基于Hadoop的带词频统计的文档倒排索引算法实现
实验目的
通过对倒排索引的编程实现,熟练掌握 MapReduce 程序在集群上的提交与执行过程,加深对 MapReduce 编程框架的理解。
实验背景
文档倒排索引是一种支持全文检索的数据结构,该索引结构被用来存储某个单词(或词组)在一个文档或者一组文档中存储位置的映射,即提供了一种根据内容来查找文档的方式。
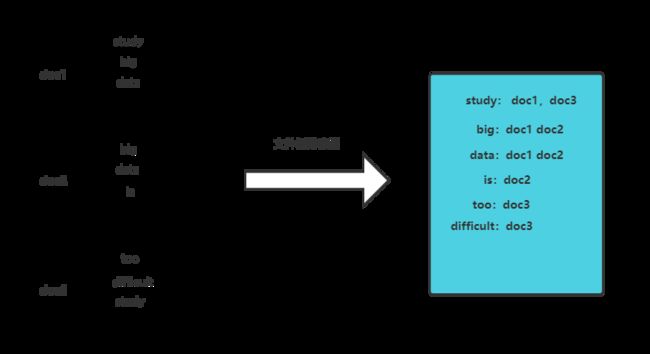
一个倒排索引由大量的postings列表构成,每一个posting列表与一个单词term相关联,由多个posting的列表组成,每一个posting表示对应的单词term在一个具体的文档中出现的描述信息(本实验中描述信息是文件名和词频)。
简单的倒排算法不记录除文件名以外的信息,本实验是实现带词频统计的文档倒排索引,主要功能是实现每个单词的倒排索引,并且统计出单词在每篇文档中出现的次数,同时要求对每个单词按照文档的顺序形成postings。此外还移除了stopwords(一些在检索中没有必要实现倒排索引的词汇,如he,of,re等等)。
实验任务
给定输入文件如下:
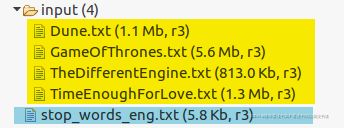
黄色框框内是4篇输入文本,蓝色框框内是停词表。
①要求统计出每个单词出现的对应文本和在对应文本出现的频率,返回一个
②停词表里面的单词都不予统计。
输出文件格式如下:

③ 要求同一个单词里面,对于单词所出现的文档的名字按字典序排序
实验思路
数据预处理
首先查看文档的输入输出数据及其格式。
 节选自GameOfThrones.txt
节选自GameOfThrones.txt
 节选自标准输出
节选自标准输出
初步分析可以获得信息有:
a.文件有标点符号,要去除或者说替换。如 “Do 实际就是Do单词,只是多了一个引号;个别单词结尾后面会带个逗号或者句号或者问号;有的单词会有连词符号如grey-eyed,通过查看标准输出可以知道,连词符被去掉生成了两个单词(可能是为了方便起见,依据生活实际应该算一个单词)。也就是只保留了字母数字,其他字符在标准输出都是没有的,全部去除掉。
b.单词有大小写。有的单词可能会因为处于句子开头(如Are)而被误认为与小写不同(如are),因此统一将所有大写都变为小写。
c.个别单词不在标准输出里面。查看停词表,可以知道对于出现在停词表里面的单词都不予统计:
 节选自stop_words_eng.txt
节选自stop_words_eng.txt
因此需要对每个单词都检索一遍停词表。同时还有一个小坑需要注意的是,stop_words_eng.txt里面并不是每一行就代表一个单词,每个单词后面可能有空格或者tab,即不是规范的一个单词后面就跟着一个回车。所以不能直接readline一行作为一个单词,否则到时候会出现两个单词输出明明一样,但是就是不相等。
使文件名有序
如果只是使用简单的文档倒排,也就是map输出
解决这种问题就只能在Reducer里面将Mapper输出的values进行一次内排序,数据量小的时候没有问题(本实验也没有问题,因为文件数目不多),数据量大的时候可能会内存溢出(指的是如果文件名很多,一个单词属于多个文件)。
还有一种方法是在把文件名filename也归入到key里面,变成
分区Partitioner的重写
在map阶段修改为键值对
因此需要定制一个Partitioner,在里面把word#filename临时拆开(实际上拆开也不会影响到reduce节点收到的key-value,因为partition所做的操作只用于选择分区,不会修改输出的key-value),“蒙骗”Partitioner仍然按照word进行分区,使得不同的word#filename能依据相同的word被分发到相同的节点。
Reduce的处理
要明确一点的是,Reducer从Partitioner处得到有关一个word的文档信息是多次得到的。也就是如果good存在于doc1和doc2文档,那么
因此reduce要解决两部分问题:
a.对于单独的一次key为 good#doc2 的输入,要统计处good在doc2文档里的总出现次数。这无非就是使用for values里的每一个value算总和sum。
b.对于多次key不相同但word相同的输入,如
①如果相同,那就是他们都还是同一个word的输入过程,继续加入到列表list里;
②如果不相同:
因为发送到同一个reduce节点(更准确的说应该是reducetask)的word#filename是有序的(先按word字典序再按filename字典序),所以现在的word#filename已经是新的单词,具体例子是:
如果对于多次调用reduce函数的输入如下:
那么当出现
本地Hadoop的代码实现与运行
map部分
由于添加了停词表,因此Mapper部分需要一个初始化的setup()函数来把hdfs文件系统的停词表文件先读进来。
public void setup(Context context) throws IOException, InterruptedException {
stopwords = new TreeSet();
Configuration conf = context.getConfiguration();
// 每个map节点每次开始map之前都从hdfs文件系统读出停词表
FileSystem fs = FileSystem.get(conf);
//根据自己的路径设置
Path remoPath = new Path("hdfs://localhost:9000/ex2/stop_words_eng.txt");
FSDataInputStream in = fs.open(remoPath);
