Python 爬虫学习笔记(九)requests库+实战登录古诗文网(含验证码)
一、requests基本使用
requests库是python自己封装的一个库,使用起来会方便很多
首先在PyCharm中pip install requests
1个类型6个属性:
response的类型是models.Response而不是HTTPRsponse
- r.text:获取网站源码
- r.encoding:访问或定制编码方式
- r.url:获取请求的url
- r.content:获取响应的内容(字节类型)
- r.status_code:响应的状态码
- r.headers:响应头
二、GET请求
requests库实现GET请求会比urllib简单许多
需要注意的点如下:
- 参数使用params传递
- 参数无需先urlencoude编码
- 不需要请求对象的定制
- url中的?可以加也可以不加
代码如下,关键代码只有一行!
import requests
url = 'http://www.baidu.com/s?'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/98.0.4758.102 Safari/537.36 "
}
data = {
'wd': '武忠祥'
}
response = requests.get(url=url, params=data, headers=headers)
print(response.text)
三、POST请求
还是以百度翻译为例,跳过一些步骤,详情可以对比文章urllib的POST请求
需要注意的点如下:
- requests的POST请求不需要编解码
- POST请求的参数是data不是params
- 不需要请求对象的定制
- 最后加了json.loads()只是为了看懂结果
代码如下,关键代码只有一行!
示例代码如下:
import requests
import json
url = 'https://fanyi.baidu.com/sug'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/98.0.4758.102 Safari/537.36 "
}
data = {
'kw': 'eye'
}
response = requests.post(url=url, data=data, headers=headers)
content = json.loads(response.text, encoding='utf-8')
print(content)
四、代理
requests使用代理也简单很多,与urllib的代理方法详情请看urllib代理,这里还是以查看ip地址为例
只需给requests.get函数添加参数proxies即可,示例如下:
proxy = {
'http': '121.230.210.31:3256'
}
response = requests.get(url=url, params=data, headers=headers, proxies=proxy)
五、实战:登录古诗文网站(有验证码)
首先在登录界面故意输入错误的密码,不要点击确定否则会自动跳转。抓取登陆接口,在Form Data中找到了我们输入的账号密码,说明接口抓取的没有错。
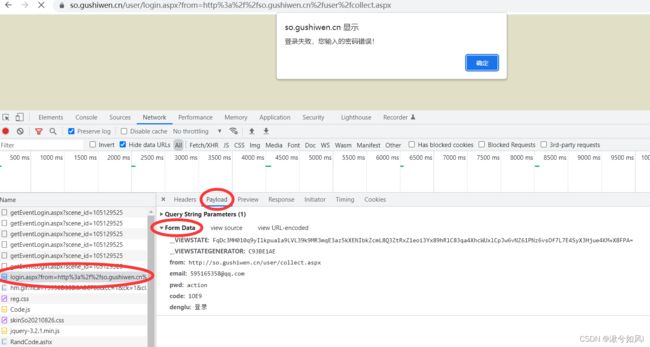
分析参数,我们要成功登录的话,form, email, pwd, denglu这些参数都是固定的, 只有__VIEWSTATE,__VIEWSTATEGENERATOR和code是三个变量,这也是我们需要确定的难点。
接下来一个个突破:
1. VIEW的两个变量
试着在网页源码搜索VIEW的两个变量,果然源码中出现了,那好说,我们只需要获取页面的源码,然后解析获取值就可以了。
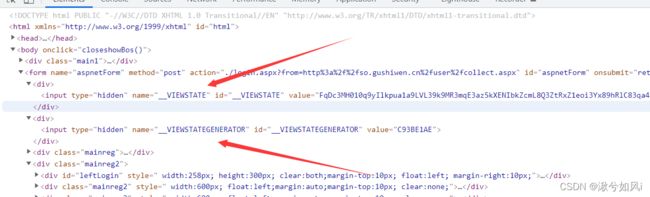
我这里用的是xpath,也可以用beautifulsoup
# 获取'__VIEWSTATE'和'__VIEWSTATEGENERATOR'
viewstate = tree.xpath('//input[@id="__VIEWSTATE"]/@value')[0]
viewstate_gen = tree.xpath('//input[@id="__VIEWSTATEGENERATOR"]/@value')[0]
2. 验证码code
验证码是一张图片,我们可以定位到它的url,点进去会发现,每次刷新验证码也会改变,我们可以把验证码图片下载下来然后文字识别获取它的值。

# 获取验证码图片url
pic_baseurl = tree.xpath('//img[@id="imgCode"]/@src')[0]
pic_url = 'https://so.gushiwen.cn' + pic_baseurl
response_code = requests.get(pic_url)
content_code = response_code.content # .content获取二进制
with open('yanzhengma.jpg', 'wb') as f:
f.write(content_code)
文字识别这里我用到了百度智能云提供的文字识别OCR,这里不详细叙述,百度有详细的API使用方法。
3. 模拟登录
data里面的变量都确定之后,就可以用下面的代码,requests.post来模拟表单提交登录信息完成登陆了。最后在把登陆后的页面源码下载下来,打开检查一下是不是我们想要的页面即可。
response_post = requests.post(url=url, data=data, headers=headers)
content_post = response_post.text
4. 有坑!!!
我们在获取验证码图片时,用到了一次get请求,最后模拟登陆时,又进行了一次post请求。问题在于,每一次不同的请求都会导致验证码刷新!!
我们必须用到session = requests.session()来创建一个对话,然后用这个session来进行get请求和post请求,这样就能确保请求是同一个,验证码不会被刷新。并且之后的requests.get和requests.post要换成session.get和session.post
5. 完整代码
import requests
from lxml import etree
from TextRecogAPI import killer # API接口(封装在了一个自定义函数)
# 登陆接口中的url
url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/98.0.4758.102 Safari/537.36 "
}
login_response = requests.post(url=url, headers=headers)
login_content = login_response.text # 登录页面源代码
tree = etree.HTML(login_content)
# 获取'__VIEWSTATE'和'__VIEWSTATEGENERATOR'
viewstate = tree.xpath('//input[@id="__VIEWSTATE"]/@value')[0]
viewstate_gen = tree.xpath('//input[@id="__VIEWSTATEGENERATOR"]/@value')[0]
# 获取验证码图片url
pic_baseurl = tree.xpath('//img[@id="imgCode"]/@src')[0]
pic_url = 'https://so.gushiwen.cn' + pic_baseurl
# 用session请求验证码图片 和 模拟登录,避免不同请求的验证码会被刷新
session = requests.session()
response_code = session.get(pic_url)
content_code = response_code.content # .content获取二进制
with open('yanzhengma.jpg', 'wb') as f:
f.write(content_code)
# 调用文字识别API
code = killer('yanzhengma.jpg').get('words_result')[0].get('words')
data = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstate_gen,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '11111111111',
'pwd': 'qwer1234',
'code': code,
'denglu': '登录'
}
# 模拟登录
response_post = session.post(url=url, data=data, headers=headers)
content_post = response_post.text
# 保存成功登陆后的页面
with open('gushiwen.html', 'w', encoding='utf-8') as f:
f.write(content_post)
将下载的页面源码打开,可以看到明显是已经登录后的状态,虽然没有前端的渲染

总结
- requests库的使用比urllib要简便很多
- 解析页面时也需要用到BeautifulSoup或xpath,各有特点
- 登录遇到验证码时,要是用session来保证请求是同一个,避免验证码刷新。