【机器学习】05. 聚类分析(代码注释,思路推导)
目录
-
- 资源下载
- 1. KMeans实现聚类
-
- K-Means实现聚类效果图
- 2.分析不同的距离算法带来的影响
-
- 分成4类的效果图
- 分成8类的效果图
- 3.分析不同的K值带来的影响
-
- 效果图
- 4.分析不同的初始簇中心带来的影响
-
- 分析图
- 总结
『机器学习』分享机器学习课程学习笔记,逐步讲述从简单的线性回归、逻辑回归到 ▪ 决策树算法 ▪ 朴素贝叶斯算法 ▪ 支持向量机算法 ▪ 随机森林算法 ▪ 人工神经网络算法 等算法的内容。
欢迎关注 『机器学习』 系列,持续更新中
欢迎关注 『机器学习』 系列,持续更新中
资源下载
拿来即用,所见即所得。
项目仓库:https://gitee.com/miao-zehao/machine-learning/tree/master

1. KMeans实现聚类
题目:基于MATLAB或者Python机器学习库Sklearn,对数据集testSet.txt中包含80个样本的数据实现聚类。
分析:很常规的读取数据然后fit训练即可,只需要注意数据的格式符合要求即可。格式如下:
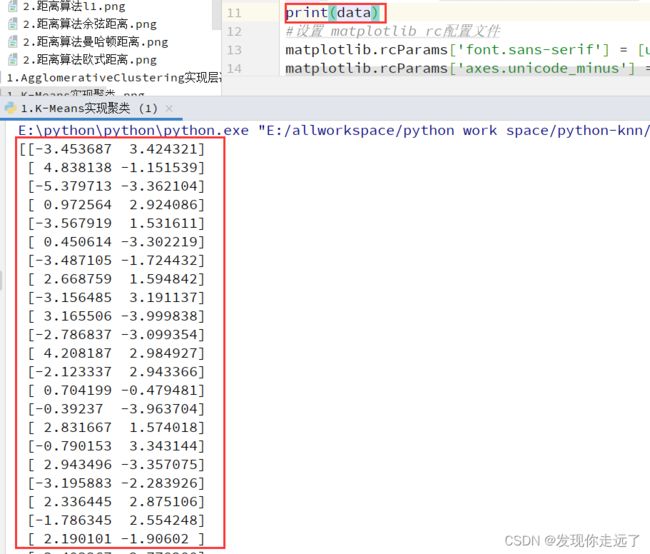
对于函数的详细参数介绍我们在第三节具体介绍,这里就简单的处理一下。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
from sklearn.cluster import KMeans
#读取数据
DFdata=pd.read_csv("testSet.csv")
data=DFdata.values#dataframe数据类型转为列表
# print(data)
#设置 matplotlib rc配置文件
matplotlib.rcParams['font.sans-serif'] = [u'SimHei'] # 用来设置字体样式以正常显示中文标签
matplotlib.rcParams['axes.unicode_minus'] = False # 设置为 Fasle 来解决负号的乱码问题
k = 3 # 假设聚类为 3 类,默认分为 8 个 簇
# 构建算法模型
km = KMeans(n_clusters=k) # n_clusters参数表示分成几个簇(此处k=3)
km.fit(data)
# 获取聚类后样本所属簇的对应编号(label_pred)
label_pred = km.labels_ # labels_属性表示每个点的分簇号,会得到一个关于簇编号的数组
centroids = km.cluster_centers_ #cluster_center 属性用来获取簇的质心点,得到一个关于质心的二维数组,形如[[x1,y1],[x2,y2],[x3,x3]]
# 未聚类前的数据分布图
plt.subplot(121)
plt.scatter(data[:, 0], data[:, 1], s=50)
plt.xlabel('x')
plt.ylabel('y')
plt.title("未聚类之前")
# wspace 两个子图之间保留的空间宽度
plt.subplots_adjust(wspace=0.5) # subplots_adjust()用于调整边距和子图间距
# 聚类后的分布图
plt.subplot(122)
# c:表示颜色和色彩序列,此处与 cmap 颜色映射一起使用(cool是颜色映射值)s表示散点的的大小,marker表示标记样式(散点样式)
plt.scatter(data[:, 0], data[:, 1], c=label_pred, s=50, cmap='cool')
