数据库选型粗略对比,欢迎补充!!!
关系型数据库 Oracle、SQL Server、 MySQL 、PostgreSQL、SQLite
- Oracle:甲骨文开发的商业数据库,不开源,支持所有主流平台,性能好,功能强,稳定性好,安全性好,支持大数据量,比较复杂,收费昂贵
- SQL Server:微软开发的商业数据库,只能在 Windows 运行
- MySQL :甲骨文拥有的开源数据库,支持多种操作系统,体积小,功能弱些,简单的操作性能好,复杂的操作性能差些
- PostgreSQL:使用 BSD 协议的完全开源免费的项目,支持多种操作系统,功能更强大,可以和多种开源工具配合
- SQLite:开源、轻型、无服务器、零配置,一个数据库就只是一个文件,在应用程序内执行操作,占用资源小,可用于嵌入式或小型应用
Oracle 多用于银行等高要求的领域,要求不高的比如互联网行业多用 MySQL 和 PostgreSQL,而 SQLite 用于嵌入式或作为应用程序内的数据库使用,SQL Server 用于 Window 服务器;
MySQL (开源,非国产,关系型数据库,最流行)
(1) 数据库介绍
MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。 MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- MySQL 是开源的,目前隶属于 Oracle 旗下产品。
- MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL 使用标准的 SQL 数据语言形式。
- MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby 和 TCL等。
- MySQL 是可以定制的,采用了 GPL 协议,可以修改源码来开发自己的 MySQL 系统。
** MySQL 数据库的可扩展性**
- 支持基于二进制日志的逻辑复制
- 存在多种第三方数据库中间件,支持读写分离及分库分表
(2) 适用场景
- Web网站系统
- 日志记录系统
- 数据仓库系统
- 嵌入式系统
(3)性能估算
单机性能
MySQL 支持大型数据库,
- 支持 5000 万条记录的数据仓库,
- 32 位系统表文件最大可支持 4GB,
- 64 位系统支持最大的表文件为8TB。
查询性能
-
主键查询: 千万级别数据 == 1-10ms
-
唯一索引查询: 千万级别数据 == 10-100ms
-
非唯一索引查询: 千万级别数据 == 100-1000ms
-
无索引数据: 百万级别数据 == 1000ms+
-
非插入的更新删除操作: 同查询性能
-
插入操作: 1w–10w tps (依赖配置优化)
集群
如果应用程序要向 MySQL 数据库插入上万条甚至更多的海量数据,对单机的 MySQL 数据库肯定压力很大,但是对于 MySQL 集群,在其中的一个 MySQL 节点插入这么大的数据,和单机 MySQL 服务器没有什么区别,那么这种情况下 MySQL 集群是如何提高性能和效率的呢?分库分表构建集群;
MySQL 与 MongoDB 的对比压测:
百万、千万级别的下不同查询量不同并发量的压测结果
数据库表中记录数总量在百万、千万级别的压测数据及结果如表所示。

亿级别的下不同查询量不同并发量的压测结果
数据库表中记录数总量在亿级别的压测数据及结果如表所示。

压测结果分析:
1)当每次查询数据量在500条时,无论表中数据总量千万或者亿级别,Mysql和MongoDB在100线程并发的情况下查询性能相当,表现良好,平均响应时间在500ms以内,TPS在230左右。
2)当每次查询数据量在5000条时,表中数据总量为千万级别时,MongoDB在50线程并发情况下查询性能不及Mysql 的一半,100线程并发情况查询性能都很差,平均响应时间在4500ms左右,表中数据总量为亿级别时,在50个及以上的并发情况下,MongoDB和Mysql性能都较差。
在本案例简单数据模型下的时间范围内的等值查询应用场景下,MongoDB在高并发条件下的大数据量查询性能并没有比Mysql更好。另外还有一点需要注意的是,在本案例中,数据总量由百万级别到千万级别再到亿级别的变化过程中,对于查询性能的影响都不是很大,但对于查询数据量的数倍增长却十分敏感,所以在考量数据库查询性能的时候,也要重点考量应用的单次查询量的需求。
尽管MongoDB在我们的这种应用场景下并没有达到我们预期的性能,我们也简单的调研了下Mysql和MongoDB对于内存的使用机制以及一些可能影响查询效率的内部配置。
(4) 优缺点
优点:
-
体积小、速度快、总体拥有成本低,开源;
-
核心程序采用完全的多线程编程。用多线程和C语言实现的 MySQL 能很容易充分利用CPU;
-
MySQL 有一个非常灵活而且安全的权限和口令系统。当客户与 MySQL 服务器连接时,他们之间所有的口令传送被加密,而且 MySQL 支持主机认证;
-
支持大型的数据库, 可以方便地支持上千万条记录的数据库。作为一个开放源代码的数据库,可以针对不同的应用进行相应的修改;
-
拥有一个非常快速而且稳定的基于线程的内存分配系统,可以持续使用面不必担心其稳定性;
缺点:
-
不支持热备份;
-
MySQL 最大的缺点是其安全系统,主要是复杂而非标准,另外只有到调用 MySQL admin 来重读用户权限时才发生改变;
-
没有一种存储过程(Stored Procedure)语言,这是对习惯于企业级数据库的程序员的最大限制;
-
MySQL 的价格随平台和安装方式变化。Linux的 MySQL 如果由用户自己或系统管理员而不是第三方安装则是免费的,第三方案则必须付许可费。Unix 或Linux自行安装 免费 、Unix或Linux 第三方安装 收费。
(5) 工作原理架构
一、MySQL逻辑架构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e9Uhp2iu-1658461638235)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220117151510816.png)]
MySQL逻辑架构整体分为三层,最上层为客户层,并非MySQL所独有,诸如,连接处理、授权认证、安全等功能均在这一层处理。
MySQL大多数核心服务均在中间这一层,包括查询解析、分析、优化、缓存、内置函数(时间、数学、加密等),所有的跨存储引擎的功能也在这一层实现:存储过程、触发器、视图等。
最下层为存储引擎,其负责MySQL中的数据存储和提取,中间的服务层通过API与存储引擎通信,这些API接口屏蔽了不同存储引擎的差异。
二、MySQL查询过程
当向MySQL发送一个请求的时候:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KNgh6Bc0-1658461638237)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220117151541651.png)]
1.客户端/服务端通信协议
MySQL客户端/服务端通信协议是“半双工”的:在任意时刻,要么是服务器向客户端发送数据,要么是客户端向服务器发送数据,这两个动作不能同时发生。一旦一端开始发送消息,另一端要接受完整个消息才能响应它,所以我们无法也无须将一个消息切成小块独立发送,也没有办法进行流量控制。
客户端用一个单独的数据包将查询请求发送给服务器,所以当查询语句很长的时候,需要设置max_allowed_packet参数。但是需要的注意的是,如果查询实在是太大,服务端会拒绝接受更多数据并抛出异常。
与之相反的是,服务器响应给用户的数据通常会很多,由多个数据包组成。但是当服务器响应客户端请求时,客户端必须完整的接受整个返回结果,而不能简单的只取前面几条结果,然后让服务器停止发送。因而在实际开发中,尽量保持查询简单且只返回必需的数据,减小通信间数据包的大小和数量是一个非常好的习惯,这也是查询中尽量避免使用SELECT * 以及加上LIMIT限制的原因之一。
2.查询缓存
在解析一个查询语句前,如果查询缓存是打开的,那么MySQL会检查这个查询语句是否命中查询缓存中的数据。如果当前查询恰好命中查询缓存,在检查一次用户权限后直接返回缓存中的结果。这种情况下,查询不会被解析,也不会生成执行计划,更不会执行。
MySQL将缓存存放在一个引用表(类似于HashMap的数据结构),通过一个哈希值索引,这个哈希值通过查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息计算得来。所以两个查询在任何字符上的不同(空格、注释),都会导致缓存不会命中。
如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、mysql库中的系统表,其查询结果都不会被缓存。比如函数NOW()或者CURRENT_DATE()会因为不同的查询时间,返回不同的查询结果,再比如包含CURRENT_USER或者CONNECION_ID()的查询语句会因为不同的用户而返回不同的结果,将这样的查询结果缓存起来没有任何的意义。
3.缓存失效
MySQL的查询缓存系统会跟踪查询中涉及的每个表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。正因为如此,在任何的写操作时,MySQL必须将对应表的所有缓存都设置为失效。如果查询缓存非常大或者碎片很多,这个操作就可能带来很大的系统消耗,甚至导致系统僵死一会儿。而且查询缓存对系统的额外消耗也不仅仅在写操作,读操作也不例外:
1.任何的查询语句在开始之前都必须经过检查,即使这条SQL语句永远不会命中缓存
2.如果查询结果可以被缓存,那么执行完成后,会将结果存入缓存,也会带来额外的系统消耗
基于此,要知道并不是什么情况下查询缓存都会提高系统性能,缓存和失效都会带来额外消耗,只有当缓存带来的资源节约大于其本身消耗的资源时,才会给系统带来性能提升。但要如何评估打开缓存是否能够带来性能提升是一件非常困难的事情,。如果系统确实存在一些性能问题,可以尝试打开查询缓存,并在数据库设计上做一些优化:比如:
1.用多个小表代替一个大表,注意不要过度设计
2.批量插入代替循环单条插入
3.合理控制缓存空间大小,一般来说其大小设置为几十兆比较合适
4.可以通过SQL_CACHE和SQL_NO_CACHE来控制某个查询语句是否需要进行缓存
不要轻易打开查询缓存,特别是写密集型应用。如果实在是忍不住,可以将query_cache_type 设置为DEMAND,这时只有加入SQL_CACH的查询才会走缓存,其他查询则不会,这样可以非常自由地控制哪些查询需要被缓存。
4.语法解析和预处理
MySQL通过关键字将SQL语句进行解析,并生成一颗对应的解析树。这个过程解析器主要通过语法规则来验证和解析。比如SQL中是否使用了错误的关键字或者关键字的顺序是否正确等等。预处理则会根据MySQL规则进一步检查解析树是否合法。比如检查要查询的数据表和数据列是否存在等等。
5.查询优化
语法树被认为是合法之后,并且有优化器将其转化成查询计划,多数情况下,一条查询可以有很多种执行方式,最后都返回相应的结果,优化器的作用就是找到这其中最好的执行计划。
MySQL使用基于成本的优化器,它尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最小的一个。在MySQL可以通过查询当前会话的last_query_cost的值来得到其计算当前查询的成本。(show status like 'last_query_cost')
show status like 'last_query_cost';
+-------------+| Variable_name | Value |
+-------------+| Last_query_cost | 6391.799000 |
