数据中台的数据仓库和商业智能BI的数据仓库有什么区别?
数据中台的数据仓库和商业智能BI的数据仓库本质上没有任何区别,都是在底层业务系统数据源和上层应用之间做了一个隔离层,进行上下两层的解耦合。从数据分析应用角度来讲,不管是大数据还是小数据,都是把业务系统中不规范、不规则的、不可分析的数据变成规范、规则、可分析的数据过程,都是把描述业务过程的数据模型变成描述业务分析数据模型的转换过程。不管你是做大数据、数据中台还是商业智能BI,只要实现数据仓库,本质过程就是这样的。
只是现在各种各样新的概念满天飞,很多人分不清楚。今天我想通过文字尽量把这个问题给大家讲清楚,能让大家看到一些本质上的问题。大家也可以看下之前讲的有关大数据、数据中台、商业智能BI方面的视频,可以结合起来看下。
一、数据仓库数据库类型的选择
从技术实现角度上来说,我们在通常的商业智能BI项目中,数据仓库大多构建在以关系型数据库为代表的数据库上。数据中台的数据仓库在底层是以大数据为基础架构的。
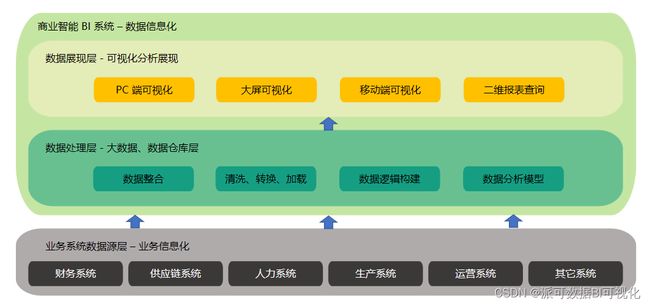 商业智能BI - 派可数据商业智能BI可视化分析平台
商业智能BI - 派可数据商业智能BI可视化分析平台
比如大数据的数据仓库Hive,就是构建在大数据Hadoop分布式基础架构之上。底层的HDFS分布式文件系统为海量数据提供文件式的存储,MapReduce为海量数据提供了计算能力。在Hive数据仓库上可以将Hive SQL转化成MapReduce任务与底层HDFS文件系统进行因映射和数据交互。
二、实现数据仓库的SQL
在商业智能BI的数据仓库中通过标准的SQL就可以进行数据的操作,数据中台大数据架构Hive数据仓库中是通过Hive SQL进行数据操作。但Hive SQL最初的设计目的就是为了让会SQL但是不会编程MapReduce的人也能使用Hadoop进行数据处理,所以在很多语法上不像标准的SQL那么灵活。所以商业智能BI的数据仓库和数据中台数据仓库在技术架构上,一个是基于传统关系型数据库来实现,一个是基于大数据来实现。操作底层数据的基本SQL有一些语法上的差异,但也大同小异。
三、数据仓库的分层实现
只要是数据仓库都会对数据进行分层处理和规划,比如在商业智能BI的数据仓库中我们讲到要构建ODS层,再构建DW里面的Dimension维度和标准的Fact事实层,到Data Mart 数据集市层,最后面向前端的商业智能BI可视化分析应用。数据中台数据仓库就提到了贴源层、统一数据仓库DW层、TDM、ADS层等等,最后也是面向应用端比如商业智能BI可视化分析。
 数据仓库 - 派可数据商业智能BI可视化分析平台
数据仓库 - 派可数据商业智能BI可视化分析平台
这些分层从本质上有区别吗?并没有,都是在讲一些概念。比如标签层,不就是描述一个对象、一个实体的分析维度属性吗?应用数据ADS层不就是我们通常讲到的数据集市层做一些数据的特定加工,比如聚合、跨事实的聚合去组装各种分析的基础数据表吗?所谓的One ID 打通的不就是在一个或者多个业务流程中通过ID编码将各类数据串联起来做一个ID的对照和映射关系吗?本质上都在做什么事情?数据的标准化分类、归档,将不规范、不规则、不可分析的数据变成一种规范、规则、可分析的数据过程。这就是为什么像商业智能BI数据仓库要进行分层实现。
可以这么来说,十来年前商业智能BI的数据仓库怎么构建的,现在的数据中台数据仓库就是怎么构建的,一样的写SQL、做分层、打标签、建模型,并没有什么特殊的。
四、指标的定义
像原子指标、衍生指标、组合指标、过程指标、结果指标,这也不就是我们通常在商业智能BI里面按照用户分层,越面向一线业务的越关注的是原子性的基础性指标,看的是基础的二维明细数据统计报表,越偏向高层管理的越关注的是高度聚合的结果性指标。
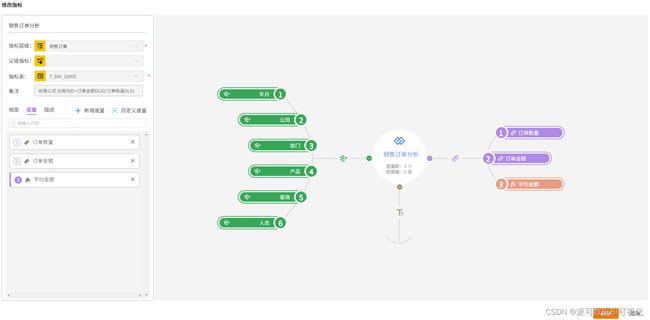 指标 - 派可数据商业智能BI可视化分析平台