BufferedReader buffread = new BufferedReader(new InputStreamReader(in));
String line = buffread.readLine();// 经过测试发现,停词表并不是一行一个 单词就换行,而是个别单词之后存在空格
// 因此需要取出第一个空格之前的单词
while (line != null) {
StringTokenizer itr = new StringTokenizer(line);
stopwords.add(itr.nextToken());
line = buffread.readLine();
}
buffread.close();
} hdfs://localhost:9000/ex2/stop_words_eng.txt是我本地停词表的路径,基本方式就是通过HDFS的FileSystem打开HDFS里的停词表,一行一行读入。停词表里面一行就是一个单词,为了避免单词后面可能跟着空格,因此还是用StringTokenizer分词。Stopwords是TreeSet
对于map函数,map的输入是<行偏移,一行文件内容>。
// map函数
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 从分片得到进入到map里的分片属于哪一个文件
FileSplit filesplit = (FileSplit) context.getInputSplit();
String fileName = filesplit.getPath().getName();
// 读入一行文件数据,先将所有大写变为小写,因为某些单词可能出现句首等等会出现大写,但实际上与小写单词是同一个单词
// 再去除掉除了字母和数字以外的符号,因为可能有些单词带着双引号或者逗号,但实际上与不带符号的单词是同一个单词
String line = value.toString().toLowerCase().replaceAll("[^0-9a-zA-Z]", " ");
// 取出每一个单词
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
String term = itr.nextToken();
if (!stopwords.contains(term)) {// 判断这个单词是否是停词表里面的,若不是才继续发送给reduce节点
context.write(new Text(term + "#" + fileName), new IntWritable(1));
}
}
}为了输出word#filename,显然需要得到这个word所在的文件名。而输入到map的是经过inputFormat分片后的inputSplit,inputSplit记录了这一个分片的信息,包括了分块大小、分块所在数据节点位置等。我们采用的是TextInputFormat(读入的是<行偏移,一行文件内容>),而TextInputFormat是FileInputFormat的子类,FileInputFormat对应数据分块类是FileSplit。FileSplit提供了一些方法方便用户获取文件分块的相关属性、该分块在整个文件的相关信息。GetPath()就是获取文件分块的文件名。
一行文件内容是英语句子,我们前面说过,需要进行预处理,转化为只有数字和小写字母的、以空格分割的单词串。通过了toLowerCase()转为小写,replaceAll()去掉非数字和字母符号(用了正则表达式)。
最后就是我们熟悉的操作map操作,将每一个单词连同文件名都输出,输出格式为
Combiner部分
Combiner事实上可有可无,不写Combiner函数的话(相当于使用默认的Combiner,也就是什么也不做)对整个结果也没有影响。使用Combiner的原因在于,上述Mapper程序输出的中间结果中,会包含大量相同主键的键值对。例如word在文档doc中出现100次,那么就会有100个
// 自定义combiner函数,不重载也不影响结果,但可以减少网络通信数据量
public static class CombinerSumFromMapper extends Reducer {
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values)
sum += val.get();
context.write(key, new IntWritable(sum));
}
}
Combiner的输入和Reducer的输入格式相同(这点不难理解,Combiner处于Mapper和Reducer之间,没有Combiner的话Mapper的输出是直接到Reducer),都是:
对values里的每个value求总和即可。
Partitioner部分
再回到我们一开始提到的的使用简单文件倒排索引完成本实验,也就是Mapper输出的是
但现在因为我们Mapper输出的是
因此需要定制一个Partitioner,把组合的key即word#doc临时拆开,蒙骗Partitoner按照word分区,从而选择正确的Reduce节点。
// 自定义partitioner
public static class NewPartitioner extends HashPartitioner {
public int getPartition(Text key, IntWritable value, int numReduceTasks) {
// 重载自hashpartition,但是把key里的doc名划分掉,仍按照单词分区
return super.getPartition(new Text(key.toString().split("#")[0]), value, numReduceTasks);
}
} 基本过程就是调用了拆开word#doc得到word,把它作为参数再调用父类函数。
