详解预处理指令(#define)
️作者:@malloc不出对象
⛺专栏:《初识C语言》
个人简介:一名双非本科院校大二在读的科班编程菜鸟,努力编程只为赶上各位大佬的步伐

目录
- 前言
- 预定义符号
- 详解#define的用法
-
- #define定义标识符
- #define定义宏
-
- 常见错误
- 带副作用的宏参数
- #的用法
- ##的用法
- 宏和函数的对比
前言
今天我们要来学习的是预处理部分,我们将着重讲解预处理指令#define的用法以及注意事项。今天的文章内容不那么复杂相信读者认真仔细一点就能完全掌握啦
预定义符号
在C语言中我们有一些内置的预定义符号,我们一起来了解一下。
__FILE__ //进行编译的源文件
__LINE__ //文件当前的行号
__DATE__ //文件被编译的日期
__TIME__ //文件被编译的时间
__STDC__ //如果编译器遵循ANSI C,其值为1,否则未定义
通过下图我们来了解一下它的基本用法:

细心的朋友已经发现了我将最后一行的printf注释掉了,为什么呢?因为在VS中不遵循ANSI C的标准,所以我们的编译器是无法识别它的,如下图:

但是Linux环境gcc编译器是遵守ANSI C的标准的,下面我们来一起看看:

我们可以看到最后一行打印出来1,说明我们的gcc是遵守ANSI C标准的。
其实还有个预定义符号__FUNCTION__,读者可以自己试着打印一下,它可以打印出main函数。
利用这些预定义符号,我们可以知道我们随时清楚的知道我们是什么时间创建的文件,也可以知道我们的文件路径,在有些场景中是不是能够起到一定的作用呢。
好了,这部分的内容就分享到这,这块内容并不是我们经常用到的知识点我们只需了解一下即可。
详解#define的用法
关于预处理指令我们提的最多的莫过于#define了,在C语言中它用的还是比较广泛的,说它简单呢也不简单有很多坑点,说它难其实也不算难只要理解一个坑点之后类似的问题就可以迎刃而解了,下面我们就一起来详细谈谈#define的各种用法吧
#define定义标识符
语法形式:
#define name stuff
下面我来举一些常见的栗子:
#define MAX 100
#define STRING "hello boys and girls!"
#define reg register
#define DO_FOR for(...;...;){//code}
......
下面我们来一起使用一下上述栗子,看看是不是如我所说全都能够达到目的:
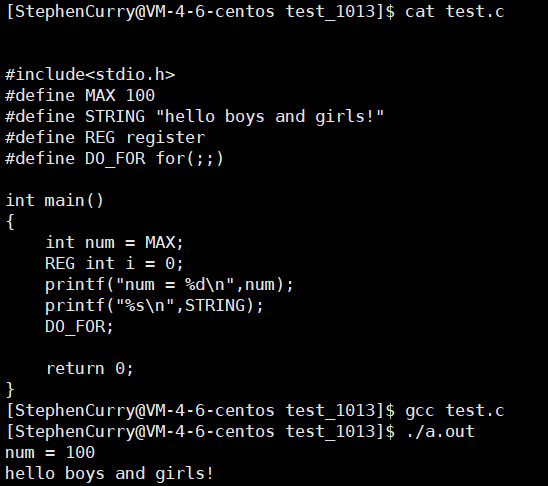
我们发现确实达到了目的,下面我们进入预处理过后的文件test.i观察一下其中的现象:

在预处理阶段#define定义的标识符已经全部替换成了后面的文本,接下来我就有一个问题了,在#define定义标识符的时候,到底要不要在后面加上;呢?
实际上你们也都看见了我在使用#define定义标识符的时候后面都未加;,这是因为在有些场景下容易产生误导性,例如:
#define MAX 100;
...
if(condition)
max = MAX;
else
max = 0;
...
我们知道max = MAX是一条语句,那么一条语句执行完了是不是以;结尾的?
如果我们在#define定义标识符后加上;那么这条语句没有问题的话就要写成这样:max = MAX,你觉得这样写不别扭吗?
所以我们尽量不要在#define定义标识符之后加;
#define定义宏
#define 机制包括了一个规定,允许把参数替换到文本中,这种实现通常称为宏(macro)或定义宏(define macro)。宏的申明形式:#define name(parament-list ) stuff。
首先我们来看看#define定义宏的基本使用方法:
#include这里的SQUARE(5)将X全部替换成了5,最后SQUARE(5)就替换成了5*5,最后打印出的结果就为25了。