示例中的结果表示优化器认为大概需要做6391个数据页的随机查找才能完成上面的查询。这个结果是根据一些列的统计信息计算得来的,这些统计信息包括:每张表或者索引的页面个数、索引的基数、索引和数据行的长度、索引的分布情况等等。
有非常多的原因会导致MySQL选择错误的执行计划,比如统计信息不准确、不会考虑不受其控制的操作成本(用户自定义函数、存储过程)、MySQL认为的最优跟我们想的不一样(我们希望执行时间尽可能短,但MySQL值选择它认为成本小的,但成本小并不意味着执行时间短)等等。
MySQL的查询优化器是一个非常复杂的部件,它使用了非常多的优化策略来生成一个最优的执行计划:
1.重新定义表的关联顺序(多张表关联查询时,并不一定按照SQL中指定的顺序进行,但有一些技巧可以指定关联顺序)
2.优化MIN()和MAX()函数(找某列的最小值,如果该列有索引,只需要查找B+Tree索引最左端,反之则可以找到最大值)
3.提前终止查询(使用Limit时,查找到满足数量的结果集后会立即终止查询)
4.优化排序(在老版本MySQL会使用两次传输排序,即先读取行指针和需要排序的字段在内存中对其排序,然后再根据排序结果去读取数据行,而新版本采用的是单次传输排序,也就是一次读取所有的数据行,然后根据给定的列排序)
6.查询执行引擎
在完成解析和优化阶段以后,MySQL会生成对应的执行计划,查询执行引擎根据执行计划给出的指令逐步执行得出结果。整个执行过程的大部分操作均是通过调用存储引擎实现的接口来完成,这些接口被称为handler API。查询过程中的每一张表由一个handler实例表示,实际上,MySQL在查询优化阶段就为每一张表创建了一个handler实例,优化器可以根据这些实例的接口来获取表的相关信息,包括表的所有列名、索引统计信息等。存储引擎接口提供了非常丰富的功能,但其底层仅有几十个接口,这些接口像塔积木一样完成了一次查询的大部分操作。
7.返回结果给客户端
查询执行的最后一个阶段就是将结果返回给客户端。即使查询不到数据,MySQL仍然会返回这个查询的相关信息,比如该查询影响到的行数以及执行时间等等。
如果查询缓存被打开且这个查询可以被缓存,MySQL也会将结果存放到缓存中。
结果集返回客户端是一个增量且逐步返回的过程。有可能MySQL在生成第一条结果时,就开始向客户端逐步返回结果集了。这样服务端就无须存储太多结果而消耗过多内存,也可以让客户端第一时间获得返回结果。需要注意的是,结果集中的每一行都会以一个满足①中所描述的通信协议的数据包发送,再通过TCP协议进行传输,在传输过程中,可能对MySQL的数据包进行缓存然后批量发送。
三、MySQL整个查询执行过程
1.客户端向MySQL服务器发送一条查询请求
2.服务器首先先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。否则进入下一级段
3.服务器进行SQL解析、预处理、再由优化器生成对应的执行计划
4.MySQL根据执行计划,调用存储引擎的API来执行查询
5.将结果返回给客户端,同时缓存查询结果
TiDB (开源,国产,分布式关系型数据库)
(1) 数据库介绍
[ TiDB ](https://github.com/pingcap/ TiDB ) 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。
特点:
TiDB 高度兼容 MySQL 5.7 协议、MySQL 5.7 常用的功能及语法。MySQL 5.7 生态中的系统工具(PHPMyAdmin、Navicat、MySQL Workbench、mysqldump、Mydumper/Myloader)、客户端等均适用于 TiDB 。
但 TiDB 尚未支持一些 MySQL 功能,可能的原因如下:
- 有更好的解决方案,例如 JSON 取代 XML 函数。
- 目前对这些功能的需求度不高,例如存储流程和函数。
- 一些功能在分布式系统上的实现难度较大。
除此以外, TiDB 不支持 MySQL 复制协议,但提供了专用工具用于与 MySQL 复制数据
- 从 MySQL 复制:[ TiDB Data Migration (DM)](https://docs.pingcap.com/zh/ TiDB -data-migration/stable/overview) 是将 MySQL/MariaDB 数据迁移到 TiDB 的工具,可用于增量数据的复制。
- 向 MySQL 复制:[TiCDC](https://docs.pingcap.com/zh/ TiDB /v4.0/ticdc-overview) 是一款通过拉取 TiKV 变更日志实现的 TiDB 增量数据同步工具,可通过 [MySQL sink](https://docs.pingcap.com/zh/ TiDB /v4.0/ticdc-overview#sink-支持) 将 TiDB 增量数据复制到 MySQL。
(2) 适用场景
TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。 四大核心应用场景如下:
-
对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高的金融行业属性的场景
众所周知,金融行业对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高。传统的解决方案是同城两个机房提供服务、异地一个机房提供数据容灾能力但不提供服务,此解决方案存在以下缺点:资源利用率低、维护成本高、RTO (Recovery Time Objective) 及 RPO (Recovery Point Objective) 无法真实达到企业所期望的值。 TiDB 采用多副本 + Multi-Raft 协议的方式将数据调度到不同的机房、机架、机器,当部分机器出现故障时系统可自动进行切换,确保系统的 RTO <= 30s 及 RPO = 0。
-
对存储容量、可扩展性、并发要求较高的海量数据及高并发的 OLTP 场景
随着业务的高速发展,数据呈现爆炸性的增长,传统的单机数据库无法满足因数据爆炸性的增长对数据库的容量要求,可行方案是采用分库分表的中间件产品或者 NewSQL 数据库替代、采用高端的存储设备等,其中性价比最大的是 NewSQL 数据库,例如: TiDB 。 TiDB 采用计算、存储分离的架构,可对计算、存储分别进行扩容和缩容,计算最大支持 512 节点,每个节点最大支持 1000 并发,集群容量最大支持 PB 级别。
-
Real-time HTAP 场景
随着 5G、物联网、人工智能的高速发展,企业所生产的数据会越来越多,其规模可能达到数百 TB 甚至 PB 级别,传统的解决方案是通过 OLTP 型数据库处理在线联机交易业务,通过 ETL 工具将数据同步到 OLAP 型数据库进行数据分析,这种处理方案存在存储成本高、实时性差等多方面的问题。 TiDB 在 4.0 版本中引入列存储引擎 TiFlash 结合行存储引擎 TiKV 构建真正的 HTAP 数据库,在增加少量存储成本的情况下,可以同一个系统中做联机交易处理、实时数据分析,极大地节省企业的成本。
-
数据汇聚、二次加工处理的场景
当前绝大部分企业的业务数据都分散在不同的系统中,没有一个统一的汇总,随着业务的发展,企业的决策层需要了解整个公司的业务状况以便及时做出决策,故需要将分散在各个系统的数据汇聚在同一个系统并进行二次加工处理生成 T+0 或 T+1 的报表。传统常见的解决方案是采用 ETL + Hadoop 来完成,但 Hadoop 体系太复杂,运维、存储成本太高无法满足用户的需求。与 Hadoop 相比, TiDB 就简单得多,业务通过 ETL 工具或者 TiDB 的同步工具将数据同步到 TiDB ,在 TiDB 中可通过 SQL 直接生成报表。
(3) 性能估算
近对比 TiDB 和 MySQL 在大表复杂join方面, TiDB 比MySQL快很多(至少三倍),这应该得益于 TiDB 的 分布式架构,把逻辑计算下推到各个数据节点并行执行导致的。

由于 TiDB 有着很好的水平分布式扩展,突破了单实例容量的限制,和分库分表比,应该有着更好的优势。
TiDB Sysbench 性能对比测试报告
Point Select 性能
| Threads | v5.2.2 TPS | v5.3.0 TPS | v5.2.2 95% latency (ms) | v5.3.0 95% latency (ms) | TPS 提升 (%) |
|---|---|---|---|---|---|
| 300 | 267673.17 | 267516.77 | 1.76 | 1.67 | -0.06 |
| 600 | 369820.29 | 361672.56 | 2.91 | 2.97 | -2.20 |
| 900 | 417143.31 | 416479.47 | 4.1 | 4.18 | -0.16 |
v5.3.0 对比 v5.2.2,Point Select 性能基本持平,略下降了 0.81%。

Update Non-index 性能
| Threads | v5.2.2 TPS | v5.3.0 TPS | v5.2.2 95% latency (ms) | v5.3.0 95% latency (ms) | TPS 提升 (%) |
|---|---|---|---|---|---|
| 300 | 39715.31 | 40041.03 | 11.87 | 12.08 | 0.82 |
| 600 | 50239.42 | 51110.04 | 20.74 | 20.37 | 1.73 |
| 900 | 57073.97 | 57252.74 | 28.16 | 27.66 | 0.31 |
v5.3.0 对比 v5.2.2,Update Non-index 性能基本持平,略上升了 0.95%。

Update Index 性能
| Threads | v5.2.2 TPS | v5.3.0 TPS | v5.2.2 95% latency (ms) | v5.3.0 95% latency (ms) | TPS 提升 (%) |
|---|---|---|---|---|---|
| 300 | 17634.03 | 17821.1 | 25.74 | 25.74 | 1.06 |
| 600 | 20998.59 | 21534.13 | 46.63 | 45.79 | 2.55 |
| 900 | 23420.75 | 23859.64 | 64.47 | 62.19 | 1.87 |
v5.3.0 对比 v5.2.2,Update Index 性能基本持平,略上升了 1.83%。

Read Write 性能
| Threads | v5.2.2 TPS | v5.3.0 TPS | v5.2.2 95% latency (ms) | v5.3.0 95% latency (ms) | TPS 提升 (%) |
|---|---|---|---|---|---|
| 300 | 3872.01 | 3848.63 | 106.75 | 106.75 | -0.60 |
| 600 | 4514.17 | 4471.77 | 200.47 | 196.89 | -0.94 |
| 900 | 4877.05 | 4861.45 | 287.38 | 282.25 | -0.32 |
v5.3.0 对比 v5.2.2,Read Write 性能基本持平,略下降了 0.62%。

(4) 优缺点
优点:
-
一键水平扩容或者缩容
得益于 TiDB 存储计算分离的架构的设计,可按需对计算、存储分别进行在线扩容或者缩容,扩容或者缩容过程中对应用运维人员透明。
-
金融级高可用
数据采用多副本存储,数据副本通过 Multi-Raft 协议同步事务日志,多数派写入成功事务才能提交,确保数据强一致性且少数副本发生故障时不影响数据的可用性。可按需配置副本地理位置、副本数量等策略满足不同容灾级别的要求。
-
实时 HTAP