Reduce部分
Reduce部分的思想在前面已经讲的很清楚了,这里描述一下具体实现:
数据成员:
private Text word1 = new Text();// 要输出的key,也就是word
private Text word2 = new Text();// 要输出的value,也就是
String filename = new String();// 存从输入的拆除来的文件名
static Text CurrentItem = new Text("_top_");// 设置第一个状态,因为单词都是没有下划线的,所以不会冲突
static List postingList = new ArrayList();// 存postinglist
Reduce函数:
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
// 单词
word1.set(key.toString().split("#")[0]);
// 文件名
filename = key.toString().split("#")[1];
// 统计里面次数的总和
int sum = 0;
for (IntWritable val : values)
sum += val.get();
// 将文件名和sum重组为要写出的value
word2.set("<" + filename + "," + sum + ">");
if (CurrentItem.equals(new Text("_top_")))// 之前没有任何单词进入过
{// 不能直接用字符串“_top_”,不然会输出false
CurrentItem.set(word1);
postingList.add(word2.toString());
} else {// 之前已经有相同单词的进入posting
if (!CurrentItem.equals(word1))// 此时进来的是新的单词
{// 意味着前面一个单词的统计已经结束了,因此需要将postinglist输出
StringBuilder out = new StringBuilder();
long count = 0;
for (String posting : postingList) {// 将前面那个单词的每一个posting输出
out.append(posting + ";");
// 从word2的字符串里得到这个单词在该doc里的词频
String oneCount = new String(
posting.substring(posting.lastIndexOf(",") + 1, posting.indexOf(">")));
// System.out.println(posting);
// System.out.println(oneCount);
// 统计这个词在所有文件的总词频
count += Long.parseLong(oneCount);
}
// 写下最后的统计词频
out.append(".");
context.write(CurrentItem, new Text(out.toString()));
// 清空,postinglist交给新来的单词使用
postingList.clear();
// 当前的单词 易主
CurrentItem.set(word1);
}
// 不管是不是新来的
// 若新来的单词已经把前一个单词的postinglist写入了而新的postinglist也已经为空,
// 若还是原本的单词则继续加入到postinglist
// 因此执行的操作都是继续继续写入到postinglist
postingList.add(word2.toString());
}
}
善后工作cleanup:
public void cleanup(Context context) throws IOException, InterruptedException {
// 善后工作
// 把postinglist里面残留的posting的写出来
// 因为最后一个单词没有了后面的单词来把他从postinglist里面写出来
StringBuilder out = new StringBuilder();
long count = 0;
for (String posting : postingList) {
out.append(posting + ";");
String oneCount = new String(posting.substring(posting.lastIndexOf(",") + 1, posting.indexOf(">")));
count += Long.parseLong(oneCount);
}
out.append(".");
context.write(CurrentItem, new Text(out.toString()));
} 要进行cleanup是因为里面最后一个单词的postinglist还在程序里面,还没写入到文件。过程就是重复了一次写过程。
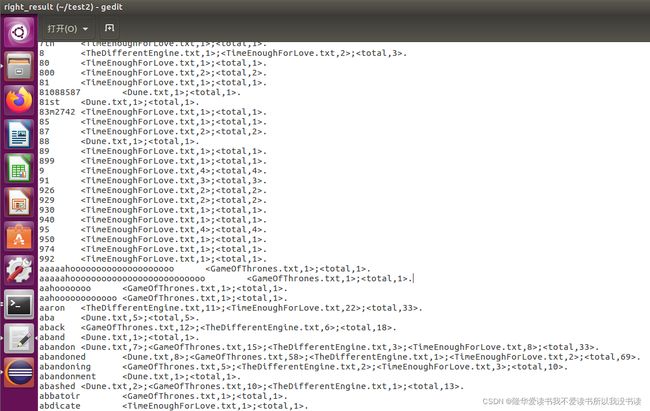
输出结果
结果共32345行:
完整代码
这是针对本地Hadoop编写的代码,只要本地的Hadoop文件系统有所需要的文件,通过eclipse运行Run就可以直接运行出结果,测试的话比较推荐用这种方式。也可以打包成jar包上传到本地的Hadoop系统进行运行(我在本地运行没有几次成功的,map总是到50%左右就卡住了,可能是我机器硬件不太好)。对于结果的查看,可以直接在eclipse里面查看HDFS文件系统,也可以命令行使用hadoop dfs -cat查看。
