【点云深度学习】常见网络模块:transformer中的attention机制
论文原文:Attention is all you need
最近在学习网络的时候发现,许多新论文中的网络设计中仍然沿用了之前经典网络的结构。3D点云领域有一篇热度非常高的网络Deep Closet Point(DCP),其属于Frame-toFrame的结构,其中网络设计部分有提到其中的Transformer 模块:
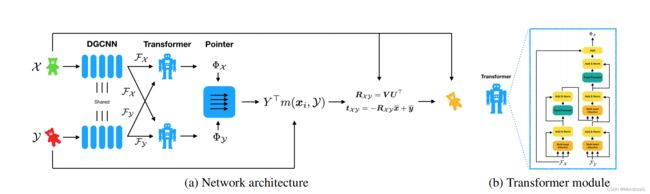
并且在效果比较时DCP也有两个版本:V1,与V2,区别就是是否加入了Attention模块。该论文作者WangYue也是DGCNN(Dynamic Graph CNN)的作者 ,他就是受到了transformer的影响而设计这样的结构的。
将其中的Transformer 模块结构放大就是这个样子:
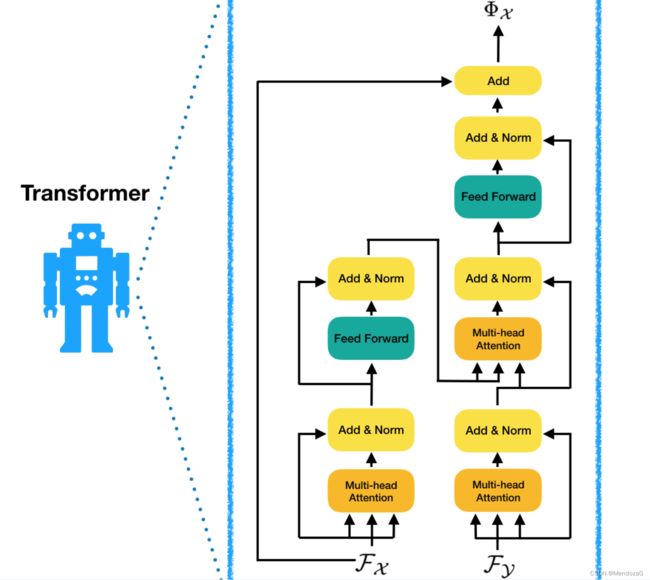
而Transformer 结构为:
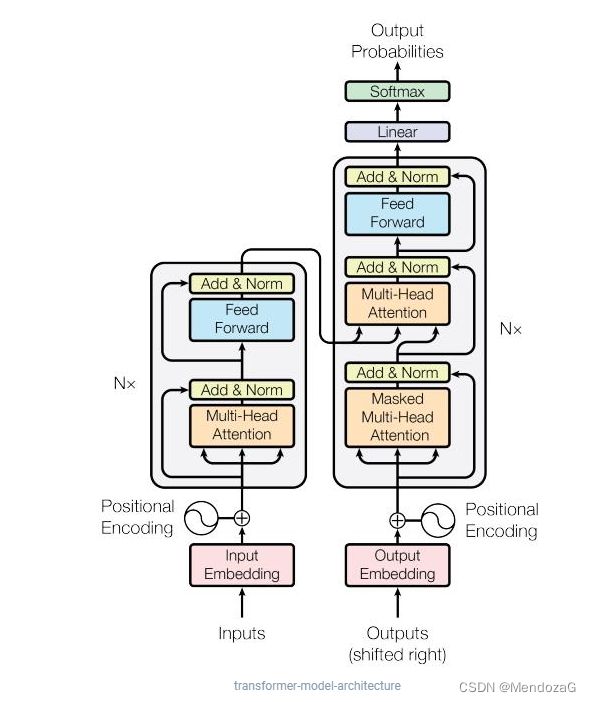
左边的为Encoder,右边为Decoder。该模型是由谷歌在2017年提出的,最早也是用来解决NLP问题的。如下图:

我们先看简单的图:
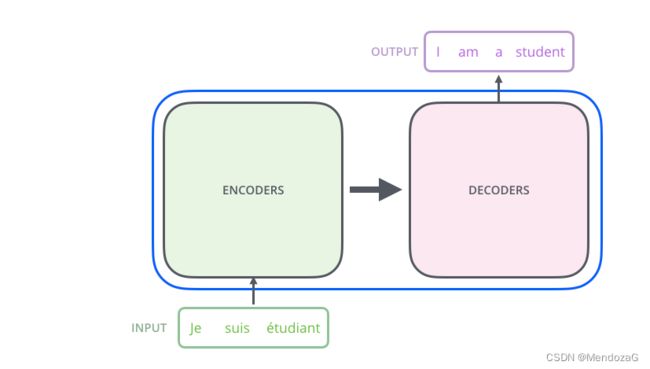
输入为法语,输出为英语,将法语单词通过某种法式(embedding)输入到Encoder当中,再通过Decoder输出为英文单词,这是我们直观能感受到的。那么Encoder和Decoder模块是如何设计的呢:
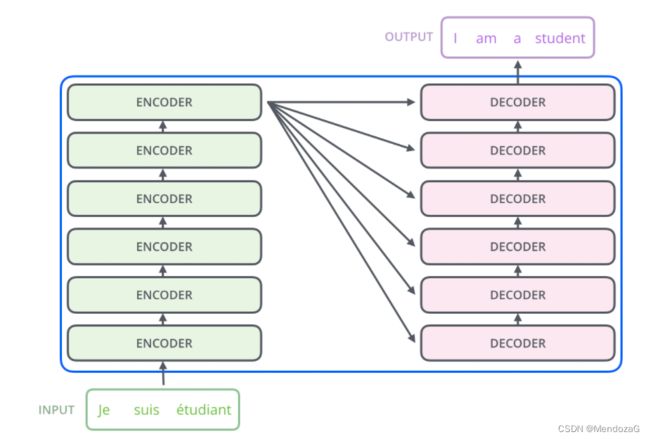
boom,其实这两个模块是由一些列的Encoder和decoder组成的,上图结构为6个,实际上看我们的设计和需求来,但是Encoder和decoder数目需要一样。
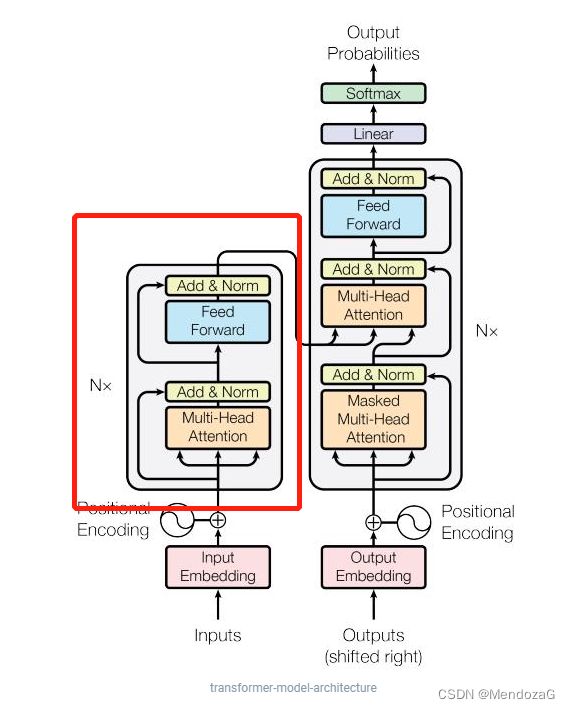
我们将模块放大:
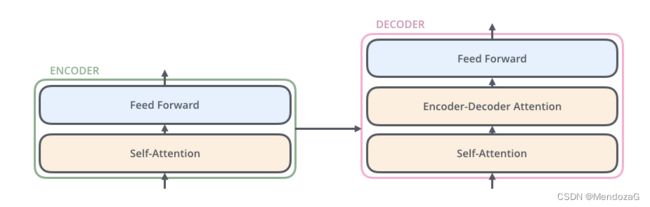
可以发现结构上两者都是相似的,而decoder则中间有一层Attention Layer,作用是帮助decoder注意力集中在输入的相关部分。
前面我们提到的将输入单词转化为某种形式(vector)的方法在NLP中称为Embedding算法。可以这么理解:

所以我们实际实现的内容为:
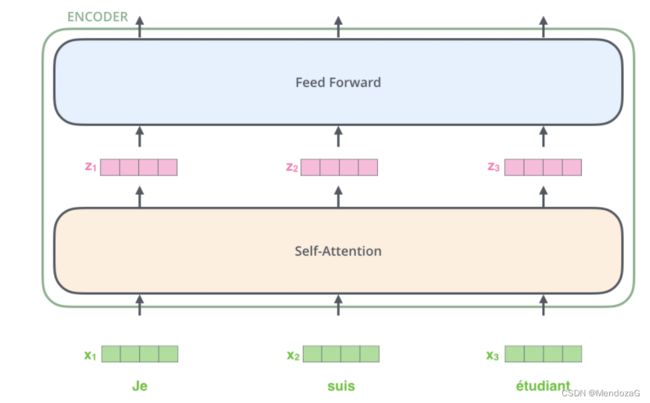
其中z为经过self-attention的结果,是softmax后的结果。具体我们后面会提到。我们来详细说一下这个self-attention部分:
该部分涉及论文中非常重要的部分:Q、K、V,当我们第一眼看到这三个字母时肯定会有些懵逼,其实三者分别代表:Query,Key,Value,即后面的操作实际上是我们在Query和Key来进行一个Match,并结合不同key对应的value值给出一个score,对于得分高的我们就分配更高的attention,这就是注意力机制。