# 绘制质心点
plt.scatter(centroids[:,0],centroids[:,1],c='red',marker='o',s=100)
plt.xlabel('x')
plt.ylabel('y')
plt.title("K-Means算法聚类结果")
plt.savefig("1.K-Means实现聚类.png")
plt.show()
K-Means实现聚类效果图
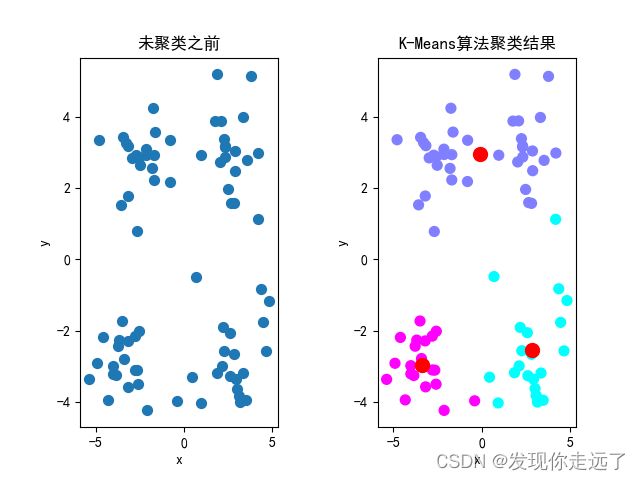
2.分析不同的距离算法带来的影响
题目:2.采用不同的距离算法(曼哈顿距离、欧氏距离、切比雪夫距离、余弦距离)对数据集testSet.txt中包含80个样本的数据实现聚类,设置K=4,同时设置初始的簇中心保持一致;可视化不同的聚类结果。
分析:这里遇到了困难,查阅了相关资料后发现因为
KMeans方法默认使用欧氏距离,切不可修改,没有提供参数修改,所以我使用了AgglomerativeClustering层次聚类法,但是只有曼哈顿距离、欧氏距离、余弦距离而没有切比雪夫距离。
此外,4个距离的模型在分为4类时的效果训练可视化效果居然完全一致·······数据量还是太小,区别不出不同距离方法的区别,所以我后来就改为了分为8类,看到了不同距离方法的效果。
AgglomerativeClustering文档说明
核心函数: km=AgglomerativeClustering(affinity=affinity,compute_full_tree=“auto”,n_clusters=k,linkage=“average”)
- affinity ,默认:“欧几里得”用于计算链接的度量。可以是“euclidean”, “l1”, “l2”, “manhattan”, “cosine”, or ‘precomputed’
样本点之间距离计算方式,可以是euclidean(欧式距离), l1、 l2、manhattan(曼哈顿距离)、cosine(余弦距离)、precomputed(可以预先设定好距离),如果参数linkage选择“ward”的时候只能使用euclidean。 - compute_full_tree bool 或 ‘auto’ (可选)在 n_clusters 处尽早停止树的构建。如果集群的数量与样本数量相比不小,这对于减少计算时间很有用。此选项仅在指定连接矩阵时有用。还要注意,当改变集群的数量并使用缓存时,计算完整的树可能是有利的。
- n_clusters 参数表示分成几个簇整数,默认=2要查找的集群数。
- linkage : {“ward”, “complete”, “average”},可选,默认:“ward” 会导致 affinity只能是euclidean。使用哪个链接标准。链接标准确定在观察集之间使用哪个距离。该算法将合并使该标准最小化的集群对。
- ward 最小化被合并的集群的方差。
- average 平均值使用两组每个观测值的距离平均值。
- complete完整或最大链接使用两组所有观测值之间的最大距离。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
from sklearn.cluster import AgglomerativeClustering
#读取数据
DFdata=pd.read_csv("testSet.csv")
data=DFdata.values#dataframe数据类型转为列表
#设置 matplotlib rc配置文件
matplotlib.rcParams['font.sans-serif'] = [u'SimHei'] # 用来设置字体样式以正常显示中文标签
matplotlib.rcParams['axes.unicode_minus'] = False # 设置为 Fasle 来解决负号的乱码问题
