高阶数据结构 —— 二叉搜索树
文章目录
-
-
- 1. 二叉搜索树的概念
- 2. 二叉搜索树的操作
-
- 2.1 查找操作
- 2.2 插入操作
- 2.3 删除操作
- 2.4 中序遍历
- 3. 非递归二叉搜索树的实现
-
- 3.1 构造函数
- 3.2 查找操作的实现
- 3.3 插入操作
- 3.4 中序遍历
- 3.5 删除操作
- 3.5 非递归版的二叉搜索树代码
- 4.递归版本的搜索二叉树的实现
-
- 4.1 查找操作
- 4.2 插入操作
- 4.3 删除操作
- 4.4 递归实现的总结
- 4.5 递归实现的版本代码
- 5. 二叉搜索树的应用
- 5. 二叉搜索树的性能分析
-
前言:二叉搜索树,是一种效率很高的搜索树,也可以叫做二叉排序树;本章讲解一下,二叉搜索树,相当于二叉树进阶吧,同时也为map和set的学习,打下些基础。
1. 二叉搜索树的概念
- 二叉搜索树的左子树一定小于根节点
- 二叉搜索树的右子树一定大于根节点
- 二叉搜索树的左右子树都是二叉树
这样的结构非常利于我们搜索某个数据,比如:查找某个数据,从根节点开始查找,比根节点大就到右树去查找;比根节点小就到左子树去查找;相当于一个建堆的时间复杂度,就完成了查找。如果是完全二叉树,那么查找的效率就是O(logn);如果不是完全二叉树,最多也就是个O(n)的时间复杂度进行查找。
我可以画个图:
这就是完全二叉搜索树,查找个数据很舒服:

非完全二叉搜索树,查找个数据比较麻烦:

其实对这种情况,是有解决方案的,就是平衡搜索二叉树:AVL树,红黑树。
2. 二叉搜索树的操作
2.1 查找操作
查找一个数据是简单的,如果查找的数据比根节点大,就到右树中找;查找的数据比根节点小,就到左树中找;
找到了就返回 true ,如果找不到就返回 false。
比如:现在要查找 4。

(1) 4<5,所以到左树中找:
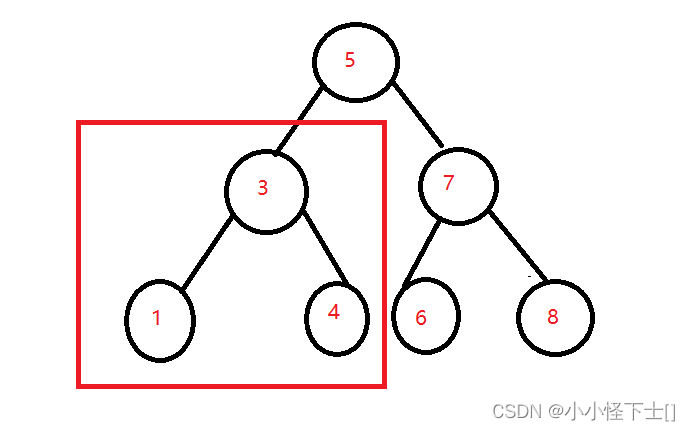
(2) 4>3,所以到右树中找:

(3)4==4,找到了,返回 true。
什么时候找不到呢?等根节点为 空,说明搜索树中没有我们要查找的数据,所以返回 false。
2.2 插入操作
在二叉搜索树中插入操作也相对简单,首先,我要说的是,插入绝对是插入到叶子节点后,它不可能破坏之前二叉搜索树的结构,完成插入,也就是在节点为空时,说明找到了它的位置,然后构造节点,链接好关系,完成插入。当然如果二叉搜索树中已经有了此节点的值,就不会再重复插入了。其次,该如何查找它的位置呢?一样就和上面查找工作差不多,也是从根节点开始,比根节点大插入到右树,比根节点小插入到左树;最后我来举个例子,假如在下面的搜索树中,我要插入 一个节点,节点的数据是 2。

一上来,可能有人说,插到1和3的中间,这样是不可以的,把事情搞复杂了。你就不能插入到1的右边吗?这样才是最简单,最好的操作,而且它也不会破坏之前的二叉搜索树结构:
(1) 2 < 5,所以插入到左树:

(2) 2 < 3,所以插入到左树:

(3) 2>1,所以插入到右树:

但是有人问:1 的右树没有呀?是有的,是空树,而且只有走到空树,我们才可以完成插入。
2.3 删除操作
这个操作才是难的,相对复杂,主要考虑以下三种情况:
- 不带孩子的节点:这个节点真是好删除,只要结束它和父亲节点的链接,将父亲节点指向它的指针置空,最后释放节点就行了。
- 带一个孩子的节点:将这个节点的孩子托付给它的父亲节点,再释放节点,ok了。
- 带两个孩子的节点:这就有点头疼了,因为,不能将两个孩子都托付个父亲节点,父亲节点一般只接收一个孩子的托付,用的方法是替换法。
我们来画图理解:

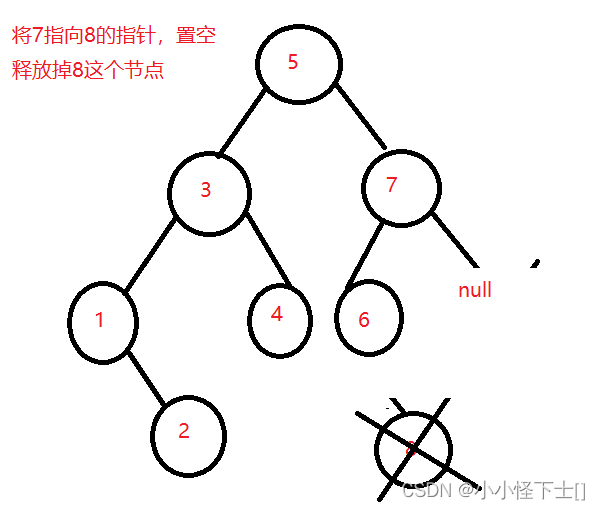
- 不带孩子的节点删除,比如删除掉 8这个节点
- 带一个孩子节点的删除:比如删除掉 1 这个节点

- 删除带俩个孩子的节点: 比如删除根节点
替换法,我们想想:哪个节点可以替换此根节点?左子树的最右节点:左子树的最大节点 || 右子树的最左节点:右子树的最小节点。这俩个节点都是可以替代根节点的。
就看上面那颗树,左子树的最右节点 4 和右子树的最左节点 6,都是可以替换根节点的。假如我使得6 和 5的值交换一下,问题就变成了,到右子树去删除 5 这个节点,也就完成了对根节点 5 的删除。
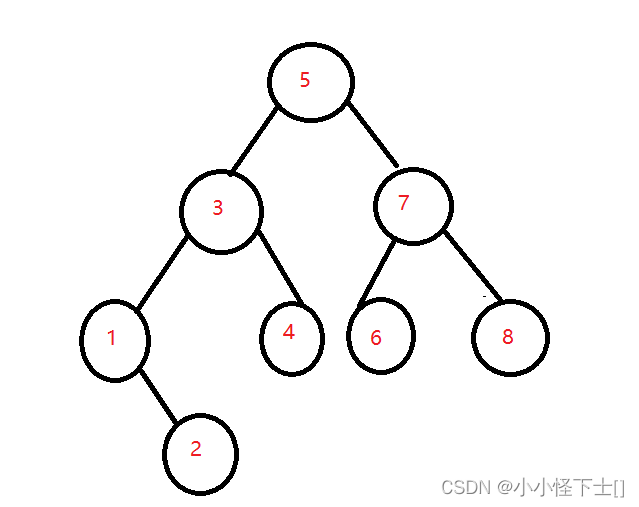
(1) 交换 根节点 和 右树最左节点 的值:

(2) 到右子树中删除,值为5 的最左节点

2.4 中序遍历
中序遍历二叉搜索树,会以排序的方式输出二叉搜索树的值。

中序遍历就是,遍历左子树,然后是根节点,最后是右子树:
所以上面的树打印出来的顺序是: 1 2 3 4 5 6 7 8
所以向二叉搜索树中插入一组数据是可以完成排序+去重的。
3. 非递归二叉搜索树的实现
上面我们讲了二叉搜索树的逻辑,现在我们来进行代码实现:
二叉搜索树的整体框架:
template<class K>
class BSTree
{
typedef BSTreeNode<K> Node;
public:
BSTree();
bool Insert(const K& key);
Node* Find(const K& key);
bool Erase(const K& key);
void _InOrder(Node* root);
void InOrder();
private:
Node* _root;
3.1 构造函数
二叉搜索树,是由一个一个的节点构成的,所以我们先来实现节点这个结构体:
template<class T>
struct BSTreeNode
{
BSTreeNode<T>* left;
BSTreeNode<T>* right;
T val;
BSTreeNode(const T& n=0)
:left(nullptr),
right(nullptr),
val(n)
{
}
};
很明显,在结构体中:有两个指针,分别指向左树节点和右树节点,当然,结构体中也有我们要保存的数据 val。同时我也实现了它的构造函数。
构造函数很简单,只需要给空就好了:
BSTree()
:_root(nullptr)
{
}
3.2 查找操作的实现
bool Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (key > cur->val)
{
cur = cur->right;
}
else if (key < cur->val)
{
cur = cur->left;
}
else
{
return true;
}
}
return false;
}
这代码是好理解的,从根节点开始查找,比根节点大就到右树去查找,比根节点小就到左树去查找,找到了返回true。如果找不到,肯定就cur == null,找到了空树那里,所以停止循环,返回 false。
3.3 插入操作
bool Insert(const K& key)
{
//如果是空树,直接插入
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
// 从根节点遍历,还得记录一下父亲节点,方便后序链接
Node* cur = _root;
Node* father = nullptr;
// 走出循环后,cur就是我们要插入的位置,并且father的位置也找到了
while (cur)
{
if (key > cur->val)
{
father = cur;
cur = cur->right;
}
else if (key < cur->val)
{
father = cur;
cur = cur->left;
}
else
{
return false;
}
}
// 在cur处new一个节点
cur = new Node(key);
// 最后判断一下,是链接都父亲节点的左边还是右边
if (key > father->val)
{
father->right = cur;
}
if (key < father->val)
{
father->left = cur;
}
return true;
}
3.4 中序遍历
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
// 为空就返回
if (root == nullptr)
{
return;
}
//递归其左树
_InOrder(root->left);
//打印根节点
cout << root->val << " ";
// 递归其右树
_InOrder(root->right);
}
上面我写了个私有的子函数 _InOrder(),我们调用的时候,是直接调用InOrder(),但是因为_root根结点是私有的无法访问,所以只能搞个子函数在类中去调用_root。
测试一下以上的代码:可以用中序遍历来测试,我们不是说过吗?中序遍历可以按顺序打印出二叉搜索树。
void test1()
{
int arr[] = { 1,1,3,5,7,8,3,2,67,9 };
BSTree<int> my_tree;
for (auto i : arr)
{
my_tree.Insert(i);
}
my_tree.InOrder();
}
int main()
{
test1();
return 0;
}
我们来看一下运行结果:

说明以上的代码,写的没问题!!!
3.5 删除操作
这有点难懂,同学们注意听了:
上面画图写逻辑中,我说过对于有两个孩子的用替换法删除,但是对于没有孩子和只有一个孩子的删除是简单的,我们先来实现简单情况的删除,循序渐进的完成删除操作:
bool Erase(const K& key)
{
Node* cur = _root;
Node* father = cur;
while (cur)
{
if (key > cur->val)
{
father = cur;
cur = cur->right;
}
else if (key < cur->val)
{
father = cur;
cur = cur->left;
}
else
{
if (cur->left == nullptr)
{
if (cur == father->left)
{
father->left = cur->right;
}
else
{
father->right = cur->right;
}
return true;
}
else if (cur->right == nullptr)
{
if (cur == father->left)
{
father->left = cur->left;
}
else
{
father->right = cur->left;
}
return true;
}
else
{
//有俩孩子
}
}
}
}
我们先要查找需要删除节点的位置,找到后进行判断,判断要删除的节点是否为有一个孩子或者没有孩子。
假如没有左孩子,那么就将其右孩子链接到父亲节点的左边或者右边,这取决于要删除节点在父亲的左边还是右边。画图讲一下:

我现在删除节点 1 ,它的左孩子为空,那么将右孩子 2 链接到父节点的左端,那是因为 1 节点连在父节点的左边;那么我现在要删除节点 8 ,它的左孩子也为空,那么将右孩子 9 链接到 父亲节点的右端,这是取决于删除节点链接到父亲节点的哪一侧。所以还需要判断一下,对吧。
好,现在我们就完成对有两个孩子的节点进行删除。
//有俩孩子
// 先找到其右子树的最左孩子
Node* min = cur->right;
Node* minfather = cur;
while (min->left)
{
minfather = min;
min = min->left;
}
// 使得删除节点值 = 右树最左孩子的值,覆盖一下
cur->val = min->val;
// 现在需要的就是删除右树的最左孩子
if (minfather->left == min)
{
minfather->left = min->right;
}
else
{
minfather->right = min->right;
}
delete min;
return true;
其实删除有两个孩子的节点,也有两种情况:
首先,我先找到右子树的最左节点min,以及最左节点的父亲节点minfather;然后使得要删除的节点的值 = min节点的值;接下来的任务就是删除掉min节点。
然后我画个图讲一下:

(1) 现在我要删除节点 5,找到的右树的最左节点是 6,然后使得 节点 5的值等于 6:
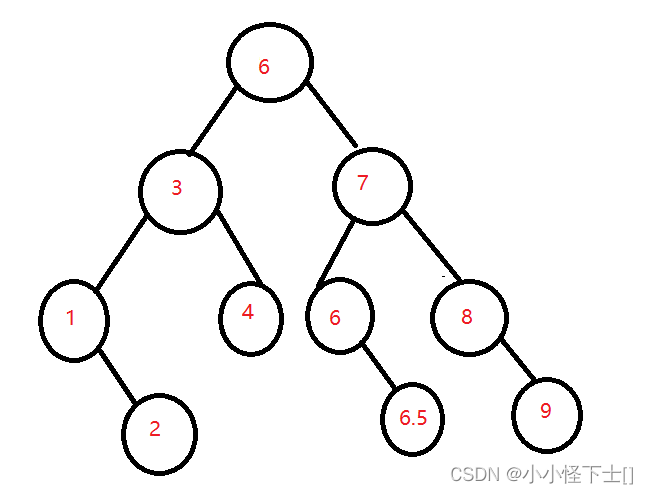
(2) 现在的问题就是删除掉 min节点 6,min结点可能有右孩子,或者没有,但是保险的做法是:父亲节点,指向min节点的右节点,然后释放 min节点:

这种情况是一般情况,但是有一种特殊情况:

现在我要删除节点 7,该怎么办?毫无疑问,找右树的最左节点,但是右树的最左节点没有,我丢,这种情况下,右树的根节点就是所谓的右树的最左节点。替换值之后,是让父亲节点的右指向右数根结点的右。

这两种情况对应得代码是:
if (minfather->left == min)
{
minfather->left = min->right;
}
else
{
minfather->right = min->right;
}
给出删除操作的代码:
bool Erase(const K& key)
{
Node* cur = _root;
Node* father = cur;
while (cur)
{
if (key > cur->val)
{
father = cur;
cur = cur->right;
}
else if (key < cur->val)
{
father = cur;
cur = cur->left;
}
else
{
if (cur->left == nullptr)
{
if (cur == father->left)
{
father->left = cur->right;
}
else
{
father->right = cur->right;
}
delete cur;
return true;
}
else if (cur->right == nullptr)
{
if (cur == father->left)
{
father->left = cur->left;
}
else
{
father->right = cur->left;
}
delete cur;
return true;
}
else
{
//有俩孩子
// 先找到其右子树的最左孩子
Node* min = cur->right;
Node* minfather = cur;
while (min->left)
{
minfather = min;
min = min->left;
}
// 使得删除节点值 = 右树最左孩子的值,覆盖一下
cur->val = min->val;
// 现在需要的就是删除右树的最左孩子
if (minfather->left == min)
{
minfather->left = min->right;
}
else
{
minfather->right = min->right;
}
delete min;
return true;
}
}
}
return false;
}
3.5 非递归版的二叉搜索树代码
#include4.递归版本的搜索二叉树的实现
上面的inorder(),就是递归实现,中序遍历嘛。接下来实现的递归版本,代码量少了点,理解也好理解,有点巧妙之处,需要好好研究一下。先说明一下,因为要访问根节点,所以我们都实现一个子函数去访问根结点,在类外,我们调用的是函数。
4.1 查找操作
public:
Node* FindR(const K& key)
{
return _FindR(key, _root);
}
private:
Node* _FindR(const K& key, Node* root)
{
if (root == nullptr)
{
return nullptr;
}
if (key > root->val)
{
return _FindR(key, root->right);
}
else if(key <root->val)
{
return _FindR(key, root->left);
}
else
{
return root;
}
}
我这个查找操作返回的是,节点的指针。
4.2 插入操作
bool _insertR(const K& key, Node* &root)
{
if (root == nullptr)
{
root = new Node(key);
return true;
}
if (key > root->val)
return _insertR(key, root->right);
else if (key < root->val)
return _insertR(key, root->left);
else
return false;
}
看到那个参数了吗?Node*& root这是关键点。
我直接画递归展开图:
在下面的搜索二叉树中插入 9 。

(1)

(2)

(3)

