容充电达到不同的电压,来标识不同的数据值
10.2.2 SLC / MLC / TLC / QLC
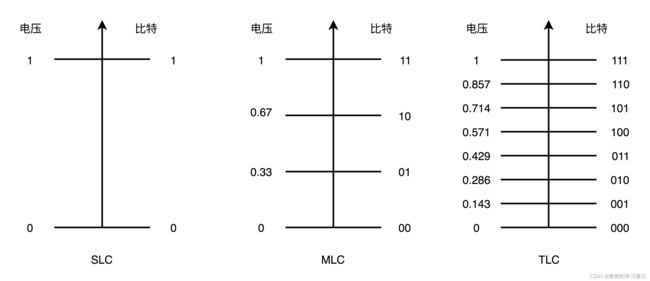
根据每个存储颗粒能记录的比特位个数,SSD硬盘分为SLC(Single-Level Cell) / MLC(Multi-Level Cell) / TLC(Triple-Level Cell) / QLC(Quad-Level Cell),他们分别可以在一个电容中存储1 / 2 / 3 / 4个比特位
说明1:如果只使用SLC,存储密度太低,就会导致存储容量上不去,因此才有了MLC / TLC / QLC
说明2:电容中能存储的比特位越多,充电与读取数据时对精度的要求就更高,这会导致充电和读取速度更慢,所以QLC的SSD读写速度比SLC的慢好几倍
说明3:电容中能存储的比特位越多,可擦除次数越少,使用寿命也越短
SLC可以擦除约10W次,MLC只能擦除1W次,而TLC和QLC只能擦除几千次
10.2.3 硬盘结构
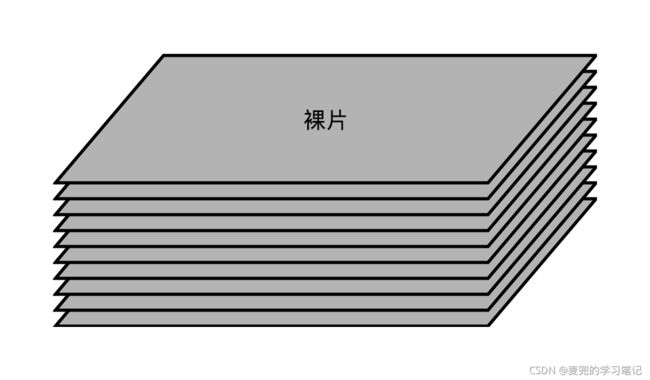
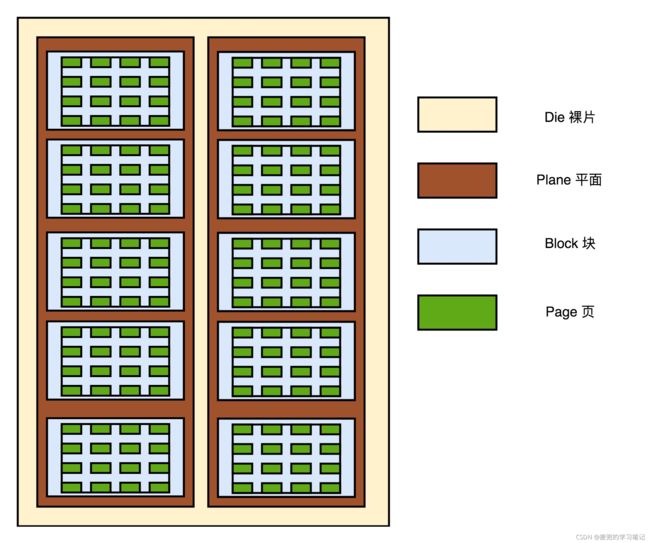
目前新的大容量SSD硬盘均采用3D封装,内部由多个裸片(Die)堆叠构成,在裸片中又划分了平面、块和页
10.3 SSD擦写问题
10.3.1 读写与擦除单位
1. SSD硬盘读写以页为单位,一个页通常大小为4KB
2. 在写入之前必须要先擦除,而不能覆写
3. SSD硬盘擦除以块为单位,SSD的使用寿命就是每个块的擦除次数
10.3.2 SSD读写生命周期
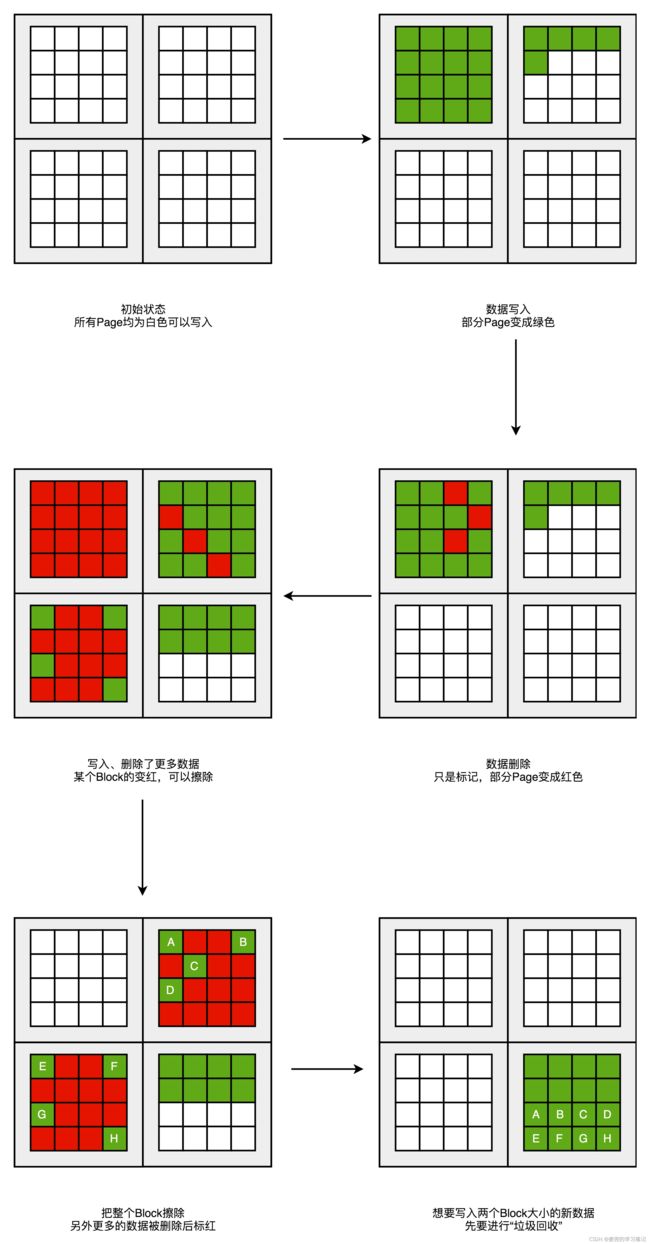
1. 对于整个block被标记为数据已删除的区域,可以进行擦除,以便继续写入数据
2. 如果红色空洞过多,就要进行类似"磁盘碎片整理"的操作。但是这种操作不能太主动、太频繁,因为SSD的擦除次数是有限的
10.3.3 SSD预留空间
从SSD的读写生命周期可见,SSD硬盘的容量是用不满的,因为总会有一些红色空洞,所以生产SSD的厂商会预留一部分空间,专门用来做"磁盘碎片整理"的工作
