机器学习中SGD等优化算法总结+BN原理和作用+ROC、F1等度量分类性能指标+Bagging、Boosting小结+进制转换
Date: 2019-08-07
接下来总结一下昨天遇到的有点小迷糊的遗留问题,所有的知识点标题已在标题中出现,具体目录如下:
part 1: 机器学习中的SGD + MGD + BGD + Monentum + Adagrad + Rmsprop + Adam的小结和优缺点对比
part2 : 机器学习(深度神经网络)中的BN原理和作用
part3: 机器学习中的分类性能度量指标:ROC曲线 + AUC值 + P值 + R值 + F1值的小结
part4 : Bagging 和Boosting的 小结,主要针对Bagging降低方差(减少过拟合),Boosting降低偏差(减少欠拟合)
part5: 进制转换
CONTENTS:
Part 1: 机器学习中的SGD + MGD + BGD + Monentum + Adagrad + Rmsprop + Adam的小结和优缺点对比
*** Stochastic Gradient Descent(SGD)
和批梯度下降算法相反,Stochastic gradient descent 算法每读入一个数据,便立刻计算cost fuction的梯度来更新参数:
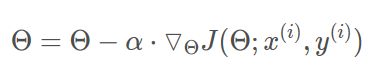
优点:
算法收敛速度快(在Batch Gradient Descent算法中, 每轮会计算很多相似样本的梯度, 这部分是冗余的)
可以在线更新
有几率跳出一个比较差的局部最优而收敛到一个更好的局部最优甚至是全局最优
缺点:
容易收敛到局部最优,并且容易被困在鞍点
*** Mini-batch Gradient Descent(MGD)
mini-batch Gradient Descent的方法是在上述两个方法中取折衷, 每次从所有训练数据中取一个子集(mini-batch) 用于计算梯度:

优点: Mini-batch Gradient Descent在每轮迭代中仅仅计算一个mini-batch的梯度,不仅计算效率高,而且收敛较为稳定。该方法是目前深度学训练中的主流方法
上述三个方法面临的主要挑战如下:
选择适当的学习率α 较为困难。太小的学习率会导致收敛缓慢,而学习速度太块会造成较大波动,妨碍收敛。
目前可采用的方法是在训练过程中调整学习率大小,例如模拟退火算法:预先定义一个迭代次数m,每执行完m次训练便减小学习率,或者当cost function的值低于一个阈值时减小学习率。然而迭代次数和阈值必须事先定义,因此无法适应数据集的特点。
上述方法中, 每个参数的 learning rate 都是相同的,这种做法是不合理的:如果训练数据是稀疏的,并且不同特征的出现频率差异较大,那么比较合理的做法是对于出现频率低的特征设置较大的学习速率,对于出现频率较大的特征数据设置较小的学习速率。
近期的的研究表明,深层神经网络之所以比较难训练,并不是因为容易进入local minimum。相反,由于网络结构非常复杂,在绝大多数情况下即使是 local minimum 也可以得到非常好的结果。而之所以难训练是因为学习过程容易陷入到马鞍面中,即在坡面上,一部分点是上升的,一部分点是下降的。而这种情况比较容易出现在平坦区域,在这种区域中,所有方向的梯度值都几乎是 0。
*** Batch Gradient Descent(BGD)
在每一轮的训练过程中,Batch Gradient Descent算法用整个训练集的数据计算cost fuction的梯度,并用该梯度对模型参数进行更新:
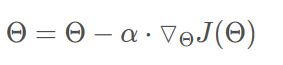
优点:
cost fuction若为凸函数,能够保证收敛到全局最优值;若为非凸函数,能够收敛到局部最优值
缺点:
由于每轮迭代都需要在整个数据集上计算一次,所以批量梯度下降可能非常慢
训练数较多时,需要较大内存
批量梯度下降不允许在线更新模型,例如新增实例。