但其实这种定义宏的方式是非常容易出问题的,我们来看一下栗子:
#include我相信肯定会有人出问题的,这里我再提示一下:#define只是简单的进行了一下文本替换,不要在心里想着给它添加括号!!!
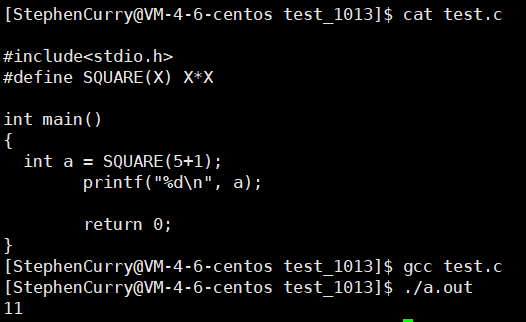
不知道为什么格式出现了一些问题,大伙将就着看吧
计算出来的答案为11,我相信肯定有读者将5+1先计算出来了,最后计算出来的答案为36。
好了,我们来进行分析,我在上面讲过#define它只是进行了一下文本替换操作,那么我们就按这种形式给它原原本本的写出来,X全部被替换成5+1,那么SQUARE(5+1)==>5+1*5+1=11,不要老想着给它加括号先将它运算出来,你直接写成原型再全部替换就行了。
我们进入预处理过后的test.i中观察一下,发现确实如我们所说:

如果我们想得到36,那么应该如何操作呢?
我们想是不是(5+1)*(5+1)这样就能得到,那么我们只需在宏参数列表之后为参数加上括号就行了,如下图所示:

请读者再好好思考一下这个过程。
好了,我们继续来看下一个栗子:
#include这段代码会打印出什么东西呢?我相信只要明白了我上面举的栗子这题就不会有问题,大家来试一试吧

这次还做错的读者还请细心一点,我再带大家分析一遍,先将X全部替换成5+1,所以SQUARE(5+1)==>(5+1)+(5+1),接着不要把这一堆看成整体了啊,别又自行加括号了,所以最终表达式为:10*(5+1)+(5+1)=66.
如果我们想得到宏替换后的整体结果,我们只需为整个宏要替换成的文本添加括号即可,如下图所示:

当然,举这个例子是想向大家说明我们经常会因为参数中的操作符或邻近操作符之间的优先级或求值顺序问题而打乱我们最初的本意,从而得不到我们想看见的答案,那么我在这里想跟大家总结以下几点:
用于对数值表达式进行求值的宏定义都应该尽量将参数加上括号,避免在使用宏时由于参数中的操作符或邻近操作符之间进行不可预料的相互作用。除非是你故意想得到某种结果,当然这种情况一般是出现在面试题当中,想尽一切办法来坑你
下面给大家分享一道题,请大家仔细思考一下再看我的分析:

这里分享一下我的思路,我们看到结果为
2442,又看到add你会想到什么,不管三七二十一,我想从里到外相加再说,结果发现加到add(444,add(555,add(666,777)))这个地方结果就为2442了,这就意味着333没有加进来,我们再看向前的0,我想到0* 333不就没了嘛,所以只有add(444,add(555,add(666,777)))这部分留了下来,这里我假设#define定义add(x,y)宏参数列表为这样,那么我们就断定x+ y必然就不会是一个整体,如果是一个整体了那不就是等于0了嘛,所以不能写成#define add(x,y) ((x)+(y))或(x+y)这样,于是就只好这样来写咯#define add(x,y) (x)+(y)或者x+y。 最后一个0* add(.......)改变了add的执行顺序,也就是0*333+add(444,add(555,add(666,777))) =2442
总结:写到关于 #define定义宏的题时,我建议大家最好动笔进行替换一下,因为如果出现一些很复杂的嵌套定义宏的题,心算也会难免会出现一些错误,所以我个人强烈推荐这种做法,一步步进行替换。
常见错误
我在学习过程中也经常看见有人出现这样的错误,如下图所示:

大家觉得能将c的值成功打印出来吗?我们一起来看看

我们发现在编译时出现了错误,报错的原因大概是X未定义、宏MAX没有参数列表,这到底是什么原因导致的呢?
初步猜想是因为MAX后多加了一个空格,导致#define认为MAX是一个标识符替换的是空格后面的文本,即(x,y) ((x)>(y)?(x):(y)),但是我们在main函数中求c时宏MAX后并没有参数列表,所以出现了报错现象。
接下来我们进入test.i中进行验证,发现确实如我们所猜想的那样MAX被当成是标识符了替换的是空格后面的文本:

那么有没有读者想过如果在函数名后面也加上空格,能求出C的值吗?

实践出真知,答案是可以的,对于函数来说并没有那么严格。

关于这部分我还想给大家讲两点:
1.在#define进行文本替换时不要随意加空格;
2.宏参数最好带上括号,当然括号也不是越多越好,只要得当即可。
带副作用的宏参数
当宏参数在宏的定义中出现超过一次的时候,如果参数带有副作用,那么你在使用这个宏的时候就可能出现危险,导致不可预测的后果。
副作用就是表达式求值的时候出现的永久性效果。例如:x++带有副作用,因为x本身的值发生了改变;而x+1不具有副作用,因为x并没有发生变化。
下面我们来看一道例题,大家先计算一下吧:
#include 我们一起来看看答案,a = 4,b = 6,c = 6,这到底是怎么来的呢?