#affinity 距离算法参数
#name 距离算法名字
def myTest(affinity,name):
k = 4 # 假设聚类为 4 类.
k = 8 #4个距离的模型在分为4类时的效果训练可视化效果居然完全一致·······数据量还是太小,区别不出不同距离方法的区别,所以我后来就改为了分为8类,看到了不同距离方法的效果。
# 构建算法模型
km = AgglomerativeClustering(affinity=affinity,compute_full_tree="auto",n_clusters=k,linkage="average")
#- affinity ,默认:“欧几里得”用于计算链接的度量。可以是“euclidean”, “l1”, “l2”, “manhattan”, “cosine”, or ‘precomputed’
#样本点之间距离计算方式,可以是euclidean(欧式距离), l1、 l2、manhattan(曼哈顿距离)、cosine(余弦距离)、precomputed(可以预先设定好距离),如果参数linkage选择“ward”的时候只能使用euclidean。
#- compute_full_tree bool 或 'auto' (可选)在 n_clusters 处尽早停止树的构建。如果集群的数量与样本数量相比不小,这对于减少计算时间很有用。此选项仅在指定连接矩阵时有用。还要注意,当改变集群的数量并使用缓存时,计算完整的树可能是有利的。
#- n_clusters 参数表示分成几个簇整数,默认=2要查找的集群数。
#- linkage : {“ward”, “complete”, “average”},可选,默认:“ward” 会导致 affinity只能是euclidean
#使用哪个链接标准。链接标准确定在观察集之间使用哪个距离。该算法将合并使该标准最小化的集群对。
#- ward 最小化被合并的集群的方差。
#- average 平均值使用两组每个观测值的距离平均值。
#- complete完整或最大链接使用两组所有观测值之间的最大距离。
km.fit(data)
# 获取聚类后样本所属簇的对应编号(label_pred)
label_pred = km.labels_ # labels_属性表示每个点的分簇号,会得到一个关于簇编号的数组
# 未聚类前的数据分布图
plt.subplot(121)
plt.scatter(data[:, 0], data[:, 1], s=50)
plt.xlabel('x')
plt.ylabel('y')
plt.title("未聚类之前")
# wspace 两个子图之间保留的空间宽度
plt.subplots_adjust(wspace=0.5) # subplots_adjust()用于调整边距和子图间距
# 聚类后的分布图
plt.subplot(122)
# c:表示颜色和色彩序列,此处与 cmap 颜色映射一起使用(cool是颜色映射值)s表示散点的的大小,marker表示标记样式(散点样式)
plt.scatter(data[:, 0], data[:, 1], c=label_pred, s=50, cmap='cool')
plt.xlabel('x')
plt.ylabel('y')
plt.title("2.距离算法"+name)
plt.savefig("2/2.距离算法"+name+".png")
plt.show()
myTest("euclidean","欧式距离")
myTest("manhattan","曼哈顿距离")
#切比雪夫距离 没有内置的···用l1代替
myTest("l1","l1")
myTest("cosine","余弦距离")
分成4类的效果图
-
2.距离算法曼哈顿距离