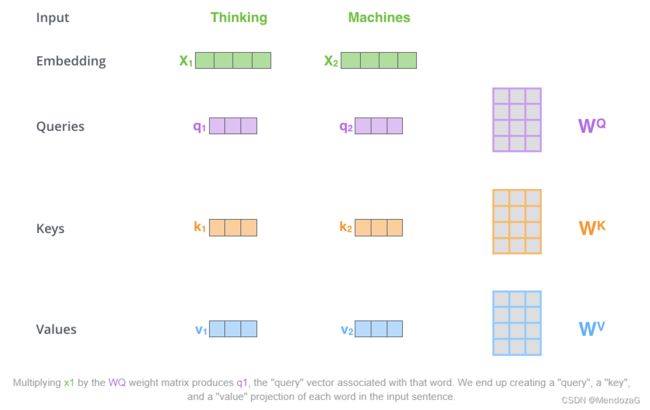
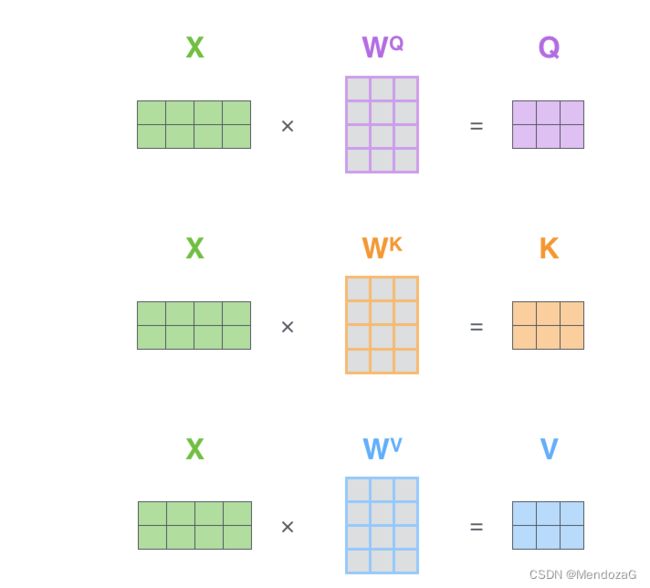
上面的三个矩阵为训练中得到的。
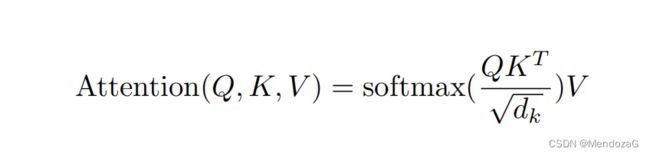
上面式子的值就是我们上面说后面会提到的z值。
该图是对于单个的理解,那么对于多个呢?构成矩阵:
而Z值也可表示为:
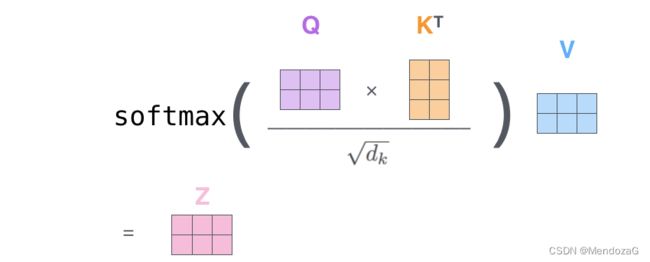
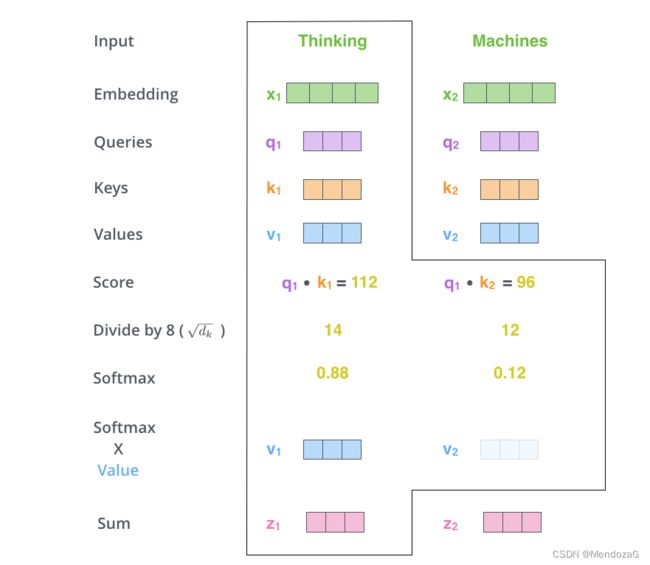
是不是一目了然了,这里Q与K相乘可以结合每个元素的点乘来理解,两个向量的点乘表征了两者的相关性,如果为0,则表示两者不相关,越接近于1两者相关程度越高。
其中dk为为输入向量的维度。除以维度是为了保证梯度的稳定性。可以有效的控制梯度消失,假设Q与K都是均值为0方差为1的dk维度矩阵,则相乘的结果为均值为0,方差为根号下dk,故而除以根号下dk。
对于Multi-Head而言就是多个拼接加上线性化的结果:
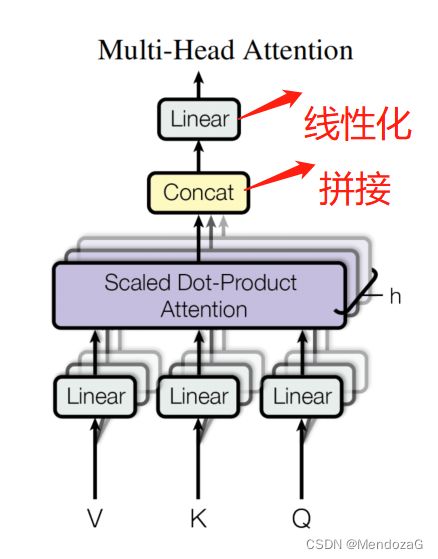
整个流程可以这么理解:

以下是一个应用实例:
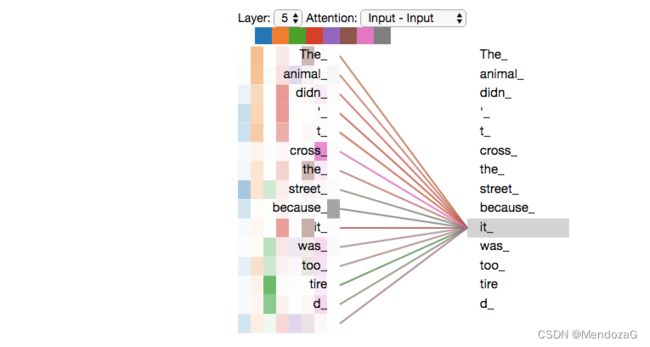
