Linux内核详解与内核优化方案
一、Linux历史
1、Unix
UNIX 与 Linux 之间的关系是一个很有意思的话题。在目前主流的服务器端操作系统中,UNIX 诞生于 20 世纪 60 年代末,Windows 诞生于 20 世纪 80 年代中期,Linux 诞生于 20 世纪 90 年代初,可以说 UNIX 是操作系统中的"老大哥",后来的 Windows 和 Linux 都参考了 UNIX。
UNIX 操作系统由肯•汤普森(Ken Thompson)和丹尼斯•里奇(Dennis Ritchie)发明。它的部分技术来源可追溯到从 1965 年开始的 Multics 工程计划,该计划由贝尔实验室、美国麻省理工学院和通用电气公司联合发起,目标是开发一种交互式的、具有多道程序处理能力的分时操作系统,以取代当时广泛使用的批处理操作系统。
说明:分时操作系统使一台计算机可以同时为多个用户服务,连接计算机的终端用户交互式发出命令,操作系统采用时间片轮转的方式处理用户的服务请求并在终端上显示结果(操作系统将CPU的时间划分成若干个片段,称为时间片)。操作系统以时间片为单位,轮流为每个终端用户服务,每次服务一个时间片。
可惜,由于 Multics 工程计划所追求的目标太庞大、太复杂,以至于它的开发人员都不知道要做成什么样子,最终以失败收场。
以肯•汤普森为首的贝尔实验室研究人员吸取了 Multics 工程计划失败的经验教训,于 1969 年实现了一种分时操作系统的雏形,1970 年该系统正式取名为 UNIX。
有意思的是,肯•汤普森当年开发 UNIX 的初衷是运行他编写的一款计算机游戏 Space Travel,这款游戏模拟太阳系天体运动,由玩家驾驶飞船,观赏景色并尝试在各种行星和月亮上登陆。他先后在多个系统上试验,但运行效果不甚理想,于是决定自己开发操作系统,就这样,UNIX 诞生了。
自 1970 年后,UNIX 系统在贝尔实验室内部的程序员之间逐渐流行起来。1971-1972 年,肯•汤普森的同事丹尼斯•里奇发明了传说中的C语言,这是一种适合编写系统软件的高级语言,它的诞生是 UNIX 系统发展过程中的一个重要里程碑,它宣告了在操作系统的开发中,汇编语言不再是主宰。
到了 1973 年,UNIX 系统的绝大部分源代码都用C语言进行了重写,这为提高 UNIX 系统的可移植性打下了基础(之前操作系统多采用汇编语言,对硬件依赖性强),也为提高系统软件的开发效率创造了条件。可以说,UNIX 系统与C语言是一对孪生兄弟,具有密不可分的关系。
20 世纪 70 年代初,计算机界还有一项伟大的发明——TCP/IP 协议,这是当年美国国防部接手 ARPAnet 后所开发的网络协议。美国国防部把 TCP/IP 协议与 UNIX 系统、C语言捆绑在一起,由 AT&T 发行给美国各个大学非商业的许可证,这为 UNIX 系统、C语言、TCP/IP 协议的发展拉开了序幕,它们分别在操作系统、编程语言、网络协议这三个领域影响至今。肯•汤普森和丹尼斯•里奇因在计算机领域做出的杰出贡献,于 1983 年获得了计算机科学的最高奖——图灵奖。
随后出现了各种版本的 UNIX 系统,目前常见的有 Sun Solaris、FreeBSD、IBM AIX、HP-UX 等。
2、Solaris 和 FreeBSD
Solaris是UNIX系统的一个重要分支。Solaris 除可以运行在 SPARC CPU 平台上外,还可以运行在 x86 CPU 平台上。在服务器市场上,Sun 的硬件平台具有高可用性和高可靠性,是市场上处于支配地位的 UNIX 系统。Solaris x86 用于实际生产应用的服务器,在遵守 Sun 的有关许可条款的情况下,Solaris x86 可以免费用于学习研究或商业应用。
FreeBSD源于美国加利福尼亚大学伯克利分校开发的 UNIX 版本,它由来自世界各地的志愿者开发和维护,为不同架构的计算机系统提供了不同程度的支持。FreeBSD 在 BSD 许可协议下发布,允许任何人在保留版权和许可协议信息的前提下随意使用和发行,并不限制将 FreeBSD 的代码在另一协议下发行,因此商业公司可以自由地将 FreeBSD 代码融入它们的产品中。苹果公司的 OS X 就是基于 FreeBSD 的操作系统。
FreeBSD 与 Linux 的用户群有相当一部分是重合的,二者支持的硬件环境也比较一致,所采用的软件也比较类似。FreeBSD 的最大特点就是稳定和高效,是作为服务器操作系统的不错选择;但其对硬件的支持没有 Linux 完备,所以并不适合作为桌面系统。
3、Linux的诞生
Linux 内核最初是由李纳斯•托瓦兹(Linus Torvalds)在赫尔辛基大学读书时出于个人爱好而编写的,当时他觉得教学用的迷你版 UNIX 操作系统 Minix 太难用了,于是决定自己开发一个操作系统。第 1 版本于 1991 年 9 月发布,当时仅有 10 000 行代码。
李纳斯•托瓦兹没有保留 Linux 源代码的版权,公开了代码,并邀请他人一起完善 Linux。与 Windows 及其他有专利权的操作系统不同,Linux 开放源代码,任何人都可以免费使用它。
据估计,现在只有 2% 的 Linux 核心代码是由李纳斯•托瓦兹自己编写的,虽然他仍然拥有 Linux 内核(操作系统的核心部分),并且保留了选择新代码和需要合并的新方法的最终裁定权。现在大家所使用的 Linux,我更倾向于说是由李纳斯•托瓦兹和后来陆续加入的众多 Linux 好者共同开发完成的。
开源软件是不同于商业软件的一种模式,从字面上理解,就是开放源代码,大家不用担心里面会搞什么猫腻,这会带来软件的革新和安全。
Linux 受至旷大计算机爱好者的喜爱,主要原因也有两个:
- 它属于开源软件,用户不用支付可费用就可以获得它和它的源代码,并且可以根据自己的需要对它进行必要的修改,无偿使用,无约束地继续传播;
- 它具有 UNIX 的全部功能,任何使用 UNIX 操作系统或想要学习 UNIX 操作系统的人都可以从 Linux 中获益。
另外,开源其实并不等同于免费,而是一种新的软件盈利模式。目前很多软件都是开源软件,对计算机行业与互联网影响深远。
二、Linux kernel 简介
1、计算机系统组成
一个计算机系统是一个硬件和软件的共生体,它们互相依赖,不可分割。
计算机的硬件,含有外围设备、处理器、内存、硬盘和其他的电子设备组成计算机的发动机,但是没有软件来操作和控制它,自身是不能工作的。
完成这个控制工作的软件就称为操作系统。操作系统是管理计算机硬件与软件资源的系统软件,同时也是计算机系统的内核与基石。操作系统需要处理如管理与配置内存、决定系统资源供需的优先次序、控制输入与输出设备、操作网络与管理文件系统等基本事务。操作系统也提供一个让用户与系统交互的操作界面。
操作系统的的组成:
· Bootloader:它主要负责设备的启动过程。
· Shell:Shell是一种编程语言,它可以控制其他文件,进程以及所有其他程序。
· Kernel:它是操作系统的主要组件,管理内存,CPU和其他相关组件。
· Desktop Environment:这是用户通常与之交互的环境。
· Graphical server(图形服务器):它是操作系统的子系统,用于在屏幕上显示图形
· Applications:这些是执行不同用户任务(例如word,excel等)的程序集。
· Daemons :后台服务提供商。
2、何为内核(Kernel)
内核是操作系统的关键组成部分,因为它控制系统中的所有程序。它借助进程间通信和系统调用,在硬件级别上充当应用程序和数据处理之间的桥梁。
当设备启动时,会将操作系统加载到内存,这时内核会经历一个初始化的过程,它负责内存分配部分,并将其保留在那里,直到操作系统关闭。并创建了一个运行应用程序的环境,在该环境中内核负责处理低级任务,例如任务管理,内存管理,风险管理等。
内核相当于服务提供者,因此程序可以请求内核完成多项任务,例如请求使用磁盘,网卡或其他硬件,并且内核为CPU设置中断以启用多任务处理。它不让错误的程序进入其他程序的操作功能,从而保护了计算环境。它通过不允许存储空间来阻止未经授权的程序进入入口,并限制它们消耗的
CPU时间。
简而言之:
1. 从技术层面讲,内核是硬件与软件之间的一个中间层。作用是将应用层序的请求传递给硬件,并充当底层驱动程序,对系统中的各种设备和组件进行寻址。
2. 从应用程序的层面讲,应用程序与硬件没有联系,只与内核有联系,内核是应用程序知道的层次中的最底层。在实际工作中内核抽象了相关细节。
3. 内核是一个资源管理程序。负责将可用的共享资源(CPU时间、磁盘空间、网络连接等)分配得到各个系统进程。
4. 内核就像一个库,提供了一组面向系统的命令。系统调用对于应用程序来说,就像调用普通函数一样。
3、内核的分类
内核通常有三类:
1. Monolithic kernel:它包含许多设备驱动程序,可在设备的硬件和软件之间创建通信接口。
它是操作系统广泛使用的内核。在单片架构中,内核由可以动态加载和卸载的各种模块组成。这种体系结构将扩展OS的功能,并允许轻松扩展内核。
使用单片式体系结构,内核的维护变得容易,因为当需要修复特定模块中的错误时,它允许相关模块进行加载和卸载。因此,它消除了繁琐的工作,即降低并重新编译整个内核以进行很小的更改。在单片内核中,卸载不再使用的模块更加容易。
2. Micro kernel:它只能执行基本功能。
微内核已经发展成为单片内核的替代产品,以解决单片内核无法做到的内核代码不断增长的问题。这种体系结构允许某些基本服务(例如协议栈,设备驱动程序管理,文件系统等)在用户空间中运行。这样可以以最少的代码增强OS的功能,提高安全性并确保稳定性。
它通过使系统的其余部分正常运行而不会造成任何中断,从而限制了对受影响区域的损坏。在微内核体系结构中,所有基本OS服务都可以通过进程间通信(IPC)提供给程序。微内核允许设备驱动程序和硬件之间的直接交互。
3. Hybrid kernel:它结合了单片内核和微内核的各个方面。
混合内核可以决定要在用户模式和主管模式下运行什么。通常,在混合内核环境中,设备驱动程序,文件系统I / O之类的内容将在用户模式下运行,而服务器调用和IPC则保持在管理者模式下。
4、内核设计流派
1. 微内核。最基本的功能由中央内核(微内核)实现。Windows NT采用的就是微内核体系结构。对于微内核体系结构特点,操作系统的核心部分是一个很小的内核,实现一些最基本的服务,如创建和删除进程、内存管理、中断管理等等。而文件系统、网络协议等其它部分都在微内核外的用户空间里运行。这些功能都委托给一些独立进程,这些进程通过明确定义的通信接口与中心内核通信。
2. 宏(单)内核。内核的所有代码,包括子系统(如内存管理、文件管理、设备驱动程序)都打包到一个文件中。所有功能都做在一起,都在内核中,也就是说,整个内核是一个单独的非常大的程序。内核中的每一个函数都可以访问到内核中所有其他部分。目前支持模块的动态装卸(裁剪),Linux内核就是基于这个策略实现的。
使用微内核的操作系统具有很好的可扩展性而且内核非常的小,但这样的操作系统由于不同层次之间的消息传递要花费一定的代价所以效率比较低。对单一体系结构的操作系统来说,所有的模块都集成在一起,系统的速度和性能都很好,但是可扩展性和维护性就相对比较差。
按道理来说,Linux微内核结构实现的,但恰恰不是,Linux是单内核(monolithic)结构。这意味着虽然Linux被划分成控制系统各种组件(例如内存管理和进程管理)的多个子系统,但所有的子系统都紧密集成在一起,从而构成整个内核。
与之相反,微内核(microkernel)操作系统提供了最少量的功能集合,而所有其他的操作系统层次都在微内核之上以进程方式执行。由于各个层次之间存在着消息传递,微内核操作系统的效率通常较低,但这类操作系统非常便于扩展。
从根本上讲,将一个事情拆成各个小问题,然后每个小问题只负责一个任务是linux的设计哲学之一,Linux内核可通过模块方式进行扩展。
模块是在内核空间运行的程序,实际上是一种目标对象文件,没有链接,不能独立运行,但是其代码可以在运行时链接到系统中作为内核的一部分运行或从内核中取下,从而可以动态扩充内核的功能。
这种目标代码通常由一组函数和数据结构组成,用来实现一种文件系统,一个驱动程序,或其它内核上层的功能。模块机制的完整叫法应该是动态可加载内核模块(Loadable Kernel Module)或 LKM,一般就简称为模块。与前面讲到的运行在微内核体系操作系统的外部用户空间的进程不同,模块不是作为一个进程执行的,而像其他静态连接的内核函数一样,它在内核态代表当前进程执行。由于引入了模块机制,Linux的内核可以达到最小,即内核中实现一些基本功能,如从模块到内核的接口,内核管理所有模块的方式等等,而系统的可扩展性就留给模块来完成。
模块具有既提供了微内核的优点却又没有额外开销的内核特性。
5、内核职能
Linux 内核实现了很多重要的体系结构属性。在或高或低的层次上,内核被划分为多个子系统。
Linux 也可以看作是一个整体,因为它会将所有这些基本服务都集成到内核中。这与微内核的体系结构不同,后者会提供一些基本的服务,例如通信、I/O、内存和进程管理,更具体的服务都是插入到微内核层中的。
内核主要的任务有:
· 用于应用程序执行的流程管理。
· 内存和I / O(输入/输出)管理。
· 系统调用控制(内核的核心行为)。
· 借助设备驱动程序进行设备管理。
· 为应用程序提供运行环境。
6、内核所具备的核心功能
Linux内核主要负责的功能有:存储管理、CPU和进程管理、文件系统、设备管理和驱动、网络通信,以及系统的初始化(引导)、系统调用等。
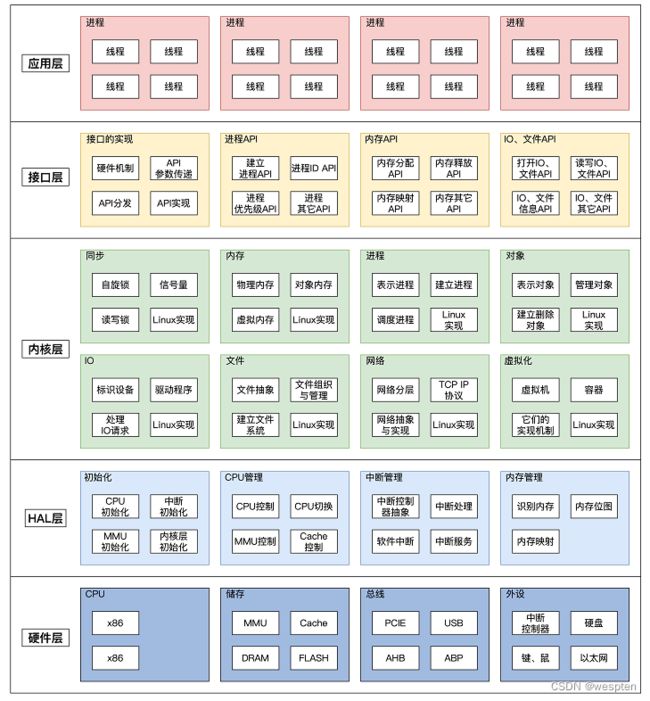
主要功能有以下:
- 系统内存管理
- 软件程序管理
- 硬件设备管理
- 文件系统管理
1)系统内存管理
操作系统内核的主要功能之一就是内存管理。内核不仅管理服务器上的可用物理内存,还可以创建和管理虚拟内存(即实际并不存在的内存)。
内核通过硬盘上的存储空间来实现虚拟内存,这块区域称为交换空间(swap space)。内核不断地在交换空间和实际的物理内存之间反复交换虚拟内存中的内容。这使得系统以为它拥有比物理内存更多的可用内存。
内存存储单元按组划分成很多块,这些块称作页面(page)。内核将每个内存页面放在物理内存或交换空间。然后,内核会维护一个内存页面表,指明哪些页面位于物理内存内,哪些页面被换到了磁盘上。
2)软件程序管理
Linux操作系统将运行中的程序称为进程。进程可以在前台运行,将输出显示在屏幕上,也可以在后台运行,隐藏到幕后。内核控制着Linux系统如何管理运行在系统上的所有进程。
内核创建了第一个进程(称为init进程)来启动系统上所有其他进程。当内核启动时,它会
将init进程加载到虚拟内存中。内核在启动任何其他进程时,都会在虚拟内存中给新进程分配一块专有区域来存储该进程用到的数据和代码。
一些Linux发行版使用一个表来管理在系统开机时要自动启动的进程。在Linux系统上,这个表通常位于专门文件/etc/inittab中。
另外一些系统(比如现在流行的Ubuntu Linux发行版)则采用/etc/init.d目录,将开机时启动
或停止某个应用的脚本放在这个目录下。这些脚本通过/etc/rcX.d目录下的入口(entry)启动,这里的X代表运行级(run level)。
Linux操作系统的init系统采用了运行级。运行级决定了init进程运行/etc/inittab文件或/etc/rcX.d目录中定义好的某些特定类型的进程。 Linux操作系统有5个启动运行级。
- 运行级为1时,只启动基本的系统进程以及一个控制台终端进程。我们称之为单用户模式。单用户模式通常用来在系统有问题时进行紧急的文件系统维护。显然,在这种模式下,仅有一个人(通常是系统管理员)能登录到系统上操作数据。
- 标准的启动运行级是3。在这个运行级上,大多数应用软件,比如网络支持程序,都会启动。另一个Linux中常见的运行级是5。在这个运行级上系统会启动图形化的X Window系统,允许用户通过图形化桌面窗口登录系统。
可以使用ps命令查看当前运行在Linux系统上的进程。
3)硬件设备管理
内核的另一职责是管理硬件设备。任何Linux系统需要与之通信的设备,都需要在内核代码
中加入其驱动程序代码。驱动程序代码相当于应用程序和硬件设备的中间人,允许内核与设备之间交换数据。在Linux内核中有两种方法用于插入设备驱动代码:
- 编译进内核的设备驱动代码
- 可插入内核的设备驱动模块
以前,插入设备驱动代码的唯一途径是重新编译内核。每次给系统添加新设备,都要重新编译一遍内核代码。随着Linux内核支持的硬件设备越来越多,这个过程变得越来越低效。不过好在Linux开发人员设计出了一种更好的将驱动代码插入运行中的内核的方法。
开发人员提出了内核模块的概念。它允许将驱动代码插入到运行中的内核而无需重新编译内
核。同时,当设备不再使用时也可将内核模块从内核中移走。这种方式极大地简化和扩展了硬件设备Linux上的使用。
Linux系统将硬件设备当成特殊的文件,称为设备文件。设备文件有3种分类:
- 字符型设备文件:指处理数据时每次只能处理一个字符的设备 ,比如大多数类型的调制解调器和
终端 。 - 块设备文件: 指处理数据时每次能处理大块数据的设备,比如硬盘。
- 网络设备文件:指采用数据包发送和接收数据的设备,包括各种网卡和一个特殊的回环设备。
4)文件系统管理
不同于其他一些操作系统, Linux内核支持通过不同类型的文件系统从硬盘中读写数据。除
了自有的诸多文件系统外, Linux还支持从其他操作系统(比如Microsoft Windows)的文件
系统中读写数据。内核必须在编译时就加入对所有可能用到的文件系统的支持。下表列出了Linux系统用来读写数据的标准文件系统。
Linux服务器所访问的所有硬盘都必须格式化成上表所列文件系统类型中的一种。
随着时间的流逝,Linux 内核在内存和 CPU 使用方面具有较高的效率,并且非常稳定。但是对于 Linux 来说,最为有趣的是在这种大小和复杂性的前提下,依然具有良好的可移植性。Linux 编译后可在大量处理器和具有不同体系结构约束和需求的平台上运行。一个例子是 Linux 可以在一个具有内存管理单元(MMU)的处理器上运行,也可以在那些不提供MMU的处理器上运行。Linux 内核的uClinux移植提供了对非 MMU 的支持。
三、Linux内核整体架构
1、Linux内核体系结构
UNIX/Linux 系统可以粗糙地抽象为 3 个层次,底层是系统内核(Kernel);中间层是Shell层,即命令解释层;高层则是应用层。

(1)内核层
内核层是 UNIX/Linux 系统的核心和基础,它直接附着在硬件平台之上,控制和管理系统内各种资源(硬件资源和软件资源),有效地组织进程的运行,从而扩展硬件的功能,提高资源的利用效率,为用户提供方便、高效、安全、可靠的应用环境。
(2)Shell层
Shell 层是与用户直接交互的界面。用户可以在提示符下输入命令行,由 Shell 解释执行并输出相应结果或者有关信息,所以我们也把 Shell 称作命令解释器,利用系统提供的丰富命令可以快捷而简便地完成许多工作。
(3)应用层
应用层提供基于 X Window 协议的图形环境。X Window 协议定义了一个系统所必须具备的功能。
Linux内核只是Linux操作系统一部分。对下,它管理系统的所有硬件设备;对上,它通过系统调用,向Library Routine(例如C库)或者其它应用程序提供接口。
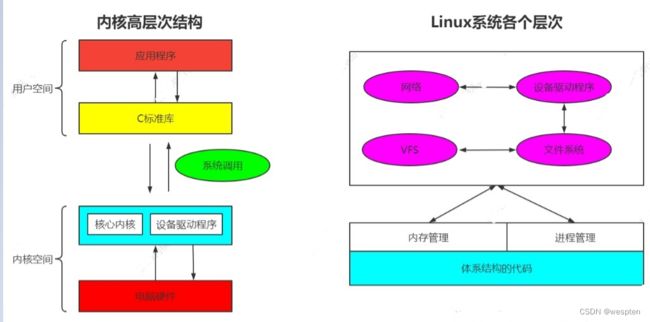
1)内核空间:
内核空间包括系统调用,内核,以及与平台架构相关的代码。内核处于提升的系统状态,其中包括受保护的内存空间以及对设备硬件的完全访问权限。此系统状态和内存空间统称为内核空间。在内核空间内,对硬件和系统服务的核心访问进行管理,并作为服务提供给系统的其余部分。
2)用户空间:
用户空间中又包含了,用户的应用程序,C库。用户空间或用户域是在操作系统内核环境之外运行的代码,用户空间定义为操作系统用来与内核连接的各种应用程序或程序或库。
用户的应用程序是在用户空间中执行的,它们可以通过内核系统调用访问计算机可用资源的一部分。通过使用内核提供的核心服务,可以创建用户级别的应用程序,例如游戏或办公软件。
内核为在用户模式中运行的应用程序提供了一组与系统进行交互的接口。这些接口也称为系统调用,应用程序可以通过接口访问硬件和其他内核资源。系统调用不仅为应用程序提供了抽象化的硬件层次,还确保了系统的安全和稳定性。
大多数应用程序并不直接使用系统调用。相反,在编程时采用了应用程序接口(API)。需要注意的是,在API和系统调用之间不存在关联。API是作为库文件的组成部分提供给应用程序使用的,这些API一般通过一个或多个系统调用来实现。
2、Linux内核架构
为了管理以上的各种资源与设备,Linux内核提出了如下的架构:

根据内核的核心功能,Linux内核提出了5个子系统:

1. Process Scheduler,也称作进程管理、进程调度。负责管理CPU资源,以便让各个进程可以以尽量公平的方式访问CPU。
2. Memory Manager,内存管理。负责管理Memory(内存)资源,以便让各个进程可以安全地共享机器的内存资源。另外,内存管理会提供虚拟内存的机制,该机制可以让进程使用多于系统可用Memory的内存,不用的内存会通过文件系统保存在外部非易失存储器中,需要使用的时候,再取回到内存中。
3. VFS(Virtual File System),虚拟文件系统。Linux内核将不同功能的外部设备,例如Disk设备(硬盘、磁盘、NAND Flash、Nor Flash等)、输入输出设备、显示设备等等,抽象为可以通过统一的文件操作接口(open、close、read、write等)来访问。这就是Linux系统“一切皆是文件”的体现(其实Linux做的并不彻底,因为CPU、内存、网络等还不是文件,如果真的需要一切皆是文件,还得看贝尔实验室正在开发的"Plan 9”的)。
4. Network,网络子系统。负责管理系统的网络设备,并实现多种多样的网络标准。
5. IPC(Inter-Process Communication),进程间通信。IPC不管理任何的硬件,它主要负责Linux系统中进程之间的通信。
进程调度(Process Scheduler)
进程调度是Linux内核中最重要的子系统,它主要提供对CPU的访问控制。因为在计算机中,CPU资源是有限的,而众多的应用程序都要使用CPU资源,所以需要“进程调度子系统”对CPU进行调度管理。
进程调度子系统包括4个子模块(见下图),它们的功能如下:
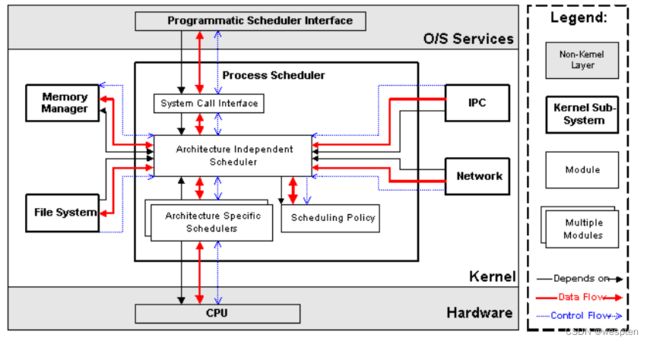
- Scheduling Policy,实现进程调度的策略,它决定哪个(或哪几个)进程将拥有CPU。
- Architecture-specific Schedulers,体系结构相关的部分,用于将对不同CPU的控制,抽象为统一的接口。这些控制主要在suspend和resume进程时使用,牵涉到CPU的寄存器访问、汇编指令操作等。
- Architecture-independent Scheduler,体系结构无关的部分。它会和“Scheduling Policy模块”沟通,决定接下来要执行哪个进程,然后通过“Architecture-specific Schedulers模块”resume指定的进程。
- System Call Interface,系统调用接口。进程调度子系统通过系统调用接口,将需要提供给用户空间的接口开放出去,同时屏蔽掉不需要用户空间程序关心的细节。
内存管理(Memory Manager, MM)
内存管理同样是Linux内核中最重要的子系统,它主要提供对内存资源的访问控制。Linux系统会在硬件物理内存和进程所使用的内存(称作虚拟内存)之间建立一种映射关系,这种映射是以进程为单位,因而不同的进程可以使用相同的虚拟内存,而这些相同的虚拟内存,可以映射到不同的物理内存上。
内存管理子系统包括3个子模块(见下图),它们的功能如下:

- Architecture Specific Managers,体系结构相关部分。提供用于访问硬件Memory的虚拟接口。
- Architecture Independent Manager,体系结构无关部分。提供所有的内存管理机制,包括:以进程为单位的memory mapping;虚拟内存的Swapping。
- System Call Interface,系统调用接口。通过该接口,向用户空间程序应用程序提供内存的分配、释放,文件的map等功能。
虚拟文件系统(Virtual Filesystem, VFS)
传统意义上的文件系统,是一种存储和组织计算机数据的方法。它用易懂、人性化的方法(文件和目录结构),抽象计算机磁盘、硬盘等设备上冰冷的数据块,从而使对它们的查找和访问变得容易。因而文件系统的实质,就是“存储和组织数据的方法”,文件系统的表现形式,就是“从某个设备中读取数据和向某个设备写入数据”。
随着计算机技术的进步,存储和组织数据的方法也是在不断进步的,从而导致有多种类型的文件系统,例如FAT、FAT32、NTFS、EXT2、EXT3等等。而为了兼容,操作系统或者内核,要以相同的表现形式,同时支持多种类型的文件系统,这就延伸出了虚拟文件系统(VFS)的概念。VFS的功能就是管理各种各样的文件系统,屏蔽它们的差异,以统一的方式,为用户程序提供访问文件的接口。
我们可以从磁盘、硬盘、NAND Flash等设备中读取或写入数据,因而最初的文件系统都是构建在这些设备之上的。这个概念也可以推广到其它的硬件设备,例如内存、显示器(LCD)、键盘、串口等等。我们对硬件设备的访问控制,也可以归纳为读取或者写入数据,因而可以用统一的文件操作接口访问。Linux内核就是这样做的,除了传统的磁盘文件系统之外,它还抽象出了设备文件系统、内存文件系统等等。这些逻辑,都是由VFS子系统实现。
VFS子系统包括6个子模块(见下图),它们的功能如下:
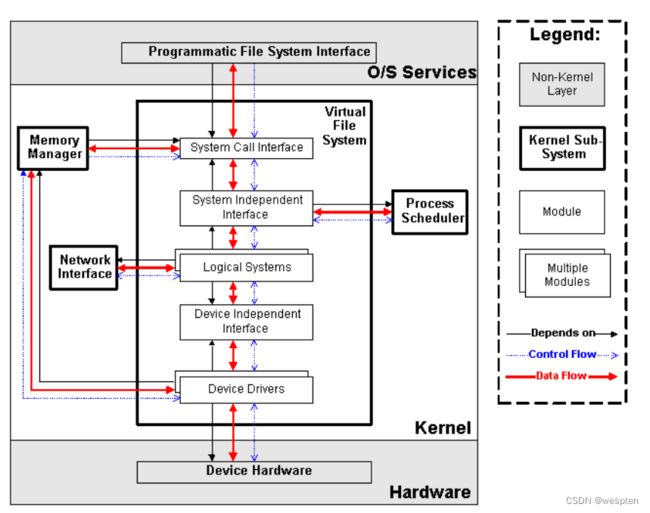
- Device Drivers,设备驱动,用于控制所有的外部设备及控制器。由于存在大量不能相互兼容的硬件设备(特别是嵌入式产品),所以也有非常多的设备驱动。因此,Linux内核中将近一半的Source Code都是设备驱动,大多数的Linux底层工程师(特别是国内的企业)都是在编写或者维护设备驱动,而无暇估计其它内容(它们恰恰是Linux内核的精髓所在)。
- Device Independent Interface, 该模块定义了描述硬件设备的统一方式(统一设备模型),所有的设备驱动都遵守这个定义,可以降低开发的难度。同时可以用一致的形势向上提供接口。
- Logical Systems,每一种文件系统,都会对应一个Logical System(逻辑文件系统),它会实现具体的文件系统逻辑。
- System Independent Interface,该模块负责以统一的接口(快设备和字符设备)表示硬件设备和逻辑文件系统,这样上层软件就不再关心具体的硬件形态了。
- System Call Interface,系统调用接口,向用户空间提供访问文件系统和硬件设备的统一的接口。
网络子系统(Net)
网络子系统在Linux内核中主要负责管理各种网络设备,并实现各种网络协议栈,最终实现通过网络连接其它系统的功能。在Linux内核中,网络子系统几乎是自成体系,它包括5个子模块(见下图),它们的功能如下:
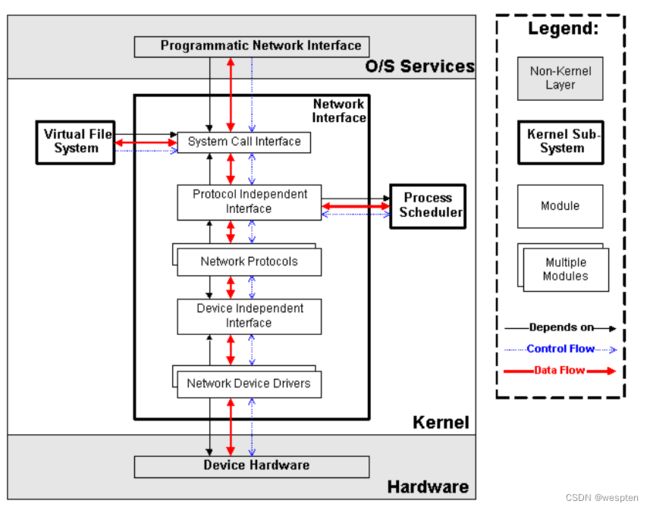
- Network Device Drivers,网络设备的驱动,和VFS子系统中的设备驱动是一样的。
- Device Independent Interface,和VFS子系统中的是一样的。
- Network Protocols,实现各种网络传输协议,例如IP, TCP, UDP等等。
- Protocol Independent Interface,屏蔽不同的硬件设备和网络协议,以相同的格式提供接口(socket)。
- System Call interface,系统调用接口,向用户空间提供访问网络设备的统一的接口。
IPC子系统,请参考:
Linux进程管理和计划任务与系统备份恢复_wespten的博客-CSDN博客
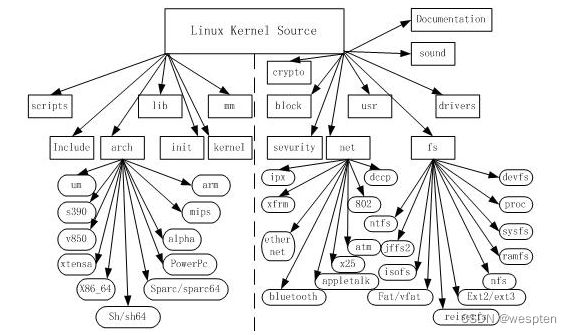
3、Linux内核源代码的目录结构
Linux内核源代码包括三个主要部分:
1. 内核核心代码,包括各个子系统和子模块,以及其它的支撑子系统,例如电源管理、Linux初始化等
2. 其它非核心代码,例如库文件(因为Linux内核是一个自包含的内核,即内核不依赖其它的任何软件,自己就可以编译通过)、固件集合、KVM(虚拟机技术)等
3. 编译脚本、配置文件、帮助文档、版权说明等辅助性文件
下面内核目录以linux-3.14内核作为讲解:
1. documentation:
提供文档帮助。关于内核的一些说明信息,在这个目录下会有帮助手册。
比如linux-3.14-fs4412/Documentation/devicetree/bindings/interrupt-controller/interrupts.txt
该文件讲解了关于设备数节点 中断设备interrupts属性的cell的详细说明。
只要根据文件夹名字,便可查找到我们所需的说明文档。
2. arch:
arch是architecture的缩写。所有与体系结构相关的代码都在这个目录以
include/asm-*/目录中。Linux支持的每种体系结构在arch目录下都有对应的目录,又进一
步分解为boot,mm,kernel等子目录:
|--arm arm及与之相兼容体系结构的子目录
|--boot 引导程序,以及在这种硬件平台上启动内核所使用的内存管理程序的实现。
|--compressed 内核解压缩
|--tools 生成压缩内核映像的程序
| --kernel: 存放支持体系结构特有的诸如信号量处理和SMP之类特征的实现。
| --lib: 存放体系结构特有的对诸如strlen和memcpy之类的通用函数的实现。
| --mm: 存放体系结构特有的内存管理程序的实现。
除了这3个子目录以外,大多数体系结构在必要的情况下还有一个boot子目录,包括了在这种硬件平台上启动内核所使用的内存管理程序的实现。
3. drivers:
驱动代码,驱动是一个控制硬件的软件。这个目录是内核中最庞大的一个目录,显卡、网卡、SCSI适配器、PCI总线、USB总线和其他任何Linux支持的外围设备或总线的驱动程序都可以在这儿找到。
4. fs:
虚拟文件系统(VFS)的代码,和各个不同文件系统的代码都在这个目录中。Linux支持的所有文件系统在fs目录下面都有一个对应的子目录。比如ext2文件系统对应的是fs/ext2目录。
一个文件系统是存储设备和需要访问存储设备的进程之间的媒介。存储设备可能是本地的物理上可以访问的,比如硬盘或者CD-ROM驱动器,他们分别使用而系统ext2/ext3和isofs文件系统。
还有一些虚拟文件系统(proc),它是一个标准文件系统出现。然而,他其中的文件只存在于内存中,并不占磁盘空间。
5. include:
这个目录包含了内核中大部分的头文件,它按照下面的子目录进行分组。要修改处理器结构则只需编辑核心的makefile并重新运行Linux核心配置程序。
| include/asm-*/ 每一个对应着一个arch的子目录,比如include/asm-alpha、
Include/asm-arm等。每个子目录中的文件都定义了支持给定体系结构所必要的预处理函数和内联函数,这些内联函数多数都是全部或者部分的汇编语言实现。
| include/linux 与平台无关的头文件都在这个目录下,它通常会被链接到目录
/usr/include/linux(或者它里面的所有文件都会被复制到/usrinclude/linux目录下边)
6. init:
内核的初始化代码。包括main.c、创建早起用户空间的代码及其他初始化代码。
7. ipc:
IPC(进程间通信)。它包含了共享内存、信号量及其他形式的IPC代码。
8. kernel:
内核中最核心的部分,包括进程的调度(sched.c),以及进程的创建和撤销(fork.c和exit.c)和平台相关的另外一部分核心代码在arch/*/kernel目录下。
9. mm
此目录包含了与体系无关的部分内存管理代码。与体系结构相关的内存管理代码位于arch/*/mm下。
10. net
核心的网络部分代码,实现了各种常见的网络协议,入TCP/IP、IPX等。
11. lib
此目录包含了核心的库代码。实现了一个标准C库的通用子集,包括字符串和内存操作的函数(strlen、mmcpy等)以及有关sprintf和atoi系列函数。与arch/lib下的代码不同,这里的库代码都是C编写的,在内核新的移植版本中可以直接使用。与处理器结构相关库代码被放在arch/mm中。
12. block:
块设备驱动包括IDE(在ide.c中)驱动。块设备是以数据块方式接收和发送的数据的设备。最初block层代码一部分位于drivers目录,一部分位于fs目录。从2.6.15开始,block层的核心代码就被提取出来放在顶层的block目录中。如果你想寻找这些可包含文件系统的设备的初始化过程则应该在drivers/block/genhd.c中的device_setup()。当安装一个nfs文件系统时不但要初始化硬盘还需初始化网络。块设备包括IDE与SCSI设备。
13. firmware
fireware中包含了让计算机读取和理解从设备发来的信号的代码。举例来说,一个摄像头管理它自己的硬件,但计算机必须了解摄像头给计算机发送的信号。Linux系统会使用vicam固件(firmware)来理解摄像头的通讯。否则,没有了固件,Linux系统将不知道如何处理摄像头发来的信息。另外,固件同样有助于将Linux系统发送消息给该设备。这样Linux系统可以告诉摄像头重新调整或关闭摄像头。
13. usr:
实现用于打包和压缩的cpio等。这个文件夹中的代码在内核编译完成后创建这些文件。
14. securtity:
这个目录下包含了不同的Linux安全模型的代码。它对计算机免于受到病毒和黑客的侵害很重要。否则,Linux系统可能会遭到损坏。
15. crypto:
内核本身所用的加密API,实现了常用的加密和散列算法,还有一些压缩和CRC校验算法。例:“sha1_generic.c”这个文件包含了SHA1加密算法的代码。
16. scripts:
该目录下没有内核代码,只是包含了用来配置内核的脚本文件。当运行make menuconfig或者make xconfig之类的命令配置内核时,用户就是和位于这个目录下的脚本进行交互的。
17. sound:
声卡驱动以及其他声音相关的源码。
18. samples
一些内核编程的范例
19. virt
此文件夹包含了虚拟化代码,它允许用户一次运行多个操作系统。通过虚拟化,客户机操作系统就像任何其他运行在Linux主机的应用程序一样运行。
20. tools
这个文件夹中包含了和内核交互的工具。
COPYING:许可和授权信息。Linux内核在GPLv2许可证下授权。该许可证授予任何人有权免费去使用、修改、分发和共享源代码和编译代码。然而,没有人可以出售源代码。
CREDITS : 贡献者列表
Kbuild : 这是一个设置一些内核设定的脚本。打个比方,这个脚本设定一个ARCH变量,这是开发者想要生成的内核支持的处理器类型。
Kconfig: 这个脚本会在开发人员配置内核的时候用到
MAINTAINERS : 这是一个目前维护者列表,他们的电子邮件地址,主页,和他们负责开发和维护的内核的特定部分或文件。当一个开发者在内核中发现一个问题,并希望能够报告给能够处理这个问题的维护者时,这是是很有用的。
Makefile :这个脚本是编译内核的主要文件。这个文件将编译参数和编译所需的文件和必要的信息传给编译器。
README : 这个文档提供给开发者想要知道的如何编译内核的信息。
REPORTING-BUGS : 这个文档提供如何报告问题的信息。
内核的代码是以“.c”或“.h”为扩展名的文件。 “.c”的扩展名表明内核是用众多的编程语言之一的C语言写的, “h”的文件是头文件,而他们也是用C写成。头文件包含了许多“.c”文件需要使用的代码,因为他们可以引入已有的代码而不是重新编写代码,这节省了程序员的时间。否则,一组执行相同的动作的代码,将存在许多或全部都是“c”文件。这也会消耗和浪费硬盘空间。(译注:头文件不仅仅可节省重复编码,而且代码复用也会降低代码错误的几率)
Linux内核整体架构总结:
Linux内核体系结构:

(1)系统调用接口
SCI 层提供了某些机制执行从用户空间到内核的函数调用。正如前面讨论的一样,这个接口依赖于体系结构,甚至在相同的处理器家族内也是如此。SCI 实际上是一个非常有用的函数调用多路复用和多路分解服务。在 ./linux/kernel 中您可以找到 SCI 的实现,并在 ./linux/arch 中找到依赖于体系结构的部分。
(2)进程管理
进程管理的重点是进程的执行。在内核中,这些进程称为线程,代表了单独的处理器虚拟化(线程代码、数据、堆栈和 CPU 寄存器)。在用户空间,通常使用进程 这个术语,不过 Linux 实现并没有区分这两个概念(进程和线程)。内核通过 SCI 提供了一个应用程序编程接口(API)来创建一个新进程(fork、exec 或 Portable Operating System Interface [POSIX] 函数),停止进程(kill、exit),并在它们之间进行通信和同步(signal 或者 POSIX 机制)。
进程管理还包括处理活动进程之间共享 CPU 的需求。内核实现了一种新型的调度算法,不管有多少个线程在竞争 CPU,这种算法都可以在固定时间内进行操作。这种算法就称为 O(1) 调度程序,这个名字就表示它调度多个线程所使用的时间和调度一个线程所使用的时间是相同的。O(1) 调度程序也可以支持多处理器(称为对称多处理器或 SMP)。您可以在 ./linux/kernel 中找到进程管理的源代码,在 ./linux/arch 中可以找到依赖于体系结构的源代码。
(3)内存管理
内核所管理的另外一个重要资源是内存。为了提高效率,如果由硬件管理虚拟内存,内存是按照所谓的内存页 方式进行管理的(对于大部分体系结构来说都是 4KB)。Linux 包括了管理可用内存的方式,以及物理和虚拟映射所使用的硬件机制。不过内存管理要管理的可不止 4KB 缓冲区。Linux 提供了对 4KB 缓冲区的抽象,例如 slab 分配器。这种内存管理模式使用 4KB 缓冲区为基数,然后从中分配结构,并跟踪内存页使用情况,比如哪些内存页是满的,哪些页面没有完全使用,哪些页面为空。这样就允许该模式根据系统需要来动态调整内存使用。为了支持多个用户使用内存,有时会出现可用内存被消耗光的情况。由于这个原因,页面可以移出内存并放入磁盘中。这个过程称为交换,因为页面会被从内存交换到硬盘上。内存管理的源代码可以在 ./linux/mm 中找到。
(4)虚拟文件系统
虚拟文件系统(VFS)是 Linux 内核中非常有用的一个方面,因为它为文件系统提供了一个通用的接口抽象。VFS 在 SCI 和内核所支持的文件系统之间提供了一个交换层。
文件系统层次结构:
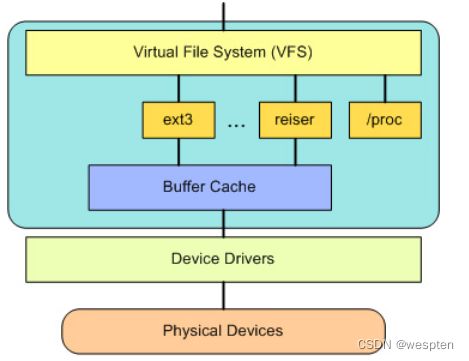
在 VFS 上面,是对诸如 open、close、read 和 write 之类的函数的一个通用 API 抽象。在 VFS 下面是文件系统抽象,它定义了上层函数的实现方式。它们是给定文件系统(超过 50 个)的插件。文件系统的源代码可以在 ./linux/fs 中找到。文件系统层之下是缓冲区缓存,它为文件系统层提供了一个通用函数集(与具体文件系统无关)。这个缓存层通过将数据保留一段时间(或者随即预先读取数据以便在需要时就可用)优化了对物理设备的访问。缓冲区缓存之下是设备驱动程序,它实现了特定物理设备的接口。
(5)网络堆栈
网络堆栈在设计上遵循模拟协议本身的分层体系结构。回想一下,Internet Protocol (IP) 是传输协议(通常称为传输控制协议或 TCP)下面的核心网络层协议。TCP 上面是 socket 层,它是通过 SCI 进行调用的。socket 层是网络子系统的标准 API,它为各种网络协议提供了一个用户接口。从原始帧访问到 IP 协议数据单元(PDU),再到 TCP 和 User Datagram Protocol (UDP),socket 层提供了一种标准化的方法来管理连接,并在各个终点之间移动数据。内核中网络源代码可以在 ./linux/net 中找到。
(6)设备驱动程序
Linux 内核中有大量代码都在设备驱动程序中,它们能够运转特定的硬件设备。Linux 源码树提供了一个驱动程序子目录,这个目录又进一步划分为各种支持设备,例如 Bluetooth、I2C、serial 等。设备驱动程序的代码可以在 ./linux/drivers 中找到。
(7)依赖体系结构的代码
尽管 Linux 很大程度上独立于所运行的体系结构,但是有些元素则必须考虑体系结构才能正常操作并实现更高效率。./linux/arch 子目录定义了内核源代码中依赖于体系结构的部分,其中包含了各种特定于体系结构的子目录(共同组成了 BSP)。对于一个典型的桌面系统来说,使用的是 x86 目录。每个体系结构子目录都包含了很多其他子目录,每个子目录都关注内核中的一个特定方面,例如引导、内核、内存管理等。这些依赖体系结构的代码可以在 ./linux/arch 中找到。
如果 Linux 内核的可移植性和效率还不够好,Linux 还提供了其他一些特性,它们无法划分到上面的分类中。作为一个生产操作系统和开源软件,Linux 是测试新协议及其增强的良好平台。Linux 支持大量网络协议,包括典型的 TCP/IP,以及高速网络的扩展(大于 1 Gigabit Ethernet [GbE] 和 10 GbE)。Linux 也可以支持诸如流控制传输协议(SCTP)之类的协议,它提供了很多比 TCP 更高级的特性(是传输层协议的接替者)。
Linux 还是一个动态内核,支持动态添加或删除软件组件。被称为动态可加载内核模块,它们可以在引导时根据需要(当前特定设备需要这个模块)或在任何时候由用户插入。
Linux 最新的一个增强是可以用作其他操作系统的操作系统(称为系统管理程序)。最近,对内核进行了修改,称为基于内核的虚拟机(KVM)。这个修改为用户空间启用了一个新的接口,它可以允许其他操作系统在启用了 KVM 的内核之上运行。除了运行 Linux 的其他实例之外, Microsoft Windows也可以进行虚拟化。惟一的限制是底层处理器必须支持新的虚拟化指令。
四、内核整体架构设计
1、内核机制
将各个功能做成不同的内核子系统,若子系统要通信,则必须设计一种机制可以让子系统彼此间通信时是安全可靠且高效的。
linux在一步步的发展中吸取了微内核的设计经验,虽然是单内核,但是兼具微内核的特性。
linux通过使用模块化内核设计来兼具微内核特性,但这样的模块化设化设计并不是像微内核一样是各个子系统,而是由核心加外围的功能性模块组成内核。而微内核子系统都是各自独立运行的,不需要依赖其他部分就能工作,而linux各模块必许依赖核心,只是能在使用时进行装载,不用时被动态卸载。linux下的模块外在表现为类型程序的库文件,只是程序库文件为.so,而内核模块为.ko(kernel object),被内核调用。
假设,如果驱动是内核提供的,想象下,编译好一个内核,装在主机上,万一后来发现他无法驱动我们后来新添加的新硬件设备。由于各种硬件都是由内核驱动的,内核没有提供这个程序,是不是得重新编译内核,这对用户和厂商来说是非常麻烦的一件事。
模块化设计得以避免这种情况,各厂商以模块化的形式开发自己的驱动,只需针对某一特定设备开发自己驱动程序的即可。
Linux内核开发人员所做的一件事就是使内核模块可以在运行时加载和卸载,这意味着您可以动态地添加或删除内核的特性。这不仅可以向内核添加硬件功能,还可以包括运行服务器进程的模块,比如低级别虚拟化,但也可以替换整个内核,而不需要在某些情况下重启计算机。
需要时我们编译这些模块即可,不需要某一功能时,可自行拆卸,并不影响核心的运行。想象一下,如果您可以升级到Windows服务包,而不需要重新启动,这就是模块化的好处和优势之一。
1)CPU工作机制
CPU工作模式
现代CPU通常都实现了不同的工作模式,以ARM为例:ARM实现了7种工作模式,不同模式下CPU可以执行的指令或者访问的寄存器不同:
(1)用户模式 usr
(2)系统模式 sys
(3)管理模式 svc
(4)快速中断 fiq
(5)外部中断 irq
(6)数据访问终止 abt
(7)未定义指令异常
以(2)X86为例:X86实现了4个不同级别的权限,Ring0—Ring3 ;Ring0下可以执行特权指令,可以访问IO设备;Ring3则有很多的限制
所以,Linux从CPU的角度出发,为了保护内核的安全,把系统分成了用户空间和内核空间。
用户空间和内核空间是程序执行的两种不同状态,我们可以通过“系统调用”和“硬件中断“来完成用户空间到内核空间的转移。
应用程序运行在内核上,只是逻辑上的情况。但实际是直接工作在硬件上的,任意应用程序数据都在内存中,数据处理都是CPU,只是他们不能随意使用而已,要接受内核的管理。
但CPU只有一颗,应用程序工作的时候,内核就暂停了,应用程序也在内存空间中,一旦应用程序想要访问其他硬件资源时,即要执行I/O指令时,但却不能执行。因为应用程序看不见硬件,应用程序是基于系统调用的程序,当应用程序需要访问硬件资源时时,就向CPU发起特权请求,一旦CPU收到特权请求,CPU就会唤醒内核,从而执行内核中的某段代码(非完整的内核程序),然后将结果返回给应用程序,而后内核代码退出,内核程序暂停。
在这期间CPU就从用户模式转换成了内核模式,内核模式就好似能够执行特权的模式。
所有的应用程序时在硬件上直接执行的,只是在必要时接受内核的管理和监控,故内核也是监控器,监控程序,是资源和进程的监控程序。
内核没有生产力,生产力是由个被调用的应用程序产生,故我们应该尽量让系统运行在应用程序模式中,故内核占据的时间越少越好。而内核主要在进程切换、中断处理等相关功能上,占据时间,模式切换到目的也是为了生产完成,但进程切换与生产就没有任何意义了,中断处理可以认为与生产本身相关,因为应用要执行I/O。
内核的主要目的是完成硬件管理,而linux中有一个思想,各进程都是由其父进程衍生的,由父进程fork()而来的,那么由谁来fork()以及管理这些进程,于是有了大管家程序init,统筹管理用户空间的所有进程。
用户空间的管理工作都不会由内核执行,故我们启动完内核之后,要想启动用户空间首先需要启动init,故init的PID号永远为1。 init也是由其父进程fork()而来,是内核空间中的用来专门引导用户空间进程的机制。init是一个应用程序,在/sbin/init下,是一个可执行文件。
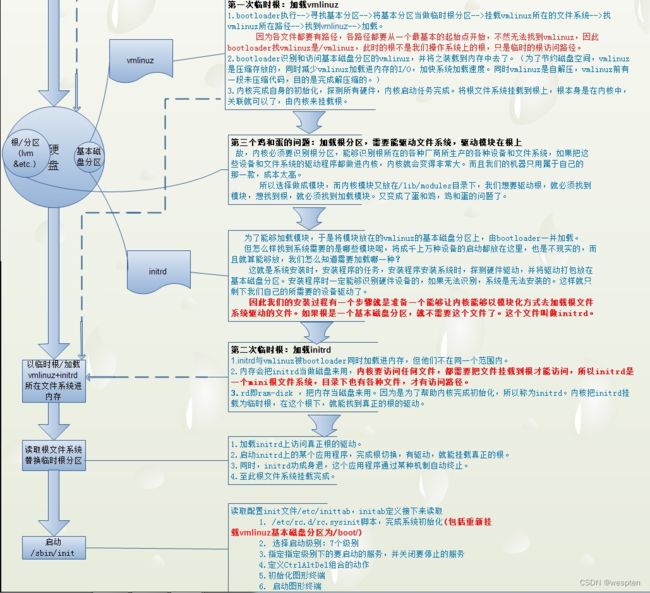
CPU的时间
因为内存中每一个进程都直接是独占CPU的,故内核即是将CPU虚拟化,提供给进程,CPU在内核级别就已经虚拟化了,通过将CPU切成时间片,随着时间流逝而完成在个进程之间分派计算能力的,CPU是以时间提供其计算能力的。
在单位时间内要能够提供的计算能力越大,必须速度越快,否则只能延长时间。这也就是我们需要更快的CPU,以节约时间。
CPU的运算特性
I/O是最慢的设备,我们CPU有大量时间都拿来等待I/O完成,为避免空余的没有任何意义的等待,需要等待时,就让CPU运行别的进程或线程。
我们应该最大能力榨取CPU的计算能力,因为CPU的计算能力是随着时间时钟频率的振荡器在震荡,你用或者不用他都在跑。
如果你让CPU空闲着,他依然耗电,而且随时间流逝,计算能力白白消逝了,因此能够让CPU工作在80-90%的利用率下,这就意味着他的生产能力得到了充分的发挥。CPU是用不坏的,没有什么磨损很消耗,是电器设备,除了功率大是发热量大,散热足够就好了,对于电器设备而言不用反而会坏。
Linux内核中9种同步机制
Linux经常使用散列表来实现高速缓存(Cache),高速缓存是需要快速访问的信息。
在操作系统引入了进程概念,进程成为调度实体后,系统就具备了并发执行多个进程的能力,但也导致了系统中各个进程之间的资源竞争和共享。
另外,由于中断、异常机制的引入,以及内核态抢占都导致了这些内核执行路径(进程)以交错的方式运行。对于这些交错路径执行的内核路径,如不采取必要的同步措施,将会对一些关键数据结构进行交错访问和修改,从而导致这些数据结构状态的不一致,进而导致系统崩溃。因此,为了确保系统高效稳定有序地运行,linux必须要采用同步机制。
在linux系统中,我们把对共享的资源进行访问的代码片段称为临界区。把导致出现多个进程对同一共享资源进行访问的原因称为并发源。
Linux系统下并发的主要来源有:
中断处理:例如,当进程在访问某个临界资源的时候发生了中断,随后进入中断处理程序,如果在中断处理程序中,也访问了该临界资源。虽然不是严格意义上的并发,但是也会造成了对该资源的竞态。
内核态抢占:例如,当进程在访问某个临界资源的时候发生内核态抢占,随后进入了高优先级的进程,如果该进程也访问了同一临界资源,那么就会造成进程与进程之间的并发。
多处理器的并发:多处理器系统上的进程与进程之间是严格意义上的并发,每个处理器都可以独自调度运行一个进程,在同一时刻有多个进程在同时运行 。
如前所述可知:采用同步机制的目的就是避免多个进程并发并发访问同一临界资源。
9种同步机制:
1)每CPU变量
主要形式是数据结构的数组,系统中的每个CPU对应数组的一个元素。
使用情况:数据应在逻辑上是独立的
使用原则:应在内核控制路径禁用抢占的情况下访问每CPU变量。
2)原子操作
原理:是借助于汇编语言指令中对“读--修改--写”具有原子性的汇编指令来实现。
3)内存屏障
原理:使用内存屏障原语确保在原语之后的操作开始之前,原语之前的操作已经完成。
4)自旋锁
主要用于多处理器环境中。
原理:如果一个内核控制路径发现所请求的自旋锁已经由运行在另一个CPU上的内核控制路径“锁着”,就反复执行一条循环指令,直到锁被释放。
说明:自旋锁一般用于保护禁止内核抢占的临界区。
在单处理器上,自旋锁的作用仅是禁止或启用内核抢占功能。
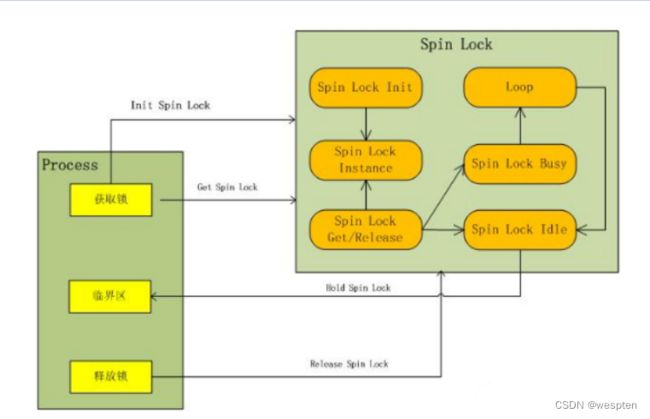
5)顺序锁
顺序锁与自旋锁非常相似,仅有一点不同,即顺序锁中的写者比读者有较高的优先级,也就意味着即使读者正在读的时候也允许写者继续运行。
6)RCU
主要用于保护被多个CPU读的数据结构。
允许多个读者和写者同时运行,且RCU是不用锁的。
使用限制:
1)RCU只保护被动态分配并通过指针引用的数据结构
2)在被RCU保护的临界区中,任何内核控制路径都不能睡眠。
原理:
当写者要更新数据时,它通过引用指针来复制整个数据结构的副本,然后对这个副本进行修改。修改完毕后,写者改变指向原数据结构的指针,使它指向被修改后的副本,(指针的修改是原子的)。
7)信号量:
原理: 当内核控制路径试图获取内核信号量所保护的忙资源时,相应的进程被挂起;只有在资源被释放时,进程才再次变为可运行。
使用限制:只有可以睡眠的函数才能获取内核信号量 ;
中断处理程序和可延迟函数都不能使用内核信号量。
8)本地中断禁止
原理:本地中断禁止可以保证即使硬件设备产生了一个IRQ信号时,内核控制路径也会继续运行,从而使中断处理例程访问的数据结构受到保护。
不足:禁止本地中断并不能限制运行在另一个CPU上的中断处理程序对共享数据结构的并发访问,
故在多处理器环境中,禁止本地中断需要与自旋锁一起使用。
9)本地软中断的禁止
方法1:
由于软中断是在硬件中断处理程序结束时开始运行的,所以最简单的方式是禁止那个CPU上的中断。
因为没有中断处理例程被激活,故软中断就没有机会运行。
方法2:
通过操纵当前thread_info描述符preempt_count字段中存放的软中断计数器,可以在本地CPU上激活或禁止软中断。因为内核有时只需要禁止软中断而不禁止中断。
2)内存机制
Linux的内存机制包括地址空间、物理内存、内存映射、分页机制及交换机制。
地址空间
虚存的优点之一是每个进程都认为自己拥有所需的全部地址空间。虚存的大小可以是系统中物理内存大小的许多倍。系统中的每个进程都有自己的虚址空间,这些虚址空间相互之间完全独立。运行某个应用程序的进程不会影响到其他进程,应用程序之间也是相互保护的。虚址空间由操作系统映射至物理内存。从应用程序的角度来说,这个地址空间是一个线性的平面地址空间;但内核对用户虚址空间的处理则有很大的不同。
线性地址空间被划分为两部分:用户地址空间和内核地址空间。用户地址空间不会在每次发生上下文切换时都改变,而内核地址空间则始终保持不变。为用户空间和内核空间分配的空间容量主要取决于系统是32位还是64位的体系结构。例如,x86是32位的体系结构,它只支持4GB的地址空间,其中3GB为用户空间保留,1GB分配给内核地址空间。具体的划分大小由内核配置变量PAGE_OFFSET决定。
物理内存
为了支持多种体系结构,Linux使用与体系结构无关的方式来描述物理内存。
物理内存可以组织成内存体(bank)的结构,每个内存体与处理器的距离都是特定的。随着越来越多的机器采用非一致性内存访问(Nonuniform Memory Access,NUMA)技术,这种类型的内存布局已非常普遍。Linux VM以节点来表示这种排列方式。每个节点划分为许多称为管理区(zone)的内存块,它们代表了内存中的地址范围。有三种不同的管理区:ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM。例如,x86具有以下内存管理区:
ZONE_DMA 内存地址的前16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB~内存结束地址
每个管理区都有各自的用途。从前的一些ISA设备对于可以在哪些地址上执行I/O操作具有限制条件,而ZONE_DMA可以消除这些限制。
ZONE_NORMAL用于所有的内核操作和分配。它对于系统性能是极为重要的。
ZONE_HIGHMEM是系统中其余的内存。需要注意的是,ZONE_HIGHMEM无法用于内核的分配和数据结构,只能用于保存用户数据。
内存映射
为了更好地理解内核内存的映射机制,下面以x86为例加以说明。前文提过,内核只有1GB的虚址空间可用,其他3GB保留给用户空间。内核将ZONE_DMA 和 ZONE_NORMAL中的物理内存直接映射到其地址空间。这意味着系统中最前面的896MB物理内存被映射到内核虚址空间,从而只剩下128MB的虚址空间。这128MB的虚址空间用于诸如vmalloc和kmap等操作。
如果物理内存容量较小(少于1GB),这种映射机制运作良好。然而,目前的所有服务器都支持数十千兆字节的内存。Intel公司在其Pentium处理器中引入了物理地址扩展(Physical Address Extension,PAE)机制,能够支持最多64GB物理内存。前述的内存映射机制使得如何处理高达数十千兆字节的物理内存成为x86 Linux的一个主要问题来源。Linux内核按照如下方式处理高端内存(896MB以上的所有内存):当Linux内核需要寻址高端内存中的某个页面时,通过kmap操作将该页面映射到一个小的虚址空间窗口中,在该页面上执行操作,然后解除对该页面的映射。64位体系结构的地址空间非常巨大,因此这类系统不存在这个问题。
分页机制
虚存可以有多种实现方式,其中最有效的方式是基于硬件的方案。虚址空间被划分成固定大小的内存块,称之为页面。虚存访问通过页表被转换成物理内存地址。为了支持各种体系结构和页面尺寸,Linux采用了三级分页机制。它提供了如下三种页表类型:
页面全局目录(Page Global Directory,PGD)
页面中层目录(Page Middle Directory,PMD)
页表(Page Table,PTE)
地址转换提供了一种将进程的虚址空间与物理地址空间分离的方法。每个虚存页面都可以在主内存中标记为“存在”或“不存在”。如果进程访问某个不存在的虚存地址,硬件就会产生一个页面错误,并由内核对其进行处理。内核处理该错误时将该页面置于主内存中。在这个过程中,系统可能需要将现有的某个页面替换掉,以便为新页面提供空间。
替换策略是分页系统最关键的内容之一。Linux 2.6版本修补了以前Linux版本中关于各种页面选择和替换的问题。
交换机制
交换是当主存容量不足时将整个进程移入或移出辅助存储器的过程。由于上下文切换的开销非常大,许多现代的操作系统,包括Linux,都不采用这种方法,而是采用分页机制。在Linux中,交换是在页面层次而不是在进程层次上执行的。交换的主要优点是扩展了进程可用的地址空间。当内核需要释放内存以便为新页面提供空间时,可能需要丢弃一些较少使用的或未用的页面。某些页面因为未被磁盘备份而不容易释放,需要被复制到后备存储器(交换区)中,在必要时还要从后备存储器中读回。交换机制的主要缺点是速度慢。磁盘的读写速度通常都非常缓慢,因此应该尽量消除交换操作。
3)进程机制
进程、任务与内核线程
任务只是一种“需要完成的工作的一般性描述”,可以是一个轻权的线程,也可以是一个完整的进程。
线程是最轻权的任务实例。在内核中创建线程的成本可能很高,也可能较低,这取决于线程需要拥有的特征。最简单的情形是线程与其父线程共享所有资源,包括代码、数据以及许多内部数据结构,而仅在区分该线程与其他线程上有一点点差异。
Linux中的进程是一个“重权的”数据结构。如果有必要的话,多个线程可以在单个进程中运行(并共享该进程的一些资源)。在Linux中,进程只是一个拥有全部重权特征的线程。线程和进程由调度器以相同方式进行调度。
内核线程是始终在内核模式中运行且没有用户上下文的线程。内核线程通常针对某个特定功能而存在,很容易在内核中处理它。内核线程经常具有所期望的作用:能够像其他任何进程一样进行调度;当其他进程需要该功能发挥作用时,为这些进程提供实现该功能的目标线程(通过发送信号)。
调度与上下文切换
进程调度是确保每个进程能公平分享CPU的一门科学(有人称之为艺术)。对于“公平”的定义,人们总是存在着不同的看法,因为调度器往往根据并不明显的可见的信息来做出选择。
需要注意的是,许多Linux用户都认为,一个在所有时候大部分正确的调度器要比一个在大多数时候完全正确的调度器更为重要,即缓慢运行的进程要优于因过于精心选择调度策略或错误而停止运行的进程。Linux当前的调度器程序就遵循了这个原则。
当一个进程停止运行,被另一个进程替换时,称为上下文切换。通常,这个操作的开销是很高的,内核程序员和应用程序员总是试图尽量减少系统执行上下文切换的数量。进程可以因为等待某个事件或资源而主动停止运行,或者因为系统决定应将CPU分配给另一个进程而被动地放弃运行。对于第一种情况,如果没有其他进程等待执行,CPU实际上可能进入空闲状态。在第二种情况下,该进程或者被另一个等待进程所替换,或者分配到一个新的运行时间片或时间周期继续执行。
即使在某个进程正按照有序的方式调度和执行时,也可以被其他更高优先级的任务中断。例如,假若磁盘为磁盘读操作准备好了数据后,就向CPU发送信号,并期望CPU从磁盘上获取数据。内核必须及时地处理这个情况,否则就会降低磁盘的传输率。信号、中断和异常是不同的异步事件,但在许多方面却类似,并且即使CPU已处于忙状态,它们也都必须被迅速处理。
例如,准备好了数据的磁盘会导致一个中断。内核调用该特定设备的中断处理程序,中断当前运行的进程并使用其众多资源。当中断处理程序执行结束后,当前运行的进程恢复执行。这实际上是侵占当前运行进程的CPU时间,因为当前版本的内核只测量自从该进程进入CPU之后所经过的时间,却忽略了中断会耗用该进程的宝贵时间这一事实。
中断处理程序通常是非常快速和简洁的,因而能够快速处理和清除以便使后续数据能够进入。但有时一个中断可能需要处理的工作比在中断处理程序中所期望的短时间内完成的工作更多。中断也需要一个定义良好的环境来完成其工作(要记住,中断利用了某个随机进程的资源)。在这种情况下,要收集足够信息,将工作延迟提交至bottom half处理程序进行处理。bottom half处理程序会不时地被调度执行。尽管在Linux早期版本中普遍使用了bottom half机制,但当前的Linux版本中不鼓励使用这种机制。
4)Linux驱动的platform机制
Linux的这种platform driver机制和传统的device_driver机制相比,一个十分明显的优势在于platform机制将本身的资源注册进内核,由内核统一管理,在驱动程序中使用这些资源时通过platform_device提供的标准接口进行申请并使用。这样提高了驱动和资源管理的独立性,并且拥有较好的可移植性和安全性。下面是SPI驱动层次示意图,Linux中的SPI总线可理解为SPI控制器引出的总线:
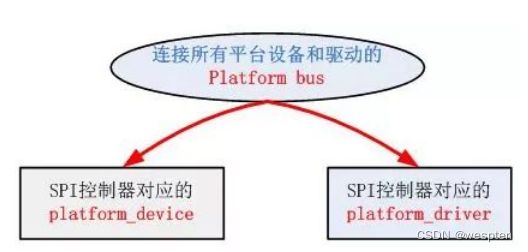
和传统的驱动一样,platform机制也分为三个步骤:
1、总线注册阶段:
内核启动初始化时的 main.c 文件中的 kernel_init()→do_basic_setup() →driver_init()→ platform_bus_init()→bus_register(&platform_bus_type) ,注册了一条 platform 总线(虚拟总线,platform_bus)。
2、添加设备阶段:
设备注册的时候 Platform_device_register()→platform_device_add()→ (pdev→dev.bus = &platform_bus_type)→device_add() ,就这样把设备给挂到虚拟的总线上。
3、驱动注册阶段:
Platform_driver_register() →driver_register() →bus_add_driver() →driver_attach()→bus_for_each_dev(), 对在每个挂在虚拟的platform bus的设备作 __driver_attach()→driver_probe_device(),判断 drv→bus→match() 是否执行成功,此时通过指针执行 platform_match→strncmp(pdev→name , drv→name , BUS_ID_SIZE ),如果相符就调用really_probe(实际就是执行相应设备的 platform_driver→probe(platform_device) 。)开始真正的探测,如果probe成功,则绑定设备到该驱动。
从上面可以看出,platform机制最后还是调用了bus_register() , device_add() , driver_register()这三个关键的函数。
下面看几个结构体:
struct platform_device
(/include/linux/Platform_device.h)
{
const char * name;
int id;
struct device dev;
u32 num_resources;
struct resource * resource;
};Platform_device结构体描述了一个platform结构的设备,在其中包含了一般设备的结构体 struct device dev; 设备的资源结构体 struct resource * resource; 还有设备的名字const char * name。(注意,这个名字一定要和后面platform_driver.driver àname相同,原因会在后面说明。)
该结构体中最重要的就是resource结构,这也是之所以引入platform机制的原因。
struct resource
( /include/linux/ioport.h)
{
resource_size_t start;
resource_size_t end;
const char *name;
unsigned long flags;
struct resource *parent, *sibling, *child;
};其中 flags位表示该资源的类型,start和end分别表示该资源的起始地址和结束地址(/include/linux/Platform_device.h):
struct platform_driver
{
int (*probe)(struct platform_device *);
int (*remove)(struct platform_device *);
void (*shutdown)(struct platform_device *);
int (*suspend)(struct platform_device *, pm_message_t state);
int (*suspend_late)(struct platform_device *, pm_message_t state);
int (*resume_early)(struct platform_device *);
int (*resume)(struct platform_device *);
struct device_driver driver;
};
Platform_driverPlatform_driver结构体描述了一个platform结构的驱动。其中除了一些函数指针外,还有一个一般驱动的device_driver结构。
名字要一致的原因:
上面说的驱动在注册的时候会调用函数bus_for_each_dev(), 对在每个挂在虚拟的platform bus的设备作__driver_attach()→driver_probe_device() ,在此函数中会对dev和drv做初步的匹配,调用的是 drv->bus->match 所指向的函数。 platform_driver_register 函数中 drv-> driver.bus = &platform_bus_type ,所以 drv->bus->matc 就为platform_bus_type→match, 为platform_match 函数,该函数如下:
static int platform_match(struct device * dev, struct device_driver * drv)
{
struct platform_device *pdev = container_of(dev, struct platform_device, dev);
return (strncmp(pdev->name, drv->name, BUS_ID_SIZE) == 0);
}是比较dev和drv的name,相同则会进入really_probe()函数,从而进入自己写的probe函数做进一步的匹配。所以dev→name和driver→drv→name在初始化时一定要填一样的。
不同类型的驱动,其match函数是不一样的,这个platform的驱动,比较的是dev和drv的名字,还记得usb类驱动里的match吗?它比较的是Product ID和Vendor ID。
Platform机制的好处:
1、提供platform_bus_type类型的总线,把那些不是总线型的soc设备都添加到这条虚拟总线上。使得,总线——设备——驱动的模式可以得到普及。
2、提供platform_device和platform_driver类型的数据结构,将传统的device和driver数据结构嵌入其中,并且加入resource成员,以便于和Open Firmware这种动态传递设备资源的新型bootloader和kernel 接轨。
2、自己编写一个操作系统
跟各种应用程序一样,内核也是一种应用程序,只不过,这种应用程序是直接操作硬件的。内核直接面对的是硬件,调用的是硬件接口,是通过个硬件厂商和CPU厂商提供的指令集进行开发。开发应用程序则面对的是内核,系统调用,或库调用进行的,故简单得多。
为编写内核级的应用程序,又为了避免过于底层,固有很多库文件,可以让内核编译时使用。
内核是直接面向硬件的,故可用资源权限很大,但内核是工作在有限地址空间内的,就linux而言,32位系统上,线性地址空间中,内核只认为自己有1G的,虽然可以掌握4G,但是自己的运行只能使用1G,剩下的3G给其他应用程序。win是各2G。故我们开发内核时可用的内存空间很有限,尤其是开发驱动,要明白自己的可用空间很有限,故需高效。
内核的架构也非常清晰,从硬件层,硬件抽象层,内核基础模块(进程调度,内存管理,网络协议栈等)到应用层,这个基本上也是各类软硬件结合的系统架构的基础设计,例如物联网系统(从单片机,MCU等小型嵌入式系统,到智能家居,智慧社区甚至智慧城市)在接入端设备的可参考架构模型。
Linux最初是运行在PC机上的,使用的x86架构处理器相对来说比较强大,各类指令和模式也比较齐全。例如我们看到的用户态和内核态,在一般的小型嵌入式处理器上是没有的,它的好处是通过将代码和数据段(segment)给予不同的权限,保护内核态的代码和数据(包括硬件资源)必须通过类似系统调用(SysCall)的方式才能访问,确保内核的稳定。
编写操作系统的流程:
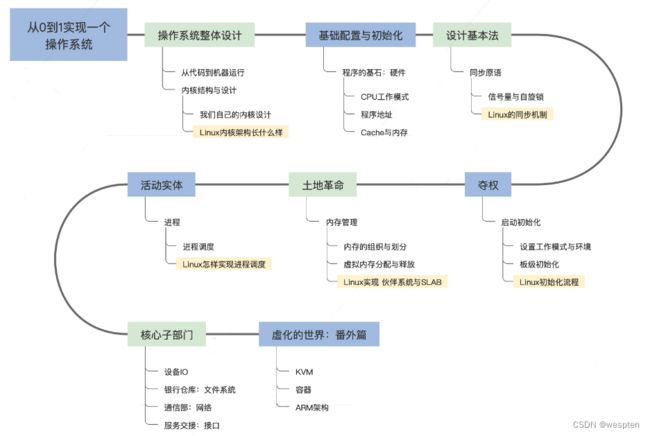
想象一下,如果需要你写一个操作系统,有哪些因素需要考虑?
进程管理:如何在多任务系统中按照调度算法分配CPU的时间片。
内存管理:如何实现虚拟内存和物理内存的映射,分配和回收内存。
文件系统:如何将硬盘的扇区组织成文件系统,实现文件的读写等操作。
设备管理:如何寻址,访问,读,写设备配置信息和数据。
进程管理
进程在不同的操作系统中有些称为process,有些称为task。操作系统中进程数据结构包含了很多元素,往往用链表连接。
进程相关的内容主要包括:虚拟地址空间,优先级,生命周期(阻塞,就绪,运行等),占有的资源(例如信号量,文件等)。
CPU在每个系统滴答(Tick)中断产生的时候检查就绪队列里面的进程(遍历链表中的进程结构体),如有符合调度算法的新进程需要切换,保存当前运行的进程的信息(包括栈信息等)后挂起当前进程,选择新的进程运行,这就是进程调度。
进程的优先级差异是CPU调度的基本依据,调度的终极目标是让高优先级的活动能够即时得到CPU的计算资源(即时响应),低优先级的任务也能公平分配到CPU资源。因为需要保存进程运行的上下文(process context)等,进程的切换本身是有成本的,调度算法在进程切换频率上也需要考虑效率。
在早期的Linux操作系统中,主要采用的是时间片轮转算法(Round-Robin),内核在就绪的进程队列中选择高优先级的进程运行,每次运行相等的时间。该算法简单直观,但仍然会导致某些低优先级的进程长时间无法得到调度。为了提高调度的公平性,在Linux 2.6.23之后,引入了称为完全公平调度器CFS(Completely Fair Scheduler)。
CPU在任何时间点只能运行一个程序,用户在使用优酷APP看视频时,同时在微信中打字聊天,优酷和微信是两个不同的程序,为什么看起来像是在同时运行?CFS的目标就是让所有的程序看起来都是以相同的速度在多个并行的CPU上运行,即nr_running 个运行的进程,每个进程以1/nr_running的速度并发执行,例如如有2个可运行的任务,那么每个以50%的CPU物理能力并发执行。
CFS引入了"虚拟运行时间"的概念,虚拟运行时间用p->se.vruntime (nanosec-unit) 表示,通过它记录和度量任务应该获得的"CPU时间"。在理想的调度情况下,任何时候所有的任务都应该有相同的p->se.vruntime值(上面提到的以相同的速度运行)。因为每个任务都是并发执行的,没有任务会超过理想状态下应该占有的CPU时间。CFS选择需要运行的任务的逻辑基于p->se.vruntime值,非常简单:它总是挑选p->se.vruntime值最小的任务运行(最少被调度到的任务)。
CFS使用了基于时间排序的红黑树来为将来任务的执行排时间线。所有的任务按p->se.vruntime关键字排序。CFS从树中选择最左边的任务执行。随着系统运行,执行过的任务会被放到树的右边,逐步地地让每个任务都有机会成为最左边的任务,从而在一个可确定的时间内获得CPU资源。
总结来说,CFS首先运行一个任务,当任务切换(或者Tick中断发生的时候)时,该任务使用的CPU时间会加到p->se.vruntime里,当p->se.vruntime的值逐渐增大到别的任务变成了红黑树最左边的任务时(同时在该任务和最左边任务间增加一个小的粒度距离,防止过度切换任务,影响性能),最左边的任务被选中执行,当前的任务被抢占。