提供行存储引擎 [TiKV](https://docs.pingcap.com/zh/ TiDB /v4.0/tikv-overview)、列存储引擎 [TiFlash](https://docs.pingcap.com/zh/ TiDB /v4.0/tiflash-overview) 两款存储引擎,TiFlash 通过 Multi-Raft Learner 协议实时从 TiKV 复制数据,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。TiKV、TiFlash 可按需部署在不同的机器,解决 HTAP 资源隔离的问题。
-
云原生的分布式数据库
专为云而设计的分布式数据库,通过 [ TiDB Operator](https://docs.pingcap.com/zh/ TiDB -in-kubernetes/v1.1/ TiDB -operator-overview) 可在公有云、私有云、混合云中实现部署工具化、自动化。
-
兼容 MySQL 5.7 协议和 MySQL 生态
兼容 MySQL 5.7 协议、 MySQL 常用的功能、 MySQL 生态,应用无需或者修改少量代码即可从 MySQL 迁移到 TiDB 。提供丰富的[数据迁移工具](https://docs.pingcap.com/zh/ TiDB /v4.0/ecosystem-tool-user-guide)帮助应用便捷完成数据迁移。
与传统的单机数据库相比, TiDB 具有以下优势:
- 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
- 支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
- 支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
缺点:
不支持以下的特性:
存储过程,视图,触发器,自定义函数,外键约束,全文索引,空间索引,非 UTF8 字符集
(5) 工作原理架构
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:

-
TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
-
PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
-
存储节点
**TiKV Server:**负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
**TiFlash:**TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
PostgreSQL(开源,非国产,关系型数据库,BSD协议)
(1)数据库介绍
PostgreSQL 是全球强大的开源数据库,支持主流开发语言,包括 C,C++,Perl,Python,Java,Tcl 以及 PHP 等,能够对 SQL 规范的完整实现,以及丰富多样的数据类型支持,包括 JSON 数据、IP 数据和几何数据等,而这些能力大部分商业数据库都无法全面支持。在过去的若干年间,PostgreSQL 正在以飞快的速度发展,目前已经广泛用在包括地球空间、移动应用、数据分析等各个行业,已成为众多企业开发人员和创新公司的首选。
(2)适用场景
企业数据库
如 ERP、交易系统、财务系统涉及资金、客户等信息,数据不能丢失且业务逻辑复杂,选择 PostgreSQL 作为数据底层存储,一是可以帮助您在数据一致性前提下提供高可用性,二是可以用简单的编程实现复杂的业务逻辑。
含 LBS 的应用
大型游戏、O2O 等应用需要支持世界地图、附近的商家,两个点的距离等能力,PostGIS 增加了对地理对象的支持,允许您以 SQL 运行位置查询,而不需要复杂的编码,帮助您更轻松理顺逻辑,更便捷的实现 LBS,提高用户粘性。
数据仓库和大数据
PostgreSQL 更多数据类型和强大的计算能力,能够帮助您更简单搭建数据库仓库或大数据分析平台,为企业运营加分。
建站或 App
PostgreSQL 良好的性能和强大的功能,可以有效的提高网站性能,降低开发难度。
位置应用系统:PostgreSQL支持PostGIS插件,PostGIS提供如下空间信息服务功能:空间对象、空间索引、空间操作函数和空间操作符,非常适合位置应用类产品。
科研项目信息系统:PostgreSQL支持更复杂的数据类型,并且能够自定义数据类型。可将不常用的数据转存到OBS云存储,节省存储成本和主机空间。
金融保险系统:PostgreSQL使用多版本并发控制(MVCC),保证数据一致性,主备实例数据同步复制实现数据双保险,确保数据不丢失,并且配合OBS实现存储空间扩展,将冷数据转存到OBS中,进一步节省历史数据存储成本
互联网电商:PostgreSQL在互联网应用高并发场景下具有较高稳定性,并且所有操作都可以在SQL中完成,无需来回进行数据导入,提高开发效率
(3)性能估算
- 单机性能极限
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-75J8TMno-1658461638253)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113085527625.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n4Bjk2N4-1658461638256)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113085613655.png)]
- 集群性能极限
(4) 优缺点
优点:
功能强大
过去的几年,PostgreSQL 已成为商用的首选开源关系数据库。
- PostgreSQL 遵循 BSD 协议,这意味着使用 PostgreSQL 无任何限制。
- 可支持 C、C++、Java、PHP、Python 及 Perl 等,使您的业务开发更简单更易用。
- PostgreSQL 是架构、语法、数据类型等与 Oracle 最接近的开源数据库。
- 兼容 SQL 标准:SQL2003,支持 SQL2011 的主要特性。
- 除了支持传统 SQL 的 LIKE 操作符、还支持 SQL99 新增的 SIMILAR TO 操作符和 POSIX 风格的正则表达式。
- 丰富的数据类型:几何、网络地址、XML、JSON、RANGE、数组等。
- 支持复合类型(自定义数据类型)。
- 支持复杂的多表 JOIN 查询 SQL:JOIN 算法支持 hash join、merge join 等。
- 支持窗口函数,可以改成复杂分析函数,因为分析函数包括了窗口函数。
- 支持函数索引、部分(行)索引、自定义索引、全文索引。
- 多进程的架构,更加稳定,单机可以支持更高访问量的数据库。
- 有功能强大,性能优秀的插件,如 PostGIS 是一个空间数据库扩展程序插件,它增加了对地理对象的支持,允许您以 SQL 运行位置查询。
- 达到商用级的数据强一致,基于 Synchronous Replication 复制技术,数据做到零丢失,即使类似于资金交易系统,也可以使用 PostgreSQL。
高性能
可适用于 OLAP 或 OLTP 场景的高性能数据库。
- 可与商业数据库媲美的查询优化器,支持所有主流多表连接查询(如 Nest loop、hash join、sort merge join 等),例如10万乘10万的表 join 是 MySQL 的100倍以上,可更快的从更多的表中获取结果,获得更精准的分析。
- 基于 NVMe SSD 存储,最大 QPS 可达23万以上,让您以更少的数据库数量支撑更高的业务并发请求量。
- 大量性能视图,可查看正在执行 SQL、当前锁等待、表扫描和索引扫描方面等性能数据,帮助您更快速精准定位性能问题。
- 通过优化 PostgreSQL 内核,提高内置算子性能,通过性能超高的 NVMe SSD 配置的硬盘,提供至少高于 SATA 十倍的 QPS 的配置。云数据库 PostgreSQL 默认为您提供一主一备架构的部署模式,默认启动同步复制(Synchronous Replication),使您的业务不中断,避免出现数据错乱、丢失等问题。
便捷管理
腾讯云可以让您在几分钟之内启动 PostgreSQL 实例并连接应用程序,而无需其他配置。默认配置具有通用性的参数,并可在管理中心参数设置实时修改。帮助您摆脱繁重和复杂的安装配置过程,提高您的运维效率。
便捷监控
提供了 PostgreSQL 的关键运行指标,包括 CPU 利用率、存储容量使用率、I/O 活动等性能监控数据,您可以在管理中心查看,且无需额外收费,帮助您快速定位和解决问题。自定义指标告警阈值,您无需时刻关注监控,而可通过电子邮件或短信及时了解当前异常。
可扩展
高保障
节点故障后,集群调度将立即开始自动重试恢复节点。当您的数据出现严重问题时,能快速恢复到某个正常时间点,以应对升级故障、灾难恢复等情况。云数据库默认为每个数据库都提供了多重安全防护,无需单独购买即可拥有。
缺点:
-
MVCC会生成多个版本,需要定期清理;
-
并发问题:用抢占资源方式,如有一个大SQL在执行,其它线程不能进行,但可设置优先级;
-
扩容问题:扩容花费时间长;
-
MVCC会生成多个版本,需要定期清理;单节点单实例运行,对分布式支持有限;
(5) 工作原理架构
一、PostgreSQL的物理架构
PostgreSQL的物理架构非常简单,它由共享内存、一系列后台进程和数据文件组成。 (如下图)
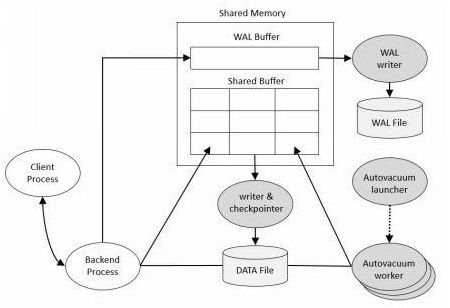
二、Shared Memory
共享内存是服务器服务器为数据库缓存和事务日志缓存预留的内存缓存空间。其中最重要的组成部分是Shared Buffer和WAL Buffer。
Shared Buffer
Shared Buffer的目的是减少磁盘IO。为了达到这个目的,必须满足以下规则:
- 当需要快速访问非常大的缓存时(10G、100G等)
- 如果有很多用户同时使用缓存,需要将内容尽量缩小
- 频繁访问的磁盘块必须长期放在缓存中
WAL Buffer
WAL Buffer是用来临时存储数据库变化的缓存区域。存储在WAL Buffer中的内容会根据提前定义好的时间点参数要求写入到磁盘的WAL文件中。在备份和恢复的场景下,WAL Buffer和WAL文件是极其重要的。
三、PostgreSQL 进程类型
PostgreSQL有四种进程类型
- Postmaster (Daemon) Process(主后台驻留进程)
- Background Process(后台进程)
- Backend Process(后端进程)
- Client Process(客户端进程)
Postmaster Process
主后台驻留进程是PostgreSQL启动时第一个启动的进程。启动时,他会执行恢复、初始化共享内存运行后台进程操作。正常服役期间,当有客户端发起链接请求时,它还负责创建后端进程。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-knqq2uyc-1658461638261)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220117162517809.png)]
如果通过pstree命令查看进程之间的关系,你会发现Postmaster进程是其他所有进程的父进程。
Background Process
PostgreSQL操作需要的后台进程列表如下:
| 进程 | 作用 |
|---|---|
| logger | 将错误信息写到log日志中 |
| checkpointer | 当检查点出现时,将脏内存块写到数据文件 |
| writer | 周期性的将脏内存块写入文件 |
| wal writer | 将WAL缓存写入WAL文件 |
| Autovacuum launcher | 当自动vacuum被启用时,用来派生autovacuum工作进程。autovacuum进程的作用是在需要时自动对膨胀表执行vacuum操作。 |