*** Momentum(引入一阶动量,梯度的一阶矩估计)
SGD方法的一个缺点是其更新方向完全依赖于当前batch计算出的梯度,因而十分不稳定。Momentum算法借用了物理中的动量概念,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力:

Momentum算法会观察历史梯度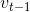 ,若当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度,若当前梯度与历史梯方向不一致,则梯度会衰减。**一种形象的解释是:**我们把一个球推下山,球在下坡时积聚动量,在途中变得越来越快,γ可视为空气阻力,若球的方向发生变化,则动量会衰减。
,若当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度,若当前梯度与历史梯方向不一致,则梯度会衰减。**一种形象的解释是:**我们把一个球推下山,球在下坡时积聚动量,在途中变得越来越快,γ可视为空气阻力,若球的方向发生变化,则动量会衰减。
*** Adagrad (自适应学习率引入的开始)
上述方法中,对于每一个参数![]()
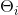 的训练都使用了相同的学习率α。Adagrad算法能够在训练中自动的对learning rate进行调整,对于出现频率较低参数采用较大的α更新;相反,对于出现频率较高的参数采用较小的α更新。因此,Adagrad非常适合处理稀疏数据。
的训练都使用了相同的学习率α。Adagrad算法能够在训练中自动的对learning rate进行调整,对于出现频率较低参数采用较大的α更新;相反,对于出现频率较高的参数采用较小的α更新。因此,Adagrad非常适合处理稀疏数据。
我们设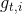 为第t轮第i个参数的梯度,即
为第t轮第i个参数的梯度,即![]() 。因此,SGD中参数更新的过程可写为:
。因此,SGD中参数更新的过程可写为:

Adagrad在每轮训练中对每个参数θiθi θ_iθi的学习率进行更新,参数更新公式如下:
![]()
其中,![]() 为对角矩阵,每个对角线位置i为对应参数从第1轮到第t轮梯度的平方和。ϵ是平滑项,用于避免分母为0,一般取值1e−8。Adagrad的缺点是在训练的中后期,分母上梯度平方的累加将会越来越大,从而梯度趋近于0,使得训练提前结束。
为对角矩阵,每个对角线位置i为对应参数从第1轮到第t轮梯度的平方和。ϵ是平滑项,用于避免分母为0,一般取值1e−8。Adagrad的缺点是在训练的中后期,分母上梯度平方的累加将会越来越大,从而梯度趋近于0,使得训练提前结束。
RMSprop(引入二阶动量,梯度的二阶矩估计)
RMSprop是Geoff Hinton提出的一种自适应学习率方法。Adagrad会累加之前所有的梯度平方,而RMSprop仅仅是计算对应的平均值,因此可缓解Adagrad算法学习率下降较快的问题。
![]()
![\Theta_{t+1} =\Theta_{t}- \frac{\alpha}{\sqrt{E[g^2]_t+\epsilon }}\cdot g_{t}](http://img.e-com-net.com/image/info8/77bb7113aea24429b5b6cd491b40f677.gif)
*** Adam(momentum 和rmsprop的结合,结合了一阶矩估计和二阶矩估计)
Adam(Adaptive Moment Estimation)是另一种自适应学习率的方法。它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。公式如下:
![]() (from momentum)
(from momentum)
![]() (from rmsprop)
(from rmsprop)
![]()
![]()
![]()
其中, ,
, 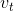 分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望