CFS红黑树
一般来说,调度器处理单个任务,且尽可能为每个任务提供公平的CPU时间。某些时候,可能需要将任务分组,并为每个组提供公平的CPU时间。例如,系统可以为每个用户分配平均的CPU时间后,再为每个用户的每个任务分配平均的CPU时间。
内存管理
内存本身是一个外部存储设备,系统需要对内存区域寻址,找到对应的内存单元(memory cell),读写其中的数据。
内存区域通过指针寻址,CPU的字节长度(32bit机器,64bit机器)决定了最大的可寻址地址空间。在32位机器上最大的寻址空间是4GBtyes。在64位机器上理论上有2^64Bytes。
最大的地址空间和实际系统有多少物理内存无关,所以称为虚拟地址空间。对系统中所有的进程来说,看起来每个进程都独立占有这个地址空间,且它无法感知其它进程的内存空间。事实上操作系统让应用程序无需关注其它应用程序,看起来每个任务都是这个电脑上运行的唯一进程。
Linux将虚拟地址空间分为内核空间和用户空间。每个用户进程的虚拟空间范围从0到TASK_SIZE。从TASK_SIZE到2^32或2^64的区域保留给内核,不能被用户进程访问。TASK_SIZE可以配置,Linux系统默认配置3:1,应用程序使用3GB的空间,内核使用1GB的空间,这个划分并不依赖实际RAM的大小。在64位机器上,虚拟地址空间的范围可以非常大,但实际上只使用其中42位或47位(2^42 或 2^47)。

虚拟地址空间
绝大多数情况下,虚拟地址空间比实际系统可用的物理内存(RAM)大,内核和CPU必须考虑如何将实际可用的物理内存映射到虚拟地址空间。
一个方法是通过页表(Page Table)将虚拟地址映射到物理地址。虚拟地址与进程使用的用户&内核地址相关,物理地址用来寻址实际使用的RAM。
如下图所示,进程A和B的虚拟地址空间被分为大小相等的部分,称为页(page)。物理内存同样被分割为大小相等的页(page frame)。
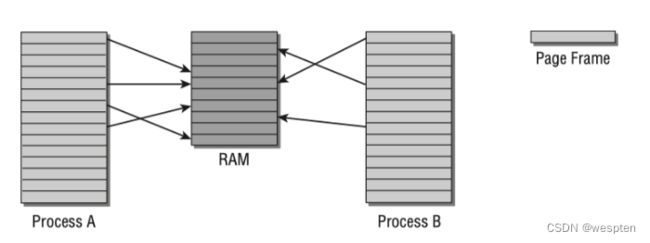
虚拟和物理地址空间映射
进程A第1个内存页映射到物理内存(RAM)的第4页;进程B第1个内存页映射到物理内存第5页。进程A第5个内存页和进程B第1个内存页都映射到物理内存的第5页(内核可决定哪些内存空间被不同进程共享)。
如图所示,并不是每个虚拟地址空间的页都与某个page frame关联,该页可能并未使用或者数据还没有被加载到物理内存(暂时不需要),也可能因为物理内存页被置换到了硬盘上,后续实际再需要的时候再被置换回内存。
页表(page table)将虚拟地址空间映射到物理地址空间。最简单的做法是用一个数组将虚拟页和物理页一一对应,但是这样做可能需要消耗整个RAM本身来保存这个页表,假设每个页大小为4KB,虚拟地址空间大小为4GB,需要一个1百万个元素的数组来保存页表。
因为虚拟地址空间的绝大多数区域实际并没有使用,这些页实际并没有和page frame关联,引入多级页表(multilevel paging)能极大降低页表使用的内存,提高查询效率。关于多级也表的细节描述可以参考xxx。
内存映射(memory mapping)是一个重要的抽象方法,被运用在内核和用户应用程序等多个地方。映射是将来自某个数据源的数据(也可以是某个设备的I/O端口等)转移到某个进程的虚拟内存空间。对映射的地址空间的操作可以使用处理普通内存的方法(对地址内容直接进行读写)。任何对内存的改动会自动转移到原数据源,例如将某个文件的内容映射到内存中,只需要通过读该内存来获取文件的内容,通过将改动写到该内存来修改文件的内容,内核确保任何改动都会自动体现到文件里。
另外,在内核中,实现设备驱动时,外设(外部设备)的输入和输出区域可以被映射到虚拟地址空间,读写这些空间会被系统重定向到设备,从而对设备进行操作,极大地简化了驱动的实现。
内核必须跟踪哪些物理页已经被分配了,哪些还是空闲的,避免两个进程使用RAM中的同一个区域。内存的分配和释放是非常频繁的任务,内核必须确保完成的速度尽量快,内核只能分配整个page frame,它将内存分为更小的部分的任务交给了用户空间,用户空间的程序库可以将从内核收到的page frame分成更小的区域后分配给进程。
虚拟文件系统
Unix系统是建立在一些有见地的理念上的,一个非常重要的隐喻是:
Everything is a file.
即系统几乎所有的资源都可以看成是文件。为了支持不同的本地文件系统,内核在用户进程和文件系统实现间包含了一层虚拟文件系统(Virtual File System)。大多数的内核提供的函数都能通过VFS(Virtual File System)定义的文件接口访问。例如内核子系统:字符和块设备,管道,网络Socket,交互输入输出终端等。
另外用于操作字符和块设备的设备文件是在/dev目录下的真实文件,当读写操作执行的时候,其的内容会被对应的设备驱动动态创建。
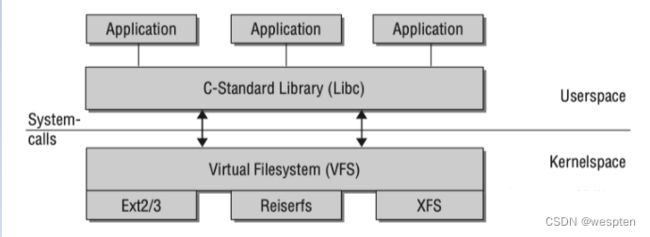
VFS系统
在虚拟文件系统中,inode用来表示文件和文件目录(对于系统来说,目录是一种特殊的文件)。inode的元素包含两类:1. Metadata用于描述文件的状态,例如读写权限。2. 用于保存文件内容的数据段。
每个inode都有一个特别的号码用于唯一识别,文件名和inode的关联建立在该编号基础上。以内核查找/usr/bin/emacs为例,讲解inodes如何组成文件系统的目录结构。从根inode开始查找(即根目录‘/’),该目录使用一个inode表示,inode的数据段没有普通的数据,只包含了根目录存的一些文件/目录项,这些项可以表示文件或其它目录,每项包含两个部分:1. 下一个数据项所在的inode编号 2. 文件或目录名
首先扫描根inode的数据区域直到找到一个名为‘usr’的项,查找子目录usr的inode。通过‘usr’ inode编号找到关联的inode。重复以上步骤,查找名为‘bin’的数据项,然后在其数据项的‘bin’对应的inode中搜索名字‘emacs’的数据项,最后返回的inode表示一个文件而不是一个目录。最后一个inode的文件内容不同于之前,前三个每个都表示了一个目录,包含了它的子目录和文件清单,和emacs文件关联的inode在它的数据段保存了文件的实际内容。
尽管在VFS查找某个文件的步骤和上面的描述一样,但细节上还是有些差别。例如因为频繁打开文件是一个很慢的操作,引入缓存加速查找。
通过inode机制查找某个文件:

设备驱动
与外设通信往往指的是输入(input)和输出(output)操作,简称I/O。实现外设的I/O内核必须处理三个任务:第一,必须针对不同的设备类型采用不同的方法来寻址硬件。第二,内核必须为用户应用程序和系统工具提供操作不同设备的方法,且需要使用一个统一的机制来确保尽量有限的编程工作,和保证即使硬件方法不同应用程序也能互相交互。第三,用户空间需要知道在内核中有哪些设备。
与外设通信的层级关系如下:
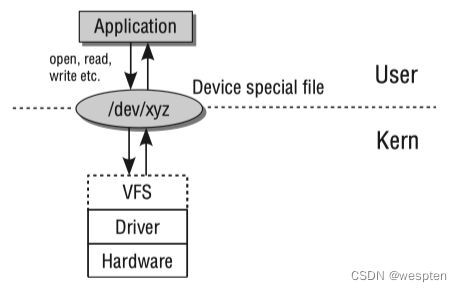
设备通信层级图
外部设备大多通过总线与CPU连接,系统往往不止一个总线,而是总线的集合。在很多PC设计中包含两个通过一个bridge相连的PCI总线。某些总线例如USB不能当作主总线使用,需要通过一个系统总线将数据传递给处理器。下图显示不同的总线是如何连接到系统的。
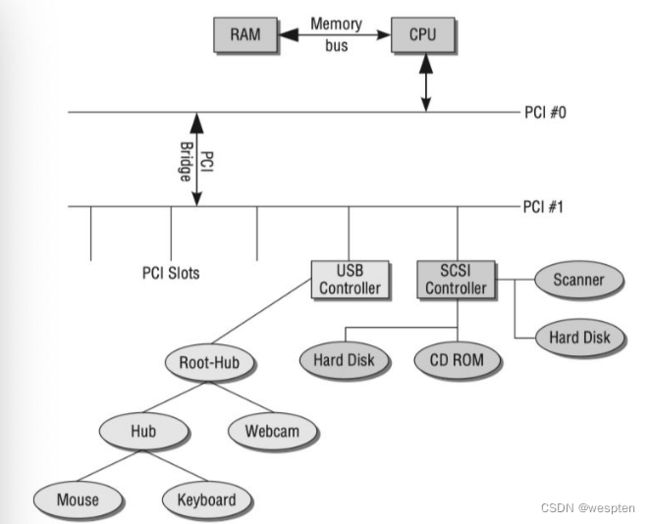
系统总线拓扑图
系统与外设交互主要有以下方式:
I/O端口:使用I/O端口通信的情况下,内核通过一个I/O控制器发送数据,每个接收设备有唯一的端口号,且将数据转发给系统附着的硬件。有一个由处理器管理的单独的虚拟地址空间用来管理所有的I/O地址。
I/O地址空间并不总是和普通的系统内存关联,考虑到端口能够映射到内存中,这往往不好理解。
端口有不同的类型。一些是只读的,一些是只写的,一般情况下它们是可以双向操作的,数据能够在处理器和外设间双向交换。
在IA-32架构体系中,端口的地址空间包含了2^16个不同的8位地址,这些地址可以通过从0x0到0xFFFFH间的数唯一识别。每个端口都有一个设备分配给它,或者空闲没有使用,多个外设不能共享一个端口。很多情况下,交换数据使用8位是不够用的,基于这个原因,可以将两个连续的8位端口绑定为一个16位的端口。两个连续的16位端口能够被当作一个32位的端口,处理器可以通过组装语句来做输入输出操作。
不同处理器类型在实现操作端口时有所不同,内核必须提供一个合适的抽象层,例如outb(写一个字节),outw(写一个字)和inb(读一个字节)这些命令可以用来操作端口。
I/O内存映射:必须能够像访问RAM内存一样寻址许多设备。因此处理器提供了将外设对应的I/O端口映射到内存中,这样就能像操作普通内存一样操作设备了。例如显卡使用这样的机制,PCI也往往通过映射的I/O地址寻址。
为了实现内存映射,I/O端口必须首先被映射到普通系统内存中(使用处理器特有的函数)。因为平台间的实现方式差异比较大,所以内核提供了一个抽象层来映射和去映射I/O区域。
除了如何访问外设,什么时候系统会知道是否外设有数据可以访问?主要通过两种方式:轮询和中断。
轮询周期性地访问查询设备是否有准备好的数据,如果有,便获取数据。这种方法需要处理器在设备没有数据的情况下也不断去访问设备,浪费了CPU时间片。
另一种方式是中断,它的理念是外设把某件事情做完了后,主动通知CPU,中断的优先级最高,会中断CPU的当前进程运行。每个CPU都提供了中断线(可被不同的设备共享),每个中断由唯一的中断号识别,内核为每个使用的中断提供一个服务方法(ISR,Interrupt Service Routine,即中断发生后,CPU调用的处理函数),中断本身也可以设置优先级。
中断会挂起普通的系统工作。当有数据已准备好可以给内核或者间接被一个应用程序使用的时候,外设出发一个中断。使用中断确保系统只有在外设需要处理器介入的时候才会通知处理器,有效提高了效率。
通过总线控制设备:不是所有的设备都是直接通过I/O语句寻址操作的,很多情况下是通过某个总线系统。
不是所有的设备类型都能直接挂接在所有的总线系统上,例如硬盘挂到SCSI接口上,但显卡不可以(显卡可以挂到PCI总线上)。硬盘必须通过IDE间接挂到PCI总线上。
总线类型可分为系统总线和扩展总线。硬件上的实现差别对内核来说并不重要,只有总线和它附着的外设如何被寻址才相关。对于系统总线来说,例如PCI总线,I/O语句和内存映射用来与总线通信,也用于和它附着的设备通信。内核还提供了一些命令供设备驱动来调用总线函数,例如访问可用的设备列表,使用统一的格式读写配置信息。
扩展总线例如USB,SCSI通过清晰定义的总线协议与附着的设备来交换数据和命令。内核通过I/O语句或内存映射来与总线通信,通过平台无关的函数来使总线与附着的设备通信。
与总线附着的设备通信不一定需要通过在内核空间的驱动进行,在某些情况下也可以通过用户空间实现。一个主要的例子是SCSI Writer,通过cdrecord工具来寻址。这个工具产生所需要的SCSI命令,在内核的帮助下通过SCSI总线将命令发送到对应的设备,处理和回复设备产生或返回的信息。
块设备(block)和字符设备(character)在3个方面显著不同:
块设备中的数据能够在任何点操作,而字符设备不能也没这个要求。
块设备数据传输的时候总是使用固定大小的块。即使只请求一个字节的情况下,设备驱动也总是从设备获取一个完整的块。相反,字符设备能够返回单个字节。
读写块设备会使用缓存。读操作方面,数据缓存在内存中,能够在需要的时候重新访问。写操作方面,也会被缓存,延时写入设备。使用缓存对于字符设备(例如键盘)来说不合理,每个读请求都必须被可靠地交互到设备。
块和扇区的概念:块是一个指定大小的字节序列,用于保存在内核和设备间传输的数据,块的大小可以被设置。扇区是固定大小的,能被设备传输的最小的数据量。块是一段连续的扇区,块大小是扇区的整数倍。
网络
Linux的网络子系统为互联网的发展提供了坚实的基础。网络模型基于ISO的OSI模型,如下图右半部分。但在具体应用中,往往会把相应层级结合以简化模型,下图左半部分为Linux运用的TCP/IP参考模型。(由于介绍Linux网络部分的资料比较多,在本文中只对大的层级简单介绍,不展开说明。)
Host-to-host层(Physical Layer和Data link layer,即物理层和数据链路层)负责将数据从一个计算机传输到另一台计算机。这一层处理物理传输介质的电气和编解码属性,也将数据流拆分成固定大小的数据帧用于传输。如多个电脑共享一个传输路线,网络适配器(网卡等)必须有一个唯一的ID(即MAC地址)来区分。从内核的角度,这一层是通过网卡的设备驱动实现的。
OSI模型的网络层在TCP/IP模型中称为网络层,网络层使网络中的计算机之间能交换数据,而这些计算机不一定是直接相连的。
如果物理上并没有直接相连,所以也没有直接的数据交换。网络层的任务是为网络中各机器之间通信找到路由。
网络连接的电脑
网络层也负责将要传输的包分成指定的大小,因为包在传输路径上每个电脑支持的最大的数据包大小可能不一样,在传输时,数据流被分割成不同的包,在接收端再被组合。
网络层为网络中的电脑分配了唯一的网络地址以便他们能互相通信(不同于硬件的MAC地址,因为网络往往由子网络组成)。在互联网中,网络层由IP网络组成,有V4和V6版本。
传输层的任务是规范在两个连接的电脑上运行的应用程序之间的数据传输。例如两台电脑上的客户端和服务端程序,包括TCP或UDP连接,通过端口号来识别通信的应用程序。例如端口号80用于web server,浏览器的客户端必须将请求发送到这个端口来获取需要的数据。而客户端也需要有一个唯一的端口号以便web server能将回复发送给它。
这一层还负责为数据的传输提供一个可靠的连接(TCP情况下)。
TCP/IP模型中的应用层在OSI模型中包含(session层,展现层,应用层)。当通信连接在两个应用之间建立起来后,这一层负责实际内容的传输。例如web server与它的客户端传输时的协议和数据,不同与mail server与它的客户端之间。
大多数的网络协议在RFC(Request for Comments)中定义。
网络实现分层模型:内核对网络层的实现类似TCP/IP参考模型。它是通过C代码实现的,每个层只能和它的上下层通信,这样的好处是可以将不同的协议和传输机制结合。如下图所示:

四、Linux内核模块详解
内核并不神奇,但对于任何正常运行的计算机来说,它都是必不可少的。Linux内核不同于OS X和Windows,因为它包含内核级别的驱动程序,并使许多东西“开箱即用”。
如果Windows已经安装了所有可用的驱动程序,而您只需要打开所需的驱动程序怎么办?这本质上就是内核模块为Linux所做的。内核模块,也称为可加载内核模块(LKM),对于保持内核在不消耗所有可用内存的情况下与所有硬件一起工作是必不可少的。

模块通常向基本内核添加设备、文件系统和系统调用等功能。lkm的文件扩展名是.ko,通常存储在/lib/modules目录中。由于模块的特性,您可以通过在启动时使用menuconfig命令将模块设置为load或not load,或者通过编辑/boot/config文件,或者使用modprobe命令动态地加载和卸载模块,轻松定制内核。
第三方和封闭源码模块在一些发行版中是可用的,比如Ubuntu,默认情况下可能无法安装,因为这些模块的源代码是不可用的。该软件的开发人员(即nVidia、ATI等)不提供源代码,而是构建自己的模块并编译所需的.ko文件以便分发。虽然这些模块像beer一样是免费的,但它们不像speech那样是免费的,因此不包括在一些发行版中,因为维护人员认为它通过提供非免费软件“污染”了内核。
使用模块的优点:
1. 使得内核更加紧凑和灵活
2. 修改内核时,不必全部重新编译整个内核,可节省不少时间,避免人工操作的错误。系统中如果 需要使用新模块,只要编译相应的模块然后使用特定用户空间的程序将模块插入即可。
3.模块可以不依赖于某个固定的硬件平台。
4. 模块的目标代码一旦被链接到内核,它的作用和静态链接的内核目标代码完全等价。 所以,当调用模块的函数时,无须显式的消息传递。
但是,内核模块的引入也带来一定的问题:
1. 由于内核所占用的内存是不会被换出的,所以链接进内核的模块会给整个系统带来一定的性能和内存利用方面的损失。
2. 装入内核的模块就成为内核的一部分,可以修改内核中的其他部分,因此,模块的使用不当会导致系统崩溃。
3. 为了让内核模块能访问所有内核资源,内核必须维护符号表,并在装入和卸载模块时修改符号表。
4. 模块会要求利用其它模块的功能,所以,内核要维护模块之间的依赖性。
模块是和内核在同样的地址空间运行的,模块编程在一定意义上说也就是内核编程。但是并不是内核中所有的地方都可以使用模块。 一般是在设备驱动程序、文件系统等地方使用模块,而对Linux内核中极为重要的地方,如进程管理和内存管理等,仍难以通过模块来实现,通常必须直接对内核进行修改。
在Linux内核源程序中,经常利用内核模块实现的功能,有文件系统,SCSI高级驱动程序,大多数的SCSI驱动程序,多数CD-ROM驱动程序,以太网驱动程序等等。
1、编译安装Linux内核
Linux内核的组成部分:
-
kernel:内核核心,一般为bzImage,通常在/boot目录
vmlinuz-VERSION-RELEASE -
kernel object:内核对象,一般放置于
/lib/modules/VERSION-RELEASE/ -
辅助文件:ramdisk
initrd-VERSION-RELEASE.img:从CentOS 5 版本以前 initramfs-VERSION-RELEASE.img:从CentOS6 版本以后
内核版本查看:
uname -r
-r 显示VERSION-RELEASE
-n 打印网络节点主机名
-a 打印所有信息内核模块命令
系统调用当然是将内核模块插入到内核的可行方法。但是毕竟太底层了。此外,Linux环境里还有两种方法可达到此目的。一种方法稍微自动一些,可以做到需要时自动装入,不需要时自动卸载。这种方法需要执行modprobe程序。
另一种是用insmod命令,手工装入内核模块。在前面分析helloworld例子的时候,我们提到过insmod的作用就是将需要插入的模块以目标代码的形式插入到内核中。注意,只有超级用户才能使用这个命令。
Linux内核模块机制提供的系统调用大多数都是为modutils程序使用的。可以说,是Linux的内核模块机制和modutils两者的结合提供了模块的编程接口。modutils(modutils-x.y.z.tar.gz)可以在任何获得内核源代码的地方获得, 选择最高级别的patchlevel x.y.z等于或者小于当前的内核版本,安装后在/sbin目录下就会有insmod、rmmod、ksyms、lsmod、modprobe等等实用程序。当然,通常我们在加载Linux内核的时候,modutils已经被装入了。
lsmod命令:
- 显示由核心已经装载的内核模块
- 显示的内容来自于: /proc/modules文件
实际上这个程序的功能就是读取/proc文件系统中的文件/proc/modules中的信息。所以这个命令和cat /proc/modules等价。它的格式就是:
[root@centos8 ~]#lsmod
Module Size Used by
uas 28672 0
usb_storage 73728 1 uas
nls_utf8 16384 0
isofs 45056 0 #显示:名称、大小,使用次数,被哪些模块依赖ksyms命令:
显示内核符号和模块符号表的信息,可以读取/proc/kallsyms文件。
modinfo命令:
功能:管理内核模块
配置文件:
/etc/modprobe.conf, /etc/modprobe.d/*.conf- 显示模块的详细描述信息
modinfo [ -k kernel ] [ modulename|filename... ]常用选项:
-n:只显示模块文件路径
-p:显示模块参数
-a:作者
-d:描述案例:
lsmod |grep xfs
modinfo xfsinsmod命令:
指定模块文件,不自动解决依赖模块。将模块插入Linux内核的简单程序。
语法:
insmod [ filename ] [ module options... ]案例:
insmod
modinfo –n exportfs
lnsmod
modinfo –n xfsinsmod其实是一个modutils模块实用程序,当我们以超级用户的身份使用这个命令的时候,这个程序完成下面一系列工作:
1. 从命令行中读入要链接的模块名,通常是扩展名为“.ko”,elf格式的目标文件。
2. 确定模块对象代码所在文件的位置。通常这个文件都是在lib/modules的某个子目录中。
3. 计算存放模块代码、模块名和module对象所需要的内存大小。
4. 在用户空间中分配一个内存区,把module对象、模块名以及为正在运行的内核所重定位的模块代码拷贝到这个内存里。其中,module对象中的init域指向这个模块的入口函数重新分配到的地址;exit域指向出口函数所重新分配的地址。
5. 调用init_module(),向它传递上面所创建的用户态的内存区的地址,其实现过程我们已经详细分析过了。
6. 释放用户态内存, 整个过程结束。
modprobe命令:
- 在Linux内核中添加和删除模块
modprobe [ -C config-file ] [ modulename ] [ module parame-ters... ] modprobe [ -r ] modulename…常用选项:
-C:使用文件
-r:删除模块用法:
装载:modprobe 模块名
卸载: modprobe -r 模块名 # rmmod命令:卸载模块modprobe是由modutils提供的根据模块之间的依赖性自动插入模块的程序。前面讲到的按需装入的模块加载方法会调用这个程序来实现按需装入的功能。举例来讲,如果模块A依赖模块B,而模块B并没有加载到内核里,当系统请求加载模块A时,modprobe程序会自动将模块B加载到内核。
与insmod类似,modprobe程序也是链接在命令行中指定的一个模块,但它还可以递归地链接指定模块所引用到的其他模块。从实现上讲,modprobe只是检查模块依赖关系,真正的加载的工作还是由insmod来实现的。那么,它又是怎么知道模块间的依赖关系的呢? 简单的讲,modprobe通过另一个modutils程序depmod来了解这种依赖关系。而depmod是通过查找内核中所有的模块并把它们之间的依赖关系写入/lib/modules/2.6.15-1.2054_FC5目录下,一个名为modules.dep的文件。
kmod命令:
在以前版本的内核中,模块机制的自动装入通过一个用户进程kerneld来实现,内核通过IPC和内核通信,向kerneld发送需要装载的模块的信息,然后kerneld调用modprobe程序将这个模块装载。 但是在最近版本的内核中,使用另外一种方法kmod来实现这个功能。kmod与kerneld比较,最大的不同在于它是一个运行在内核空间的进程,它可以在内核空间直接调用modprobe,大大简化了整个流程。
depmod命令:
内核模块依赖关系文件及系统信息映射文件的生成工具,生成模块.dep和map文件。
rmmod命令:
卸载模块,从Linux内核中删除模块的简单程序。
rmmod程序将已经插入内核的模块从内核中移出,rmmod会自动运行在内核模块自己定义的出口函数。它的格式是:
rmmod xfs
rmmod exportfs当然,它最终还是通过delete_module()系统调用实现的。
编译内核
编译安装内核准备:
(1) 准备好开发环境;
(2) 获取目标主机上硬件设备的相关信息;
(3) 获取目标主机系统功能的相关信息,例如:需要启用相应的文件系统;
(4) 获取内核源代码包,www.kernel.org;
编译准备
目标主机硬件设备相关信息
CPU:
cat /proc/cpuinfo
x86info -a
lscpuPCI设备:lspci -v ,-vv:
[root@centos8 ~]#lspci
00:00.0 Host bridge: Intel Corporation 440BX/ZX/DX - 82443BX/ZX/DX Host bridge (rev 01)
00:01.0 PCI bridge: Intel Corporation 440BX/ZX/DX - 82443BX/ZX/DX AGP bridge (rev 01)
00:07.0 ISA bridge: Intel Corporation 82371AB/EB/MB PIIX4 ISA (rev 08)
00:07.1 IDE interface: Intel Corporation 82371AB/EB/MB PIIX4 IDE (rev 01)
00:07.3 Bridge: Intel Corporation 82371AB/EB/MB PIIX4 ACPI (rev 08)
00:07.7 System peripheral: VMware Virtual Machine Communication Interface (rev 10)
00:0f.0 VGA compatible controller: VMware SVGA II Adapter
00:10.0 SCSI storage controller: Broadcom / LSI 53c1030 PCI-X Fusion-MPT Dual Ultra320 SCSI (rev 01)
00:11.0 PCI bridge: VMware PCI bridge (rev 02)
00:15.0 PCI bridge: VMware PCI Express Root Port (rev 01)
00:15.1 PCI bridge: VMware PCI Express Root Port (rev 01)USB设备:lsusb -v,-vv:
[root@centos8 ~]#dnf install usbutils -y
[root@centos8 ~]#lsusb
Bus 001 Device 004: ID 0951:1666 Kingston Technology DataTraveler 100 G3/G4/SE9 G2
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 003: ID 0e0f:0002 VMware, Inc. Virtual USB Hub
Bus 002 Device 002: ID 0e0f:0003 VMware, Inc. Virtual Mouse
Bus 002 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
[root@centos8 ~]#lsmod |grep usb
usb_storage 73728 1 uaslsblk 块设备
全部硬件设备信息:hal-device:CentOS 6
开发环境相关包
gcc make ncurses-devel flex bison openssl-devel elfutils-libelf-devel- 下载源码文件
- 准备文本配置文件/boot/.config
- make menuconfig:配置内核选项
- make [-j #] 或者用以下两步实现:
make -j # bzImage make -j # modules - 安装模块:make modules_install
- 安装内核相关文件:make install
- 安装bzImage为 /boot/vmlinuz-VERSION-RELEASE
- 生成initramfs文件
- 编辑grub的配置文件
编译安装内核实战案例:
[root@centos7 ~]#yum -y install gcc gcc-c++ make ncurses-devel flex bison openssl-devel elfutils-libelf-devel
[root@centos7 ~]#tar xvf linux-5.15.51.tar.xz -C /usr/local/src
[root@centos7 ~]#cd /usr/local/src
[root@centos7 src]#ls
linux-5.15.51
[root@centos7 src]#du -sh *
1.2G linux-5.15.51
[root@centos7 src]#cd linux-5.15.51/
[root@centos7 linux-5.15.51]#ls
arch COPYING Documentation include Kbuild lib Makefile README security usr
block CREDITS drivers init Kconfig LICENSES mm samples sound virt
certs crypto fs ipc kernel MAINTAINERS net scripts tools
[root@centos7 linux-5.15.51]#cp /boot/config-3.10.0-1160.el7.x86_64 .config
[root@centos7 linux-5.15.51]#vim .config
#修改下面三行
#CONFIG_MODULE_SIG=y #注释此行
CONFIG_SYSTEM_TRUSTED_KEYRING="" #修改此行
#CONFIG_DEBUG_INFO=y #linux-5.8.5版本后需要注释此行
#升级gcc版本,可以到清华的镜像站上下载相关的依赖包
#https://mirrors.tuna.tsinghua.edu.cn/gnu/gcc/gcc-9.1.0/
#https://mirrors.tuna.tsinghua.edu.cn/gnu/gmp/
#https://mirrors.tuna.tsinghua.edu.cn/gnu/mpc/
#https://mirrors.tuna.tsinghua.edu.cn/gnu/mpfr/
[root@centos7 linux-5.15.51]#cd ..
[root@centos7 src]#tar xvf gcc-9.1.0.tar.gz
[root@centos7 src]#tar xvf gmp-6.1.2.tar.bz2 -C gcc-9.1.0/
[root@centos7 src]#cd gcc-9.1.0/
[root@centos7 gcc-9.1.0]#mv gmp-6.1.2 gmp
[root@centos7 gcc-9.1.0]#cd ..
[root@centos7 src]#tar xvf mpc-1.1.0.tar.gz -C gcc-9.1.0/
[root@centos7 src]#cd gcc-9.1.0/
[root@centos7 gcc-9.1.0]#mv mpc-1.1.0 mpc
[root@centos7 gcc-9.1.0]#cd ..
[root@centos7 src]#tar xvf mpfr-4.0.2.tar.gz -C gcc-9.1.0/
[root@centos7 src]#cd gcc-9.1.0/
[root@centos7 gcc-9.1.0]#mv mpfr-4.0.2 mpfr
#编译安装gcc
[root@centos7 gcc-9.1.0]#./configure --prefix=/usr/local/ --enable-checking=release --disable-multilib --enable-languages=c,c++ --enable-bootstrap
[root@centos7 gcc-9.1.0]#make -j 2 #CPU核数要多加,不然编译会很慢
[root@centos7 gcc-9.1.0]#make install
[root@centos7 gcc-9.1.0]#cd ..
[root@centos7 src]#cd linux-5.15.51/
[root@centos7 linux-5.15.51]#make help
[root@centos7 linux-5.15.51]#make menuconfig
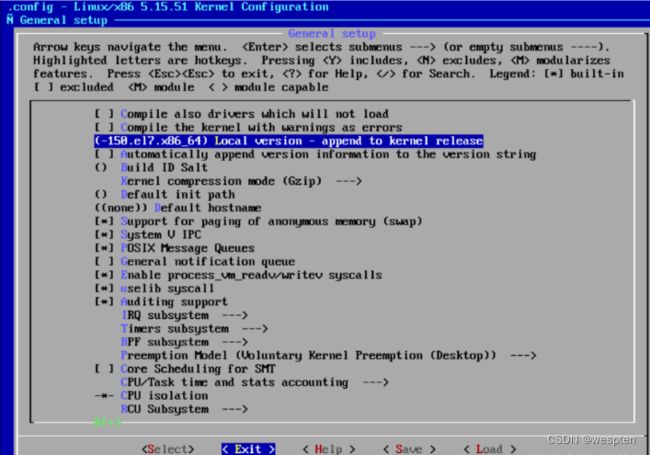
进入【常规设置】回车:
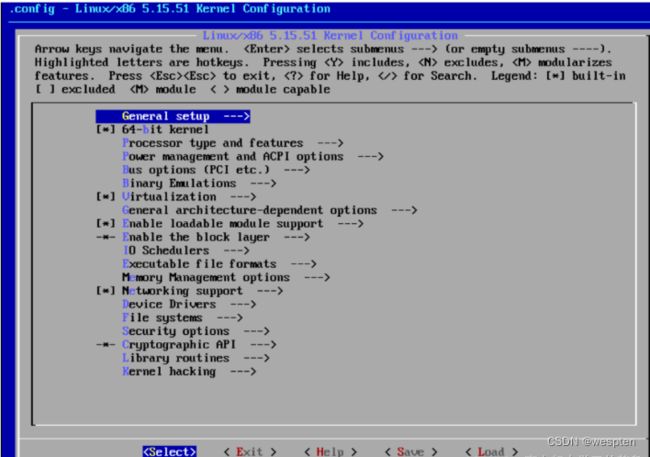
添加内核版本,回车:

输入自定义内核版本,回车:

按【Tab键】,选择【Exit】退出:
选择【文件系统】,回车:

选择【NT 文件系统】,回车:
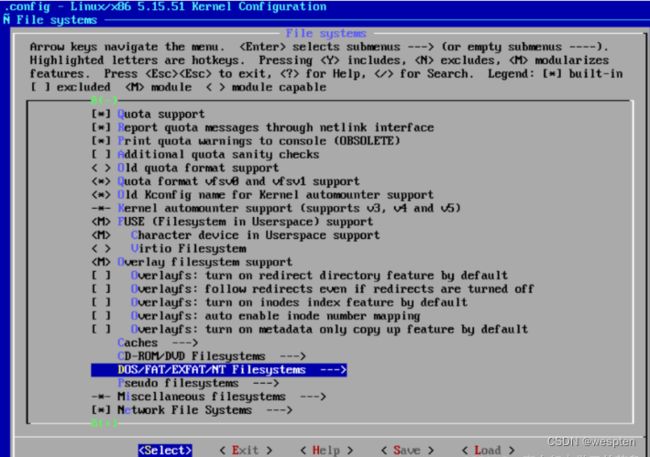
选择【NTFS 文件系统】,按【空格键】,M表示模块化方式:

选择【支持调试和写】,按【空格键】选中,按【Tab键】,选择【Exit】,回车退出:

按【Tab键】,选择【Exit】,回车退出:

按【Tab键】,选择【Exit】,回车退出:
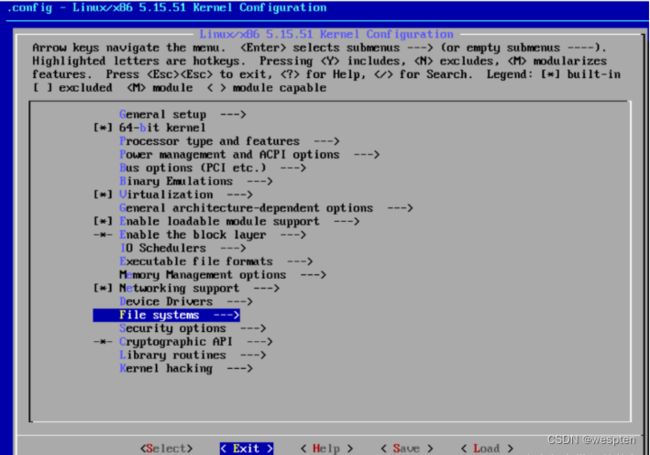
保存配置,回车:
[root@centos7 linux-5.15.51]#grep -i ntfs .config
CONFIG_NTFS_FS=m
CONFIG_NTFS_DEBUG=y
CONFIG_NTFS_RW=y
# CONFIG_NTFS3_FS is not set
[root@centos7 linux-5.15.51]#make -j 2 #CPU核数要多加,不然编译会很慢
[root@centos7 linux-5.15.51]#pwd
/usr/local/src/linux-5.15.51
[root@centos7 linux-5.15.51]#du -sh .
3.0G .
[root@centos7 linux-5.15.51]#make modules_install
[root@centos7 linux-5.15.51]#ls /lib/modules
3.10.0-1160.el7.x86_64 5.15.51-150.el7.x86_64
[root@centos7 linux-5.15.51]#du -sh /lib/modules/*
45M /lib/modules/3.10.0-1160.el7.x86_64
224M /lib/modules/5.15.51-150.el7.x86_64
[root@centos7 linux-5.15.51]#make install
[root@centos7 linux-5.15.51]#ls /boot/
config-3.10.0-1160.el7.x86_64 System.map
efi System.map-3.10.0-1160.el7.x86_64
grub System.map-5.15.51-150.el7.x86_64
grub2 vmlinuz
initramfs-0-rescue-afe373e8a26e45c681032325645782c8.img vmlinuz-0-rescue-afe373e8a26e45c681032325645782c8
initramfs-3.10.0-1160.el7.x86_64.img vmlinuz-3.10.0-1160.el7.x86_64
initramfs-5.15.51-150.el7.x86_64.img vmlinuz-5.15.51-150.el7.x86_64
symvers-3.10.0-1160.el7.x86_64.gz
选择Linux5.15内核启动:
[root@centos7 linux-5.15.51]#reboot
[root@centos7 ~]#uname -r
5.15.51-150.el7.x86_64
内核编译说明
配置内核选项:
支持“更新”模式进行配置,make help:
(a) make config:基于命令行以遍历的方式配置内核中可配置的每个选项
(b) make menuconfig:基于curses的文本窗口界面
(c) make gconfig:基于GTK (GNOME)环境窗口界面
(d) make xconfig:基于QT(KDE)环境的窗口界面
支持“全新配置”模式进行配置:
(a) make defconfig:基于内核为目标平台提供的“默认”配置进行配置
(b) make allyesconfig: 所有选项均回答为“yes“
(c) make allnoconfig: 所有选项均回答为“no“
编译内核
- 全编译:
make [-j #]- 编译内核的一部分功能:
(a) 只编译某子目录中的相关代码
cd /usr/src/linux
make dir/(b) 只编译一个特定的模块
cd /usr/src/linux
make dir/file.ko
只为e1000编译驱动:
make drivers/net/ethernet/intel/e1000/e1000.ko交叉编译内核
编译的目标平台与当前平台不相同:
make ARCH=arch_name要获取特定目标平台的使用帮助:
make ARCH=arch_name help重新编译需要事先清理操作:
make clean:清理大多数编译生成的文件,但会保留.config文件等
make mrproper: 清理所有编译生成的文件、config及某些备份文件
make distclean:包含 make mrproper,并清理patches以及编辑器备份文件卸载内核:
1. 删除/usr/src/linux/目录下不需要的内核源码;
2. 删除/lib/modules/目录下不需要的内核库文件;
3. 删除/boot目录下启动的内核和内核映像文件;
4. 更改grub的配置文件,删除不需要的内核启动列表 grub2-mkconfig -o /boot/grub2/grub.cfg
CentOS 8 还需要删除 /boot/loader/entries/5b85fc7444b240a992c42ce2a9f65db5-新内核版本.conf;
2、Linux内核模块的实现机制
在深入研究模块之前,我们有必要回顾一下内核模块与我们熟悉的应用程序之间的区别。
最主要的一点,我们必须明确,内核模块是在“内核空间”中运行的,而应用程序运行在“用户空间”。内核空间和用户空间是操作系统中最基本的两个概念,也许你还不是很清楚它们之间的区别,那么我们先一起复习一下。
操作系统的作用之一,就是为应用程序提供资源的管理,让所有的应用程序都可以使用它需要的硬件资源。然而,目前的常态是,主机往往只有一套硬件资源;现代操作系统都能利用这一套硬件,支持多用户系统。为了保证内核不受应用程序的干扰,多用户操作系统都实现了对硬件资源的授权访问,而这种授权访问机制的实现,得益于在CPU内部实现不同的操作保护级别。以INTEL的CPU为例,在任何时候,它总是在四个特权级当中的一个级别上运行,如果需要访问高特权级别的存储空间,必须通过有限数目的特权门。 Linux系统就是充分利用这个硬件特性设计的,它只使用了两级保护级别(尽管i386系列微处理器提供了四级模式)。
在Linux系统中,内核在最高级运行。在这一级,对任何设备的访问都可以进行。而应用程序则运行在最低级。在这一级,处理器禁止程序对硬件的直接访问和对内核空间的未授权访问。所以,对应于在最高级运行的内核程序,它所在的内存空间是内核空间。而对应于在最低级运行的应用程序,它所在的内存空间是用户空间。Linux通过系统调用或者中断,完成从用户空间到内核空间的转换。执行系统调用的内核代码在进程上下文中运行,它代表调用进程完成在内核空间上的操作,而且还可以访问进程的用户地址空间的数据。但对中断来说,它并不存在于任何进程上下文中,而是由内核来运行的。
好了,下面我们可以比较具体地分析内核模块与应用程序的异同。让我们看一下表6-1。
应用程序和内核模块程序编程方式的比较:

这个表里,我们看到内核模块必须通过init_module()函数告诉系统,“我来了”;通过cleanup_module()函数告诉系统,“我走了”。这也就是模块最大的特点,可以被动态地装入和卸载。insmod是内核模块操作工具集modutils中,把模块装入内核的命令,我们会在后面详细介绍。因为地址空间的原因,内核模块不能像应用程序那样自由地使用在用户空间定义的函数库如libc,例如printf();模块只能使用在内核空间定义的那些资源受到限制的函数,例如printk()。应用程序的源代码,可以调用本身没有定义的函数,只需要在连接过程中用相应的函数库解析那些外部引用。应用程序可调用的函数printf(),是在stdio.h中声明,并在libc中存在目标可连接代码。然而对于内核模块来说,它无法使用这个打印函数,而只能使用在内核空间中定义的printk()函数。printk()函数不支持浮点数的输出,而且输出数据量受到内核可用内存空间的限制。
内核模块的另外一个困难,是内核失效对于整个系统或者对于当前进程常常是致命的,而在应用程序的开发过程中,缺段(segment fault)并不会造成什么危害,我们可以利用调试器轻松地跟踪到出错的地方。所以在内核模块编程的过程中,必须特别的小心。
下面我们可以具体地看一看内核模块机制究竟是怎么实现的。
内核符号表
首先,我们来了解一下内核符号表这个概念。内核符号表是一个用来存放所有模块可以访问的那些符号以及相应地址的特殊的表。模块的连接就是将模块插入到内核的过程。模块所声明的任何全局符号都成为内核符号表的一部分。内核模块根据系统符号表从内核空间中获取符号的地址,从而确保在内核空间中正确地运行。
这是一个公开的符号表,我们可以从文件/proc/kallsyms中以文本的方式读取。在这个文件中存放数据地格式如下:
内存地址 属性 符号名称 【所属模块】
在模块编程中,可以利用符号名称从这个文件中检索出该符号在内存中的地址,然后直接对该地址内存访问从而获得内核数据。对于通过内核模块方式导出的符号,会包含第四列“所属模块”,用来标志这个符号所属的模块名称;而对于从内核中释放出的符号就不存在这一列的数据了。
内核符号表处于内核代码段的_ksymtab部分,其开始地址和结束地址是由C编译器所产生的两个符号来指定:__start___ksymtab和__stop___ksymtab。
模块依赖
内核符号表记录了所有模块可以访问的符号及相应地址。一个内核模块被装入后,它所声明的符号就会被记录到这个表里,而这些符号当然就可能会被其他模块所引用。这就引出了模块依赖这个问题。
一个模块A引用另一个模块B所导出的符号,我们就说模块B被模块A引用,或者说模块A装载到模块B的上面。如果要链接模块A,必须先要链接模块B。否则,模块B所导出的那些符号的引用就不可能被链接到模块A中。这种模块间的相互关系就叫做模块依赖。
内核代码分析
内核模块机制的源代码实现,来自于Richard Henderson的贡献。2002年后,由Rusty Russell重写。较新版本的Linux内核,采用后者。
1)数据结构
跟模块有关的数据结构存放在include/linux/module.h中,当然,首推struct module:
include/linux/module.h
232 struct module
233 {
234 enum module_state state;
235
236 /* Member of list of modules */
237 struct list_head list;
238
239 /* Unique handle for this module */
240 char name[MODULE_NAME_LEN];
241
242 /* Sysfs stuff. */
243 struct module_kobject mkobj;
244 struct module_param_attrs *param_attrs;
245 const char *version;
246 const char *srcversion;
247
248 /* Exported symbols */
249 const struct kernel_symbol *syms;
250 unsigned int num_syms;
251 const unsigned long *crcs;
252
253 /* GPL-only exported symbols. */
254 const struct kernel_symbol *gpl_syms;
255 unsigned int num_gpl_syms;
256 const unsigned long *gpl_crcs;
257
258 /* Exception table */
259 unsigned int num_exentries;
260 const struct exception_table_entry *extable;
261
262 /* Startup function. */
263 int (*init)(void);
264
265 /* If this is non-NULL, vfree after init() returns */
266 void *module_init;
267
268 /* Here is the actual code + data, vfree'd on unload. */
269 void *module_core;
270
271 /* Here are the sizes of the init and core sections */
272 unsigned long init_size, core_size;
273
274 /* The size of the executable code in each section. */
275 unsigned long init_text_size, core_text_size;
276
277 /* Arch-specific module values */
278 struct mod_arch_specific arch;
279
280 /* Am I unsafe to unload? */
281 int unsafe;
282
283 /* Am I GPL-compatible */
284 int license_gplok;
285
286 /* Am I gpg signed */
287 int gpgsig_ok;
288
289 #ifdef CONFIG_MODULE_UNLOAD
290 /* Reference counts */
291 struct module_ref ref[NR_CPUS];
292
293 /* What modules depend on me? */
294 struct list_head modules_which_use_me;
295
296 /* Who is waiting for us to be unloaded */
297 struct task_struct *waiter;
298
299 /* Destruction function. */
300 void (*exit)(void);
301 #endif
302
303 #ifdef CONFIG_KALLSYMS
304 /* We keep the symbol and string tables for kallsyms. */
305 Elf_Sym *symtab;
306 unsigned long num_symtab;
307 char *strtab;
308
309 /* Section attributes */
310 struct module_sect_attrs *sect_attrs;
311 #endif
312
313 /* Per-cpu data. */
314 void *percpu;
315
316 /* The command line arguments (may be mangled). People like
317 keeping pointers to this stuff */
318 char *args;
319 };
在内核中,每一个内核模块信息都由这样的一个module对象来描述。所有的module对象通过list链接在一起。链表的第一个元素由static LIST_HEAD(modules)建立,见kernel/module.c第65行。如果阅读include/linux/list.h里面的LIST_HEAD宏定义,你很快会明白,modules变量是struct list_head类型结构,结构内部的next指针和prev指针,初始化时都指向modules本身。对modules链表的操作,受module_mutex和modlist_lock保护。
下面就模块结构中一些重要的域做一些说明:
234 state表示module当前的状态,可使用的宏定义有:
MODULE_STATE_LIVE
MODULE_STATE_COMING
MODULE_STATE_GOING
240 name数组保存module对象的名称。
244 param_attrs指向module可传递的参数名称,及其属性
248-251 module中可供内核或其它模块引用的符号表。num_syms表示该模块定义的内核模块符号的个数,syms就指向符号表。
300 init和exit 是两个函数指针,其中init函数在初始化模块的时候调用;exit是在删除模块的时候调用的。
294 struct list_head modules_which_use_me,指向一个链表,链表中的模块均依靠当前模块。在介绍了module{}数据结构后,也许你还是觉得似懂非懂,那是因为其中有很多概念和相关的数据结构你还不了解。
例如kernel_symbol{} (见include/linux/module.h):
struct kernel_symbol
{
unsigned long value;
const char *name;
};这个结构用来保存目标代码中的内核符号。在编译的时候,编译器将该模块中定义的内核符号写入到文件中,在读取文件装入模块的时候通过这个数据结构将其中包含的符号信息读入。
value定义了内核符号的入口地址;
name指向内核符号的名称;
实现函数
接下来,我们要研究一下源代码中的几个重要的函数。正如前段所述,操作系统初始化时,static LIST_HEAD(modules)已经建立了一个空链表。之后,每装入一个内核模块,则创建一个module结构,并把它链接到modules链表中。
我们知道,从操作系统内核角度说,它提供用户的服务,都通过系统调用这个唯一的界面实现。那么,有关内核模块的服务又是怎么做的呢?请参看arch/i386/kernel/syscall_table.S,2.6.15版本的内核,通过系统调用init_module装入内核模块,通过系统调用delete_module卸载内核模块,没有其它途径。这下,代码阅读变得简单了。
kernel/module.c:
1931 asmlinkage long
1932 sys_init_module(void __user *umod,
1933 unsigned long len,
1934 const char __user *uargs)
1935 {
1936 struct module *mod;
1937 int ret = 0;
1938
1939 /* Must have permission */
1940 if (!capable(CAP_SYS_MODULE))
1941 return -EPERM;
1942
1943 /* Only one module load at a time, please */
1944 if (down_interruptible(&module_mutex) != 0)
1945 return -EINTR;
1946
1947 /* Do all the hard work */
1948 mod = load_module(umod, len, uargs);
1949 if (IS_ERR(mod)) {
1950 up(&module_mutex);
1951 return PTR_ERR(mod);
1952 }
1953
1954 /* Now sew it into the lists. They won't access us, since
1955 strong_try_module_get() will fail. */
1956 stop_machine_run(__link_module, mod, NR_CPUS);
1957
1958 /* Drop lock so they can recurse */
1959 up(&module_mutex);
1960
1961 down(¬ify_mutex);
1962 notifier_call_chain(&module_notify_list, MODULE_STATE_COMING, mod);
1963 up(¬ify_mutex);
1964
1965 /* Start the module */
1966 if (mod->init != NULL)
1967 ret = mod->init();
1968 if (ret < 0) {
1969 /* Init routine failed: abort. Try to protect us from
1970 buggy refcounters. */
1971 mod->state = MODULE_STATE_GOING;
1972 synchronize_sched();
1973 if (mod->unsafe)
1974 printk(KERN_ERR "%s: module is now stuck!\n",
1975 mod->name);
1976 else {
1977 module_put(mod);
1978 down(&module_mutex);
1979 free_module(mod);
1980 up(&module_mutex);
1981 }
1982 return ret;
1983 }
1984
1985 /* Now it's a first class citizen! */
1986 down(&module_mutex);
1987 mod->state = MODULE_STATE_LIVE;
1988 /* Drop initial reference. */
1989 module_put(mod);
1990 module_free(mod, mod->module_init);
1991 mod->module_init = NULL;
1992 mod->init_size = 0;
1993 mod->init_text_size = 0;
1994 up(&module_mutex);
1995
1996 return 0;
1997 }
函数sys_init_module()是系统调用init_module( )的实现。入口参数umod指向用户空间中该内核模块image所在的位置。image以ELF的可执行文件格式保存,image的最前部是elf_ehdr类型结构,长度由len指示。uargs指向来自用户空间的参数。系统调用init_module( )的语法原型为:
long sys_init_module(void *umod, unsigned long len, const char *uargs);说明:
1940-1941 调用capable( )函数验证是否有权限装入内核模块。
1944-1945 在并发运行环境里,仍然需保证,每次最多只有一个module准备装入。这通过down_interruptible(&module_mutex)实现。
1948-1952 调用load_module()函数,将指定的内核模块读入内核空间。这包括申请内核空间,装配全程量符号表,赋值__ksymtab、__ksymtab_gpl、__param等变量,检验内核模块版本号,复制用户参数,确认modules链表中没有重复的模块,模块状态设置为MODULE_STATE_COMING,设置license信息,等等。
1956 将这个内核模块插入至modules链表的前部,也即将modules指向这个内核模块的module结构。
1966-1983 执行内核模块的初始化函数,也就是表6-1所述的入口函数。
1987 将内核模块的状态设为MODULE_STATE_LIVE。从此,内核模块装入成功。/kernel/module.c:
573 asmlinkage long
574 sys_delete_module(const char __user *name_user, unsigned int flags)
575 {
576 struct module *mod;
577 char name[MODULE_NAME_LEN];
578 int ret, forced = 0;
579
580 if (!capable(CAP_SYS_MODULE))
581 return -EPERM;
582
583 if (strncpy_from_user(name, name_user, MODULE_NAME_LEN-1) < 0)
584 return -EFAULT;
585 name[MODULE_NAME_LEN-1] = '\0';
586
587 if (down_interruptible(&module_mutex) != 0)
588 return -EINTR;
589
590 mod = find_module(name);
591 if (!mod) {
592 ret = -ENOENT;
593 goto out;
594 }
595
596 if (!list_empty(&mod->modules_which_use_me)) {
597 /* Other modules depend on us: get rid of them first. */
598 ret = -EWOULDBLOCK;
599 goto out;
600 }
601
602 /* Doing init or already dying? */
603 if (mod->state != MODULE_STATE_LIVE) {
604 /* FIXME: if (force), slam module count and wake up
605 waiter --RR */
606 DEBUGP("%s already dying\n", mod->name);
607 ret = -EBUSY;
608 goto out;
609 }
610
611 /* If it has an init func, it must have an exit func to unload */
612 if ((mod->init != NULL && mod->exit == NULL)
613 || mod->unsafe) {
614 forced = try_force_unload(flags);
615 if (!forced) {
616 /* This module can't be removed */
617 ret = -EBUSY;
618 goto out;
619 }
620 }
621
622 /* Set this up before setting mod->state */
623 mod->waiter = current;
624
625 /* Stop the machine so refcounts can't move and disable module. */
626 ret = try_stop_module(mod, flags, &forced);
627 if (ret != 0)
628 goto out;
629
630 /* Never wait if forced. */
631 if (!forced && module_refcount(mod) != 0)
632 wait_for_zero_refcount(mod);
633
634 /* Final destruction now noone is using it. */
635 if (mod->exit != NULL) {
636 up(&module_mutex);
637 mod->exit();
638 down(&module_mutex);
639 }
640 free_module(mod);
641
642 out:
643 up(&module_mutex);
644 return ret;
645 }函数sys_delete_module()是系统调用delete_module()的实现。调用这个函数的作用是删除一个系统已经加载的内核模块。入口参数name_user是要删除的模块的名称。
说明:
580-581 调用capable( )函数,验证是否有权限操作内核模块。
583-585 取得该模块的名称
590-594 从modules链表中,找到该模块
597-599 如果存在其它内核模块,它们依赖该模块,那么,不能删除。
635-638 执行内核模块的exit函数,也就是表6-1所述的出口函数。
640 释放module结构占用的内核空间。源代码的内容就看到这里。kernel/module.c文件里还有一些其他的函数。
尝试着分析一下,top命令显示的进程名包含中括号"[]"的含义
在执行top/ps命令的时候,在COMMAND一列,我们会发现,有些进程名被[]括起来了,例如:
PID PPID USER STAT VSZ %VSZ %CPU COMMAND
1542 928 root R 1064 2% 5% top
1 0 root S 1348 2% 0% /sbin/procd
928 1 root S 1060 2% 0% /bin/ash --login
115 2 root SW 0 0% 0% [kworker/u4:2]
6 2 root SW 0 0% 0% [kworker/u4:0]
4 2 root SW 0 0% 0% [kworker/0:0]
697 2 root SW 0 0% 0% [kworker/1:3]
703 2 root SW 0 0% 0% [kworker/0:3]
15 2 root SW 0 0% 0% [kworker/1:0]
27 2 root SW 0 0% 0% [kworker/1:1]应用代码逻辑分析
关键字:COMMAND
获取busybox的源码后,试试简单粗暴的检索关键字:
[GMPY@12:22 busybox-1.27.2]$grep "COMMAND" -rnw *结果发现,太多匹配的数据:
applets/usage_pod.c:79: printf("=head1 COMMAND DESCRIPTIONS\n\n");
archival/cpio.c:100: --rsh-command=COMMAND Use remote COMMAND instead of rsh
docs/BusyBox.html:1655:which [COMMAND]...
docs/BusyBox.html:1657:Locate a COMMAND
docs/BusyBox.txt:93:COMMAND DESCRIPTIONS
docs/BusyBox.txt:112: brctl COMMAND [BRIDGE [INTERFACE]]
docs/BusyBox.txt:612: ip ip [OPTIONS] address|route|link|neigh|rule [COMMAND]
docs/BusyBox.txt:614: OPTIONS := -f[amily] inet|inet6|link | -o[neline] COMMAND := ip addr
docs/BusyBox.txt:1354: which [COMMAND]...
docs/BusyBox.txt:1356: Locate a COMMAND
......此时我发现,第一次匹配时因为存在大量非源码文件,所以显得很多,那么我能不能只检索C文件呢?
[GMPY@12:25 busybox-1.27.2]$find -name "*.c" -exec grep -Hn --color=auto "COMMAND" {} \;这次结果只有71行,简单扫了下匹配的文件,有个有意思的发现:
......
./shell/ash.c:9707: if (cmdentry.u.cmd == COMMANDCMD) {
./editors/vi.c:1109: // get the COMMAND into cmd[]
./procps/lsof.c:31: * COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
./procps/top.c:626: " COMMAND");
./procps/top.c:701: /* PID PPID USER STAT VSZ %VSZ [%CPU] COMMAND */
./procps/top.c:841: strcpy(line_buf, HDR_STR " COMMAND");
./procps/top.c:854: /* PID VSZ VSZRW RSS (SHR) DIRTY (SHR) COMMAND */
./procps/ps.c:441: { 16 , "comm" ,"COMMAND",func_comm ,PSSCAN_COMM },
......在busybox中,每一个命令都是单独一个文件,这代码逻辑结构好,我们直接进入procps/top.c文件626行
函数:display_process_list
procps/top.c的626行属于函数display_process_list,简单看一下代码逻辑:
static NOINLINE void display_process_list(int lines_rem, int scr_width)
{
......
/* 打印表头 */
printf(OPT_BATCH_MODE ? "%.*s" : "\033[7m%.*s\033[0m", scr_width,
" PID PPID USER STAT VSZ %VSZ"
IF_FEATURE_TOP_SMP_PROCESS(" CPU")
IF_FEATURE_TOP_CPU_USAGE_PERCENTAGE(" %CPU")
" COMMAND");
......
/* 遍历每一个进程对应的描述 */
while (--lines_rem >= 0) {
if (s->vsz >= 100000)
sprintf(vsz_str_buf, "%6ldm", s->vsz/1024);
else
sprintf(vsz_str_buf, "%7lu", s->vsz);
/*打印每一行中除了COMMAND之外的信息,例如PID,USER,STAT等 */
col = snprintf(line_buf, scr_width,
"\n" "%5u%6u %-8.8s %s%s" FMT
IF_FEATURE_TOP_SMP_PROCESS(" %3d")
IF_FEATURE_TOP_CPU_USAGE_PERCENTAGE(FMT)
" ",
s->pid, s->ppid, get_cached_username(s->uid),
s->state, vsz_str_buf,
SHOW_STAT(pmem)
IF_FEATURE_TOP_SMP_PROCESS(, s->last_seen_on_cpu)
IF_FEATURE_TOP_CPU_USAGE_PERCENTAGE(, SHOW_STAT(pcpu))
);
/* 关键在这,读取cmdline */
if ((int)(col + 1) < scr_width)
read_cmdline(line_buf + col, scr_width - col, s->pid, s->comm);
......
}
}剔除无关代码后,函数逻辑就清晰了
- 在此函数之前的代码中已经遍历了所有进程,并构建了描述结构体
- 在display_process_list中遍历描述结构体,并按规定顺序打印信息
- 通过read_cmdline,获取并打印进程名
我们进入到函数read_cmdline
函数:read_cmdline
void FAST_FUNC read_cmdline(char *buf, int col, unsigned pid, const char *comm)
{
......
sprintf(filename, "/proc/%u/cmdline", pid);
sz = open_read_close(filename, buf, col - 1);
if (sz > 0) {
......
while (sz >= 0) {
if ((unsigned char)(buf[sz]) < ' ')
buf[sz] = ' ';
sz--;
}
......
if (strncmp(base, comm, comm_len) != 0) {
......
snprintf(buf, col, "{%s}", comm);
......
} else {
snprintf(buf, col, "[%s]", comm ? comm : "?");
}
}剔除无关代码后,我发现
- 通过
/proc/获取进程名/cmdline - 如果
/proc/为空时,则使用/cmdline comm,此时用[]括起来 - 如果
cmdline的basename与comm不一致,则用{}括起来
为了方便阅读,不再展开分析cmdline和comm。
我们把问题聚焦在,什么情况下,/proc/为空?
内核代码逻辑分析
关键字:cmdline
/proc挂载的是proc,一种特殊的文件系统,cmdline也肯定是其特有的功能。
假设我们是内核小白,此时我们可以做的就是 在内核proc源码中检索关键字cmdline。
[GMPY@09:54 proc]$cd fs/proc && grep "cmdline" -rnw *发现有两个关键的匹配文件 base.c 和 cmdline.c
array.c:11: * Pauline Middelink : Made cmdline,envline only break at '\0's, to
base.c:224: /* Check if process spawned far enough to have cmdline. */
base.c:708: * May current process learn task's sched/cmdline info (for hide_pid_min=1)
base.c:2902: REG("cmdline", S_IRUGO, proc_pid_cmdline_ops),
base.c:3294: REG("cmdline", S_IRUGO, proc_pid_cmdline_ops),
cmdline.c:26: proc_create("cmdline", 0, NULL, &cmdline_proc_fops);
Makefile:16:proc-y += cmdline.o
vmcore.c:1158: * If elfcorehdr= has been passed in cmdline or created in 2nd kernel,cmdline.c的代码逻辑非常简单,很容易发现其是/proc/cmdline的实现,并不是我们的需求
让我们把目光聚焦到base.c,相关代码
REG("cmdline", S_IRUGO, proc_pid_cmdline_ops),经验的直觉告诉我,
- cmdline:是文件名
- S_IRUGO:是文件权限
- proc_pid_cmdline_ops:是文件对应的操作结构体
果不其然,进入proc_pid_cmdline_ops我们发现其定义为:
static const struct file_operations proc_pid_cmdline_ops = {
.read = proc_pid_cmdline_read,
.llseek = generic_file_llseek,
}函数:proc_pid_cmdline_read
static ssize_t proc_pid_cmdline_read(struct file *file, char __user *buf,
size_t _count, loff_t *pos)
{
......
/* 获取进程对应的虚拟地址空间描述符 */
mm = get_task_mm(tsk);
......
/* 获取argv的地址和env的地址 */
arg_start = mm->arg_start;
arg_end = mm->arg_end;
env_start = mm->env_start;
env_end = mm->env_end;
......
while (count > 0 && len > 0) {
......
/* 计算地址偏移 */
p = arg_start + *pos;
while (count > 0 && len > 0) {
......
/* 获取进程地址空间的数据 */
nr_read = access_remote_vm(mm, p, page, _count, FOLL_ANON);
......
}
}
}小白此时可能就疑惑了,你怎么知道access_remote_vm是干嘛的?
很简单,跳转到access_remote_vm函数中,可以看到此函数是有注释的
/**
* access_remote_vm - access another process' address space
* @mm: the mm_struct of the target address space
* @addr: start address to access
* @buf: source or destination buffer
* @len: number of bytes to transfer
* @gup_flags: flags modifying lookup behaviour
*
* The caller must hold a reference on @mm.
*/
int access_remote_vm(struct mm_struct *mm, unsigned long addr,
void *buf, int len, unsigned int gup_flags)
{
return __access_remote_vm(NULL, mm, addr, buf, len, gup_flags);
}Linux内核源码中,很多函数都有很规范的功能说明,参数说明,注意事项等等,我们要充分利用这些资源学习代码。
扯远了,让我们回到主题上。
从proc_pid_cmdline_read中我们发现,读/proc/实际上就是读取arg_start开始的的地址空间数据。所以,当这地址空间数据为空时,当然就读不到任何数据了。那么问题来了,什么时候arg_start标识的地址空间数据为空?
关键字:arg_start
地址空间相关的,绝对不仅仅是proc的事儿,我们试着在内核源码全局检索关键字:
[GMPY@09:55 proc]$find -name "*.c" -exec grep --color=auto -Hnw "arg_start" {} \;匹配不少,不想一个一个看,且从检索出来的代码找不到方向:
./mm/util.c:635: unsigned long arg_start, arg_end, env_start, env_end;
......
./kernel/sys.c:1747: offsetof(struct prctl_mm_map, arg_start),
......
./fs/exec.c:709: mm->arg_start = bprm->p - stack_shift;
./fs/exec.c:722: mm->arg_start = bprm->p;
......
./fs/binfmt_elf.c:301: p = current->mm->arg_end = current->mm->arg_start;
./fs/binfmt_elf.c:1495: len = mm->arg_end - mm->arg_start;
./fs/binfmt_elf.c:1499: (const char __user *)mm->arg_start, len))
......
./fs/proc/base.c:246: len1 = arg_end - arg_start;
......但是从匹配的文件名给了我灵感:
/proc/
进一步联想到在用户空间创建进程不外乎两个步骤:
- fork
- exec
在fork时只是创建新的task_struct,父子进程共用一份mm_struct,只有在exec的时候,才会独立出mm_struct,所以arg_start一定是在exec时被修改!而匹配arg_start的文件中,刚好有exec.c。
查看了fs/exec.c中关键字所在函数setup_arg_pages后,并没找到关键代码,于是继续查看匹配的文件名,产生了进一步联想:
exec执行一个新的程序,实际是加载新程序的bin文件,关键字匹配的文件中刚好也有binfmt_elf.c!
定位问题不仅仅要看得懂代码,联想有时候也是非常有效的
函数:create_elf_tables
binfmt_elf.c中匹配关键字arg_start的是函数create_elf_tables,函数挺长,我们精简一下:
static int
create_elf_tables(struct linux_binprm *bprm, struct elfhdr *exec,
unsigned long load_addr, unsigned long interp_load_addr)
{
......
/* Populate argv and envp */
p = current->mm->arg_end = current->mm->arg_start;
while (argc-- > 0) {
......
if (__put_user((elf_addr_t)p, argv++))
return -EFAULT;
......
}
......
current->mm->arg_end = current->mm->env_start = p;
while (envc-- > 0) {
......
if (__put_user((elf_addr_t)p, envp++))
return -EFAULT;
......
}
......
}在此函数中,实现了把argv和envp方别存入arg_start和env_start的地址空间。
接下来,我们试试溯本逐源,一起追溯函数create_elf_tables的调用
首先,create_elf_tables声明为static,表示其有效范围不可能超过所在文件。在文件中检索,发现上级函数为:
static int load_elf_binary(struct linux_binprm *bprm)竟然还是static,进而继续在本文件中检索load_elf_binary,找到了以下代码:
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
.load_shlib = load_elf_library
.core_dump = elf_core_dump,
.min_coredump = ELF_EXEC_PAGESIZE,
};
static int __init init_elf_binfmt(void)
{
register_binfmt(&elf_format);
return 0;
}
core_initcall(init_elf_binfmt);检索到这里,代码结构非常清晰了,load_elf_binary函数赋值于struct linux_binfmt,通过`register_binfmt向上层注册,提供上层回调。
关键字:load_binary
为什么要锁定关键字load_binary呢?既然.load_binary = load_elf_binary,,表示上层的调用应该是XXX->load_binary(...),因此锁定关键字load_binary即可定位,哪里调用了此回调。
[GMPY@09:55 proc]$ grep "\->load_binary" -rn *非常幸运,此回调只有fs/exec.c调用:
fs/exec.c:78: if (WARN_ON(!fmt->load_binary))
fs/exec.c:1621: retval = fmt->load_binary(bprm);进入fs/exex.c的1621行,归属于函数search_binary_handler,而不幸的是EXPORT_SYMBOL(search_binary_handler);的存在,表示很可能此函数会有多处被调用,此时继续正向分析显然非常困难,为什么不试试逆向分析呢?
道路走不通的时候,换个角度看问题,答案就在眼前
既然从search_binary_handler继续分析不容易,我们不妨看看execve的系统调用是否可以一步步到search_binary_handler?
关键字:exec
在Linux-4.9上,系统调用的定义一般是SYSCALL_DEFILNE<参数数量>(<函数名>...,因此我们全局检索关键字,先确定系统调用定义在哪里?
[GMPY@09:55 proc]$ grep "SYSCALL_DEFINE.*exec" -rn *定位到文件fs/exec.c:
fs/exec.c:1905:SYSCALL_DEFINE3(execve,
fs/exec.c:1913:SYSCALL_DEFINE5(execveat,
fs/exec.c:1927:COMPAT_SYSCALL_DEFINE3(execve, const char __user *, filename,
fs/exec.c:1934:COMPAT_SYSCALL_DEFINE5(execveat, int, fd,
kernel/kexec.c:187:SYSCALL_DEFINE4(kexec_load, unsigned long, entry, unsigned long, nr_segments,
kernel/kexec.c:233:COMPAT_SYSCALL_DEFINE4(kexec_load, compat_ulong_t, entry,
kernel/kexec_file.c:256:SYSCALL_DEFINE5(kexec_file_load, int, kernel_fd, int, initrd_fd,后面跟进函数的调用不再累赘,总结其调用关系为:
execve -> do_execveat -> do_execveat_common -> exec_binprm -> search_binary_handler终究是回归到了search_binary_handler
分析到这,我们确定了赋值逻辑:
-
在
execve执行新程序时,会初始化mm_struct -
把
execve中传递的argv和envp保存到arg_start和env_start指定的地址中 -
在
cat /proc/时则从arg_start的虚拟地址获取数据/cmdline
因此,只要是用户空间创建的进程经过execve的系统调用,都会有/proc/,但依然没澄清,什么时候会cmdline会为空?
我们知道,在Linux中,进程可分为用户空间进程和内核空间进程,既然用户空间进程cmdline非空,我们再看看内核进程。
函数:kthread_run
内核驱动中,经常通过kthread_run创建内核进程,我们以此函数为切入口,分析创建内核进程时,是否会赋值cmdline?
直接从kthread_run开始,跟踪调用关系,发现真正干活的是函数__kthread_create_on_node:
kthread_run -> kthread_create -> kthread_create_on_node -> __kthread_create_on_node去掉冗余代码,专注于函数做了什么:
static struct task_struct *__kthread_create_on_node(int (*threadfn)(void *data),
void *data, int node, const char namefmt[], va_list args)
{
/* 把新进程相关的属性存于 kthread_create_info 的结构体中 */
struct kthread_create_info *create = kmalloc(sizeof(*create), GFP_KERNEL);
create->threadfn = threadfn;
create->data = data;
create->node = node;
create->done = &done;
/* 把初始化后的create加入到链表,并唤醒kthreadd_task进程来完成创建工作 */
list_add_tail(&create->list, &kthread_create_list);
wake_up_process(kthreadd_task);
/* 等待创建完成 */
wait_for_completion_killable(&done)
......
task = create->result;
if (!IS_ERR(task)) {
......
/* 创建后,设置进程名,此处的进程名属性为comm,不同于cmdline */
vsnprintf(name, sizeof(name), namefmt, args);
set_task_comm(task, name);
......
}
}分析方法跟上文相似,不在累述。总结来说,函数做了两件事
-
唤醒进程
kthread_task来创建新进程 -
设置进程的属性,其中属性包括comm,但不包括cmdline
回顾用户代码分析,如果/proc/为空时,则使用comm,此时用[]括起来**
因此,经过kthread_run/ktrhread_create创建的内核进程,/proc/内容为空。
本次分析过程中,主要用了以下几种分析方法
- 关键字检索 - 从top程序的COMMAND到内核源码的arg_start、load_binary、exec
- 函数注释 - 函数access_remote_vm的功能说明
- 联想 - 从进程属性联想到用户空间创建进程,进而定位到arg_start关键字的处理函数
- 逆向思维 - 从search_binary_handler向上推导调用关系困难,改为分析execve的系统调用是否可以一步步到search_binary_handler?
根据本次分析,我们得出以下结论:
-
用户空间创建的进程在top/ps显示不需要[];
-
内核空间创建的进程在top/ps显示会有[];
模块单元是怎样与系统内核交互的?
内核模块的make文件:
首先我们来看一看模块程序的make文件应该怎么写。自2.6版本之后,Linux对内核模块的相关规范,有很大变动。例如,所有模块的扩张名,都从“.o”改为“.ko”。详细信息,可参看Documentation/kbuild/makefiles.txt。针对内核模块而编辑Makefile,可参看Documentation/kbuild/modules.txt。
我们练习“helloworld.ko”时,曾经用过简单的Makefile:
TARGET = helloworld
KDIR = /usr/src/linux
PWD = $(shell pwd)
obj-m += $(TARGET).o
default:
make -C $(KDIR) M=$(PWD) modules$(KDIR)表示源代码最高层目录的位置。
“obj-m += $(TARGET).o”告诉kbuild,希望将$(TARGET),也就是helloworld,编译成内核模块。
“M=$(PWD)”表示生成的模块文件都将在当前目录下。
多文件内核模块的 make文件
现在,我们把问题引申一下,对于多文件的内核模块该如何编译呢?同样以“Hello,world”为例,我们需要做以下事情:
在所有的源文件中,只有一个文件增加一行#define __NO_VERSION__。这是因为module.h一般包括全局变量kernel_version的定义,该全局变量包含模块编译的内核版本信息。如果你需要version.h,你需要自己把它包含进去,因为定义了 __NO_VERSION__后module.h就不会包含version.h。
下面给出多文件的内核模块的范例。
Start.c:
/* start.c
*
* "Hello, world" –内核模块版本
* 这个文件仅包括启动模块例程
*/
/* 必要的头文件 */
/* 内核模块中的标准 */
#include /*我们在做内核的工作 */
#include
/*初始化模块 */
int init_module()
{
printk("Hello, world!\n");
/* 如果我们返回一个非零值, 那就意味着
* init_module 初始化失败并且内核模块
* 不能加载 */
return 0;
} stop.c:
/* stop.c
*"Hello, world" -内核模块版本
*这个文件仅包括关闭模块例程
*/
/*必要的头文件 */
/*内核模块中的标准 */
#include /*我们在做内核的工作 */
#define __NO_VERSION__
#include
#include /* 不被module.h包括,因为__NO_VERSION__ */
/* Cleanup - 撤消 init_module 所做的任何事情*/
void cleanup_module()
{
printk("Bye!\n");
}
/*结束*/ 这一次,helloworld内核模块包含了两个源文件,“start.c”和“stop.c”。再来看看对于多文件内核模块,该怎么写Makefile文件
Makefile:
TARGET = helloworld
KDIR = /usr/src/linux
PWD = $(shell pwd)
obj-m += $(TARGET).o
$(TARGET)-y := start.o stop.o
default:
make -C $(KDIR) M=$(PWD) modules相比前面,只增加一行:
$(TARGET)-y := start.o stop.o编写内核模块
我们试着写一个非常简单的模块程序,它可以在2.6.15的版本上实现,对于低于2.4的内核版本可能还需要做一些调整。
helloworld.c
#include /* Needed by all modules */
#include /* Needed for KERN_INFO */
int init_module(void)
{
printk(KERN_INFO “Hello World!\n”);
return 0;
}
void cleanup_module(void)
{
printk(KERN_INFO “Goodbye!\n”);
}
MODULE_LICENSE(“GPL”); 说明:
1. 任何模块程序的编写都需要包含linux/module.h这个头文件,这个文件包含了对模块的结构定义以及模块的版本控制。文件里的主要数据结构我们会在后面详细介绍。
2. 函数init_module()和函数cleanup_module( )是模块编程中最基本的也是必须的两个函数。init_module()向内核注册模块所提供的新功能;cleanup_module()负责注销所有由模块注册的功能。
3. 注意我们在这儿使用的是printk()函数(不要习惯性地写成printf),printk()函数是由Linux内核定义的,功能与printf相似。字符串KERN_INFO表示消息的优先级,printk()的一个特点就是它对于不同优先级的消息进行不同的处理。
接下来,我们就要编译和加载这个模块了。还要注意的一点就是:确定你现在是超级用户。因为只有超级用户才能加载和卸载模块。在编译内核模块前,先准备一个Makefile文件:
TARGET = helloworld
KDIR = /usr/src/linux
PWD = $(shell pwd)
obj-m += $(TARGET).o
default:
make -C $(KDIR) M=$(PWD) modules然后简单输入命令make:
#make结果,我们得到文件“helloworld.ko”。然后执行内核模块的装入命令:
#insmod helloworld.ko
Hello World!这个时候,生成了字符串“Hello World!”,它是在init_module()中定义的。由此说明,helloworld模块已经加载到内核中了。我们可以使用lsmod命令查看。lsmod命令的作用是告诉我们所有在内核中运行的模块的信息,包括模块的名称,占用空间的大小,使用计数以及当前状态和依赖性。
root# lsmod
Module Size Used by
helloworld 464 0 (unused)
…最后,我们要卸载这个模块。
# rmmod helloworld
Goodbye!看到了打印在屏幕上的“Goodbye!”,它是在cleanup_module()中定义的。由此说明,helloworld模块已经被删除。如果这时候我们再使用lsmod查看,会发现helloworld模块已经不在了。
关于insmod和rmmod这两个命令,现在只能简单地告诉你,他们是两个用于把模块插入内核和从内核移走模块的实用程序。前面用到的insmod, rmmod和lsmod都属于modutils模块实用程序。
我们已经成功地在机子上实现了一个最简单的模块程序。
3、Memory Management (内存管理)
内存管理子系统是操作系统的重要部分。从计算机发展早期开始,就存在对于大于系统中物理能力的内存需要。为了克服这种限制,开发了许多种策略,其中最成功的就是虚拟内存。虚拟内存通过在竞争进程之间共享内存的方式使系统显得拥有比实际更多的内存。
虚拟内存不仅仅让你的计算机内存显得更多,内存管理子系统还提供:
Large Address Spaces(巨大的地址空间)操作系统使系统显得拥有比实际更大量的内存。虚拟内存可以比系统中的物理内存大许多倍。
Protection(保护)系统中的每一个进程都有自己的虚拟地址空间。这些虚拟的地址空间是相互完全分离的,所以运行一个应用程序的进程不会影响另外的进程。另外,硬件的虚拟内存机制允许对内存区写保护。这可以防止代码和数据被恶意的程序覆盖。
Memory Mapping(内存映射)内存映射用来将映像和数据映射到进程的地址空间。用内存映射,文件的内容被直接连结到进程的虚拟地址空间。
Fair Physics Memory Allocation(公平分配物理内存)内存管理子系统允许系统中每一个运行中的进程公平地共享系统的物理内存
Shared Virtual Memory(共享虚拟内存)虽然虚拟内存允许进程拥有分离(虚拟)的地址空间,有时你也需要进程之间共享内存。例如,系统中可能有多个进程运行命令解释程序bash。虽然可以在每一个进程的虚拟地址空间都拥有一份bash的拷贝,更好的是在物理内存中只拥有一份拷贝,所有运行bash的进程共享代码。动态连接库是多个进程共享执行代码的另一个常见例子。共享内存也可以用于进程间通讯(IPC)机制,两个或多个进程可以通过共同拥有的内存交换信息。Linux系统支持系统V的共享内存IPC机制。
3.1 An Abstract Model of Virtual Memory(虚拟内存的抽象模型)
在考虑Linux支持虚拟内存的方法之前,最好先考虑一个抽象的模型,以免被太多的细节搞乱。
在进程执行程序的时候,它从内存中读取指令并进行解码。解码指令也许需要读取或者存储内存特定位置的内容,然后进程执行指令并转移到程序中的下一条指令。进程不管是读取指令还是存取数据都要访问内存。
在一个虚拟内存系统中,所有的地址都是虚拟地址而非物理地址。处理器通过操作系统保存的一组信息将虚拟地址转换为物理地址。
为了让这种转换更简单,将虚拟内存和物理内存分为适当大小的块,叫做页(page)。页的大小一样。(当然可以不一样,但是这样一来系统管理起来比较困难)。Linux在Alpha AXP系统上使用8K字节的页,而在Intel x86系统上使用4K字节的页。每一页都赋予一个唯一编号:page frame number(PFN 页编号)。在这种分页模型下,虚拟地址由两部分组成:虚拟页号和页内偏移量。假如页大小是4K,则虚拟地址的位11到0包括页内偏移量,位12和以上的位是页编号。每一次处理器遇到虚拟地址,它必须提取出偏移和虚拟页编号。处理器必须将虚拟页编号转换到物理的页,并访问物理页的正确偏移处。为此,处理器使用了页表(page tables)。
图3.1显示了两个进程的虚拟地址空间,进程X和进程Y,每一个进程拥有自己的页表。这些页表将每一个进程的虚拟页映射到内存的物理页上。图中显示进程X的虚拟页号0映射到物理页号1,而进程Y的虚拟页编号1映射到物理页号4。理论上页表每一个条目包括以下信息:
有效标志 表示页表本条目是否有效
本页表条目描述的物理页编号
访问控制信息 描述本页如何使用:是否可以写?是否包括执行代码?
页表通过虚拟页标号作为偏移来访问。虚拟页编号5是表中的第6个元素(0是第一个元素)
要将虚拟地址转换到物理地址,处理器首先找出虚拟地址的页编号和页内偏移量。使用2的幂次的页尺寸,可以用掩码或移位简单地处理。再一次看图3.1,假设页大小是0x2000(十进制8192),进程Y的虚拟地址空间的地址是0x2194,处理器将会把地址转换为虚拟页编号1内的偏移量0x194。
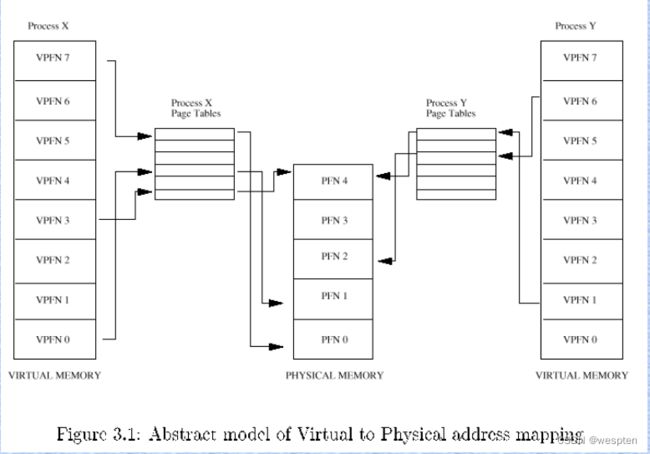
处理器使用虚拟页编号作为索引在进程的页表中找到它的页表的条目。如果该条目有效,处理器从该条目取出物理的页编号。如果本条目无效,就是进程访问了它的虚拟内存中不存在的区域。在这种情况下,处理器无法解释地址,必须将控制权传递给操作系统来处理。
处理器具体如何通知操作系统进程在访问无法转换的无效的虚拟地址,这个方式是和处理器相关的。处理器将这种信息(page fault)进行传递,操作系统得到通知,虚拟地址出错,以及出错的原因。
假设这是一个有效的页表条目,处理器取出物理页号并乘以页大小,得到了物理内存中本页的基础地址。最后,处理器加上它需要的指令或数据的偏移量。
再用上述例子,进程Y的虚拟页编号1映射到了物理页编号4(起始于0x8000 , 4x 0x2000),加上偏移0x194,得到了最终的物理地址0x8194。
通过这种方式将虚拟地址映射到物理地址,虚拟内存可以用任意顺序映射到系统的物理内存中。例如,图3.1 中,虚拟内存X的虚拟页编号映射到了物理页编号1而虚拟页编号7虽然在虚拟内存中比虚拟页0要高,却映射到了物理页编号0。这也演示了虚拟内存的一个有趣的副产品:虚拟内存页不必按指定顺序映射到物理内存中。
3.1.1 Demand Paging
因为物理内存比虚拟内存少得多,操作系统必须避免无效率地使用物理内存。节省物理内存的一种方法是只加载执行程序正在使用的虚拟页。例如:一个数据库程序可能正在数据库上运行一个查询。在这种情况下,并非所有的数据必须放到内存中,而只需要正被检查的数据记录。如果这是个查找型的查询,那么加载程序中增加记录的代码就没什么意义。这种进行访问时才加载虚拟页的技术叫做demand paging。
当一个进程试图访问当前不在内存中的虚拟地址的时候处理器无法找到引用的虚拟页对应的页表条目。例如:图3.1中进程X的页表中没有虚拟页2 的条目,所以如果进程X试图从虚拟页2中的地址读取时,处理器无法将地址转换为物理地址。这时处理器通知操作系统发生page fault。
如果出错的虚拟地址无效意味着进程试图访问它不应该访问的虚拟地址。也许是程序出错,例如向内存中任意地址写。这种情况下,操作系统会中断它,从而保护系统中其他的进程。
如果出错的虚拟地址有效但是它所在的页当前不在内存中,操作系统必须从磁盘映像中将相应的页加载到内存中。相对来讲磁盘存取需要较长时间,所以进程必须等待直到该页被取到内存中。如果当前有其他系统可以运行,操作系统将选择其中一个运行。取到的页被写到一个空闲的页面,并将一个有效的虚拟页条目加到进程的页表中。然后这个进程重新运行发生内存错误的地方的机器指令。这一次虚拟内存存取进行时,处理器能够将虚拟地址转换到物理地址,所以进程得以继续运行。
Linux使用demand paging技术将可执行映像加载到进程的虚拟内存中。当一个命令执行时,包含它的文件被打开,它的内容被映射到进程的虚拟内存中。这个过程是通过修改描述进程内存映射的数据结构来实现,也叫做内存映射(memory mapping)。但是,实际上只有映像的第一部分真正放在了物理内存中。映像的其余部分仍旧在磁盘上。当映像执行时,它产生page fault,Linux使用进程的内存映像表来确定映像的那一部分需要加载到内存中执行。
3.1.2 Swapping(交换)
如果进程需要将虚拟页放到物理内存中而此时已经没有空闲的物理页,操作系统必须废弃物理空间中的另一页,为该页让出空间。
如果物理内存中需要废弃的页来自磁盘上的映像或者数据文件,而且没有被写过所以不需要存储,则该页被废弃。如果进程又需要该页,它可以从映像或数据文件中再次加载到内存中。
但是,如果该页已经被改变,操作系统必须保留它的内容以便以后进行访问。这种也叫做dirty page,当它从物理内存中废弃时,被存到一种叫做交换文件的特殊文件中。因为访问交换文件的速度和访问处理器以及物理内存的速度相比很慢,操作系统必须判断是将数据页写到磁盘上还是将它们保留在内存中以便下次访问。
如果决定哪些页需要废弃或者交换的算法效率不高,则会发生颠簸(thrashing)。这时,页不断地被写到磁盘上,又被读回,操作系统过于繁忙而无法执行实际的工作。例如在图3.1中,如果物理页号1经常被访问,那么就不要将它交换到硬盘上。进程正在使用的也叫做工作集(working set)。有效的交换方案应该保证所有进程的工作集都在物理内存中。
Linux使用LRU(Least Recently Used最近最少使用)的页面技术来公平地选择需要从系统中废弃的页面。这种方案将系统中的每一页都赋予一个年龄,这个年龄在页面存取时改变。页面访问越多,年纪越轻,越少访问,年纪越老越陈旧。陈旧的页面是交换的好候选。
3.1.3 Shared Vitual Memory(共享虚拟内存)
虚拟内存使多个进程可以方便地共享内存。所有的内存访问都是通过页表,每一个进程都有自己的页表。对于两个共享一个物理内存页的进程,这个物理页编号必须出现在两个进程的页表中。
图3.1显示了两个共享物理页号4的进程。对于进程X虚拟页号是4,而对于进程Y虚拟页号是6。这也表明了共享页的一个有趣的地方:共享的物理页不必存在共享它的进程的虚拟内存空间的同一个地方。
3.1.4 Physical and Vitual Addressing Modes(物理和虚拟寻址模式)
对于操作系统本身而言,运行在虚拟内存中没有什么意义。如果操作系统必须维护自身的页表,这将会是一场噩梦。大多数多用途的处理器同时支持物理地址模式和虚拟地址模式。物理寻址模式不需要页表,处理器在这种模式下不需要进行任何地址转换。Linux核心运行在物理地址模式。
Alpha AXP处理器没有特殊的物理寻址模式。它将内存空间分为几个区,将其中两个指定为物理映射地址区。核心的地址空间叫做KSEG地址空间,包括从0xfffffc0000000000向上的所有地址。为了执行连接在KSEG的代码(核心代码)或者访问那里的数据,代码必须在核心态执行。Alpha 上的Linux核心连接到从地址0xfffffc0000310000执行。

3.1.5 Access Control(访问控制)
页表条目也包括访问控制信息。当处理器使用页表条目将进程的虚拟地址映射到物理地址的时候,它很容易利用访问控制信息控制进程不要用不允许的方式进行访问。
有很多原因你希望限制对于内存区域的访问。一些内存,比如包含执行代码,本质上是只读的代码,操作系统应该禁止进程写它的执行代码。反过来,包括数据的页可以写,但是如果试图执行这段内存应该失败。大多数处理器有两种执行状态:核心态和用户态。你不希望用户直接执行核心态的代码或者存取核心数据结构,除非处理器运行在核心态。
访问控制信息放在PTE(page table entry)中,而且和具体处理器相关。图3.2显示了Alpha AXP的PTE。各个位意义如下:
V 有效,这个PTE是否有效
FOE “Fault on Execute” 试图执行本页代码时,处理器是否要报告page fault,并将控制权传递给操作系统。
FOW “Fault on Write” 如上,在试图写本页时产生page fault
FOR “fault on read” 如上,在试图读本页时产生page fault
ASM 地址空间匹配。用于操作系统清除转换缓冲区中的部分条目
KRE 核心态的代码可以读本页
URE 用户态的代码可以读本页
GII 间隔因子,用于将一整块映射到一个转换缓冲条目而非多个。
KWE 核心态的代码可以写本页
UWE 用户态的代码可以写本页
Page frame number 对于V位有效的PTE,包括了本PTE的物理页编号;对于无效的PTE,如果不是0,包括了本页是否在交换文件的信息。以下两位由Linux定义并使用:
_PAGE_DIRTY 如果设置,本页需要写到交换文件中
_PAGE_ACCESSED Linux 使用,标志一页已经访问过3.2 Caches(高速缓存)
如果你用以上理论模型来实现一个系统,它可以工作,但是不会太高效率。操作系统和处理器的设计师都尽力让系统性能更高。除了使用更快的处理器、内存等,最好的方法是维护有用信息和数据的高速缓存,这会使一些操作更快。
Linux使用了一系列和高速缓存相关的内存管理技术:
Buffer Cache: Buffer cache 包含了用于块设备驱动程序的数据缓冲区。这些缓冲区大小固定(例如512字节),包括从块设备读出的数据或者要写到块设备的数据。块设备是只能通过读写固定大小的数据块来访问的设备。所有的硬盘都是块设备。块设备用设备标识符和要访问的数据块编号作为索引,用来快速定位数据块。块设备只能通过buffer cache存取。如果数据可以在buffer cache中找到,那就不需要从物理块设备如硬盘上读取,从而使访问加快。
参见fs/buffer.c
Page Cache 用来加快对磁盘上映像和数据的访问。它用于缓存文件的逻辑内容,一次一页,并通过文件和文件内的偏移来访问。当数据页从磁盘读到内存中时,被缓存到page cache中。
参见mm/filemap.c
Swap Cache 只有改动过的(或脏dirty)页才存在交换文件中。只要它们写到交换文件之后没有再次修改,下一次这些页需要交换出来的时候,就不需要再写到交换文件中,因为该页已经在交换文件中了,直接废弃该页就可以了。在一个交换比较厉害的系统,这会节省许多不必要和高代价的磁盘操作。
参见mm/swap_state.c mm/swapfile.c
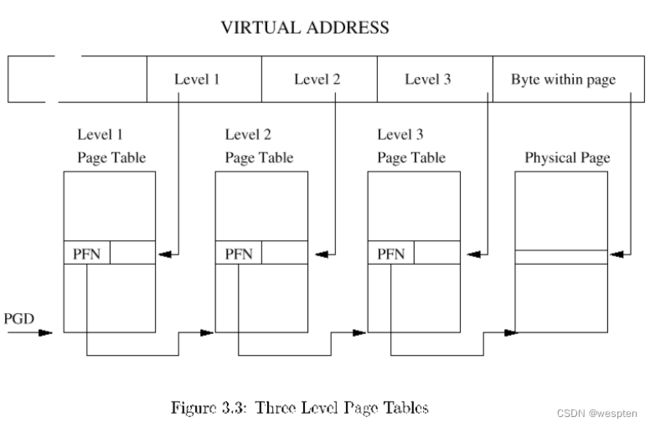
Hardware Cache:硬件高速缓存的常见的实现方法是在处理器里面:PTE的高速缓存。这种情况下,处理器不需要总是直接读页表,而在需要时把页转换表放在缓存区里。CPU里有转换表缓冲区(TLB Translation Look-aside Buffers),放置了系统中一个或多个进程的页表条目的缓存的拷贝。
当引用虚拟地址时,处理区试图在TLB中寻找。如果找到了,它就直接将虚拟地址转换到物理地址,进而对数据执行正确的操作。如果找不到,它就需要操作系统的帮助。它用信号通知操作系统,发生了TLB missing。一个和系统相关的机制将这个异常转到操作系统相应的代码来处理。操作系统为这个地址映射生成新的TLB条目。当异常清除之后,处理器再次尝试转换虚拟地址,这一次将会成功因为TLB中该地址有了一个有效的条目。
高速缓存的副作用(不管是硬件或其他方式的)在于Linux必须花大量时间和空间来维护这些高速缓存区,如果这些高速缓存区崩溃,系统也会崩溃。
3.3 Linux Page Tables(Linux页表)
Linux假定了三级页表。访问的每一个页表包括了下一级页表的页编号。图3.3显示了一个虚拟地址如何分为一系列字段:每一个字段提供了在一个页表中的偏移量。为了将虚拟地址转换为物理地址,处理器必须取得每一级字段的内容,转换为包括该页表的物理页内的偏移,然后读取下一级页表的页编号。重复三次直到包括虚拟地址的物理地址的页编号找到为止。然后用虚拟地址中的最后一个字段:字节偏移量,在页内查找数据。
Linux运行的每一个平台都必须提供转换宏,让核心处理特定进程的页表。这样,核心不需要知道页表条目的具体结构或者如何组织。通过这种方式,Linux成功地使用了相同的页表处理程序用于Alpha和Intel x86处理器,其中Alpha使用三级页表,而Intel使用二级页表。
参见include/asm/pgtable.h
3.4 Page Allocation and Deallocation (页的分配和回收)
系统中对于物理页有大量的需求。例如,当程序映像加载到内存中的时候,操作系统需要分配页。当程序结束执行并卸载时需要释放这些页。另外为了存放核心相关的数据结构比如页表自身,也需要物理页。这种用于分配和回收页的机制和数据结构对于维护虚拟内存子系统的效率也许是最重要的。
系统中的所有的物理页都使用mem_map数据结构来描述。这是一个mem_map_t结构的链表,在启动时进行初始化。每一个mem_map_t(容易混淆的是这个结构也被称为page 结构)结构描述系统中的一个物理页。重要的字段(至少对于内存管理而言)是:
参见include/linux/mm.h
count 本页用户数目。如果本页由多个进程共享,计数器大于1。
Age 描述本页的年龄。用于决定本页是否可以废弃或交换出去。
Map_nr mem_map_t描述的物理页编号。
页分配代码使用free_area向量来查找空闲的页。整个缓冲管理方案用这种机制来支持。只要用了这种代码,处理器使用的页的大小和物理页的机制就可以无关。
每一个free_area单元包括页块的信息。数组中的第一个单元描述了单页,下一个是2页大小的块,下一个是4页大小的块,以此类推,依次向上都是2的倍数。这个链表单元用作队列的开头,有指向mem_map数组中页的数据结构的指针。空闲的页块在这里排队。Map是一个跟踪这么大小的页的分配组的位图。如果页块中的第N块空闲,则位图中的第N位置位。
图3.4显示了free_area结构。单元0有一个空闲页(页编号0),单元2有2个4页的空闲块,第一个起始于页编号4,第二个起始于页编号56。
3.4.1 Page Allocation (页分配)
参见mm/page_alloc.c get_free_pages()
Linux使用Buddy算法有效地分配和回收页块。页分配代码试图分配一个由一个或多个物理页组成的块。页分配使用2的幂数大小的块。这意味着可以分配1页大小,2页大小,4页大小的块,依此类推。只要系统有满足需要的足够的空闲页(nr_free_pages > min_free_pages),分配代码就会在free_area中查找满足需要大小的一个页块。Free_area中的每一个单元都有描述自身大小的页块的占用和空闲情况的位图。例如,数组中的第2个单元拥有描述4页大小的块的空闲和占用的分配图。
这个算法首先找它请求大小的内存页块。它跟踪free_area数据结构中的list单元队列中的空闲页的链表。如果请求大小的页块没有空闲,就找下一个尺寸的块(2倍于请求的大小)。继续这一过程一直到遍历了所有的free_area或者找到了空闲页块。如果找到的页块大于请求的页块,则该块将被分开成为合适大小的块。因为所有的块都是2的幂次的页数组成,所以这个分割的过程比较简单,你只需要将它平分就可以了。空闲的块则放到适当的队列,而分配的页块则返回给调用者。

例如在图3.4中,如果请求2页的数据块,第一个4页块(起始于页编号4)将会被分为两个2页块。起始于页号4的第一个2页块将会被返回给调用者,而第二个2页块(起始于页号6)将会排在free_area数组中的单元1中2页空闲块的队列中。
3.4.2 Page Deallocation(页回收)
分配页块的过程中将大的页块分为小的页块,将会使内存更为零散。页回收的代码只要可能就把页联成大的页块。其实页块的大小很重要(2的幂数),因为这样才能很容易将页块组成大的页块。
只要一个页块回收,就检查它的相邻或一起的同样大小的页块是否空闲。如果是这样,就把它和新释放的页块一起组成以一个新的下一个大小的空闲页块。每一次两个内存页块组合成为更大的页块时,页回收代码都要试图将页块合并成为更大的块。这样,空闲的页块就会尽可能的大。
例如,在图3.4,如果页号1释放,那么它会和已经空闲的页号0一起组合并放在free_area的单元1中空闲的2页块队列中。
3.5 Memory Mapping (内存映射)
当一个映像执行时,执行映像的内容必须放在进程的虚拟地址空间中。对于执行映像连接到的任意共享库,情况也是一样。执行文件实际并没有放到物理内存,而只是被连接到进程的虚拟内存。这样,只要运行程序引用了映像的部分,这部分映像就从执行文件中加载到内存中。这种映像和进程虚拟地址空间的连接叫做内存映射。
每一个进程的虚拟内存用一个mm_struct 数据结构表示。这包括当前执行的映像的信息(例如bash)和指向一组vm_area_struct结构的指针。每一个vm_area_struct的数据结构都描述了内存区域的起始、进程对于内存区域的访问权限和对于这段内存的操作。这些操作是一组例程,Linux用于管理这段虚拟内存。例如其中一种虚拟内存操作就是当进程试图访问这段虚拟内存时发现(通过page fault)内存不在物理内存中所必须执行的正确操作,这个操作叫做 nopage 操作。Linux请求把执行映像的页加载到内存中的时候用到nopage操作。
当一个执行映像映射到进程的虚拟地址空间时,产生一组vm_area_struct数据结构。每一个vm_area_struct结构表示执行映像的一部分:执行代码、初始化数据(变量)、未初始化数据等等。Linux支持一系列标准的虚拟内存操作,当vm_area_struct数据结构创建时,一组正确的虚拟内存操作就和它们关联在一起。
3.6 Demand Paging
只要执行映像映射到进程的虚拟内存中,它就可以开始运行。因为只有映像的最开始的部
分是放在物理内存中,很快就会访问到还没有放在物理内存的虚拟空间区。当进程访问没有有效页表条目的虚拟地址的时候,处理器向Linux报告page fault。Page fault描述了发生page fault的虚拟地址和内存访问类型。
Linux必须找到page fault 发生的空间区所对应的vm_area_struct数据结构(用Adelson-Velskii and Landis AVL树型结构连接在一起)。如果找不到这个虚拟地址对应的vm_area_struct结构,说明进程访问了非法的虚拟地址。Linux将向该进程发信号,发送一个SIGSEGV信号,如果进程没有处理这个信号,它就会退出。
参见 handle_mm_fault() in mm/memory.c
Linux然后检查page faul的类型和该虚拟内存区所允许的访问类型。如果进程用非法的方式访问内存,比如写一个它只可以读的区域,也会发出内存错的信号。
现在Linux确定page fault是合法的,它必须进行处理。Linux必须区分在交换文件和磁盘映像中的页,它用发生page fault的虚拟地址的页表条目来确定。
参见do_no_page() in mm/memory.c
如果该页的页表条目是无效的但非空,此页是在交换文件中。对于Alpha AXP页表条目来讲,有效位置位但是PFN域非空。这种情况下PFN域存放了此页在交换文件(以及那一个交换文件)中的位置。页在交换文件中如何处理在后面讨论。
并非所有的vm_area_struct数据结构都有一整套虚拟内存操作,而且那些有特殊的内存操作的也可能没有nopang操作。因为缺省情况下,对于nopage操作,Linux会分配一个新的物理页并创建有效的页表条目。如果这一段虚拟内存有特殊的nopage操作,Linux会调用这个特殊的代码。
通常的Linux nopage操作用于对执行映像的内存映射,并使用page cache将请求的映像页加载到物理内存中。虽然在请求的页调入的物理内存中以后,进程的页表得到更新,但是也许需要必要的硬件动作来更新这些条目,特别是如果处理器使用了TLB。既然page fault得到了处理,就可以扔在一边,进程在引起虚拟内存访问错误的指令那里重新运行。
参见mm/filemap.c 中filemap_nopage()