一块标称240GB的SSD硬盘,通常实际有256GB空间,此处多出来的16GB空间就是预留空间(Over Provisioning)
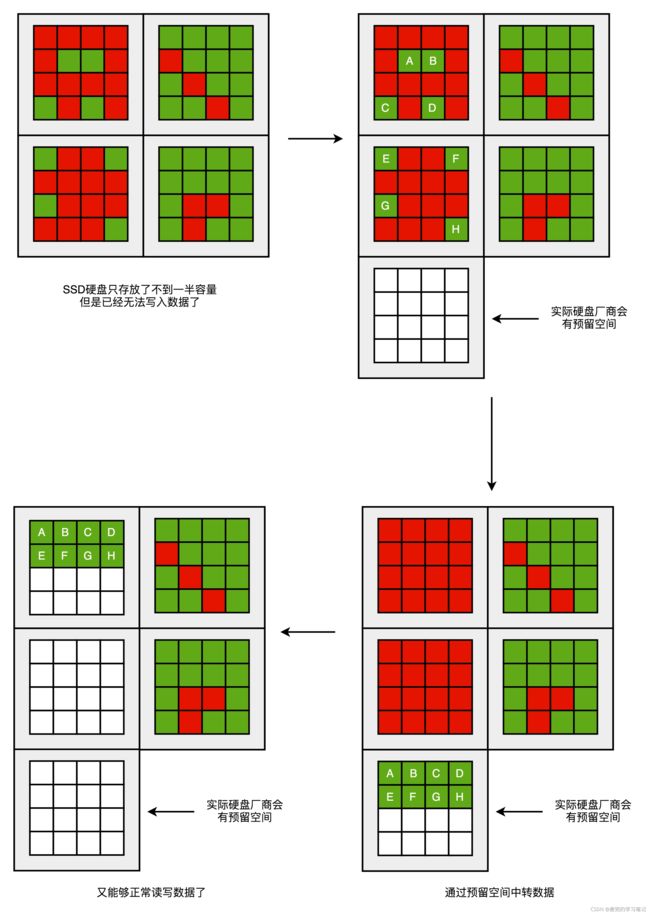
说明:根据SSD硬盘的原理,SSD硬盘特别适合读多写少的应用,因此适合作为系统盘适用。如果用SSD作为下载盘,则会缩短适用寿命
10.4 FTL与磨损均衡问题
10.4.1 磨损均衡问题
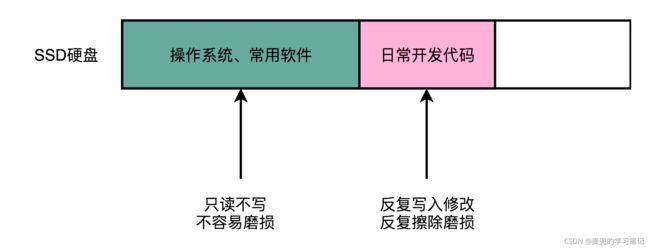
1. 操作系统与常用软件部分在安装后,一般只有读的需求,很少擦除
2. 对于日常开发代码部分,会不断新增文件并修改已有文件,因为SSD没有覆写功能,这个过程实际上在反复写入新的文件,然后将原来的文件存储区域标记为逻辑上删除的状态
3. 当SSD中空闲块不足时,就会用"磁盘碎片整理"的方式进行擦除。这样反复擦除就会导致日常开发代码部分出现坏块,而操作系统区域没有损坏,这块硬盘的可用容量就变小了
10.4.2 FTL的作用
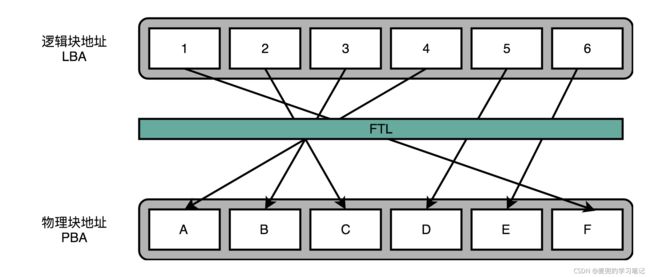
1. FTL(Flash Translation Layer)闪存转换层实现在SSD controller中
2. FTL中存放了逻辑块地址(Logical Block Address,LBA)到物理块地址(Physical Block Address,PBA)的映射关系
3. 操作系统对SSD硬盘的读写请求都要经过FTL,所以FTL中能够记录每个物理块被擦除的次数。如果一个物理块被擦除的次数较多,FTL可以将这个物理块挪到一个擦写次数少的物理块上,但是逻辑块无需改变,操作系统无需知道该变化,这就实现了磨损均衡(Wear-Leveling)
10.5 TRIM指令的引入
10.5.1 操作系统删除文件操作
1. 操作系统在删除一个文件时,只是在操作系统逻辑层将inode中的元数据清空,并没有在物理层面删除该文件
2. 由于将inode中的元数据清空,则inode指向的存储空间在操作系统中就被标记为可以写入