分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望 ![]() 2]的近似;
2]的近似; 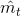 ,
, 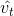 是
是 ![]() 的校正,这样可以近似为对期望的无偏估计。 Adam算法的提出者建议
的校正,这样可以近似为对期望的无偏估计。 Adam算法的提出者建议 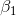 的默认值为0.9,
的默认值为0.9,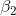 的默认值为.999,默认为
的默认值为.999,默认为 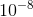 。 另外,在数据比较稀疏的时候,adaptive的方法能得到更好的效果,例如Adagrad,RMSprop, Adam 等。Adam 方法也会比 RMSprop方法收敛的结果要好一些, 所以在实际应用中 ,Adam为最常用的方法,可以比较快地得到一个预估结果。
。 另外,在数据比较稀疏的时候,adaptive的方法能得到更好的效果,例如Adagrad,RMSprop, Adam 等。Adam 方法也会比 RMSprop方法收敛的结果要好一些, 所以在实际应用中 ,Adam为最常用的方法,可以比较快地得到一个预估结果。
自适应学习率的方法有: Adagrad + Rpmsprop + Adam
part2 : 机器学习(深度神经网络)中的BN原理和作用
1. BN概念
传统的神经网络,只是在将样本x输入输入层之前对x进行标准化处理,以降低样本间的差异性。BN是在此基础上,不仅仅只对输入层的输入数据x进行标准化,还对每个隐藏层的输入进行标准化。
(那为什么需要对每个隐藏层的输入进行标准化呢?或者说这样做有什么好处呢?这就牵涉到一个Covariate Shift问题)
2. Covariate Shift问题 (BN引入的原理)
Convariate shift是BN论文作者提出来的概念,指的是具有不同分布的输入值对深度网络学习的影响。当神经网络的输入值的分布不同是,我们可以理解为输入特征值的scale差异较大,与权重进行矩阵相乘后,会产生一些偏离较大地差异值;而深度学习网络需要通过训练不断更新完善,那么差异值产生的些许变化都会深深影响后层,偏离越大表现越为明显;因此,对于反向传播来说,这些现象都会导致梯度发散,从而需要更多的训练步骤来抵消scale不同带来的影响,也就是说,这种分布不一致将减缓训练速度。
而BN的作用就是将这些输入值进行标准化,降低scale的差异至同一个范围内。这样做的好处在于一方面提高梯度的收敛程度,加快模型的训练速度;另一方面使得每一层可以尽量面对同一特征分布的输入值,减少了变化带来的不确定性,也降低了对后层网路的影响,各层网路变得相对独立,缓解了训练中的梯度消失问题。
(因此总结起来,BN的作用主要有)
3. BN的作用
** 缓解DNN训练中的梯度消失问题
** 加快模型的训练速度
4. 公式
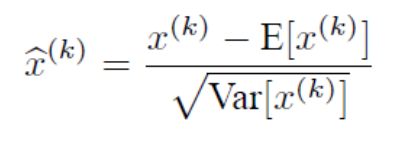
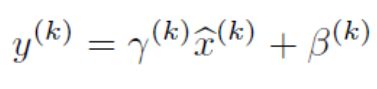
其中,第一式是白化预处理,减期望,除以标准差。在此基础上引入两个超参数进行微调,整体就是BN的公式,
part3: 机器学习中的分类性能度量指标:ROC曲线 + AUC值 + P值 + R值 + F1值的小结
经典二分类问题常用到的分类度量指标有以上五种方法:

1. ROC曲线
ROC曲线的横坐标是FPR,纵坐标是TPR。(两个都是从上表中的纵轴维度进行的刻画)
* TPR:在所有实际为阳性的样本中,被正确地判断为阳性之比率。![]() (有病样本中有多少样本被正确诊断为有病)
(有病样本中有多少样本被正确诊断为有病)
* FPR:在所有实际为阴性的样本中,被错误地判断为阳性之比率。![]() (无病样本中有多少样本被误诊为有病)
(无病样本中有多少样本被误诊为有病)