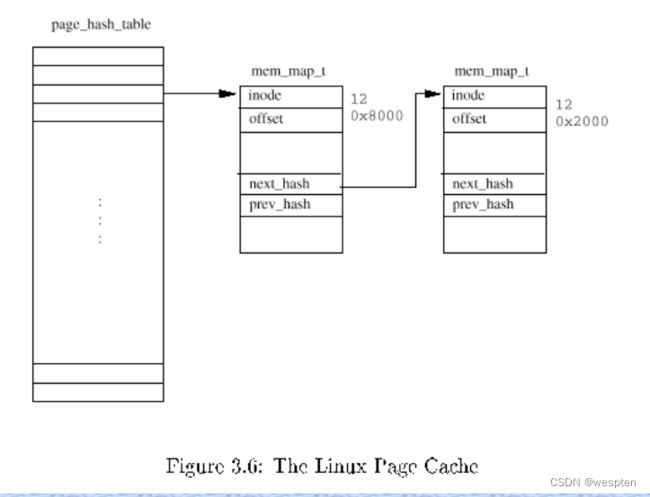
3.7 The Linux Page Cache
Linux的page cache的作用是加速对于磁盘文件的访问。内存映射文件每一次读入一页,这些页被存放在page cache中。图3.6显示了page cache,包括一个指向mem_map_t数据结构的指针向量:page_hash_table。Linux中的每一个文件都用一个VFS inode的数据结构标示(在第9小节描述),每一个VFS I节点都是唯一的并可以完全确定唯一的一个文件。页表的索引取自VFS的I节点号和文件中的偏移。
参见linux/pagemap.h
当一页的数据从内存映射文件中读出,例如当demand paging时需要放到内存中的时候,此页通过page cache中读出。如果此页在缓存中,就返回一个指向mem_map_t数据结构的指针给page fault 的处理代码。否则,此页必须从存放此文件的文件系统中加载到内存中。Linux分配物理内存并从磁盘文件中读出该页。如果可能,Linux会启动对文件下一页的读。这种单页的超前读意味着如果进程从文件中顺序读数据的话,下一页数据将会在内存中等待。
当程序映像读取和执行的时候page cache 不断增长。如果页不在需要,将从缓存中删除。比如不再被任何进程使用的映像。当Linux使用内存的时候,物理页可能不断减少,这时Linux可以减小page cache。
3.8 Swapping out and Discarding Pages(交换出去和废弃页)
当物理内存缺乏的时候,Linux内存管理子系统必须试图释放物理页。这个任务落在核心交换进程上(kswapd)。核心交换守护进程是一种特殊类型的进程,一个核心线程。核心线程是没有虚拟内存的进程,以核心态运行在物理地址空间。核心交换守护进程名字有一点不恰当,因为它不仅仅是将页交换到系统交换文件上。它的任务是保证系统有足够的空闲页,使内存管理系统有效地运行。
核心交换守护进程(kswapd)在启动时由核心的init 进程启动,并等待核心的交换计时器到期。每一次计时器到期,交换进程检查系统中的空闲页数是否太少。它使用两个变量:free_pages_high和free_pages_low来决定是否释放一些页。只要系统中的空闲页数保持在free_pages_high之上,交换进程什么都不做。它重新睡眠直到它的计时器下一次到期。为了做这种检查,交换进程要考虑正在向交换文件中写的页数,用nr_async_pages来计数:每一次一页排到队列中等待写到交换文件中的时候增加,写完的时候减少。Free_page_low和free_page_high是系统启动时间设置的,和系统中的物理页数相关。如果系统中的空闲页数小于free_pages_high或者比free_page_low还低,核心交换进程会尝试三种方法来减少系统使用的物理页数:
参见mm/vmscan.c 中的kswapd()
减少buffer cache 和page cache的大小
将系统V的共享内存页交换出去
交换和废弃页
如果系统中的空闲页数低于free_pages_low,核心交换进程将试图在下一次运行前释放6页。否则试图释放3页。以上的每一种方法都要被尝试直到释放了足够的页。核心交换进程记录了它上一次使用的释放物理页的方法。每一次运行时它都会首先尝试上一次成功的方法来释放页。
释放了足够的页之后,交换进程又一次睡眠,直到它的计时器又一次过期。如果核心交换进程释放页的原因是系统空闲页的数量少于free_pages_low,它只睡眠平时的一半时间。只要空闲页数大于free_pages_low,交换进程就恢复原来的时间间隔进行检查。
3.8.1 Reducing the size of the Page and Buffer Caches
page 和buffer cache中的页是释放到free_area向量中的好选择。Page Cache,包含了内存映射文件的页,可能有不必要的数据,占去了系统的内存。同样,Buffer Cache ,包括了从物理设备读或向物理设备写的数据,也可能包含了无用的缓冲。当系统中的物理页将要耗尽的时候,废弃这些缓存区中的页相对比较容易,因为它不需要向物理设备写(不象将页从内存中交换出去)。废弃这些页不会产生多少有害的副作用,只不过使访问物理设备和内存映射文件时慢一点。虽然如此,如果公平地废弃这些缓存区中的页,所有的进程受到的影响就是平等的。
每一次当核心交换进程要缩小这些缓存区时,它要检查mem_map页矢量中的页块,看是否可以从物理内存中废弃。如果系统空闲页太低(比较危险时)而核心交换进程交换比较厉害,这个检查的页块大小就会更大一些。页块的大小进行循环检查:每一次试图减少内存映射时都用一个不同的页块大小。这叫做clock算法,就象钟的时针。整个mem_map页向量都被检查,每次一些页。
参见mm/filemap.c shrink_map()
检查的每一页都要判断缓存在page cache 或者buffer cache中。注意共享页的废弃这时不考虑,一页不会同时在两个缓存中。如果该页不在这两个缓冲区中,则mem_map页向量表的下一页被检查。
缓存在buffer cache ch中的页(或者说页中的缓冲区被缓存)使缓冲区的分配和释放更有效。缩小内存映射的代码试图释放包含检查过的页的缓冲区。如果缓冲区释放了,则包含缓冲区的页也被释放了。如果检查的页是在Linux的page cache 中,它将从page cache 中删除并释放。
参见 fs/buffer.c free_buffer()
如果这次尝试释放了足够的页,核心交换进程就会继续等待直到下一次被周期性地唤醒。因为释放的页不属于任何进程的虚拟内存(只是缓存的页),因此不需要更新进程的页表。如果废弃的缓存页仍然不够,交换进程会试图交换出一些共享页。
3.8.2 Swapping Out System V Shared Memory Pages(交换出系统V的共享内存页)
系统V的共享内存是一种进程间通讯的机制,通过两个或多个进程共享虚拟内存交换信息。进程间如何共享内存在第5小节详细讨论。现在只要讲讲每一块系统V共享内存都用一个shmid_ds的数据结构描述就足够了。它包括一个指向vm_area_struct链表数据结构的指针,用于共享此内存的每一个进程。Vm_area_struct数据结构描述了此共享内存在每一个进程中的位置。这个系统V的内存中的每一个vm_area_struct结构都用vm_next_shared和vm_prev_shared指针连接在一起。每一个shmid_ds数据结构都有一个页表条目的链表,每一个条目都描述一个共享的虚拟页和物理页的对应关系。
核心交换进程将系统V的共享内存页交换出去时也用clock算法。它每一次运行都记录了上一次交换出去了那一块共享内存的那一页。它用两个索引来记录:第一个是shmid_ds数据结构数组中的索引,第二个是这块共享内存区的页表链中的索引。这样可以共享内存区的牺牲比较公平。
参见ipc/shm.c shm_swap()
因为一个指定的系统V共享内存的虚拟页对应的物理页号包含在每一个共享这块虚拟内存的进程的页表中,所以核心交换进程必须修改所有的进程的页表来体现此页已经不在内存而在交换文件中。对于每一个交换出去的共享页,交换进程必须找到在每一个共享进程的页表中对应的此页的条目(通过查找每一个vm_area_struct指针)如果在一个进程页表中此共享内存页的条目有效,交换进程要把它变为无效,并且标记是交换页,同时将此共享页的在用数减1。交换出去的系统V共享页表的格式包括一个在shmid_ds数据结构组中的索引和在此共享内存区中页表条目的索引。
如果所有共享的内存都修改过,页的在用数变为0,这个共享页就可以写到交换文件中。这个系统V共享内存区的shmid_ds数据结构指向的页表中此页的条目将会换成交换出的页表条目。交换出的页表条目无效但是包含一个指向打开的交换文件的索引和此页在此文件内的偏移量。这个信息用于将此页再取回物理内存中。
3.3 Swapping Out and Discarding Pages
交换进程轮流检查系统中的每一个进程是否可以用于交换。好的候选是可以交换的进程(有一些不行)并且有可以从内存中交换出去或废弃的一个或多个页。只有其他方法都不行的时候才会把页从物理内存交换到系统交换文件中。
参见 mm/vmscan.c swap_out()
来自于映像文件的执行映像的大部分内容可以从文件中重新读出来。例如:一个映像的执行指令不会被自身改变,所以不需要写到交换文件中。这些页只是被简单地废弃。如果再次被进程引用,可以从执行映像再次加载到内存中。
一旦要交换的进程确定下来,交换进程就查看它的所有虚拟内存区域,寻找没有共享或锁定的区域。Linux不会把选定进程的所有可以交换出去的页都交换出去,而只是去掉少量的页。如果页在内存中锁定,则不能被交换或废弃。
参见mm/vmscan.c swap_out_vme() 跟踪进程mm_struct中排列的vm_area_struct结构中的vm_next vm_nex指针。
Linux的交换算法使用了页的年龄。每一个页都有一个计数器(放在mem_map_t数据结构中),告诉核心交换进程此页是否值得交换出去。页不用时变老,访问时更新。交换进程只交换老的页。缺省地,页第一次分配时年龄赋值为3。每一次访问,它的年龄就增加3,直到20。每一次系统交换进程运行时它将页的年龄减1使页变老。这个缺省的行为可以更改,所以这些信息(和其他相关信息)都存放在swap_control数据结构中。
如果页太老(年龄age = 0),交换进程会进一步处理。脏页可以交换出去,Linux在描述此页的PTE中用一个和体系结构相关的位来描述这种页(见图3.2)。但是,并非所有的脏页都需要写到交换文件。每一个进程的虚拟内存区域都可以拥有自己的交换操作(由vm_area_struct中的vm_ops指针指示),如果这样,交换进程会用它的这种方式。否则,交换进程会从交换文件中分配一页,并把此页写到该文件中。
此页的页表条目会用一个无效的条目替换,但是包括了此页在交换文件的信息:此页所在文件内的偏移和所用的交换文件。不管什么方式交换,原来的物理页被放回到free_area重释放。干净(或不脏)的页可以被废弃,放回到free_area中重用。
如果交换或废弃了足够的可交换进程的页,交换进程重新睡眠。下一次唤醒时它会考虑系统中的下一个进程。这样,交换进程轻咬去每一个进程的物理页,直到系统重新达到平衡。这种做法比交换出整个进程更公平。
3.9 The Swap Cache(交换缓存)
当把页交换到交换文件时,Linux会避免写不必要写的页。有时可能一个页同时存在于交换文件和物理内存中。这发生于一页被交换出内存然后在进程要访问时又被调入内存的情况下。只要内存中的页没有被写过,交换文件中的拷贝就继续有效。
Linux用swap cache来记录这些页。交换缓存是一个页表条目或者系统物理页的链表。一个交换页有一个页表条目,描述使用的交换文件和它在交换文件中的位置。如果交换缓存条目非0,表示在交换文件中的一页没有被改动。如果此页后来被改动了(被写),它的条目就从交换缓存中删除)
当Linux需要交换一个物理页到交换文件的时候,它查看交换缓存,如果有此页的有效条目,它不需要把此页写到交换文件。因为内存中的此页从上次读到交换文件之后没有被修改过。
交换缓存中的条目是曾经交换出去的页表条目。它们被标记为无效,但是包含了允许Linux找到正确交换文件和交换文件中正确页的信息。
3.10 Swapping Page In(交换进)
保存在交换文件中的脏页可能又需要访问。例如:当应用程序要向虚拟内存中写数据,而此页对应的物理页交换到了交换文件时。访问不在物理内存的虚拟内存页会引发page fault。Page fault是处理器通知操作系统它不能将虚拟内存转换到物理内存的信号。因为交换出去后虚拟内存中描述此页的页表条目被标记为无效。处理器无法处理虚拟地址到物理地址的转换,将控制转回到操作系统,告诉它发生错误的虚拟地址和错误的原因。这个信息的格式和处理器如何把控制转回到操作系统是和处理器类型相关的。处理器相关的page faule处理代码必须定位描述包括出错虚拟地址的虚拟内存区的vm_area_struct的数据结构。它通过查找该进程的vm_area_struct数据结构,直到找到包含了出错的虚拟地址的那一个。这是对时间要求非常严格的代码,所以一个进程的vm_area_struct数据结构按照特定的方式排列,使这种查找花费时间尽量少。
参见 arch/i386/mm/fault.c do_page_fault()
执行了合适的和处理器相关的动作并找到了包括错误(发生)的虚拟地址的有效的虚拟内存,page fault的处理过程又成为通用的,并可用于Linux能运行的所有处理器。通用的page fault处理代码查找错误虚拟地址的页表条目。如果它找到的页表条目是交换出去的页,Linux必须把此页交换回物理内存。交换出去的页的页表条目的格式和处理器相关,但是所有的处理器都将这些页标为无效并在页表条目中放进了在交换文件中定位页的必要信息。Linux使用这种信息把此页调回到物理内存中。
参见mm/memory.c do_no_page()
这时,Linux知道了错误(发生)的虚拟地址和关于此页交换到哪里去的页表条目。Vm_area_struct数据结构可能包括一个例程的指针,用于把这块虚拟内存中的页交换回到物理内存中。这是swapin操作。如果这块内存中有swapin操作,Linux会使用它。其实,交换出去的系统V的共享内存之所以需要特殊的处理因为交换的系统V的共享内存页的格式和普通交换页的不同。如果没有swapin操作,Linux假定这是一个普通页,不需要特殊的处理。它分配一块空闲的物理页并将交换出去的页从交换文件中读进来。关于从交换文件哪里(和哪一个交换文件)的信息取自无效的页表条目。
参见mm/page_alloc.c swap_in()
如果引起page fault的访问不是写访问,页就留在交换缓存中,它的页表条目标记为不可写。如果后来此页又被写,会产生另一个page fault,这时,此页被标志为脏页,而它的条目也从交换缓存中删除。如果此页没有被修改而又需要交换出来,Linux就可以避免将此页写到交换文件,因为此页已经在交换文件中了。
如果将此页从交换文件调回的访问是写访问,这个页就从交换缓存中删除,此页的页表条目页标记为脏页和可写。
4、Processes (进程)
进程执行操作系统中的任务。程序是存放在磁盘上的包括一系列机器代码指令和数据的可执行的映像,因此,是一个被动的实体。进程可以看作是一个执行中的计算机程序。它是动态的实体,在处理器执行机器代码指令时不断改变。处理程序的指令和数据,进程也包括程序计数器和其他CPU的寄存器以及包括临时数据(例如例程参数、返回地址和保存的变量)的堆栈。当前执行的程序,或者说进程,包括微处理器中所有的当前的活动。Linux是一个多进程的操作系统。进程是分离的任务,拥有各自的权利和责任。如果一个进程崩溃,它不应该让系统中的另一个进程崩溃。每一个独立的进程运行在自己的虚拟地址空间,除了通过安全的核心管理的机制之外无法影响其他的进程。
在一个进程的生命周期中它会使用许多系统资源。它会用系统的CPU执行它的指令,用系统的物理内存来存储它和它的数据。它会打开和使用文件系统中的文件,会直接或者间接使用系统的物理设备。Linux必须跟踪进程本身和它使用的系统资源以便管理公平地管理该进程和系统中的其他进程。如果一个进程独占了系统的大部分物理内存和CPU,对于其他进程就是不公平的。
系统中最宝贵的资源就是CPU。通常系统只有一个。Linux是一个多进程的操作系统。它的目标是让进程一直在系统的每一个CPU上运行,充分利用CPU。如果进程数多于CPU(多数是这样),其余的进程必须等到CPU被释放才能运行。多进程是一个简单的思想:一个进程一直运行,直到它必须等待,通常是等待一些系统资源,等拥有了资源,它才可以继续运行。在一个单进程的系统,比如DOS,CPU被简单地设为空闲,这样等待的时间就会被浪费。在一个多进程的系统中,同一时刻许多进程在内存中。当一个进程必须等待时操作系统将CPU从这个进程拿走,并将它交给另一个更需要的进程。是调度程序选择了
下一次最合适的进程。Linux使用了一系列的调度方案来保证公平。
Linux支持许多不同的可执行文件格式,ELF是其中之一,Java是另一个。Linux必须透明地管理这些文件,因为进程使用系统的共享的库。
4.1 Linux Processes(Linux的进程)
Linux中,每一个进程用一个task_struct(在Linux中task和process互用)的数据结构来表示,用来管理系统中的进程。Task向量表是指向系统中每一个task_struct数据结构的指针的数组。这意味着系统中最大进程数受task向量表的限制,缺省是512。当新的进程创建的时候,从系统内存中分配一个新的task_struct,并增加到task向量表中。为了更容易查找,用current指针指向当前运行的进程。
参见include/linux/sched.h
除了普通进程,Linux也支持实时进程。这些进程必须对于外界事件迅速反应(因此叫做“实时”),调度程序必须和普通用户进程区分对待。虽然task_struct数据结构十分巨大、复杂,但是它的域可以分为以下的功能:
State 进程执行时它根据情况改变状态(state)。Linux进程使用以下状态:(这里漏掉了SWAPPING,因为看来没用到)
Running 进程在运行(是系统的当前进程)或者准备运行(等待被安排到系统的一个CPU上)
Waiting 进程在等待一个事件或资源。Linux区分两种类型的等待进程:可中断和不可中断的(interruptible and uninterruptible)。可中断的等待进程可以被信号中断,而不可中断的等待进程直接等待硬件条件,不能被任何情况中断。
Stopped 进程停止了,通常是接收到了一个信号。正在调试的进程可以在停止状态。
Zombie 终止的进程,因为某种原因,在task 向量表重任旧有一个task_struct数据结构的条目。就想听起来一样,是一个死亡的进程。
Scheduling Information 调度者需要这个信息用于公平地决定系统中的进程哪一个更应该运行。
Identifiers 系统中的每一个进程都有一个进程标识符。进程标识符不是task向量表中的索引,而只是一个数字。每一个进程也都有用户和组(user and group)的标识符。用来控制进程对于系统中文件和设备的访问。
Inter-Process Communication Linux支持传统的UNIX-IPC机制,即信号,管道和信号灯(semaphores),也支持系统V的IPC机制,即共享内存、信号灯和消息队列。关于Linux支持的IPC机制在第5小节中描述。
Links 在Linux系统中,没有一个进程是和其他进程完全无关的。系统中的每一个进程,除了初始的进程之外,都有一个父进程。新进程不是创建的,而是拷贝,或者说从前一个进程克隆的(cloned)。每一个进程的task_struct中都有指向它的父进程和兄弟进程(拥有相同的父进程的进程)以及它的子进程的的指针。
在Linux系统中你可以用pstree命令看到正在运行的进程的家庭关系:
init(1)-+-crond(98)
|-emacs(387)
|-gpm(146)
|-inetd(110)
|-kerneld(18)
|-kflushd(2)
|-klogd(87)
|-kswapd(3)
|-login(160)---bash(192)---emacs(225)
|-lpd(121)
|-mingetty(161)
|-mingetty(162)
|-mingetty(163)
|-mingetty(164)
|-login(403)---bash(404)---pstree(594)
|-sendmail(134)
|-syslogd(78)
`-update(166)另外系统中的所有的进程信息还存放在一个task_struct数据结构的双向链表中,根是init进程。这个表让Linux可以查到系统中的所有的进程。它需要这个表以提供对于ps或者kill等命令的支持。
Times and Timers 在一个进程的生命周期中,核心除了跟踪它使用的CPU时间还记录它的其他时间。每一个时间片(clock tick),核心更新jiffies中当前进程在系统和用户态所花的时间综合。Linux也支持进程指定的时间间隔的计数器。进程可以使用系统调用建立计时器,在计时器到期的时候发送信号给自己。这种计时器可以是一次性的,也可是周期性的。
File system 进程可以根据需要打开或者关闭文件,进程的task_struct结构存放了每一个打开的文件描述符的指针和指向两个VFS I节点(inode)的指针。每一个VFS I节点唯一描述一个文件系统中的一个文件或目录,也提供了对于底层文件系统的通用接口。Linux下如何支持文件系统在第9小节中描述。第一个I节点是该进程的根(它的主目录),第二个是它的当前或者说pwd目录。Pwd取自Unix命令:印出工作目录。这两个VFS节点本身有计数字段,随着一个或多个进程引用它们而增长。这就是为什么你不能删除一个进程设为工作目录的目录。
Virtual memory 多数进程都有一些虚拟内存(核心线程和核心守护进程没有),Linux核心必须知道这些虚拟内存是如何映射到系统的物理内存中的。
Processor Specific Context 进程可以看作是系统当前状态的总和。只要进程运行,它就要使用处理器的寄存器、堆栈等等。当一个进程暂停的时候,这些进程的上下文、和CPU相关的上下文必须保存到进程的task_struct结构中。当调度者重新启动这个进程的时候,它的上下文就从这里恢复。
4.2 Identifiers (标识)
Linux,象所有的Unix,使用用户和组标识符来检查对于系统中的文件和映像的访问权限。Linux系统中所有的文件都有所有权和许可,这些许可描述了系统对于该文件或目录拥有什么样的权限。基本的权限是读、写和执行,并分配了3组用户:文件属主、属于特定组的进程和系统中的其他进程。每一组用户都可以拥有不同的权限,例如一个文件可以让它的属主读写,它的组读,而系统中的其他进程不能访问。
Linux使用组来给一组用户赋予对文件或者目录的权限,而不是对系统中的单个用户或者进程赋予权限。比如你可以为一个软件项目中的所有用户创建一个组,使得只有他们才能够读写项目的源代码。一个进程可以属于几个组(缺省是32个),这些组放在每一个进程的task_struct结构中的groups向量表中。只要进程所属的其中一个组对于一个文件有访问权限,则这个进程就又对于这个文件的适当的组权限。
一个进程的task_struct中有4对进程和组标识符。
Uid,gid 该进程运行中所使用的用户的标识符和组的标识符
Effective uid and gid 一些程序把执行进程的uid和gid 改变为它们自己的(在VFS I节点执行映像的属性中)。这些程序叫做setuid程序。这种方式有用,因为它可以限制对于服务的访问,特别是那些用其他人的方式运行的,例如网络守护进程。有效的uid 和gid来自setuid程序,而uid和gid 仍旧是原来的。核心检查特权的时候检查有效 uid和gid。
File system uid and gid 通常和有效uid和gid相等,检查对于文件系统的访问权限。用于通过NFS安装的文件系统。这时用户态的NFS服务器需要象一个特殊进程一样访问文件。只有文件系统uid和gid改变(而非有效uid和gid)。这避免了恶意用户向NFS的服务程序发送Kill信号。Kill用一个特别的有效uid和gid发送给进程。
Saved uid and gid 这是POSIX标准的要求,让程序可以通过系统调用改变进程的uid和gid。用于在原来的uid和gid改变之后存储真实的uid和gid。
4.3 Scheduling (调度)
所有的进程部分运行与用户态,部分运行于系统态。底层的硬件如何支持这些状态各不相同但是通常有一个安全机制从用户态转入系统态并转回来。用户态比系统态的权限低了很多。每一次进程执行一个系统调用,它都从用户态切换到系统态并继续执行。这时让核心执行这个进程。Linux中,进程不是互相争夺成为当前运行的进程,它们无法停止正在运行的其它进程然后执行自身。每一个进程在它必须等待一些系统事件的时候会放弃CPU。例如,一个进程可能不得不等待从一个文件中读取一个字符。这个等待发生在系统态的系统调用中。进程使用了库函数打开并读文件,库函数又执行系统调用从打开的文件中读入字节。这时,等候的进程会被挂起,另一个更加值得的进程将会被选择执行。进程经常调用系统调用,所以经常需要等待。即使进程执行到需要等待也有可能会用去不均衡的CPU事件,所以Linux使用抢先式的调度。用这种方案,每一个进程允许运行少量一段时间,200毫秒,当这个时间过去,选择另一个进程运行,原来的进程等待一段时间直到它又重新运行。这个时间段叫做时间片。
需要调度程序选择系统中所有可以运行的进程中最值得的进程。一个可以运行的进程是一个只等待CPU的进程。Linux使用合理而简单的基于优先级的调度算法在系统当前的进程中进行选择。当它选择了准备运行的新进程,它就保存当前进程的状态、和处理器相关的寄存器和其他需要保存的上下文信息到进程的task_struct数据结构中。然后恢复要运行的新的进程的状态(又和处理器相关),把系统的控制交给这个进程。为了公平地在系统中所有可以运行(runnable)的进程之间分配CPU时间,调度程序在每一个进程的task_struct结构中保存了信息:
参见 kernel/sched.c schedule()
policy 进程的调度策略。Linux有两种类型的进程:普通和实时。实时进程比所有其它进程的优先级高。如果有一个实时的进程准备运行,那么它总是先被运行。实时进程有两种策略:环或先进先出(round robin and first in first out)。在环的调度策略下,每一个实时进程依次运行,而在先进先出的策略下,每一个可以运行的进程按照它在调度队列中的顺序运行,这个顺序不会改变。
Priority 进程的调度优先级。也是它允许运行的时候可以使用的时间量(jiffies)。你可以通过系统调用或者renice命令来改变一个进程的优先级。
Rt_priority Linux支持实时进程。这些进程比系统中其他非实时的进程拥有更高的优先级。这个域允许调度程序赋予每一个实时进程一个相对的优先级。实时进程的优先级可以用系统调用来修改
Coutner 这时进程可以运行的时间量(jiffies)。进程启动的时候等于优先级(priority),每一次时钟周期递减。
调度程序从核心的多个地方运行。它可以在把当前进程放到等待队列之后运行,也可以在系统调用之后进程从系统态返回进程态之前运行。需要运行调度程序的另一个原因是系统时钟刚好把当前进程的计数器(counter)置成了0。每一次调度程序运行它做以下工作:
参见 kernel/sched.c schedule()
kernel work 调度程序运行bottom half handler并处理系统的调度任务队列。这些轻量级的核心线程在第11小节详细描述
Current pocess 在选择另一个进程之前必须处理当前进程。
如果当前进程的调度策略是环则它放到运行队列的最后。
如果任务是可中断的而且它上次调度的时候收到过一个信号,它的状态变为RUNNING
如果当前进程超时,它的状态成为RUNNING
如果当前进程的状态为RUNNING则保持此状态
不是RUNNING或者INTERRUPTIBLE的进程被从运行队列中删除。这意味着当调度程序查找最值得运行的进程时不会考虑这样的进程。
Process Selection 调度程序查看运行队列中的进程,查找最值得运行的进程。如果有实时的进程(具有实时调度策略),就会比普通进程更重一些。普通进程的重量是它的counter,但是对于实时进程则是counter 加1000。这意味着如果系统中存在可运行的实时进程,就总是在任何普通可运行的进程之前运行。当前的进程,因为用掉了一些时间片(它的counter减少了),所以如果系统中由其他同等优先级的进程,就会处于不利的位置:这也是应该的。如果几个进程又同样的优先级,最接近运行队列前段的那个就被选中。当前进程被放到运行队列的后面。如果一个平衡的系统,拥有大量相同优先级的进程,那么回按照顺序执行这些进程。这叫做环型调度策略。不过,因为进程需要等待资源,它们的运行顺序可能会变化。
Swap Processes 如果最值得运行的进程不是当前进程,当前进程必须被挂起,运行新的进程。当一个进程运行的时候它使用了CPU和系统的寄存器和物理内存。每一次它调用例程都通过寄存器或者堆栈传递参数、保存数值比如调用例程的返回地址等。因此,当调度程序运行的时候它在当前进程的上下文运行。它可能是特权模式:核心态,但是它仍旧是当前运行的进程。当这个进程要挂起时,它的所有机器状态,包括程序计数器(PC)和所有的处理器寄存器,必须存到进程的task_struct数据结构中。然后,必须加载新进程的所有机器状态。这种操作依赖于系统,不同的CPU不会完全相同地实现,不过经常都是通过一些硬件的帮助。
交换出去进程的上下文发生在调度的最后。前一个进程存储的上下文,就是当这个进程在调度结束的时候系统的硬件上下文的快照。相同的,当加载新的进程的上下文时,仍旧是调度结束时的快照,包括进程的程序计数器和寄存器的内容。
如果前一个进程或者新的当前进程使用虚拟内存,则系统的页表需要更新。同样,这个动作适合体系结构相关。Alpha AXP处理器,使用TLT(Translation Look-aside Table)或者缓存的页表条目,必须清除属于前一个进程的缓存的页表条目。
4.3.1 Scheduling in Multiprocessor Systems(多处理器系统中的调度)
在Linux世界中,多CPU系统比较少,但是已经做了大量的工作使Linux成为一个SMP(对称多处理)的操作系统。这就是,可以在系统中的CPU之间平衡负载的能力。负载均衡没有比在调度程序中更重要的了。
在一个多处理器的系统中,希望的情况是:所有的处理器都繁忙地运行进程。每一个进程都独立地运行调度程序直到它的当前的进程用完时间片或者不得不等待系统资源。SMP系统中第一个需要注意的是系统中可能不止一个空闲(idle)进程。在一个单处理器的系统中,空闲进程是task向量表中的第一个任务,在一个SMP系统中,每一个CPU都有一个空闲的进程,而你可能有不止一个空闲CPU。另外,每一个CPU有一个当前进程,所以SMP系统必须记录每一个处理器的当前和空闲进程。
在一个SMP系统中,每一个进程的task_struct都包含进程当前运行的处理器编号(processor)和上次运行的处理器编号(last_processor)。为什么进程每一次被选择运行时不要在不同的CPU上运行是没什么道理的,但是Linux可以使用processor_mask把进程限制在一个或多个CPU上。如果位N置位,则该进程可以运行在处理器N上。当调度程序选择运行的进程的时候,它不会考虑processor_mask相应位没有设置的进程。调度程序也会利用上一次在当前处理器运行的进程,因为把进程转移到另一个处理器上经常会有性能上的开支。
4.4 Files(文件)
图4.1显示了描述系统每一个进程中的用于描述和文件系统相关的信息的两个数据结构。第一个fs_struct包括了这个进程的VFS I节点和它的umask。Umask是新文件创建时候的缺省模式,可以通过系统调用改变。
参见include/linux/sched.h
第二个数据结构,files_struct,包括了进程当前使用的所有文件的信息。程序从标准输入读取,向标准输出写,错误信息输出到标准错误。这些可以是文件,终端输入/输出或者世纪的设备,但是从程序的角度它们都被看作是文件。每一个文件都有它的描述符,files_struct包括了指向256个file数据结果,每一个描述进程形用的文件。F_mode域描述了文件创建的模式:只读、读写或者只写。F_pos记录了下一次读写操作在文件中的位置。F_inode指向描述该文件的I节点,f_ops是指向一组例程地址的指针,每一个地址都是一个用于处理文件的函数。例如写数据的函数。这种抽象的接口非常强大,使得Linux可以支持大量的文件类型。我们可以看到,在Linux中pipe也是用这种机制实现的。
每一次打开一个文件,就使用files_struct中的一个空闲的file指针指向这个新的file结构。Linux进程启动时有3个文件描述符已经打开。这就是标准输入、标准输出和标准错误,这都是从创建它们的父进程中继承过来的。对于文件的访问都是通过标准的系统调用,需要传递或返回文件描述符。这些描述符是进程的fd向量表中的索引,所以标准输入、标准输出和标准错误的文件描述符分别是0,1和2。对于文件的所有访问都是利用file数据结构中的文件操作例程和它的VFS I节点一起来实现的。
4.5 Virtual Memory(虚拟内存)
进程的虚拟内存包括多种来源的执行代码和数据。第一种是加载的程序映像,例如ls命令。这个命令,象所有的执行映像一样,由执行代码和数据组成。映像文件中包括将执行代码和相关的程序数据加载到进程地虚拟内存中所需要的所有信息。第二种,进程可以在处理过程中分配(虚拟)内存,比如用于存放它读入的文件的内容。新分配的虚拟内存需要连接到进程现存的虚拟内存中才能使用。第三中,Linux进程使用通用代码组成的库,例如文件处理。每一个进程都包括库的一份拷贝没有意义,Linux使用共享库,几个同时运行的进程可以共用。这些共享库里边的代码和数据必须连接到该进程的虚拟地址空间和其他共享该库的进程的虚拟地址空间。
在一个特定的时间,进程不会使用它的虚拟内存中包括的所有代码和数据。它可能包括旨在特定情况下使用的代码,比如初始化或者处理特定的事件。它可能只是用了它的共享库中一部分例程。如果把所有这些代码都加载到物理内存中而不使用只会是浪费。把这种浪费和系统中的进程数目相乘,系统的运行效率会很低。Linux改为使用demand paging 技术,进程的虚拟内存只在进程试图使用的时候才调入物理内存中。所以,Linux不把代码和数据直接加载到内存中,而修改进程的页表,把这些虚拟区域标志为存在但是不在内存中。当进程试图访问这些代码或者数据,系统硬件会产生一个page fault,把控制传递给Linux核心处理。因此,对于进程地址空间的每一个虚拟内存区域,Linux需要直到它从哪里来和如何把它放到内存中,这样才可以处理这些page fault。
Linux核心需要管理所有的这些虚拟内存区域,每一个进程的虚拟内存的内容通过一个它的task_struct指向的一个mm_struct mm_struc数据结构描述。该进程的mm_struct数据结构也包括加载的执行映像的信息和进程页表的指针。它包括了指向一组vm_area_struct数据结构的指针,每一个都表示该进程中的一个虚拟内存区域。
这个链接表按照虚拟内存顺序排序。图4.2显示了一个简单进程的虚拟内存分布和管理它的核心数据结构。因为这些虚拟内存区域来源不同,Linux通过vm_area_struct指向一组虚拟内存处理例程(通过vm_ops)的方式抽象了接口。这样进程的所有虚拟内存都可以用一种一致的方式处理,不管底层管理这块内存的服务如何不同。例如,会有一个通用的例程,在进程试图访问不存在的内存时调用,这就是page fault 的处理。
当Linux为一个进程创建新的虚拟内存区域和处理对于不在系统物理内存中的虚拟内存的引用时,反复引用进程的vm_area_struct数据结构列表。这意味着它查找正确的vm_area_struct数据结构所花的事件对于系统的性能十分重要。为了加速访问,Linux也把vm_area_struct数据结构放到一个AVL(Adelson-Velskii and Landis)树。对这个树进行安排使得每一个vm_area_struct(或节点)都有对相邻的vm_area_struct结构的一个左和一个右指针。左指针指向拥有较低起始虚拟地址的节点,右指针指向一个拥有较高起始虚拟地址的节点。为了找到正确的节点,Linux从树的根开始,跟从每一个节点的左和右指针,直到找到正确的vm_area_struct。当然,在这个树中间释放不需要时间,而插入新的vm_area_struct需要额外的处理时间。
当一个进程分配虚拟内存的时候,Linux并不为该进程保留物理内存。它通过一个新的vm_area_struct数据结构来描述这块虚拟内存,连接到进程的虚拟内存列表中。当进程试图写这个新的虚拟内存区域的时候,系统会发生page fault。处理器试图解码这个虚拟地址,但是没有对应该内存的页表条目,它会放弃并产生一个page fault异常,让Linux核心处理。Linux检查这个引用的虚拟地址是不是在进程的虚拟地址空间, 如果是,Linux创建适当的PTE并为该进程分配物理内存页。也许需要从文件系统或者交换磁盘中加载相应的代码或者数据,然后进程从引起page fault的指令重新运行,因为这次该内存实际存在,可以继续。
4.6 Creating a Process(创建一个进程)
当系统启动的时候它运行在核心态,这时,只有一个进程:初始化进程。象所有其他进程一样,初始进程有一组用堆栈、寄存器等等表示的机器状态。当系统中的其他进程创建和运行的时候这些信息存在初始进程的task_struct数据结构中。在系统初始化结束的时候,初始进程启动一个核心线程(叫做init)然后执行空闲循环,什么也不做。当没有什么可以做的时候,调度程序会运行这个空闲的进程。这个空闲进程的task_struct是唯一一个不是动态分配而是在核心连接的时候静态定义的,为了不至于混淆,叫做init_task。
Init核心线程或进程拥有进程标识符1,是系统的第一个真正的进程。它执行系统的一些初始化的设置(比如打开系统控制它,安装根文件系统),然后执行系统初始化程序。依赖于你的系统,可能是/etc/init,/bin/init或/sbin/init其中之一。Init程序使用/etc/inittab作为脚本文件创建系统中的新进程。这些新进程自身可能创建新的进程。例如:getty进程可能会在用户试图登录的时候创建一个login的进程。系统中的所有进程都是init核心线程的后代。
新的进程的创建是通过克隆旧的进程,或者说克隆当前的进程来实现的。一个新的任务是通过系统调用创建的(fork或clone),克隆发生在核心的核心态。在系统调用的最后,产生一个新的进程,等待调度程序选择它运行。从系统的物理内存中为这个克隆进程的堆栈(用户和核心)分配一个或多个物理的页用于新的task_struct数据结构。一个进程标识符将会创建,在系统的进程标识符组中是唯一的。但是,也可能克隆的进程保留它的父进程的进程标识符。新的task_struct进入了task 向量表中,旧的(当前的)进程的task_struct的内容拷贝到了克隆的task_struct。
参见kernel/fork.c do_fork()
克隆进程的时候,Linux允许两个进程共享资源而不是拥有不同的拷贝。包括进程的文件,信号处理和虚拟内存。共享这些资源的时候,它们相应的count字段相应增减,这样Linux不会释放这些资源直到两个进程都停止使用。例如,如果克隆的进程要共享虚拟内存,它的task_struct会包括一个指向原来进程的mm_struct的指针,mm_struct的count域增加,表示当前共享它的进程数目。
克隆一个进程的虚拟内存要求相当的技术。必须产生一组vm_area_struct数据结构、相应的mm_struct数据结构和克隆进程的页表,这时没有拷贝进程的虚拟内存。这会是困难和耗时的任务,因为一部分虚拟内存可能在物理内存中而另一部分可能在交换文件中。替代底,Linux使用了叫做“copy on write”的技术,即只有两个进程中的一个试图写的时候才拷贝虚拟内存。任何不写入的虚拟内存,甚至可能写的,都可以在两个进程之间共享二部会有什么害处。只读的内存,例如执行代码,可以共享。为了实现“copy on write”,可写的区域的页表条目标记为只读,而描述它的vm_area_struct数据结构标记为“copy on write”。当一个进程试图写向着这个虚拟内存的时候会产生page fault。这时Linux将会制作这块内存的一份拷贝并处理两个进程的页表和虚拟内存的数据结构。
4.7 Times and Timer(时间和计时器)
核心跟踪进程的CPU时间和其他一些时间。每一个时钟周期,核心更新当前进程的jiffies来表示在系统和用户态下花费的时间总和。
除了这些记账的计时器,Linux还支持进程指定的间隔计时器(interval timer)。进程可以使用这些计时器在这些计时器到期的时候发送给自身信号。支持三种间隔计时器:
参见kernel/itimer.c
Real 这个计时器使用实时计时,当计时器到期,发送给进程一个SIGALRM信号。
Virtual 这个计时器只在进程运行的时候计时,到期的时候,发送给进程一个SIGVTALARM信号。
Profile 在进程运行的时候和系统代表进程执行的时候都及时。到期的时候,会发送SIGPROF信号。
可以运行一个或者所有的间隔计时器,Linux在进程的task_struct数据结构中记录所有的必要信息。可以使用系统调用建立这些间隔计时器,启动、停止它们,读取当前的数值。虚拟和profile计时器的处理方式相同:每一次时钟周期,当前进程的计时器递减,如果到期,就发出适当的信号
参见kernel/sched.c do_it_virtual(), do_it_prof()
实时间隔计时器稍微不同。Linux使用计时器的机制在第11小节描述。每一个进程都有自己的timer_list数据结构,当时使用实时计时器的时候,使用系统的timer表。当它到期的时候,计时器后半部分处理把它从队列中删除并调用间隔计时器处理程序。它产生SIGALRM信号并重启动间隔计时器,把它加回到系统计时器队列。
参见:kernel/iterm.c it_real_fn()
4.8 Executing Programs (执行程序)
在Linux中,象Unix一样,程序和命令通常通过命令解释器执行。命令解释程序是和其他进程一样的用户进程,叫做shell(想象一个坚果,把核心作为中间可食的部分,而shell包围着它,提供一个接口)。Linux中有许多shell,最常用的是sh、bash和tcsh。除了一些内部命令之外,比如cd和pwd,命令是可执行的二进制文件。对于输入的每一个命令,shell在当前进程的搜索路径指定的目录中(放在PATH环境变量)查找匹配的名字。如果找到了文件,就加载并运行。Shell用上述的fork机制克隆自身,并在子进程中用找到的执行映像文件的内容替换它正在执行的二进制映像(shell)。通常shell等待命令结束,或者说子进程退出。你可以通过输入control-Z发送一个SIGSTOP信号给子进程,把子进程停止并放到后台,让shell重新运行。你可以使用shell命令bg让shell向子进程发送SIGCONT信号,把子进程放到后台并重新运行,它会持续运行直到它结束或者需要从终端输入或输出。
执行文件可以由许多格式甚至可以是一个脚本文件(script file)。脚本文件必须用合适的解释程序识别并运行。例如/bin/sh解释shell script。可执行的目标文件包括了执行代码和数据以及足够的其他信息,时的操作系统可以把它们加载到内存中并执行。Linux中最常用的目标文件类型是ELF,而理论上,Linux灵活到足以处理几乎所有的目标文件格式。
好像文件系统一样,Linux可以支持的二进制格式也是在核心连接的时候直接建立在核心的或者是可以作为模块加载的。核心保存了支持的二进制格式(见图4.3)的列表,当试图执行一个文件的时候,每一个二进制格式都被尝试,直到可以工作。通常,Linux支持的二进制文件是a.out和ELF。可执行文件不需要完全读入内存,而使用叫做demand loading的技术。当进程使用执行映像的一部分的时候它才被调入内存,未被使用的映像可以从内存中废弃。
参见fs/exec.c do_execve()

4.9 ELF
ELF(Executable and Linkable Format 可执行可连接格式)目标文件,由Unix系统实验室设计,现在成为Linux最常用的格式。虽然和其他目标文件格式比如ECOFF和a.out相比,有性能上的轻微开支,ELF感觉更灵活。ELF可执行文件包括可执行代码(有时叫做text)和数据(data)。执行映像中的表描述了程序应该如何放到进程的虚拟内存中。静态连接的映像是用连接程序(ld)或者连接编辑器创建的,单一的映像中包括了运行该映像所需要的所有的代码和数据。这个映像也描述了该映像在内存中的布局和要执行的第一部分代码在映像中的地址。
图4.4象是了静态连接的ELF可执行映像的布局。这是个简单的C程序,打印“hello world”然后退出。头文件描述了它是一个ELF映像,有两个物理头(e_phnum是2),从映像文件的开头第52字节开始(e_phoff)。第一个物理头描述映像中的执行代码,在虚拟地址0x8048000,有65532字节。因为它是静态连接的,所以包括输出“hello world”的调用printf()的所有的库代码。映像的入口,即程序的第一条指令,不是位于映像的起始位置,而在虚拟地址0x8048090(e_entry)。代码紧接着在第二物理头后面开始。这个物理头描述了程序的数据,将会加载到虚拟内存地址0x8059BB8。这块数据可以读写。你会注意到文件中数据的大小是2200字节(p_filesz)而在内存中的大小是4248字节。因为前2200字节包括预先初始化的数据,而接着的2048字节包括会被执行代码初始化的数据。
参见include/linux/elf.h
当Linux把ELF可执行映像加载到进程的虚拟地址空间的时候,它不是实际的加载映像。它设置虚拟内存数据结构,即进程的vm_area_struct和它的页表。当程序执行了page fault的时候,程序的代码和数据会被放到物理内存中。没有用到的程序部分将不会被放到内存中。一旦ELF 二进制格式加载程序满足条件,映像是一个有效的ELF可执行映像,它把进程的当前可执行映像从它的虚拟内存中清除。因为这个进程是个克隆的映像(所有的进程都是),旧的映像是父进程执行的程序的映像(例如命令解释程序shell bash)。清除旧的可执行映像会废弃旧的虚拟内存的数据结构,重置进程的页表。它也会清除设置的其他信号处理程序,关闭打开的文件。在清除过程的最后,进程准备运行新的可执行映像。不管可执行映像的格式如何,进程的mm_struct中都要设置相同的信息。包括指向映像中代码和数据起始的指针。这些数值从ELF可执行映像的物理头中读入,它们描述的部分也被映射到了进程的虚拟地址空间。这也发生在进程的vm_area_struct数据结构建立和页表修改的时候。mm_struct数据结构中也包括指针,指向传递给程序的参数和进程的环境变量。
ELF Shared Libraries(ELF共享库)
动态连接的映像,反过来,不包含运行所需的所有的代码和数据。其中一些放在共享库并在运行的时候连接到映像中。当运行时动态库连接到映像中的时候,动态连接程序(dynamic linker)也要使用ELF共享库的表。Linux使用几个动态连接程序,ld.so.1,libc.so.1和ld-linux.so.1,都在/lib目录下。这些库包括通用的代码,比如语言子例程。如果没有动态连接,所有的程序都必须有这些库的独立拷贝,需要更多的磁盘空间和虚拟内存。在动态连接的情况下,ELF映像的表中包括引用的所有库例程的信息。这些信息指示动态连接程序如何定位库例程以及如何连接到程序的地址空间。
4.10 Scripts Files
脚本文件是需要解释器才能运行的可执行文件。Linux下有大量的解释器,例如wish、perl和命令解释程序比如tcsh。Linux使用标准的Unix约定,在脚本文件的第一行包括解释程序的名字。所以一个典型的脚本文件可能开头是:
#!/usr/bin/wish
脚本文件加载器试图找出文件所用的解释程序。它试图打开脚本文件第一行指定的可执行文件。如果可以打开,就得到一个指向该文件的VFS I 节点的指针,然后执行它去解释脚本文件。脚本文件的名字成为了参数0(第一个参数),所有的其他参数都向上移动一位(原来的第一个参数成为了第二个参数等等)。加载解释程序和Linux加载其他可执行程序一样。Linux依次尝试各种二进制格式,直到可以工作。这意味着理论上你可以把几种解释程序和二进制格式堆积起来,让Linux的二进制格式处理程序更加灵活。
参见fs/binfmt_script.c do_load_script()
5、Interprocess Communication Mechanisms(进程间通讯机制)
进程之间互相通讯并和核心通讯,协调它们的行为。Linux支持一些进程间通讯(IPC)的机制。信号和管道是其中的两种,Linux还支持系统V IPC(用首次出现的Unix的版本命名)的机制。
5.1 Signals(信号)
信号是Unix系统中使用的最古老的进程间通讯的方法之一。用于向一个或多个进程发送异步事件的信号。信号可以用键盘终端产生,或者通过一个错误条件产生,比如进程试图访问它的虚拟内存中不存在的位置。Shell也使用信号向它的子进程发送作业控制信号。
有一些信号有核心产生,另一些可以由系统中其他有权限的进程产生。你可以使用kill命令(kill –l)列出你的系统的信号集,在我的Linux Intel系统输出:
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGIOT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 17) SIGCHLD
18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN
22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO
30) SIGPWR
在Alpha AXP Linux系统上编号不同。进程可以选择忽略产生的大多数信号,有两个例外:SIGSTOP(让进程停止执行)和SIGKILL(让进程退出)不可以忽略,虽然进程可以选择它如何处理信号。进程可以阻塞信号,如果它不阻塞信号,它可以选择自己处理或者让核心处理。如果核心处理,将会执行该信号的缺省行为。例如,进程接收到SIGFPE(浮点意外)的缺省动作是产生core并退出。信号没有固有的优先级,如果一个进程同时产生了两个信号,它们会以任意顺序出现在进程中并按任意顺序处理。另外,也没有机制可以处理统一种类的多个信号。进程无法知道它接收了1还是42个SIGCONT信号。
Linux用进程的task_struct中存放的信息来实现信号机制。支持的信号受限于处理器的字长。32位字长的处理器可以有32中信号,而64位的处理器,比如Alpha AXP可以有多达64种信号。当前待处理的信号放在signal域,blocked域放着要阻塞的信号掩码。除了SIGSTOP和SIGKILL,所有的信号都可以被阻塞。如果产生了一个被阻塞的信号,它一直保留待处理,直到被解除阻塞。Linux也保存每一个进程如何处理每一种可能的信号的信息,这些信息放在一个sigaction的数据结构数组中,每一个进程的task_struct都有指针指向对应的数组。这个数组中包括处理这个信号的例程的地址,或者包括一个标志,告诉Linux该进程是希望忽略这个信号还是让核心处理。进程通过执行系统调用改变缺省的信号处理,这些调用改变适当的信号的sigaction和阻塞的掩码。
并非系统中所有的进程都可以向其他每一个进程发送信号,只有核心和超级用户可以。普通进程只可以向拥有相同uid和gid或者在相同进程组的进程发送信号。通过设置task——struct的signal中适当的位产生信号。如果进程不阻塞信号,而且正在等待但是可以中断(状态是Interruptible),那么它的状态被改为Running并确认它在运行队列,通过这种方式把它唤醒。这样调度程序在系统下次调度的时候会把它当作一个运行的候选。如果需要缺省的处理,Linux可以优化信号的处理。例如如果信号SIGWINCH(X window改变焦点)发生而使用缺省的处理程序,则不需要做什么事情。
信号产生的时候不会立刻出现在进程中,它们必须等到进程下次运行。每一次进程从系统调用中退出的时候都要检查它的signal和blocked域,如果有任何没有阻塞的信号,就可以发送。这看起来好像非常不可靠,但是系统中的每一个进程都在调用系统调用,比如向终端写一个字符的过程中。如果愿意,进程可以选择等待信号,它们挂起在Interruptible状态,直到有了一个信号。Linux信号处理代码检查sigaction结构中每一个当前未阻塞的信号。
如果信号处理程序设置为缺省动作,则核心会处理它。SIGSTOP信号的缺省处理是把当前进程的状态改为Stopped,然后运行调度程序,选择一个新的进程来运行。SIGFPE信号的缺省动作是让当前进程产生core(core dump),让它退出。变通地,进程可以指定自己的信号处理程序。这是一个例程,当信号产生的时候调用而且sigaction结构包括这个例程的地址。Linux必须调用进程的信号处理例程,至于具体如何发生是和处理器相关。但是,所有的CPU必须处理的是当前进程正运行在核心态,并正准备返回到调用核心或系统例程的用户态的进程。解决这个问题的方法是处理该进程的堆栈和寄存器。进程程序计数器设为它的信号处理程序的地址,例程的参数加到调用结构或者通过寄存器传递。当进程恢复运行的时候显得信号处理程序是正常的调用。
Linux是POSIX兼容的,所以进程可以指定调用特定的信号处理程序的时候要阻塞的信号。这意味着在调用进程的信号处理程序的时候改变blocked掩码。信号处理程序结束的时候,blocked掩码必须恢复到它的初始值。因此,Linux在收到信号的进程的堆栈中增加了对于一个整理例程的调用,把blocked掩码恢复到初始值。Linux也优化了这种情况:如果同时几个信号处理例程需要调用的时候,就在它们堆积在一起,每次退出一个处理例程的时候就调用下一个,直到最后才调用整理例程。
5.2 Pipes(管道)
普通的Linux shell都允许重定向。例如:
$ ls | pr | lpr
把列出目录文件的命令ls的输出通过管道接到pr命令的标准输入上进行分页。最后,pr命令的标准输出通过管道连接到lpr命令的标准输入上,在缺省打印机上打印出结果。管道是单向的字节流,把一个进程的标准输出和另一个进程的标准输入连接在一起。没有一个进程意识到这种重定向,和它平常一样工作。是shell建立了进程之间的临时管道。在Linux中,使用指向同一个临时VFS I节点(本身指向内存中的一个物理页)的两个file数据结构来实现管道。图5.1显示了每一个file数据结构包含了不同的文件操作例程的向量表的指针:一个用于写,另一个从管道中读。这掩盖了和通用的读写普通文件的系统调用的不同。当写进程向管道中写的时候,字节拷贝到了共享的数据页,当从管道中读的时候,字节从共享页中拷贝出来。Linux必须同步对于管道的访问。必须保证管道的写和读步调一致,它使用锁、等待队列和信号(locks,wait queues and signals)。
参见include/linux/inode_fs.h
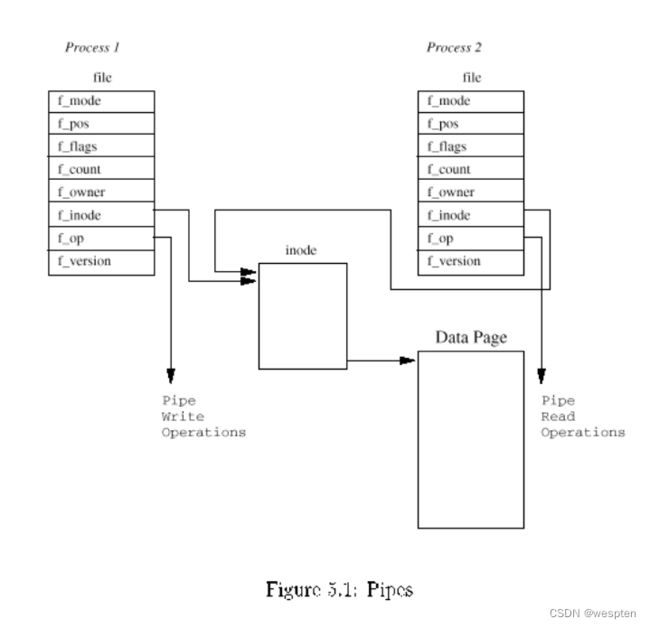
当写进程向管道写的时候,它使用标准的write库函数。这些库函数传递的文件描述符是进程的file数据结构组中的索引,每一个都表示一个打开的文件,在这种情况下,是打开的管道。Linux系统调用使用描述这个管道的file数据结构指向的write例程。这个write例程使用表示管道的VFS I 节点存放的信息,来管理写的请求。如果有足够的空间把所有的字节都写导管到中,只要管道没有被读进程锁定,Linux为写进程上锁,并把字节从进程的地址空间拷贝到共享的数据页。如果管道被读进程锁定或者空间不够,当前进程睡眠,并放在管道I节点的等待队列中,并调用调度程序,运行另外一个进程。它是可以中断的,所以它可以接收信号。当管道中有了足够的空间写数据或者锁定解除,写进程就会被读进程唤醒。当数据写完之后,管道的VFS I 节点锁定解除,管道I节点的等待队列中的所有读进程都会被唤醒。
参见fs/pipe.c pipe_write()
从管道中读取数据和写数据非常相似。进程允许进行非阻塞的读(依赖于它们打开文件或者管道的模式),这时,如果没有数据可读或者管道被锁定,会返回一个错误。这意味着进程会继续运行。另一种方式是在管道的I节点的等待队列中等待,直到写进程完成。如果管道的进程都完成了操作,管道的I节点和相应的共享数据页被废弃。
参见fs/pipe.c pipe_read()
Linux也可以支持命名管道,也叫FIFO,因为管道工作在先入先出的原则下。首先写入管道的数据是首先被读出的数据。不想管道,FIFO不是临时的对象,它们是文件系统中的实体,可以用mkfifo命令创建。只要有合适的访问权限,进程就可以使用FIFO。FIFO的大开方式和管道稍微不同。一个管道(它的两个file数据结构,VFS I节点和共享的数据页)是一次性创建的,而FIFO是已经存在,可以由它的用户打开和关闭的。Linux必须处理在写进程打开FIFO之前打开FIFO读的进程,以及在写进程写数据之前读的进程。除了这些,FIFO几乎和管道的处理完全一样,而且它们使用一样的数据结构和操作。
5.3 System V IPC mechanisms (系统V IPC机制)
Linux支持三种首次出现在Unix 系统V(1983)的进程间通讯的机制:消息队列、信号灯和共享内存(message queues, semaphores and shared memory)。系统V IPC机制共享通用的认证方式。进程只能通过系统调用,传递一个唯一的引用标识符到核心来访问这些资源。对于系统V IPC对象的访问的检查使用访问许可权,很象对于文件访问的检查。对于系统V IPC对象的访问权限由对象的创建者通过系统调用创建。每一种机制都使用对象的引用标识符作为资源表的索引。这不是直接的索引,需要一些操作来产生索引。
系统中表达系统V IPC对象的所有Linux数据结构都包括一个ipc_perm的数据结构,包括了创建进程的用户和组标识符,对于这个对象的访问模式(属主、组和其他)和IPC对象的key。Key 用作定位系统V IPC对象的引用标识符的方法。支持两种key:公开和四有的。如果key是公开的,那么系统中的任何进程,只要通过了权限检查,就可以找到对应的系统V IPC对象的引用标识符。系统V IPC对象不能使用key引用,必须使用它们的引用标识符。
参见include/linux/ipc.h
5.4 Message Queues(消息队列)
消息队列允许一个或多个进程写消息,一个或多个进程读取消息。Linux维护了一系列消息队列的msgque 向量表。其中的每一个单元都指向一个msqid_ds的数据结构,完整描述这个消息队列。当创建消息队列的时候,从系统内存中分配一个新的msqid_ds的数据结构并插入到向量表中
每一个msqid_ds数据结构都包括一个ipc_perm的数据结构和进入这个队列的消息的指针。另外,Linux保留队列的改动时间,例如上次队列写的时间等。Msqid_ds队列也包括两个等待队列:一个用于向消息队列写,另一个用于读。
参见include/linux/msg.h

每一次一个进程试图向写队列写消息,它的有效用户和组的标识符就要和队列的ipc_perm数据结构的模式比较。如果进程可以想这个队列写,则消息会从进程的地址空间写到msg数据结构,放到消息队列的最后。每一个消息都带有进程间约定的,应用程序指定类型的标记。但是,因为Linux限制了可以写的消息的数量和长度,可能会没有空间容纳消息。这时,进程会被放到消息队列的写等待队列,然后调用调度程序选择一个新的进程运行。当一个或多个消息从这个消息队列中读出去的时候会被唤醒。
从队列中读是一个相似的过程。进程的访问权限一样被检查。一个读进程可以选择是不管消息的类型从队列中读取第一条消息还是选择特殊类型的消息。如果没有符合条件的消息,读进程会被加到消息队列的读等待进程,然后运行调度程序。当一个新的消息写到队列的时候,这个进程会被唤醒,继续运行。
5.5 Semaphores(信号灯)
信号灯最简单的形式就是内存中一个位置,它的取值可以由多个进程检验和设置。检验和设置的操作,至少对于关联的每一个进程来讲,是不可中断或者说有原子性:只要启动就不能中止。检验和设置操作的结果是信号灯当前值和设置值的和,可以是正或者负。根据测试和设置操作的结果,一个进程可能必须睡眠直到信号灯的值被另一个进程改变。信号灯可以用于实现重要区域(critical regions),就是重要的代码区,同一时刻只能有一个进程运行。
比如你有许多协作的进程从一个单一的数据文件读写记录。你可能希望对文件的访问必须严格地协调。你可以使用一个信号灯,初始值1,在文件操作的代码中,加入两个信号灯操作,第一个检查并把信号灯的值减小,第二个检查并增加它。访问文件的第一个进程试图减小信号灯的数值,如果成功,信号灯的取值成为0。这个进程现在可以继续运行并使用数据文件。但是,如果另一个进程需要使用这个文件,现在它试图减少信号灯的数值,它会失败因为结果会是-1。这个进程会被挂起直到第一个进程处理完数据文件。当第一个进程处理完数据文件,它会增加信号灯的数值成为1。现在等待进程会被唤醒,这次它减小信号灯的尝试会成功。
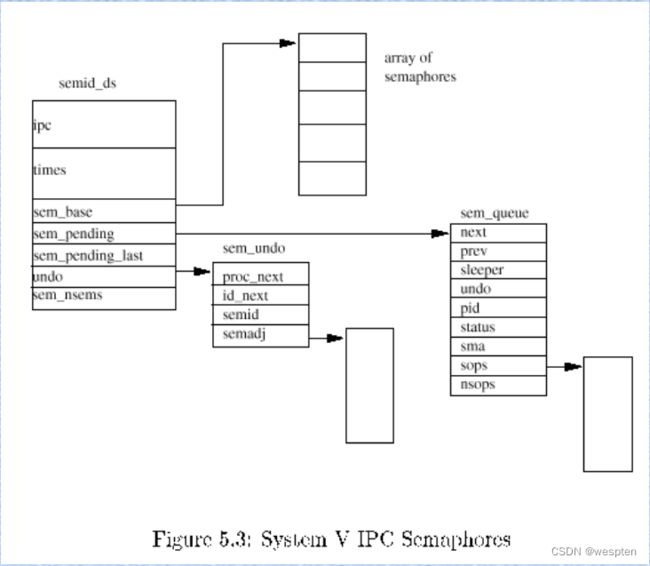
每一个系统V IPC信号灯对象都描述了一个信号灯数组,Linux使用semid_ds数据结构表达它。系统中所有的semid_ds数据结构都由semary指针向量表指向。每一个信号灯数组中都有sem_nsems,通过sem_base指向的一个sem数据结构来描述。所有允许操作一个系统V IPC信号灯对象的信号灯数组的进程都可以通过系统调用对它们操作。系统调用可以指定多种操作,每一种操作多用三个输入描述:信号灯索引、操作值和一组标志。信号灯索引是信号灯数组的索引,操作值是要增加到当前信号灯取值的数值。首先,Linux检查所有的操作是否成功。只有操作数加上信号灯的当前值大于0或者操作值和信号灯的当前值都是0,操作才算成功。如果任意信号灯操作失败,只要操作标记不要求系统调用无阻塞,Linux会挂起这个进程。如果进程要挂起,Linux必须保存要进行的信号灯操作的状态并把当前进程放到等待队列重。它通过在堆栈中建立一个sem_queue的数据结构并填满它来实现上述过程。这个新的sem_queue数据结构被放到了这个信号灯对象的等待队列的结尾(使用sem_pending和sem_pending_last指针)。当前进程被放到了这个sem_queue数据结构的等待队列中(sleeper),调用调度程序,运行另外一个进程。
参见include/linux/sem.h
如果所有的信号灯操作都成功,当前的进程就不需要被挂起。Linux继续向前并把这些操作应用到信号灯数组的合适的成员上。现在Linux必须检查任何睡眠或者挂起的进程,它们的操作现在可能可以实施。Linux顺序查找操作等待队列(sem_pending)中的每一个成员,检查现在它的信号灯操作是否可以成功。如果可以它就把这个sem_queue数据结构从操作等待表中删除,并把这种信号灯操作应用到信号灯数组。它唤醒睡眠的进程,让它在下次调度程序运行的时候可以继续运行。Linux从头到尾检查等待队列,直到不能执行信号灯操作无法唤醒更多的进程为止。
在信号灯操作中有一个问题:死锁(deadlock)。这发生在一个进程改变了信号灯的值进入一个重要区域(critical region)但是因为崩溃或者被kill而没有离开这个重要区域的情况下。Linux通过维护信号灯数组的调整表来避免这种情况。就是如果实施这些调整,信号灯就会返回一个进程的信号灯操作前的状态。这些调整放在sem_undo数据结构中,排在sem_ds数据结构的队列中,同时排在使用这些信号灯的进程的task_struct数据结构的队列中。
每一个独立的信号灯操作可能都需要维护一个调整动作。Linux至少为每一个进程的每一个信号灯数组都维护一个sem_undo的数据结构。如果请求的进程没有,就在需要的时候为它创建一个。这个新的sem_undo数据结构同时在进程的task_struct数据结构和信号灯队列的semid_ds数据结构的队列中排队。对信号灯队列中的信号灯执行操作的时候,和这个操作值相抵消的值加到这个进程的sem_undo数据结构的调整队列这个信号灯的条目上。所以,如果操作值为2,那么这个就在这个信号灯的调整条目上增加-2。
当进程被删除,比如退出的时候,Linux遍历它的sem_undo数据结构组,并实施对于信号灯数组的调整。如果删除信号灯,它的sem_undo数据结构仍旧停留在进程的task_struct队列中,但是相应的信号灯数组标识符标记为无效。这种情况下,清除信号灯的代码只是简单地废弃这个sem_undo数据结构。
5.6 Shared Memory(共享内存)
共享内存允许一个或多个进程通过同时出现在它们的虚拟地址空间的内存通讯。这块虚拟内存的页面在每一个共享进程的页表中都有页表条目引用。但是不需要在所有进程的虚拟内存都有相同的地址。象所有的系统V IPC对象一样,对于共享内存区域的访问通过key控制,并进行访问权限检查。内存共享之后,就不再检查进程如何使用这块内存。它们必须依赖于其他机制,比如系统V的信号灯来同步对于内存的访问。
每一个新创建的内存区域都用一个shmid_ds数据结构来表达。这些数据结构保存在shm_segs向量表中。Shmid_ds数据结构描述了这个共享内存取有多大、多少个进程在使用它以及共享内存如何映射到它们的地址空间。由共享内存的创建者来控制对于这块内存的访问权限和它的key是公开或私有。如果有足够的权限它也可以把共享内存锁定在物理内存中。
参见include/linux/sem.h
每一个希望共享这块内存的进程必须通过系统调用粘附(attach)到虚拟内存。这为该进程创建了一个新的描述这块共享内存的vm_area_struct数据结构。进程可以选择共享内存在它的虚拟地址空间的位置或者由Linux选择一块足够的的空闲区域。
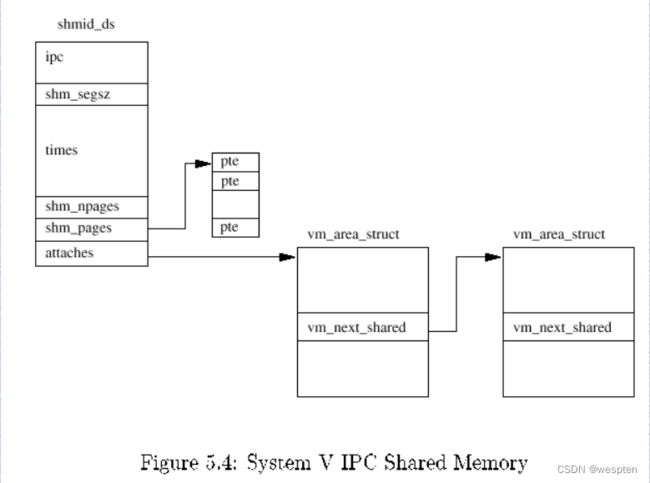
这个新的vm_area_struct结构放在由shmid_ds指向的vm_area_struct列表中。通过vm_next_shared和vm_prev_shared把它们连在一起。虚拟内存在粘附的时候其实并没有创建,而发生在第一个进程试图访问它的时候。
在一个进程第一次访问共享虚拟内存的其中一页的时候,发生一个page fault。当Linux处理这个page fault的时候,它找到描述它的vm_area_struct数据结构。这里包含了这类共享虚拟内存的处理例程的指针。共享内存的page fault处理代码在这个shmid_ds的页表条目列表中查找,看是否存在这个共享虚拟内存页的条目。如果不存在,它就分配一个物理页,并为它创建一个页表条目。这个条目不但进入当前进程的页表,也存到这个shmid_ds。这意味着当下一个进程试图访问这块内存并得到一个page fault的时候,共享内存错误处理代码也会让这个进程使用这个新创建的物理页。所以,是第一个访问共享内存页的进程使得这一页被创建,而随后访问的其他进程使得此页被加到它们的虚拟地址空间。
当进程不再需要共享虚拟内存的时候,它们从中分离(detach)出来。只要仍旧有其他进程在使用这块内存,这种分离只是影响当前的进程。它的vm_area_struct从shmid_ds数据结构中删除,并释放。当前进程的页表也进行更新,使它共享过的虚拟内存区域无效。当共享这块内存的最后一个进程从中分离出的时候,共享内存当前在物理内存中的页被释放,这块共享内存的shmid_ds数据结构也被释放。
如果共享的虚拟内存没有被锁定在物理内存中的话会更加复杂。在这种情况下,共享内存的页可能在系统大量使用内存的时候交换到了系统的交换磁盘。共享内存如何交换初和交换入物理内存在第3小节中有描述。
6、Peripheral Component Interconnect(PCI)
PCI好像它的名字暗示的一样,是描述如何通过一个结构化和可控制的方式把系统中的外设组件连接起来的一个标准。标准的PCI Local Bus规范描述了系统组件电气连接的方法和它们行为的方法。本小节探讨Linux核心如何初始化系统的PCI总线和设备。
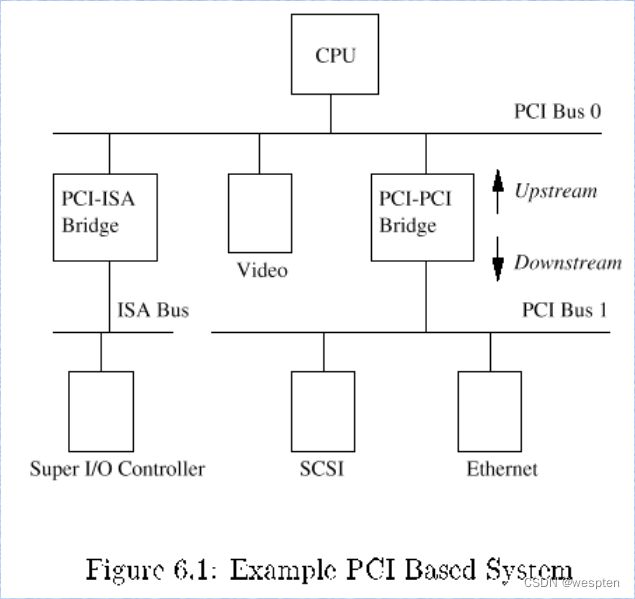
图6.1是一个PCI基础的系统的逻辑图。PCI总线和PCI-PCI桥(bridge)是系统组件联系在一起的粘合剂。CUP和video设备连在主要的PCI总线,PCI总线0。一个特殊的PCI设备,PCI-PCI桥把主总线连接到次PCI总线,PCI总线1。按照PCI规范的术语,PCI总线1描述成为PCI-PCI桥的下游而PCI总线0是桥的上游。连接在次PCI总线上的是系统的SCSI和以太网设备。物理上桥、次要PCI总线和这两种设备可以在同一块PCI卡上。系统中的PCI-ISA桥支持老的、遗留的ISA设备,本图显示了一个超级I/O控制芯片,控制键盘、鼠标和软驱。
6.1 PCI Address Space(PCI地址空间)
CPU和PCI设备需要访问它们所共享的内存。这些内存让设备驱动程序控制这些PCI设备并在它们之间传递信息。一般地共享的内存包括设备的控制和状态寄存器。这些寄存器用于控制设备和读取它的状态。例如:PCI SCSI设备驱动程序可以读取SCSI设备的状态寄存器,判断它是否可以向SCSI磁盘写一块信息。或者它可以写入控制寄存器让它关闭的设备开始运行。
CPU的使用的系统内存可以用作这种共享内存,但是如果这样的话,每一次PCI设备访问内存,CPU都不得不停顿,等待PCI设备完成。对于内存的访问通常有限制,同一时间只能有一个系统组件允许访问。这会使得系统速度降低。允许系统的外部设备在一个不受控的方式下访问主内存也不是一个好主意。这会非常危险:一个恶意的设备会让系统非常不稳定。
外部设备由它们自己的内存空间。CPU可以访问这些空间,但是设备对于系统内存的访问受到严格的控制,必须通过DMA(Direct Memory Access直接内存存取)通道。ISA设备可以访问两种地址空间:ISA I/O(输入/输出)和ISA内存。PCI由三中:PCI I/O、PCI内存和PCI配置空间(configuration space)。CPU可以访问所有的地址空间其中PCI I/O和PCI内存地址空间由设备驱动程序使用而PCI配置空间由Linux和心中的PCI初始化代码使用。
Alpha AXP处理器没有对于除了系统地址空间之外的地址空间的天生的访问模式。它需要使用支持芯片来访问象PCI配置空间这样的其他地址空间。它使用了一个地址空间的映射方案,从巨大的虚拟地址空间中偷出一部分映射到PCI地址空间。
6.2 PCI Configuration Headers(PCI配置头)
系统中的每一个PCI设备,包括PCI-PCI桥都由一个配置数据结构,位于PCI配置地址空间中。PCI配置头允许系统识别和控制设备。这个头位于PCI配置地址空间的确切位置依赖于设备使用的PCI拓扑。例如,插在PC主板一个PCI槽位的一个PCI显示卡配置头会在一个位置,而如果它被插到另一个PCI槽位则它的头会出现在PCI配置内存中的另一个位置。但是不管这些PCI设备和桥在什么位置,系统都可以发现并使用它们配置头中的状态和配置寄存器来配置它们。
通常,系统的设计使得每一个PCI槽位的PCI配置头都有一个和它在板上的槽位相关的偏移量。所以,举例来说,板上的第一个槽位的PCI配置可能位于偏移0而第二个槽位的在偏移256(所有的头都一样长度,256字节),依此类推。定义了系统相关的硬件机制使得PCI配置代码可以尝试检查一个给定的PCI总线上的所有可能的PCI配置头,试图读取头中的一个域(通常是Vendor Identification 域)得到一些错误,从而知道那些设备存在而那些设备不存在。PCI Local Bus规范描述了一种可能的错误信息:试图读取一个空的PCI槽位的Verdor Identification和Device Indentification域时候返回0xFFFFFFFF。