package org.apache.hadoop.examples;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
import java.util.StringTokenizer;
import java.util.TreeSet;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.util.GenericOptionsParser;
public class InvertedIndex {
public static class InveredIndexMapper extends Mapper {
private Set stopwords;// 停词表
private Path[] localFile;// 用于分布式缓存
public void setup(Context context) throws IOException, InterruptedException {
stopwords = new TreeSet();
Configuration conf = context.getConfiguration();
localFile = DistributedCache.getLocalCacheFiles(conf);
//
// System.out.println(localFile.length);
// System.out.println(localFile[0].toString());
// for (int i = 0; i < localFile.length; i++) {
// BufferedReader buffread = new BufferedReader(new FileReader(localFile[i].toString()));
// String line = buffread.readLine();// 经过测试发现,停词表并不是一行一个 单词就换行,而是个别单词之后存在空格
// // 因此需要取出第一个空格之前的单词
// while (line != null) {
// StringTokenizer itr = new StringTokenizer(line);
// stopwords.add(itr.nextToken());
// line = buffread.readLine();
// }
// buffread.close();
// }
// 每个map节点每次开始map之前都从hdfs文件系统读出停词表
FileSystem fs = FileSystem.get(conf);
Path remoPath = new Path("hdfs://localhost:9000/ex2/stop_words_eng.txt");
FSDataInputStream in = fs.open(remoPath);
BufferedReader buffread = new BufferedReader(new InputStreamReader(in));
String line = buffread.readLine();// 经过测试发现,停词表并不是一行一个 单词就换行,而是个别单词之后存在空格
// 因此需要取出第一个空格之前的单词
while (line != null) {
StringTokenizer itr = new StringTokenizer(line);
stopwords.add(itr.nextToken());
line = buffread.readLine();
}
buffread.close();
}
// map函数
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 从分片得到进入到map里的分片属于哪一个文件
FileSplit filesplit = (FileSplit) context.getInputSplit();
String fileName = filesplit.getPath().getName();
// 读入一行文件数据,先将所有大写变为小写,因为某些单词可能出现句首等等会出现大写,但实际上与小写单词是同一个单词
// 再去除掉除了字母和数字以外的符号,因为可能有些单词带着双引号或者逗号,但实际上与不带符号的单词是同一个单词
String line = value.toString().toLowerCase().replaceAll("[^0-9a-zA-Z]", " ");
// 取出每一个单词
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
String term = itr.nextToken();
if (!stopwords.contains(term)) {// 判断这个单词是否是停词表里面的,若不是才继续发送给reduce节点
context.write(new Text(term + "#" + fileName), new IntWritable(1));
}
}
}
}
// 自定义combiner函数,不重载也不影响结果,但可以减少网络通信数据量
public static class CombinerSumFromMapper extends Reducer {
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values)
sum += val.get();
context.write(key, new IntWritable(sum));
}
}
// 自定义partitioner
public static class NewPartitioner extends HashPartitioner {