根据实际情况来看,TPR越大越好,FPR越小越好(即,TPR=1,FPR=0,ROC曲线左上方),注:ROC曲线上每一个点是每一个阈值的分类的TPR 和FPR。
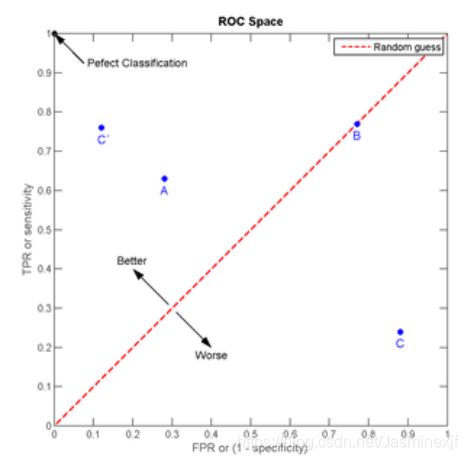
- 横坐标:1-Specificity,伪正类率(False positive rate, FPR),预测为正但实际为负的样本占所有负例样本 的比例;
- 纵坐标:Sensitivity,真正类率(True positive rate, TPR),预测为正且实际为正的样本占所有正例样本 的比例。
2. AUC值
2.1AUC值的定义
AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
2.2AUC值的物理意义
假设分类器的输出是样本属于正类的socre(置信度),则AUC的物理意义为,任取一对(正、负)样本,正样本的score大于负样本的score的概率。
2.3AUC值的计算
(1)第一种方法:AUC为ROC曲线下的面积,那我们直接计算面积可得。面积为一个个小的梯形面积之和,计算的精度与阈值的精度有关。
(2)第二种方法:根据AUC的物理意义,我们计算正样本score大于负样本的score的概率。取N*M(N为正样本数,M为负样本数)个二元组,比较score,最后得到AUC。时间复杂度为O(N*M)。
(3)第三种方法:与第二种方法相似,直接计算正样本score大于负样本的score的概率。我们首先把所有样本按照score排序,依次用rank表示他们,如最大score的样本,rank=n(n=N+M),其次为n-1。那么对于正样本中rank最大的样本(rank_max),有M-1个其他正样本比他score小,那么就有(rank_max-1)-(M-1)个负样本比他score小。其次为(rank_second-1)-(M-2)。最后我们得到正样本大于负样本的概率为:
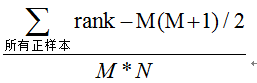
3. P R F1
P (Precision) = ![]() (精确度: 预测为有病中的样本中,到底有多少是真正有病的样本)
(精确度: 预测为有病中的样本中,到底有多少是真正有病的样本)
R (Recall) = ![]() (召回率:真实有病样本中,有多少样本是被真正预测为有病)
(召回率:真实有病样本中,有多少样本是被真正预测为有病)
F1-Score = ![]() (综合PR的结果,进行的综合评估)
(综合PR的结果,进行的综合评估)
4.为什么使用ROC曲线(对于类别不均衡问题的稳定性)
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。下图是ROC曲线和Precision-Recall曲线的对比:

在上图中,(a)和(c)为ROC曲线,(b)和(d)为Precision-Recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)和(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果。可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线则变化较大。
part4 : Bagging 和Boosting的 小结,主要针对Bagging降低方差(减少过拟合),Boosting降低偏差(减少欠拟合)
机器学习中集成学习有两个重要的方法:Bagging和Boosting.
* Bagging: 算法构建多个分类器,每个分类器都随机从原样本中做有放回的抽样,利用这些采样后的样本训练该分类器,然后将这些分类器构成一个更强效果的组合分类器,最后的分类类别决策采用vote原则等可以决定。代表:Ramdom Forest.
* Boosting: 算法通过构建迭代一系列分类器,每次分类都将上一次分错的数据权重提高一点,再进行下一次分类器的分类。这样最终得到的分类器在测试数据与训练数据上效果都很好。代表:AdaBoost, GDBT,XGBoost, LightGBM,GatBoost.