3. 这种删除逻辑在机械硬盘上没有问题,因为后续的文件可以覆写这些存储空间;但是SSD硬盘不能覆写,这种处理就有问题
10.5.2 删除文件导致状态不匹配问题
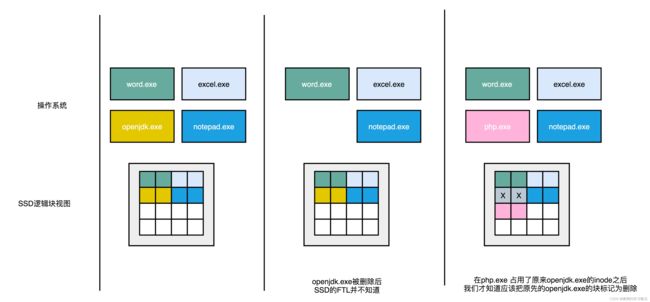
1. 由于SSD硬盘不支持覆写,而操作系统删除文件时不会将信息同步给SSD逻辑层,因此只有当新写入的文件尝试写入已删除文件占用的存储空间时,才会将该位置标记为逻辑上已删除
2. 在此之前,SSD硬盘仍认为这些存储空间有效,在进行磨损均衡时,就会搬运很多已经删除的数据。这样既消耗了SSD性能,也缩短了SSD的使用寿命
10.5.3 TRIM命令
1. 目前的操作系统与SSD controller均支持TRIM命令
2. TRIM命令在文件被删除时,让操作系统通知SSD硬盘,将对应的逻辑快标记为已删除
10.6 写入放大问题
1. 虽然SSD硬盘存储空间被占用得越来越多,写入新数据时可能需要进行"磁盘碎片清理"操作,因此从应用层看来只写入了少量数据,但是经过FTL后可能需要搬运大量数据
2. 实际的闪存写入的数据量 / 系统通过FTL写入的数据量 = 写入放大
写入放大倍数越多,意味着实际的SSD性能越差
说明:要解决写入放大问题,需要在后台定时进行垃圾回收,在硬盘比较空闲时完成搬运数据、擦除数据、留出空白块的工作,而不是等实际数据写入时再进行
11. DMA
11.1 DMA原理
11.1.1 DMA的引入
1. IO设备数据传输是在IO设备与内存之间传输数据
2. 轮询与中断的传输方式中,都是CPU实现数据的传输。由于CPU主频远高于内存与IO设备,因此会存在io_wait现象
3. 直接内存访问(Direct Memory Access,DMA)技术的引入,目的是将CPU从IO设备数据传输中解放出来
说明:即使是基于中断的IO传输,数据也是由CPU控制传输的。因为IO设备通过中断向CPU发送的是控制信号,而不是数据内容。即IO设备只能通知CPU此处有数据要传输,最终数据仍然由CPU完成传输
11.1.2 DMAC的角色