图6.2显示了256字节的PCI配置头的布局。它包括以下域:
参见include/linux/pci.h
Vendor Identification 唯一的数字,描述这个PCI设备的发明者。Digital的PCI Vendor Identification 是0x1011而Intel是0x8086。
Device Identification 描述设备自身的唯一数字。例如Digital的21141快速以太网设备的设备标识符是0x0009。
Status 此域给除了设备的状态,它的位的含义由PCI Local Bus规范规定。
Command 系统通过写这个域控制这个设备。例如:允许设备访问PCI I/O内存。
Class Code 标识了设备的类型。对于每一种设备都有标准分类:显示、SCSI等等。对于SCSI的类型编码是0x0100。
Base Address Registers 这些寄存器用于确定和分配设备可以使用的PCI I/O和PCI内存的类型、大小和位置。
Interrupt Pin PCI卡的物理管脚中的4个用于向PCI总线传递中断。标准中把它们标记为A、B、C和D。Interrupt Pin域描述了这个PCI设备使用那个管脚。通常对于一个设备来说这时硬件决定的。就是说每一次系统启动的时候,这个设备都使用同一个中断管脚。这些信息允许中断处理子系统管理这些设备的中断。
Interrupt Line PCI配置头中的Interrupt Line域用于在PCI初始化代码、设备驱动程序和Linux的中断处理子系统之间传递中断控制。写在这里的数字对于设备驱动程序来讲是没有意义的,但是它可以让中断处理程序正确地把一个中断从PCI设备发送到Linux操作系统中正确的设备驱动程序的中断处理代码处。Linux如何处理中断参看第7小节。
6.3 PCI I/O and PCI Memory Address(PCI I/O和PCI内存地址)
这两种地址空间用于设备和CPU上运行的Linux核心的它们的设备驱动程序通讯。例如:DECchip 21141快速以太网设备把它的内部寄存器映射到了PCI I/O空间。然后它的Linux设备驱动程序通过读写这些寄存器来控制设备。显示驱动程序通常使用大量的PCI内存空间来放置显示信息。
直到PCI系统建立起来并使用PCI配置头中的Command域打开了设备对于这些地址空间的访问为止,设备都无法访问这些空间。应该注意的是只有PCI配置代码读写PCI配置地址,Linux的设备驱动程序只是读写PCI I/O和PCI内存地址。
6.4 PCI-ISA Bridges(PCI-ISA桥)
这种桥把对于PCI I/O和PCI内存地址空间的访问转换成为ISA I/O和ISA内存访问,用来支持ISA设备。现在销售的多数系统都包括几个ISA总线插槽和几个PCI总线插槽。这种向后的兼容的需要会不断减少,将来会有只有PCI的系统。在早期的Intel 8080基础的PC时代,系统中的ISA设备的ISA 地址空间(I/O和内存)就被固定下来。甚至一个S5000 Alpha AXP基础的计算机系统的ISA软驱驱动器的ISA I/O地址也会和第一台IBM PC一样。PCI规范保留了PCI I/O和PCI内存的地址空间中的较低的区域保留给系统中的ISA外设并使用一个PCI-ISA桥把所有对于这些区域的PCI内存访问转换为ISA访问。

6.5 PCI-PCI Bridges(PCI-PCI桥)
PCI-PCI桥是特殊的PCI设备,把系统中的PCI总线粘和在一起。简单系统中只有一个PCI总线,当时单个PCI总线可以支持的PCI设备的数量有电气限制。使用PCI-PCI桥增加更多的PCI总线允许系统支持更多的PCI设备。这对于高性能的服务器尤其重要。当然,Linux完全支持使用PCI-PCI桥的使用。
6.5.1 PCI-PCI Bridges: PCI I/O and PCI Memory Windows
PCI-PCI桥只向下游传递对于PCI I/O和PCI内存读和写的一个子集。例如在图6.1中,只有读和写的地址属于SCSI或者以太网设备的时候PCI-PCI桥才会把读写的地址从PCI总线0传递到总线1,其余的都被忽略。这种过滤阻止了不必要的地址信息遍历系统。为了达到这个目的,PCI-PCI桥必须编程设置它们必须从主总线向次总线通过的PCI I/O和PCI内存地址空间访问的基础(base)和限制。一旦系统中的PCI-PCI桥设置好,只要Linux设备驱动程序只是通过这些窗口存取PCI I/O和PCI内存空间,PCI-PCI桥是不可见的。这是个重要的特性,使得Linux的PCI设备驱动程序的作者的日子好过了。但是它也让Linux下的PCI-PCI桥在一定程度上需要技巧才能配置,我们不久就会看到。
6.5.2 PCI-PCI Bridges: PCI Configuration Cycles and PCI Bus Numbering(PCI-PCI桥:PCI配置cycle和PCI总线编号)
既然CPU的PCI初始化代码可以定位不在主PCI总线上的设备,必须有一种机制使得桥可以决定是否把配置cycle从它的主接口传递到次接口上。一个cycle就是它显示在PCI总线上的地址。PCI规范定义了两种PCI地址配置格式:类型0和类型1,分别在图6.3和图6.4中显示。类型0的PCI配置cycle不包含总线号,被这个PCI总线上的所有的PCI设备解释用于PCI地址配置。配置cycle的位32:11看作是设备选择域。设计系统的一个方法是让每一个位选择一个不同的设备。这种情况下为11可能选择槽位0的PCI设备,位12选择槽位1的PCI设备,依此类推。另一种方法是把设备的槽位号直接写到位31:11中。一个系统使用哪一种机制依赖于系统的PCI内存控制器。
类型1的PCI配置cycle包括一个PCI总线号,这种配置循环被除了PCI-PCI桥之外的所有PCI设备忽略。所有看到了类型1的PCI配置cycle的PCI-PCI桥都可以把这些信息向它们的下游传送。一个PCI-PCI桥是否忽略PCI配置循环或者向它的下游传递,依赖于这个桥是如何配置的。每一个PCI-PCI桥都有一个主总线接口号和一个次总线接口号。主总线接口离CPU最近而次总线接口是离CPU最远的。每一个PCI-PCI桥都还有一个附属总线编号,这是在第二个总线接口之外可以桥接的最大的PCI总线数目。或者说,附属总线编号是PCI-PCI桥下游的最大的PCI总线编号。当PCI-PCI桥看到一个类型1的PCI配置cycle的时候,它做以下事情:
如果指定的总线编号不在桥的次总线编号和总线的附属编号之间就忽略它。
如果指定的总线编号和桥的次总线编号符合就把它转变成为类型0的配置命令
如果指定的总线编号大于次要总线编号而小于或等于附属总线编号,就不改变地传递到次要总线接口上。
所以,如果我们希望寻址图6.9的拓扑中总线3上的设备1,我们必须从CPU生成一个类型1的配置命令。桥1不改变地传递到总线1,桥2忽略它但是桥3把它转换成一个类型0的配置命令,并把它发送到总线3,使设备1响应它。
每一个独立的操作系统负责在PCI配置阶段分配总线编号,但是不管使用哪一种编码方案,对于系统中所有的PCI-PCI桥,以下陈述都必须是正确的:
所有位于一个PCI-PCI桥后面的PCI总线的编码都必须在次总线编号和附属总线编号之间(包含)
如果违背了这条规则,则PCI-PCI桥将无法正确地传递和转换类型1的PCI配置cycle,系统无法成功地找到并初始化系统中的PCI设备。为了完成编码方案,Linux按照特定的顺序配置这些特殊设备。参看6.6.2节对于Linux PCI桥和总线编码方案的描述以及一个可以工作的例子。

6.6 Linux PCI Initialization(Linux PCI初始化过程)
Linux中PCI初始化代码分为三个逻辑部分:
PCI Device Driver 这个伪设备驱动程序从总线0开始查找PCI系统,定位系统中所有的PCI设备和桥。它建立一链接的数据结构的列表,描述系统的拓扑。另外,它还为系统中所有的桥编码。
参见drivers/pci/pci.c and include/linux/pci.h
PCI BIOS 这个软件层提供了PCI BIOS ROM规范中描述的服务。即使Alpha AXP没有BIOS服务,在Linux核心也有提供了相同的功能的等价代码。
参见arch/*/kernel/bios32.c
PCI Fixup 系统相关的整理代码,整理和系统相关的在PCI初始化最后的内存疏松的情况。
参见arch/*/kernel/bios32.c
6.6.1 Linux Kernel PCI Data Structures(Linux核心的PCI数据结构)
当Linux核心初始化PCI系统的时候它建立反映系统真实的PCI拓扑结构的数据结构。图6.5显示了数据结构之间的关系,它用来描述了图6.1中示例的PCI系统。
每一个PCI设备(包括PCI-PCI桥)都用一个pci_dev的数据结构描述。每一个PCI总线用一个pci_bus的数据结构描述。结果是一个PCI总线的树型结构,每一个总线上有粘附着一些子PCI设备。因为一个PCI总线只能通过PCI-PCI桥达到(除了主PCI总线,总线0),每一个pci_bus都包括一个它要通过的PCI设备的指针(这个PCI-PCI桥)。这个PCI设备是这个PCI总线的父总线的一个子设备。
图6.5中没有显示的还有一个指向系统中所有的PCI设备的指针:pci_devices。系统中所有的PCI设备的pci_dev的数据结构都排在这个队列中。Linux核心使用这个队列快速查找系统中所有的PCI设备。
6.6.2 The PCI Device Driver(PCI 设备驱动程序)
PCI设备驱动程序完全不是一个真正的设备驱动程序,只是系统初始化的时候操作系统调用的一个函数。PCI初始化代码必须扫描系统中所有的PCI总线,查找系统中所有的PCI设备(包括PCI-PCI桥接设备)。它使用PCI BIOS代码来查看它当前扫描的PCI总线上的每一个可能的槽位是否被占用。如果这个PCI槽位占用,它就建立一个描述这个设备的pci_dev数据结构,并把它链接到已知PCI设备的列表中(由pci_deivices指向)。
参见drivers/pci/pci.c Scan_bus()
PCI初始化代码从PCI总线0开始扫描。它试图读出每一个可能的PCI槽位中每一个可能的PCI设备的Vendor Identification和Device Identification域。当它找到了占用的槽位它就建立一个pci_dev数据结构来描述它。PCI初始化代码所建立的所有的pci_dev数据结构(包括所有的PCI-PCI桥)都链接到一个链接表:pci_devices。
如果找到的设备是一个PCI-PCI桥,则建立一个pci_bus的数据结构,并链接到pci_root指向的由pci_bus和pci_dev数据结构组成的树上。PCI的初始代码可以判断PCI设备是否PCI-PCI桥,因为它的分类编码(class code)是0x060400。然后Linux核心配置它刚刚找到的PCI-PCI桥的另一端的PCI总线(下游)。如果找到更多的PCI-PCI桥,它们都一样被配置。这个过程成为深度(depthwize)算法:系统在宽度搜索之前先在深度展开。看图6.1,Linux会首先配置PCI总线1和它的以太网和SCSI设备,然后配置PCI总线0上的显示设备。
在Linux向下游查找PCI总线的时候它必须配置介入的PCI-PCI桥的次总线和附属总线编号。这些在下面的6.6.2节详细描述:
Configuring PCI-PCI Bridges – Assigning PCI Bus Numbers(配置PCI-PCI桥-分配PCI总线编号)
对于传送通过它们进行的PCI I/O、PCI内存或者PCI配置地址空间的读写,PCI-PCI桥必须直到以下:
Primary Bus Number 刚好在PCI-PCI桥上游的总线编号
Secondary Bus Number 刚好在PCI-PCI桥下游的总线编号
Subordinate Bus Number 从这个桥向下可以达到的所有总线中最高的总线编号。
PCI I/O and PCI Memory Windows 从这个PCI-PCI桥向下的所有的地址的PCI I/O地址空间和PCI 内存空间的窗口的base和size。
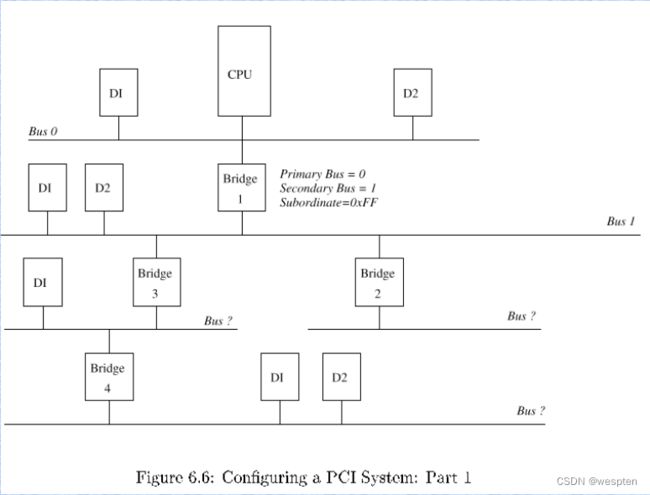
问题是当你希望配置任何指定的PCI-PCI桥的时候你并不知道这个桥的附属总线数目。你不知道是否下游还有其他PCI-PCI桥。就算知道,你也不知道它们将会被分配什么编号。答案是使用一个深度递归算法(depthwise recursive algorithm)。在每一个总线上找到任何PCI-PCI桥的时候都就给它们分配编号。对于找到的每一个PCI-PCI桥,就给它的次总线分配编号,并给它分配临时的附属总线编号0xFF,并扫描它的下游所有的PCI-PCI桥并分配编号。这看起来相当复杂,但是下面的实际例子能使这个过程更清楚。
PCI-PCI Bridge Numbering: Step 1 参考图6.6中的拓扑,扫描找到的第一个桥是桥1(Bridge1)。桥1下游的PCI总线编号为1,桥1分配一个次总线号1和一个临时的附属总线编号0xFF。这意味着指定PCI总线1或更高的所用的类型1的PCI配置地址会穿过桥1到达PCI总线1。如果它们的总线编号是1,就转换成为类型0的配置cycle,否则对于其他的总线编号就不变。这也正是Linux PCI初始化代码需要做的,这样才能访问并扫描PCI总线1。

PCI-PCI Bridge Numbering: Step 2 Linux使用深度算法,所以初始化代码开始扫描PCI总线1。这是它找到了PCI-PCI桥2,桥2之外没有其他的PCI-PCI桥,所以它的附属总线编号成为2,和它的次接口一样。图6.7显示了总线和PCI-PCI桥这时是如何编码的。
PCI-PCI Bridge Numbering:Step 3 PCI初始化代码回来扫描PCI总线1,找到了另一个PCI-PCI桥3。它的主总线接口赋值1而它的次总线接口是3,它的附属总线编号是0xFF。图6.8显示了系统这时是如何配置的。带有总线编号1、2或3的类型1的PCI配置cycle现在可以正确地传送到适当的PCI总线。
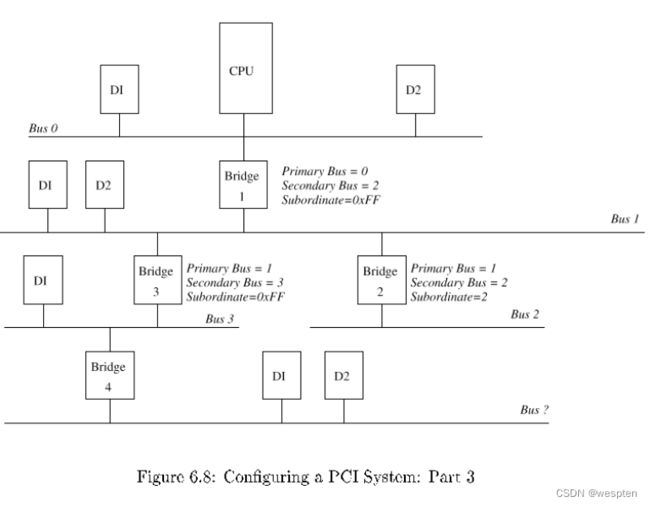
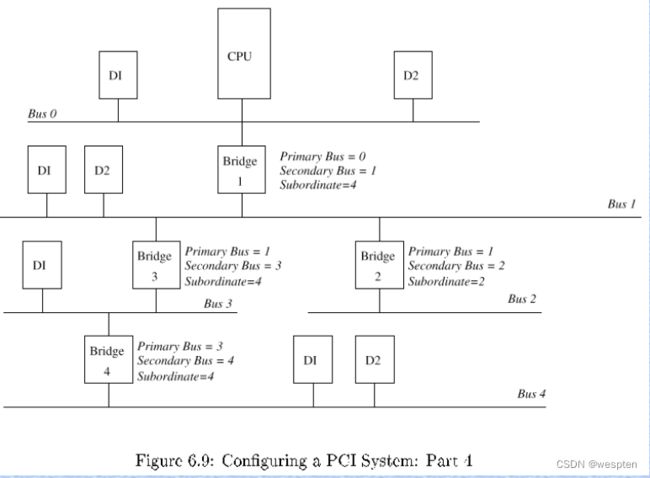

6.6.3 PCI BIOS Functions(PCI BIOS函数)
PCI BIOS函数是通用的跨平台的一系列标准例程。例如,它们对于Intel和Alpha AXP系统都是一样的。它们允许CPU控制对于所有PCI地址空间的访问。只有Linux核心和设备驱动程序需要使用它们。
参见arch/*/kernel/bios32.c
6.6.4 PCI Fixup
Alpha AXP系统上的PCI整理代码比Intel(基本不做任何事情)要做更多的工作。对于Intel系统,启动时候运行的系统BIOS,已经完全配置了PCI系统。Linux不需要做更多的事情,只是映射PCI的配置。对于非Intel系统,需要做更多的配置:
参见arch/kernel/bios32.c
对于每一个设备分配PCI I/O和PCI内存空间
对于系统重的每一个PCI-PCI桥必须配置PCI I/O和PCI内存地址窗口
对于设备产生Interrupt Line值,这些控制设备的中断处理
下面描述这些代码如何工作。
Finding Out How Much PCI I/O and PCI Memory Space a Device Needs
(找出一个设备需要多少PCI I/O和PCI内存空间)
查询找到的每一个PCI设备,找出它需要多少PCI I/O和内存地址空间。为此,把每一个Base Address Register都写成1然后读出来。设备会在不关心的地址位返回1,有效地指定了需要的地址空间。
用两个基本的基础地址寄存器(Base Address Register),第一种指示设备的寄存器以及PCI I/O和PCI 内存空间必须在哪一个地址空间。这通过寄存器的0位表示。图6.10显示了PCI 内存和PCI I/O的基础地址寄存器的两种形式。
为了找出每一个给定的基础地址寄存器需要多少地址空间,需要向所有的寄存器写并读出来。设备会把不关心的地址位设为0,这样就有效地指明了需要的地址空间。这种设计暗示了使用的所有的地址空间都是2的指数,本质上是对齐的。
例如,在你初始化DECChip 21142 PCI快速以太网设备的时候,它告诉你在PCI I/O或PCI内存空间它需要0x100字节的地址。初始化代码为它分配空间。在它分配空间之后,21142的控制和状态寄存器就可以在这些地址见到。
Allocating PCI I/O and PCI Memory to PCI-PCI Bridges and Devices
(为PCI-PCI桥和设备分配PCI I/O和PCI内存)
象所有的内存一样,PCI I/O和PCI内存空间是有限的,其中有一些相当紧缺。对于非Intel系统的PCI整理代码(和Intel系统的BIOS代码)必须有效地为每一个设备分配它需要的内存量。分配给一个设备的PCI I/O和PCI内存的分配必须自然对齐。例如,如果一个设备请求PCI I/O地址0xB0,那么分配的地址就必须是0xB0的倍数。另外,分配给任何桥的PCI I/O和PCI内存地址的基础必须分别对齐4K和1M的边界。下游的设备给定的地址空间必须位于它所有的上游的PCI-PCI桥的内存范围中间。所以有效地分配地址空间是有比较困难的问题。
Linux使用的算法依赖于用PCI设备驱动程序建立的总线/设备树所描述的每一个设备,它按照PCI I/O内存递增的顺序分配地址空间。又是使用递归算法,遍历PCI初始化代码所建立的pci_bus和pci_dev数据结构。BIOS整理代码从PCI总线的根(pci_root所指)开始:
分别把当前的全局PCI I/O和内存的基础分别对齐在4K和1M的边界
对于当前总线上的每一个设备(按照需要的PCI I/O内存顺序排列)
-分配它的PCI I/O和/或PCI内存
-将全局的PCI I/O和内存的基础按照合适的量移动
-允许设备使用给定的PCI I/O和PCI内存
分别为当前总线下游的所有总线分配空间,注意这会改变全局的PCI I/O和内存基础。
分别把当前的全局PCI I/O和内存的基础对齐在4K和1M的边界,同时指出当前的PCI-PCI桥所需要的PCI I/O和PCI内存的窗口的基础和大小
对于连接在当前总线上的PCI-PCI桥,设置它的PCI-PCI I/O和PCI内存地址和限制。
打开PCI-PCI桥上桥接PCI I/O和PCI内存访问的功能。这意味着如果任何在桥的主PCI总线上看到的PCI I/O和PCI内存地址如果位于它的PCI I/O和PCI内存地址窗口的话就会被桥接到它的次总线。
以图6.1的PCI系统作为PCI整理代码的例子:
Align the PCI base (初始的)PCI I/O是0x4000,PCI内存是0x100000。这样允许PCI-ISA桥把所有低于此的地址都转换到ISA地址。
The Video Device 请求0x200000的PCI内存,因为必须按照要求的大小对齐,所以我们从PCI内存0x200000开始分配,PCI内存基础地址移到了0x400000,而PCI I/O地址仍旧是0x4000。
The PCI-PCI Bridges 我们现在穿过PCI-PCI桥,在那里分配内存。注意因为我们不需要对其基础地址因为它们已经正确对齐了。
The Ethernet Device 它在PCI I/O和PCI内存空间都请求0xB0字节。它被分配在PCI I/O地址0x4000,PCI内存0x400000。PCI内存的基础移到了0x4000B0,PCI I/O的基础成为0x40B0。
The SCSI Device 它请求0x1000的PCI内存,所以它在对齐之后分配在0x401000。而PCI I/O的基础地址还是0x40B0,PCI内存的基础移到了0x402000。
The PCI-PCI Bridge’s PCI I/O and Memory Windows 我们现在返回到桥,把它的PCI I/O窗口设置成为0x4000和0x40B0之间,它的PCI内存窗口在0x400000和0x402000之间。这意味着PCI-PCI桥会忽略对于显示设备的PCI内存访问,如果是对以太网或者SCSI设备的访问就可以通过。
7、Interrupts and Interrupt Handling(中断和中断处理)
虽然核心有用于处理中断的通用机制和接口,大部分中断处理的细节还是和体系结构相关的。
Linux使用大量不同的硬件来完成许多不同的任务。显示设备驱动显示器,IDE设备驱动磁盘等等。你可以同步地驱动这些设备,就是你可以发出一个请求执行一些操作(比如把一块内存写到磁盘)然后等待操作结束。这种方式,虽然可以工作,但是非常没有效率,操作系统当它等待每一个操作完成的时候会花费大量时间“忙于什么也不做”(busy doing nothing)。一个好的,更有效的方法是做出了请求然后去作其他更有用的事情,然后当设备完成请求的时候被设备中断。在这种方案下,系统中同一时刻可能有许多设备的请求在同时发生。
让设备中断CPU当前的工作必须有一些硬件的支持。大多数,如果不是所有的话,通用目的的处理器比如Alpha AXP都使用相似的方法。CPU的一些物理管脚的电路只要改变电压(例如从+5V到-5V)就会让CPU停止正在做的工作,开始执行处理中断的特殊代码:中断处理代码。这些管脚之一可能连接一个内部适中,每一个1000分之一秒就接收一个中断,其他的也许连接到系统的其他设备,比如SCSI控制器。
系统通常使用一个中断控制器把设备的中断集合在一起,然后把信号传送到CPU的一个单一的中断管脚。这可以节省CPU的中断管教,也给设计系统带来了灵活性。中断控制器有掩码和状态寄存器,用于控制这些中断。设置掩码寄存器的位可以允许和禁止中断,状态寄存器返回系统中当前的中断。
一些系统中的中断可能是硬连接的,例如实时时钟的内部时钟可能永久地连接到中断控制器的第3管脚。但是,另一些管脚连接什么可能由在特定的ISA或者PCI槽位插入什么控制卡决定。例如,中断控制器的第4管脚可能和PCI槽位0相连,可能某一天有一个以太网卡,当时后来可能是一块SCSI控制卡。每一个系统都有它自己的中断中转机制,操作系统必须足够灵活才能处理。
大多数现代的通用目的微处理器用相同的方式处理中断。发生硬件中断的时候,CPU停止它正在运行的指令,跳到内存中一个位置运行,这里或者包含中断处理代码或者是跳到中断处理代码的指令。这种代码通常在CPU的特殊模式下工作:中断模式,通常,这种模式下其他中断不能产生。这里也有例外:一些CPU将中断划分级别,更高级别的中断可以发生。这意味着写第一级的中断处理程序必须非常小心。中断处理程序通常都有自己的堆栈,用来存放CPU的执行状态(CPU所有的通用寄存器和上下文)并处理中断。一些CPU有一组只在中断模式下存在的寄存器,中断处理代码可以使用这些寄存器来存储它需要保存的大部分上下文信息。
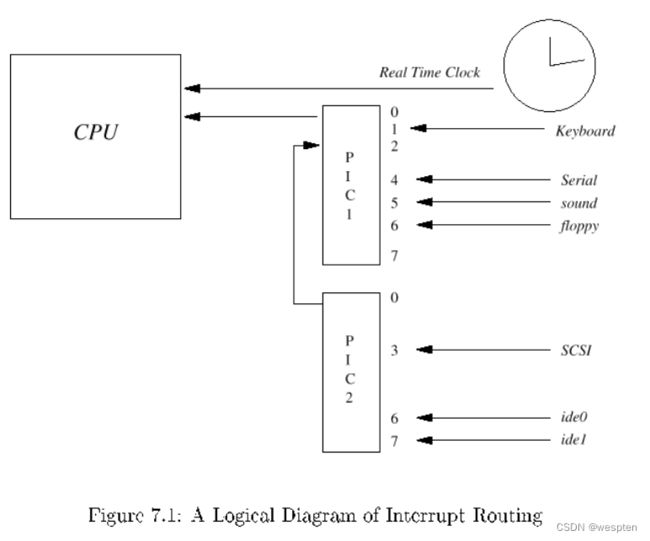
当处理完中断,CPU的状态恢复,中断结束。CPU会继续做它在中断发生之前做的事情。重要的事中断处理程序必须尽可能地有效,通常操作系统不能经常或者长时间阻塞中断。
7.1 Programmable Interrupt Controllers(可编程中断控制器)
系统设计师可以任意使用他们希望用的中断体系结构,但是IBM PC都使用Intel 82C59A-2 CMOS可编程中断控制器或者它的衍生物。这种控制器在PC最初的时候就使用了。它可通过寄存器编程,这些寄存器在ISA地址空间的众所周知的位置。甚至很现代的逻辑芯片组都在ISA内存的相同位置保留了等价的寄存器。非Intel的系统,例如Alpha AXP PC不受这些体系限制,通常使用不同的中断控制器。
图7.1显示了两个串联在一起的8位控制器:每一个都有一个掩码和一个中断状态寄存器,PIC1和PIC2。掩码寄存器位于地址0x21和0xA1,而状态寄存器位于0x20和0xA0。在掩码寄存器的一个特殊位写1允许一种中断,写0可以禁止它。所以向位3写1允许中断3,写0会禁止它。不幸的是(也是让人气恼的),中断掩码寄存器只可以写,你无法读回你所写的值。这意味着Linux必须为它设置的掩码(mask)寄存器保留一份本地拷贝。它在中断允许和禁止的例程中修改这些保存的掩码,每一次都要把整个掩码写到寄存器中。
当产生中断信号,中断处理程序读取两个中断状态寄存器(ISR)。它把0x20的ISR看作16位的中断寄存器的第8位,0xA0中的ISR看作高8位。所以,发生在0xA0的ISR的第1位的中断被看作是中断9。PCI1的第2位不可用,因为它用作串联PIC2的中断,任何PIC2的中断都会使PIC1的第2位置位。
7.2 Initializing the Interrupt Handling Data Structures(初始化中断处理数据结构)
当设备驱动程序要求控制系统的中断的时候建立核心的中断处理数据结构。为此,设备驱动程序使用一系列Linux核心服务,用来请求一个中断、允许它和禁止它。这些设备驱动程序调用这些例程来登记它们的中断处理例程的地址。
参见arch/*/kernel/irq.c request_irq() enable_irq() and disable_irq()
PC体系结构为了方便把一些中断固定下来,所以驱动程序在初始化的时候只需要简单地请求它的中断。软盘设备驱动程序就是这样:它总是请求中断6。但是也可能一个设备驱动程序不知道设备会使用什么中断。对于PCI设备驱动程序这不是问题,因为它们总是知道它们的中断编号。不幸的是对于ISA设备没有什么简单的办法找到它们的中断号码,Linux允许设备驱动程序探查它们的中断来解决这个问题。
首先,设备驱动程序让设备产生中断,然后系统中所有没有分配的中断都允许了。这意味着设备等待处理的中断现在会通过可编程中断控制器传递。Linux读取中断状态寄存器然后把它的内容返回到设备驱动程序。非0 的结果表示在探查中发生了一或多个中断。驱动程序现在关闭探查,并禁止所有位分配的中断。如果ISA设备驱动程序成功地找到了它的IRQ号,它就可以想平常一样地请求控制它。
参见arch/*/kernel/irq.c irq_probe_*()
PCI系统比ISA系统更加动态。ISA设备的中断通常用硬件设备上的跳线来设置,对于设备驱动程序是固定的。反过来,PCI设备的中断是在系统启动的时候由PCI BIOS或者PCI子系统在PCI初始化的时候分配的。每一个PCI设备可以使用4个中断管脚其中之一:A、B、C或D。这时设备制造的时候确定的,大多数设备缺省用中断管脚A。每一个PCI槽位的PCI中断线(interrupte line)A、B、C和D都转到中断控制器。所以槽位4的管脚A可能转到了中断控制器的第6管脚,槽位4的管脚B可能转到了中断控制器的管脚7,依此类推。

PCI中断如何被转发(路由route)完全是和系统相关的,必须有一些理解这种PCI中断路由拓扑的设置代码。在Intel PC上,这是启动的时候的系统BIOS代码完成的。但是对于没有BIOS的系统(例如Alpha AXP系统),Linux进行这种设置。PCI设置代码把中断控制器的管脚编号写到每一个设备的PCI配置头中。它使用它知道的PCI中断路有拓扑和设备的PCI槽位以及它正在使用的PCI中断管脚来决定中断管脚(或者说IRQ)编号。设备使用的中断管脚就确定下来并放到PCI配置头的一个域。它把这个信息写到中断线(interrupte line)域(这是为此目的保留的)。当设备驱动程序运行的时候,它读取这个信息,并使用它向Linux核心请求对中断的控制。
参见arch/alpha/kernel/bios32.c
系统中可能使用许多PCI中断资源。例如,当使用PCI-PCI桥的时候。中断来源的数目可能超过系统的可编程中断控制器的管脚数目。这种情况下,PCI设备可以共享中断:中断控制器上的一个管脚接收来自多于一个PCI设备的中断。Linux让第一个请求一个中断的源宣称(declare)它是否可以共享,这样来支持中断共享。共享中断结果是irq_action向量表中的一个条目可以指向几个irqaction的数据结构。当发生了一个共享的中断的时候,Linux会调用这个源的所有的中断处理程序。所有可以共享中断的设备驱动程序(都应该是PCI设备驱动程序)必须预备在没有中断服务的时候被调用。
7.3 Interrupt Handling(中断处理)
Linux中断处理子系统的一个主要任务是把中断转送到(route)正确的中断处理代码段。这种代码必须了解系统的中断拓扑。例如,如果软驱控制器在中断控制器的管脚6发生中断,它必须可以识别出中断是来自软驱,并把它转送到软驱设备驱动程序的中断处理程序代码。Linux使用一系列数据结构的指针,包含了处理系统中断的例程的地址。这些例程属于系统中的设备的设备驱动程序,每一个设备驱动程序必须负责在驱动程序初始化的时候请求它想要的中断。图7.2显示了irq_action是一个指向irqaction数据结构的指针的向量表。每一个irqaction数据结构都包括了这个中断处理程序的信息,包括中断处理例程的地址。不同体系的中断数目和如何处理是不同的,通常,不同系统之间,Linux中断处理代码是和体系结构相关的。这意味着irq_action向量表的大小依赖于中断源的数目而不同。
当发生中断的时候,Linux必须首先通过读取系统的可编程中断控制器的状态寄存器确定它的来源。然后把这个来源转换成irq_action向量表中的偏移。例如,从软驱控制器来的中断控制器管脚6的中断会转为中断处理程序向量表中的第7个指针。如果发生的中断没有对应的中断处理程序,Linux核心会记录下一个错误,否则,它会调用这个中断源的所有的irqaction数据结构中的中断处理例程。
当Linux核心调用设备驱动程序的中断处理例程的时候,它必须有效地判断为什么被中断,并进行响应。为了找出中断的原因,设备驱动程序会读取中断设备的状态寄存器。设备可能回应:发生了一个错误或者完成了一个请求的操作。例如软驱控制器可能报告它已经把软驱的读磁头定位到了软盘正确的扇区。一旦确定了中断的原因,设备驱动程序可能还需要做更多的工作。如果是这样,Linux核心有机制允许延迟这个操作稍候进行。这可以避免让CPU在中断模式下花费太多时间。
8、Device Drivers(设备驱动程序)
操作系统其中一个目的就是向用户掩盖系统硬件设备的特殊性。例如,虚拟文件系统呈现了安装的文件系统的一个统一的试图,而和底层的物理设备无关。本小节描述Linux核心是如何管理系统中的物理设备的。
CPU不是系统中唯一的智能设备,每一个物理设备都由它自己的硬件控制器。键盘、鼠标和串行口由SuperIO芯片控制,IDE磁盘由IDE控制器控制,SCSI磁盘由SCSI控制器控制,等等。每一个硬件控制器都由自己的控制和状态控制器(CSR),不同的设备之间是不同的。一个Adaptec 2940 SCSI控制器的CSR和NCR 810 SCSI控制器的完全不同。CSR用于启动和停止设备,初始化设备和诊断它的问题。管理这些硬件控制器的代码不是放在每一个应用程序里边,而是放在Linux核心。这些处理或者管理硬件控制器的软件脚做设备驱动程序。Linux核心的设备驱动程序本质上是特权的、驻留内存的低级的硬件控制例程的共享库。是Linux的设备驱动程序在处理它们管理的设备的特质。
UN*X的一个基本特点是它抽象了设备的处理。所有的硬件设备都象常规文件一样看待:它们可以使用和操作文件相同的、标准的系统调用来进行打开、关闭和读写。系统中的每一个设备都用一个设备特殊文件代表。例如系统中第一个IDE硬盘用/dev/had表示。对于块(磁盘)和字符设备,这些设备特殊文件用mknod命令创建,并使用主(major)和次(minor)设备编号来描述设备。网络设备也用设备特殊文件表达,但是它们由Linux在找到并初始化系统中的网络控制器的时候创建。同一个设备驱动程序控制的所有设备都由一个共同的major设备编号。次设备编号用于在不同的设备和它们的控制器之间进行区分。例如,主IDE磁盘的不同分区都由一个不同的次设备编号。所以,/dev/hda2,主IDE磁盘的第2个分区的主设备号是3,而次设备号是2。Linux使用主设备号表和一些系统表(例如字符设备表chrdevs)把系统调用中传递的设备特殊文件(比如在一个块设备上安装一个文件系统)映射到这个设备的设备驱动程序中。
参见fs/devices.c
Linux支持三类的硬件设备:字符、块和网络。字符设备直接读写,没有缓冲区,例如系统的串行端口/dev/cua0和/dev/cua1。块设备只能按照一个块(一般是512字节或者1024字节)的倍数进行读写。块设备通过buffer cache访问,可以随机存取,就是说,任何块都可以读写而不必考虑它在设备的什么地方。块设备可以通过它们的设备特殊文件访问,但是更常见的是通过文件系统进行访问。只有一个块设备可以支持一个安装的文件系统。网络设备通过BSD socket接口访问,网络子系统在第10小节描述。
Linux有许多不同的设备驱动程序(这也是Linux的力量之一)但是它们都具有一些一般的属性:
Kernel code 设备驱动程序和核心中的其他代码相似,是kenel的一部分,如果发生错误,可能严重损害系统。一个写错的驱动程序甚至可能摧毁系统,可能破坏文件系统,丢失数据。
Kenel interfaces 设备驱动程序必须向Linux核心或者它所在的子系统提供一个标准的接口。例如,终端驱动程序向Linux核心提供了一个文件I/O接口,而SCSI设备驱动程序向SCSI子系统提供了SCSI设备接口,接着,向核心提供了文件I/O和buffer cache的接口。
Kernel mechanisms and services 设备驱动程序使用标准的核心服务例如内存分配、中断转发和等待队列来完成工作
Loadable Linux大多数的设备驱动程序可以在需要的时候作为核心模块加载,在不再需要的时候卸载。这使得核心对于系统资源非常具有适应性和效率。
Configurable Linux设备驱动程序可以建立在核心。哪些设备建立到核心在核心编译的时候是可以配置的。
Dynamic 在系统启动,每一个设备启动程序初始化的时候它查找它管理的硬件设备。如果一个设备驱动程序所控制的设备不存在并没有关系。这时这个设备驱动程序只是多余的,占用很少的系统内存,而不会产生危害。
8.1 Poling and Interrupts(轮询和中断)
每一次给设备命令的时候,例如“把读磁头移到软盘的第42扇区“,设备驱动程序可以选择它如何判断命令是否执行结束。设备驱动程序可以轮询设备或者使用中断。
轮询设备通常意味着不断读取它的状态寄存器,直到设备的状态改变指示它已经完成了请求。因为设备驱动程序是核心的一部分,如果驱动程序一直在轮询,核心在设备完成请求之前不能运行其他任何东西,会是损失惨重的。所以轮询的设备驱动程序使用一个系统计时器,让系统在晚些时候调用设备驱动程序中的一个例程。这个定时器例程会检查命令的状态,Linux的软盘驱动程序就是这样工作的。使用计时器进行轮询是一种最好的接近,而更加有效的方法是使用中断。
中断设备驱动程序在它控制的硬件设备需要服务的时候会发出一个硬件中断。例如:一个以太网设备驱动程序会在设备在网络上接收到一个以太网报文的时候被中断。Linux核心需要有能力把中断从硬件设备转发到正确的设备驱动程序。这通过设备驱动程序向核心登记它所使用的中断来实现。它登记中断处理程序例程的地址和它希望拥有的中断编号。你通过/proc/interrupts可以看到设备驱动使用了哪些中断和每一类型的中断使用了多少次:
0: 727432 timer
1: 20534 keyboard
2: 0 cascade
3: 79691 + serial
4: 28258 + serial
5: 1 sound blaster
11: 20868 + aic7xxx
13: 1 math error
14: 247 + ide0
15: 170 + ide1对于中断资源的请求发生在驱动程序初始化的时间。系统中的一些中断是固定的,这是IBM PC体系结构的遗留物。例如软驱磁盘控制器总是用中断6。其他中断,例如PCI设备的中断,在启动的时候动态分配。这时设备驱动程序必须首先找出它所控制的设备的中断号,然后才能请求拥有这个中断(的处理权)。对于PCI中断,Linux支持标准的PCI BIOS回调(callback)来确定系统中设备的信息,包括它们的IRQ。
一个中断本身是如何转发到CPU依赖于体系结构。但是在大多数的体系上,中断都用一种特殊的模式传递,而停止系统中发生其他中断。设备驱动程序在它的中断处理例程中应该做尽可能少的工作,使得Linux核心可以结束中断并返回到它中断之前的地方。收到中断后需要做大量工作的设备驱动程序可以使用核心的bottom half handler或者任务队列把例程排在后面,以便在以后调用。
8.2 Direct Memory Access (DMA)
当数据量比较少的时候用中断驱动的设备驱动程序向设备或者通过设备传输数据工作地相当好。例如,一个9600波特率的modem每一毫秒(1/1000秒)大约可以传输一个字符。如果中断延迟,就是从硬件设备发出中断到开始调用设备驱动程序中的中断处理程序所花的时间比较少(比如2毫秒),那么数据传输对系统整体的映像就非常小。9600波特率的modem数据传出只会占用0.002%的CPU处理时间。但是对于高速的设备,比如硬盘控制器或者以太网设备,数据传输速率相当高。一个SCSI设备每秒可以传输高达40M字节的信息。
直接内存存取,或者说DMA,就是发明来解决这个问题的。一个DMA控制器允许设备不需要处理器的干预而和系统内存创树数据。PC的ISA DMA控制器由8个DMA通道,其中7个可用于设备驱动程序。每一个DMA通道都关联一个16位的地址寄存器和一个16位的计数寄存器(count register)。为了初始化一次数据传输,设备驱动程序需要建立DMA通道的地址和计数寄存器,加上数据传输的方向,读或写。当传输结束的时候,设备中断PC。这样,传输发生的时候,CPU可以作其他事情。
使用DMA的时候设备驱动程序必须小心。首先,所有的DMA控制器都不了解虚拟内存,它只能访问系统中的物理内存。因此,需要进行DMA传输的内存必须是物理内存中连续的块。这意味着你不能对于一个进程的虚拟地址空间进行DMA访问。但是你可以在执行DMA操作的时候把进程的物理也锁定到内存中。第二:DMA控制器无法访问全部的物理内存。DMA通道的地址寄存器表示DMA地址的首16位,跟着的8位来自于页寄存器(page register)。这意味着DMA请求限制在底部的16M内存中。
DMA通道是稀少的资源,只有7个,又不能在设备驱动程序之间共享。象中断一样,设备驱动程序必须有能力发现它可以使用哪一个DMA通道。象中断一样,一些设备有固定的DMA通道。比如软驱设备,总是用DMA通道2。有时,设备的DMA通道可以用跳线设置:一些以太网设备用这种技术。一些更灵活的设备可以告诉它(通过它们的CSR)使用哪一个DMA通道,这时,设备驱动程序可以简单地找出一个可用的DMA通道。
Linux使用dma_chan数据结构向量表(每一个DMA通道一个)跟踪DMA通道的使用。Dma_chan数据结构只有两个玉:一个字符指针,描述这个DMA通道的属主,一个标志显示这个DMA通道是否被分配。当你cat /proc/dma的时候显示的就是dma_chan向量表。
8.3 Memory(内存)
设备驱动程序必须小心使用内存。因为它们是Linux核心的一部分,它们不能使用虚拟内存。每一次设备驱动程序运行的时候,可能是接收到了中断或者调度了一个buttom half handler或任务队列,当前的进程都可能改变。设备驱动程序不能依赖于一个正在运行的特殊进程。象核心中其他部分一样,设备驱动程序使用数据结构跟踪它控制的设备。这些数据结构可以在设备驱动程序的代码部分静态分配,但是这会让核心不必要地增大而浪费。多数设备驱动程序分配核心的、不分页的内存存放它们的数据。
Linux核心提供了核心的内存分配和释放例程,设备驱动程序正是使用了这些例程。核心内存按照2的幂数的块进行分配。例如128或512字节,即使设备驱动程序请求的数量没有这么多。设备驱动程序请求的字节数按照下一个块的大小取整。这使得核心的内存回收更容易,因为较小的空闲块可以组合成更大的块。
请求核心内存的时候Linux还需要做更多的附加工作。如果空闲内存的总数太少,物理页需要废弃或者写到交换设备。通常,Linux 会挂起请求者,把这个进程放到一个等待队列,直到有了足够的物理内存。不是所有的设备驱动程序(或者实际是Linux的核心代码)希望发生这样的事情,核心内存分配例程可以请求如果不能立刻分配内存就失败。如果设备驱动程序希望为DMA访问分配内存,它也需要指出这块内存是可以进行DMA的。因为需要让Linux核心明白系统中哪些是连续的可以进行DMA的内存,而不是让设备驱动程序决定。
8.4 Interfacing Device Drivers with the Kernel(设备驱动程序和核心接口)
Linux核心必须能够用标准的方式和它们作用。每一类的设备驱动程序:字符、块和网络,都提供了通用的接口供核心在需要请求它们的服务的时候使用。这些通用的接口意味着核心可以完全相同地看待通常是非常不同的设备和它们的设备驱动程序。例如,SCSI和IDE磁盘的行为非常不同,但是Linux核心对它们使用相同的接口。
Linux非常地动态,每一次Linux核心启动,它都可能遇到不同的物理设备从而需要不同的设备驱动程序。Linux允许你在核心建立的时间通过配置脚本包含设备驱动程序。当启动的时候这些设备驱动程序初始化,它们可能没发现它们可以控制的任何硬件。其他驱动程序可以在需要的时候作为核心模块加载。为了处理设备驱动程序的这种动态的特质,设备驱动程序在它们初始化的时候向核心登记。Linux维护已经登记的设备驱动程序列表,作为和它们接口的一部分。这些列表包括了例程的指针和支持这一类设备的接口的信息。
8.4.1 Character Devices(字符设备)
字符设备,Linux最简单的设备,象文件一样访问。应用程序使用标准系统调用打开、读取、写和关闭,完全好像这个设备是一个普通文件一样。甚至连接一个Linux系统上网的PPP守护进程使用的modem,也是这样的。当字符设备初始化的时候,它的设备驱动程序向Linux核心登记,在chrdevs向量表增加一个device_struct数据结构条目。这个设备的主设备标识符(例如对于tty设备是4),用作这个向量表的索引。一个设备的主设备标识符是固定的。Chrdevs向量表中的每一个条目,一个device_struct数据结构,包括两个元素:一个登记的设备驱动程序的名称的指针和一个指向一组文件操作的指针。这块文件操作本身位于这个设备的字符设备驱动程序中,每一个都处理特定的文件操作比如打开、读、写和关闭。/proc/devices中字符设备的内容来自chrdevs向量表
参见include/linux/major.h

当代表一个字符设备(例如/dev/cua0)的字符特殊文件打开,核心必须做一些事情,从而去掉用正确的字符设备驱动程序的文件操作例程。和普通文件或目录一样,每一个设备特殊文件都用VFS I节点表达。这个字符特殊文件的VFS inode(实际上所有的设备特殊文件)都包括设备的major和minor标识符。这个VFS I节点由底层的文件系统(例如EXT2),在查找这个设备特殊文件的时候根据实际的文件系统创建。
参见fs/ext2/inode.c ext2_read_inode()
每一个VFS I节点都联系着一组文件操作,依赖于I节点所代表的文件系统对象不同而不同。不管代表一个字符特殊文件的VFS I节点什么时候创建,它的文件操作被设置成字符设备的缺省操作。这只有一种文件操作:open操作。当一个应用程序打开这个字符特殊文件的时候,通用的open文件操作使用设备的主设备标识符作为chrdevs向量表中的索引,取出这种特殊设备的文件操作块。它也建立描述这个字符特殊文件的file数据结构,让它的文件操作指向设备驱动程序中的操作。然后应用程序所有的文件系统操作都被映射到字符设备的文件操作。
参见fs/devices.c chrdev_open() def_chr_fops
8.4.2 Block Devices(块设备)
块设备也支持象文件一样被访问。这种为打开的块特殊文件提供正确的文件操作组的机制和字符设备的十分相似。Linux用blkdevs向量表维护已经登记的块设备文件。它象chrdevs向量表一样,使用设备的主设备号作为索引。它的条目也是device_struct数据结构。和字符设备不同,块设备进行分类。SCSI是其中一类,而IDE是另一类。类向Linux核心登记并向核心提供文件操作。一种块设备类的设备驱动程序向这种类提供和类相关的接口。例如,SCSI设备驱动程序必须向SCSI子系统提供接口,让SCSI子系统用来对核心提供这种设备的文件操作
参见fs/devices.c

每一个块设备驱动程序必须提供普通的文件操作接口和对于buffer cache的接口。每一个块设备驱动程序填充blk_dev向量表中它的blk_dev_struct数据结构。这个向量表的索引还是设备的主设备号。这个blk_dev_struct数据结构包括一个请求例程的地址和一个指针,指向一个request数据结构的列表,每一个都表达buffer cache向设备读写一块数据的一个请求。
参见drivers/block/ll_rw_blk.c include/linux/blkdev.h
每一次buffer cache希望读写一块数据到或从一个登记的设备的时候它就在它的blk_dev_struc中增加一个request数据结构。图8.2显示了每一个request都有一个指针指向一个或多个buffer_head数据结构,每一个都是一个读写一块数据的请求。这个buffer_head数据结构被锁定(buffer cache),可能会有一个进程在等待这个缓冲区的阻塞进程完成。每一个request结构都是从一个静态表,all_request表中分配的。如果这个request增加到一个空的request列表,就调用驱动程序的request函数处理这个request队列。否则,驱动程序只是简单地处理request队列中的每一个请求。
一旦设备驱动程序完成了一个请求,它必须把每一个buffer_head结构从request结构中删除,标记它们为最新的,然后解锁。对于buffer_head的解锁会唤醒任何正在等待这个阻塞操作完成的进程。这样的例子包括文件解析的时候:必须等待EXT2文件系统从包括这个文件系统的块设备上读取包括下一个EXT2目录条目的数据块,这个进程将会在将要包括目录条目的buff_head队列中睡眠,直到设备驱动程序唤醒它。这个request数据结构会被标记为空闲,可以被另一个块请求使用。
8.5 Hard Disks(硬盘)
硬盘把数据存放在转动的磁碟上,提供了一个更永久存储数据的方式。为了写入数据,微小的磁头把磁碟表面的一个微小的点磁化。通过磁头可以探测指定的微粒是否被磁化,从而可以读出数据。
一个磁盘驱动器由一个或多个磁碟组成,每一个都用相当光滑的玻璃或者陶瓷制成,并覆盖上一层精细的金属氧化物。磁碟放在一个中心轴上面,并按照稳定的速度转动。转动速度根据型号不同从3000到1000RPM(转/每分钟)。磁盘的读/写磁头负责读写数据,每一个磁碟有一对,每一面一个。读/写磁头和磁碟表面并没有物理的接触,而是在一个很薄的空气垫(十万分之一英寸)上面漂浮。读写磁头通过一个驱动器在磁碟表面移动。所有的磁头都粘在一起,一起在磁碟表面移动。
每一个磁碟的表面都分成多个狭窄的同心环,叫做磁道(track)。磁道0是最外面的磁道,最高编号的磁道是最接近中心轴的磁道。一个柱面(cylinder)是相同编号磁道的组合。所以每一个磁碟的每一面的所有的第5磁道就是第5柱面。因为柱面数和磁道数相同,所以磁盘的尺寸常用柱面来描述。每一个磁道分成扇区。一个扇区是可以从硬盘读写的最小数据单元,也就是磁盘的块大小。通常扇区大小是512字节,扇区大小通常是在制造磁盘的时候进行格式化的时候设定的。
磁盘通常用它的尺寸(geometry)描述:柱面数、磁头数和扇区数。例如,启动的时候Linux这样描述我的IDE磁盘:
hdb: Conner Peripherals 540MB - CFS540A, 516MB w/64kB Cache, CHS=1050/16/63这意味着它由1050柱面(磁道),16头(8个磁碟)和63个扇区/磁道。对于512字节的扇区或块大小,磁盘的容量是529200K字节。这和磁盘声明的516M的存储能力不符合,因为一些扇区用作存储磁盘的分区信息。一些磁盘可以自动找出坏的扇区,对其进行重新索引。
硬盘可以再分为分区。一个分区是分配用于特定目的的一大组扇区。对磁盘分区允许磁盘用于几个操作系统或多个目的。大多数单个磁盘的Linux系统都由3个分区:一个包含DOS文件系统,另一个是EXT2文件系统,第三个是交换分区。硬盘的分区用分区表描述,每一个条目用磁头、扇区和柱面号描述分区的起止位置。对于用fdisk格式化的DOS磁盘,可以有4个主磁盘分区。不是分区表所有的4个条目都必须用到。Fdisk支持三种类型的分区:主分区、扩展分区和逻辑分区。扩展分区不是真正的分区,它可以包括任意数目的逻辑分区。发明扩展分区和逻辑分区是为了突破4个主分区的限制。下面是一个包括2个主分区的磁盘的fdisk的输出:
Disk /dev/sda: 64 heads, 32 sectors, 510 cylinders
Units = cylinders of 2048 * 512 bytes
Device Boot Begin Start End Blocks Id System
/dev/sda1 1 1 478 489456 83 Linux native
/dev/sda2 479 479 510 32768 82 Linux swap
Expert command (m for help): p
Disk /dev/sda: 64 heads, 32 sectors, 510 cylinders
Nr AF Hd Sec Cyl Hd Sec Cyl Start Size ID
1 00 1 1 0 63 32 477 32 978912 83
2 00 0 1 478 63 32 509 978944 65536 82
3 00 0 0 0 0 0 0 0 0 00
4 00 0 0 0 0 0 0 0 0 00它显示了第一个分区开始于柱面或磁道0,磁头1和扇区1,直到柱面477,扇区32和磁头63。因为一个磁道由32个扇区和64个读写磁头,这个分区的柱面都是完全包括的。Fdisk缺省把分区对齐在柱面的边界。它从最外面的柱面(0)开始向内,朝向中心轴,扩展478个柱面。第2个分区,交换分区,开始于下一个柱面(478)并扩展到磁盘最里面的柱面。
在初始化的时候Linux映射系统中的硬盘的拓扑结构。它找出系统中有多少个硬盘以及硬盘的类型。Linux还找出每一个磁盘如何分区。这些都是由gendisk_head指针列表指向的一组gendisk数据结构的列表表达。对于每一个磁盘子系统,例如IDE,初始化的时候生成gendisk数据结构表示它找到的磁盘。这个过程和它登记它的文件操作和在blk_dev数据结构中增加它的条目发生在同一时间。每一个gendisk数据结构都由一个唯一的主设备号,和块特殊设备的相同。例如,SCSI磁盘子系统会创建一个独立的gendisk条目(“sd”),主设备号是8(所有SCSI磁盘设备的主设备号)。图8.3显示了两个gendisk条目,第一个是SCSI磁盘子系统,第二个是IDE磁盘控制器。这里是ide0,主IDE控制器。
虽然磁盘子系统在初始化的时候会建立相应的gendisk条目,Linux只是在进行分区检查的时候才用到。每一个磁盘子系统必须维护自己的数据结构,让它自己可以把设备的主设备号和次设备号映射到物理磁盘的分区上。不管什么时候读写块设备,不管是通过buffer cache或者文件操作,核心都根据它在块特殊设备文件(例如/dev/sda2)中找到的主设备号和次设备号把操作定向到合适的设备。是每一个设备驱动程序或子系统把次设备号映射到真正的物理设备上。
8.5.1 IDE Disks(IDE磁盘)
今天Linux系统中最常用的磁盘是IDE磁盘(Integrated Disk Electronic)。IDE和SCSI一样是一个磁盘接口而不是一个I/O总线。每一个IDE控制器可以支持最多2个磁盘,一个是master,另一个是slave。Master和slave通常用磁盘上的跳线设置。系统中的第一个IDE控制器叫做主IDE控制器,下一个叫从属控制器等等。IDE可以从/向磁盘进行3.3M/秒的传输,IDE磁盘的最大尺寸是538M字节。扩展IDE或EIDE把最大磁盘尺寸增加到8.6G字节,数据传输速率高达16.6M/秒。IDE和EIDE磁盘比SCSI磁盘便宜,大多数现代PC都有一个或更多的主板上的IDE控制器。
Linux按照它发现的控制器的顺序命名IDE磁盘。主控制器上的主磁盘是/dev/had,slave磁盘是/dev/hdb。/dev/hdc是次IDE控制器上的master磁盘。IDE子系统向Linux登记IDE控制器而不是磁盘。主IDE控制器的主标识符是3,次IDE控制器的标识符是22。这意味着如果一个系统有两个IDE控制器,那么在blk_dev和blkdevs向量表中在索引3和22会有IDE子系统的条目。IDE磁盘的块特殊文件反映了这种编号:磁盘/dev/had和/dev/hdb,都连接在主IDE控制器上,主设备号都是3。核心使用主设备标识符作为索引,对于这些块特殊文件的IDE子系统进行的所有的文件或者buffer cache操作都被定向到相应的IDE子系统。当执行一个请求的时候,IDE子系统负责判断这个请求是针对哪一个IDE磁盘。为此,IDE子系统使用设备特殊文件中的次设备号,这些信息允许它把请求定向到正确的磁盘的正确的分区。/dev/hdb,主IDE控制器上的slave IDE磁盘的设备标识符是(3,64)。它的第一个分区(/dev/hdb1)的设备标识符是(3,65)。
8.5.2 Initializing the IDE Subsystem(初始化IDE子系统)
IBM PC的大部分历史中都有IDE磁盘。这期间这些设备的接口发生了变化。这让IDE子系统的初始化过程比它第一次出现的时候更加复杂。
Linux可以支持的最大IDE控制器数目是4。每一个控制器都用一个ide_hwifs向量表中的一个ide_hwif_t数据结构表示。每一个ide_hwif_t数据结构包含两个ide_drive_t数据结构,分别表示可能支持的master和slave IDE驱动器。在IDE子系统初始化期间,Linux首先查看在系统的CMOS内存中记录的磁盘的信息。这种用电池做后备的内存在PC关机的时候不会丢失它的内容。这个CMOS内存实际上在系统的实时时钟设备里面,不管你的PC开或者关,它都在运行。CMOS内存的位置由系统的BIOS设置,同时告诉Linux系统中找到了什么IDE控制器和驱动器。Linux从BIOS中获取找到的磁盘的尺寸(geometry),用这些信息设置这个驱动器的ide_hwif_t的数据结构。大多数现代PC使用PCI芯片组例如Intel的82430 VX芯片组,包括了一个PCI EIDE控制器。IDE子系统使用PCI BIOS回调(callback)定位系统中的PCI (E)IDE控制器。然后调用这些芯片组的询问例程。
一旦发现一个IDE接口或者控制器,就设置它的ide_hwif_t来反映这个控制器和上面的磁盘。操作过程中IDE驱动程序向I/O内存空间的IDE命令寄存器写命令。主IDE控制器的控制和状态寄存器的缺省的I/O地址是0x1F0-0x1F7。这些地址是早期的IBM PC约定下来的。IDE驱动程序向Linux的buffer cache和VFS登记每一个控制器,分别把它加到blk_dev和blkdevs向量表中。IDE驱动程序也请求控制适当的中断。同样,这些中断也有约定,主IDE控制器是14,次IDE控制器是15。但是,象所有的IDE细节一样,这些都可以用核心的命令行选项改变。IDE驱动程序在启动的时候也为每一个找到的IDE控制器在gendisk列表中增加一个gendisk条目。这个列表稍后用于查看启动时找到的所有的硬盘的分区表。分区检查代码明白每一个IDE控制器可以控制两个IDE磁盘。
8.5.3 SCSI Disks(SCSI磁盘)
SCSI(Small Computer System Interface小型计算机系统接口)总线是一种有效的点对点的数据总线,每个总线支持多达8个设备,每个主机可以有一或者多个。每一个设备都必须由一个唯一的标识符,通常用磁盘上的跳线设置。数据可以在总线上的任意两个设备之间同步或者异步传输,可以用32位宽的数据传输,速度可能高达40M/秒。SCSI总线可以在设备之间传输数据和状态信息,发起者(initiator)和目标(target)之间的事务会涉及多达8个不同的阶段。你可以通过SCSI总线上的5种信号判断出当前的阶段。这8个阶段是:
BUS FREE 没有设备有总线的控制权,当前没有发生任何事务。
ARBITRATION (仲裁)一个SCSI设备试图得到SCSI总线的控制权,它在地址管脚上声明(assert)它的SCSI标识符。最高编号的SCSI标识符成功。
SELECTION 一个设备通过仲裁成功地得到了SCSI总线的控制权,现在它必须向它要发送命令的SCSI目标发送信号。它在地址管脚上声明目标的SCSI标识符。
RESELECTION SCSI设备在处理请求的过程中可能断线,目标会重新选择发起者。并非所有的SCSI设备都支持这一阶段。
COMMAND 6、10或者12字节的命令可以从发起者发送到目标。
DATA IN,DATA OUT在这一阶段,数据在发起者和目标之间传输。
STATUS 在完成了所有的命令,进入这一阶段。允许目标向发起者发送一个状态字节,表示成功或失败。
MESSAGE IN,MESSAGE OUT在发起者和目标之间传递的附加信息。
Linux SCSI子系统由两个基本元素组成,每一个都用数据结构表示:
Host 一个SCSI host是一个物理的硬件,一个SCSI控制器。NCR810 PCI SCSI控制器是一个SCSI host的例子。如果一个Linux系统有多于一个同类型的SCSI控制器,每一个实例都分别用一个SCSI host表示。这意味着一个SCSI设备驱动程序可能控制多于一个控制器的实例。SCSI host通常总是SCSI命令的发起者(initiator)。
Device SCSI设备通常是磁盘,但是SCSI标准支持多种类型:磁带、CD-ROM和通用(generic)SCSI设备。SCSI设备通常都是SCSI命令的目标。这些设备必须不同地对待。例如可移动介质如CD-ROM或磁带,Linux需要探测介质是否取出。不同的磁盘类型有不同的主设备编号,允许Linux把块设备请求定向到合适的SCSI类型。
Initializing the SCSI Subsystem(初始化SCSI子系统)
初始化SCSI子系统相当复杂,反映出SCSI总线和设备的动态的实质。Linux在启动的时候初始化SCSI子系统:它查找系统中的SCSI控制器(SCSI host),并探测每一个SCSI总线,查找每一个设备。然后初始化这些设备,让Linux核心的其余部分可以通过普通的文件和buffer cache块设备操作访问它们。这个初始化过程有四个阶段:
首先,Linux找出核心建立的时候建立到核心的哪一个SCSI host适配器或控制器有可以控制的硬件。每一个内建的SCSI host在buildin_scsi_hosts向量表中都有一个Scsi_Host_Template的条目。这个Scsi_Host_Template数据结构包括例程的指针,这些例程可以执行和SCSI host相关的动作例如探测这个SCSI host上粘附了什么SCSI设备。这些例程在SCSI子系统配置期间被调用,是支持这种host类型的SCSI设备驱动程序的一部分。每一个查到的SCSI控制器(有真实的SCSI设备粘附),它的Scsi_Host_Template数据结构都加到scsi_hosts列表中,表示有效的SCSI host。每一个探测到的host类型的每一个实例都用scsi_hostlist列表中的一个Scsi_Host数据结构表示。例如一个系统有两个NCR810 PCI SCSI控制器,在这个列表中会有两个Scsi_Host条目,每一个控制器一个。每一个Scsi_Host指向的Scsi_Host_Template表示它的设备驱动程序。
现在每一个SCSI host都找到了,SCSI子系统必须找到每一个host总线上的所有的SCSI设备。SCSI设备编号从0到7,每一个设备编号或者SCSI标识符在它所粘附的SCSI总线上都是唯一的。SCSI标识符通常用设备上的跳线设置。SCSI初始化代码通过向每一个设备发送TEST_UNIT_READY命令来查找一个SCSI总线上的每一个SCSI设备。当一个设备回应,再向它发送一个ENQUIRY命令来完成它的判别。这向Linux给出Vendor的名称和设备的型号和修订号。SCSI命令用一个Scsi_Cmnd数据结构来表示,这些命令通过调用这个SCSI host的Scsi_Host_Template数据结构中的设备驱动程序例程传递给设备驱动程序。每一个找到的SCSI设备用一个Scsi_Device数据结构表示,每一个都指向它的父Scsi_Host。所有的Scsi_Device数据结构都加到scsi_devices列表中。图8.4显示了主要的数据结构和其他数据结构的关系。
有四种SCSI设备类型:磁盘、磁带、CD和通用(generic)。每一种SCSI类型都分别向核心登记,有不同的主块设备类型。但是,它们只有在一个或多个给定的SCSI设备类型的设备找到的时候才登记自己。每一个SCSI类型,例如SCSI磁盘,维护它自己的设备表。它用这些表把核心的块操作(文件或buffer cache)定向到正确的设备驱动程序或SCSI host。每一个SCSI类型都用一个Scsi_Type_Template数据结构表示。它包括这种类型的SCSI设备的信息和执行多种任务的例程的地址。SCSI子系统使用这些模板调用每一种SCSI设备类型的SCSI类型例程。换句话说,如果SCSI子系统希望粘附一个SCSI磁盘设备,它会调用SCSI 磁盘类型的例程。如果探测到某类型的一个或多个SCSI设备,它的Scsi_Type_Templates的数据结构就加到了scsi_devicelist列表中。
SCSI子系统初始化的最后阶段是调用每一个登记的Scsi_Device_Template的完成函数。对于SCSI磁盘类型让所有的SCSI磁盘转动起来并记录它们的磁盘尺寸。它也把表示所有SCSI磁盘的gendisk数据结构增脚的磁盘的链接列表中,如图8.3。
Delivering Block Device Requests(传递块设备请求)
一旦Linux初始化了SCSI子系统,就可以使用SCSI设备了。每一个有效的SCSI设备类型都在核心中登记自己,所以Linux可以把块设备请求定向到它那里。这些请求可能是通过blk_dev的buffer cache请求或者是通过blkdevs的文件操作。拿一个由一个或多个EXT2文件系统分区的SCSI磁盘驱动器为例,当它的EXT2分区安装上的时候核心的缓冲区请求是如何定向到正确的SCSI磁盘呢?
每一个向/从一个SCSI磁盘分区读/写一块数据的请求都会在blk_dev向量表中这个SCSI磁盘的current_request列表中加入一个新的request数据结构。如果这个request列表正在处理,那么buffer cache不需要做什么。否则它必须让SCSI磁盘子系统处理它的请求队列。系统中的每一个SCSI磁盘用一个Scsi_Disk数据结构表示。它们保存在rscsi_disks向量表中,用SCSI磁盘分区的次设备号的一部分作为索引。例如,/dev/sdb1主设备号8,次设备号17,它的所以是1。每一个Scsi_Disk的数据结构包括一个指向表示这个设备的Scsi_Device数据结构的指针。Scsi_Device又指向一个“拥有它”的Scsi_Host数据结构。Buffer cache中的request数据结构转换成为描述需要发送到SCSI设备的SCSI命令的Scsi_Cmd数据结构中,并在表示这个设备的Scsi_Host数据结构中排队。一旦适当的数据块读/写之后,会由各自的SCSI设备驱动程序处理。
8.6 Network Devices(网络设备)
一个网络设备,只要关系到Linux的网络子系统,是一个发送和接收数据包的实体。通常是一个物理的设备,例如一个以太网卡。但是一些网络设备是纯软件的,例如loopback设备,用于向自己发送数据。每一个网络设备用一个device数据结构表示。网络设备驱动程序在核心启动网络初始化的时候向Linux登记它控制的设备。Device数据结构包括这个设备的信息和允许大量支持的网络协议使用这个设备的服务的函数的地址。这些函数多数和使用这个网络设备传输数据有关。设备使用标准的网络支持机制,向适当的协议层传输接收的数据。传输和接收的所有的网络数据(包packets)都用sk_buff数据结构表示,这是灵活的数据结构,允许网络协议头很容易地增加和删除。网络协议层如何使用网络设备,它们如何使用sk_buff数据结构来回传递数据,在第10小节有详细的描述。这里集中在device数据结构以及网络设备如何被发现和初始化。
参见include/linux/netdevice.h
device数据结构包括网络设备的信息:
Name 不象块和字符设备,它们的设备特殊文件用mknod命令创建,网络设备特殊文件在系统的网络设备发现并初始化的时候自然出现。它们的名字是标准的,每一个名字都表示了它的设备类型。同种类型的多个设备从0向上依次编号。因此以太网设备编号为/dev/eth0、/dev/eth1、/dev/eth2等等。一些常见的网络设备是:
/dev/ethN 以太网设备
/dev/slN SLIP设备
/dev/pppN PPP设备
/dev/lo loopback 设备Bus Information 这是设备驱动程序控制设备需要的信息。Irq是设备使用的中断。Base address是设备的控制和状态寄存器在I/O内存种的地址。DMA通道是这个网络设备使用的DMA通道号。所有这些信息在启动时设备初始化的时候设置。
Interface Flags 这些描述了这个网络设备的特性和能力。
IFF_UP 接口up ,正在运行
IFF_BROADCAST 设备的广播地址有效
IFF_DEBUG 设备的debug选项打开
IFF_LOOPBACK 这是一个loopback设备
IFF_POINTTOPOINT 这是点对点的连接(SLIP and PPP)
IFF_NOTRAILERS No network trailers
IFF_RUNNING 分配了资源
IFF_NOARP 不支持ARP协议
IF_PROMISC 设备在混合(promiscuous)接收模式,它会接收所有的包,不管它们的地址是谁。
IFF_ALLMULTI 接收所有的IP Multicast帧
IFF_MULTICAST 可以接收IP multicast帧
Protocal Information 每一个设备都描述它可以被网络协议层如何使用:
Mtu 不包括需要增加的链路层的头这个网络能够传输的最大尺寸的包。这个最大值用于协议层例如IP,来选择一个合适的包大小进行发送。
Family family显示了设备可以支持的协议族。所有Linux网络设备都支持的family是AF_INET,Internet地址family。
Type 硬件接口类型描述了这个网络设备连接的介质。Linux网络设备支持多种介质类型。包括Ethernet、X.25,Token Ring、Slip、PPP和Apple Localtalk。
Addresses device 数据结构保存一些和这个网络设备相关的地址,包括IP地址
Packet Queue 这是一个sk_buff的包队列,等待网络设备进行传输
Support Functions 每一个设备都提供了一组标准的例程,让协议层调用,作为对于设备链路层的接口的一部分。包括设置和帧传输例程,以及增加标准帧头和收集统计信息的例程。这些统计信息可以用ifcnfig看到
8.6.1 Initializing Network Devices(初始化网络设备)
网络设备驱动程序象其他Linux设备驱动程序一样,可以建立到Linux核心中。每一个可能的网络设备都用dev_base列表指针指向的网络设备列表中的一个device数据结构表示。如果需要设备相关的操作,网络层调用网络设备服务例程(放在device数据结构中)其中的一个。但是,初始的时候,每一个device数据结构只是放了初始化或者探测例程的地址。
网络驱动程序必须解决两个问题。首先,不是所有建立在Linux核心的网络设备驱动程序都会有控制的设备;第二,系统中的以太网设备总是叫做/dev/eth0、/dev/eth1等等,而不管底层的设备驱动程序是什么。“丢失“网络设备的问题容易解决。在调用每一个网络设备的初始化例程的时候,它返回一个状态,显示它是否定位到了它驱动的控制器的一个实例。如果驱动程序没有找到任何设备,它由dev_base指向的device列表中的条目就被删除。如果驱动程序可以找到一个设备,它就用这个设备的信息和网络设备驱动程序中的支持函数的地址填充device数据结构其余的部分。
第二个问题,就是动态地分配以太网设备到标准的/dev/ethN设备特殊文件上,用更优雅的方式解决。Device列表中有8个标准的条目:eth0、eth1到eth7。所有条目的初始化例程都一样。它顺序尝试建立在核心的每一个以太网设备驱动程序,直到找到一个设备。当驱动程序找到它的以太网设备,它就填充它现在拥有的ethN的device数据结构。这时网络驱动程序也要初始化它控制的物理硬件,并找出它使用的IRQ、DMA等等。驱动程序可能找到它控制的网络设备的几个实例,在这种情况下,它就占用几个/dev/ethN的device数据结构。一旦所有的8个标准的/dev/ethN都分配了,就不会再探测更多的以太网设备。
9、The File System(文件系统)
Linux的一个最重要的特点之一使它可以支持许多不同的文件系统。这让它非常灵活,可以和许多其他操作系统共存。inux可一直支持15种文件系统:ext、ext2、xia、minix、umsdos、msdos、vfat、proc、smb、ncp、iso9660、sysv、hpfs、affs和ufs,而且不容置疑,随着时间流逝,会加入更多的文件系统。
在Linux中,象Unix一样,系统可以使用的不同的文件系统不是通过设备标识符(例如驱动器编号或设备名称)访问,而是连接成一个单一的树型的结构,用一个统一的单个实体表示文件系统。Linux在文件系统安装的时候把它加到这个单一的文件系统树上。所有的文件系统,不管什么类型,都安装在一个目录,安装的文件系统的文件掩盖了这个目录原来存在的内容。这个目录叫做安装目录或安装点。当这个文件系统卸载的时候,安装目录自己的文件又可以显现出来。
当磁盘初始化的时候(比如用fdisk),利用一个分区结构把物理磁盘划分成一组逻辑分区。每一个分区可以放一个文件系统,例如一个EXT2文件系统。文件系统在物理设备的块上通过目录、软链接等把文件组织成逻辑的树型结构。可以包括文件系统的设备是块设备。系统中的第一个IDE磁盘驱动器的第一个分区,IDE磁盘分区/dev/hda1,是一个块设备。Linux文件系统把这些块设备看成简单的线性的块的组合,不知道也不去关心底层的物理磁盘的尺寸。把对设备的特定的块的读的请求映射到对于设备有意义的术语:这个块保存在硬盘上的磁道、扇区和柱面,这是每一个块设备驱动程序的任务。一个文件系统不管它保存在什么设备上,都应该用同样的方式工作,有同样的观感。另外,使用Linux的文件系统,是否这些不同的文件系统在不同的硬件控制器的控制下的不同的物理介质上都是无关紧要的(至少对于系统用户是这样)。文件系统甚至可能不在本地系统上,它可能是通过网络连接远程安装的。考虑以下的例子,一个Linux系统的根文件系统在一个SCSI磁盘上。
A E boot etc lib opt tmp usr
C F cdrom fd proc root var sbin
D bin dev home mnt lost+found
不管是操作这些文件的用户还是程序都不需要知道/C实际上是在系统的第一个IDE磁盘上的一个安装的VFAT文件系统。本例中(实际是我家中的Linux系统),/E是次IDE控制器上的master IDE磁盘。第一个IDE控制器是PCI控制器,而第二个是ISA控制器,也控制着IDE CDROM,这些也都无关紧要。我可以用一个modem和PPP网络协议拨号到我工作的网络,这时,我可以远程安装我的Alpha AXP Linux系统的文件系统到/mnt/remote。
文件系统中的文件包含了数据的集合:包含本小节源的文件是一个ASCII文件,叫做filesystems.tex。一个文件系统不仅保存它包括的文件的数据,也保存文件系统的结构。它保存了Linux用户和进程看到的所有的信息,例如文件、目录、软链接、文件保护信息等等。另外,它必须安全地保存这些信息,操作系统的基本的一致性依赖于它的文件系统。没有人可以使用一个随机丢失数据和文件的操作系统(不知道是否有,虽然我曾经被拥有的律师比Linux开发者还多的操作系统伤害过)。
Minix是Linux的第一个文件系统,有相当的局限,性能比较差。它的文件名不能长于14个字符(这仍然比8.3文件名要好),最大的文集大小是64M字节。第一眼看去,64M字节好像足够大,但是设置中等的数据库需要更大的文件大小。第一个专为Linux设计的文件系统,扩展文件系统或EXT(Extend File System),在1992年4月引入,解决了许多问题,但是仍然感到性能低。所以,1993年,增加了扩展文件系统第二版,或EXT2。这种文件系统在本小节稍后详细描述。
当EXT文件系统增加到Linux的时候进行了一个重要的开发。真实的文件系统通过一个接口层从操作系统和系统服务中分离出来,这个接口叫做虚拟文件系统或VFS。VFS允许Linux支持许多(通常是不同的)文件系统,每一个都向VFS表现一个通用的软件接口。Linux文件系统的所有细节都通过软件进行转换,所以所有的文件系统对于Linux核心的其余部分和系统中运行的程序显得一样。Linux的虚拟文件系统层允许你同时透明地安装许多不同的文件系统。