| archiver | 在归档模式下时,复制WAL文件到特定的路径下。 |
| stats collector | 用来收集数据库统计信息,例如会话执行信息统计(使用pg_stat_activity视图)和表使用信息统计(pg_stat_all_tables视图) |
Backend Process
最大后台链接数通过max_connections参数设定,默认值为100。后端进程用于处理前端用户请求并返回结果。查询运行时需要一些内存结构,就是所谓的本地内存(local memory)。本地内存涉及的主要参数有:
- work_mem:用于排序、位图索引、哈希链接和合并链接操作。默认值为4MB。
- maintenance_work_mem:用于vacuum和创建索引操作。默认值为64MB。
- temp_buffers:用于临时表。默认值为8MB。
Client Process
客户端进程需要和后端进程配合使用,处理每一个客户链接。通常情况下,Postmaster进程会派生一个紫禁城用来处理用户链接。
四、整体架构
PostgreSQL采用的是经典的C/S架构模型。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U8JuUL24-1658461638262)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220117163207611.png)]
组件名词解释
- libpq:数据库应用连接接口库(如JDBC,ODBC)
- Postmaster:守护监听进程
- Postgres:服务进程
运行流程分析
当一个前端数据库应用程序需要访问数据库:
- 调用libpq,将连接请求发送给Postmaster;
- Postmaster启用一个新的后端服务器进程postgres与前端应用连接;
- 服务进程Postgres直接与用户通信,不再通过Postmaster;
- Postgres接收客户端的命令请求,完成并返回结果;
客户端每创建一个数据库连接,postmaster就生成一个pstogres进程,是一种1:1的进程结构(一个客户端对应一个服务进程)。
多进程的好处在于:系统的各个模块,各个服务进程之间耦合度更低,多用户直接并发运行不受影响。
带来的影响是:多进程比多线程的结构开销要大,进程的创建和回收比线程更加消耗资源,当用户发来的请求过多时,会造成负载过大,执行速度变慢。
MongoDB ( 开源,非国产,分布式,NoSQL, 文档数据库, OLTP)
(1) 数据库介绍
MongoDB是一个基于分布式文件存储 [1] 的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。 MongoDB 开源;
(2) 适用场景
MongoDB已经在多个站点部署,其主要场景如下:
**1)网站实时数据处理。**它非常适合实时的插入、更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
**2)缓存。**由于性能很高,它适合作为信息基础设施的缓存层。在系统重启之后,由它搭建的持久化缓存层可以避免下层的数据源过载。
**3)高伸缩性的场景。**非常适合由数十或数百台服务器组成的数据库,它的路线图中已经包含对MapReduce引擎的内置支持。
不适用的场景如下:
1)要求高度事务性的系统。
2)传统的商业智能应用。
3)复杂的跨文档(表)级联查询。
MongoDB 更适用于高度非结构化,或者源数据就是 JSON,每条数据比较大,以 OLTP 为主的场景,不适合于事务要求比较高,或比较复杂的大数据量的查询的场景,另外由于 MongoDB 的语法和其他数据库差异比较大,需要一定的学习成本;
(3)性能估算
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NFswtL3y-1658461638264)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113092627246.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pSQ4dvrV-1658461638265)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113092647541.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rTuAqyAM-1658461638267)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113092734307.png)]
(4) 优缺点
MongoDB与关系型数据库相比的优缺点
与关系型数据库相比,MongoDB的优点:
① 弱一致性(最终一致),更能保证用户的访问速度:
举例来说,在传统的关系型数据库中,一个COUNT类型的操作会锁定数据集,这样可以保证得到“当前”情况下的较精确值。这在某些情况下,例 如通过ATM查看账户信息的时候很重要,但对于Wordnik来说,数据是不断更新和增长的,这种“较精确”的保证几乎没有任何意义,反而会产生很大的延 迟。他们需要的是一个“大约”的数字以及更快的处理速度。
但某些情况下MongoDB会锁住数据库。如果此时正有数百个请求,则它们会堆积起来,造成许多问题。我们使用了下面的优化方式来避免锁定:
每次更新前,我们会先查询记录。查询操作会将对象放入内存,于是更新则会尽可能的迅速。在主/从部署方案中,从节点可以使用“-pretouch”参数运行,这也可以得到相同的效果。
使用多个mongod进程。我们根据访问模式将数据库拆分成多个进程。
② 文档结构的存储方式,能够更便捷的获取数据。
对于一个层级式的数据结构来说,如果要将这样的数据使用扁平式的,表状的结构来保存数据,这无论是在查询还是获取数据时都十分困难。
③ 内置GridFS,支持大容量的存储。
GridFS是一个出色的分布式文件系统,可以支持海量的数据存储。
内置了GridFS了MongoDB,能够满足对大数据集的快速范围查询。
④ 内置Sharding。
提供基于Range的Auto Sharding机制:一个collection可按照记录的范围,分成若干个段,切分到不同的Shard上。
Shards可以和复制结合,配合Replica sets能够实现Sharding+fail-over,不同的Shard之间可以负载均衡。查询是对 客户端是透明的。客户端执行查询,统计,MapReduce等操作,这些会被MongoDB自动路由到后端的数据节点。这让我们关注于自己的业务,适当的 时候可以无痛的升级。MongoDB的Sharding设计能力较大可支持约20 petabytes,足以支撑一般应用。
这可以保证MongoDB运行在便宜的PC服务器集群上。PC集群扩充起来非常方便并且成本很低,避免了“sharding”操作的复杂性和成本。
⑤ 第三方支持丰富。(这是与其他的NoSQL相比,MongoDB也具有的优势)
现在网络上的很多NoSQL开源数据库完全属于社区型的,没有官方支持,给使用者带来了很大的风险。
而开源文档数据库MongoDB背后有商业公司10gen为其提供供商业培训和支持。
而且MongoDB社区非常活跃,很多开发框架都迅速提供了对MongDB的支持。不少知名大公司和网站也在生产环境中使用MongoDB,越来越多的创新型企业转而使用MongoDB作为和Django,RoR来搭配的技术方案。
⑥ 性能优越:
在使用场合下,千万级别的文档对象,近10G的数据,对有索引的ID的查询不会比 MySQL 慢,而对非索引字段的查询,则是全面胜出。 MySQL 实际无法胜任大数据量下任意字段的查询,而MongoDB的查询性能实在让我惊讶。写入性能同样很令人满意,同样写入百万级别的数 据,MongoDB比我以前试用过的couchdb要快得多,基本10分钟以下可以解决。补上一句,观察过程中MongoDB都远算不上是CPU杀手。
与关系型数据库相比,MongoDB的缺点:
① MongoDB不支持事务操作。
所以事务要求严格的系统(如果银行系统)肯定不能用它。(这点和优点①是对应的)
② MongoDB占用空间过大。
关于其原因,在官方的FAQ中,提到有如下几个方面:
1、空间的预分配:为避免形成过多的硬盘碎片,MongoDB每次空间不足时都会申请生成一大块的硬盘空间,而且申请的量从64M、128M、256M那 样的指数递增,直到2G为单个文件的较大体积。随着数据量的增加,你可以在其数据目录里看到这些整块生成容量不断递增的文件。
2、字段名所占用的空间:为了保持每个记录内的结构信息用于查询,MongoDB需要把每个字段的key-value都以BSON的形式存储,如果 value域相对于key域并不大,比如存放数值型的数据,则数据的overhead是较大的。一种减少空间占用的方法是把字段名尽量取短一些,这样占用 空间就小了,但这就要求在易读性与空间占用上作为权衡了。我曾建议作者把字段名作个index,每个字段名用一个字节表示,这样就不用担心字段名取多长 了。但作者的担忧也不无道理,这种索引方式需要每次查询得到结果后把索引值跟原值作一个替换,再发送到客户端,这个替换也是挺耗费时间的。现在的实现算是 拿空间来换取时间吧。
3、删除记录不释放空间:这很容易理解,为避免记录删除后的数据的大规模挪动,原记录空间不删除,只标记“已删除”即可,以后还可以重复利用。
4、可以定期运行 db.repairDatabase() 来整理记录,但这个过程会比较缓慢
③ MongoDB 没有如 MySQL 那样成熟的维护工具,这对于开发和IT运营都是个值得注意的地方。
MongoDB适合存储一些关系简单、数据量又很大的数据,比如我们的平台上虚拟机的监控信息,包括内存、IO、CPU、网络等数据,每隔几秒就采集一次数据,每周、每月,量很大,而且旧的监控数据也不会保留太长时间,就使用的MongoDB来存储这些数据;
另外MongoDB的集群部署相对比较简单,易于扩展;
比如主从复制,在mongo.conf配置几个参数就OK了;分片集群的配置也比较简单。还支持使用命令行来进行动态地添加和删除节点;
MongoDB的优点与不足
(1)MongoDB的不足之处
1、在集群分片中的数据分布不均匀
2、单机可靠性比较差
3、大数据量持续插入,写入性能有较大波动
4、磁盘空间占用比较大
(2)MongoDB的过人之处
1、无模式
2、查询与索引方式灵活,是最像SQL的Nosql
3、支持复制集、主备、互为主备、自动分片等特性
(5)工作原理架构
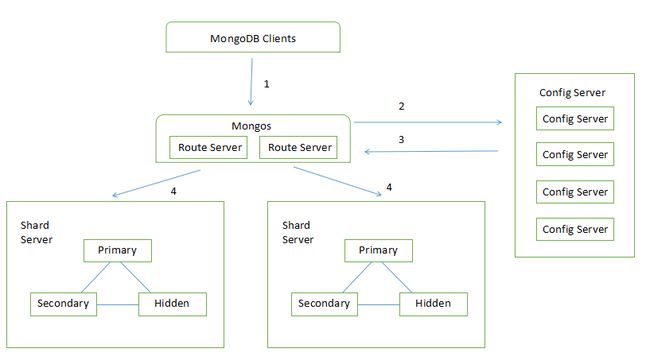
MongoDB是面向文档型非关系数据库。

- 副(复)本集(replica set)中存储的数据是相同的,为的是容灾。
- 分片(Shard Server)为了数据扩展,按照片键进行节点划分,数据根据片键存储到对应的服务器上。
- Mongos是路由。
向MongoDB写入数据

写数据时,先向配置中心注册,配置中心会返回相对应的key值
向MongoDB读取数据

副本集写数据
副本集分主从两种角色,写数据和读数据不一样。写数据的过程只是写到主节点中,由主节点以异步的方式同步到从节点中。

可以从任意节点读取数据,具体到哪个节点读可以指定。

写入数据
Elasticsearch (开源,非国产,倒排索引、分词、搜索引擎)
(1)数据库介绍
Elasticsearch是一个基于[Lucene ](https://baike.baidu.com/item/Lucene /6753302)的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。
Elasticsearch 是一个分布式、可扩展、实时的搜索与数据分析引擎。 它能从项目一开始就赋予数据以搜索、分析和探索的能力,