1. 在进行内存和IO设备的数据传输时,不再通过CPU来控制数据传输,而是直接通过DMA控制器(DMA Controller,DMAC)控制
2. DAMC本身是一个特殊的IO设备,对于CPU而言,他是一个从设备;对于硬盘等IO设备来说,他是一个主设备
11.1.3 DMA传输流程
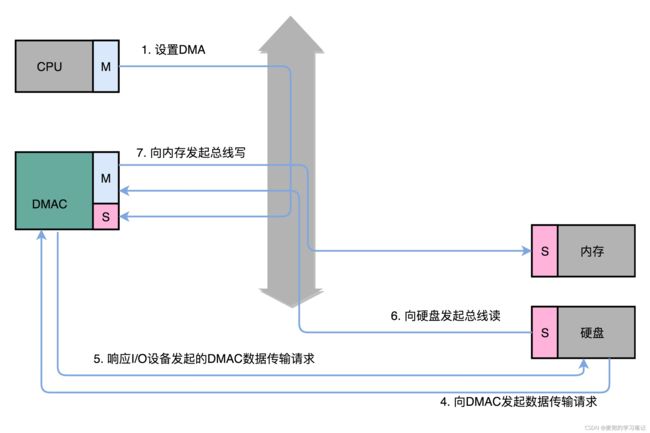
1. CPU作为主设备,向DMAC设备发起请求。发起请求通过设置DMAC的寄存器实现,需要设置如下信息,
① 源地址的初始值及传输时的地址增减方式
② 目的地址的初始值及传输时的地址增减方式
③ 要传输的数据长度
2. 设置完成后,DMAC进入空闲状态(idle)
3. 如果要从硬盘向内存传输数据,硬盘会向DMAC发起一个数据传输请求。这个请求并不是通过总线,而是通过一个额外的连线
4. DMAC通过一个额外的连线响应这个申请
5. DMAC向硬盘的接口发起总线读的传输请求,数据就从硬盘中读取到了DMAC的控制器中
6. DMAC再向内存发起总线写的传输请求,将数据写入内存
7. DMAC反复进行⑤、⑥的操作,直到DMAC的寄存器中设置的数据长度传输完成
8. 数据传输完成后,DMAC重新回到空闲状态
11.2 零拷贝传输
11.2.1 零拷贝传输原理
假设要从磁盘读取数据然后发送到网络上,传统的方式如下,
read(filefd, buf, len);
send(socket, buf, len);这里共涉及4次数据传输,其中2次是DMA传输,2次是CPU传输
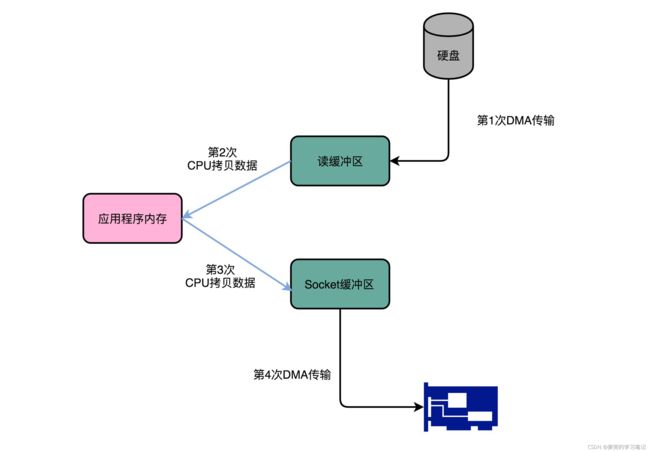
零拷贝传输则是取消2次CPU传输,
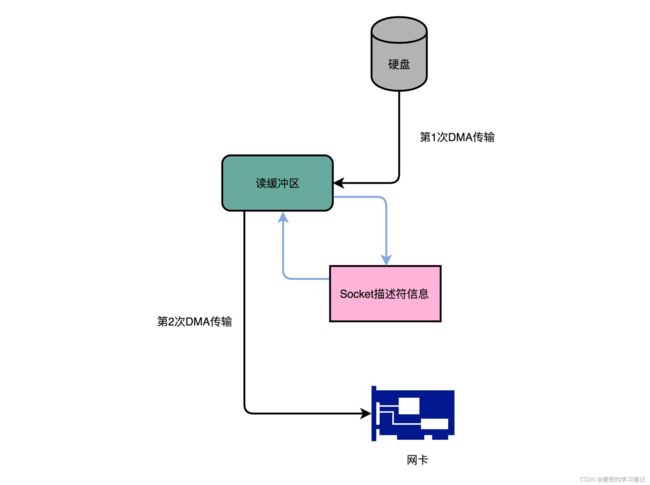
其中第2次的传输是根据socket的描述符信息,直接将数据从读缓冲区传输到网卡的缓冲区中
11.2.2 Linux零拷贝传输实例
在Linux中,可以使用sendfile函数实现零拷贝传输
#include
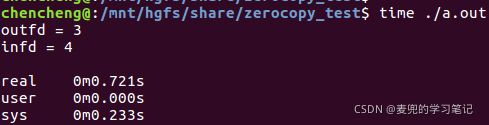
