Java集合详解
java集合
集合、数组都是对多个数据进行存储操作的结构,简称Java容器。
说明:此时的存储,主要是指的内存层面的存储,不涉及到持久化的存储 。
数组在存储多个数据方面的缺点:
一旦初始化以后,其长度就不可以修改。
数组中提供的方法十分有限,对于添加,删除,插入数据等操作时非常不便,同时效率不高。
获取数组中实际元素的个数的需求,数组没有现成的属性或方法可用。
数组存储数据的特点: 有序、可重复。对于无序、不可重复的需求,不能满足。
于是有了集合(相当于动态开辟内存空间的数组)
一,Collection集合接口
java.util.Collection是单值集合操作的最大的父接口,在该接口中定义了所有的单值数据的处理操作。这个图非常重要!!!!
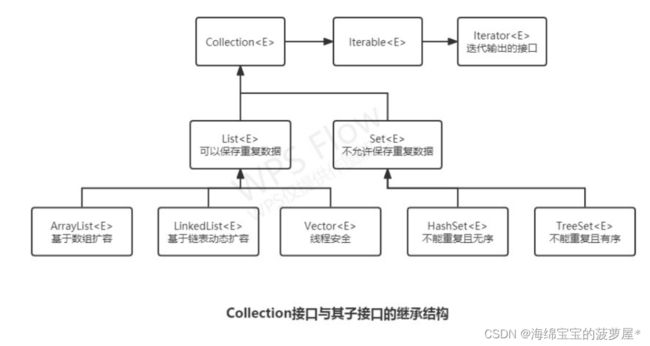
二、List集合
List是Collection最常用的子接口,其最大的特点是允许保存重复元素的数据,并且List接口对Collection接口方法进行扩充
List扩充的三个方法
public E get(int index) 获取指定索引的数据
public E set(int index,E element) 修改指定的索引数据
public ListIterator<E> listIterator 返回listItertor接口
2.1 ArrayList
ArrayList子类是在使用List接口最常用的一个子类,该类利用数组实现List集合操作
复习旧的知识可以从源码中分析:(如果不会看源码没有关系 先学会看API)
通过有参构造方法发现,在ArrayList里面包含的数据实际上就是一个对象数组。
范例:集合操作的方法
public class LinkedList12 {
public static void main(String[] args) {
List<String> all = new ArrayList<>();
System.out.println("集合是否为空?"+all.isEmpty()+"集合的元素个数:"+all.size());
all.add("一只羊");
all.add("一只羊"); //允许重复
all.add("两只羊");
System.out.println("数据存在判断:"+all.contains("一只羊"));
all.remove("两只羊");
System.out.println("集合是否为空?"+all.isEmpty()+"集合的元素个数:"+all.size());
System.out.println(all.get(1)); //获取指定索引元素
}
}

这个类本身含有的add()方法是如何实现东西添加的呢?

通过grow()这个方法我们可以发现,如果ArrayList集合里面保存的对象数组长度不够的时候会进行新的数组开辟,同时将原始的旧数组拷贝到新数组当中。
那新的大小是如何定义的呢?
JDK1.9之后:ArrayList默认的构造方法只会使用默认的空数组,使用的时候才会开辟新的数。
JDK1.9之前:ArrayList默认的构造会默认开辟大小为10的数组。
2.2、LinkedList
LinkedList子类是基于链表的形式实现的List接口标准。
先观察其继承关系:

LinkedList和ArrayList的使用是完全一样的,但是其内部的实现机制是完全不同的,首先观察LinkedList的构造方法。
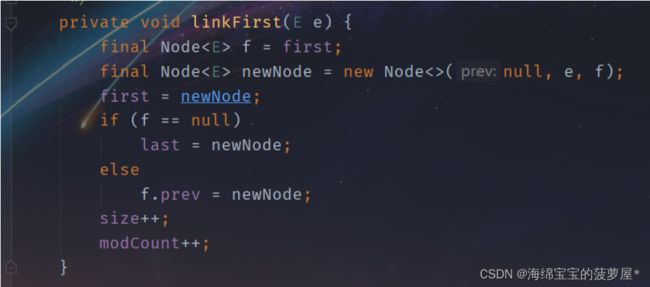
其底层数据结构链表的实现。
面试题:请问ArrayList与LinkedList有什么区别?
ArrayList是数组实现的集合操作,而LinkedList是链表实现的集合操作。
链表与数组最大的区别在于:链表实现不需要频繁的进行新数组的空间开辟,
但是数组在根据索引获取数据时时间复杂度为O(1),链表的时间复杂度为O(n)。
(List集合中的get()方法)根据索引获取数据时,ArrayList的时间复杂度为O(1),LinkedList的时间复杂度为O(n)。
ArrayList在使用的时候默认的初始化对象数组的大小长度为10,如果空间不足采用2倍形式进行容量的扩充,如果保存大数据的时候有可能造成垃圾的产生以及性能的下降,但是这个时候可以使用LinkedList子类保存。
2.3 Vector
Vector是一个原始的程序类,这个类在JDK1.0时就提供,而到了JDK1.2的时候,很多开发者已经习惯使用Vector,而且许多系统类也是基于Vector来实现的。
关于Vector的进一步说明
ArrayList与Vector除了推出时间不同以外,实际上他们内部的实现机制也有所不同,通过源代码的分析可以发现Vector类的操作方法采用的都是synchronize同步处理,而ArrayList并没有进行同步处理,所有Vector类中方法在多线程访问的时候属于线程安全的,但是性能不如ArrayList高,所以在考虑到线程并发访问的情况下才会去使用Vector子类。
三,set集合
Set集合的定义如下:
Set接口中定义的方法是Set是无序(无下标),不重复的,当使用(jdk1.9才有这个方法,1.8没有)of() 这个新方法的时候如何发现集合中存在重复的元素则会直接抛出异常,Set集合的常规使用形式一定是依靠子类进行实例化的,Set接口中有两个常用的子类:
HashSet(散列存放) TreeSet(有序存放)
HashSet
HashSet是Set接口较为常见的子类,所有的内容都采用散列(无序)的方式进行存储。该子类的最大特点就是不允许保存重复元素,为啥呢?
HashSet会识别重复的元素,HashSet可以实现去重操作。
HashSet如何实现去重的呢?
它利用的是Object类中提供的方法实现的:
public int hashCode(); // 对象编码
public boolean equals(Object obj); // 对象比较
首先利用hashCode()进行编码匹配,如果编码不存在则表示数据不存在,证明没有重复的对象需要比较,如果发现重复了,则该数据是不能被保存。
TreeSet
TreeSet(内部实现二叉树) 特点:有序 不重复 主要作用:排序。
这个类需要根据Comparable接口来确定大小关系。
public static void main(String[] args) {
Set<String> all = new TreeSet<>();
all.add("sky_ang");
all.add("Java");
all.add("Java");
all.add("Hello World");
System.out.println(all);
}

通过执行结果发现:所有保存的数据都会按照从小到大的顺序(字符串会按照字母大小的顺序依次比较)排列,并且元素不重复。
在Java程序之中,判断重复元素的判断处理就是hashCode()与equals()两个方法共同完成。
四,Map集合
在开发当中,Collection集合保存数据的目的是为了输出,Map集合保存数据的目的是为了进行key的查找。
Map接口是进行二元偶对象保存的最大父接口public interface Map
通过HashMap实例化Map接口,可以针对key或value保存null的数据,同时发现及时保存数据的key重复,那么也不会出现错误。
但是对于Map接口提供的put()方法本身是有返回值的,这个返回值是指在重复key的情况下返回旧的value。
以下这个图非常重要!!!
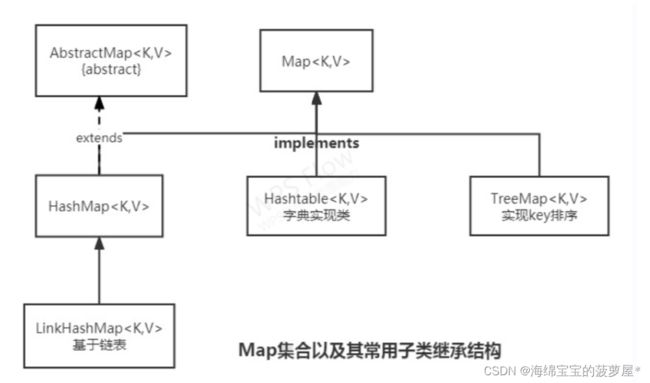
HashMap
HashMap是Map接口中常用的子类,该类的主要特点是采用散列的方式存储。
范例:使用HashMap进行Map集合操作
public class HashMap12 {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<String,Integer>();
map.put("one",1);
map.put("two",2);
map.put("one",12); //key重复会发生覆盖
map.put("zero",null);
map.put(null,1);
System.out.println(map.get("one"));
System.out.println(map.get(null));
System.out.println(map.get("ten"));
}
}