Elasticsearch 不仅仅只是全文搜索,我们还将介绍结构化搜索、数据分析、复杂的人类语言处理、地理位置和对象间关联关系等。 我们还将探讨为了充分利用 Elasticsearch 的水平伸缩性,应当如何建立数据模型,以及在生产环境中如何配置和监控你的集群。
特点
(1)可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上,服务小公司
(2)Elasticsearch不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES;Lucene (全文检索),商用的数据分析软件(也是有的),分布式数据库组件(MyCat)
(3)对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下ES,就可以作为生产环境的系统来使用了,数据量不大,操作不是太复杂
(4)数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型的操作);特殊的功能,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;Elasticsearch作为传统数据库的一个。
(2)适用场景
(1)维基百科和百度百科,手机维基百科,全文检索,高亮,搜索推荐。
(2)The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
(3)Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
(4)GitHub(开源代码管理),搜索上千亿行代码。
(5)电商网站,检索商品。
(6)日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
(7)商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅手机的监控,如果iphone的手机低于3000块钱,就通知我,我就去买
(8)BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,**区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘,Kibana进行数据可视化国内。
(9)国内:站内搜索(电商,招聘,门户,等等),IT OA系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)
(3)性能估算
大型分布式集群(数百台服务器)技术,处理PB级数据;
(4) 优缺点
优点:
- 分布式的搜索引擎和数据分析引擎
- 支持全文检索,结构化检索,数据分析
- 支持对海量数据进行近实时的处理;
- ES的分布式优势主要可以看以下几个方面:
1. 横向可扩展性:只需要增加一台服务器,做一点儿配置,启动一下ES进程就可以并入集群;
2. 分片机制提供更好的分布性:同一个索引分成多个分片(sharding),这点类似于HDFS的块机制;分而治之的方式来提升处理效率,相信大家都不会陌生;
3. 高可用:提供复制(replica)机制,一个分片可以设置多个复制,使得某台服务器宕机的情况下,集群仍旧可以照常运行,并会把由于服务器宕机丢失的复制恢复到其它可用节点上;这点也类似于HDFS的复制机制(HDFS中默认是3份复制);
缺点:
1. 各ES节点的一致性问题:其默认的机制是通过多播机制,同步元数据信息,但是在比较繁忙的集群中,可能会由于网络的阻塞,或者节点处理能力达到饱和导致各节点元数据不一致——也就是所谓的脑裂问题,这样会使集群处于不一致状态。目前并没有一个彻底的解决方案来解决这个问题,但是可以通过将工作节点与元数据节点分开的部署方案来缓解这种情况。
2. ES没有细致的权限管理机制,也就是说,没有像 MySQL 那样的分各种用户,每个用户又有不同的权限。所以在操作上的限制需要自己开发一个系统来完成;
(5)工作原理架构
整体架构:
z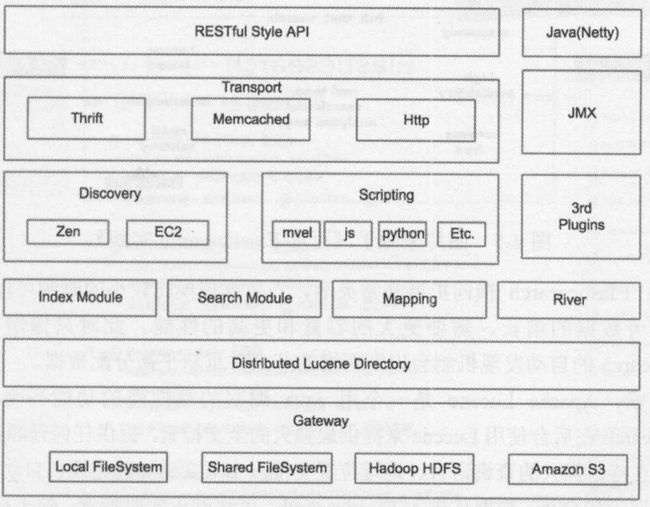
**Gateway:**Gateway是Elasticsearch用来存储索引的文件系统,支持多种文件类型,LocalFileSystem是存储在本地的文件系统,SharedFileSystem是共享存储,也可以使用Hadoop的HDFS分布式存储,也可以存储在AmazonS3云服务上。
**Lucene框架:**Gateway的上层是一个分布式的Lucene框架,Elasticsearch的底层API是由Lucene提供的,每一个Elasticsearch节点上都有一个Lucene引擎的支持。
**Elasticsearch的模块:**Lucene之上是Elasticsearch的模块,包括索引模块、搜索模块、映射解析模块等。River相当于第三方插件,用来导入第三方数据源,在2.X之后己经不再使用。
**Discovery:**Elasticsearch模块之上是Discovery、Scripting和第三方插件。Discovery是Elasticsearch的节点发现模块,不同机器上的Elasticsearch节点要组成集群需要进行消息通信,集群内部需要选举master节点,这些工作都是由Discovery模块完成的。Scripting用来支持JavaScript、Python等多种语言,可以在查询语句中嵌入,使用Script语句性能稍低。Elasticsearch也支持多种第三方插件。
**Elasticsearch的传输模块和JMX:**再上层是Elasticsearch的传输模块和JMX。传输模块支持Thrift,Memcached、HTTP,默认使用HTTP传输。JMX是Java的管理框架,用来管理Elasticsearch应用。
**交互接口:**最上层是Elasticsearch提供给用户的接口,可以通过阻RESTfulAPI和Elasticsearch集群进行交互。
一些基本概念:
集群(Cluster)
> 一组拥有共同的 cluster name 的节点。
节点(Node)
> 集群中的一个 Elasticearch 实例
索引(Index)
> ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。
类型(Type)
> 类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。
文档(Document)
> 文档是索引和搜索的原子单位,它是包含了一个或多个域(Field)的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。
SHARD
> index包含多个shard,每个shard都是一个最小工作单元,承载部分数据;每个shard都是一个lucene实例,有完整的建立索引和处理请求的能力。增减节点时,shard会自动在nodes中负载均衡;
> elasticsearch中每个shard每隔1秒都会refresh一次,每次refresh都会生成一个新的segment.一个segment对应着硬盘或者缓存(内存充当文件系统的)的一个文件,占用一个文件描述符。
translog
>事务日志,在每一次对 Elasticsearch 进行操作时均进行了日志记录。作为临时文件存储在硬盘上。理想中应该是任何一次写入都刷入磁盘,但是性能考虑不可能。实际上是每几秒中调用一次fsync刷到磁盘来提高吞吐量。这当然带来了丢失数据的可能。
副本与分片
分片(Shard)以及副本(Replica) 分布式存储系统为了解决单机容量以及容灾的问题,都需要有分片以及副本机制,同时分片和副本也提供负载均衡等支持。Elasticsearch 没有采用节点级别的主从复制,而是基于分片。ElasticSearch当前还未提供分片切分(shard-splitting)的机制,只能创建索引的时候静态设置,所以提前合理分配索引分片尤为重要,否则,当发现需要调整分片数量, 只能重新对数据进行创建索引。

提高分片数量有利于提高整体可用性,但过度分片会引起以下问题:
- 每个分片本质上就是一个Lucene索引, 因此会消耗相应的文件句柄, 内存和CPU资源
- 每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降
- ES使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差
分布式下的索引和搜索
-
创建索引:文档被索引到随机的主分片,然后转发到它的副本分片。
-
搜索请求:搜索在完整的分片集合上运行,无论他们是主分片还是副本分片,然后聚集结果返回。
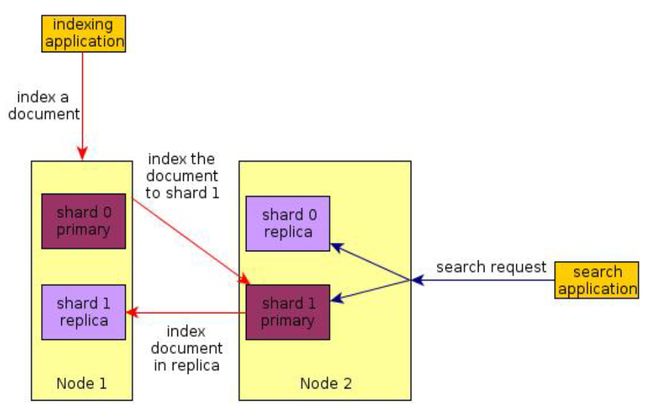
分布式架构图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rd3vt4GN-1658461638282)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113100327147.png)]
写入数据底层原理:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PgSEExQl-1658461638283)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113100437150.png)]
倒排索引原理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hqyqDScs-1658461638284)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113102510623.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AxB0DFq7-1658461638285)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113102640721.png)]
Nebula Graph (开源,非国产,分布式,图数据库)
(1)数据库介绍
Nebula Graph是一款**开源的、分布式的、易扩展的原生图数据库,**能够承载数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。
作为唯一能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在高并发场景下满足毫秒级的低时延查询要求,而且能够提供极高的服务可用性和数据安全性。
特点:
- 全对称分布式集群,无单点故障
- 存储计算架构分离,轻松水平扩展迁移
- 类 SQL 的查询语言,无需学习即可上手
- 支持 Spark、 HBase 等多数据源导入导出
- 支持多地多中心方案,故障自动恢复
(2)适用场景
- 社交关系网络
- 金融风控欺诈检测
- 知识图谱构建
- 实时推荐引擎
(3)性能估算
能够承载数千亿个点和数万亿条边的超大规模数据集
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZS0FAvxx-1658461638286)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113112817584.png)]
(4) 优缺点
优点:
- 高性能 基于图数据库的特性使用C++编写的Nebula Graph,可以提供毫秒级查询。众多数据库中,Nebula Graph在图数据服务领域展现了卓越的性能,数 据规模越大,Nebula Graph优势就越大。
- 易扩展 Nebula Graph采用shared-nothing架构,支持在不停止数据库服务的情况下扩缩容。
- 易开发 Nebula Graph提供Java、Python、C++和Go等流行编程语言的客户端,更多客户端仍在开发中。详情请参见Nebula Graph clients。