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count); 以下为不使用零拷贝传输的代码及程序运行耗时,其中outfile为一个10MB大小的全零文件
char buf[4096];
int main(void)
{
int outfd;
int infd;
int ret;
outfd = open("outfile", O_RDONLY);
printf("outfd = %d\n", outfd);
infd = open("infile", O_WRONLY | O_CREAT);
printf("infd = %d\n", infd);
while ((ret = read(outfd, buf, 4096)) > 0) {
write(infd, buf, ret);
}
close(outfd);
close(infd);
return 0;
}
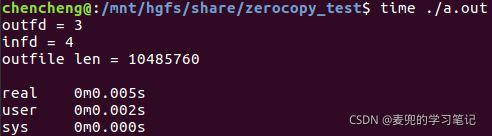
以下为使用零拷贝传输的代码及程序运行耗时,可见性能有很大提高
int main(void)
{
int outfd;
int infd;
int ret;
int len;
outfd = open("outfile", O_RDONLY);
printf("outfd = %d\n", outfd);
infd = open("infile", O_WRONLY | O_CREAT);
printf("infd = %d\n", infd);
len = lseek(outfd, 0, SEEK_END);
printf("outfile len = %d\n", len);
lseek(outfd, 0, SEEK_SET);
sendfile(outfd, infd, NULL, len);
close(outfd);
close(infd);
return 0;
}
12. 数据完整性
12.1 单比特翻转
1. 单比特翻转(Single-Bit Flip)是在内存中发生的硬件错误