机器学习调参的目标是:在bias和variance之间做均衡(权衡)
*** Bagging:并行训练很多分类器:降低方差(但每个分类器必须保证:低偏差(不会出现高偏差:欠拟合的状态))
*** Boosting: 在每一轮基础上不断修正的目的:降低偏差(但每个基分类器必须保证低方差(不会出现高方差,过拟合的状态))。
part5: 进制转换
进制主要有:二进制(Binary)、八进制(Octal)、十进制(Decimal)、十六进制(Hexadecimal string)。则进制之间的转换就是这四者之间的转换。下面主要谈及:二/八/十六进制 ——> 十进制数的转换;十进制 ——>二/八/十六进制
(一) (二、八、十六进制) → (十进制)
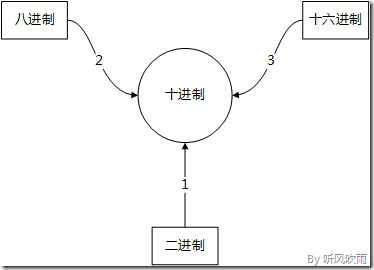
(Figure2:其他进制转换为十进制)
- 二进制 → 十进制
方法:二进制数从低位到高位(即从右往左)计算,第0位的权值是2的0次方,第1位的权值是2的1次方,第2位的权值是2的2次方,依次递增下去,把最后的结果相加的值就是十进制的值了。
例:将二进制的(101011)B转换为十进制的步骤如下:
1. 第0位 1 x 2^0 = 1;
2. 第1位 1 x 2^1 = 2;
3. 第2位 0 x 2^2 = 0;
4. 第3位 1 x 2^3 = 8;
5. 第4位 0 x 2^4 = 0;
6. 第5位 1 x 2^5 = 32;
7. 读数,把结果值相加,1+2+0+8+0+32=43,即(101011)B=(43)D。
- 八进制 → 十进制
方法:八进制数从低位到高位(即从右往左)计算,第0位的权值是8的0次方,第1位的权值是8的1次方,第2位的权值是8的2次方,依次递增下去,把最后的结果相加的值就是十进制的值了。
八进制就是逢8进1,八进制数采用 0~7这八数来表达一个数。
例:将八进制的(53)O转换为十进制的步骤如下:
1. 第0位 3 x 8^0 = 3;
2. 第1位 5 x 8^1 = 40;
3. 读数,把结果值相加,3+40=43,即(53)O=(43)D。
- 十六进制 → 十进制
方法:十六进制数从低位到高位(即从右往左)计算,第0位的权值是16的0次方,第1位的权值是16的1次方,第2位的权值是16的2次方,依次递增下去,把最后的结果相加的值就是十进制的值了。
十六进制就是逢16进1,十六进制的16个数为0123456789ABCDEF。
例:将十六进制的(2B)H转换为十进制的步骤如下:
1. 第0位 B x 16^0 = 11;
2. 第1位 2 x 16^1 = 32;
3. 读数,把结果值相加,11+32=43,即(2B)H=(43)D。
(二) (十进制) → (二、八、十六进制) (除2/8/16取余法)
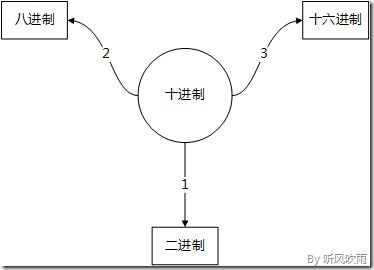
(Figure3:十进制转换为其它进制)
- 十进制 → 二进制
方法:除2取余法,即每次将整数部分除以2,余数为该位权上的数,而商继续除以2,余数又为上一个位权上的数,这个步骤一直持续下去,直到商为0为止,最后读数时候,从最后一个余数读起,一直到最前面的一个余数。
例:将十进制的(43)D转换为二进制的步骤如下:
1. 将商43除以2,商21余数为1;
2. 将商21除以2,商10余数为1;
3. 将商10除以2,商5余数为0;