分辨:The animal didn't cross the street because it was too tired”中 it的指代,这对于人类来说很简单但是对于机器就不是这样了,multi-head模型如下:

通过z1,z2的值我们可以得知,animal和tired对于机器来说都会基于较高的attention。
将五层展开,结果如下但是可能就有些难以理解了。
此外还有一个没解决的问题就是语序问题:由同样单词或文字组成的句子语序不同意思会大有不同,这点在网络比较难以实现。所以在进入网络前加入了位置编码部分:

此外,输入和输出为维度也未必相同,此时就需要去padding mask,一般我们是在对应的位置补上负无穷,这样经过softmax值就为0了。
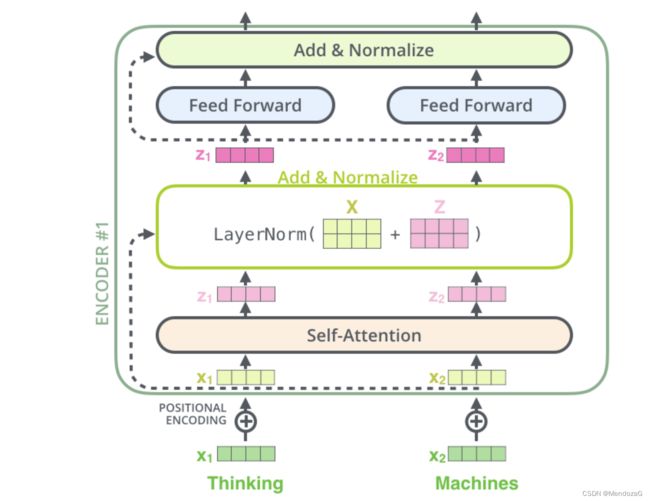
上图的结构中:Add&Normalization可视的表示为:
-----------------------------------------------------------------------------------------
本文大部分图片来源于:
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
非常推荐大家阅读上面的文章,讲的非常好。
此外推荐阅读或观看:
1. Self-Attention和Transformer - machine-learning-notes (这一篇是对推荐文章的解读)
2. Transformer为什么会比CNN好_哔哩哔哩_bilibili