2. 单比特翻转是一个随机现象,无法稳定复现
3. 可以使用ECC内存(Error-Correcting Code memory,纠错内存)避免单比特翻转问题
12.2 奇偶校验
1. 奇偶校验思路简单,将内存中的N个比特作为一组,然后用额外的一位记录校验码,以偶校验为例,示例如下,
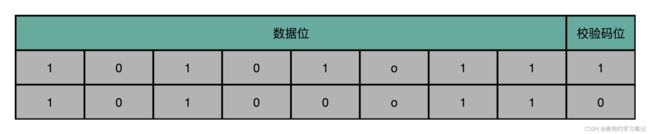
2. 奇偶校验的计算非常快,通过O(N)的时间复杂度算法就可以计算出校验码
3. 奇偶校验只能检测出奇数个位的错误
4. 奇偶校验只能发现错误,不能纠正错误
说明:纠错码和纠删码
① 校验码只是检错码(Error Detecting Code)
② 如果要纠正错误就需要使用纠错码(Error Correcting Code)
③ 纠错码的升级版本叫纠删码(Erasure Code),不仅能纠正错误,还能够在错误不能纠正时直接将数据删除
ECC内存、网络传输和硬盘RAID等技术中,都利用了纠错码和纠删码的相关技术
12.3 海明码
12.3.1 概述
1. 海明码作为一种纠错码,需要冗余信息才能判断出错的比特位,并将其改正
2. ECC内存就是使用海明码进行纠错
3. 海明码只能纠正某一个比特位的错误,必须认识到纠错码的纠错能力是有限的
12.3.2 海明码冗余信息
以7-4海明码为例,说明海明码所需的冗余信息
1. 7-4海明码是指实际有效数据为7位,校验位为4位
2. 4位校验码可以表示2^4 = 16个不同的数,也就是可以标识15种错误情况(还有一种情况就是正确的情况)
3. 之所以需要具备15种错误情况,是因为传输过程中,不仅数据位会出错,校验位也可能出错,所以7-4海明码共有11位数据要传输,就需要4位校验码
同时也可以得出,4位校验码最多可以覆盖11位数据位
4. 如果数据位有K位,校验位有N位,那么需要满足如下不等式,
K + N <= 2^N - 1
常见海明码校验码位数如下表所示,

12.3.3 海明码纠错原理
以4-3海明码为例,说明海明码的纠错原理
1. 计算校验位值时,确保只要有一个数据位出错,就至少有2个校验位不一致,且校验位不一致的组合方式不同