-
2.距离算法欧式距离

-
2.距离算法余弦距离
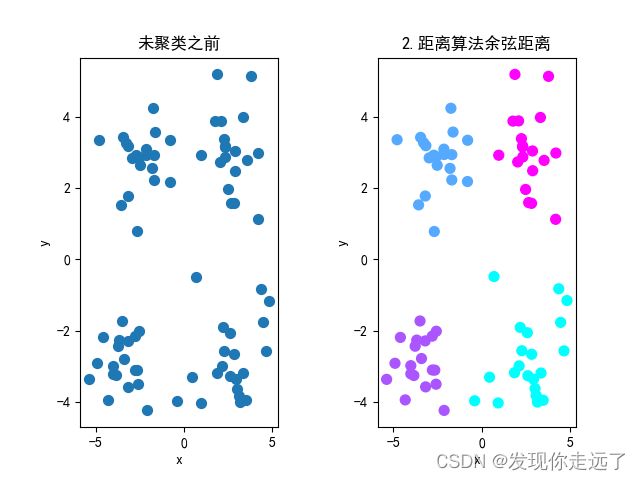
-
2.距离算法l1

分成8类的效果图
-
2.距离算法曼哈顿距离

-
2.距离算法欧式距离

-
2.距离算法余弦距离

-
2.距离算法l1

3.分析不同的K值带来的影响
题目:3.设置初始的簇中心一致,采用不同的K值对数据集进行聚类分析,可视化聚类结果并查看不同的K值对聚类结果的影响。
KMeans文档说明
核心函数:km = KMeans(n_clusters=k,random_state=0)
- n_clusters:int,可选,默认值:8 要形成的簇数以及要生成的质心数。
- max_iter:整数,默认值:300 k - means 算法单次运行的最大迭代次数。
- n_init:整数,默认值:10使用不同质心种子运行 k - means算法的次数。就惯性而言,最终结果将是n_init连续运行的最佳输出。
- init: {‘k-means++’, ‘random’ or an ndarray}初始化方法,默认为’k-means++’ :以智能方式为k - means聚类选择初始聚类中心以加速收敛。
- random_state:整数或 numpy.RandomState,可选用于初始化中心的生成器。如果给出一个整数,它会修复种子。默认为全局 numpy 随机数生成器。详细:int,默认 0
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
from sklearn.cluster import KMeans
#读取数据
DFdata=pd.read_csv("testSet.csv")
data=DFdata.values#dataframe数据类型转为列表
# print(data)
#设置 matplotlib rc配置文件
matplotlib.rcParams['font.sans-serif'] = [u'SimHei'] # 用来设置字体样式以正常显示中文标签
matplotlib.rcParams['axes.unicode_minus'] = False # 设置为 Fasle 来解决负号的乱码问题
k = 3 # 假设聚类为 3 类,默认分为 8 个 簇
def myTest(k):
# 构建算法模型
km = KMeans(n_clusters=k,random_state=0) # n_clusters参数表示分成几个簇(此处k=3)
#- n_clusters:int,可选,默认值:8 要形成的簇数以及要生成的质心数。
#- max_iter:整数,默认值:300 k - means 算法单次运行的最大迭代次数。
#- n_init:整数,默认值:10使用不同质心种子运行 k - means算法的次数。就惯性而言,最终结果将是n_init连续运行的最佳输出。
#- init: {'k-means++', 'random' or an ndarray}初始化方法,默认为'k-means++' :以智能方式为k - means聚类选择初始聚类中心以加速收敛。
#- random_state:整数或 numpy.RandomState,可选用于初始化中心的生成器。如果给出一个整数,它会修复种子。默认为全局 numpy 随机数生成器。详细:int,默认 0
km.fit(data)
# 获取聚类后样本所属簇的对应编号(label_pred)
label_pred = km.labels_ # labels_属性表示每个点的分簇号,会得到一个关于簇编号的数组
centroids = km.cluster_centers_ #cluster_center 属性用来获取簇的质心点,得到一个关于质心的二维数组,形如[[x1,y1],[x2,y2],[x3,x3]]
# 未聚类前的数据分布图
plt.subplot(121)
plt.scatter(data[:, 0], data[:, 1], s=50)
plt.xlabel('x')
plt.ylabel('y')
plt.title("未聚类之前")
# wspace 两个子图之间保留的空间宽度
plt.subplots_adjust(wspace=0.5) # subplots_adjust()用于调整边距和子图间距
# 聚类后的分布图
plt.subplot(122)
# c:表示颜色和色彩序列,此处与 cmap 颜色映射一起使用(cool是颜色映射值)s表示散点的的大小,marker表示标记样式(散点样式)
plt.scatter(data[:, 0], data[:, 1], c=label_pred, s=50, cmap='cool')
# 绘制质心点
plt.scatter(centroids[:,0],centroids[:,1],c='red',marker='o',s=100)
plt.xlabel('x')
plt.ylabel('y')
plt.title("k={} 结果".format(k))
plt.savefig("3/3.分析不同的K值带来的影响k={}.png".format(k))
plt.show()
for k in range(4,9):
myTest(k)
效果图
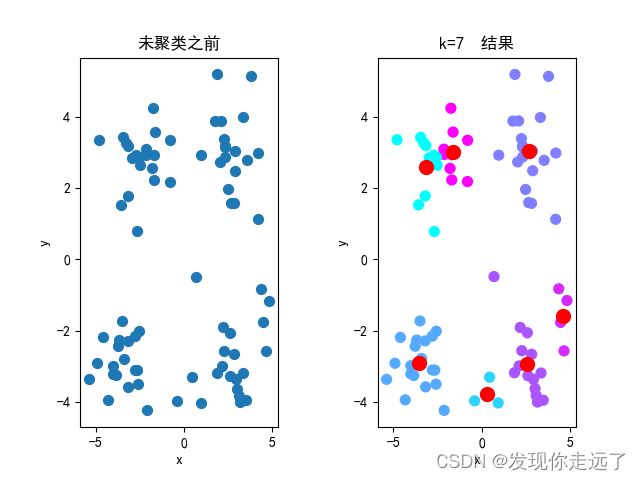