指标 - 派可数据商业智能BI可视化分析平台
中间要是去追过程的话就去看过程指标,所谓衍生、组合不都是基于原子性指标计算来的吗?这不就是非常简单的指标梳理、指标计算的商业智能BI实现过程吗?有非常特别的地方吗?并没有。
五、ETL和ELT
还有人会提到传统的商业智能BI数据仓库是ETL,数据中台就是ELT,这些还是在玩一些概念。所谓的ELT就是先把原始数据抽取加载到数据仓库贴源层,再进行数据的转换,这样既保留了原始数据,又可以充分利用大数据的计算能力做转化操作。
我想问下这些概念的提出者,商业智能BI的数据仓库在处理数据的时候不也是这么干的吗?不也是把各个业务系统原始数据给抽取到ODS原始数据层之后再去加工形成DW,做维度表和事实表的划分吗?有没有区别,也没有区别啊,都是这么干的啊。
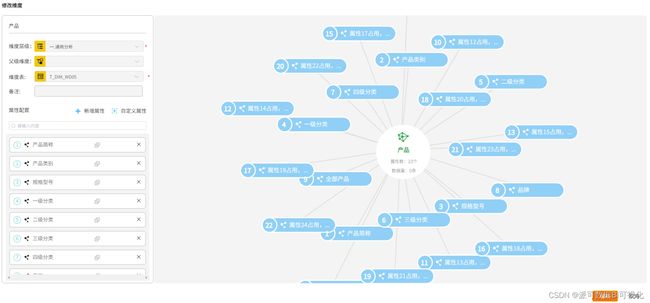 维度 - 派可数据商业智能BI可视化分析平台
维度 - 派可数据商业智能BI可视化分析平台
只是按照ELT的说法,商业智能BI数据仓库在从业务系统抽取数据的时候就直接在SQL里面对数据进行一些转换,落到数据仓库表的时候存储的是已经进行清洗和格式转化之后的数据,所以这样就不好。所以结论就是你们还在讲ETL,太Low了,现在大家都是ELT了。
说到这里也差不多了,通过上面几个点大家就能够看出来,很多概念本质上都是相通的,也回到了主题的数据中台的数据仓库和商业智能BI的数据仓库区别之间的讨论上。
所以,如果你只是听了一个新鲜的概念,就急于拿这些概念来否定一些传统的概念,我觉得大可不必,还是先把一些基础的概念弄明白了再回头看看这些说法对不对。
总结
这样讲并不是去否定大数据、数据中台。传统商业智能BI数据仓库也是有它自己的不足之处的,比如传统商业智能BI数据仓库存储能力、传统ETL的数据处理能力、算力就摆在那,是有数据存储和处理效率瓶颈的。
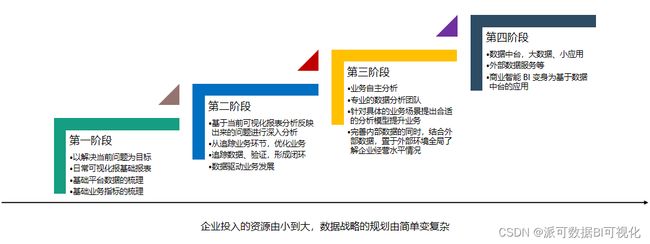 数据战略 - 派可数据商业智能BI可视化分析平台
数据战略 - 派可数据商业智能BI可视化分析平台
比如每天要是处理多少个TB以上的数据,一般的ETL肯定是搞不定的,就算是T+1的方式,晚上跑八个小时到早上也有可能就处理不完,这个时候底层就一定要借助大数据的数据处理能力来解决这些问题。但对于大部分的企业,数据量达不到这种程度,一般的商业智能BI数据仓库和ETL是完全可以搞定的,根本就到不了大数据、数据中台这种量级。
还有像实时数据处理、数据资产管理、数据服务等等,这些也都是传统的商业智能BI数据仓库都不具备的能力,如果企业对这种诉求非常迫切也是可以考虑规划大数据、数据中台这些技术架构的。并且现在很多大数据、数据中台的搞法是把它们数据仓库的数据推送到一个中间库,商业智能BI再从中间库取数做分析展现。
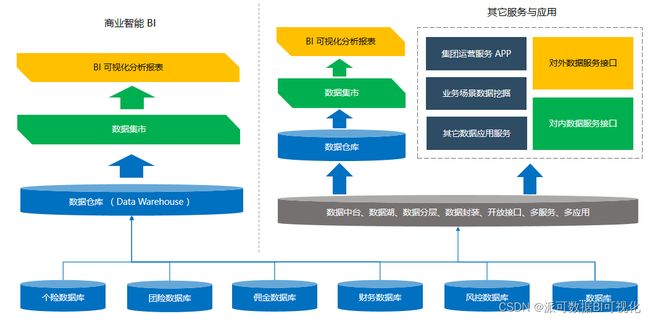 基于数据中台的商业智能BI应用 - 派可数据商业智能BI可视化分析平台
基于数据中台的商业智能BI应用 - 派可数据商业智能BI可视化分析平台
所以是把原来商业智能BI的数据仓库算力的那一部分释放到大数据、数据中台的数据仓库中去实现,中间库的作用就相当于原来商业智能BI数据仓库的数据集市层,纯粹是未来分析展现来使用。但我们的建议这个中间库其实还是要做成数据仓库,只是会做的薄一些,还是要保留基础的维度和事实,只不过事实表做的宽一些而已。
我认为技术并没有高低之分,面对不同的问题解决的方式不同,选择的技术路线不同。
所以,创新一些概念本来也没有错,错的是把这些概念当成尚方宝剑就去急于否定一些很传统的、有着很多年实践落地沉淀的经验总结,这种做法是不对的。
好的,今天的分享就到这里,后续还会持续更新大数据、数据中台、商业智能BI、数据分析等知识,喜欢我们内容的朋友欢迎关注点赞收藏支持,非常感谢大家。