public int getPartition(Text key, IntWritable value, int numReduceTasks) {// 重载自hashpartition,但是把key里的doc名划分掉,仍按照单词分区
return super.getPartition(new Text(key.toString().split("#")[0]), value, numReduceTasks);
}
}
// reduce函数
public static class InvertedIndexReducer extends Reducer {
private Text word1 = new Text();// 要输出的key,也就是word
private Text word2 = new Text();// 要输出的value,也就是
String filename = new String();// 存从输入的拆除来的文件名
static Text CurrentItem = new Text("_top_");// 设置第一个状态,因为单词都是没有下划线的,所以不会冲突
static List postingList = new ArrayList();// 存postinglist
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
// 单词
word1.set(key.toString().split("#")[0]);
// 文件名
filename = key.toString().split("#")[1];
// 统计里面次数的总和
int sum = 0;
for (IntWritable val : values)
sum += val.get();
// 将文件名和sum重组为要写出的value
word2.set("<" + filename + "," + sum + ">");
if (CurrentItem.equals(new Text("_top_")))// 之前没有任何单词进入过
{// 不能直接用字符串“_top_”,不然会输出false
CurrentItem.set(word1);
postingList.add(word2.toString());
} else {// 之前已经有相同单词的进入posting
if (!CurrentItem.equals(word1))// 此时进来的是新的单词
{// 意味着前面一个单词的统计已经结束了,因此需要将postinglist输出
StringBuilder out = new StringBuilder();
long count = 0;
for (String posting : postingList) {// 将前面那个单词的每一个posting输出
out.append(posting + ";");
// 从word2的字符串里得到这个单词在该doc里的词频
String oneCount = new String(
posting.substring(posting.lastIndexOf(",") + 1, posting.indexOf(">")));
// System.out.println(posting);
// System.out.println(oneCount);
// 统计这个词在所有文件的总词频
count += Long.parseLong(oneCount);
}
// 写下最后的统计词频
out.append(".");
context.write(CurrentItem, new Text(out.toString()));
// 清空,postinglist交给新来的单词使用
postingList.clear();
// 当前的单词 易主
CurrentItem.set(word1);
}
// 不管是不是新来的
// 若新来的单词已经把前一个单词的postinglist写入了而新的postinglist也已经为空,
// 若还是原本的单词则继续加入到postinglist
// 因此执行的操作都是继续继续写入到postinglist
postingList.add(word2.toString());
}
}
public void cleanup(Context context) throws IOException, InterruptedException {
// 善后工作
// 把postinglist里面残留的posting的写出来
// 因为最后一个单词没有了后面的单词来把他从postinglist里面写出来
StringBuilder out = new StringBuilder();
long count = 0;
for (String posting : postingList) {
out.append(posting + ";");
String oneCount = new String(posting.substring(posting.lastIndexOf(",") + 1, posting.indexOf(">")));
count += Long.parseLong(oneCount);
}
out.append(".");
context.write(CurrentItem, new Text(out.toString()));
}
}
public static void main(String[] args) throws Exception {
// 命令行参数,包括了输入的文件和要输出的文件目录
args = new String[] { "hdfs://localhost:9000/ex2/input", "hdfs://localhost:9000/ex2/output" };
