【论文阅读】Point Transformer解读
文章目录
- 前言
-
- 摘要
- 1.介绍
- 2.相关工作
- 3.Point Transformer
-
- 3.1.Background
- 3.2. Point Transformer Layer
- 3.3. Position Encoding
- 3.4. Point Transformer Block
- 3.5. Network Architecture
- 4. Experiments
- 5.总结
前言
1. 为什么要做这个研究?
探究Transformer在点云处理中的应用。
2. 实验方法是什么样的?
在场景分割中采用了U-net结构,包含5个编码器和5个解码器,编码器通过Transition Down + Point Transformer Block来降采样和提取特征,解码器通过Transition Up+ Point Transformer Block来上采样映射特征。
Point Transformer Block:基于vector self-attention,使用减法关系,并将位置编码 δ \delta δ加到注意向量 γ \gamma γ和变换特征 α \alpha α上。
3. 得到了什么结果?
在场景分割、目标分类和语义分割中都取得了很不错的效果,或许使用Transformer来作为提取点云特征的操作是很有效果的。
摘要
本文研究了self-attention网络在三维点云处理中的应用。作者为点云设计了self-attention层,并使用这些层来构建用于语义场景分割、语义分割和目标分类等任务的self-attention网络。在大规模语义场景分割的S3DIS数据集上,Point Transformer表现SOTA。
1.介绍
Transformer的核心self-attention操作本质上是集合操作:它对输入元素的排列和基数不变。因此,将self-attention应用于三维点云是非常自然的,因为点云本质上就是嵌入在三维空间中的集合。
作者研究了self-attention算子的形式,self-attention在每个点周围的局部邻域中的应用,以及网络中位置信息的编码。由此产生的网络完全基于self-attention和逐点操作。结果表明Point Transformer在3D深度学习任务中非常有效。
作者贡献:
- 为点云处理设计了一个高表现力的Point Transformer层。该层对于排列和基数是不变的,因此本质上适合于点云处理。
- 基于Point Transformer层,构建了高性能的Point Transformer网络,用于点云的分类和密集预测。这些网络可以作为三维场景理解的通用主干。
- 作者报告了在多个领域和数据集上的大量实验,进行了对照研究,以检查Point Transformer设计中的具体选择,并在多个高度竞争的基准上设定了新的技术水平,优于之前的工作。
2.相关工作
此前三维点云处理方法:基于投影的、基于体素的和基于点的网络。
3.Point Transformer
首先回顾一下 Transformer和self-attention的一般公式,然后给出用于3D点云处理的Point Transformer层,最后作者提出了3D场景理解网络结构。
3.1.Background
self-attention算子分为两种类型:scalar attention和vector attention。
X = { x i } i \mathcal{X} = \{x_i\}_i X={xi}i为一组特征向量,标准scalar attention点积注意层可以表示如下:
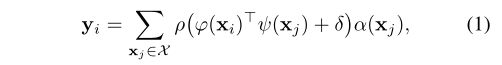