后面有两道面试题是关于HashMap的源码理解,请不要着急哦!
LinkedHashMap
Hash采用的是散列算法进行数据存储,这就造成了无序存放,但是要求严格下需要按照顺序存放,所以提供了链表的形式的Map集合。
LinkedHashMap子类最大的特点是可以基于链表形式实现偶对象的存储,这样就可以保证集合的存储顺序与数据增加的顺序相同
Hashtable
Hashtable是早期的字典实现类,可以方便的实现数据的查询
public static void main(String[] args) {
Map<String, Integer> map = new Hashtable<String, Integer>();
map.put("one",1);
map.put("two",2);
System.out.println(map);
}

HashMap与Hashtable的区别
HashMap中的方法都属于异步操作(非线程安全),HashMap允许保存的数据为空,Hashtable中的方法都属于同步操作(线程安全),Hashtable不允许保存null数据,否则会出现NullPointException异常。
TreeMap
Map集合的主要功能是依据key实现数据的查询需求,为了方便进行key排序操作提供了TreeMap集合,
public static void main(String[] args) {
Map<String, Integer> map = new TreeMap<String,Integer>();
map.put("c",1);
map.put("b",2);
map.put("a",3);
System.out.println(map);
}

本程序将TreeMap中保存的key类型设置为String,由于String实现了Comparable接口,所以此时可以根据保存的字符的编码由低到高进行排序。
面试题一:
HashMap是如何实现容量扩充的?

初始化容量扩充为16
当保存内容的容量扩充超过了与阈值*0.75=12时,就会进行容量的扩充。
在进行扩充的时候HashMap采用的成倍的扩充模式即:每一次扩充两倍(源码用的左移运算符1<<)
面试题二:HashMap的工作原理
在HashMap之中进行数据存储的依然是利用Node类完成的,那么这种情况就是可以使用的数据结构之后两种:链表和二叉树,本质区别在于时间复杂度不同,链表存储时间复杂度O(n),二叉树存储O(logn)(树的高度)
从jdk1.8开始,HashMap的实现出现了改变,因为其要适应大数据的海量数据存储,其存储发生了改变,并且HashMap内部中提供了一个特别重要的常量:

在使用HashMap存储数据的时候,如果保存的数据个数没有超过阈值8,那么会按照链表的方式存储;
则会将链表转为红黑树实现树的平衡,并且利用左旋与右旋来保证数据的查询性能。
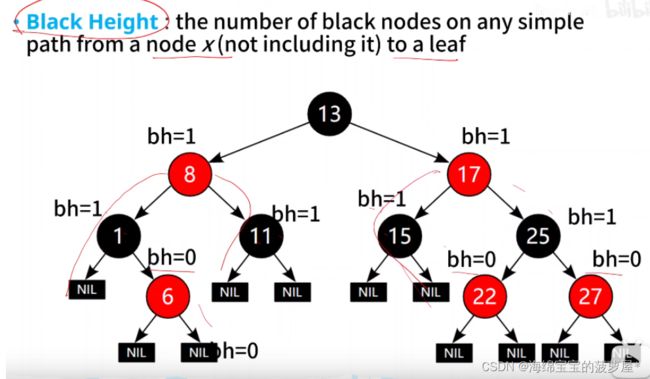
扩展红黑树:

红黑树的特点:节点是红色或者黑色,
2,根节点是黑色的
3,每个叶子的节点都是黑色的空节点(NULL)
4,每个红色节点的两个节点都是黑色的
5,从任意节点 到 其每个叶子节点的 所有路径都包含相同的黑色节点(黑色高度相同)
插入和删除节点或导致红黑树不平衡,当红黑色不平衡时,有两种调整方式**【变色】和【旋转】**
五 集合输出(Iterator)
Collection接口提供toArray()的方法可以将集合保存的数据转为对象数据返回,用户可以利用数组的循环方法进行内容的获取,但是此类的方法由于性能不高不是集合输出的首选方案,集类集框架中对于集合的输出提供了四种方式:
Iterator,ListIterator,Enumeration,foreach
这里主要讲foreach输出,foreach除了支持数组的输出以外,也支持集合的输出。
范例1:使用foreach输出set集合数据
public class Foreach12 {
public static void main(String[] args) {
Set<String> strings = new HashSet<String>();
strings.add("sky_ang");
strings.add("skyang.cn 这个是我的个人网站");
for (String temp : strings) {
System.out.println(temp);
}
}
}