Configuration conf = new Configuration();// 为任务设定配置文件
conf.set("fs.defaultFS", "hdfs://localhost:9000");
DistributedCache.addCacheFile(new URI("hdfs://localhost:9000/ex2/stop_words_eng.txt"), conf);
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();// 其它参数
if (otherArgs.length != 2) {// 参数长度不等于2则异常推出
System.err.println("Usage: wordcount ");
System.exit(2);
}
Path path = new Path(args[1]);
// 加载配置文件
FileSystem fileSystem = path.getFileSystem(conf);
// 输出目录若存在则删除
if (fileSystem.exists(new Path(args[1]))) {
fileSystem.delete(new Path(args[1]), true);
}
Job job = new Job(conf, "InvertedIndex");// 新建Job
job.setJarByClass(InvertedIndex.class);// 设置执行任务的jar
job.setMapperClass(InveredIndexMapper.class);// 设置Maper类
job.setCombinerClass(CombinerSumFromMapper.class);// 设置Combiner类
job.setReducerClass(InvertedIndexReducer.class);// 设置Reduce类
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setPartitionerClass(NewPartitioner.class);
job.setOutputKeyClass(Text.class);// 设置job输出的key
job.setOutputValueClass(Text.class);// job输出的value
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));// 输入文件的路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));// 输出文件的路径
System.exit(job.waitForCompletion(true) ? 0 : 1);// 提交任务等待任务完成
}
} 集群上运行
在本地运行理论上来说是比较慢的,因为实现上使用java线程模拟hadoop节点。在集群上提交作业并执行是比较理想的方式。
在提交到集群上运行之前需要进行一些代码的修改,因为上面代码是针对本地的:
首先是更改代码中输入输出路径,因为现在的输入输出都不在本地hadoop文件系统了,而是在服务器集群上。停词表路径为要修改,文件输入输出的路径要修改,具体修改的地址要根据具体的服务器ip地址。
其次是更改作业运行集群。因为HDFS文件系统的配置不同了,因此要发生变化,改代码中的配置:conf.set("fs.defaultFS", "hdfs://具体服务器ip"),同时更改项目中引入的 core 配置。
当上面提到的环境都被修改、配置完成后,再把代码打包成jar包提交到集群上运行。
以下是集群上运行jar包的具体步骤:
① 用 scp InvertedIndex.jar 用户名@服务器IP:/home/用户名 提交到集群:

②用 ssh 用户名@服务器IP 命令远程登录到 Hadoop 集群进行操作;

③使用 hadoop jar InvertedIndex.jar命令在集群上运行 Hadoop 作业(因为我们程序中已经指定了输入输出位置,所以不用指定输入输出参数了)
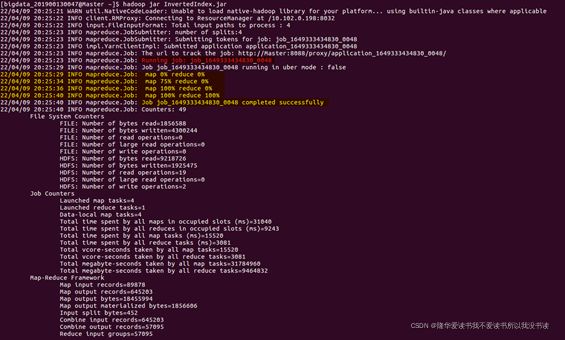
④在浏览器中查看集群的基本信息以及 hdfs 目录;在浏览器中查看集群上作业的基本执行情况。
 集群的HDFS目录
集群的HDFS目录
 集群上作业的基本执行情况
集群上作业的基本执行情况
与标准输出比较
使用 diff 命令判断自己的输出结果与标准输出的差异:
![]()
输出没有其他不同的信息,说明与标准答案一致。
对实验的一点点见解
1、关于优化的地方:
(1)combiner的优化
因为从同一个map节点(严格来说是maptask)输出的中间结果中,会包含大量相同的主键,为此可以将mapper部分的输出的中间结果中的词频先进行一次reduce的累加,依次减少Reduce节点传输的数据量。注意的是combiner不影响输出结果,只是为了解决网络通信性能问题,类似于刚刚提到的,使用简单的文档倒排索引然后再reduce里面内排序只是为了避免内存溢出和提高排序速度,对于最终输出的文档内容没有任何影响。
(2)使用分布式缓存(distributedCache)
关于教材上提到使用分布式缓存。
DistributedCache是Hadoop提供的文件缓存工具,它能够自动将指定的文件分发到各个节点上,缓存到本地,供用户程序读取使用。在作业启动之前,MapReduce框架会将可能需要的缓存文件复制到执行任务节点的本地。该方法的优点是每个Job共享文件只会在启动之后复制一次,并且它适用于大量的共享数据;而缺点是只读的。
本实验中,有一个可以利用的就是停词表,因为map函数都需要查表,把停词表通过DistributedCache读到缓存,是一个不错的方法。