按照我上面讲过的方法先无脑进行文本替换,于是c = MAX(++a,++b) ==>((++a)>(++b)?(++a):(++b);由于++a小于++b,所以最终c的值为++b,a只自增了一次而b自增了俩次,并且b是前置++所以最终跟c的值是一样的。本题容易错误的地方是容易忘记宏参数本身发生了变化而忘记加上。
#的用法
首先我们来看一组栗子,大家认为它是正确的吗?或者它能不能打印字符串呢?
#include答案是可以的,我们来看看结果

这说明什么问题呢?我们发现几个字符串竟然连在一起输出一个字符串了,由此我们能得到一个结论:字符串是有自动连接的特点的,几个字符串能自动拼接起来组成一个字符串。
讲完这个特点接下来我们介绍一下#的用法,它的作用是将宏参数变为一个字符串,语法形式如下:#define name(xxx) #xxx,接下来让我们来看看它的使用方法吧。
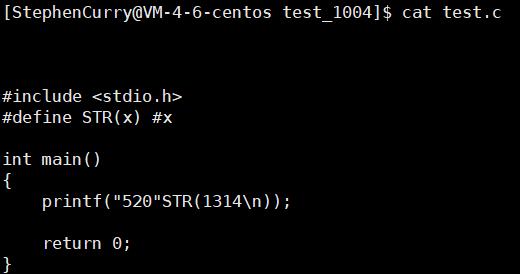
大家觉得会打印出什么东西来呢,没错就是你们经常对你伴侣说的话,算了我这个万年独不配说这句话

好了,我们继续来看看预处理过后的文件test.i里面发生了什么变化,vim test.i进入文件观察现象:

我们发现#将宏参数用双引号包含起来就成了一个字符串,然后利用了字符串自动连接的特点将该字符串成功输出,关于#的用法并不难理解。
其实它还有一个有意思的功能,我们可以将整数浮点数等直接转为字符串,我们一起来实现一下吧

利用#的用法我们将一个表面上看起来是整型的数1234转化成了一个字符串"1234"并将其成功输出,其实宏参数根本没有类型,1234它就是简单的一个文本或者连起来的四个字符,只不过我们将它视为了我们常见的数据类型。
那么,请大家看看下面这段程序认为它会打印出什么?
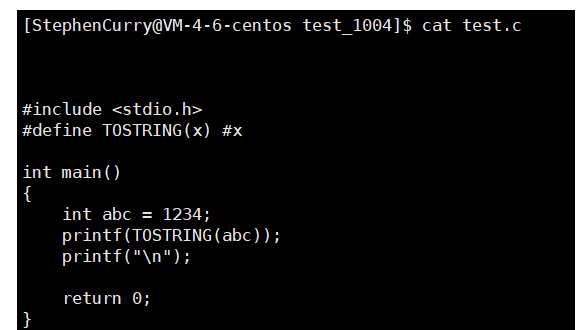
我们一起来看看结果打印出来是abc,有没有读者认为还是1234的呢?
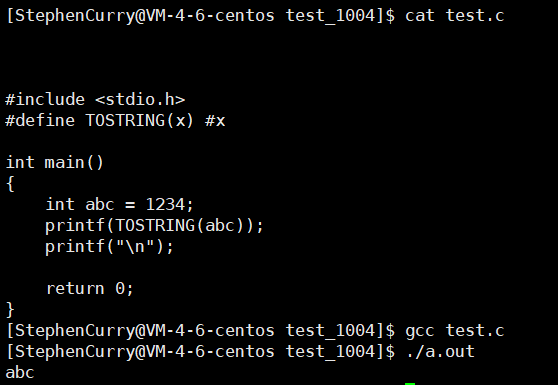
我反复提到一个问题#define做的是什么事情?
文本替换;在预处理阶段我们就已经将宏参数替换成了"abc",所以最终打印出来也为abc,而非对abc进行初始化的值。

##的用法
##可以把位于它两边的符号合成一个符号,它允许宏定义从分离的文本片段创建标识符。
注:这样的连接必须产生一个合法的标识符。否则其结果就是未定义的。
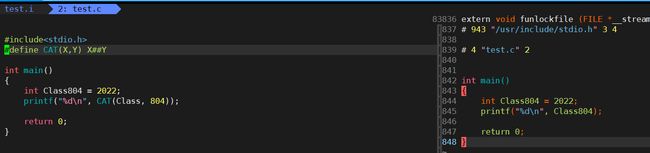
我们来看看下面的栗子:
#include来看看打印出来的结果,CAT(Class,804) == Class##804 => Class804 = 2022 :

我们也可以在预处理过后的test.i文件中观察一下,发现此时Class与804已经形成一个变量名Class804了:
好了,关于#和##其实是不难的,大家花点时间就能搞定。
宏和函数的对比
我们知道宏和函数有很多相似之处,接下来我们就将两者进行对比一下。
首先我们来看一个例子,下面代码都是求两个数中的较大值,我们分别用宏和函数来完成,结果显示也确实完成了任务,那么大家认为哪种方式更胜一筹呢?