- 高可靠访问控制 Nebula Graph支持严格的角色访问控制和LDAP(Lightweight Directory Access Protocol)等外部认证服务,能够有效提高数据安全性。
- 生态多样化 Nebula Graph开放了越来越多的原生工具,例如Nebula Graph Studio、Nebula Console、Nebula Exchange等,更多工具可以查看 生态工具 概览。 此外,Nebula Graph还具备与Spark、Flink、 HBase 等产品整合的能力,在这个充满挑战与机遇的时代,大大增强了自身的竞争力。
- 兼容OpenCypher查询语言 Nebula Graph 查询语言,简称为 nGQL,是一种声明性的、部分兼容 openCypher 的文本查询语言,易于理解和使用。
- 面向未来硬件,读写平衡 闪存型设备有着极高的性能,并且价格快速下降, Nebula Graph 是一个面向 SSD 设计的产品,相比于基于HDD + 大内存的产品,更适合面向未来的 硬件趋势,也更容易做到读写平衡。 灵活数据建模 用户可以轻松地在Nebula Graph中建立数据模型,不必将数据强制转换为关系表。而且可以自由增加、更新和删除属性。
- 广受欢迎 腾讯、美团、京东、快手、360等科技巨头都在使用Nebula Graph。详情请参见Nebula Graph官网
缺点:
批量删除支持的差,批量删除还必须得先知道要删除的节点的唯一ID;
(5)工作原理架构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nNARdDHt-1658461638287)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113110820245.png)]
一个完整的 Nebula 部署集群包含三个服务,即 Query Service,Storage Service 和 Meta Service。每个服务都有其各自的可执行二进制文件,这些二进制文件既可以部署在同一组节点上,也可以部署在不同的节点上。
Meta Service
上图为 Nebula Graph 的架构图,其右侧为 Meta Service 集群,它采用 leader / follower 架构。Leader 由集群中所有的 Meta Service 节点选出,然后对外提供服务。Followers 处于待命状态并从 leader 复制更新的数据。一旦 leader 节点 down 掉,会再选举其中一个 follower 成为新的 leader。
Meta Service 不仅负责存储和提供图数据的 meta 信息,如 schema、partition 信息等,还同时负责指挥数据迁移及 leader 的变更等运维操作。
存储计算分离
在架构图中 Meta Service 的左侧,为 Nebula Graph 的主要服务,Nebula 采用存储与计算分离的架构,虚线以上为计算,以下为存储。
存储计算分离有诸多优势,最直接的优势就是,计算层和存储层可以根据各自的情况弹性扩容、缩容。
存储计算分离还带来的另一个优势:使水平扩展成为可能。
此外,存储计算分离使得 Storage Service 可以为多种类型的个计算层或者计算引擎提供服务。当前 Query Service 是一个高优先级的计算层,而各种迭代计算框架会是另外一个计算层。
无状态计算层
现在我们来看下计算层,每个计算节点都运行着一个无状态的查询计算引擎,而节点彼此间无任何通信关系。计算节点仅从 Meta Service 读取 meta 信息,以及和 Storage Service 进行交互。这样设计使得计算层集群更容易使用 K8s 管理或部署在云上。
计算层的负载均衡有两种形式,最常见的方式是在计算层上加一个负载均衡(balance),第二种方法是将计算层所有节点的 IP 地址配置在客户端中,这样客户端可以随机选取计算节点进行连接。
每个查询计算引擎都能接收客户端的请求,解析查询语句,生成抽象语法树(AST)并将 AST 传递给执行计划器和优化器,最后再交由执行器执行。
Shared-nothing 分布式存储层
Storage Service 采用 shared-nothing 的分布式架构设计,每个存储节点都有多个本地 KV 存储实例作为物理存储。Nebula 采用多数派协议 Raft 来保证这些 KV 存储之间的一致性(由于 Raft 比 Paxo 更简洁,我们选用了 Raft )。在 KVStore 之上是图语义层,用于将图操作转换为下层 KV 操作。
图数据(点和边)是通过 Hash 的方式存储在不同 Partition 中。这里用的 Hash 函数实现很直接,即 vertex_id 取余 Partition 数。在 Nebula Graph 中,Partition 表示一个虚拟的数据集,这些 Partition 分布在所有的存储节点,分布信息存储在 Meta Service 中(因此所有的存储节点和计算节点都能获取到这个分布信息)。
Neo4j (社区版开源,非国产,NoSQL,轻量级, 图数据库)
(1) 数据库介绍
Neo4j 是一个高性能的NoSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j 也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j 因其嵌入式、高性能、轻量级等优势,越来越受到关注.
Neo4j 提供了大规模可扩展性,在一台机器上可以处理数十亿节点/关系/属性的图,可以扩展到多台机器并行运行。相对于关系数据库来说,图数据库善于处理大量复杂、互连接、低结构化的数据,这些数据变化迅速,需要频繁的查询,在关系数据库中,这些查询会导致大量的表连接,因此会产生性能上的问题。Neo4j 重点解决了拥有大量连接的传统RDBMS在查询时出现的性能衰退问题。通过围绕图进行数据建模,Neo4j 会以相同的速度遍历节点与边,其遍历速度与构成图的数据量没有任何关系。此外,Neo4j 还提供了非常快的图算法、推荐系统和OLAP风格的分析,而这一切在目前的RDBMS系统中都是无法实现的。
| 特性\数据库名称 | Neo4j |
|---|---|
| 是否开源 | 社区版开源,企业版收费 |
| 第一版发行时间 | 2007年 |
| 技术特点 | 一站式服务、工具齐全 |
| 查询语言 | Cypher |
| 开发语言 | Java |
| 集群 | 企业版支持,社区版不支持 |
| 量级 | 轻量级 |
| 额外组件依赖 | 官方提供组件,可以与ES、MongoDB、Cassandra等NoSQL DB进行交互 |
(2)适用场景
- 欺诈检测和分析解决方案:
在欺诈者和犯罪分子造成持久性损害之前,实时分析数据关系对于发现欺诈戒指和其他复杂诈 骗至关重要
- 知识图:
利用基于图形的搜索工具,利用市场上最灵活,最具扩展性的解决方案,实现更好的数字资产管理。
- IT运营的网络和数据库基础设施监控:
图形数据库本质上比RDBMS更适合于理解管理网络和IT基础架构的复杂相互依赖性。
- 推荐引擎和产品推荐系统:
图形驱动的推荐引擎通过实时利用多种连接,帮助公司个性化产品,内容和服务。
- 主数据管理:
使用灵活且无架构的图形数据库模型组织和管理主数据,以获得实时洞察和360度客户视图。
- 社交媒体和社交网络图:
当您使用图形数据库为社交网络应用程序提供动力时,可以轻松利用社交关系或根据活动推断关系。
- 身份和访问管理:
使用图形数据库进行身份和访问管理时,可以快速有效地跟踪用户,资产,关系和授权。
- 隐私,风险和合规性:
快速有效的法规遵从性(GDPR,BCBS 239,FRTB ……)。管理企业风险,同时利用连接数据来提高商业智能
- 人工智能和分析:
人工智能(AI)准备推动几乎所有行业的下一波技术中断。就像之前的网络和移动技术革命一样,基于谁利用这项技术获得真正的竞争优势,将会有赢家和输家。
(3)性能估算
| 对比点 | Neo4j | Janus Graph | Huge Graph |
|---|---|---|---|
| 品牌知名度 | 最高 | 高 | 国际知名度一般,国内知名度高 |
| 开源生态 | 社区版开源,但较多限制,商业版闭源 | 开源,兼容ApacheTinkerpop生态,主要由IBM提供云上服务 | 开源,兼容ApacheTinkerpop生态,由百度领头,提供本土化技术与服务 |
| 图查询语言 | Cypher | Gremlin | Gremlin |
| 适用场景偏向 | 人工智能、欺诈检测、知识图谱等场景 | 云服务商、具备技术能力深厚的厂商 | 互联网大规模数据场景,网络安全、金融风控、广告推荐、知识图谱等 |
| 支持数据规模 | 社区版十亿级 | 百亿级以上 | 千亿级以上 |
| 大规模数据写入性能 | 在线导入速度慢,脱机导入速度较快 | 较慢 | 在线导入速度快,支持覆盖写 |
| 大规模数据查询性能 | 快 | 较快,性能抖动较严重 | 快,较稳定 |
| 功能完善程度 | 最完善 | 完善 | 完善 |
| Feature迭代速度 | 趋于完善,新功能上线较慢 | Fork自Titan,主要提供后端存储的版本兼容适配,基本很少上线新Feature | 百度自研,2016年项目启动,开源社区新功能迭代更新快速 |
| 开放及可扩展性 | 无法扩展 | 可扩展,不过代码复杂导致难度较大,内置支持4种后端存储:HBase、Cassandra、Bigtable、Berkeley | 可扩展,插件化机制扩展容易,内置支持6种以上后端存储:RocksDB、Cassandra、HBase、ScyllaDB、MySQL、PostgreSQL等 |
| 数据导入工具 | 支持CSV在线导入,速度在1万/秒内;支持neo4j-import脱机导入,速度在10万/秒级别,只能用于初始化导入 | 未提供支持 | 支持在线导入,速度在10万/秒级别,支持格式丰富:CSV、TXT、Json,支持从HDFS导入并兼任其各类压缩格式,支持从传统关系型数据库导入,包括MySQL、Oracle、PostgreSQL、SQL-Server等,支持从消息队列导入 |
| 数据备份恢复 | 支持脱机备份与恢复,需停机状态,商业版支持在线增量备份与脱机恢复 | 未提供支持,需要用户手动写程序 | 支持在线远程备份,支持在线远程恢复 |
| 数据增量备份 | 商业版支持,且支持备份数据加密 | 不支持 | 不支持 |
| API与客户端 | 支持HTTPAPI,支持Java、C#、JS语言版本的Client | 支持HTTPAPI或WebSocket,支持Java、Python、C#、JS语言版本的Client | 支持HTTPRESTfulAPI,原生仅支持Java语言Client;支持GremlinAPI,如果对外暴露Gremlin-Server后可支持Java、Python、C#、JS语言版本的Client |
| 可视化界面 | 支持,功能丰富 | 不支持,需要用户集成第三方界面 | 支持,功能丰富,支持可视化的数据建模、导入、分析等 |
| 内置常用图算法 | 提供安装算法包,提供了丰富的基本图算法,包括路径搜索、相似性、中心性、社区检测、链接预测等类别的算法 | 不支持 | 内置提供了基本的图算法,包括路径搜索、协同推荐、中心性、社区发现等类别的算法 |
| 支持图计算平台集成 | 未提供支持 | 支持SparkGraphX、Giraph等 | 支持SparkGraphX |
| 基础功能(属性图的增删该查、持久化存储、元数据、事务、缓存、查询优化、增量更新图) | 支持 | 支持 | 支持 |
| ACID事务 | 支持 | 部分支持,根据后端存储而定,Berkeley后端可完整支持事务,Cassandra后端支持原子性提交事务,HBase后端仅支持单行原子性理解,可能导致多行数之间据不一致 | 部分支持,根据后端存储而定,MySQL、PostgreSQL后端可完整支持事务,RocksDB、Cassandra后端支持原子性提交事务,HBase后端仅支持单行原子性;保证最终一致性 |