(4) 关键点来了

走到这,我们就应该要进行插入了,现在的root是空,同时它也是 8 节点的右子树的引用。所以我直接就可以在这个位置root,new一个Node,根本不用我们去链接,因为它是 8 节点的右树的引用,已经链接好了。
灰常的巧妙,利用引用完成了此操作。
4.3 删除操作
public:
bool eraseR(const K& key)
{
return _eraseR(key,_root);
}
private:
bool _eraseR(const K& key,Node*& root)
{
if (root == nullptr)
{
return false;
}
if (key > root->val)
{
return _eraseR(key, root->right);
}
else if (key < root->val)
{
return _eraseR(key, root->left);
}
else
{
Node* del = root;
找到了开始删除
if (root->left == nullptr)
{
root = root->right;
}
else if (root->right == nullptr)
{
root = root->left;
}
else
{
Node* min = root->right;
while (min->left)
{
min = min->left;
}
swap(root->val, min->val);
return _eraseR(root->right, key);
}
delete del;
return true;
}
}
找到了,就开始删除,此时的root就是要删除的节点,同时这个root也是它父亲节点的左指针或者右指针的引用。
- 如果 root的左子树为空,那么就 root = root -> right;
- 如果 root的右子树为空,那么就 root = root -> left;
这两句代码就可以处理删除中的简单情况,为什么呢?
root是父节点的左子树或者右子树的指针引用,我不需要进行链接操作,直接让它指向 -> root可能不为空的一边就可以了,也就是root = root -> 可能不为空的一边
- 如果root的左右子树都不为空,那么依旧需要找右子树的最左节点,这逃不掉
找了之后,将min的值和root的值,交换一下,这样我们要删除的root值就成了root右子树的最左节点的值,因为交换了值嘛,递归删除操作是可以控制根节点的,所以我们只需要去root的右子树去删除key就可以了,而且想嘛,右树的最左节点,很好删除。
Node* min = root->right;
while (min->left)
{
min = min->left;
}
swap(root->val, min->val);
return _eraseR(root->right, key);
4.4 递归实现的总结
递归实现:
- 首先,搞了子函数和函数,这是为了能够使用到根节点
- 其次,代码逻辑相对简单,不用考虑那么多的特殊情况
- 最后,递归实现,非常舒服了使用了
引用,这使得我们不用去手动的链接了
4.5 递归实现的版本代码
template<class K>
class BSTree
{
typedef BSTreeNode<K> Node;
public:
BSTree()
:_root(nullptr)
{
}
Node* FindR(const K& key)
{
return _FindR(key, _root);
}
bool insertR(const K& key)
{
return _insertR(key, _root);
}
void InOrder()
{
_InOrder(_root);
cout << endl;
}
bool eraseR(const K& key)
{
return _eraseR(key,_root);
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->left);
cout << root->val << " ";
_InOrder(root->right);
}
bool _eraseR(const K& key,Node*& root)
{
if (root == nullptr)
{
return false;
}
if (key > root->val)
{
return _eraseR(key, root->right);
}
else if (key < root->val)
{
return _eraseR(key, root->left);
}
else
{
Node* del = root;
找到了开始删除
if (root->left == nullptr)
{
root = root->right;
}
else if (root->right == nullptr)
{
root = root->left;
}
else
{
Node* min = root->right;
while (min->left)
{
min = min->left;
}
swap(root->val, min->val);
_eraseR(root->right, key);
}
delete del;
return true;
}
}
Node* _FindR(const K& key, Node* root)
{
if (root == nullptr)
{
return nullptr;
}
if (key > root->val)
{
return _FindR(key, root->right);
}
else if(key <root->val)
{
return _FindR(key, root->left);
}
else
{
return root;
}
}
bool _insertR(const K& key, Node* &root)
{
if (root == nullptr)
{
root = new Node(key);
return true;
}
if (key > root->val)
return _insertR(key, root->right);
else if (key < root->val)
return _insertR(key, root->left);
else
return false;
}
private:
Node* _root;
};
5. 二叉搜索树的应用
- 可以用于数据的排序+去重,这是好理解的,将一组数据,插入到二叉搜索树中,再以中序遍历方式,打印出来,就完成了数据的排序+去重
- 搜索功能:
- key模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。之后set会好好将这个。
举例说明:往二叉搜索树中,存一种数据,比如学号,只要多一个学生,就存一个学号。那么在教务管理系统中,查找是否有此学号的学生,也是很快的。
- key - val模型 :每一个关键码key,都有与之对应的值Value,即
举例说明:字典中的英汉互译,我查一个苹果,然后对应的是 apple,等;这种有对应关系的,无非是在二叉搜索树的节点中多存一个数据而已,别说是两两对应了,就算是n个互相对应,也能搞出来,只需要在节点里塞数据类型就行了。
5. 二叉搜索树的性能分析

-
最优情况下,二叉搜索树为完全二叉树,其平均比较次数为:logn
-
最差情况下,二叉搜索树退化为单支树,其平均比较次数为:n/2
该怎么解决最差情况?后面讲到AVL树,红黑树会给出答案。
结尾语: 以上就是本章内容,有问题,评论私信,觉得有帮助的朋友,可以点个赞支持一下哦!!!