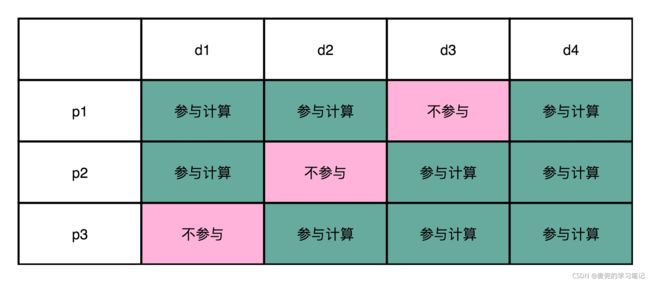
如上图所示,如果d1位出错,则p1 & p2校验位就会不一致;d2位出错,则是p1 & p3校验位不一致
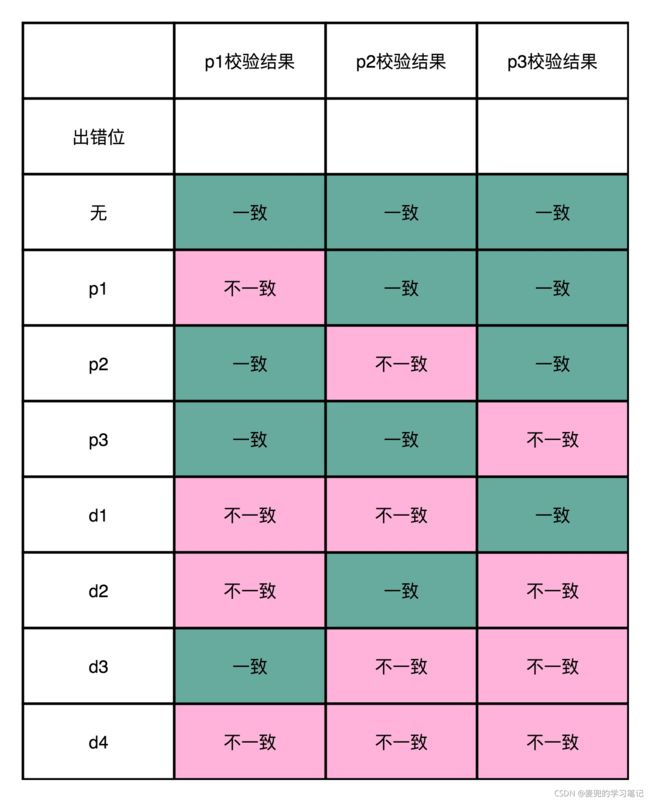
2. 纠错时逆向判断,根据校验位的错误情况,判断出错的比特位
12.3.4 海明码编码方式
以7-4海明码说明编码方式,步骤如下图所示
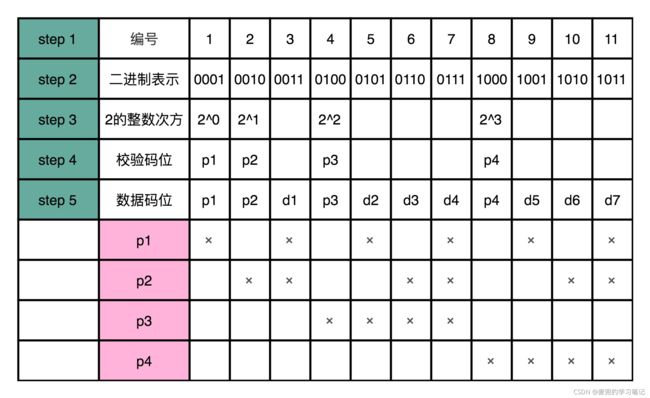
1. 将要传输的数据位与校验位总和编号,之后从左到右选择2^n幂作为校验位,此处就是第1 / 2 / 4 / 8位
之所以选择2^n幂作为校验位,是因为这些位只有一个比特位为1,这点在后续的编码和校验中非常重要
2. 计算各个校验位的值
p1选择编号bit[0] = 1的数据位计算
p2选择编号bit[1] = 1的数据位计算
p3选择编号bit[2] = 1的数据位计算
p4选择编号bit[5] = 1的数据位计算
这样计算出的校验值就具备的如下特征,
① 如果只有1bit校验位出错,则只涉及校验位
② 如果只有1bit数据位出错,则至少有2个校验位不一致,且组合不重叠
说明:海明距离
① 对于2个二进制数,他们之间有差异的位数,称为海明距离
② 所谓进行一位纠错,就是所有和我们要传输的数据的海明距离为1的数,都能被纠正回来
③ 任何实际要传输的数,海明距离至少为3,这样一旦出现1比特错误,就能知道应该被纠正到哪个数值
13. 分布式计算
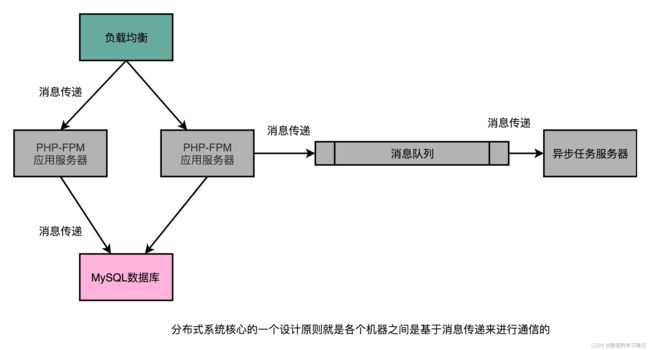
1. 分布式计算需要引入负载均衡(Load Balancer)组件,进行流量分配
2. 通过消息传递(Message Passing)而不是共享内存(Shared Memory)的方式让多台不同的计算机协同工作
3. 负载均衡能够通过健康检测(Health Check)发现故障的服务器没有响应,就可以自动将所有流量切换到其他服务器,这个操作叫做故障转移(Failover)