| Schema约束 | 商业版支持,包括属性非空、唯一性等约束,同时也支持Schema-Free | 支持,同时也支持Schema-Free | 支持,包括模式校验、属性非空、唯一性等约束,不允许Schema-Free |
| 属性索引 | 支持简单索引和复合索引,支持全文索引,依赖第三方Lucene库 | 支持复合索引和混合索引,复合索引允许精确匹配查询,混合索引支持范围查询、全文检索和空间检索,依赖第三方系统ES或Solr | 支持二级索引、范围索引、联合索引、全文索引,允许精确匹配查询、范围查询、全文检索等,均为原生实现不依赖第三方系统,不支持空间检索 |
| 图存储类型 | 本地存储 | 非本地存储,支持分布式存储 | 非本地存储,支持分布式存储 |
| 图分区 | 不支持 | 支持 | 支持 |
| 超级点问题 | 超级点的邻接边查询慢,十字链表存储结构难以加速部分边的查询 | 通过Vertex-Centric索引可缓解 | 通过Vertex-Centric索引可缓解,支持全量获取数据 |
| 多图实例 | 版本4.0支持 | 支持 | 支持 |
| 主键ID、自定义ID | 不支持 | 不支持主键ID,有限制的支持自定义LongID,不过会导致数据不一致 | 支持 |
| 顶点或边数据的TTL | 不支持 | 支持,可精细到顶点属性粒度 | 支持 |
| 用户认证与权限控制 | 商业版支持 | 支持用户认证 | 支持用户认证、支持基于用户角色的权限控制 |
| 高危查询语句限制 | Cypher无关 | 不支持Gremlin高危语句限制 | 支持,可限制用户执行高危Gremlin语句,如禁止访问本地文件、退出进程、打开Socket连接等高危操作 |
| 运行中语句跟踪 | 商业版支持,包括:列出正在运行的查询语句、中断正在运行的查询 | 不支持 | 同步Gremlin查询不支持跟踪,异步Gremlin查询支持状态跟踪和任务取消 |
| LDAP集成 | 商业版支持 | 未提供支持 | 未提供支持,可扩展插件 |
| 高可用HA | 商业版支持 | 未提供支持 | 商业版支持 |
| 监控 | 商业版支持 | 支持Metrics监控 | 支持监控接口 |
(4) 优缺点
优点:
- 数据的插入,查询操作很直观,不用再像之前要考虑各个表之间的关系。
- 提供的图搜索和图遍历方法很方便,速度也是比较快的。
- 检索/遍历/导航更多的连接数据是非常容易和快速的
- 它非常容易地表示半结构化数据
- Neo4j CQL查询语言命令是人性化的可读格式,非常容易学习
- 使用简单而强大的数据模型
- 它不需要复杂的连接来检索连接的/相关的数据,因为它很容易检索它的相邻节点或关系细节没有连接或索引
- 采用原生图(Native Graph)存储和处理数据:提供最优化的关系遍历执行效率,比关系数据库的表连接快上千倍。
- 基于(标签)属性图模型:支持丰富的数据语义描述、并且兼具灵活性。
- 基于纯Java实现,支持最广泛的操作系统和最便捷的部署,支持云端和容器部署。
- 提供面向图分析和模式匹配、声明型的Cypher查询语言,直观、简介、易于理解。
- 完全ACID兼容、保证数据一致性,因此同样适用于事务型(OLTP)和分析型(OLAP)应用
- 基于因果集群(Causal Clustering)的分布式数据库,提供高可用性、故障切换、数据冗余和可扩展的吞吐量
- 丰富的驱动语言支持:官方发布的有Java, JavaScript, Python, .Net和GO。另外还有社区用户提供的C/C++, R, JDBC, Python等各类语言驱动。
- 最具规模和最活跃的社区:社区版累计下载次数超过1千3百万,社区活跃技术人员超过5万,每年线上线下技术交流聚会超过400场。github上与Neo4j 相关项目超过1万个。
缺点:
- 极慢的插入速度。可能是因为创建节点和边的时候需要保存一些额外信息(为了查询服务),插入10000个节点,10000条边花了将近10分钟…
- 超大节点。当有一个节点的边非常多时(常见于大V),有关这个节点的操作的速度将大大下降。这个问题很早就有了,官方也说过会处理,然而现在仍然不能让人满意。
- 提高数据库速度的常用方法就是多分配内存,然而看了官方操作手册,貌似无法直接设置数据库内存占用量,而是需要计算后为其”预留“内存…
- 它不支持Sharding。
(5)工作原理架构
Neo4j 是基于图论实现的一种新型NoSQL数据库。图数据模型包括:属性图,超图和三元组。
免索引邻接
Neo4j 的重要特点就是保证了关系数据的查询速度。为什么关系会查询快速呢,就是因为免索引邻接属性:数据库中的每个节点都会维护与它相邻节点的引用。这相当于每个节点都与它相邻节点建立了微索引,这比全局索引的代价小很多。这意味着查询时间与图的规模无关,只与它附近节点的数量成正比。
相对于RDBMS的关系查询的改进:
1)免索引邻接使用遍历物理关系的方法查找,比全局索引来说代价小很多。查询一个索引的时间复杂度一般为0(log(n)),而遍历物理关系的时间复杂度仅为0(1)。
2)RDBMS当索引建立后,试图反向遍历时,建立的索引就会不起作用了。免索引邻接机制就不会有问题。
Neo4j 底层数据结构
从宏观来讲:Neo4j 只有节点和关系两种数据类型。
1)节点
节点存储文件用来存储节点的记录,文件名为neostore.nodestore.db。节点记录的长度为固定的大小,9字节。
格式为:Node:inUse+nextRelId+nextPropId.
inUse: 1 表示该节点被正常使用,0表示该节点被删除。
nextRelId: 该节点的下一个关系Id.
nextPropId:该节点的下一个属性Id.
固定字节长度的方式可以让我很快计算出不同ID的存储位置。
2)关系
关系存储文件用来存储关系的记录,文件名为neostore.relationshipstore.db。跟节点的存储一样,关系存储区的记录大小也是固定的。
格式为:
Relationshop:inUse+firstNode+secondNode+relType+firstPreRelId+secondPrevRelId+secondNextRelId+nextPropId。
inUse,nextPropId:作用同上。
firstNode:当前关系的起始节点。
secondNode:当前关系的终止节点。
relType:关系的类型
firstPrevRelId,firstNextRelId:起始节点的前一个和后一个关系的ID.
secondPrevRelId,secondNextRelId:终止节点的前一个和后一个关系ID.
3)这样的数据结构的好处:
Neo4j 节点和关系的存储文件只关系图的基本存储结构而不是属性数据。这两种记录都使用固定大小的记录,能方便根据ID快速计算存储位置。并且节点和关系记录变得相当轻量级。
4)属性的存储
属性的记录是存储在neostore.propertystore.db文件中。与节点和关系记录一样,也是固定长度。每个属性包含4个属性块和属性链中下一个属性ID.属性链是单向链,关系链是双向链。属性索引文件主要用于存储属性的名称,属性索引的值部分存储的是指向动态内存的记录或者内联值,短字符串和短数组会直接内联在属性存储记录中。当长度超过属性记录的Propblock长度限制后,会单独存储在其他的动态存储文件中。
HBase ( *开源,非国产宽表、列式存储、键值对存储、NoSQL、OLTP )
(1)数据库介绍
HBase 是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样, HBase 在Hadoop之上提供了类似于Bigtable的能力。 HBase 是Apache的Hadoop项目的子项目。 HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是 HBase 基于列的而不是基于行的模式。、
** HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用 HBase 技术可在廉价PC Server上搭建起大规模结构化存储集群。**
(2)适用场景
- 对象存储:我们知道不少的头条类、新闻类的的新闻、网页、图片存储在 HBase 之中,一些病毒公司的病毒库也是存储在 HBase 之中
- 时序数据: HBase 之上有OpenTSDB模块,可以满足时序类场景的需求
- 推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在 HBase 之上
- 时空数据:主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在 HBase 之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在 HBase 之中
- CubeDB OLAP:Kylin一个cube分析工具,底层的数据就是存储在 HBase 之中,不少客户自己基于离线计算构建cube存储在 HBase 之中,满足在线报表查询的需求
- 消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在 HBase 之上
- Feeds流:典型的应用就是xx朋友圈类似的应用
- NewSQL:之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求
(3)性能估算
承载数据量级评估、性能瓶颈,单机/集群 数据量与集群节点数评估等
HBase 适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与 HBase 的极易扩展性息息相关。正式因为 HBase 良好的扩展性,才为海量数据的存储提供了便利。
1. 海量数据存储:
上百亿行 x 上百万列,并没有列的限制,当表非常大的时候才能发挥这个作用, 最多百万行的话,没有必要放入 HBase 中
2. 准实时查询:
百亿行 x 百万列,在百毫秒以内
(4) 优缺点
优点:
1. 容量大:
传统关系型数据库,单表不会超过五百万,超过要做分表分库,不会超过30列
HBase 单表可以有百亿行、百万列,数据矩阵横向和纵向两个维度所支持的数据量级都非常具有弹性
2. 面向列:
面向列的存储和权限控制,并支持独立检索,可以动态增加列,即,可单独对列进行各方面的操作
列式存储,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,能大大减少读取的数量
3. 多版本:
HBase 的每一个列的数据存储有多个Version,比如住址列,可能有多个变更,所以该列可以有多个version
4. 稀疏性:
为空的列并不占用存储空间,表可以设计的非常稀疏。
不必像关系型数据库那样需要预先知道所有列名然后再进行null填充
5. 拓展性:
底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加 data node 节点服务(机器)就可以了
6. 高可靠性:
WAL机制,保证数据写入的时候不会因为集群异常而导致写入数据丢失
Replication机制,保证了在集群出现严重的问题时候,数据不会发生丢失或者损坏
HBase 底层使用HDFS,本身也有备份。
7.高性能:
底层的LSM数据结构和RowKey有序排列等架构上的独特设计,使得 HBase 写入性能非常高。
Region切分、主键索引、缓存机制使得 HBase 在海量数据下具备一定的随机读取性能,该性能针对Rowkey的查询能够到达毫秒级别
LSM树,树形结构,最末端的子节点是以内存的方式进行存储的,内存中的小树会flush到磁盘中(当子节点达到一定阈值以后,会放到磁盘中,且存入的过程会进行实时merge成一个主节点,然后磁盘中的树定期会做merge操作,合并成一棵大树,以优化读性能。
缺点:
1 不能支持条件查询,只支持按照Row key来查询.