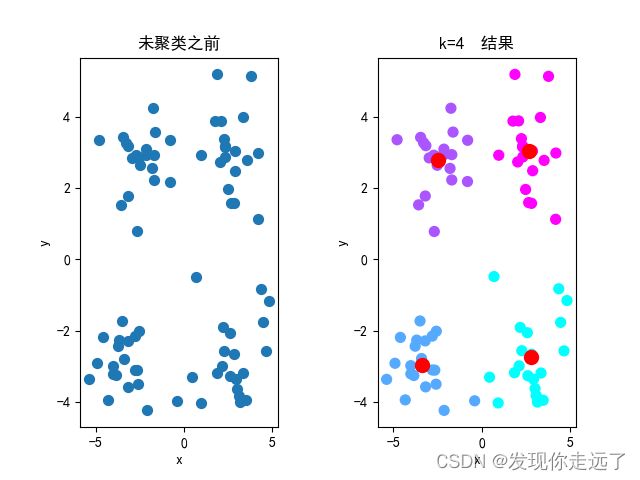
4.分析不同的初始簇中心带来的影响
题目:4.设置K=4,选取不同的初始簇中心进行5次对比实验,可视化每次的聚类结果,观察不同的初始值的选取对聚类效果的影响。
特别注意! init=random random_state设置整数可以初始化中心
- init: 设置为random结合random_state起到初始化中心的作用 {‘k-means++’, ‘random’ or an ndarray}初始化方法,默认为’k-means++’ :以智能方式为k - means聚类选择初始聚类中心以加速收敛。
- random_state:整数或 numpy.RandomState,可选用于初始化中心的生成器。如果给出一个整数,它会修复种子。默认为全局 numpy 随机数生成器。详细:int,默认 0
# @Time : 2022/10/13 21:02
# @Author : 南黎
# @FileName: 4.分析不同的初始簇中心带来的影响.py
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
from sklearn.cluster import KMeans
#读取数据
DFdata=pd.read_csv("testSet.csv")
data=DFdata.values#dataframe数据类型转为列表
# print(data)
#设置 matplotlib rc配置文件
matplotlib.rcParams['font.sans-serif'] = [u'SimHei'] # 用来设置字体样式以正常显示中文标签
matplotlib.rcParams['axes.unicode_minus'] = False # 设置为 Fasle 来解决负号的乱码问题
k = 8 # 假设聚类为 8 类,默认分为 8 个 簇
def myTest(random_state):
# 构建算法模型
km = KMeans(n_clusters=k,init="random",random_state=random_state) # n_clusters参数表示分成几个簇(此处k=3)
# - n_clusters:int,可选,默认值:8 要形成的簇数以及要生成的质心数。
# - max_iter:整数,默认值:300 k - means 算法单次运行的最大迭代次数。
# - n_init:整数,默认值:10使用不同质心种子运行 k - means算法的次数。就惯性而言,最终结果将是n_init连续运行的最佳输出。
# - init: 设置为random结合random_state起到初始化中心的作用 {'k-means++', 'random' or an ndarray}初始化方法,默认为'k-means++' :以智能方式为k - means聚类选择初始聚类中心以加速收敛。
# - random_state:整数或 numpy.RandomState,可选用于初始化中心的生成器。如果给出一个整数,它会修复种子。默认为全局 numpy 随机数生成器。详细:int,默认 0
km.fit(data)
# 获取聚类后样本所属簇的对应编号(label_pred)
label_pred = km.labels_ # labels_属性表示每个点的分簇号,会得到一个关于簇编号的数组
centroids = km.cluster_centers_ #cluster_center 属性用来获取簇的质心点,得到一个关于质心的二维数组,形如[[x1,y1],[x2,y2],[x3,x3]]
# 未聚类前的数据分布图
plt.subplot(121)
plt.scatter(data[:, 0], data[:, 1], s=50)
plt.xlabel('x')
plt.ylabel('y')
plt.title("未聚类之前")
# wspace 两个子图之间保留的空间宽度
plt.subplots_adjust(wspace=0.5) # subplots_adjust()用于调整边距和子图间距
# 聚类后的分布图
plt.subplot(122)
# c:表示颜色和色彩序列,此处与 cmap 颜色映射一起使用(cool是颜色映射值)s表示散点的的大小,marker表示标记样式(散点样式)
plt.scatter(data[:, 0], data[:, 1], c=label_pred, s=50, cmap='cool')
# 绘制质心点
plt.scatter(centroids[:,0],centroids[:,1],c='red',marker='o',s=100)
plt.xlabel('x')
plt.ylabel('y')
plt.title("random_state={} 结果".format(random_state))
plt.savefig("4/4.分析不同的初始簇中心带来的影响random_state={}.png".format(random_state))
plt.show()
for random_state in range(1000,6000,1000):
myTest(random_state)
分析图