Linux虚拟文件系统的实现使得对于它的文件的访问尽可能的快速和有效。它也必须保证文件和文件数据正确地存放。这两个要求相互可能不平等。Linux VFS在安装和使用每一个文件系统的时候都在内存中高速缓存信息。在文件和目录创建、写和删除的时候这些高速缓存的数据被改动,必须非常小心才能正确地更新文件系统。如果你能看到运行的核心中的文件系统的数据结构,你就能够看到文件系统读写数据块,描述正在访问的文件和目录的数据结构会被创建和破坏,同时设备驱动程序会不停地运转,获取和保存数据。这些高速缓存中最重要的是Buffer Cache,在文件系统访问它们底层的块设备的时候结合进来。当块被访问的时候它们被放到Buffer Cache,根据它们的状态放在不同的队列中。Buffer Cache不仅缓存数据缓冲区,它也帮助管理块设备驱动程序的异步接口。
9.1 The Second Extended File System (EXT2)
EXT2被发明(Remy Card)作为Linux一个可扩展和强大的文件系统。它至少在Linux社区中是最成功的文件系统,是所有当前的Linux发布版的基础。EXT2文件系统,象所有多数文件系统一样,建立在文件的数据存放在数据块中的前提下。这些数据块都是相同长度,虽然不同的EXT2文件系统的块长度可以不同,但是对于一个特定的EXT2文件系统,它的块长度在创建的时候就确定了(使用mke2fs)。每一个文件的长度都按照块取整。如果块大小是1024字节,一个1025字节的文件会占用两个1024字节的块。不幸的是这一意味着平均你每一个文件浪费半个块。通常计算中你会用磁盘利用来交换CPU对于内存的使用,这种情况下,Linux象大多数操作系统一样,为了较少CPU的负载,使用相对低效率的磁盘利用率来交换。不是文件系统中所有的块都包含数据,一些块必须用于放置描述文件系统结构的信息。EXT2用一个inode数据结构描述系统中的每一个文件,定义了系统的拓扑结构。一个inode描述了一个文件中的数据占用了哪些块以及文件的访问权限、文件的修改时间和文件的类型。EXT2文件系统中的每一个文件都用一个inode描述,而每一个inode都用一个独一无二的数字标识。文件系统的inode都放在一起,在inode表中。EXT2的目录是简单的特殊文件(它们也使用inode描述),包括它们目录条目的inode的指针。
图9.1显示了一个EXT2文件系统占用了一个块结构的设备上一系列的块。只要提到文件系统,块设备都可以看作一系列能够读写的块。文件系统不需要关心自身要放在物理介质的哪一个块上,这是设备驱动程序的工作。当一个文件系统需要从包括它的块设备上读取信息或数据的时候,它请求对它支撑的设备驱动程序读取整数数目的块。EXT2文件系统把它占用的逻辑分区划分成块组(Block Group)。每一个组除了当作信息和数据块来存放真实的文件和目录之外,还复制对于文件系统一致性至关重要的信息。这种复制的信息对于发生灾难,文件系统需要恢复的时候是必要的。下面对于每一个块组的内容进行了详细的描述。
9.1.1 The EXT2 Inode(EXT2 I节点)
在EXT2文件系统中,I节点是建设的基石:文件系统中的每一个文件和目录都用一个且只用一个inode描述。每一个块组的EXT2的inode都放在inode表中,还有一个位图,让系统跟踪分配和未分配的I节点。图9.2显示了一个EXT2 inode的格式,在其他信息中,它包括一些域:
参见include/linux/ext2_fs_i.h
mode 包括两组信息:这个inode描述了什么和用户对于它的权限。对于EXT2,一个inode可以描述一个文件、目录、符号链接、块设备、字符设备或FIFO。
Owner Information 这个文件或目录的数据的用户和组标识符。这允许文件系统正确地进行文件访问权限控制
Size 文件的大小(字节)
Timestamps 这个inode创建的时间和它上次被修改的时间。
Datablocks 指向这个inode描述的数据的块的指针。最初的12个是指向这个inode描述的数据的物理块,最后的3个指针包括更多级的间接的数据块。例如,两级的间接块指针指向一个指向数据块的块指针的块指针。的这意味着小于或等于12数据块大小的文件比更大的文件的访问更快。
你应该注意EXT2 inode可以描述特殊设备文件。这些不是真正的文件,程序可以用于访问设备。/dev下所有的设备文件都是为了允许程序访问Linux的设备。例如mount程序用它希望安装的设备文件作为参数。
9.1.2 The EXT2 Superblock(EXT2超级块)
超级块包括这个文件系统基本大小和形状的描述。它里面的信息允许文件系统管理程序用于维护文件系统。通常文件系统安装时只有块组0中的超级块被读取,但是每一个块组中都包含一个复制的拷贝,用于系统崩溃的时候。除了其他一些信息,它包括:
参见include/linux/ext2_fs_sb.h
Magic Number 允许安装软件检查这是否是一个EXT2文件系统的超级块。对于当前版本的EXT2是0xEF53。
Revision Level major和minor修订级别允许安装代码确定这个文件系统是否支持只有在这种文件系统特定修订下才有的特性。这也是特性兼容域,帮助安装代码确定哪些新的特征可以安全地使用在这个文件系统上。
Mount Count and Maximum Mount Count 这些一起允许系统确定这个文件系统是否需要完全检查。每一次文件系统安装的时候mount count增加,当它等于maximum mount count的时候,会显示告警信息“maximal mount count reached,running e2fsck is recommended”。
Block Group Number 存放这个超级块拷贝的块组编号。
Block Size 这个文件系统的块的字节大小,例如1024字节。
Blocks per Group 组中的块数目。象块大小一样,这是文件系统创建的时候确定的。
Free Blocks 文件系统中空闲块的数目。
Free Inodes 文件系统中空闲的inode。
First Inode 这是系统中第一个inode的编号。一个EXT2根文件系统中的第一个inode是‘/’目录的目录条目。
9.1.3 The EXT2 Group Descriptor(EXT2组描述符)
每一个块组都有一个数据结构描述。象超级块,所有得亏组的组描述符在每一块组都进行复制。每一个组描述符包括以下信息:
参见include/linux/ext2_fs.h ext2_group_desc
Blocks Bitmap 这个块组的块分配位图的块编号,用在块的分配和回收过程中
Inode Bitmap 这个块组的inode位图的块编号。用在inode的分配和回收过程中。
Inode Table 这个块组的inode table的起始块的块编号。每一个EXT2 inode数据结构表示的inode在下面描述。
Free blocks count,Free Inodes count,Used directory count
组描述符依次排列,它们一起组成了组描述符表(group descriptor table)。每一个块组包括块组描述符表和它的超级块的完整拷贝。只有第一个拷贝(在块组0)实际被EXT2文件系统使用。其他拷贝,象超级块的其他拷贝一样,只有在主拷贝损坏的时候才使用。
9.1.4 EXT2 Directories(EXT2目录)
在EXT2文件系统中,目录是特殊文件,用来创建和存放对于文件系统中的文件的访问路径。图9.3显示了内存中一个目录条目的布局。一个目录文件,是一个目录条目的列表,每一个目录条目包括以下信息:
参见include/linux/ext2_fs.h ext2_dir_entry
inode 这个目录条目的inode。这是个放在块组的inode表中的inode数组的索引。图9.3叫做file的文件的目录条目引用的inode 是 i1。
Name length 这个目录条目的字节长度
Name 这个目录条目的名字
每一个目录中的前两个条目总是标准的“.”和“..”,分别表示“本目录”和“父目录”。
9.1.5 Finding a File in a EXT2 File System(在一个EXT2文件系统中查找一个文件)
Linux的文件名和所有的Unix文件名的格式一样。它是一系列目录名,用“/”分隔,以文件名结尾。一个文件名称的例子是/home/rusling/.cshrc,其中/home和/rusling是目录名,文件名是.cshrc。象其它Unix系统一样,Linux不关心文件名本身的格式:它可以任意长度,由可打印字符组成。为了在EXT2文件系统中找到代表这个文件的inode,系统必须逐个解析目录中的文件名直到得到这个文件。
我们需要的第一个inode是这个文件系统的根的inode。我们通过文件系统的超级块找到它的编号。为了读取一个EXT2 inode我们必须在适当的块组中的inode表中查找。举例,如果根的inode编号是42,那么我们需要块组0中的inode表中的第42个inode。Root inode是一个EXT2目录,换句话说root inode的模式描述它是一个目录,它的数据块包括EXT2目录条目。
Home是这些目录条目之一,这个目录条目给了我们描述/home目录的inode编号。我们必须读取这个目录(首先读取它的inode,然后读取从这个inode描述的数据块读取目录条目),查找rusling条目,给出描述/home/rusling目录的inode编号。最后,我们读取描述/home/rusling目录的inode指向的目录条目,找到.cshrc文件的inode编号,这样,我们得到了包括文件里信息的数据块。
9.1.6 Changing the size of a File in an EXT2 File System(在EXT2文件系统中改变一个文件的大小)
文件系统的一个常见问题是它趋于更多碎片。包含文件数据的块分布在整个文件系统,数据块越分散,对于文件数据块的顺序访问越没有效率。EXT2文件系统试图克服这种情况,它分配给一个文件的新块物理上和它的当前数据块接近或者至少和它的当前数据块在一个块组里面。只有这个失败了它才分配其它块组中的数据块。
无论何时一个进程试图象一个文件写入数据,Linux文件系统检查数据是否会超出文件最后分配块的结尾。如果是,它必须为这个文件分配一个新的数据块。直到这个分配完成,该进程无法运行,它必须等待文件系统分配新的数据块并把剩下的数据写入,然后才能继续。EXT2块分配例程所要做的第一个事情是锁定这个文件系统的EXT2超级块。分配和释放块需要改变超级块中的域,Linux文件系统不能允许多于一个进程同一时间都进行改变。如果另一个进程需要分配更多的数据块,它必须等待,直到这个进程完成。等待超级块的进程被挂起,不能运行,直到超级块的控制权被它的当前用户释放。对于超级块的访问的授权基于一个先来先服务的基础(first come first serve),一旦一个进程拥有了超级块的控制,它一直维持控制权到它完成。锁定超级块之后,进程检查文件系统是否有足够的空闲块。如果没有足够的空闲块,分配更多的尝试会失败,进程交出这个文件系统超级块的控制权。
如果文件系统中有足够的空闲块,进程会试图分配一块。如果这个EXT2文件系统已经建立了预分配的数据块,我们就可以取用。预分配的块实际上并不存在,它们只是分配块的位图中的保留块。VFS inode用两个EXT2特有的域表示我们试图分配新数据块的文件:prealloc_block and prealloc_count,分别是预分配块中第一块的编号和预分配块的数目。如果没有预分配块或者预分配被禁止,EXT2文件系统必须分配一个新的数据块。EXT2文件系统首先查看文件最后一个数据块之后数据块是否空闲。逻辑上,这是可分配的效率最高的块,因为可以让顺序访问更快。如果这个块不是空闲,继续查找,在随后的64块中找理想的数据块。这个块,虽然不是最理想,但是至少和文件的其它数据块相当接近,在一个块组中。
参见fs/ext2/balloc.c ext2_new_block()
如果这些块都没有空闲的,进程开始顺序查看所有其它块组直到它找到空闲的块。块分配代码在这些块组中查找8个空闲数据块的簇。如果无法一次找到8个,它会降低要求。如果希望进行块预分配,并允许,它会相应地更新prealloc_block和prealloc_count。
不管在哪里找到了空闲的数据块,块分配代码会更新块组的块位图,并从buffer cache中分配一个数据缓冲区。这个数据缓冲区使用支撑文件系统的设备标识符和分配块的块编号来唯一标识。缓冲区中的数据被置为0,缓冲区标记为“dirty”表示它的内容还没有写到物理磁盘上。最后,超级块本身也标记位“dirty”,显示它进行了改动,然后它的锁被释放。如果有进程在等待超级块,那么队列中第一个进程就允许运行,得到超级块的排它控制权,进行它的文件操作。进程的数据写到新的数据块,如果数据块填满,整个过程重复进行,再分配其它数据块
9.2 The Virtual File System(虚拟文件系统VFS)
图9.4显示了Linux核心的虚拟文件系统和它的真实的文件系统之间的关系。虚拟文件系统必须管理任何时间安装的所有的不同的文件系统。为此它管理描述整个文件系统(虚拟)和各个真实的、安装的文件系统的数据结构。
相当混乱的是,VFS也使用术语超级块和inode来描述系统的文件,和EXT2文件系统使用的超级块和inode的方式非常相似。象EXT2的inode,VFS的inode描述系统中的文件和目录:虚拟文件系统的内容和拓扑结构。从现在开始,为了避免混淆,我会用VFS inode和VFS超级块以便同EXT2的inode和超级块区分开来。
参见fs/*
当每一个文件系统初始化的时候,它自身向VFS登记。这发生在系统启动操作系统初始化自身的时候。真实的文件系统自身建立在内核中或者是作为可加载的模块。文件系统模块在系统需要的时候加载,所以,如果VFAT文件系统用核心模块的方式实现,那么它只有在一个VFAT文件系统安装的时候才加载。当一个块设备文件系统安装的时候,(包括root文件系统),VFS必须读取它的超级块。每一个文件系统类型的超级块的读取例程必须找出这个文件系统的拓扑结构,并把这些信息映射到一个VFS超级块的数据结构上。VFS保存系统中安装的文件系统的列表和它们的VFS超级块列表。每一个VFS超级块包括了文件系统的信息和完成特定功能的例程的指针。例如,表示一个安装的EXT2文件系统的超级块包括一个EXT2相关的inode的读取例程的指针。这个EXT2 inode读取例程,象所有的和文件系统相关的inode读取例程一样,填充VFS inode的域。每一个VFS超级块包括文件系统中的一个VFS inode的指针。对于root文件系统,这是表示“/”目录的inode。这种信息映射对于EXT2文件系统相当高效,但是对于其他文件系统相对效率较低。
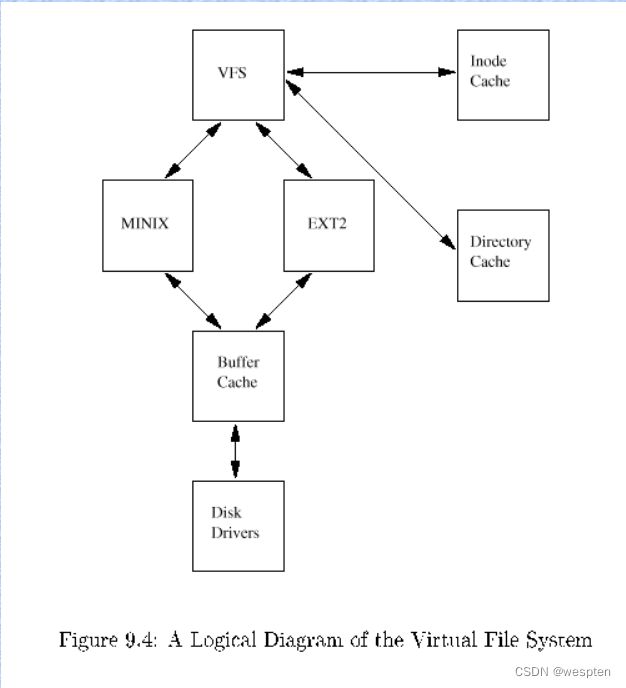
当系统的进程访问目录和文件的时候,调用系统例程,游历系统中的VFS inode。例如再一个目录中输入ls或者cat一个文件,让VFS查找代表这个文件系统的VFS inode。映为系统中的每一个文件和目录都用一个VFS inode代表,所以一些inode会被重复访问。这些inode保存在inode cache,这让对它们的访问更快。如果一个inode不在inode cache中,那么必须调用一个和文件系统相关的例程来读取适当的inode。读取这个inode的动作让它被放到了inode cache,以后对这个inode的访问会让它保留在cache中。较少使用的VFS inode 会从这个高速缓存中删除。
参见fs/inode.c
所有的Linux文件系统使用一个共同的buffer cache来缓存底层的设备的数据缓冲区,这样可以加速对于存放文件系统的物理设备的访问,从而加快对文件系统的访问。这个buffer cache独立于文件系统,集成在Linux核心分配、读和写数据缓冲区的机制中。让Linux文件系统独立于底层的介质和支撑的设备驱动程序有特殊的好处。所有的块结构的设备向Linux核心登记,并表现为一个统一的,以块为基础的,通常是异步的接口。甚至相对复杂的块设备比如SCSI设备也是这样。当真实的文件系统从底层的物理磁盘读取数据的,引起块设备驱动程序从它们控制的设备上读取物理块。在这个块设备接口中集成了buffer cache。当文件系统读取了块的时候,它们被存放到了所有的文件系统和Linux核心共享的全局的buffer cache中。其中的buffer(缓冲区)用它们的块编号和被读取设备的一个唯一的标识符来标记。所以,如果相同的数据经常需要,它会从buffer cache中读取,而不是从磁盘读取(会花费更多时间)。一些设备支持超前读(read ahead),数据块会预先读取,以备以后可能的读取。
参见fs/buffer.c
VFS也保存了一个目录查找的缓存,所以一个常用的目录的inode可以快速找到。作为一个试验,试着对于你最近没有列表的目录列表。第一次你列表的时候,你会注意到短暂的停顿,当时第二次你列表的时候,结果会立即出来。目录缓存本身不存储目录里的inode,这是inode cache负责的,目录缓存只是存储目录项目全称和它们的inode编号。
参见fs/dcache.c
9.2.1 The VFS Superblock(VFS超级块)
每一个安装的文件系统都用VFS超级块表示。除了其它信息,VFS超级块包括:
参见include/linux/fs.h
Device 这是包含文件系统的块设备的设备标识符。例如,/dev/hda1,系统中的第一个IDE磁盘,设备标识符是0x301
Inode pointers 其中的mounted inode指针指向该文件系统的第一个inode。Covered inode指针指向文件系统安装到的目录的inode。对于root文件系统,它的VFS超级块中没有covered指针。
Blocksize 文件系统块的字节大小,例如1024字节。
Superblock operations 指向一组本文件系统超级块例程的指针。除了其他类型之外,VFS使用这些例程读写inode和超级块
File System type 指向这个安装的文件系统的file_system_type数据结构的一个指针
File System Specific 指向这个文件系统需要的信息的一个指针
9.2.2 The VFS Inode
象EXT2文件系统,VFS中每一个文件、目录等等都用一个且只用一个VFS inode代表。每一个VFS inode中的信息使用文件系统相关的例程从底层的文件系统中获取。VFS inode只在核心的内存中存在,只要对系统有用,就一直保存在VFS inode cache中。除了其它信息,VFS inode包括一些域:
参见include/linux/fs.h
device 存放这个文件(或这个VFS inode代表的其它实体)的设备的设备标识符。
Inode nunber 这个inode的编号,在这个文件系统中唯一。Device 和inode number的组合在整个虚拟文件系统中是唯一的。
Mode 象EXT2一样,这个域描述这个VFS inode代表的东西和对它的访问权限。
User ids 属主标识符
Times 创建、修改和写的时间
Block size 这个文件的块的字节大小,例如1024字节
Inode operations 指向一组例程地址的指针。这些例程和文件系统相关,执行对于这个inode的操作,例如truncate这个inode代表的文件
Count 系统组件当前使用这个VFS inode的数目。Count 0意味着这个inode是空闲,可以废弃或者重用。
Lock 这个域用于锁定这个VFS inode。例如当从文件系统读取它的时候
Dirty 显示这个VFS inode是否被写过,如果这样,底层的文件系统需要更新。
File system specific information
9.2.3 Registering the File Systems(登记文件系统)

当你建立Linux核心的时候,你会被提问是否需要每一个支持的文件系统。当核心建立的时候,文件系统初始化代码包括对于所有内建的文件系统的初始化例程的调用。Linux文件系统也可以建立成为模块,这种情况下,它们可以在需要的时候加载或者手工使用insmod加载。当家在一个文件系统模块的时候,它自身向核心登记,当卸载的时候,它就注销。每一个文件系统的初始化例程都向虚拟文件系统注册自身,并用一个file_system_type数据结构代表,这里面包括文件系统的名称和一个指向它的VFS超级块的读取例程的指针。图9.5显示file_system_type数据结构被放到了由file_systems指针指向的一个列表中。每一个file_system_type数据结构包括以下信息:
参见fs/filesystems.c sys_setup()
参见 include/linux/fs.h file_system_type
Superblock read routine 在这个文件系统的一个实例安装的时候,由VFS调用这个例程
File Systme name 文件系统的名称,例如ext2
Device needed 是否这个文件系统需要一个设备支持?并非所有的文件系统需要一个设备来存放。例如/proc文件系统,不需要一个块设备
你可以检查/proc/filesystems来查看登记了哪些文件系统,例如:
ext2
nodev proc
iso9660
9.2.4 Mounting a File System(安装一个文件系统)
当超级用户试图安装一个文件系统的时候,Linux核心必须首先验证系统调用中传递的参数。虽然mount可以执行一些基本的检查,但是它不知道这个核心建立是可以支持的文件系统或者提议的安装点是否存在。考虑以下的mount 命令:
$ mount –t iso9660 –o ro /dev/cdrom /mnt/cdrom
这个mount命令会传递给核心三部分信息:文件系统的名称、包括这个文件系统的物理块设备和这个新的文件系统要安装在现存的文件系统拓扑结构中的哪一个地方。
虚拟文件系统要做的第一件事情是找到这个文件系统。它首先查看file_systems指向的列表中的每一个file_system_type数据结构,查看所有已知的文件系统。如果它找到了一个匹配的名称,它就直到这个核心支持这个文件系统类型,并得到了文件系统相关例程的地址,去读取这个文件系统的超级块。如果它不能找到一个匹配的文件系统名称,如果核心内建了可以支持核心模块按需加载(参见第12小节),就可以继续。这种情况下,在继续之前,核心会请求核心守护进程加载适当的文件系统模块。
参见fs/super.c do_mount()
参见fs/super.c get_fs_type()
第二步,如果mount传递的物理设备还没有安装,必须找到即将成为新的文件系统的安装点的目录的VFS inode。这个VFS inode可能在inode cache或者必须从支撑这个安装点的文件系统的块设备上读取。一旦找到了这个inode,就检查它是否是一个目录,而且没有其他文件系统安装在那里。同一个目录不能用作多于一个文件系统的安装点。
这时,这个VFS安装代码必须分配以一个VFS超级块并传递安装信息给这个文件系统的超级块读取例程。系统所有的VFS超级块都保存在super_block数据结构组成的super_blocks向量表中,必须为这次安装分配一个结构。超级块读取例程必须根据它从物理设备读取得信息填充VFS超级块的域。对于EXT2文件系统而言,这种信息的映射或者转换相当容易,它只需要读取EXT2的超级块并填到VFS超级块。对于其他文件系统,例如MS DOS文件系统,并不是这么简单的任务。不管是什么文件系统,填充VFS超级块意味着必须从支持它的块设备读取描述该文件系统的信息。如果块设备不能读取或者它不包含这种类型的文件系统,mount命令会失败。
每一个安装的文件系统用一个vfsmount数据结构描述,参见图9.6。它们在vfsmntlist指向的一个列表中排队。另一个指针, vfsmnttail指向列表中最后一个条目,而mru_vfsmnt指针指向最近使用的文件系统。每一个vfsmount结构包括存放这个文件系统的块设备的设备编号,文件系统安装的目录和一个指向这个文件系统安装时所分配的VFS超级块的指针。VFS超级块指向这一类型的文件系统的file_system_type数据结构和这个文件系统的root inode。这个inode在这个文件系统加载过程中一直驻留在VFS inode cache中。
参见fs/super.c add_vfsmnt()
9.2.5 Finding a File in the Virtual File System(在虚拟文件系统中查找一个文件)
为了找到一个文件在虚拟文件系统中的VFS inode,VFS必须依次名称,一次一个目录,找到中间的每一个的目录的VFS inode。每一个目录查找都要调用和文件系统相关的查找例程(地址放在代表父目录的VFS inode中)。因为在文件系统的VFS超级块中总是有文件系统的root inode,并在超级块中用指针指示,所以整个过程可以继续。每一次查找真实文件系统中的inode的时候,都要检查这个目录的目录缓存。如果目录缓存中没有这个条目,真实文件系统要么从底层的文件系统要么从inode cache中获得VFS inode。
9.2.6 Creating a File in the Virtual File System(在虚拟文件系统中创建一个文件)
9.2.7 Unmounting a File System(卸载一个文件系统)
我的工作手册通常把装配描述成为拆卸的反过程,但是对于卸载文件系统有些不同。如果系统有东西在使用文件系统的一个文件,那么这个文件系统就不能被卸载。例如,如果一个进程在使用/mnt/cdrom目录或它的子目录,你就不能卸载/mnt/cdrom。如果有东西在使用要卸载的文件系统,那么它的VFS inode会在VFS inode cache中。卸载代码检查整个inode列表,查找属于这个文件系统所占用的设备的inode。如果这个安装的文件系统的VFS超级块是dirty,就是它被修改过了,那么它必须被写回到磁盘上的文件系统。一旦它写了磁盘,这个VFS超级块占用的内存就被返回到核心的空闲内存池中。最后,这个安装的vmsmount数据结构也从vfsmntlist中删除并释放。
参见fs/super.c do_umount()
参见fs/super.c remove_vfsmnt()
9.2.8 The VFS Inode Cache
当游历安装的文件系统的时候,它们的VFS inode不断地被读取,有时是写入。虚拟文件系统维护一个inode cache,用于加速对于所有安装的文件系统的访问。每一次从inode cache读出一个VFS inode,系统就可以省去对于物理设备的访问。
参见fs/inode.c
VFS inode cache用散列表(hash table)的方式实现,条目是指针,指向既有同样hash value的VFS inode 列表。一个inode的hash value从它的inode 编号和包括这个文件系统的底层的物理设备的设备编号中计算出来。不论何时虚拟文件系统需要访问一个inode,它首先查看VFS inode cache。为了在inode hash table中查找一个inode,系统首先计算它的hash value,然后用它作为inode hash table的索引。这样得到了具有相同hash value的inode的列表的指针。然后它一次读取所有的inode直到它找到和它要找的inode具有相同的inode编号和相同的设备标识符的inode为止。
如果可以在cache中找到这个inode,它的count就增加,表示它有了另一个用户,文件系统的访问继续进行。否则必须找到一个空闲的VFS inode让文件系统把inode读入到内存。如何得到一个空闲的inode,VFS有一系列选择。如果系统可以分配更多的VFS inode,它就这样做:它分配核心页并把它们分成新的、空闲的inode,放到inode列表中。系统中所有的VFS inode除了在inode hash table中之外也在一个由first_inode指向的列表。如果系统已经拥有了它允许有的所有的inode,它必须找到一个可以重用的inode。好的候选是哪些使用量(count)是0的inode:这表示系统当前没有使用它们。真正重要的VFS inode,例如文件系统的root inode,已经有了一个大于0的使用量,所以永远不会选做重用。一旦定位到一个重用的候选,它就被清除。这个VFS inode可能是脏的,这时系统必须等待它被解锁然后才能继续。在重用之前这个VFS inode的候选必须被清除。
虽然找到了一个新的VFS inode,还必须调用一个和文件系统相关的例程,用从底层的真正的文件系统中毒取得信息填充这个inode。当它填充的时候,这个新的VFS inode的使用量为1,并被锁定,所以在它填入了有效的信息之前除了它没有其它进程可以访问。
为了得到它实际需要的VFS inode,文件系统可能需要访问其它一些inode。这发生在你读取一个目录的时候:只有最终目录的inode是需要的,但是中间目录的inode也必须读取。当VFS inode cache使用过程并填满时,较少使用的inode会被废弃,较多使用的inode会保留在高速缓存中。
9.2.9 The Directory Cache(目录缓存)
为了加速对于常用目录的访问,VFS维护了目录条目的一个高速缓存。当真正的文件系统查找目录的时候,这些目录的细节就被增加到了目录缓存中。下一次查找同一个目录的时候,例如列表或打开里边的文件,就可以在目录缓存中找到。只有短的目录条目(最多15字符)被缓存,不过这是合理的,因为较短的目录名称是最常用的。例如:当X服务器启动的时候,/usr/X11R6/bin非常频繁地被访问。
参见fs/dcache.c
目录缓存中包含一个hash table,每一个条目都指向一个具有相同的hash value的目录缓存条目的列表。Hash 函数使用存放这个文件系统的设备的设备编号和目录的名称来计算在hash table中的偏移量或索引。它允许快速找到缓存的目录条目。如果一个缓存在查找的时候花费时间太长,或根本找不到,这样的缓存是没有用的。
为了保持这些cache有效和最新,VFS保存了一个最近最少使用(LRU)目录缓存条目的列表。当一个目录条目第一次被放到了缓存,就是当它第一次被查找的时候,它被加到了第一级LRU列表的最后。对于充满的cache,这会移去LRU列表前面存在的条目。当这个目录条目再一次被访问的时候,它被移到了第二个LRU cache列表的最后。同样,这一次它移去了第二级LRU cache列表前面的二级缓存目录条目。这样从一级和二级LRU列表中移去目录条目是没有问题的。这些条目之所以在列表的前面只是因为它们最近没有被访问。如果被访问,它们会在列表的最后。在二级LRU缓存列表中的条目比在一级LRU缓存列表中的条目更加安全。因为这些条目不仅被查找而且曾经重复引用。
9.3 The Buffer Cache
当使用安装的文件系统的时候,它们会对块设备产生大量的读写数据块的请求。所有的块数据读写的请求都通过标准的核心例程调用,以buffer_head数据结构的形式传递给设备驱动程序。这些数据结构给出了设备驱动程序需要的所有信息:设备标识符唯一标识了设备,块编号告诉了驱动程序读去哪一块。所有的块设备被看成同样大小的块的线性组合。为了加速对于物理块设备的访问,Linux维护了一个块缓冲区的缓存。系统中所有的块缓冲区动保存在这个buffer cache,甚至包括那些新的、未使用的缓冲区。这个缓存区被所有的物理块设备共享:任何时候缓存区中都有许多块缓冲区,可以属于任何一个系统块设备,通常具有不同的状态。如果在buffer cache中有有效的数据,这就可以节省系统对于物理设备的访问。任何用于从/向块设备读取/写入数据的块缓冲区都进入这个buffer cache。随着时间的推移,它可能从这个缓存区中删除,为其它更需要的缓冲区让出空间,或者如果它经常被访问,就可能一直留在缓存区中。
这个缓存区中的块缓冲区用这个缓冲区所属的设备标识符和块编号唯一标识。这个buffer cache由两个功能部分组成。第一部分是空闲的块缓冲区列表。每一个同样大小的缓冲区(系统可以支持的)一个列表。系统的空闲的块缓冲区当第一次创建或者被废弃的时候就在这些列表中排队。当前支持的缓冲区大小是512、1024、2048、4096和8192字节。第二个功能部分是缓存区(cache)本身。这是一个hash table,是一个指针的向量表,用于链接具有相同hash index的buffer。Hash index从数据块所属的设备标识符和块编号产生出来。图9.7显示了这个hash table和一些条目。块缓冲区要么在空闲列表之一,要么在buffer cache中。当它们在buffer cache的时候,它们也在LRU列表中排队。每一个缓冲区类型一个LRU列表,系统使用这些类型在一种类型的缓冲区上执行操作。例如,把有新数据的缓冲区写到磁盘上。缓冲区的类型反映了它的状态,Linux当前支持以下类型:
clean 未使用,新的缓冲区(buffer)
locked 锁定的缓冲区,等待被写入
dirty 脏的缓冲区。包含新的有效的数据,将被写到磁盘,但是直到现在还没有调度到写
shared 共享的缓冲区
unshared 曾经共享的缓冲区,但是现在没有共享不论何时文件系统需要从它的底层的物理设备读取一个缓冲区的时候,它都试图从buffer cache中得到一个块。如果它不能从buffer cache中得到一个缓冲区,它就从适当大小的空闲列表中取出一个干净的缓冲区,这个新的缓冲区会进入到buffer cache中。如果它需要的缓冲区已经在buffer cache中,那么它可能是也可能不是最新。如果它不是最新,或者它是一个新的块缓冲区,文件系统必须请求设备驱动程序从磁盘上读取适当的数据块。
象所有的高速缓存一样,buffer cache必须被维护,这样它才能有效地运行,并在使用buffer cache的块设备之间公平地分配缓存条目。Linux使用核心守护进程bdflush在这个缓存区上执行大量的整理工作,不过另一些是在使用缓存区的过程中自动进行的。
9.3.1 The bdflush Kernel Daemon(核心守护进程bdflsuh)
核心守护进程bdflush是一个简单的核心守护进程,对于有许多脏的缓冲区(包含必须同时写到磁盘的数据的缓冲区)的系统提供了动态的响应。它在系统启动的时候作为一个核心线程启动,相当容易混淆,它叫自己位“kflushd”,而这是你用ps显示系统中的进程的时候你会看得的名字。这个进程大多数时间在睡眠,等待系统中脏的缓冲区的数目增加直到太巨大。当缓冲区分配和释放的时候,就检查系统中脏的缓冲区的数目,然后唤醒bdflush。缺省的阈值是60%,但是如果系统非常需要缓冲区,bdflush也会被唤醒。这个值可以用updage命令检查和设置:
#update –d
bdflush version 1.4
0: 60 Max fraction of LRU list to examine for dirty blocks
1: 500 Max number of dirty blocks to write each time bdflush activated
2: 64 Num of clean buffers to be loaded onto free list by refill_freelist
3: 256 Dirty block threshold for activating bdflush in refill_freelist
4: 15 Percentage of cache to scan for free clusters
5: 3000 Time for data buffers to age before flushing
6: 500 Time for non-data (dir, bitmap, etc) buffers to age before flushing
7: 1884 Time buffer cache load average constant
8: 2 LAV ratio (used to determine threshold for buffer fratricide).不管什么时候写入了数据,成为了脏的缓冲区,所有的脏的缓冲区都链接在BUF_DIRTY LRU列表中,bdflush会尝试把合理数目的缓冲区写到它们的磁盘中。这个数目也可以用update命令检查和设置,缺省是500(见上例)。
9.3.2 The update Process(update 进程)
update 命令不仅仅是一个命令,它也是一个守护进程。当以超级用户身份(系统初始化)运行的时候,它会定期把所有旧的脏缓冲区写到磁盘上。它通过调用系统服务例程执行这些任务,或多或少和bdflush的任务相同。当生成了一个脏缓冲区的时候,都标记上它应该被写到它自己的磁盘上的系统时间。每一次update运行的时候,它都查看系统中所有的脏的缓冲区,查找具有过期的写时间的缓冲区。每一个过期的缓冲区都被写到磁盘上。
参见fs/buffer.c sys_bdflush()
9.3.3 The /proc File System
/proc文件系统真实地体现了Linux虚拟文件系统的能力。它实际上并不存在(这也是Linux另外一个技巧),/proc和它的子目录以及其中的文件都不存在。但是为什么你可以cat /proc/devices? /proc文件系统,象一个真正的文件系统一样,也向虚拟文件系统登记自己,但是当它的文件和目录被打开,VFS执行调用请求它的inode的时候,/proc文件系统才利用核心中的信息创建这些文件和目录。例如,核心的/proc/devices文件是从核心描述它的设备的数据结构中产生出来的。
/proc文件系统代表了一个用户可读的窗口,进入核心的内部工作空间。一些Linux子系统,例如第12小节描述的Linux核心模块,都在/proc文件系统中创建条目。
9.3.4 Device Special Files
inux,象所有版本的Unix一样,把它的硬件设备表示成为特殊文件。例如,/dev/null是空设备。设备文件不在文件系统中占用任何数据空间,它只是设备驱动程序的一个访问点。EXT2文件系统和Linux的VFS都把设备文件作为特殊类型的inode。有两种类型的设备文件:字符和块特殊文件。在核心内部本身,设备驱动程序都实现文件的基本操作:你可以打开、关闭等等。字符设备允许字符模式的I/O操作,而块设备要求所有的I/O通过buffer cache。当对于一个设备文件执行一个I/O请求的时候,它被转到系统中适当的设备驱动程序。通常这不是一个真正的设备驱动程序,而是一个用于子系统的伪设备驱动程序(pseudo-device driver)例如SCSI设备驱动程序层。设备文件用主设备编号(标识设备类型)和次类型来引用(用于标识单元,或者主类型的实例)。例如,对于系统中的第一个IDE控制器上的IDE磁盘,主设备编号是3,IDE磁盘的第一个分区的次设备编号应该是1,所以,ls –l /dev/hda1输出
$ brw-rw---- 1 root disk 3, 1 Nov 24 15:09 /dev/hda1
参见/include/linux/major.h中所有Linux的主设备编号
在核心中,每一个设备用一个kdev_t数据类型唯一描述。这个类型有两个字节长,第一个包括设备的次设备编号,第二个包括主设备编号。上面的IDE设备在核心中保存为0x0301。代表一个块或者字符设备的EXT2 inode把设备的主和次设备号放在它的第一个直接块指针那里。当它被VFS读取的时候,代表它的VFS inode数据结构的I_rdev域被设成正确的设备标识符。
参见include/linux/kdev_t.h
10、Networks(网络)
Linux和网络几乎是同义词。实际上Linux是Internet或WWW的产物。它的开发者和用户使用web交换信息、想法、代码而Linux自身也常用于支持一些组织的联网需求。本小节描述了Linux如何支持统称为TCP/IP的网络协议。
TCP/IP协议设计用来支持连接在ARPANET上的计算机之间的通讯。ARPANET是美国政府投资的一个美国的研究网络。ARPANET是一些网络概念的先驱,例如报文交换和协议分层,让一种协议利用其它协议提供的服务。ARPANET于1988年退出,但是它的后继者(NSF NET和Internet)发展的甚至更大。现在所知的World Wide Web是在ARPANET中发展的,它本身也是由TCP/IP协议支持的。Unix在ARPANET上大量使用,第一个发布的网络版的Unix是4.3BSD。Linux的网络实现是基于4.3BSD的模型,它支持BSD socket(和一些扩展)和全系列的TCP/IP网络功能。选择这种编程接口是因为它的流行程度,而且可以帮助程序在Linux和其它Unix平台之间移植。
10.1 An Overview of TCP/IP Networking(TCP/IP网络概览)
本节为TCP/IP网络的主要原理给出了一个概览。这并不是一个详尽的描述。
在一个IP网络中,每一个机器都分配一个IP地址,这是一个32位的数字,唯一标识这一台机器。WWW是一个非常巨大、不断增长的IP网络,每一个连接在上面的机器都分配了一个独一无二的IP地址。IP地址用点分隔的四个数字表示,例如,16.42.0.9。IP地址实际上分为两个部分:网络地址和主机地址。这些地址的大小(尺寸)可能不同(有几类IP地址),以16.42.0.9为例,网络地址是16.42,主机地址是0.9。主机地址可以进一步划分成为子网(subnetwork)和主机地址。再次以16.42.0.9为例,子网地址可以是16.42.0,主机地址为16.42.0.9。对于IP地址进行进一步划分允许各个组织划分它们自己的网络。例如,假设16.42是ACME计算机公司的网络地址,16.42.0可以是子网0,16.42.1可以是子网1。这些子网可以在分离的大楼里,也许通过电话专线或者甚至通过微波连接。IP地址由网络管理员分配,使用IP子网是分散网络管理任务的一个好办法。IP子网的管理员可以自由地分配他们自己子网内的IP地址。
但是,通常IP地址难于记忆,而名字更容易记忆。Linux.acme.com比16.42.0.9更好记。必须使用一种机制把网络名字转换为IP地址。这些名字可以静态地存在/etc/hosts文件中或者让Linux询问一个分布式命名服务器(Distributed Name Server DNS)来解析名字。这种情况下,本地主机必须知道一个或多个DNS服务器的IP地址,在/etc/resolv.conf中指定。
不管什么时候你连接另外一台机器的时候,比如读取一个web page,都要使用它的IP地址和那台机器交换数据。这种数据包括在IP报文(packet)中,每一个报文都有一个IP头(包括源和目标机器的IP地址,一个校验和和其它有用的信息。这个校验和是从IP报文的数据中得到的,可以让IP报文的接收者判断传输过程中IP报文是否损坏(可能是一个噪音很大的电话线)。应用程序传输的数据可能被分解成容易处理的更小的报文。IP数据报文的大小依赖于连接的介质而变化:以太网报文通常大于PPP报文。目标主机必须重新装配这些数据报文,然后才能交给接收程序。如果你通过一个相当慢的串行连接访问一个包括大量图形图像的web页,你就可以用图形的方式看出数据的分解和重组。
连接在同一个IP子网的主机可以互相直接发送IP报文,而其它的IP报文必须通过一个特殊的主机(网关)发送。网关(或路由器)连接在多于一个子网上,它们会把一个子网上接收的IP报文重新发送到另一个子网。例如,如果子网16.42.1.0和16.42.0.0通过一个网关连接,那么所有从子网0发送到子网1的报文必须先发送到网关,这样才能转发。本地的主机建立一个路由表,让它可以把要转发的IP报文发送到正确的机器。对于每一个IP目标,在路由表中都有一个条目,告诉Linux要到达目标需要先把IP报文发送到那一台主机。这些路由表是动态的,而且当应用程序使用网络和网络拓扑变化的时候不断改变。
IP协议是传输层协议,被其他协议使用,携带它们的数据。传输控制协议(TCP)是一个可靠的端到端的协议,使用IP传送和接收它的报文。象IP报文有自己的头一样,TCP也有自己的头。TCP是一个面向连接的协议,两个网络应用程序通过一个虚拟的连接连接在一起,甚至它们中间可能会有许多子网、网关和路由器。TCP在两个应用程序之间可靠地传送和接收数据,并且保证不会有丢失和重复的数据。当TCP使用IP传送它的报文的时候,在IP报文中包含的数据就是TCP报文自身。每一个通讯的主机的IP层负责传送和接收IP报文。用户数据报协议(UDP)也使用IP层传送它的报文,但是不象TCP,UDP不是一个可靠的协议,它只提供数据报服务。其它协议也可以使用IP意味着当接收到IP报文,接收的IP层必须知道把这个IP报文中包含的数据交给哪一个上层协议。为此,每一个IP报文的头都有一个字节,包含一个协议标识符。当TCP请求IP层传输一个IP报文的时候IP报文的头就说明它包含一个TCP报文。接收的IP层,使用这个协议标识符来决定把接收到的数据向上传递给哪一个协议,在这种情况下,是TCP层。当应用程序通过TCP/IP通讯的时候,它们不但必须指定目标的IP地址,也要指定目标应用程序的端口(port)地址。一个端口地址唯一标识一个应用程序,标准的网络应用程序使用标准的端口地址:例如web服务器使用端口80。这些已经注册的端口地址可以在/etc/services中查到。
协议分层不仅仅停留在TCP、UDP和IP。IP协议本身使用许多不同的物理介质和其它IP主机传输IP报文。这些介质自己也可能增加它们自己的协议头。这样的例子有以太网层、PPP和SLIP。一个以太网允许许多主机同时连接在一个物理电缆上。每一个传送的以太帧可以被所有连接的主机看到,所以每一个以太网设备都有一个独一无二的地址。每一个传送到那个地址的以太网帧会被那个地址的主机接收,而被连接到这个网络的其它主机忽略掉。这个独一无二的地址当每一个以太网设备制造的时候内建在设备里边,通常保存在以太网卡的SROM中。以太地址由6个字节长,例如,可能是08-00-2b-00-49-4A。一些以太网地址保留用于多点广播,用这种目标地址发送的以太网帧会被网络上的所有的主机接收。因为以太网帧中可能运载许多不同的协议(作为数据),和IP报文一样,它们的头中都包含一个协议标识符。这样以太网层可以正确地接收IP报文并把数据传输到IP层。
为了通过多种连接协议,例如通过以太网来传输IP报文,IP层必须找出这个IP主机的以太网地址。这是因为IP地址只是一个寻址的概念,以太网设备自己有自己的物理地址。IP地址可以由网络管理员根据需要分配和再分配,而网络硬件则只响应具有它自己物理地址的以太网帧,或者特殊的多点广播地址(所有的机器都必须接收)。Linux使用地址解析协议(ARP)让机器把IP地址转换成真实的硬件地址例如以太网地址。为了得到一个IP地址所联系的硬件地址,一个主机会发送一个ARP请求包,包含它希望转换的IP地址,发送到一个多点广播地址,让网络上所有的点都可以收到。具有这个IP地址的目标主机用一个ARP回应来应答,这中间包括了它的物理硬件地址。APR不仅仅限制在以太网设备,它也可以解析其它物理介质的IP地址,例如FDDI。不能进行ARP的设备会有标记,这样Linux就不需要试图对它们进行ARP。也有一个相反的功能,反向ARP,或RARP,把物理地址转换到IP地址。这用于网关,回应对于代表远端网络的IP地址的ARP请求。
10.2 The Linux TCP/IP Networking Layers(Linux TCP/IP网络分层)
象网络协议一样,图10.2显示了Linux对于internet 协议地址族的实现就好像一系列连接的软件层。BSD socket由只和BSD socket相关的通用的socket管理软件来支持。支持这些的是INET socket层,它管理以IP为基础的协议TCP和UDP的通讯端点。UDP是一个无连接的协议,而TCP是一个可靠的端到端的协议。当传送UDP报文的时候,Linux不知道也不关心它们是否安全到达目的地。TCP报文进行了编号,TCP连接的每一端都要确保传送的数据正确地接收到。IP层包括了网际协议(Internet Protocol)的代码实现。这种代码在传送的数据前增加IP头,而且知道如何把进来的IP报文转送到TCP或者UDP层。在IP层之下,支持Linux联网的是网络设备,例如PPP和以太网。网络设备并非总是表现为物理设备:其中一些比如loopback设备只是纯粹的软件设备。不象标准的Linux设备用mknod命令创建,网络设备只有在底层的软件找到并且初始化它们之后才出现。你只有在建立俄一个包含恰当的以太望设备驱动程序的核心之后你才能看到设备文件/dev/eth0。ARP协议位于IP层和支持ARP的协议之间。
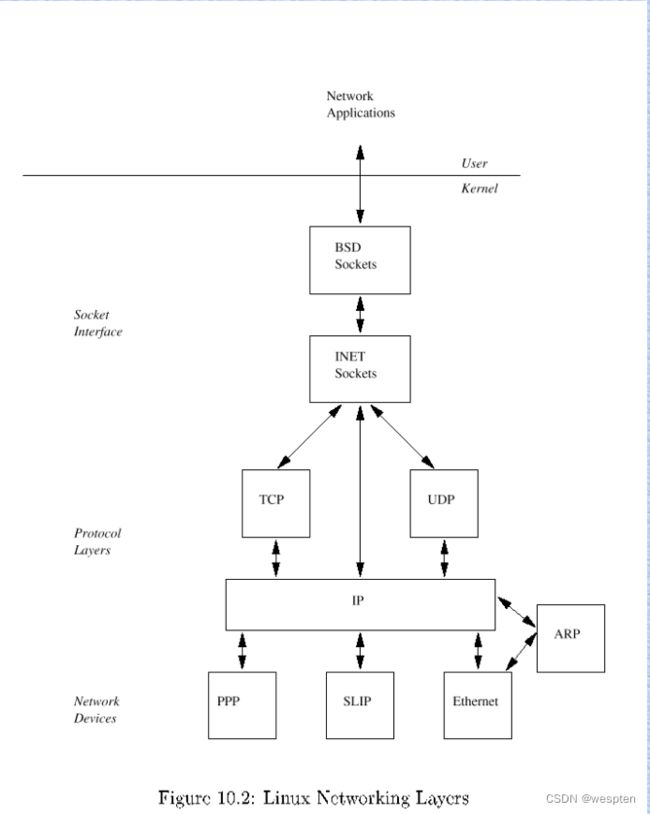
10.3 The BSD Socket Interface(BSD socket 接口)
这是一个通用的接口,不仅仅支持多种形式的联网,也是一种进程间通讯机制。一个socket描述了通讯连接的一端,两个通讯进程每一个都会有一个socket,描述它们之间通讯连接的自己部分。Socket可以想象成一种特殊形式的管道,但是和管道不同,socket对于可以容纳的数据量没有限制。Linux支持几种类型的socket,这些类叫做address families(地址族)。这是因为每一类都有自己通讯寻址方式。Linux支持以下socket address families或domain:
UNIX Unix domain sockets,
INET The Internet address family supports communications via
TCP/IP protocols
AX25 Amateur radio X25
IPX Novell IPX
APPLETALK Appletalk DDP
X25 X25有几种socket类型,每一种都代表了连接上支持的服务的类型。并非所有的address families都支持所有类型的服务。Linux BSD socket支持以下socket类型。
Stream 这种socket提供了可靠的、双向顺序的数据流,保证传输过程中数据不会丢失、损坏或重复。Stream socket在INET address family中由TCP协议支持
Datagram 这种socket也提供了双向的数据传输,但是和stream socket不同,它不保证消息会到达。甚至它到达了也不保证它们会顺序到达或没有重复或损坏。这种类型的socket在Internet address family中由UDP协议支持。
RAW 这允许进程直接(所以叫“raw”)访问底层的协议。例如,可以向一个以太网设备打开一个raw socket,观察raw IP数据流。
Reliable Delivered Messages 这很象数据报但是数据保证可以到达
Sequenced Packets 象stream socket但是数据报文大小是固定的
Packet 这不是标准的BSD socket类型,它是Linux特定的扩展,允许进程直接在设备层访问报文
使用socket通讯的进程用一个客户服务器的模型。服务器提供服务,而客户使用这种服务。一个这样的例子是一个Web 服务器,提供web page和一个web 客户(或浏览器),读取这些页。使用socket的服务器,首先创建一个socket,然后为它bind一个名字。这个名字的格式和socket的address family有关,它是服务器的本地地址。Socket的名字或地址用sockaddr数据结构指定。一个INET socket会绑定一个IP端口地址。注册的端口编号可以在/etc/services中看到:例如,web服务器的端口是80。在socket上绑定一个地址后,服务器就listen进来的对于绑定的地址的连接请求。请求的发起者,客户,创建一个socket,并在上面执行一个连接请求,指定服务器的目标地址。对于一个INET socket,服务器的地址是它的IP地址和它的端口地址。这些进来的请求必须通过大量的协议层,找到它的路径,然后就在服务器的监听端口等待。一旦服务器接收到了进来的请求,它可以接受(accept)或者拒绝它。如果要接受进来的请求,服务器必须创建一个新的socket来接受它。一旦一个socket已经用于监听进来的连接请求,它就不能再用于支持一个连接。连接建立之后,两端都可以自由地发送和接收数据。最后,当一个连接不再需要的时候,它可以被关闭。必须小心,保证正确地处理正在传送的数据报文。
一个BSD socket上的操作的确切意义依赖于它底层的地址族。建立一个TCP/IP连接和建立一个业余无线电X.25连接有很大的不同。象虚拟文件系统一样,Linux在和独立的地址族相关的软件所支持的BSD socket层抽象了BSD socket和应用程序之间的socket接口。当核心初始化的时候,建立在核心的地址族就向BSD socket接口登记自己。稍后,当应用程序创建和使用BSD socket的时候,在BSD socket和它的支撑地址族之间建立一个联系。这种联系是通过交叉的数据结构和地址族支持例程表实现的。例如,当应用程序创建一个新的socket的时候,BSD socket接口就使用地址族相关的socket创建例程。
当配置核心的时候,一组地址族和协议都建立到了protocols向量表中。每一个都用它的名称(例如“INET”)和它的初始化例程的地址来代表。当启动的时候,socket接口初始化,每一个协议的初始化代码都要被调用。对于socket地址族,它们里边会登记一系列协议操作。这都是一些例程,每一个都执行一个和地址族相关的特殊操作。登记的协议操作保存在pops向量表中,这个向量表保存指向proto_ops数据结构的指针。Proto_ops数据结构包括协议族类型和一批和特定地址族相关的socket操作例程的指针。Pops向量表用地址族的标识符作为索引,例如Internet address family的标识符(AF_INET是2)。
参见include/linux/net.h
10.4 The INET Socket Layer
INET socket层支持包含TCP/IP协议的internet address family。象上面讨论的,这些协议是分层的,每一个协议都使用其它协议的服务。Linux的TCP/IP代码和数据结构反映了这种分层。它和BSD socket层的接口是通过网络初始化的时候它向BSD socket层登记的internet address family socket操作进行的。这些和其它登记的地址族一起放在pops向量表中。BSD socket层通过调用在登记的proto_ops数据结构中的INET层的socket支持例程完成它的工作。例如,一个地址族是INET的BSD socket创建请求会使用底层的INET socket创建函数。每一次操作BSD socket层都把代表BSD socket的socket数据结构传递给INET层。INET socket层使用它自己的数据结构socket,连接到BSD socket数据结构,而不是用TCP/IP相关的信息把BSD socket搞乱。这种连接参见图10.3。它使用BSD socket中的data指针把sock数据结构和BSD socket数据结构连接起来。这意味着后续的INET socket调用可以很容易地获取这个sock 数据结构。在创建的时候sock数据结构的协议操作指针也被建立,这些指针依赖于请求的协议。如果请求TCP,则sock数据结构的协议操作指针会指向TCP连接所需要的一系列TCP协议的操作。
参见include/net/sock.h
10.4.1 Creating a BSD Socket(创建一个BSD Socket)
创建一个新的socket的系统调用需要传递它的地址族的标识符、socket的类型和协议。首先,用请求的地址族在pops向量表中查找一个匹配的地址族。它可能是一个使用核心模块实现的特殊的地址族,如果这样,kerneld核心进程必须加载这个模块,我们才能继续。然后分配一个新的socket数据结构来表示这个BSD socket。实际上这个socket数据结构物理上是VFS inode数据结构的一部分,分配一个socket实际上就是分配一个VFS inode。这看起来比较奇怪,除非你考虑让socket可以用和普通文件一样的方式进行操作。象所有文件都用VFS inode 数据结构表示一样,为了支持文件操作,BSD socket也必须用一个VFS inode数据结构表示。
这个新创建的BSD socket数据结构包括一个指针指向和地址族相关的socket例程,这个指针被设置到从pops向量表中取出的proto_ops数据结构。它的类型被设置成请求的socket类型:SOCK_STREAM、SOCK_DGRAM等等其中之一,然后用proto_ops数据结构中保存的地址调用和地址族相关的创建例程。
然后从当前进程的fd向量表中分配一个空闲的文件描述符,它所指向的file数据结构也被初始化。这包括设置文件操作指针,指向BSD socket接口支持的BSD socket文件操作例程。所有将来的操作会被定向到socket接口,依次通过调用支撑的地址族的操作例程传递到相应的地址族。