为了使用 DistributedCache,我重写了map部分的setup部分:
public void setup(Context context) throws IOException, InterruptedException {
stopwords = new TreeSet();
Configuration conf = context.getConfiguration();
localFile = DistributedCache.getLocalCacheFiles(conf);
//
// System.out.println(localFile.length);
// System.out.println(localFile[0].toString());
for (int i = 0; i < localFile.length; i++) {
BufferedReader buffread = new BufferedReader(new FileReader(localFile[i].toString()));
String line = buffread.readLine();// 经过测试发现,停词表并不是一行一个 单词就换行,而是个别单词之后存在空格
// 因此需要取出第一个空格之前的单词
while (line != null) {
StringTokenizer itr = new StringTokenizer(line);
stopwords.add(itr.nextToken());
line = buffread.readLine();
}
buffread.close();
}
} 需要注意的是,main函数里面也要相应增加下面代码:
Configuration conf = new Configuration();// 为任务设定配置文件
conf.set("fs.defaultFS", "hdfs://服务器集群IP");
DistributedCache.addCacheFile(new URI("hdfs://服务器集群IP/文件路径/stop_words_eng.txt"), conf);同样打包成jar包之后上传集群运行,输出结果和采用从HDFS读取停词表的结果一致。
但使用distributedCache后,对于本次实验优化程度我认为应该画个问号。
以下是我认为的几点理由:
在每个map节点(严格来说是mapTask,一个map节点可以有多个maptask,maptask是逻辑单位,map节点是物理单位)的setup阶段都会从HDFS文件系统里面的stop_words_eng.txt里面读出停词表,这个停词表是每一个节点都共享使用的。
而要实现共享可以采用两种方式:一种是map任务开始时(也就是Mapper类实例化时)从HDFS文件系统读取出停词表,一种是job启动时就把需要的缓存文件复制到执行任务节点的本地。这其中的差别我想了一下应该有两点,第一点是时间:一个是map节点开始工作时才去读文件而另外一个是job启动时就把共享文件发送到各个节点,第二点是空间,一个是从HDFS文件系统去读取,有网络代价,而另一个是从本地缓存取,速度更快(如果不考虑初始发送文件到本地这个代价)。这么看来用分布式缓存会更好,这也是我理解的采用分布式缓存的好处。
但是从网上的一些其他优缺点分析来看,那些优点在实际使用中固然存在,但是针对本实验又不是很适用。
首先是如果共享数据放在HDFS而不是本地缓存,对其数据操作会明显慢于分布式存储。但实际上本实验不符合这一点,因为我们使用数据对象都是会读入到程序内部数据结构,再对这些数据结构进行操作。实验中,两种方式在setup阶段都被读入到Mapper类的数据成员,以后的操作都是针对他们,因此单论读入后(指的是不管采用哪一种方式,停词表都已经读到本地了)的操作时间而言是没有差别的。
其次是对于多节点的情况分布式缓存效率更好。如果采用从HDFS读取停词表,每个Map线程(程序中的体现是一个实例化的Mapper类)中都会执行一次读取HDFS文件系统的文件操作,意味着如果对于文件比较大或者有很多个线程时,那么在数据IO方面会浪费大量时间;而分布式缓存它是从本地文件系统读取,时间少于前者。但从本次实验上传集群后的测试结果来看,默认只使用了一个ReduceTask,因此影响并不是很大。
还有就是如果采用HDFS读取停词表引起的写冲突,如果多个map涉及到文件的写操作,那么可能会相互覆盖数据。分布式缓存不会有写冲突,因为分布式缓存只支持只读。而本实验的停词表是只读的,所以也不算优化。
综上,分布式缓存虽然适合共享较大的数据,但是应该根据实际进行采用,不一定使用HDFS里的文件进行数据共享效率就差很多。
2、关于Partitioner
实验中我们重写了Partitioner分区,确保不同的
但是对于更实际的环境一般是多个ReduceTask,重写Partitioner是完全有必要的。本实验中可以设置用setNumReduceTask设置多个ReduceTask,让Partitioner发挥作用。但是会导致一个问题就是和标准答案不同了。因为会输出了多个结果文件,每个结果文件内部有序,但多个结果文件全局不是有序的,也就是把文件1、文件2、文件n挨个连起来不是有序的。
为了能让Partitioner有用,而且还要全局有序,那么Partitioner就不能仅仅调用HashPartitioner。经过思考我认为可以用到TotalOrderPartitioner的思想,预读一小部分数据采样,对采样数据排序后均分,假设有N个reducer,则取得N-1个分割点,先明确大概每个Reduce节点分多少数据量。然后确定分割点的值,比如a~c开头的单词分一个Reduce节点,d~w开头的单词分一个Reduce节点,x~z开头的单词分一个Reduce节点,这样就能在Reduce内部保证有序,同时全局有序。