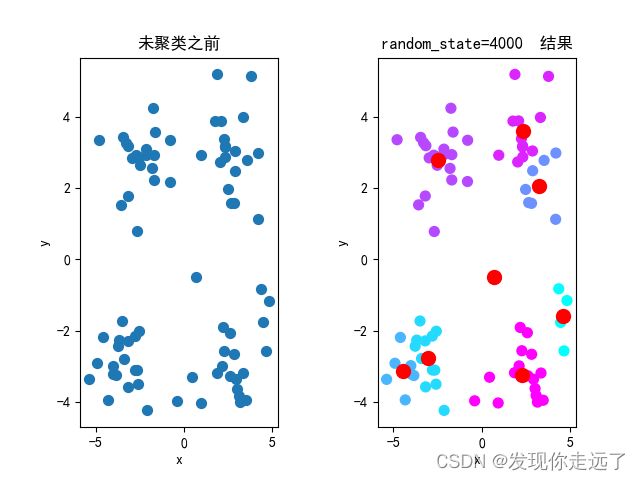
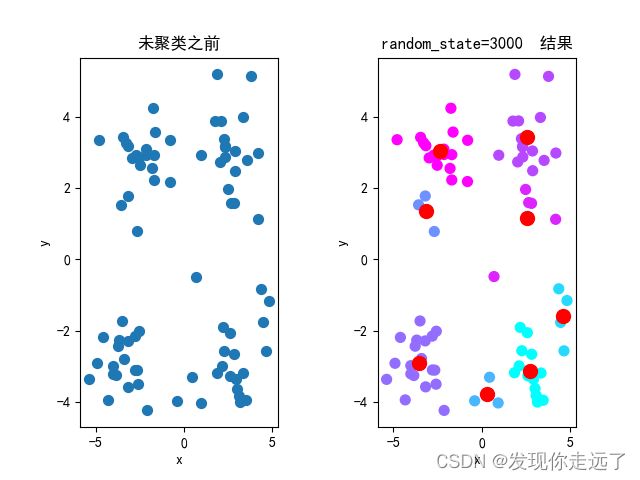
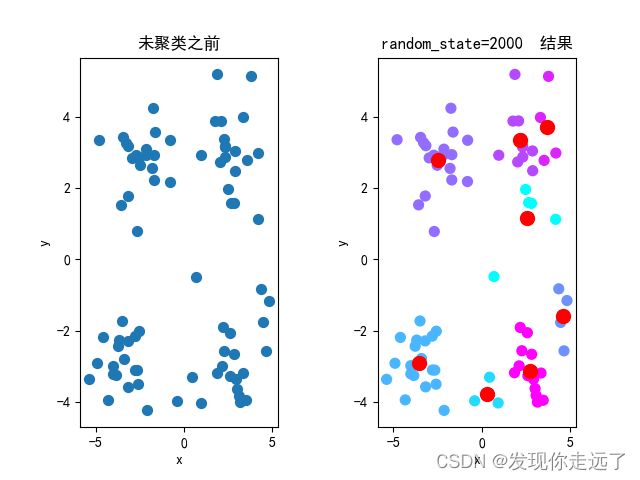

可以很明显的发现质心点发生了明显的偏移变化。(注意,k=8时比较明显,k=4的话完全没有变化,是一模一样的效果)
优点
K-Means聚类算法的优点主要集中在:
1.算法快速、简单;
2.对大数据集有较高的效率并且是可伸缩性的;
3.时间复杂度近于线性,而且适合挖掘大规模数据集。K-Means聚类算法的时间复杂度是O(nkt) ,其中n代表数据集中对象的数量,t代表着算法迭代的次数,k代表着簇的数目
缺点
① 在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的
② 在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果,这也成为 K-means算法的一个主要问题。
③ 从 K-means 算法框架可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。所以需要对算法的时间复杂度进行分析、改进,提高算法应用范围。
总结
大家喜欢的话,给个,点个关注!给大家分享更多有趣好玩的python机器学习知识!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2022 mzh
Crated:2022-9-23
欢迎关注 『机器学习』 系列,持续更新中
欢迎关注 『机器学习』 系列,持续更新中
【机器学习】01. 波士顿房价为例子学习线性回归
【机器学习】02. 使用sklearn库牛顿化、正则化的逻辑回归
【机器学习】03. 支持向量机SVM库进行可视化分类
【更多内容敬请期待】