我们来分析一下,如果我们要比较两个float类型的数,那么Max函数能实现这个作用嘛,答案显然是不行的,因为Max函数的形参类型为int,而你传过去两个float类型的数,必然会造成精度损失等问题,我们只能重写一个比较float类型的函数,如果我还要比较double…等其他的一些类型呢?那岂不是要写好多个函数啊,这样就显得函数非常呆了,因为它不够灵活;而#define定义宏就很好的解决了这一点,它没有进行类型的检查,它要做的仅仅就是替换一下文本就好了不关心宏参数的类型,这样就十分的方便了;其次在这一段简单的代码中,#define定义宏它的运行速度比函数更快,因为#define在预处理阶段就完成了替换,没有函数调用和返回的开销,关于函数调用与开销的问题大家可以来我的这篇博客看看。
综上所述,用于调用函数和从函数返回的代码可能比实际执行这个小型计算工作所需要的时间更多,而宏通常被应用于执行简单的运算,所以在上述代码中宏比函数在程序的规模和速度方面更胜一筹;更为重要的是函数的参数必须声明为特定的类型,所以函数只能在类型合适的表达式上使用。反之这个宏可以适用于整形、长整型、浮点型等可以用于>来比较的类型。
宏有时候也可以做函数做不到的事情。比如:宏的参数可以出现类型,但是函数做不到,你看见过函数实参包含类型的例子吗?在函数中是不可能出现的,读者可以自行检测一下。
#include那我们讲了一大堆宏的好处,那么是不是宏就可以取代函数呢?下面我们来看看宏的缺点:
1.每次使用宏的时候,一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度。
2.宏是没法调试的。test.c ---->预编译---->编译---->链接---->可执行程序,我们的宏在预编译阶段就完成了替换,而调试是在可执行程序阶段,机器执行的只是替换后的内容,我们人眼看到的是宏,所以当检查错误时会给我们带来极大的困难。
3.宏由于类型无关,也就不够严谨。
4.宏可能会带来运算符优先级的问题,导致程容易出现错。
宏和函数的对比:
| 属性 | #define定义宏 | 函数 |
|---|---|---|
| 执行速度 | 快 | 存在函数调用以及返回时额外开销 |
| 参数类型 | 宏的参数与类型无关 | 函数的参数与类型有关,不同的参数类型、参数个数以及返回的类型都是影响函数的原因 |
| 调试 | 不方便调试 | 可以逐语句进入函数内部调试 |
| 操作符优先级 | 对数值表达式进行求值的宏定义都应该尽量将参数加上括号,避免在使用宏时由于参数中的操作符或邻近操作符之间进行不可预料的相互作用 | 函数调用求值后一次性带回,表达式结果能更好的预料 |
| 带有副作用的参数 | 宏参数在宏的定义中出现超过一次的时候,如果参数带有副作用,那么你在使用这个宏的时候就可能出现危险,导致不可预测的后果 | 函数调用只进行一次求值,结果容易控制 |
| 代码长度 | 每次使用时宏替换的文本都会插入到程序中,假设你要多次使用宏会造成程序长度大幅度增长 | 函数代码只需要定义一份,每次直接调用即可不会造成程序长度的增长 |
在以后c++的学习中我们经常会听到尽量不要去使用宏,因为宏确实很容易出现错误还有它自身的一些劣势,那我们就仅仅使用函数嘛,那函数不是也有很多缺点吗? 在C99及C++的之后我们引入了一个新的概念inline-内联函数,它很好的解决了宏和函数的缺点,同时也包括了它们的优点,关于这一点之后我们在C++的学习中再详细进行解释吧。
最后关于宏与函数的命名约定:
一般来讲函数与宏的使用语法很相似,所以语言本身没法帮我们区分二者。那我们平时的一个习惯是:把宏名全部大写,函数名不要全部大写尽量采用大驼峰的方式:单词的首字母大写,例如:MaxNum等…
好了,今天的文章内容就讲到这个地方了,明天我将更新预处理的拓展部分,包括一些条件编译的使用、头文件的包含与重复问题等,请持续关注一下哦