其中 y i y_i yi是输出特征。 ϕ , ψ , α \phi,\psi,\alpha ϕ,ψ,α是逐点transformer特征,类似先行投影或MLPs。 δ \delta δ是位置编码函数, ρ \rho ρ是归一化函数,如softmax。scalar attention计算通过 ϕ \phi ϕ变换特征和 ψ \psi ψ变换特征之间的标量积,并将输出作为关注权重,来聚集 α \alpha α变换特征。
在vector attention中,注意力权重的计算是不同的,特别是注意力权重可以调节单个特征通道的向量。
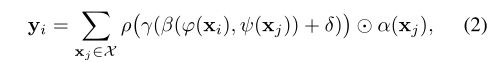
其中 β \beta β是关系函数,例如减法, γ \gamma γ是产生用于特征聚集的注意向量的映射函数,例如MLP。
3.2. Point Transformer Layer
Point Transformer层是基于vector self-attention的,使用减法关系,并将位置编码 δ \delta δ加到注意向量 γ \gamma γ和变换特征 α \alpha α上:
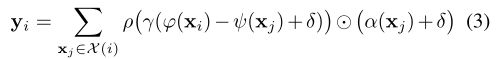
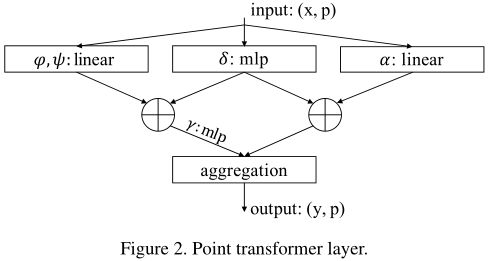
这里,子集 X ( i ) ⊆ X \mathcal{X}(i) ⊆ X X(i)⊆X是 x i x_i xi的局部邻域(k近邻,k=16)中的一组点。因此,作者采用最近的self-attention网络的实践进行图像分析,在每个数据点周围的局部邻域内局部应用self-attention。映射函数 γ \gamma γ是具有两个线性层和一个非线性层的MLP。Point Transformer层如图2所示。
3.3. Position Encoding
在3D点云处理中,3D点坐标本身是位置编码的自然候选。除此之外,作者还引入了可训练的参数化位置编码 δ \delta δ,定义如下:
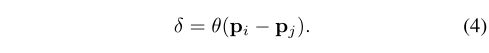
这里 p i p_i pi和 p j p_j pj是两个3D点坐标。编码函数 θ \theta θ是具有两个线性层和一个非线性层的MLP。值得注意的是,作者发现位置编码对于注意力生成分支和特征变换分支都很重要。因此Eq.3在两个分支中增加了可训练的位置编码。位置编码 θ \theta θ与其他子网端到端训练
3.4. Point Transformer Block
我们构建了一个以Point Transformer层为核心的残差Point Transformer块,如图4(a)所示。transformer块集成了self-attention层,可以降维和加速处理的线性投影以及残差连接。输入是一组具有相关3D坐标 p 的特征向量 x。Point Transformer块便于这些局部特征向量之间的信息交换,为所有数据点产生新的特征向量作为其输出。信息聚合既适应特征向量的内容,也适应它们在3D中的布局。
3.5. Network Architecture
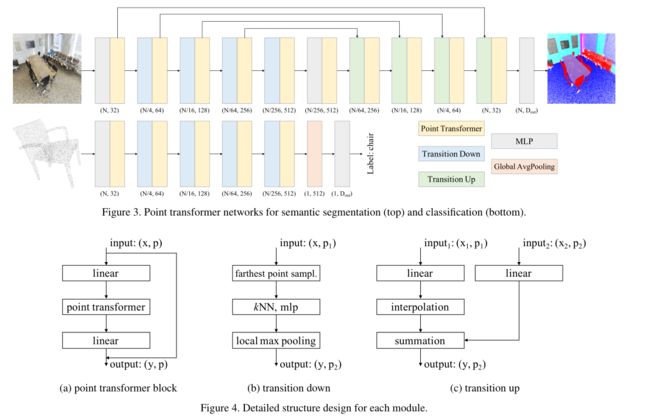
作者基于Point Transformer块构建了完整的3D点云理解网络。Point Transformer是网络中主要的特征聚合操作。作者不使用卷积进行预处理或者辅助分支:网络完全基于Point Transformer层、逐点变换和池化。网络架构如图3所示。