10.4.2 Binding an Address to an INET BSD Socket(为一个INET BSD socket绑定一个地址)
为了监听进来的网际连接请求,每一个服务器必须创建一个INET BSD socket并把自己的地址绑定到它上面。Bind的操作大部分由INET socket 层处理,另一些需要底层的TCP和UDP协议层的支持。已经绑定了一个地址的socket不能用于其它通讯。这意味着这个socket的状态必须是TCP_CLOSE。传递给bind操作的sockaddr包括要绑定的IP地址和一个端口号(可选)。通常,绑定的地址会是分配给支持INET地址族的网络设备的地址之中的一个,而且接口必须是开启的并能够使用。你可以用ifconfig命令看系统中哪一个网络接口当前是激活的。IP地址也可以是IP广播地址(全是1或0)。这是意味着“发送给每一个人”的特殊地址。如果这个机器作为一个透明的proxy或者防火墙,这个IP地址也可以设置成任何IP地址。不过只有具有超级用户特权的进程可以绑定任意IP地址。这个绑定的IP地址被存在sock数据结构的recv_addr和saddr域中。它们分别用于hash查找和发送IP地址。端口号是可选的,如果没有设置,会向支撑的网络请求一个空闲的。按照惯例,小于1024的端口号不能被没有超级用户特权的进程使用。如果底层的网络分配端口号,它总是分配一个大于1024的端口。
当底层的网络设备接收报文的时候,这些报文必须被转到正确的INET和BSD socket才能被处理。为此,UDP和TCP维护hash table,用于查找进来的IP信息的地址,把它们转到正确的socket/sock对。TCP是一个面向连接的协议,所以处理TCP报文比处理UDP报文所包括的信息要多。
UDP维护一个已经分配的UDP端口的hash table,udp_table。这包括sock数据结构的指针,用一个根据端口号的hash函数作为索引。因为UDP hash table比允许的端口号要小的多(udp_hash只有128,UDP_HTABLE_SIZE)表中的一些条目指向一个sock数据结构的链表,用每一个sock的next 指针连接在一起。
TCP更加复杂,因为它维护几个hast table 。但是,在绑定操作中,TCP实际上并不把绑定的sock数据结构加到它的hash table中,它只是检查请求的端口当前没有被使用。在listen操作中sock数据结构才加到TCP的hash table中。
10.4.3 Making a Connection to an INET BSD Socket
一旦创建了一个socket,如果没有用于监听进来的连接请求,它就可以用于建立向外的连接请求。对于无连接的协议,比如UDP,这个socket操作不需要做许多,但是对于面向连接的协议如TCP,它涉及在两个应用程序之间建立一个虚拟电路。
一个向外的连接只能在一个正确状态的INET BSD socket上进行:就是说还没有建立连接,而且没有用于监听进来的连接。这意味着这个BSD socket数据结构必须在SS_UNCONNECTED状态。UDP协议不在两个应用程序之间建立虚拟连接,所有发送的消息都是数据报,发出的消息可能到到也可能没有到达它的目的地。但是,它也支持BSD socket的connect操作。在一个UDP INET BSD socket上的一个连接操作只是建立远程应用程序的地址:它的IP地址和它的IP端口号。另外,它也要建立一个路由表条目的缓存区,这样,在这个BSD socket上发送的UDP数据报不需要在检查路由表数据库(除非这个路由变成无效)。这个缓存的路由信息被INET sock数据结构中的ip_route_cache指针指向。如果没有给出地址信息,这个BSD socket发送的消息就自动使用这个缓存的路由和IP地址信息。UDP把sock的状态改变成为TCP_ESTABLISHED。
对于在一个TCP BSD socket上进行的连接操作,TCP必须建立一个包括连接信息的TCP消息,并发送到给定的IP目标。这个TCP消息包括连接的信息:一个独一无二的起始消息顺序编号、发起主机可以管理的消息的最大尺寸、发送和接收的窗口大小等等。在TCP中,所有的消息都编了号,初始顺序编号用作第一个消息编号。Linux选择一个合理的随机数以避免恶意的协议攻击。每一个从TCP连接的一端发送,被另一端成功接收的消息被确认,告诉它成功地到达,而且没有损坏。没有确认的消息会被重发。发送和接收窗口大小是确认前允许的消息的数目。如果接收端的网络设备支持的最大消息尺寸比较小,则这个连接会使用两个中间最小的一个。执行向外的TCP连接请求的应用程序现在必须等待目标应用程序的响应,是接受还是拒绝这个连接请求。对于期望进来的消息的TCP sock,它被加到了tcp_listening_hash,这样进来的TCP消息可以定向到这个sock数据结构。TCP也启动计时器,这样如果目标应用程序对于请求不响应,向外的连接请求会超时。
10.4.4 Listening on an INET BSD Socket
一旦一个socket拥有了一个绑定的地址,它就可以监听指定这个绑定地址的进来的连接请求。一个网络应用程序可以不绑定地址直接在一个socket上监听,这种情况下,INET socket层找到一个未用的端口号(对于这种协议而言),自动把它绑定到这个socket上。这个socket的listen函数把socket变成TCP_LISTEN的状态,并且执行所需的和网络相关的工作,一边允许进来的连接。
对于UDP socket,改变socket的状态已经足够,但是TCP已经激活它现在要把socket的sock数据结构加到它的两个hash table中。这是tcp_bound_hash和tcp_listening_hash 表。这两个表都通过一个基于IP端口号的hash函数进行索引。
不论何时接收到一个对于激活的监听socket的进来的TCP连接请求,TCP都要建立一个新的sock数据结构表示它。这个sock数据结构在它最终被接受之前成为这个TCP连接的buttom half。它也克隆包含连接请求的进来的sk_buff并把它排在监听的sock数据结构的receive_queue队列中。这个克隆的sk_buff包括一个指针,指向这个新创建的sock数据结构。
10.4.5 Accepting Connection Requests
UDP不支持连接的概念,接受INET socket的连接请求只应用于TCP协议,在一个监听的sock上进行接受(accept)操作会从原来的监听的socket克隆出一个新的socket数据结构。然后这个accept操作传递给支撑的协议层,在这种情况下,是INET去接受任何进来的连接请求。如果底层的协议,比如UDP不支持连接,INET协议层的accept操作会失败。否则,连接的请求会传递到真正的协议,在这里,是TCP。这个accept操作可能是阻塞,也可能是非阻塞的。在非阻塞的情况下,如果没有需要accept的进来的连接,这个accept操作会失败,而新创建的socket数据结构会被废弃。在阻塞的情况下,执行accept操作的网络应用程序会被加到一个等待队列,然后挂起,直到接收到一个TCP的连接请求。一旦接收到一个连接请求,包含这个请求的sk_buff会被废弃,这个sock数据结构被返回到INET socket层,在这里它被连接到先前创建的新的socket数据结构。这个新的socket的文件描述符(fd)被返回给网络应用程序,应用程序就可以用这个文件描述符对这个新创建的INET BSD socket进行socket操作。
10.5 The IP Layer(IP层)
10.5.1 Socket Buffers
使用分成许多层,每一层使用其它层的服务,这样的网络协议的一个问题是,每一个协议都需要在传送的时候在数据上增加协议头和尾,而在处理接收的数据的时候需要删除。这让协议之间传送数据缓冲区相当困难,因为每一层都需要找出它的特定的协议头和尾在哪里。一个解决方法是在每一层都拷贝缓冲区,但是这样会没有效率。替代的,Linux使用socket 缓冲区或者说sock_buffs在协议层和网络设备驱动程序之间传输数据。Sk_buffs包括指针和长度域,允许每一协议层使用标准的函数或方法操纵应用程序数据。

图10.4显示了sk_buff数据结构:每一个sk_buff都有它关联的一块数据。Sk_buff有四个数据指针,用于操纵和管理socket缓冲区的数据。
参见include/linux/skbuff.h
head 指向内存中的数据区域的起始。在sk_buff和它相关的数据块被分配的时候确定的。
Data 指向协议数据的当前起始为止。这个指针随着当前拥有这个sk_buff 的协议层不同而变化。
Tail 指向协议数据的当前结尾。同样,这个指针也随拥有的协议层不同而变化。
End 指向内存中数据区域的结尾。这是在这个sk_buff分配的时候确定的。
另有两个长度字段len和truesize,分别描述当前协议报文的长度和数据缓冲区的总长度。Sk_buff处理代码提供了标准的机制用于在应用程序数据上增加和删除协议头和尾。这种代码安全地操纵了sk_buff中的data、tail和len字段。
Push 这把data 指针向数据区域的起始移动,并增加len字段。用于在传送的数据前面增加数据或协议头
参见include/linux/skbuff.h skb_push()
Pull 把data指针从数据区域起始向结尾移动,并减少len字段。用于从接收的数据中删除数据或协议头。
参见include/linux/skbuff.h skb_pull()
Put 把tail指针向数据区域的结尾移动并增加len字段,用于在传输的数据尾部增加数据或协议信息
参见include/linux/skbuff.h skb_put()
trim 把tail指针向数据区域的开始移动并减少len字段。用于从接收的数据中删除数据或协议尾
参见include/linux/skbuff.h skb_trim()
sk_buff数据结构也包括一些指针,使用这些指针,在处理过程中这个数据结构可以存储在sk_buff的双向环形链表中。有通用的sk_buff例程,在这些列表的头和尾中增加sk_buffs和删除其中的sk_buff。
10.5.2 Receiving IP Packets
第8 小节描述了Linux的网络设备驱动程序如何建立到核心以及被初始化。这产生了一系列device数据结构,在dev_base列表中链接在一起。每一个device数据结构描述了它的设备并提供了一组回调例程,当需要网络驱动程序工作的时候网络协议层可以调用。这些函数大多数和传输数据以及网络设备的地址有关。当一个网络设备从它的网络上接收到数据报文的时候,它必须把接收到的数据转换到sk_buff数据结构。这些接收的sk_buff在接收的时候被网络驱动程序增加到backlog队列。如果backlog队列增长的太大,那么接收的sk_buff就被废弃。如果有工作要执行,这个网络的button half标记成准备运行。
参见net/core/dev.c netif_rx()
当网络的bottom half处理程序被调度程序调用的时候,它首先处理任何等待传送的网络报文,然后才处理sk_buff的backlog backlo队列,确定接收到的报文需要传送到那个协议层。当Linux网络层初始化的时候,每一个协议都登记自己,在ptype_all列表或者ptype_base hash table中增加一个packet_type的数据结构。这个packet_type数据结构包括协议类型,一个网络驱动设备的指针,一个协议的数据接收处理例程的指针和一个指针,指向这个列表或者hash table下一个packet_type数据类型。Ptype_all链表用于探测(snoop)从任意网络设备上接收到的所有的数据报文,通常不使用。Ptype_base hash table使用协议标识符hash,用于确定哪一种协议应该接收进来的网络报文。网络的bottom half把进来的sk_buff的协议类型和任一表中的一个或多个packet_type条目进行匹配。协议可能会匹配一个或多个条目,例如当窥测所有的网络通信的时候,这时,这个sk_buff会被克隆。这个sk_buff被传递到匹配的协议的处理例程。
参见net/core/dev.c net_bh()
参见net/ipv4/ip_input.c ip_recv()
10.5.3 Sending IP Packets
报文在应用程序交换数据的过程中传送,或者也可能是为了支持已经建立的连接或为了建立连接而由网络协议产生产生。不管数据用什么方式产生,都建立一个包含数据的sk_buff,并当它通过协议层的时候增加许多头。
这个sk_buff需要传递到进行传输的网络设备。但是首先,协议,例如IP,需要决定使用哪一个网络设备。这依赖于这个报文的最佳路由。对于通过modem连接到一个网络的计算机,比如通过PPP协议,这种路由选择比较容易。报文应该要么通过loopback设备传送给本地主机,要么传送到PPP modem连接的另一端的网关。对于连接到以太网的计算机而言,这种选择比较困难,因为网络上连接了许多计算机。
对于传送的每一个IP报文,IP使用路由表解析目标IP地址的路由。对于每一个IP目标在路由表中进行的查找,成功就会返回一个描述要使用的路由的rtable数据结构。包括使用的源IP地址,网络device数据结构的地址,有时候还会有一个预先建立的硬件头。这个硬件头和网络设备相关,包含源和目的物理地址和其它同介质相关的信息。如果网络设备是以太网设备,硬件头会在图10.1中显示,其中的源和目的地址会是物理的以太网地址。硬件头和路由缓存在一起,因为在这个路由传送的每一个IP报文都需要追加这个头,而建立这个头需要时间。硬件头可能包含必须使用ARP协议才能解析的物理地址。这时,发出的报文会暂停,直到地址解析成功。一旦硬件地址被解析,并建立了硬件头,这个硬件头就被缓存,这样以后使用这个接口的IP报文就不需要进行ARP。
参见include/net/route.h
10.5.4 Data Fragmentation
每一个网络设备都有一个最大的报文尺寸,它无法传送或接收更大的数据报文。IP协议允许这种数据,会把数据分割成网络设备可以处理的报文大小的更小的单元。IP协议头包含一个分割字段,包含一个标记和分割的偏移量。
当要传输一个IP报文的时候,IP查找用来发送IP报文的网络设备。通过IP路由表来查找这个设备。每一个设备都有一个字段描述它的最大传输单元(字节),这是mtu字段。如果设备的mtu比等待传送的IP报文的报文尺寸小,那么这个IP报文必须被分割到更小的碎片(mtu大小)。每一个碎片用一个sk_buff代表:它的IP头标记了它被分割,以及这个IP报文在数据中的偏移量。最后一个报文被标记为最后一个IP碎片。如果在分割成碎片的过程中,IP无法分配一个sk_buff,这次传送就失败。
接收IP碎片比发送更难,因为IP碎片可能以任意顺序被接收,而且它们必须在重组之前全部接收到。每一次一个IP报文被接收的时候,都检查它是否是一个IP碎片。收到一个消息的第一个碎片,IP就建立一个新的ipq数据结构,并连接到等待组装的IP碎片的ipqueue列表中。当更多的IP碎片接收到的时候,就查到正确的ipq数据结构并建立一个新的ipfrag数据结构来描述这个碎片。每一个ipq数据结构都唯一描述了一个成为碎片的IP接收帧,包括它的源和目标IP地址,上层协议标识符和这个IP帧的标识符。当接收到所有的碎片的时候,它们被组装在一起成为一个单一的sk_buff,并传递到下一个协议层去处理。每一个ipq包括一个计时器,每一次接收到一个有效的碎片的时候就重新启动。如果这个计时器过期,这个ipq数据结构和它的ipfrag就被去除,并假设这个消息在传输过程中丢失了。然后由高层的协议负责重新传输这个消息。
参见net/ipv4/ip_input.c ip_rcv()
10.6 The Address Resolution Protocol (ARP)
地址解析协议的任务是提供IP地址到物理硬件地址的转换,例如以太网地址。IP在它把数据(用一个sk_buff的形式)传送到设备驱动程序进行传送的时候才需要这种转换。它进行一些检查,看这个设备是否需要一个硬件头,如果是,这个报文的硬件头是否需要重建。Linux缓存硬件头以免频繁地重建。如果硬件头需要重建,它就调用和设备相关的硬件头重建例程。所有的一台设备使用相同的通用的头重建例程,然后使用ARP服务把目标的IP地址转换到物理地址。
参见net/ipv4/ip_output.c ip_build_xmit()
参见net/ethernet/eth.c rebuild_header()
ARP协议本身非常简单,包含两种消息类型:ARP请求和ARP应答。ARP请求包括需要转换的IP地址,应答(希望)包括转换的IP地址和硬件地址。ARP请求被广播到连接到网络的所有的主机,所以,对于一个以太网所有连在以太网上的机器都可以看到这个ARP请求。拥有这个请求中包括的IP地址的机器会回应这个ARP请求,用包含它自己物理地址的ARP应答。
Linux中的ARP协议层围绕着一个arp_table数据结构的表而建立。每一个描述一个IP和物理地址的对应。这些条目在IP地址需要转换的时候创建,随着时间推移变得陈旧的时候被删除。每一个arp_table数据结构包含以下域:
Last used 这个ARP条目上一次使用的时间
Last update 这个ARP条目上一次更新的时间
Flags 描述这个条目的状态:它是否完成等等
IP address 这个条目描述的IP地址
Hardware address 转换(翻译)的硬件地址
Hardware header 指向一个缓存的硬件头的指针
Timer 这是一个timer_list的条目,用于让没有回应的ARP请求超时
Retries 这个ARP请求重试的次数
Sk_buff queue 等待解析这个IP地址的sk_buff条目的列表ARP表包含一个指针(arp_tables向量表)的表,把arp_table的条目链接在一起。这些条目被缓存,以加速对它们的访问。每一个条目用它的IP地址的最后两个字节做表的索引进行查找,然后跟踪这个条目链,直到找到正确的条目。Linux也缓存从arp_table条目预先建立的硬件头,用hh_cache数据结构的形式进行缓存。
当请求一个IP地址转换的时候,没有对应的arp_table条目,ARP必须发送一个ARP请求消息。它在表中创建一个新的arp_table条目,并把需要地址转换的包括了网络报文的sk_buff放到这个新的条目的sk_buff队列。它发出一个ARP请求并让ARP过时计时器运行。如果没有回应,ARP会重试几次。如果仍旧没有回应,ARP会删除这个arp_table条目。任何排队等待这个IP地址进行转换的sk_buff数据结构会被通知,由传输它们的上层协议负责处理这种失败。UDP不关心丢失的报文,但是TCP会在一个建立的TCP连接上试图重新发送。如果这个IP地址的属主用它的硬件地址应答,这个arp_table条目标记为完成,任何排队的sk_buff会被从对队列中删除,继续传送。硬件地址被写到每一个sk_buff的硬件头中。
ARP协议层也必须回应指明它的IP地址的ARP请求。它登记它的协议类型(ETH_P_ARP),产生一个packet_type数据结构。这意味着网络设备接收到的所有的ARP报文都会传给它。象ARP应答一样,这也包括ARP请求。它使用接收设备的device数据结构中的硬件地址产生ARP应答。
网络拓扑结构不断变化,IP地址可能被重新分配到不同的硬件地址。例如,一些拨号服务为它建立的每一个连接分配一个IP地址。为了让ARP表中包括最新的条目,ARP运行一个定期的计时器,检查所有的arp_table条目,看哪一个超时了。它非常小心,不删除包含包含一个或多个缓存的硬件头的条目。删除这些条目比较危险,因为其它数据结构依赖它们。一些arp_table条目是永久的,并被标记,所以它们不会被释放。ARP表不能增长的太大:每一个arp_table条目都要消耗一些核心内存。每当需要分配一个新的条目而ARP表到达了它的最大尺寸的时候,就查找最旧的条目并删除它们,从而修整这个表。
10.7 IP Routing
IP路由功能确定发向一个特定的IP地址的IP报文应该向哪里发送。当传送IP报文的时候,会有许多选择。目的地是否可以到达?如果可以,应该使用哪一个网络设备来发送?是不是有不止一个网络设备可以用来到达目的地,哪一个最好?IP路由数据库维护的信息可以回答这些问题。有两个数据库,最重要的是转发信息数据库(Forwarding Information Database)。这个数据库是已知IP目标和它们最佳路由的详尽的列表。另一个小一些,更快的数据库,路由缓存(route cache)用于快速查找IP目标的路由。象所有缓存一样,它必须只包括最常访问的路由,它的内容是从转发信息数据库中得来的。
路由通过BSD socket接口的IOCTL请求增加和删除。这些请求被传递到具体的协议去处理。INET协议层只允许具有超级用户权限的进程增加和删除IP路由。这些路由可以是固定的,或者是动态的,不断变化的。多数系统使用固定路由,除非它们本身是路由器。路由器运行路由协议,不断地检查所有已知IP目标的可用的路由。不是路由器的系统叫做末端系统(end system)。路由协议用守护进程的形式来实现,例如GATED,它们也使用BSD socket接口的IOCTL来增加和删除路由。
10.7.1 The Route Cache
不论何时查找一个IP路由的时候,都首先在路由缓存中检查匹配的路由。如果在路由缓存中没有匹配的路由,才查找转发信息数据库。如果这里也找不到路由,IP报文发送会失败,并通知应用程序。如果路由在转发信息数据库而不在路由缓存中,就为这个路由产生一个新的条目并增加到路由缓存中。路由缓存是一个表(ip_rt_hash_table),包括指向rtable数据结构链的指针。路由表的索引是基于IP地址最小两字节的hash 函数。这两个字节通常在目标中有很大不同,让hash value可以最好地分散。每一个rtable条目包括路由的信息:目标IP地址,到达这个IP地址要使用的网络设备(device结构),可以使用的最大的信息尺寸等等。它也有一个引用计数器(refrence count),一个使用计数器(usage count)和上次使用的时间戳(在jiffies中)。每一次使用这个路由的时候这个引用计数器就增加,显示利用这个路由的网络连接数目,当应用程序停止使用这个路由的时候就减少。使用计数器每一次查找路由的时候就增加,用来让这个hash条目链的rtable条目变老。路由缓存中所有条目的最后使用的时间戳用于定期检查这个rtable是否太老。如果这个路由最近没有使用,它就从路由表中废弃。如果路由保存在路由缓存中,它们就被排序,让最常用的条目在hash链的前面。这意味着当查找路由的时候找到这些路由会更快。
参见net/ipv4/route.c check_expire()
10.7.2 The Forwarding Information Database

转发信息数据库(图10.5显示)包含了当时从IP的观点看待系统可用的路由。它是非常复杂的数据结构,虽然它已经进行了合理有效的安排,但是它对于参考而言并不是一个快速的数据库。特别是如果每一个传输的IP报文都在这个数据库中查找目标会非常慢。这也是为什么要有路由缓存:加速已经知道最佳路由的IP报文的传送。路由缓存从这个转发信息数据库得到,表示了它最常用的条目。
每一个IP子网用一个fib_zone数据结构表示。所有这些都被fib_zones hash表指向。Hash索引取自IP子网掩码。所有通向同一子网的路由都用排在每一个fib_zone数据结构的fz_list队列中得的成对的fib_node和fib_info数据结构来描述。如果这个子网的路由数目变得太大,就生成一个hash table,让fib_node数据结构的查找更容易。
对于同一个IP子网,可能存在多个路由,这些路由可能穿过多个网关之一。IP路由层不允许使用相同的一个网关对于一个子网有多于一个路由。换句话说,如果对于一个子网有多个路由,那么要保证每一个路由都是用不同的网关。和每一个路由关联的是它的量度(metric),这是用来衡量这个路由的益处。一个路由的量度,基本上,是它在到达目标子网之前必须跳过的子网数目。这个量度越高,路由越差。
11、Kernel Mechanisms (核心机制)
11.1 Bottom Half Handling
通常在核心中会有这样的时候:你不希望执行工作。一个好例子是在中断处理的过程中。当引发了中断,处理器停止它正在执行的工作,操作系统把中断传递到适当的设备驱动程序。设备驱动程序不应该花费太多时间来处理中断,因为在这段时间,系统中的其他东西都不能运行。通常一些工作可以在稍后的时候进行。Linux发明了boffom half处理程序,这样设备驱动程序和Linux核心的其它部分可以把可以稍后作的工作排队。图11.1显示了同bottom half 处理相关的核心数据结构。有多达32个不同的bottom half处理程序:bh_base是一个指针的向量表,指向核心的每一个bottom half处理例程,bh_active和bh_mask按照安装和激活了哪些处理程序设置它们的位。如果bh_mask的位N设置,则bh_base中的第N个元素会包含一个bottom half例程的地址。如果bh_active的第N位设置,那么一旦调度程序认为合理,就会调用第N位的bottom half处理程序。这些索引是静态定义的:timer bottom half 处理器优先级最高(索引0),console bottom half处理程序优先级次之(index 1)等等。通常bottom half 处理例程会有和它关联的任务列表。例如这个immediate buttom half handler 通过包含需要立即执行的任务的immediate任务队列(tq_immediate)来工作。
参见include/linux/interrupt.h


核心的一些bottom half处理程序和设备有关,但是其它的是更一般的:
TIMER 这个处理程序在每一次系统定时时钟中断被标记成为激活,用来驱动核心的时钟队列机制
CONSOLE 这个处理程序用来处理控制台消息
TQUEUE 这个处理程序用来处理TTY消息
NET 这个处理程序用来处理通用的网络处理
IMMEDIATE 通用的处理程序,一些设备驱动程序用来排列稍后进行的工作
设备驱动程序或者核心的其它部分,需要调度稍后进行的工作的时候,它就在适当的系统队列中增加这个工作,例如时钟队列,然后就发送信号到核心,一些bottom half处理需要进行。它通过设置bh_active中的合适的位来做到这点。如果驱动程序在immediate队列排列了一些东西并希望immediate bottom half 处理程序会运行并处理它的时候就设置第8位。每一次系统调用的最后,把控制权返回调用程序之前都检查bh_active的位掩码。如果有任意位被设置,相应的激活的bottom half 处理例程就被调用。首先检查位0,然后1直到位31。调用每一个bottom half 处理例程调用的时候就清除bh_active中相应的位。Bh_active是易变的:它只在调用调度程序之间有意义,通过设置它,当没有需要作的工作的时候可以不调用相应的bottom half 处理程序。
Kernel/softirq.c do_bottom_half()
11.2 Task Queues(任务队列)
任务队列是核心用来把工作推迟到以后的方法。Linux由一个通用的机制,把工作排列在队列中并在稍后的时间进行处理。任务队列通常和bottom half处理程序一起使用:当timer bottom half 处理程序运行的时候处理计时器任务队列。任务队列是一个简单的数据结构,参见图11.2,包括一个tq_struct数据结构的单链表,每一个包括例程的指针和指向一些数据的指针。
参见include/linux/tqueue.h 当这个任务队列的单元被处理的时候调用这个例程,数据的指针会传递给它。
核心的任何东西,例如设备驱动程序,都可以创建和使用任务队列,但是有三个任务队列是由核心创建和管理的:
timer 这个队列用于排列在下一个系统时钟之后尽可能运行的工作。每一个时钟周期,都检查这个队列,看是否有条目,如果有,时钟队列的bottom half 处理程序被标记为激活。当调度在一次运行的时候,就处理这个时钟队列bottom half 处理程序以及其它bottom half 处理程序。不要把这个队列和系统计时器混淆,那是一个更复杂的机制
immediate 这个队列也是在调度程序处理激活的bottom half处理程序的时候被处理。这个immediate bottom half 处理程序没有timer 队列bottom half 处理程序优先级高,所以这些任务会迟疑写运行。
Scheduler 这个任务队列由调度程序直接处理。它用于支持系统中的其它任务队列,这种情况下,要运行的任务会是一个处理任务队列(例如设备驱动程序)的例程。
当处理任务队列的时候,指向队列中的一个单元的指针从队列中删除,用一个null指针代替。实际上,这种删除是一个不能被中断的原子操作。然后为队列中的每一个单元顺序调用它的处理例程。队列中的单元通常是静态分配的数据。但是没有一个固有的机制来废弃分配的内存。任务队列处理例程只是简单地移到列表中的下一个单元。保证正确地清除任何分配的核心内存是任务本身的工作。
11.3 Timers
一个操作系统都需要有能力把一个活动调度到将来的一个时间,这需要一种机制让活动可以调度到相对准确的时间去运行。任何希望支持一个操作系统的微处理器都需要一个可编程间隔适中,定期中断处理器。这个定期的中断就是系统时钟周期(system clock tick),它就象一个节拍器,指挥系统的活动。Linux用非常简单的方式看待时间:它从系统启动的时候开始用时钟周期测量时间。任何系统时间都基于这种量度,叫做jiffers,和全局变量同名。
Linux有两种类型的系统计时器,每一种都排列例程,在特定的系统时间调用,但是实现的方式上它们有轻微的不同。图11.3显示了两种机制。第一种,旧的计时器机制,有一个静态的数组,有32个指向timer_struct数据结构的指针和一个激活的时钟的掩码,timer_active。计时器放在这个计时器表中的什么位置是静态定义的(和bottom half 处理程序中的bh_base不同)。条目在系统初始化的时候被加到这个表中。第二种机制,使用一个timer_list数据结构的链接表中,按照过期时间的数据排列。
参见include/linux/timer.h
每一种方法都使用jiffies中的时间作为过期时间,这样一个希望运行5秒的计时器会有一个可以换算为5秒的jiffies单元加上当前系统时间得到计时器过期时的系统时间(以jiffies为单位)。每一次系统时钟周期,timer bottom half处理程序被标记为激活,所以当下一次调度程序运行的时候,会处理计时器队列。Timer bottom half处理程序会处理全部两种类型的系统计时器。对于旧的系统计时器,检查timer_active位掩码中置了位的。如果一个激活的计时器过期(过期时间小于当前的系统jiffies),就调用它的计时器例程,并清除它的激活位。对于新的系统计时器,检查timer_list数据结构的链接表中的条目。每一个过期的计时器从这个列表中删除并调用它的例程。新的计时器机制的优点在于它可以向计时器例程传递参数。
参见kernel/sched.c timer_bh() run_old_timers() run_timer_list()
11.4 Wait Queues(等待队列)
许多时候一个进程必须等待一个系统资源。例如,一个进程可能需要描述文件系统中一个目录的VFS inode,但是这个inode可能不在buffer cache钟。这时,系统必须等待这个inode从包含这个文件系统的物理介质中取出来,然后才能继续。
Linux核心使用一个简单的数据结构,一个等待队列(见图11.4),包含一个指向进程的task_struct的指针和一个指向等待队列中下一个元素的指针。
参见include/linux/wait.h