4. 将商5除以2,商2余数为1;
5. 将商2除以2,商1余数为0;
6. 将商1除以2,商0余数为1;
7. 读数,因为最后一位是经过多次除以2才得到的,因此它是最高位,读数字从最后的余数向前读,101011,即(43)D=(101011)B。

(Figure4:图解十进制 → 二进制)
- 十进制 → 八进制
方法1:除8取余法,即每次将整数部分除以8,余数为该位权上的数,而商继续除以8,余数又为上一个位权上的数,这个步骤一直持续下去,直到商为0为止,最后读数时候,从最后一个余数起,一直到最前面的一个余数。
例:将十进制的(796)D转换为八进制的步骤如下:
1. 将商796除以8,商99余数为4;
2. 将商99除以8,商12余数为3;
3. 将商12除以8,商1余数为4;
4. 将商1除以8,商0余数为1;
5. 读数,因为最后一位是经过多次除以8才得到的,因此它是最高位,读数字从最后的余数向前读,1434,即(796)D=(1434)O。

(Figure5:图解十进制 → 八进制)
方法2:使用间接法,先将十进制转换成二进制,然后将二进制又转换成八进制;
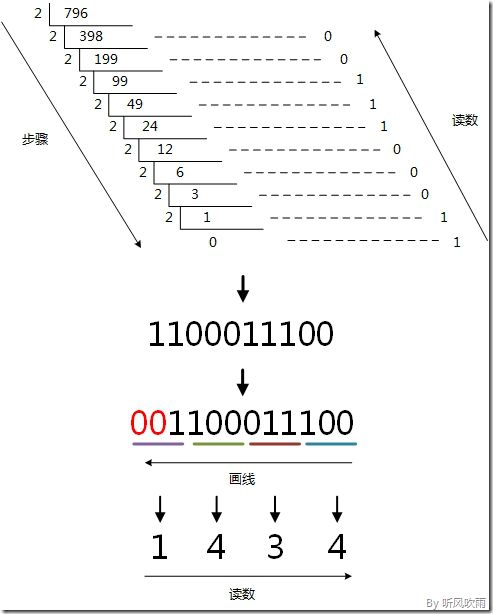
(Figure6:图解十进制 → 八进制)
- 十进制 → 十六进制
方法1:除16取余法,即每次将整数部分除以16,余数为该位权上的数,而商继续除以16,余数又为上一个位权上的数,这个步骤一直持续下去,直到商为0为止,最后读数时候,从最后一个余数起,一直到最前面的一个余数。
例:将十进制的(796)D转换为十六进制的步骤如下:
1. 将商796除以16,商49余数为12,对应十六进制的C;
2. 将商49除以16,商3余数为1;
3. 将商3除以16,商0余数为3;
4. 读数,因为最后一位是经过多次除以16才得到的,因此它是最高位,读数字从最后的余数向前读,31C,即(796)D=(31C)H。

(Figure7:图解十进制 → 十六进制)
方法2:使用间接法,先将十进制转换成二进制,然后将二进制又转换成十六进制;

(Figure8:图解十进制 → 十六进制)
其他进制之间的转换可以通过十进制来进行转换。
另外在python中有相应的内置函数直接实现相互的转换:
十进制——> 二进制: bin(x), 转换后的二进制数中带有前缀0b |||二进制——>十进制:int('binary string',2)
十进制 ——> 八进制:oct(x),转换后的八进制数中带有前缀0o |||八进制——>十进制: int('octal string',8)
十进制 ——>十六进制:hex(x),转换后的十六进制数中带有前缀0x |||十六进制——>十进制:int('hexadecial string',16)
| ↓ | 2进制 | 8进制 | 10进制 | 16进制 |
| 2进制 | - | bin(int(x, 8)) | bin(int(x, 10)) | bin(int(x, 16)) |
| 8进制 | oct(int(x, 2)) | - | oct(int(x, 10)) | oct(int(x, 16)) |
| 10进制 | int(x, 2) | int(x, 8) | - | int(x, 16) |
| 16进制 | hex(int(x, 2)) | hex(int(x, 8)) | hex(int(x, 10)) | - |