Backbone structure. 用于语义分割和分类的Point Transformer网络中的特征编码器具有五个对点集进行下采样的阶段。每个阶段的下采样速率是[1,4,4,4,4],因此每个阶段后点集中点的数量为[N,N/4,N/16,N/64,N/256],其中N是输入点数。注意,级数和下采样速率可以根据应用而变化,例如构建用于快速处理的轻量主干。连续的阶段由转换模块连接:向下转换用于特征编码,向上转换用于特征解码。
Transition down. 关键功能在于减少点的数量。将输入的点集表示为 P 1 P_1 P1,输出点集为 P 2 P_2 P2。作者在 P 1 P_1 P1中执行最远点采样,来获得分布良好的子集 P 2 ⊂ P 1 P_2 \subset P_1 P2⊂P1。使用 P 1 P_1 P1的kNN图(k=16)将特征向量从 P 1 P_1 P1汇集到 P 2 P_2 P2。每一个输入特征都经过一个线性变换,随后是batch归一化和ReLU,接着是将 P 2 P_2 P2在 P 1 P_1 P1的 k 个邻居最大池化到 P 2 P_2 P2的每个点。Transition down模块如图4(b)所示。
Transition up. 对于密集的预测任务,例如语义分割,作者采用了一种U-net设计,其中上述编码器与对称解码器耦合。解码器中的连续级由Transition up模块连接,主要功能是将来自下采样的输入点集 P 2 P_2 P2的特征映射到其超集 P 1 ⊃ P 2 P_1 \supset P_2 P1⊃P2上。为此,每个输入点都要经过一个线性图层处理,然后进行批量归一化和ReLU,再通过三线性插值将 P 2 P_2 P2特征映射到更高分辨率的点集 P 1 P_1 P1上。来自前一解码器级的这些内插特征通过跳跃连接与来自相应编码器级的特征相结合。Transition up模块的结构如图4©所示。
Output head. 对于语义分割,最终的解码器阶段为输入点集中的每个点生成一个特征向量。再应用MLP将这个特征映射到最终的逻辑。对于分类,我们对逐点特征执行全局平均汇集,以获得整个点集的全局特征向量。这个全局特征通过一个MLP得到全局分类逻辑。
4. Experiments
作者在多个领域和任务中评估了所提出的Point Transformer设计的有效性。对于三维语义分割,使用了具有挑战性的斯坦福大规模三维室内空间数据集(S3DIS) 。对于目标分类,使用广泛采用的ModelNet40数据集。对于语义分割,使用ShapeNetPart。
OA:所有类别的总体准确度。
mAcc:每个类别准确度的平均值。
mIoU:计算所有类别交集和并集之比的平均值.


效果都不错。
消融实验
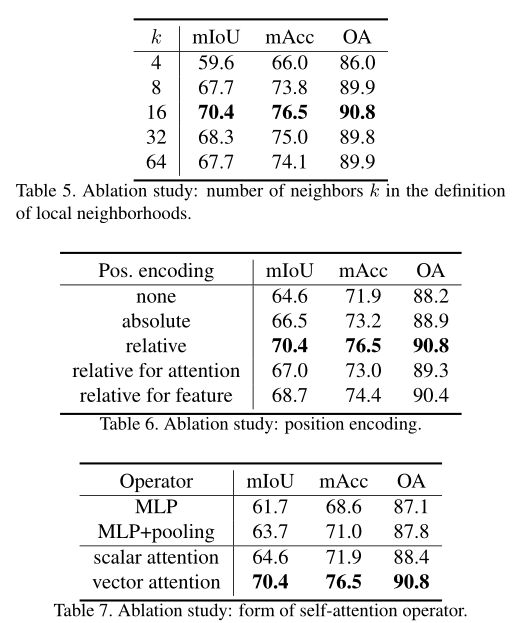
邻居点选择数量:k=16最好,k<16,则邻域较小,环境信息少;k >16,每个自关注层都有大量数据点,引入过多噪声。
Softmax正则化:也就是Eq. 3中的 ρ \rho ρ的必要性,使用Softmax正则化后性能提升显著。
位置编码:使用相对位置编码得到最高的性能,当相对位置编码仅被添加到注意力生成分支时(Eq. 3中的第一项)或仅到特征变换分支(Eq. 3中的第二项),性能再次下降,表明向两个分支添加相对位置编码很重要。
Attention类型:矢量注意力更具表现力,因为它支持单个特征通道的自适应调制,而不仅仅是整个特征向量。这种可表达性在三维数据处理中似乎非常有益。
5.总结
与语言或图像处理相比,Transformer可能更适合点云处理,因为点云本质上是嵌入在度量空间中的集合,Transformer网络核心的self-attention算子基本上是集合算子。除了这种概念兼容性之外,Transformer在点云处理方面非常有效,优于各种的最先进设计:基于图的模型、稀疏卷积网络、连续卷积网络等。Transformer在3D物体检测领域或许也可以有所应用。