当进程被增加到了一个等待队列的结尾的时候,它们可能时可被中断或者不可中断的。可中断的进程在等待队列等待的过程中可以被事件中断,例如过期的计时器或者发送来的信号等事件。等待进程的状态会反映出来,可以是INTERRUPTIBLE或者UNINTERRUPTIBLE。因为这个进程现在不能继续运行,就开始运行调度程序,当它选择了一个新的进程运行的时候,这个等待的进程就会被挂起。
当处理等待队列的时候,等待队列中的每一个进程的状态都被设置位RUNNING。如果进程从运行队列中删除了,它就被放回到运行队列。下一次运行调度程序的时候,在等待队列的进程现在就成为运行的候选,因为它们不再等待了。当一个等待队列的进程被调度的时候,首先要作的是把自己从等待队列中删除。等待队列可以用于同步访问系统资源,Linux用这种方式实现它的信号灯。
11.5 Buzz Locks
通常叫做spin locks,这是保护一个数据结构或代码段的一个原始方法。它们一次只允许一个进程处于一个重要的代码区域。Linux使用它们来限制对于数据结构中的域的访问,它利用一个整数字段作为锁。每一个希望进入这个区域的进程试图把锁的起始值从0变为1。如果当前致使1,进程重新尝试,在一个紧凑的代码循环中旋转(spin)。对于保存这个锁的内存位置的访问必须具有原子性,读取它的值、检查它是0然后把它改为1,这个动作不能被其他任何进程打断。多数CPU结构通过特殊的指令为此提供支持,但是你也可以使用未缓存的主内存实现这种buzz lock。
当属主进程离开这个重要的代码区域的时候,它减小这个buzz lock,让它的值返回到0。任何在这个锁上循环的进程现在会读到0,第一个做到的进程会把它增加到1并进入这个重要区域。
11.6 Semaphores(信号灯)
信号灯用于保护重要的代码区域或数据结构。记住,对于重要数据结构例如描述一个目录的VFS inode的每一次访问都是通过核心为进程执行的。如果允许一个进程改变另一个进程使用的重要的数据结构是非常危险的。实现的方法之一是在要访问的重要的代码片上使用一个buzz lock,虽然这是最简单的方法但是不会有太好的系统性能。Linux使用信号灯实现一次只允许一个进程访问重要的代码和数据区域:所有其它希望访问这个资源的进程会被迫等待直到信号灯空闲。等待的进程被刮起,系统中的其它进程和平时一样正常运行。
一个Linux信号灯数据结构包括以下信息:
参见include/asm/semaphore.h
count 这个字段记录了希望使用这个资源的进程数。正的数值表示这个资源可用。负值或0表示有进程在等待。起始值1表示同一时间有一个且只有一个进程可以使用这个资源。当进程希望使用这个资源的时候它们减小这个count,当结束对这个资源的使用的时候,它们增加这个count
waking 等待这个资源的进程数,这也是等待当资源空闲的时候被唤醒的进程数。
Wait queue 当进程等待这个资源的时候它们被放到这个等待队列
Lock 当访问waking域所用的buzz lock
假设信号灯的起始值是1,第一个到来的进程会看到count是正的,把它减少1,成为0。这个进程现在“拥有”这个受到信号灯保护的重要的代码片或资源。当进程离开这个重要区域的时候它增加信号灯的count。最理想的情况是没有其它进程竞争这个重要区域的所有权。Linux实现的信号灯在这种最常见的情况下工作的非常高效。
如果另一个进程希望进入这个重要区域,而它已经被一个进程拥有,它也会减少这个count。因为这个count现在是-1,这个进程不能进入这个重要区域。它必须等待直到拥有的进程退出来。Linux让等待的进程睡眠直到拥有权的进程退出这个重要区域把它唤醒。等待进程把它自己加到信号灯的等待队列中,并循环检查waking字段的值,调用调度程序直到waking非0。
这个重要区域的属主增加信号灯的count,如果它小于或等于0,那么还有进程在睡眠,等待这个资源。理想情况下,信号灯的count会返回到它的起始值1,这样就不需要做什么工作。所有权的进程增加waking计数器并唤醒在信号灯等待队列中睡眠的进程。当等待的进程被唤醒之后,waking计数器现在是1,它知道它现在可以进入这个重要区域。它减少waking计数器,把它返回0并继续。所有对于这个信号灯的waking字段的访问都用信号灯的lock这个buzz lock来保护。
12、Modules
Linux核心如何只在需要的时候才动态加载函数,例如文件系统?
Linux是一个完整的核心,就是说,它是一个单一的巨大的程序,核心的功能组件可以访问它的所有的内部数据结构以及例程。另一种方法是使用一个微内核的结构,核心的功能片被分成独立的单元,互相之间有严格的通讯机制。这样通过配置进程向核心增加新的组件不花多少时间。比如你希望增加一个NCR 810 SCSI卡的SCSI驱动程序,你不需要把它连接到核心。否则你不得不配置并建立一个新的核心才能使用这个NCR 810。作为一种变通,Linux允许在你需要的时候动态地加载和卸载操作系统的组件。Linux的模块是可以在系统启动之后任何时候动态连接到核心的代码块。它们可以在不被需要的时候从核心删除并卸载。大多数Linux核心模块是设备驱动程序,伪设备驱动程序比如网络驱动程序或文件系统。
你可以使用insmod和rmmod命令明确地加载和卸载Linux核心模块,或者在需要这些模块的时候由核心自己要求核心守护进程(kerneld)加载和卸载这些模块。在需要的时候动态地加载代码相当有吸引力,因为它让核心可以保持最小而且核心非常灵活。我当前的Intel核心大量使用模块,它只有406K大小。我通常只适用VFAT文件系统,所以我建立我的Linux核心,当我安装一个VFAT分区的时候自动加载VFAT文件系统。当我卸载VFAT文件系统的时候,系统探测到我不再需要VFAT文件系统模块,把它从系统中删除。模块也可以用来尝试新的核心代码而不需要每次都创建和重启动核心。但是,没有这么好的事情,使用核心模块通常伴随轻微的性能和内存开支。一个可加载模块必须提供更多的代码,这种代码和额外的数据结构会占用更多一点的内存。另外因为间接访问核心资源也让模块的效率轻微降低。
一旦Linux核心加载,它就和普通核心代码一样成为核心的一部分。它和任何核心代码拥有相同的权利和义务:换句话说,Linux核心模块和所有的核心代码或设备驱动程序一样可能让核心崩溃。
既然模块在需要的时候可以使用核心资源,它们必须能够找到这些资源。比如一个模块需要调用kmalloc(),核心内存分配例程。当建立的时候(build),模块不知道内存中kmalloc()在哪里,所以当这个模块加载的时候,在模块能够工作之前,核心必须整理模块对于kmmalloc()的所有的引用。核心在核心符号表中保存了所有核心资源的列表,所以当模块加载的时候它可以解析模块中对于这些资源的引用。Linux允许模块堆栈(堆砌),就是一个模块需要另一个模块的服务。例如VFAT文件系统模块需要FAT 文件系统模块的服务,因为VFAT文件系统或多或少是FAT文件系统上的扩展。一个模块需要另一个模块的服务或资源的情况和一个模块需要核心自己的服务和资源的情况非常相似,只不过这时请求的服务在另一个,此前已经加载的模块钟。当每一个模块加载的时候,核心修改它的符号表,把这个新加载的模块的所有输出的资源或符号加到核心符号表中。这意味着,当下一个模块加载的时候,它可以访问已经加载的模块的服务。
当时图卸载一个模块的时候,核心需要知道这个模块不在用,它还需要一些方法来通知它准备卸载的模块。用这种方法模块可以在它从核心删除之前释放它占用的任何的系统资源,例如核心内存或中断。当模块卸载的时候,核心把这个模块输出到核心符号表中所有的符号都删除。
除了写的不好的可加载模块可能破坏操作系统之外,还有另一个危险。如果你加载一个为比你当前运行的核心要早或迟的核心建立的模块会发生什么?如果这个模块执行一个核心例程而提供了错误的参数就会引起问题。核心可以选择防止这种情况,当模块加载的时候进行严格的版本检查。
12.1 Loading a Module(加载一个模块)
用两种方法可以加载一个核心模块。第一种使用insmod命令手工把它插入到核心。第二种,更聪明的方法是在需要的时候加载这个模块:这叫做按需加载(demand loading)。当核心发现需要一个模块的时候,例如当用户安装一个不在核心的文件系统的时候,核心会请求核心守护进程(kerneld)试图加载合适的模块。
Kerneld和insmod,lsmod以及rmmod都在modules程序包中。
核心守护进程通常是拥有超级用户特权的一个普通的用户进程。当它启动的时候(通常是在系统启动的时候启动),它打开一个通向核心的IPC通道。核心使用这个连接向kerneld发送消息,请求它执行大量的任务。Kerneld的主要功能是加载和卸载核心模块,但是它也可以执行其它任务,比如需要的时候在串行线上启动PPP连接,不需要的时候把它关闭。Kerneld本身并不执行这些任务,它运行必要的程序比如insmod来完成工作。Kerneld只是核心的一个代理,调度它的工作。
参见include/linux/kerneld.h
insmod 命令必须找到它要加载的被请求的核心模块。按徐加载的核心模块通常放在/lib/mmodules/kernel-version目录里边。核心模块和系统中的其它程序一样是连接程序的目标文件,但是它们被连接成可以重定位的映像。就是没有连接到特定地址去运行的映像。它们可以是a.out或elf格式的目标文件。Insmod指向一个特权的系统调用,找出系统的输出符号。它们以符号名称和值(例如它的地址)的形式成对存放。核心的输出符号表放在核心维护的模块列表中的第一个module数据结构,用module_list指针指向。只有在核心编译和连接的时候特殊指定的符号才加到这个表中,而并非核心的每一个符号都输出它的模块。例如符号“request_irq”是一个系统例程,当一个驱动程序希望控制一个特定的系统中断的时候必须调用它。在我当前的核心上,它的值是0x0010cd30。你可以检查文件/proc/ksyms或使用ksyms工具简单地查看输出的核心符号和它们的值。Ksyms工具可以向你显示所有的输出的核心符号或者只显示哪些加载模块输出的符号。Insmod把模块读取到它的虚拟内存,使用核心的输出符号来整理这个模块对于核心例程和资源的未解析的引用。这个整理过程是用向内存中的模块映像打补丁的方式进行,insmod物理上把符号的地址写到模块的合适的位置。
参见kernel/module.c kernel_syms() include/linux/module.h
当insmod整理完了模块对于输出的核心符号的引用之后,他向核心请求足够的空间放置新的核心,又是通过特权的系统调用。核心分配一个新的module数据结构和足够的核心内存来存放这个新的模块,并把它放置到核心的模块列表的最后。这个新的模块被标记为UNINITIALIZED。图12.1显示了核心模块列表的后面两个模块:FAT和VFAT被加载到了内存。图中没有显示的有列表的第一个模块:这是一个伪模块,用于放置核心的输出符号表。你可以使用命令lsmod列出所有加载的核心模块和它们之间的依赖关系。Lsmod只是简单地把从核心module数据结构列表中提取的/proc/modules重新安排了格式。核心为模块分配的内存映射到insmod进程的地址空间,所以它可以访问它。Insmod把模块拷贝到分配的空间,并把它重定位,这样它就可以从被分配的核心地址运行。必须进行重定位,因为一个模块不能期待在两次被加载到相同的地址或者在两个不同的Linux系统上被加载到相同的地址。这一次,重定位又关系到要用适当的地址为模块的映像打补丁。
参见kernel/module.c create_module()
新的模块也向核心输出符号,Insmod建立一个输出映像表。每一个核心模块必须包含模块初始化和模块清除的历程,这些符号必须是专用的而不是输出的,但是insmod必须知道它们的地址,能把它们传递给核心。所有这些做好之后,Insmod现在准备初始化这个模块,它执行一个特权的系统调用,把这个模块的初始化和清除例程的地址传递给核心。
参见kernel/module.c sys_init_module()
当一个新的模块加到核心的时候,它必须更新核心的符号表并改变被新的模块使用的模块。其它模块依赖的模块必须在它们的符号表之后维护一个引用列表,用它们的module数据结构指向。图12.1显示了VFAT文件系统模块依赖于FAT文件系统模块。所以FAT模块包含一个到VFAT模块的引用:这个引用在VFAT模块加载的时候增加。核心调用模块的初始化例程,如果成功,它开始安装这个模块。模块的清除例程的地址保存在它的module数据结构中,当这个模块卸载的时候核心会去调用。最后,模块的状态被设置为RUNNING。
12.2 Unloading a Module
模块可以使用rmmod命令删除,但是kerneld可以把所有不用的按需加载的模块从系统中删除。每一次它的空闲计时器到期的时候,kerneld执行系统调用,请求从系统删除所有的不需要的按需加载的模块。这个计时器的值由你在启动kerneld的时候设定:我的kerneld每180秒检查一次。如果你安装了一个iso9660 CD ROM而你的iso9660文件系统是一个可加载模块,那么,在CD ROM卸载不久,iso9660模块会从核心中删除。
如果核心中的其它组件依赖于一个模块,它就不能被删除。例如如果你安装了一个或更多的VFAT文件系统,你就不能卸载VFAT模块。如果你检查ls输出,你会看到每一个模块关联一个计数器。例如:
Module: #pages: Used by:
msdos 5 1
vfat 4 1 (autoclean)
fat 6 [vfat msdos] 2 (autoclean)这个计数器(count)是依赖于这个模块的核心实体的数目。在上例中,vfat和msdos都依赖于fat模块,所以fat模块的计数器是2。Vfat和msdos模块的依赖数都是1,因为它们都有一个安装的文件系统。如果我加载另外一个VFAT文件系统,那么vfat模块的计数器会变成2。一个模块的计数器放在它的映像的第一个长字中(longword)。
因为它也放置AUTOCLEAN和VISITED标志,所以这个字段有一些轻微过载。这些标志都用于按需加载模块。这些模块被标记为AUTOCLEAN,这样系统可以识别出哪些它可以自动卸载。VISITED标志表示这个模块被一个或多个系统组件使用:只要另一个组件使用它就设置这个标志。每一次kerneld请求系统删除不用的按需加载的模块的时候,它都查看系统中所有的模块,找到合适的候选。它只查看标记为AUTOCLEAN而且状态是RUNNING的模块。如果这个候选的VISITED标记被清除,那么它就删除这个模块,否则它就清除这个VISITED标记,继续查找系统中的下一个模块。
假设一个模块可以被卸载,就调用它的清除例程(cleanup),让它释放它所分配的核心资源。这个module数据结构被标记为DELTED,从核心模块列表中删除。任何其它的它所依赖的模块的引用表被修改,这样它们不再把它当作一个依赖者。这个模块需要的所有的核心内存被释放。
参见kernel/module.c delete_module()
13、The Linux Kernel Sources(Linux核心源程序)
Linux核心源程序的什么地方开始查看特定的核心功能?
练习查看核心源程序能够对于Linux操作系统有一个深入地理解。本小节给出核心源程序的概览:它们如何组织,你应该从哪里开始查找特定的代码。
Where to Get The Linux Kernel Sources(从哪里得到Linux核心源程序)
所有的主要的Linux分发(Craftworks,Debian,Slackware,RedHat 等等)中间都有核心源程序。通常L安装在你的Linux系统上的Linux核心都是用这些源程序建立的。实际上这些源程序显得有些过时,最新的源程序它们在ftp://ftp.cs.helsinki.fi和其它所有的镜像的web站点。Helsinki的web站点最新,但是其它站点例如MIT和Sunsite也不会太落后。
如果你无法访问web,还有许多CDROM厂家用非常合理的费用提供世界主要web站点的块找。一些甚至提供预订服务,按季或月进行更新。你的本地的Linux用户组也是一个源程序的好的来源。
Linux核心源程序有一个非常简单的编号系统。任何偶数的核心(例如2.0.30)都是一个稳定的发行的核心,而任何奇数的核心(例如2.1.42)都是一个开发中的核心,所有案例皆取自基于稳定的2.0.30源代码。开发版的核心具有所有的最新特点和所有最新的设备的支持,但是它们可能不稳定,可能不是你所要的,但是让Linux社团测试最新核心是很重要的。这样可以让整个社团都进行测试。记住,即使你测试非生产用核心,最好也要备份你的系统。
对于核心源程序的改动作为patch文件分发。工具patch可以对于一系列源文件应用一系列修改。例如,如果你有2.0.29的源程序树,而你希望转移到2.0.30,你可以取到2.0.30的patch文件,并把这些patch(编辑)应用到源程序树上:
$ cd /usr/src/linux
$ patch -p1 < patch-2.0.30这样可以不用拷贝整个源程序树,特别对于慢速的串行连接。一个核心补丁(正式和非正式的)的好来源是http://www.linuxhq.com
How The Kernel Sources Are Arranged(核心源程序如何组织)
在源程序树的最上层你会看到一些目录:
arch arch子目录包括所有和体系结构相关的核心代码。它还有更深的子目录,每一个代表一种支持的体系结构,例如i386和alpha。
Include include子目录包括编译核心所需要的大部分include文件。它也有更深的子目录,每一个支持的体系结构一个。Include/asm是这个体系结构所需要的真实的include目录的软链接,例如include/asm-i386。为了改变体系结构,你需要编辑核心的makefile,重新运行Linux的核心配置程序
Init 这个目录包含核心的初始化代码,这时研究核心如何工作的一个非常好的起点。
Mm 这个目录包括所有的内存管理代码。和体系结构相关的内存管理代码位于arch/*/mm/,例如arch/i386/mm/fault.c
Drivers 系统所有的设备驱动程序在这个目录。它们被划分成设备驱动程序类,例如block。
Ipc 这个目录包含核心的进程间通讯的代码
Modules 这只是一个用来存放建立好的模块的目录
Fs 所有的文件系统代码。被划分成子目录,每一个支持的文件系统一个,例如vfat和ext2
Kernel 主要的核心代码。同样,和体系相关的核心代码放在arch/*/kernel
Net 核心的网络代码
Lib 这个目录放置核心的库代码。和体系结构相关的库代码在arch/*/lib/
Scripts 这个目录包含脚本(例如awk和tk脚本),用于配置核心
Where to Start Looking(从哪里开始看)
看像Linux核心这么巨大复杂的程序相当困难。它就像一个巨大的线球,显示不出终点。看核心的一部分代码通常会引到查看其它几个相关的文件,不就你就会忘记你看了什么。下一节给你一个提示,对于一个给定的主题,最好看源程序树的那个地方。
System Startup and Initialization(系统启动和初始化)
在一个Intel系统上,当loadlin.exe或LILO把核心加载到内存并把控制权交给它的时候,核心开始启动。这一部分看arch/i386/kernel/head.S。head.S执行一些和体系结构相关的设置工作并跳到init/main.c中的main()例程。
Memory Management(内存管理)
代码大多在mm但是和体系结构相关的代码在arch/*/mm。Page fault处理代码在mm/memory.c中,内存映射和页缓存代码在mm/filemap.c 中。Buffer cache 在mm/buffer.c中实现,交换缓存在mm/swap_state.c和mm/swapfile.c中。
Kernel
大部分相对通用的代码在kernel,和体系结构相关的代码在arch/*/kernel。调度程序在kernel/sched.c,fork代码在kernel/fork.c。bottom half 处理代码在include/linux/interrupt.h。task_struct数据结构可以在include/linux/sched.h中找到
PC
PCI伪驱动程序在drivers/pci/pci.c,系统范围的定义在include/linux/pci.h。每一种体系结构都有一些特殊的PCI BIOS代码,Alpha AXP的位于arch/alpha/kernel/bios32.c
Interprocess Communication
全部在ipc目录。所有系统V IPC对象都包括ipc_perm数据结构,可以在include/linux/ipc.h中找到。系统V消息在ipc/msg.c中实现,共享内存在ipc/shm.c中,信号灯在ipc/sem.c。管道在ipc/pipe.c中实现。
Interrupt Handling
核心的中断处理代码几乎都是和微处理器(通常也和平台)相关。Intel中断处理代码在arch/i386/kernel/irq.c它的定义在incude/asm-i386/irq.h。
Device Drivers(设备驱动程序)
Linux核心源代码的大部分代码行在它的设备驱动程序中。Linux所有的设备驱动程序源代码都在drivers中,但是它们被进一步分类:
/block 块设备驱动程序比如ide(ide.c)。如果你希望查看所有可能包含文件系统的设备是如何初始化的,你可以看drivers/block/genhd.c中的device_setup()。它不仅初始化硬盘,也初始化网络,因为你安装nfs文件系统的时候需要网络。块设备包括基于IDE和SCSI设备。
/char 这里可以查看基于字符的设备比如tty,串行口等。
/cdrom Linux所有的CDROM代码。在这里可以找到特殊的CDROM设备(比如Soundblaster CDROM)。注意ide CD驱动程序是drivers/block中的ide-cd.c,而SCSI CD驱动程序在drivers/scsi/scsi.c中
/pci PCI伪驱动程序。这是一个观察PCI子系统如何被映射和初始化的好地方。Alpha AXP PCI整理代码也值得在arch/alpha/kernel/bios32.c中查看
/scsi 在这里不但可以找到所有的Linux支持的scsi设备的驱动程序,也可以找到所有的SCSI代码
/net 在这里可以找到网络设备驱动程序比如DEC Chip 21040 PCI以太网驱动程序在tulip.c中
/sound 所有的声卡驱动程序的位置
File Systems(文件系统)
EXT2文件系统的源程序都在fs/ext2/子目录,数据结构的定义在include/linux/ext2_fs.h,ext2_fs_i.h和ext2_fs_sb.h中。虚拟文件系统的数据结构在include/linux/fs.h中描述,代码是fs/*。Buffer cache和update 核心守护进程都是用fs/buffer.c实现的
Network(网络)
网络代码放在net子目录,大部分的include文件在include/net。BSD socket代码在net/socket.c,Ipv4 INET socket 代码在net/ipv4/af_inet.c中。通用协议的支持代码(包括sk_buff处理例程)在net/core中,TCP/IP网络代码在net/ipv4。网络设备驱动程序在drivers/net
Modules(模块)
核心模块代码部分在核心,部分在modules包中。核心代码全部在kernel/modules.c,数据结果和核心守护进程kerneld的消息则分别在include/linux/module.h和include/linux/kerneld.h中。你可能也希望在include/linux/elf.h中查看一个ELF目标文件的结构。
Appendix A
Linux Data Structures(Linux数据结构)
Block_dev_struct
block_dev_struct数据结构用于登记可用的块设备,让buffer cache使用。它们放在blk_dev向量表中。
参见include/linux/blkdev.h
struct blk_dev_struct {
void (*request_fn)(void);
struct request * current_request;
struct request plug;
struct tq_struct plug_tq;
};
buffer_head
buffer_head数据结构存放buffer cache中一个块缓冲区的信息。
参见include/linux/fs.h
device
系统中的每一个网络设备都用一个device数据结构表示。
参见 include/linux/netdevice.h
device_struct
device_struct数据结构用于登记字符和块设备(存放这个设备的名称和可能进行的文件操作)。Chrdevs和blkdevs向量表中的每一个有效的成员都分别代表一个字符或块设备。
参见fs/devices.c
struct device_struct {
const char * name;
struct file_operations * fops;
};file
每一个打开的文件、socket等等都用一个file数据结构代表。
参见include/linux/fs.h
file_struct
file_struct数据结构描述了一个进程打开的文件。
参见include/linux/sched.h
gendisk
gendisk数据结构存放硬盘的信息。用在初始化过程中找到磁盘,探测分区的时候。
参见include/linux/genhd.h
inode
VFS inode数据结构存放磁盘上的一个文件或目录的信息。
参见include/linux/fs.h
ipc_perm
ipc_perm数据结构描述一个系统V IPC对象的访问权限。
参见include/linux/ipc.h
irqaction
irqaction数据结构描述系统的中断处理程序。
参见include/linux/interrupt.h
linux_binfmt
Linux理解的每一个二进制文件格式都用一个linux_binfmt数据结构表示。
参见include/linux/binfmt.h
mem_map_t
mem_map_t数据结构(也叫做page)用于存放每一个物理内存页的信息。
参见include/linux/mm.h
mm struct
mm_struct数据结构用于描述一个任务或进程的虚拟内存。
参见include/linux/sched.h
pci_bus
系统中的每一个PCI总线用一个pci_bus数据结构表示。
参见include/linux/pci.h
pci_dev
系统中的每一个PCI设备,包括PCI-PCI和PCI-ISA桥设备都用一个pci_dev数据结构代表。
参见include/linux/pci.h
request
request用于向系统中的块设备发出请求。请求都是从/向buffer cache读/写数据块。
参见include/linux/blkdev.h
rtable
每一个rtable数据结构都存放向一个IP主机发送报文的路由的信息。Rtable数据结构在IP route缓存中使用。
参见include/net/route.h
semaphore
信号灯用于保护重要数据结构和代码区域。
参见include/asm/semaphore.h
sk_buff
sk_buff数据结构当网络数据在协议层之间移动的过程中描述网络数据。
参见include/linux/sk_buff.h
sock
每一个sock数据结构都存放一个BSD socket中和协议相关的信息。例如,对于一个INET socket,这个数据结构会存放所有的TCP/IP和UDP/IP相关的信息。
参见include/linux/net.h
socket
每一个socket数据结构都存放一个BSD socket的信息。它不会独立存在,实际上是VFS inode数据结构的一部分。
参见include/linux/net.h
task_struct
每一个task_struct描述系统中的一个任务或进程。
参见include/linux/sched.h
timer_list
timer_list数据结构用于实现进程的实时计时器。
参见include/linux/timer.h
tq_struct
每一个任务队列(tq_struct)数据结构都存放正在排队的工作的信息。通常是一个设备驱动程序需要的任务,但是不需要立即完成。
参见include/linux/tqueue.h
vm_area_struct
每一个vm_area_struct数据结构描述一个进程的一个虚拟内存区。
参见include/linux/mm.h
额外补充:
1、Hardware Basic(硬件基础知识)
1)CPU
CPU,或者说微处理器,是所有计算机系统的心脏。微处理器进行数学运算,逻辑操作并从内存中读取指令并执行指令,进而控制数据流向。计算机发展的早期,微处理器的各种功能模块是由相互分离(并且尺寸上十分巨大)的单元构成。这也是名词“中央处理单元”的起源。现代的微处理器将这些功能模块集中在一块非常小的硅晶片制造的集成电路上。名词CPU、微处理器和处理器可以交替使用。
微处理器处理二进制数据:这些数据由1和0组成。这些1和0对应电气开关的开或关。就好像42代表4个10和2个单元,二进制数字由一系列代表2的幂数的数字组成。这里,幂数意味着一个数字用自身相乘的次数。10 的一次幂是10,10的2次幂是10x10,10的3次幂是10x10x10,依此类推。二进制0001是十进制1,二进制数0010是十进制2,二进制0011是十进制3,二进制0100是十进制4,等等。所以,十进制42是二进制101010或者(2+8+32或21+23+25)。在计算机程序除了使用二进制表示数字之外,另一种基数,16进制,也经常用到。在这种进制中,每一位数字表示16的幂数。因为十进制数字只是从0到9,在十六进制中10到15分别用字母A,B,C,D,E,F表示。例如,十六进制的E是十进制的14,而十六进制的2A是十进制的42(2个16+10)。用C语言的表示法,十六进制数字使用前缀“0x”:十六进制的2A写做0x2A。
微处理器可以执行算术运算如加、乘和除,也可以执行逻辑操作例如“X是否大于Y”。
处理器的执行由外部时钟控制。这个时钟,即系统时钟,对处理器产生稳定的时钟脉冲,在每一个时钟脉冲里,处理器执行一些工作。例如,处理器可以在每一个时钟脉冲里执行一条指令。处理器的速度用系统时钟的频率来描述。一个100Mhz的处理器每秒钟接受到100,000,000次时钟脉冲。用时钟频率来描述CPU的能力是一种误解,因为不同的处理器在每一次时钟脉冲中执行的工作量不同。虽然如此,如果所有的条件同等,越快的时钟频率表示处理器的能力越强。处理器执行的指令非常简单,例如:“把内存位置X的内容读到寄存器Y中“。寄存器是微处理器的内部存储空间,用来存储数据并进行操作。执行的操作可能使处理器停止当前操作而转去执行内存中其他地方的指令。正是这些微小的指令集合在一起,赋予现代的微处理器几乎无限的能力,因为它每秒可以执行数百万甚至数十亿的指令。
执行指令时必须从内存中提取指令,指令自身也可能引用内存中的数据,这些数据也必须提取到内存中并在需要的时候保存到内存中去。
一个微处理器内部寄存器的大小、数量和类型完全决定于它的类型。一个Intel 80486处理器和一个Alpha AXP处理器的寄存器组完全不同。另外,Intel是32位宽而Alpha AXP是64位宽。但是,一般来讲,所有特定的处理器都会有一些通用目的的寄存器和少量专用的寄存器。大多数处理器拥有以下特殊用途的专用的寄存器:
Program Counter(PC)程序计数器
这个寄存器记录了下一条要执行的指令的地址。PC的内容在每次取指令的时候自动增加。
Stack Pointer(SP)堆栈指针
处理器必须能够存取用于临时存储数据的大容量的外部读写随机存取内存(RAM)。堆栈是一种用于在外部内存中存放和恢复临时数据的方法。通常,处理器提供了特殊的指令用于将数据压在堆栈中,并在以后需要是取出来。堆栈使用LIFO(后进先出)的方式。换句话说,如果你压入两个值x和y到堆栈中,然后从堆栈中弹出一个值,那么你会得到y的值。
一些处理器的堆栈向内存顶部增长,而另一些向内存的底部增长。还有一些处理器两种方式都可以支持,例如:ARM。
Processor Status(PS)
指令可能产生结果。例如:“X寄存器的内容是否大于Y寄存器的内容?“可能产生真或假的结果。PS寄存器保留这些结果以及处理器当前状态的其他信息。多数处理器至少有两种模式:kernel(核心态)和user(用户态),PS寄存器会纪录能够确定当前模式的那些信息。
2) Memory(内存)
所有系统都具有分级的内存结构,由位于不同级别的速度和容量不同的内存组成。
最快的内存是高速缓存存储器,就象它的名字暗示的一样-用于临时存放或缓存主内存的内容。这种内存非常快但是比较昂贵,因此多数处理器芯片上内置有少量的高速缓冲存储器,而大多数高速缓存存储器放在系统主板上。一些处理器用一块缓存内存同时缓存指令和数据,而另一些处理器有两块缓存内存-一个用于指令,另一个用于数据。Alpha AXP处理器有两个内置的内存高速缓存存储器:一个用于数据(D-Cache),另一个用于指令(I-Cache)。它的外部高速缓冲存储器(或B-Cache)将两者混在一起。
最后一种内存是主内存。相对于外部高速缓存存储器而言速度非常慢,对于CPU内置的高速缓存存储器,主内存简直是在爬。
高速缓存存储器和主内存必须保持同步(一致)。换句话说,如果主内存中的一个字保存在高速缓存存储器的一个或多个位置,那么系统必须保证高速缓存存储器和主内存的内容一样。使高速缓冲存储器同步的工作一部分是由硬件完成,另一部分则是由操作系统完成的。对于其它一些系统的主要任务,硬件和软件也必须紧密配合。
3) Buses(总线)
系统板的各个组成部分由被称为总线的连接系统互连在一起。系统总线分为三种逻辑功能:地址总线、数据总线和控制总线。地址总线指定了数据传输的内存位置(地址),数据总线保存了传输的数据。数据总线是双向的,它允许CPU读取,也允许CPU写。控制总线包含了各种信号线用于在系统中发送时钟和控制信号。有许多种不同的总线类型,ISA和PCI总线是系统用于连接外设的常用方式。
4) Controllers and Peripherals (控制器和外设)
外设指实在的设备,如由系统板或系统板插卡上的控制芯片所控制的图形卡或磁盘。IDE控制芯片控制IDE磁盘,而SCSI控制芯片控制SCSI磁盘。这些控制器通过不同的总线连接到CPU并相互连接。现在制造的大多数系统都是用PCI或ISA总线将系统的主要部件连接在一起。控制器本身也是象CPU一样的处理器,它们可以看作CPU的智能助手,CPU拥有系统的最高控制权。
所有的控制器都是不同的,但是通常它们都有用于控制它们的寄存器。CPU上运行的软件必须能够读写这些控制寄存器。一个寄存器可能包含描述错误的状态码,另一个寄存器可能用于控制用途,改变控制器的模式。一个总线上的每一个控制器都可以分别被CPU寻址,这样软件设备驱动程序就可以读写它的寄存器进而控制它。IDE电缆是一个好例子,它给了你分别存取总线上每一个驱动器的能力。另一个好例子是PCI总线,允许每一个设备(如图形卡)被独立存取。
5) Address Spaces(寻址空间)
连接CPU和主内存的系统总线以及连接CPU和系统硬件外设的总线是分离的。硬件外设所拥有的内存空间称为I/O空间。I/O空间本身可以再进一步划分,但是我们现在先不讨论。CPU可以访问系统内存空间和I/O空间,而控制器只能通过CPU间接访问系统内存。从设备的角度来看,比如软驱控制器,它只能看到它的控制寄存器所在的地址空间(ISA),而非系统内存。一个CPU用不同的指令去访问内存和I/O空间。例如,可能有一条指令是“从I/O地址0x3f0读取一个字节到X寄存器“。这也是CPU通过读写系统硬件外设处于I/O地址空间的寄存器从而控制外设的方法。在地址空间中,普通外设(如IDE控制器,串行端口,软驱控制器等等)的寄存器在PC外设的多年发展中已经成了定例。I/O空间的地址0x3f0正是串行口(COM1)的控制寄存器的地址。
有时控制器需要直接从系统内存读取大量内存,或直接写大量数据到系统内存中去。比如将用户数据写到硬盘上去。在这种情况下,使用直接内存存取(DMA)控制器,允许硬件设备直接存取系统内存,当然,这种存取必须在CPU的严格控制和监管下进行。
6) Timer(时钟)
所有操作系统需要知道时间,现代PC包括一个特殊的外设,叫做实时时钟(RTC)。它提供了两样东西:可靠的日期和精确的时间间隔。RTC有自己的电池,所以即使PC没有加电,它仍在运行。这也是为什么PC总是“知道”正确的日期和时间。时间间隔计时允许操作系统精确地调度基本工作。
Alpha AXP体系结构是一个为了速度而设计的64位的加载/存储(load/store)RISC体系结构。所有的寄存器都是64位长的:32个整数寄存器和32个浮点寄存器。第31个整数寄存器和第31个浮点寄存器用于null操作:读取它们得到0,写向它们没有任何结果。所有的指令和内存操作(不管是读或写)都是32位。只要具体的实现遵循这种体系结构,允许不同的实现方式。
没有直接在内存中操作数值的指令:所有的数据操作都是在寄存器之间进行。所以,如果你希望增加内存中一个计数器,你必须首先把它读到一个积存其中,修改之后再写回去。只有通过一个指令写向一个寄存器或内存位置,而另一个读取这个寄存器或内存位置,指令之间才能过相互作用。Alpha AXP的一个有趣的特点是它有可以产生标志位的指令,比如测试两个整数是否相等,这个结构不是存放到处理器的一个状态寄存器,而是存放到第三个寄存器。初看上去比较奇怪,但是不依赖于状态寄存器意味着可以更容易地让这个CPU每一个循环执行多个指令。执行过程中使用无关的寄存器的指令不需要互相等待,如果只有一个状态寄存器则必须等待。没有对于内存的直接操作以及数目众多的寄存器对于同时多条指令也有帮助。
Alpha AXP体系结构使用一系列子例程,叫做体系结构的授权库代码(privileged architecture library code PALcode)。PALcode和操作系统、Alpha AXP体系的CPU具体实现和系统硬件相关。这些子例程向操作系统提供上下文切换、中断、异常和内存管理的基本支持。这些子例程可以被硬件调用或通过CALL_PAL指令调用。PALcode用标准的Alpha AXP汇编程序编写,带有一些特殊扩展的实现,用于提供直接访问低级硬件的功能,例如内部处理器的寄存器。PALcode在PAL模式运行,这是一个特权的模式,会停止一些系统事件的发上,并允许PALcode完全控制系统的物理硬件。
2、Software Basic(软件基础)
程序是用于执行特定任务的计算机指令组合。程序可以用汇编语言,一种非常低级的计算机语言来编写,也可以使用和机器无关的高级语言,比如C语言编写。操作系统是一个特殊的程序,允许用户通过它运行应用程序,比如电子表和文字处理等等。
2.1 Computer Languages(计算机语言)
2.1.1.汇编语言
CPU从内存中读取和执行的指令对于人类来讲无法理解。它们是机器代码,精确的告诉计算机要做什么。比如十六进制数0x89E5,是Intel 80486的指令,将寄存器ESP的内容拷贝到寄存器EBP中。早期计算机中最初的软件工具之一是汇编程序,它读入人类可以阅读的源文件,将其装配成机器代码。汇编语言明确地处理对寄存器和对数据的操作,而这种操作对于特定的微处理器而言是特殊的。Intel X86微处理器的汇编语言和Alpha AXP微处理器的汇编语言完全不同。以下Alpha AXP汇编代码演示了程序可以执行的操作类型:
Ldr r16, (r15) ; 第一行
Ldr r17, 4(r15) ; 第二行
Beq r16,r17,100; 第三行
Str r17, (r15); 第四行
100: ; 第五行第一条语句(第一行)将寄存器15指定的地址中的内容加载到寄存器16中。第二条指令将紧接着的内存中的内容加载到寄存器17中。第三行比较寄存器16和寄存器17,如果相等,分支到标号100,否则,继续执行第四行,将寄存器17的内容存到内存中。如果内存中的数据相同,就不必存储数据。编写汇编级的程序需要技巧而且十分冗长,容易出错。Linux系统的核心很少的一部分是用汇编语言编写,而这些部分之所以使用汇编语言只是为了提高效率,并且和具体的微处理器相关。
2.1.2 The C Programming Language and Compiler (C语言和编译器)
使用汇编语言编写大型程序十分困难,消耗时间,容易出错而且生成的程序不能移植,只能束缚在特定的处理器家族。更好的选择是使用和机器无关的语言,例如C。C允许你用逻辑算法描述程序和要处理的数据。被称为编译程序(compiler)的特殊程序读入C程序,并将它转换为汇编语言,进而产生机器相关的代码。好的编译器生成的汇编指令可以和好的汇编程序员编写的程序效率接近。大部分Linux核心是用C语言编写的。以下的C片断:
if (x != y)
x = y;执行了和前面示例中汇编代码完全一样的操作。如果变量x的内容和变量y的内容不一样,变量y的内容被拷贝到变量x。C代码用例程(routine)进行组合,每一个例程执行一项任务。例程可以返回C所支持的任意的数值或数据类型。大型程序比如Linux核心分别由许多的C语言模块组成,每一个模块有自己的例程和数据结构。这些C源代码模块共同构成了逻辑功能比如文件系统的处理代码。
C支持多种类型的变量。一个变量是内存中的特定位置,可用符号名引用。上述的C片断中,x和y引用了内存中的位置。程序员不需要关心变量在内存中的具体位置,这是连接程序(下述)必须处理的。一些变量包含不同的数据例如整数、浮点数等和另一些则包含指针。
指针是包含其它数据在内存中的地址的变量。假设一个变量x,位于内存地址0x80010000, 你可能有一个指针px,指向x。 Px可能位于地址0x80010030。Px的值则是变量x的地址,0x80010000。
C允许你将相关的变量集合成为结构。例如:
Struct {
Int I;
Char b;
} my_struct;是一个叫做my_struct的数据结构,包括两个元素:一个整数(32位)I和一个字符(8位数据)b。
2.1.3 Linkers(连接程序)
连接程序将几个目标模块和库文件连接在一起成为一个单独的完整程序。目标模块是汇编程序或编译程序的机器码输出,它包括机器码、数据和供连接程序使用的连接信息。比如:一个目标模块可能包括程序的所有数据库功能,而另一个目标模块则包括处理命令行参数的函数。连接程序确定目标模块之间的引用关系,即确定一个模块所引用的例程和数据在另一个模块中的实际位置。Linux核心是由多个目标模块连接而成的独立的大程序。
2.2 What is an Operating System(什么是操作系统?)
没有软件,计算机只是一堆发热的电子元件。如果说硬件是计算机的心脏,则软件就是它的灵魂。操作系统是允许用户运行应用程序的一组系统程序。操作系统将系统的硬件抽象,呈现在用户和应用程序之前的是一个虚拟的机器。是软件造就了计算机系统的特点。大多数PC可以运行一到多个操作系统,而每一个操作系统从外观和感觉上都大不相同。Linux由不同功能的部分构成,这些部分总体组合构成了Linux操作系统。Linux最明显的部分就是Kernel自身,但是如果没有shell或libraries一样没有用处。
为了了解什么是操作系统,看一看在你输入最简单的命令时发生了什么:
$ls
Mail c images perl
Docs tcl
$这里的$是登录的shell输出的提示符(此例是bash):表示shell在等候你(用户)输入命令。输入ls引发键盘驱动程序识别输入的字符,键盘驱动程序将识别的字符传递给shell去处理。shell先查找同名的可执行映象,它找到了/bin/ls, 然后调用核心服务将ls执行程序加载到虚拟内存中并开始执行。ls执行程序通过执行核心的文件子系统的系统调用查找文件。文件系统可能使用缓存的文件系统信息或通过磁盘设备驱动程序从磁盘上读取文件信息,也可能是通过网络设备驱动程序同远程主机交换信息而读取本系统所访问的远程文件的详细信息(文件系统可以通过NFS网络文件系统远程安装)。不管文件信息是如何得到的,ls都将信息输出,通过显示驱动程序显示在屏幕上。
以上的过程看起来相当复杂,但是它说明了即使是最简单的命令也是操作系统各个功能模块之间共同协作的结果,只有这样才能提供给你(用户)一个完整的系统视图。
2.2.1 Memory management(内存管理)
如果拥有无限的资源,例如内存,那么操作系统所必须做的很多事情可能都是多余的。所有操作系统的一个基本技巧就是让少量的物理内存工作起来好像有相当多的内存。这种表面看起来的大内存叫做虚拟内存,就是当软件运行的时候让它相信它拥有很多内存。系统将内存分为容易处理的页,在系统运行时将这些页交换到硬盘上。而应用软件并不知道,因为操作系统还使用了另一项技术:多进程。
2.2.2 Processes (进程)
进程可以看作一个在执行的程序,每一个进程都是正在运行的特定的程序的独立实体。如果你观察一下你的Linux系统,你会发现有很多进程在运行。例如:在我的系统上输入ps 显示了以下进程:
$ ps
PID TTY STAT TIME COMMAND
158 pRe 1 0:00 -bash
174 pRe 1 0:00 sh /usr/X11R6/bin/startx
175 pRe 1 0:00 xinit /usr/X11R6/lib/X11/xinit/xinitrc --
178 pRe 1 N 0:00 bowman
182 pRe 1 N 0:01 rxvt -geometry 120x35 -fg white -bg black
184 pRe 1 < 0:00 xclock -bg grey -geometry -1500-1500 -padding 0
185 pRe 1 < 0:00 xload -bg grey -geometry -0-0 -label xload
187 pp6 1 9:26 /bin/bash
202 pRe 1 N 0:00 rxvt -geometry 120x35 -fg white -bg black
203 ppc 2 0:00 /bin/bash
1796 pRe 1 N 0:00 rxvt -geometry 120x35 -fg white -bg black
1797 v06 1 0:00 /bin/bash
3056 pp6 3 < 0:02 emacs intro/introduction.tex
3270 pp6 3 0:00 ps
$如果我的系统拥有多个CPU那么每个进程可能(至少在理论上如此)都在不同的CPU上运行。不幸的是,只有一个,所以操作系统又使用技巧,在短时间内依次运行每一个进程。这个时间段叫做时间片。这种技巧叫做多进程或调度,它欺骗了每一个进程,好像它们是唯一的进程。进程相互之间受到保护,所以如果一个进程崩溃或不能工作,不会影响其他进程。操作系统通过给每一个进程一个独立的地址空间来实现保护,进程只能访问它自己的地址空间。
2.2.3 Device Drivers(设备驱动程序)
设备驱动程序组成了Linux核心的主要部分。象操作系统的其他部分一样,它们在一个高优先级的环境下工作,如果发生错误,可能会引发严重问题。设备驱动程序控制了操作系统和它控制的硬件设备之间的交互。比如:文件系统向IDE磁盘写数据块是使用通用块设备接口。驱动程序控制细节,并处理和设备相关的部分。设备驱动程序和它驱动的具体的控制器芯片相关,所以,如果你的系统有一个NCR810的SCSI控制器,那么你需要NCR810的驱动程序。
2.2.4 The Filesystems(文件系统)
象Unix一样,在Linux里,系统对独立的文件系统不是用设备标示符来存取(比如驱动器编号或驱动器名称),而是连接成为一个树型结构。Linux在安装新的文件系统时,把它安装到指定的安装目录,比如/mnt/cdrom,从而合并到这个单一的文件系统树上。Linux的一个重要特征是它支持多种不同的文件系统。这使它非常灵活而且可以和其他操作系统良好共存。Linux最常用的文件系统是EXT2,大多数Linux发布版都支持。
文件系统将存放在系统硬盘上的文件和目录用可以理解的统一的形式提供给用户,让用户不必考虑文件系统的类型或底层物理设备的特性。Linux透明的支持多种文件系统(如MS-DOS和EXT2),将所有安装的文件和文件系统集合成为一个虚拟的文件系统。所以,用户和进程通常不需要确切知道所使用的文件所在的文件系统的类型,用就是了。
块设备驱动程序掩盖了物理块设备类型的区别(如IDE和SCSI)。对于文件系统来讲,物理设备就是线性的数据块的集合。不同设备的块大小可能不同,如软驱一般是512字节,而IDE设备通常是1024字节,同样,对于系统的用户,这些区别又被掩盖。EXT2文件系统不管它用什么设备,看起来都是一样的。
2.3 Kernet Data Structures(核心数据结构)
操作系统必须纪录关于系统当前状态的许多信息。如果系统中发生了事情,这些数据结构就必须相应改变以反映当前的实际情况。例如:用户登录到系统中的时候,需要创建一个新的进程。核心必须相应地创建表示此新进程的数据结构,并和表示系统中其他进程的数据结构联系在一起。
这样的数据结构多数在物理内存中,而且只能由核心和它的子系统访问。数据结构包括数据和指针(其他数据结构或例程的地址)。乍一看,Linux核心所用的数据结构可能非常混乱。其实,每一个数据结构都有其目的,虽然有些数据结构在多个的子系统中都会用到,但是实际上它们比第一次看到时的感觉要简单的多。
理解Linux核心的关键在于理解它的数据结构和核心处理这些数据结构所用到的大量的函数,以数据结构为基础描述Linux核心。论及每一个核心子系统的算法,处理的方式和它们对核心数据结构的使用。
2.3.1 Linked Lists(连接表)
Linux使用一种软件工程技术将它的数据结构连接在一起。多数情况下它使用链表数据结构。如果每一个数据结构描述一个物体或者发生的事件的单一的实例,比如一个进程或一个网络设备,核心必须能够找出所有的实例。在链表中,根指针包括第一个数据结构或单元的地址,列表中的每一个数据结构包含指向列表下一个元素的指针。最后元素的下一个指针可能使0或NULL,表示这是列表的结尾。在双向链表结构中,每一个元素不仅包括列表中下一个元素的指针,还包括列表中前一个元素的指针。使用双向链表可以比较容易的在列表中间增加或删除元素,但是这需要更多的内存存取。这是典型的操作系统的两难情况:内存存取数还是CPU的周期数。
2.3.2 Hash Tables
链接表是常用的数据结构,但是游历链接表的效率可能并不高。如果你要寻找指定的元素, 可能必须查找完整个表才能找到。Linux使用另一种技术:Hashing 来解决这种局限。Hash table是指针的数组或者说向量表。数组或向量表是在内存中依次存放的对象。书架可以说是书的数组。数组用索引来访问,索引是数组中的偏移量。再来看书架的例子,你可以使用在书架上的位置来描述每一本书:比如第5本书。
Hash table是一个指向数据结构的指针的数组,它的索引来源于数据结构中的信息。如果你用一个数据结构来描述一个村庄的人口,你可以用年龄作为索引。要找出一个指定的人的数据,你可以用他的年龄作为索引在人口散列表中查找,通过指针找到包括详细信息的数据结构。不幸的是,一个村庄中可能很多人年龄相同,所以散列表的指针指向另一个链表数据结构,每一个元素描述同龄人。即使这样,查找这些较小的链表仍然比查找所有的数据结构要快。
Hash table可用于加速常用的数据结构的访问,在Linux里常用hash table来实现缓冲。缓冲是需要快速存取的信息,是全部可用信息的一个子集。数据结构被放在缓冲区并保留在那里,因为核心经常访问这些结构。使用缓冲区也有副作用,因为使用起来比简单链表或者散列表更加复杂。如果数据结构可以在缓冲区找到(这叫做缓冲命中),那么一切很完美。但是如果数据结构不在缓冲区中,那么必须查找所用的相关的数据结构,如果找到,那么就加到缓冲区中。增加新的数据结构到缓冲区中可能需要废弃一个旧的缓冲入口。Linux必须决定废弃那一个数据结构,风险在于废弃的可能使Linux下一个要访问的数据结构。
2.3.3 Abstract Interfaces(抽象接口)
Linux核心经常将它的接口抽象化。接口是以特定方式工作的一系列例程和数据结构。比如:所有的网络设备驱动程序都必须提供特定的例程来处理特定的数据结构。用抽象接口的方式可以用通用的代码层来使用底层特殊代码提供的服务(接口)。例如网络层是通用的,而它由底层符合标准接口的同设备相关的代码提供支持。
通常这些底层在启动时向高一层登记。这个登记过程常通过在链接表中增加一个数据结构来实现。例如,每一个连结到核心的文件系统在核心启动时进行登记(或者如果你使用模块,在文件系统第一次使用时向核心登记)。你可以查看文件/proc/filesystems来检查那些文件系统进行了登记。登记所用的数据结构通常包括指向函数的指针。这是执行特定任务的软件函数的地址。再一次用文件系统登记的例子,每一个文件系统登记时传递给Linux核心的数据结构都包括一个和具体文件系统相关的例程地址,在安装文件系统时必须调用。
五、Linux内核管理
1、虚拟文件夹
1. 虚拟文件夹简介
虚拟的文件夹,因为其数据内容是存放在内存中的,不是存放在硬盘中,/proc和/sys都是虚拟的文件夹。其中有些文件虽然使用查看命令查看时会返回大量信息,但文件本身的大小却会显示为0字节。此外,这些特殊文件中大多数文件的时间及日期属性通常为当前系统时间和日期,都跟它们随时会被刷新(存储于RAM中)有关。
/proc文件系统的外部性能视图,并且为用户提供了关于内核内部数据结构的视图。可以利用它查看和修改内核的某些内部数据结构,从而改变内核的行为。
/proc文件系统提供了一种通过微调系统资源来改善应用程序以及系统整体性能的简单方法,/proc文件系统是一种由内核以动态创建方式生成数据的虚拟文件系统。它被组织成多种目录形式,其中每个目录都对应于特定子系统的可调选项。
/proc目录中包含许多以数字命名的子目录,这些数字表示系统当前正在运行进程的进程号,里面包含对应进程相关的多个信息文件。
[root@rhel5 ~]# ll /proc
total 0
dr-xr-xr-x 5 root root 0 Feb 8 17:08 1
dr-xr-xr-x 5 root root 0 Feb 8 17:08 10
dr-xr-xr-x 5 root root 0 Feb 8 17:08 11
dr-xr-xr-x 5 root root 0 Feb 8 17:08 1156
dr-xr-xr-x 5 root root 0 Feb 8 17:08 139
dr-xr-xr-x 5 root root 0 Feb 8 17:08 140
dr-xr-xr-x 5 root root 0 Feb 8 17:08 141
dr-xr-xr-x 5 root root 0 Feb 8 17:09 1417
dr-xr-xr-x 5 root root 0 Feb 8 17:09 1418
上面列出的是/proc目录中一些进程相关的目录,每个目录中是当程本身相关信息的文件。下面是作者系统(RHEL5.3)上运行的一个PID为2674的进程saslauthd的相关文件,其中有些文件是每个进程都会具有的。
[root@rhel5 ~]# ll /proc/2674
total 0
dr-xr-xr-x 2 root root 0 Feb 8 17:15 attr
-r-------- 1 root root 0 Feb 8 17:14 auxv
-r--r--r-- 1 root root 0 Feb 8 17:09 cmdline
-rw-r--r-- 1 root root 0 Feb 8 17:14 coredump_filter
-r--r--r-- 1 root root 0 Feb 8 17:14 cpuset
lrwxrwxrwx 1 root root 0 Feb 8 17:14 cwd -> /var/run/saslauthd
-r-------- 1 root root 0 Feb 8 17:14 environ
lrwxrwxrwx 1 root root 0 Feb 8 17:09 exe -> /usr/sbin/saslauthd
dr-x------ 2 root root 0 Feb 8 17:15 fd
-r-------- 1 root root 0 Feb 8 17:14 limits
-rw-r--r-- 1 root root 0 Feb 8 17:14 loginuid
-r--r--r-- 1 root root 0 Feb 8 17:14 maps
-rw------- 1 root root 0 Feb 8 17:14 mem
-r--r--r-- 1 root root 0 Feb 8 17:14 mounts
-r-------- 1 root root 0 Feb 8 17:14 mountstats
-rw-r--r-- 1 root root 0 Feb 8 17:14 oom_adj
-r--r--r-- 1 root root 0 Feb 8 17:14 oom_score
lrwxrwxrwx 1 root root 0 Feb 8 17:14 root -> /
-r--r--r-- 1 root root 0 Feb 8 17:14 schedstat
-r-------- 1 root root 0 Feb 8 17:14 smaps
-r--r--r-- 1 root root 0 Feb 8 17:09 stat
-r--r--r-- 1 root root 0 Feb 8 17:14 statm
-r--r--r-- 1 root root 0 Feb 8 17:10 status
dr-xr-xr-x 3 root root 0 Feb 8 17:15 task
-r--r--r-- 1 root root 0 Feb 8 17:14 wchancmdline — 启动当前进程的完整命令,但僵尸进程目录中的此文件不包含任何信息;
[root@rhel5 ~]# more /proc/2674/cmdline
/usr/sbin/saslauthdenviron — 当前进程的环境变量列表,彼此间用空字符(NULL)隔开;变量用大写字母表示,其值用小写字母表示;
[root@rhel5 ~]# more /proc/2674/environ
TERM=linuxauthdcwd — 指向当前进程运行目录的一个符号链接;
exe — 指向启动当前进程的可执行文件(完整路径)的符号链接,通过/proc/N/exe可以启动当前进程的一个拷贝;
fd — 这是个目录,包含当前进程打开的每一个文件的文件描述符(file descriptor),这些文件描述符是指向实际文件的一个符号链接;
[root@rhel5 ~]# ll /proc/2674/fd
total 0
lrwx------ 1 root root 64 Feb 8 17:17 0 -> /dev/null
lrwx------ 1 root root 64 Feb 8 17:17 1 -> /dev/null
lrwx------ 1 root root 64 Feb 8 17:17 2 -> /dev/null
lrwx------ 1 root root 64 Feb 8 17:17 3 -> socket:[7990]
lrwx------ 1 root root 64 Feb 8 17:17 4 -> /var/run/saslauthd/saslauthd.pid
lrwx------ 1 root root 64 Feb 8 17:17 5 -> socket:[7991]
lrwx------ 1 root root 64 Feb 8 17:17 6 -> /var/run/saslauthd/mux.accept
limits — 当前进程所使用的每一个受限资源的软限制、硬限制和管理单元;此文件仅可由实际启动当前进程的UID用户读取;(2.6.24以后的内核版本支持此功能);
maps — 当前进程关联到的每个可执行文件和库文件在内存中的映射区域及其访问权限所组成的列表;
[root@rhel5 ~]# cat /proc/2674/maps
00110000-00239000 r-xp 00000000 08:02 130647 /lib/libcrypto.so.0.9.8e
00239000-0024c000 rwxp 00129000 08:02 130647 /lib/libcrypto.so.0.9.8e
0024c000-00250000 rwxp 0024c000 00:00 0
00250000-00252000 r-xp 00000000 08:02 130462 /lib/libdl-2.5.so
00252000-00253000 r-xp 00001000 08:02 130462 /lib/libdl-2.5.somem — 当前进程所占用的内存空间,由open、read和lseek等系统调用使用,不能被用户读取;
root — 指向当前进程运行根目录的符号链接;在Unix和Linux系统上,通常采用chroot命令使每个进程运行于独立的根目录;
stat — 当前进程的状态信息,包含一系统格式化后的数据列,可读性差,通常由ps命令使用;
statm — 当前进程占用内存的状态信息,通常以“页面”(page)表示;
status — 与stat所提供信息类似,但可读性较好,如下所示,每行表示一个属性信息;其详细介绍请参见 proc的man手册页;
[root@rhel5 ~]# more /proc/2674/status
Name: saslauthd
State: S (sleeping)
SleepAVG: 0%
Tgid: 2674
Pid: 2674
PPid: 1
TracerPid: 0
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 32
Groups:
VmPeak: 5576 kB
VmSize: 5572 kB
VmLck: 0 kB
VmHWM: 696 kB
VmRSS: 696 kB
…………task — 目录文件,包含由当前进程所运行的每一个线程的相关信息,每个线程的相关信息文件均保存在一个由线程号(tid)命名的目录中,这类似于其内容类似于每个进程目录中的内容;(内核2.6版本以后支持此功能)。
2. /proc目录下常见的文件介绍
/proc
proc是进程(process)的缩写。这个目录文件里面存放的是进程的相关信息,把系统中的进程信息、内核状态放在proc中,是一个虚拟的文件夹,对应的数据信息是内存中的状态;
/proc/apm
高级电源管理(APM)版本信息及电池相关状态信息,通常由apm命令使用;
/proc/buddyinfo
用于诊断内存碎片问题的相关信息文件;
/proc/cmdline
在启动时传递至内核的相关参数信息,这些信息通常由lilo或grub等启动管理工具进行传递;
[root@rhel5 ~]# more /proc/cmdline
ro root=/dev/VolGroup00/LogVol00 rhgb quiet/proc/cpuinfo
处理器的相关信息的文件;
/proc/crypto
系统上已安装的内核使用的密码算法及每个算法的详细信息列表;
[root@rhel5 ~]# more /proc/crypto
name : crc32c
driver : crc32c-generic
module : kernel
priority : 0
type : digest
blocksize : 32
digestsize : 4
…………/proc/devices
系统已经加载的所有块设备和字符设备的信息,包含主设备号和设备组(与主设备号对应的设备类型)名;
[root@rhel5 ~]# more /proc/devices
Character devices:
1 mem
4 /dev/vc/0
4 tty
4 ttyS
…………
Block devices:
1 ramdisk
2 fd
8 sd
…………/proc/diskstats
每块磁盘设备的磁盘I/O统计信息列表;(内核2.5.69以后的版本支持此功能) ;
/proc/dma
每个正在使用且注册的ISA DMA通道的信息列表;
[root@rhel5 ~]# more /proc/dma
2: floppy
4: cascade/proc/execdomains
内核当前支持的执行域(每种操作系统独特“个性”)信息列表;
[root@rhel5 ~]# more /proc/execdomains
0-0 Linux [kernel]/proc/fb
帧缓冲设备列表文件,包含帧缓冲设备的设备号和相关驱动信息;
/proc/filesystems
当前被内核支持的文件系统类型列表文件,被标示为nodev的文件系统表示不需要块设备的支持;通常mount一个设备时,如果没有指定文件系统类型将通过此文件来决定其所需文件系统的类型;
[root@rhel5 ~]# more /proc/filesystems
nodev sysfs
nodev rootfs
nodev proc
iso9660
ext3
…………
…………/proc/interrupts
X86或X86_64体系架构系统上每个IRQ相关的中断号列表;多路处理器平台上每个CPU对于每个I/O设备均有自己的中断号;
[root@rhel5 ~]# more /proc/interrupts
CPU0
0: 1305421 IO-APIC-edge timer
1: 61 IO-APIC-edge i8042
185: 1068 IO-APIC-level eth0
…………/proc/iomem
每个物理设备上的记忆体(RAM或者ROM)在系统内存中的映射信息;
[root@rhel5 ~]# more /proc/iomem
00000000-0009f7ff : System RAM
0009f800-0009ffff : reserved
000a0000-000bffff : Video RAM area
000c0000-000c7fff : Video ROM
…………/proc/ioports
当前正在使用且已经注册过的与物理设备进行通讯的输入-输出端口范围信息列表;如下面所示,第一列表示注册的I/O端口范围,其后表示相关的设备;
[root@rhel5 ~]# less /proc/ioports
0000-001f : dma1
0020-0021 : pic1
0040-0043 : timer0
0050-0053 : timer1
0060-006f : keyboard
…………/proc/kallsyms
模块管理工具用来动态链接或绑定可装载模块的符号定义,由内核输出;(内核2.5.71以后的版本支持此功能);通常这个文件中的信息量相当大;
[root@rhel5 ~]# more /proc/kallsyms
c04011f0 T _stext
c04011f0 t run_init_process
c04011f0 T stext
…………/proc/kcore
系统使用的物理内存,以ELF核心文件(core file)格式存储,其文件大小为已使用的物理内存(RAM)加上4KB;这个文件用来检查内核数据结构的当前状态,因此,通常由GBD通常调试工具使用,但不能使用文件查看命令打开此文件;
/proc/kmsg
此文件用来保存由内核输出的信息,通常由/sbin/klogd或/bin/dmsg等程序使用,不要试图使用查看命令打开此文件;
/proc/loadavg
保存关于CPU和磁盘I/O的负载平均值,其前三列分别表示每1秒钟、每5秒钟及每15秒的负载平均值,类似于uptime命令输出的相关信息;第四列是由斜线隔开的两个数值,前者表示当前正由内核调度的实体(进程和线程)的数目,后者表示系统当前存活的内核调度实体的数目;第五列表示此文件被查看前最近一个由内核创建的进程的PID;
[root@rhel5 ~]# more /proc/loadavg
0.45 0.12 0.04 4/125 5549
[root@rhel5 ~]# uptime
06:00:54 up 1:06, 3 users, load average: 0.45, 0.12, 0.04
/proc/locks
保存当前由内核锁定的文件的相关信息,包含内核内部的调试数据;每个锁定占据一行,且具有一个惟一的编号;如下输出信息中每行的第二列表示当前锁定使用的锁定类别,POSIX表示目前较新类型的文件锁,由lockf系统调用产生,FLOCK是传统的UNIX文件锁,由flock系统调用产生;第三列也通常由两种类型,ADVISORY表示不允许其他用户锁定此文件,但允许读取,MANDATORY表示此文件锁定期间不允许其他用户任何形式的访问;
[root@rhel5 ~]# more /proc/locks
1: POSIX ADVISORY WRITE 4904 fd:00:4325393 0 EOF
2: POSIX ADVISORY WRITE 4550 fd:00:2066539 0 EOF
3: FLOCK ADVISORY WRITE 4497 fd:00:2066533 0 EOF
/proc/mdstat
保存RAID相关的多块磁盘的当前状态信息,在没有使用RAID机器上,其显示为如下状态:
[root@rhel5 ~]# less /proc/mdstat
Personalities :
unused devices: /proc/meminfo
系统中关于当前内存的利用状况等的信息,常由free命令使用;可以使用文件查看命令直接读取此文件,其内容显示为两列,前者为统计属性,后者为对应的值;
[root@rhel5 ~]# less /proc/meminfo
MemTotal: 515492 kB
MemFree: 8452 kB
Buffers: 19724 kB
Cached: 376400 kB
SwapCached: 4 kB
…………查看空闲内存量:
grep MemFree /proc/meminfo /proc/mounts
在内核2.4.29版本以前,此文件的内容为系统当前挂载的所有文件系统,在2.4.19以后的内核中引进了每个进程使用独立挂载名称空间的方式,此文件则随之变成了指向/proc/self/mounts(每个进程自身挂载名称空间中的所有挂载点列表)文件的符号链接;/proc/self是一个独特的目录,后文中会对此目录进行介绍;
[root@rhel5 ~]# ll /proc |grep mounts
lrwxrwxrwx 1 root root 11 Feb 8 06:43 mounts -> self/mounts
如下所示,其中第一列表示挂载的设备,第二列表示在当前目录树中的挂载点,第三点表示当前文件系统的类型,第四列表示挂载属性(ro或者rw),第五列和第六列用来匹配/etc/mtab文件中的转储(dump)属性;
[root@rhel5 ~]# more /proc/mounts
rootfs / rootfs rw 0 0
/dev/root / ext3 rw,data=ordered 0 0
/dev /dev tmpfs rw 0 0
/proc /proc proc rw 0 0
/sys /sys sysfs rw 0 0
/proc/bus/usb /proc/bus/usb usbfs rw 0 0
…………/proc/modules
当前装入内核的所有模块名称列表,可以由lsmod命令使用,也可以直接查看;如下所示,其中第一列表示模块名,第二列表示此模块占用内存空间大小,第三列表示此模块有多少实例被装入,第四列表示此模块依赖于其它哪些模块,第五列表示此模块的装载状态(Live:已经装入;Loading:正在装入;Unloading:正在卸载),第六列表示此模块在内核内存(kernel memory)中的偏移量;
[root@rhel5 ~]# more /proc/modules
autofs4 24517 2 - Live 0xe09f7000
hidp 23105 2 - Live 0xe0a06000
rfcomm 42457 0 - Live 0xe0ab3000
l2cap 29505 10 hidp,rfcomm, Live 0xe0aaa000
…………
/proc/partitions
块设备每个分区的主设备号(major)和次设备号(minor)等信息,同时包括每个分区所包含的块(block)数目(如下面输出中第三列所示);
[root@rhel5 ~]# more /proc/partitions
major minor #blocks name
8 0 20971520 sda
8 1 104391 sda1
8 2 6907950 sda2
8 3 5630782 sda3
8 4 1 sda4
8 5 3582463 sda5/proc/pci
内核初始化时发现的所有PCI设备及其配置信息列表,其配置信息多为某PCI设备相关IRQ信息,可读性不高,可以用“/sbin/lspci –vb”命令获得较易理解的相关信息;在2.6内核以后,此文件已为/proc/bus/pci目录及其下的文件代替;
/proc/slabinfo
在内核中频繁使用的对象(如inode、dentry等)都有自己的cache,即slab pool,而/proc/slabinfo文件列出了这些对象相关slap的信息;详情可以参见内核文档中slapinfo的手册页;
[root@rhel5 ~]# more /proc/slabinfo
slabinfo - version: 2.1
# name : tunables : slabdata
rpc_buffers 8 8 2048 2 1 : tunables 24 12 8 : slabdata 4 4 0
rpc_tasks 8 20 192 20 1 : tunables 120 60 8 : slabdata 1 1 0
rpc_inode_cache 6 9 448 9 1 : tunables 54 27 8 : slabdata 1 1 0
…………
…………
………… /sys
/sys目录文件存放的是和硬件有关的一些信息,也是虚拟文件夹,不是真正的硬盘上的文件夹,对应的也是内存中的数据;
新添加硬盘的识别:
echo "- - -" > /sys/class/scsi_host/hostX/scan #X表示数字,从0开始的/proc/sys
与/proc下其它文件的“只读”属性不同的是,这个目录文件里面的信息可以修改,可以通过这些配置来控制内核的运行特性;
事先可以使用“ls -l”命令查看某文件是否“可写入”。写入操作通常使用类似于“echo DATA > /path/to/your/filename”的格式进行。需要注意的是,即使文件可写,其一般也不可以使用编辑器进行编辑。
查询系统最大支持线程数:
cat /proc/sys/kernel/threads-max/proc/sys/debug 子目录
此目录通常是一空目录;
/proc/sys/dev 子目录
为系统上特殊设备提供参数信息文件的目录,其不同设备的信息文件分别存储于不同的子目录中,如大多数系统上都会具有的/proc/sys/dev/cdrom和/proc/sys/dev/raid(如果内核编译时开启了支持raid的功能) 目录,其内存储的通常是系统上cdrom和raid的相关参数信息文件;
proc/stat
实时追踪自系统上次启动以来的多种统计信息;如下所示,其中,
“cpu”行后的八个值分别表示以1/100(jiffies)秒为单位的统计值(包括系统运行于用户模式、低优先级用户模式,运系统模式、空闲模式、I/O等待模式的时间等);
“intr”行给出中断的信息,第一个为自系统启动以来,发生的所有的中断的次数;然后每个数对应一个特定的中断自系统启动以来所发生的次数;
“ctxt”给出了自系统启动以来CPU发生的上下文交换的次数。
“btime”给出了从系统启动到现在为止的时间,单位为秒;
“processes (total_forks) 自系统启动以来所创建的任务的个数目;
“procs_running”:当前运行队列的任务的数目;
“procs_blocked”:当前被阻塞的任务的数目;
[root@rhel5 ~]# more /proc/stat
cpu 2751 26 5771 266413 2555 99 411 0
cpu0 2751 26 5771 266413 2555 99 411 0
intr 2810179 2780489 67 0 3 3 0 5 0 1 0 0 0 1707 0 0 9620 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5504 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12781 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ctxt 427300
btime 1234084100
processes 3491
procs_running 1
procs_blocked 0/proc/swaps
当前系统上的交换分区及其空间利用信息,如果有多个交换分区的话,则会每个交换分区的信息分别存储于/proc/swap目录中的单独文件中,而其优先级数字越低,被使用到的可能性越大;下面是作者系统中只有一个交换分区时的输出信息;
[root@rhel5 ~]# more /proc/swaps
Filename Type Size Used Priority
/dev/sda8 partition 642560 0 -1
/proc/uptime
系统上次启动以来的运行时间,如下所示,其第一个数字表示系统运行时间,第二个数字表示系统空闲时间,单位是秒;
[root@rhel5 ~]# more /proc/uptime
3809.86 3714.13/proc/version
当前系统运行的内核版本号,在作者的RHEL5.3上还会显示系统安装的gcc版本,如下所示;
[root@rhel5 ~]# more /proc/version
Linux version 2.6.18-128.el5 ([email protected]) (gcc version 4.1.2 20080704 (Red Hat 4.1.2-44)) #1 SMP Wed Dec 17 11:42:39 EST 2008/proc/vmstat
当前系统虚拟内存的多种统计数据,信息量可能会比较大,这因系统而有所不同,可读性较好;下面为作者机器上输出信息的一个片段;(2.6以后的内核支持此文件)
[root@rhel5 ~]# more /proc/vmstat
nr_anon_pages 22270
nr_mapped 8542
nr_file_pages 47706
nr_slab 4720
nr_page_table_pages 897
nr_dirty 21
nr_writeback 0
…………/proc/zoneinfo
内存区域(zone)的详细信息列表,信息量较大,下面列出的是一个输出片段:
[root@rhel5 ~]# more /proc/zoneinfo
Node 0, zone DMA
pages free 1208
min 28
low 35
high 42
active 439
inactive 1139
scanned 0 (a: 7 i: 30)
spanned 4096
present 4096
nr_anon_pages 192
nr_mapped 141
nr_file_pages 1385
nr_slab 253
nr_page_table_pages 2
nr_dirty 523
nr_writeback 0
nr_unstable 0
nr_bounce 0
protection: (0, 0, 296, 296)
pagesets
all_unreclaimable: 0
prev_priority: 12
start_pfn: 0
…………3. 创建/proc目录子节点
内核模块机制,和/proc文件系统,都是Linux系统中具有代表性的特征。可否利用这些便利,为特殊文件、设备、公共变量等,创建/proc目录下对应的节点?答案当然是肯定的。
内核模块与内核空间之外的交互方式有很多种,/proc文件系统是其中一种主要方式。
介绍/proc文件系统,在这里我们再把一些基本知识复习一下。文件系统是操作系统在磁盘或其它外设上,组织文件的方法。Linux支持很多文件系统的类型:minix,ext,ext2,msdos,umsdos,vfat,proc,nfs,iso9660,hpfs,sysv,smb,ncpfs等等。与其他文件系统不同的是,/proc文件系统是一个伪文件系统。之所以称之为伪文件系统,是因为它没有任何一部分与磁盘有关,只存在内存当中,而不占用外存空间。而它确实与文件系统有很多相似之处。例如,以文件系统的方式为访问系统内核数据的操作提供接口,而且可以用所有一般的文件工具操作。例如我们可以通过命令cat,more或其他文本编辑工具察看proc文件中的信息。更重要的是,用户和应用程序可以通过proc得到系统的信息,并可以改变内核的某些参数。由于系统的信息,如进程,是动态改变的,所以用户或应用程序读取proc文件时,proc是动态从系统内核读出所需信息并提交的。/proc文件系统一般放在/proc目录下。
怎么让/proc文件系统反映内核模块的状态呢?我们来看看下面这个稍微复杂一些的实例。
proc_example.c
…………
int init_module()
{
int rv = 0;
/* 创建目录 */
example_dir = proc_mkdir(MODULE_NAME, NULL);
if(example_dir == NULL) {
rv = -ENOMEM;
goto out;
}
example_dir->owner = THIS_MODULE;
/* 快速创建只读文件 jiffies */
jiffies_file = create_proc_read_entry("jiffies", 0444, example_dir,
proc_read_jiffies, NULL);
if(jiffies_file == NULL) {
rv = -ENOMEM;
goto no_jiffies;
}
jiffies_file->owner = THIS_MODULE;
/* 创建规则文件foo 和 bar */
foo_file = create_proc_entry("foo", 0644, example_dir);
if(foo_file == NULL) {
rv = -ENOMEM;
goto no_foo;
}
strcpy(foo_data.name, "foo");
strcpy(foo_data.value, "foo");
foo_file->data = &foo_data;
foo_file->read_proc = proc_read_foobar;
foo_file->write_proc = proc_write_foobar;
foo_file->owner = THIS_MODULE;
bar_file = create_proc_entry("bar", 0644, example_dir);
if(bar_file == NULL) {
rv = -ENOMEM;
goto no_bar;
}
strcpy(bar_data.name, "bar");
strcpy(bar_data.value, "bar");
bar_file->data = &bar_data;
bar_file->read_proc = proc_read_foobar;
bar_file->write_proc = proc_write_foobar;
bar_file->owner = THIS_MODULE;
/* 创建设备文件 tty */
tty_device = proc_mknod("tty", S_IFCHR | 0666, example_dir, MKDEV(5, 0));
if(tty_device == NULL) {
rv = -ENOMEM;
goto no_tty;
}
tty_device->owner = THIS_MODULE;
/* 创建链接文件jiffies_too */
symlink = proc_symlink("jiffies_too", example_dir, "jiffies");
if(symlink == NULL) {
rv = -ENOMEM;
goto no_symlink;
}
symlink->owner = THIS_MODULE;
/* 所有创建都成功 */
printk(KERN_INFO "%s %s initialised\n",
MODULE_NAME, MODULE_VERSION);
return 0;
/*出错处理*/
no_symlink: remove_proc_entry("tty", example_dir);
no_tty: remove_proc_entry("bar", example_dir);
no_bar: remove_proc_entry("foo", example_dir);
no_foo: remove_proc_entry("jiffies", example_dir);
no_jiffies: remove_proc_entry(MODULE_NAME, NULL);
out: return rv;
}
…………
内核模块proc_example首先在/proc目录下创建自己的子目录proc_example。然后在这个目录下创建了三个proc普通文件(foo,bar,jiffies),一个设备文件(tty)以及一个文件链接(jiffies_too)。具体来说,foo和bar是两个可读写文件,它们共享函数proc_read_foobar和proc_write_foobar。jiffies是一个只读文件,取得当前系统时间jiffies。jiffies_too为文件jiffies的一个符号链接。
2、内核管理工具
1、sysctl管理工具
sysctl修改的参数是临时生效的,通过编写配置文件的方式实现持久化生效。
#配置文件
/run/sysctl.d/*.conf
/etc/sysctl.d/*.conf
/usr/local/lib/sysctl.d/*.conf
/usr/lib/sysctl.d/*.conf
/lib/sysctl.d/*.conf
/etc/sysctl.conf #主要存放在这里面,一般都在这个配置文件里面编写设置格式:
和文件中的格式不一样,使用点(.)来隔开路径。/proc/sys不用写, 因为这个配置文件对应就是管理/proc/sys这个文件夹的。
常用参数:
-w 临时改变某个指定参数的值
-a 显示所有生效的系统参数
-p 从指定的文件加载系统参数范例:
禁止ping通本机:
[root@centos8 ~]#cat /etc/sysctl.d/test.conf
net.ipv4.icmp_echo_ignore_all=1
[root@centos8 ~]#sysctl -p /etc/sysctl.d/test.conf
清除缓存方法:
echo 1|2|3 >/proc/sys/vm/drop_caches2、ulimit 对系统资源限制
ulimit 限制用户的某些系统资源,包括可以开启的档案数量、可以使用的 CPU 时间、可以使用的内存总量等。
语法:
ulimit [-acdfHlmnpsStvw] [size] 选项与参数:
-H : hard limit ,严格的设定,必定不能超过这个设定的数值
-S : soft limit ,警告的设定,可以超过这个设定值,但是若超过则有警告讯息
-a : 后面不接任何选项与参数,可列出所有的限制额度
-c : 当某些程序发生错误时,系统可能会将该程序在内存中的信息写成档案,这种档案就被称为核心档案(core file)。
-f : 此 shell 可以建立的最大档案容量(一般可能设定为 2GB)单位为 Kbytes
-d : 程序可使用的最大断裂内存(segment)容量
-l : 可用于锁定 (lock) 的内存量
-m : 设置可以使用的常驻内存的最大值.单位:kbytes
-n : 设置内核可以同时打开的文件描述符的最大值.单位:n
-p : 设置管道缓冲区的最大值.单位:kbytes
-s : 设置堆栈的最大值.单位:kbytes
-v : 设置虚拟内存的最大值.单位:kbytes
-t : 可使用的最大 CPU 时间 (单位为秒)
-u : 单一用户可以使用的最大程序(process)数量 一般简单设置:
ulimit -SHn 65535 让其永久生效:
[root@www ~]# vi /etc/security/limits.conf
* soft noproc 65535
* hard noproc 65535
* soft nofile 409600
* hard nofile 409600 说明:
* 代表针对所有用户
noproc 是代表最大进程数
nofile 是代表最大文件打开数
案例:
[root@www ~]# vi /etc/security/limits.conf
# End of file
* soft core unlimit
* hard core unlimit
* soft fsize unlimited
* hard fsize unlimited
* soft data unlimited
* hard data unlimited
* soft nproc 65535
* hard nproc 63535
* soft stack unlimited
* hard stack unlimited
* soft nofile 409600
* hard nofile 409600
cat /etc/security/limits.conf
cat /etc/security/limits.d/90-nproc.conf
sysctl/ulimit 设置不当,可以在上述指标都非常正常的情况下,使系统响应变得特别慢。
案例:为了方便,我在系统的初始化脚本 configure_server.py 里一次性将 redis/elasticsearch/网络 等 sysctl/ulimit 参数全部配置好。结果 elasticsearch 需要设置的 vm.max_map_count 参数导致 redis 服务器在长时间运行后响应变慢。
3、linux系统资源限制
oracle运行在linux上。对资源限制有一定要求。
limits.conf 和sysctl.conf
安装oracle总是逃不掉在这两个文件中设置参数:sysctl.conf 文件主要针对系统做资源限制。而limit.conf主要针对用户做资源限制,其依赖于PAM机制(插入式认证模块Pluggable Authentication Modules),设置的限制不能超越操作系统的设置。
limits.conf 语法:
username|@groupname type resource limitusername|@groupname:设置需要被限制的用户名,组名前面加@和用户名区别。也可以用通配符*来做所有用户的限制。
参数:
type:
可以指定 soft,hard 和 -,soft 指的是当前系统生效的设置值。hard 表明系统中所能设定的最大值。soft 的限制不能比har 限制高。用 - 就表明同时设置了 soft 和 hard 的值。
resource:
core - 限制内核文件的大小
date - 最大数据大小
fsize - 最大文件大小
memlock - 最大锁定内存地址空间
nofile - 打开文件的最大数目
rss - 最大持久设置大小
stack - 最大栈大小
cpu - 以分钟为单位的最多 CPU 时间
noproc - 进程的最大数目
as - 地址空间限制
maxlogins - 此用户允许登录的最大数目查询设置:ulimit 命令
只对当前tty(终端有效)。ulimit命令本身就有分软硬设置,加-H就是硬,加-S就是软。
参数:
-H 设置硬件资源限制.
-S 设置软件资源限制.
-a 显示当前所有的资源限制.
-c size:设置core文件的最大值.单位:blocks
-d size:设置数据段的最大值.单位:kbytes
-f size:设置创建文件的最大值.单位:blocks
-l size:设置在内存中锁定进程的最大值.单位:kbytes
-m size:设置可以使用的常驻内存的最大值.单位:kbytes
-n size:设置内核可以同时打开的文件描述符的最大值.单位:n
-p size:设置管道缓冲区的最大值.单位:kbytes
-s size:设置堆栈的最大值.单位:kbytes
-t size:设置CPU使用时间的最大上限.单位:seconds
-v size:设置虚拟内存的最大值.单位:kbytes注意:
unlimited 是一个特殊值,用于表示不限制
sys.conf 参数说明
/proc/sys目录下存放着大多数内核参数,并且可以在系统运行时进行更改,不过重新启动机器就会失效。/etc/sysctl.conf是一个允许改变正在运行中的Linux系统的接口,它包含一些TCP/IP堆栈和虚拟内存系统的高级选项,修改内核参数永久生效。也就是说/proc/sys下内核文件与配置文件sysctl.conf中变量存在着对应关系。
常见配置:
kernel.shmall=4294967296
vm.min_free_kbytes=262144
kernel.sem=4096 524288 4096 128
fs.file-max=6815744
net.ipv4.ip_local_port_range=9000 65500
net.core.rmem_default=262144
net.core.rmem_max=4194304
net.core.wmem_default=262144
net.core.wmem_max=1048576
fs.aio-max-nr=1048576
kernel.shmmni=4096
vm.nr_hugepages=8029说明:
kernel.shmmax:
是核心参数中最重要的参数之一,用于定义单个共享内存段的最大值。设置应该足够大,能在一个共享内存段下容纳下整个的SGA ,设置的过低可能会导致需要创建多个共享内存段,这样可能导致系统性能的下降。至于导致系统下降的主要原因为在实例启动以及ServerProcess创建的时候,多个小的共享内存段可能会导致当时轻微的系统性能的降低(在启动的时候需要去创建多个虚拟地址段,在进程创建的时候要让进程对多个段进行“识别”,会有一些影响),但是其他时候都不会有影响。
官方建议值:
32位Linux系统:可取最大值为4GB(4294967296bytes)-1byte,即4294967295。建议值为多于内存的一半,所以如果是32为系统,一般可取值为4294967295。32位系统对SGA大小有限制,所以SGA肯定可以包含在单个共享内存段中。
64位linux系统:可取的最大值为物理内存值-1byte,建议值为多于物理内存的一半,一般取值大于SGA_MAX_SIZE即可,可以取物理内存-1byte。例如,如果为12GB物理内存,可取12*1024*1024*1024-1=12884901887,SGA肯定会包含在单个共享内存段中。
kernel.shmall:
该参数控制可以使用的共享内存的总页数。Linux共享内存页大小为4KB,共享内存段的大小都是共享内存页大小的整数倍。一个共享内存段的最大大小是16G,那么需要共享内存页数是16GB/4KB=16777216KB /4KB=4194304(页),也就是64Bit系统下16GB物理内存,设置kernel.shmall = 4194304才符合要求(几乎是原来设置2097152的两倍)。这时可以将shmmax参数调整到16G了,同时可以修改SGA_MAX_SIZE和SGA_TARGET为12G(您想设置的SGA最大大小,当然也可以是2G~14G等,还要协调PGA参数及OS等其他内存使用,不能设置太满,比如16G)
kernel.shmmni:
该参数是共享内存段的最大数量。shmmni缺省值4096,一般肯定是够用了。
fs.file-max:
该参数决定了系统中所允许的文件句柄最大数目,文件句柄设置代表linux系统中可以打开的文件的数量。
fs.aio-max-nr:
此参数限制并发未完成的请求,应该设置避免I/O子系统故障。
kernel.sem:
以kernel.sem = 250 32000 100 128为例:
250是参数semmsl的值,表示一个信号量集合中能够包含的信号量最大数目。
32000是参数semmns的值,表示系统内可允许的信号量最大数目。
100是参数semopm的值,表示单个semopm()调用在一个信号量集合上可以执行的操作数量。
128是参数semmni的值,表示系统信号量集合总数。
net.ipv4.ip_local_port_range:
表示应用程序可使用的IPv4端口范围。
net.core.rmem_default:
表示套接字接收缓冲区大小的缺省值。
net.core.rmem_max:
表示套接字接收缓冲区大小的最大值。
net.core.wmem_default:
表示套接字发送缓冲区大小的缺省值。
net.core.wmem_max:表示套接字发送缓冲区大小的最大值。
vm.nr_hugepages=8029 大页数六、Linux内核优化
内核评估方法:
在启动参数里添加 initcall_debug,能得到更多内核 log:
[ 3.750000] calling ov2640_i2c_driver_init+0x0/0x10 @ 1
[ 3.760000] initcall ov2640_i2c_driver_init+0x0/0x10 returned 0 after 544 usecs
[ 3.760000] calling at91sam9x5_video_init+0x0/0x14 @ 1
[ 3.760000] at91sam9x5-video f0030340.lcdheo1: video device registered @ 0xe0d3e340, irq = 24
[ 3.770000] initcall at91sam9x5_video_init+0x0/0x14 returned 0 after 10388 usecs
[ 3.770000] calling gspca_init+0x0/0x18 @ 1
[ 3.770000] gspca_main: v2.14.0 registered
[ 3.770000] initcall gspca_init+0x0/0x18 returned 0 after 3966 usecs
...另外,可以用 scripts/bootgraph.pl 将 dmesg 的信息转换成图片:
$ scripts/bootgraph.pl boot.log > boot.svg
接下来,找出消耗时间最多的环节,进行优化。
1、优化编译器
ARM vs Thumb2
比较基于 ARM 或者 Thumb2 指令集编译出来的系统和应用。
ARM:rootfs 为 3.79 MB,ffmpeg 为 227 KB。
Thumb2:3.10 MB (-18 %),183 KB (-19 %)。
性能方面:Thumb2 的性能明显略有提升 (约小于 5 %)。
虽然性能有所提升,但是我个人还是会选择 ARM 指令集。
musl vs uClibc
Buildroot 里有 3 种 C库可以选择:glibc、musl、uClibc,这里我们只比较后面 2 种比较小巧的库。
musl:680 KB (统计 /lib 目录)。
uClibc:570 KB (-16 %)。
uClibc 节省了 110 KB,我们选择 uClibc。
2、优化应用程序
我们可以通过 ./configure 对 FFmpeg 的功能组件进行选择。
另外,还可以用 strace 和 perf 命令调试以优化 FFmpeg 的内部d代码。
优化后的结果:
文件系统:从 16.11 MB 缩小到 3.54 MB (-78 %)。
程序的加载和运行时间:缩短 150 ms。
整体启动时间:缩短 350 ms。
在空间的优化很大,但是在启动时间上的优化很小,这是因为 Linux 运行程序时只加载程序的必要部分。
3、优化 Init 和根文件系统
思路:
使用 bootchartd 分析系统启动并裁剪不必要的服务。
将 /etc/init.d/ 下的启动脚本合并为一个。
不挂载 /proc 和 /sys。
裁剪 BusyBox,文件系统越小,内核挂载可能会越快。
将 Init 程序替换成我们的应用程序。
静态编译应用程序。
裁剪掉不常用的文件,找出长时间不访问的文件:
$ find / -atime -1000 -type f优化后的结果:
文件系统:裁剪 Busybox 后,从 3.54 MB 缩小到 2.33 MB (-34 %)。
启动时间:基本没改变,大概是因为文件系统本身就足够小了。
4. 使用 initramfs 作为 rootfs
一般情况下,Linux 系统会先挂载 initramfs,init ramfs 很小且位于内存中,再由 initramfs 负责负载根文件系统。
当我们将 Buildroot rootfs 裁剪得很小时,就可以考虑直接将其作为 initramfs 使用。
这样有什么好处呢?
initramfs 可以和 Kernel 拼接在一起,Bootloader 负责将 Kernel+initramfs 加载到内存中,内核不再需要访问磁盘。
内核不再需要 block/storage 和 filesystem 相关的功能,体积会变得更小,加载时间和初始化时间都会变小。
注意,需要关闭 initramfs 的压缩(CONFIG_INITRAMFS_COMPRESSION_NONE)。
优化后的结果:
即便禁用了 CONFIG_BLOCK 和 CONFIG_MMC 后,总启动时间仍多了 20ms。这可能是因为 Kernel + initramfs 拼在一起之后,内核变大了许多,而内核镜像是需要解压,解压的时间增多了。
5. 裁掉 tracing
在 Kernel hacking 里关闭 Tracers 相关的功能。
启动时间:缩短 550ms。
内核大小:缩小 217KB。
6. 裁掉一些用不上的硬件功能
omap8250_platform_driver_init() // (660 ms)
cpsw_driver_init() // (112 ms)
am335x_child_init() // (82 ms)
...7. 预设 loops per jiffy
在每次启动时,内核都会校准 delay loop 的值,用于 udelay() 函数。
这会测量 loops per jiffy (lpj) 的值。我们只需要启动一次内核,在log 查找 lpj 值:
Calibrating delay loop... 996.14 BogoMIPS (lpj=4980736)然后将 lpj=4980736 填写到启动参数中,即可:
Calibrating delay loop (skipped) preset value.. 996.14 BogoMIPS (lpj=4980736)大约缩短了 82 ms。
8. 禁用 CONFIG_SMP
SMP 的初始化很慢。它通常在默认配置中是启用的,即使是一个单核 CPU。
如果我们的平台是单核的,可以禁用 SMP。
关闭后,内核缩小:-188 KB (-4.6 %),启动时间缩短 126ms.
9. 禁用 log
启动参数里添加 quiet,启动时间缩短 577 ms。
禁用 CONFIG_PRINTK 和 CONFIG_BUG 后,内核缩小 118 KB (-5.8 %) 。
禁用 CONFIG_KALLSYMS 后,内核缩小 107 KB (-5.7 %) 。
合计,启动时间缩短 767 ms。
10. 开启 CONFIG_EMBEDDED 和 CONFIG_EXPERT
这会让系统调用变得更精简,内核会变得没那么通用,但是能保持你的应用程序能运行就足够了。
内核缩小 51 KB。
启动时间缩短 34 ms。
11. 选择 SLAB memory allocators
一般是 SLAB、SLOB、SLUB 三选一。
SLAB:默认选择,最通用、最传统、最可靠。
SLOB:更简洁,代码量更少,更节省空间,适合嵌入式系统,使能后,内核缩小 5 KB,但是启动时间增加 1.43 S!
SLUB:更合适大型系统,使能后,启动时间增加 2 ms。
因此,我们仍使用 SLAB。
12. 内核压缩方式优化
不同压缩方式的特点如下:

实测效果:

看起来,gzip 和 lzo 表现更好。测试的效果应该是和 CPU/磁盘 的性能相关的。
13. 内核编译参数
使能 CONFIG_CC_OPTIMIZE_FOR_SIZE,该选项可能是用 gcc -Os 代替 gcc -O2。

注意,这只是在 BeagleBone Black + Linux 5.1 上的测试结果,不同平台之间有差异。
14. 禁用 /proc 等伪文件系统
要考虑应用的兼容性。
ffmpeg 依赖 /proc ,所以只能关闭一些 proc 相关的选项:CONFIG_PROC_SYSCTL、CONFIG_PROC_PAGE_MONITOR CONFIG_CONFIGFS_FS,启动时间没有变化。
关闭 sysfs, 启动时间缩短 35 ms。
15. 拼接 DTB
启用 CONFIG_ARM_APPENDED_DTB:
$ cat arch/arm/boot/zImage arch/arm/boot/dts/am335x-boneblack-lcd4.dtb > zImage
$ setenv bootcmd 'fatload mmc 0:1 81000000 zImage; bootz 81000000'启动时间缩短 26 ms。
16、优化 Bootloader
这里我们采用最好的方案:使用 Uboot Falcon mode。
Falcon mode 只执行 Uboot 的第一阶段:SPL,然后跳过 Stage 2,执行加载 Kernel。
启动时间缩短 250 ms。
内核优化总结:
到此,启动优化基本完成,最终效果如下:
[0.000000 0.000000]
[0.000785 0.000785] U-Boot SPL 2019.01 (Oct 27 2019 - 08:04:06 +0100)
[0.057822 0.057822] Trying to boot from MMC1
[0.378878 0.321056] fdt_root: FDT_ERR_BADMAGIC
[0.775306 0.396428] Waiting for /dev/video0 to be ready...
[1.966367 1.191061] Starting ffmpeg
...
[2.412284 0.004277] First frame decoded从上电到 LCD 显示第一帧图像,总时间为 2.41 秒。
最有效果的步骤如下:
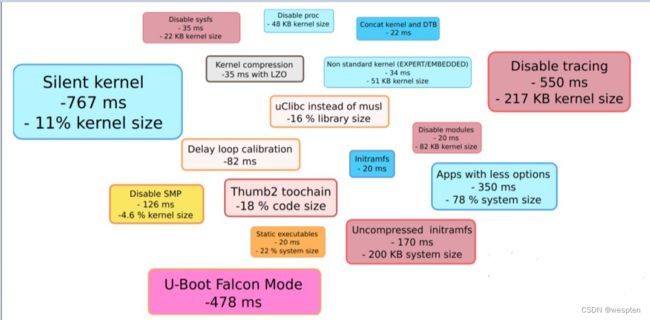
仍值得优化的空间:
系统花了 1.2 秒等待 USB 摄像头的枚举,这里是否有办法加速?
是否可以关闭 tty 和终端登录?
最后,关于优化启动时间,有一些原则可以遵循:
请不要过早地进行优化。
从一些影响面最小的点开始优化。
从 rootfs 、kernel、bootloader 自上而下进行优化。