2 暂时不能支持Master server的故障切换, 当Master宕机后, 整个存储系统就会挂掉.
补充 :
1.数据类型, HBase 只有简单的字符类型,所有的类型都是交由用户自己处理,它只保存字符串。而关系数据库有丰富的类型和存储方式。
2.数据操作: HBase 只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系,而传统数据库通常有各式各样的函数和连接操作。
3.存储模式: HBase 是基于列存储的,每个列族都由几个文件保存,不同的列族的文件时分离的。而传统的关系型数据库是基于表格结构和行模式保存的
4.数据维护, HBase 的更新操作不应该叫更新,它实际上是插入了新的数据,而传统数据库是替换修改
5.可伸缩性, HBase 这类分布式数据库就是为了这个目的而开发出来的,所以它能够轻松增加或减少硬件的数量,并且对错误的兼容性比较高。而传统数据库通常需要增加中间层才能实现类似的功能
(5) 工作原理架构
系统架构:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t3UB6AWJ-1658461638288)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113155853604.png)]
注意:应该是每一个 RegionServer 就只有一个 HLog,而不是一个 Region 有一个 HLog。
从 HBase 的架构图上可以看出, HBase 中的组件包括Client、Zookeeper、HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等,接下来介绍他们的作用。
Client
HBase 有两张特殊表:
.META.:记录了用户所有表拆分出来的的 Region 映射信息,.META.可以有多个 Regoin
-ROOT-:记录了.META.表的 Region 信息,-ROOT-只有一个 Region,无论如何不会分裂
Client 访问用户数据前需要首先访问 ZooKeeper,找到-ROOT-表的 Region 所在的位置,然 后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过 client 端会做 cache 缓存。
ZooKeeper
> ZooKeeper 为 HBase 提供 Failover 机制,选举 Master,避免单点 Master 单点故障问题
> 存储所有 Region 的寻址入口:-ROOT-表在哪台服务器上。-ROOT-这张表的位置信息
> 实时监控 RegionServer 的状态,将 RegionServer 的上线和下线信息实时通知给 Master
> 存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family
Master
1、为 RegionServer 分配 Region
2、负责 RegionServer 的负载均衡
3、发现失效的 RegionServer 并重新分配其上的 Region
4、HDFS 上的垃圾文件( HBase )回收
5、处理 Schema 更新请求(表的创建,删除,修改,列簇的增加等等)
RegionServer
1、RegionServer 维护 Master 分配给它的 Region,处理对这些 Region 的 IO 请求
2、RegionServer 负责 Split 在运行过程中变得过大的 Region,负责 Compact 操作
可以看到,client 访问 HBase 上数据的过程并不需要 master 参与(寻址访问 zookeeper 和 RegioneServer,数据读写访问 RegioneServer),Master 仅仅维护者 Table 和 Region 的元数据信息,负载很低。
.META. 存的是所有的 Region 的位置信息,那么 RegioneServer 当中 Region 在进行分裂之后 的新产生的 Region,是由 Master 来决定发到哪个 RegioneServer,这就意味着,只有 Master 知道 new Region 的位置信息,所以,由 Master 来管理.META.这个表当中的数据的 CRUD
所以结合以上两点表明,在没有 Region 分裂的情况,Master 宕机一段时间是可以忍受的。
HRegion
table在行的方向上分隔为多个Region。Region是 HBase 中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。
Region按大小分隔,每个表一般是只有一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值时就会分成两个新的region。
每个region由以下信息标识:< 表名,startRowkey,创建时间>
由目录表(-ROOT-和.META.)记录该region的endRowkey
Store
每一个region由一个或多个store组成,至少是一个store, HBase 会把一起访问的数据放在一个store里面,即为每个 ColumnFamily建一个store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者 多个StoreFile组成。 HBase 以store的大小来判断是否需要切分region
MemStore
memStore 是放在内存里的。保存修改的数据即keyValues。当memStore的大小达到一个阀值(默认128MB)时,memStore会被flush到文 件,即生成一个快照。目前 HBase 会有一个线程来负责memStore的flush操作。
StoreFile
memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile。
HFile
HBase 中KeyValue数据的存储格式,HFile是Hadoop的 二进制格式文件,实际上StoreFile就是对Hfile做了轻量级包装,即StoreFile底层就是HFile。
HLog
HLog(WAL log):WAL意为write ahead log,用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复。HLog文件就是一个普通的Hadoop Sequence File, Sequence File的value是key时HLogKey对象,其中记录了写入数据的归属信息,除了table和region名字外,还同时包括sequence number和timestamp,timestamp是写入时间,sequence number的起始值为0,或者是最近一次存入文件系统中的sequence number。 Sequence File的value是 HBase 的KeyValue对象,即对应HFile中的KeyValue。
HFDS(开源,非国产,分布式文件系统)
(1)数据库介绍
HDFS,是Hadoop抽象文件系统的一种实现。Hadoop抽象文件系统可以与本地系统、Amazon S3等集成,甚至可以通过Web协议(webhsfs)来操作。HDFS的文件分布在集群机器上,同时提供副本进行容错及可靠性保证。例如客户端写入读取文件的直接操作都是分布在集群各个机器上的,没有单点性能压力。
Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
特点: 开源,分布式,非国产
(2)适用场景
1、海量数据存储
2、高容错
3、商用廉价的硬件
4、存储大文件
5、一次写入多次读取
(3)性能估算
- 适合批处理
移动计算而非数据,数据位置暴露给计算框架 - 适合大数据处理
GB、TB、甚至PB级数据, 百万规模以上的文件数量, 10K+节点规模
(4) 优缺点
优点:
高容错性: 数据自动保存多个副本,副本丢失后,自动恢复
**适合批处理:**移动计算而非数据,数据位置暴露给计算框架
**适合大数据处理:**GB、TB、甚至PB级数据,百万规模以上的文件数量,10K+节点规模,
**流式文件访问:**一次性写入,多次读取,保证数据一致性
**可构建在廉价机器上:**通过多副本提高可靠性,提供了容错和恢复机制
缺点:
**低延迟数据访问:**比如毫秒级低延迟,与高吞吐率,
**小文件存取:**占用NameNode大量内存,寻道时间超过读取时间,
并发写入、文件随机修改:一个文件只能有一个写者,仅支持append
(5)工作原理架构
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iSIkpPi7-1658461638289)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113161126303.png)]
HDFS是一个主从结构,一个HDFS集群是由一个名字节点,它是一个管理文件命名空间和调节客户端访问文件的主服务器,当然还有一些数据节点,通常是一个节点一个机器,它来管理对应节点的存储。HDFS对外开放文件命名空间并允许用户数据以文件形式存储。
内部机制是将一个文件分割成一个或多个块,这些块被存储在一组数据节点中。名字节点用来操作文件命名空间的文件或目录操作,如打开,关闭,重命名等等。它同时确定块与数据节点的映射。数据节点负责来自文件系统客户的读写请求。数据节点同时还要执行块的创建,删除,和来自名字节点的块复制指令。
名字节点和数据节点都是运行在普通的机器之上的软件,机器典型的都是GNU/Linux,HDFS是用java编写的,任何支持java的机器都可以运行名字节点或数据节点,利用java语言的超轻便性,很容易将HDFS部署到大范围的机器上。典型的部署是由一个专门的机器来运行名字节点软件,集群中的其他每台机器运行一个数据节点实例。体系结构不排斥在一个机器上运行多个数据节点的实例,但是实际的部署不会有这种情况。
集群中只有一个名字节点极大地简单化了系统的体系结构。名字节点是仲裁者和所有HDFS元数据的仓库,用户的实际数据不经过名字节点。
存储数据架构图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-98PfFSUJ-1658461638290)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113163140838.png)]
HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。下面我们分别介绍这四个组成部分。
Client:就是客户端。
1、文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
2、与 NameNode 交互,获取文件的位置信息。
3、与 DataNode 交互,读取或者写入数据。
4、Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
5、Client 可以通过一些命令来访问 HDFS。
NameNode:就是 master,它是一个主管、管理者。
1、管理 HDFS 的名称空间。
2、管理数据块(Block)映射信息
3、配置副本策略
4、处理客户端读写请求。
DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
1、存储实际的数据块。
2、执行数据块的读/写操作。
Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
1、辅助 NameNode,分担其工作量。
2、定期合并 fsimage和fsedits,并推送给NameNode。
3、在紧急情况下,可辅助恢复 NameNode。
HDFS 读取文件步骤图:
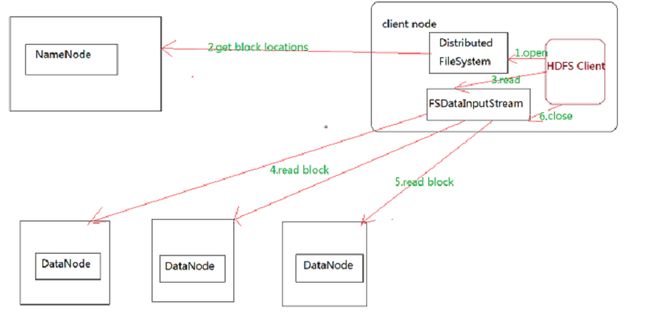
HDFS的文件读取原理,详细解析如下:
1、首先调用FileSystem对象的open方法,其实获取的是一个DistributedFileSystem的实例。
2、DistributedFileSystem通过RPC(远程过程调用)获得文件的第一批block的locations,同一block按照重复数会返回多个locations,这些locations按照Hadoop拓扑结构排序,距离客户端近的排在前面。
3、前两步会返回一个FSDataInputStream对象,该对象会被封装成 DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方 法,DFSInputStream就会找出离客户端最近的datanode并连接datanode。
4、数据从datanode源源不断的流向客户端。
5、如果第一个block块的数据读完了,就会关闭指向第一个block块的datanode连接,接着读取下一个block块。这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流。
6、如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的block块都读完,这时就会关闭掉所有的流。
HDFS的文件写入步骤图:
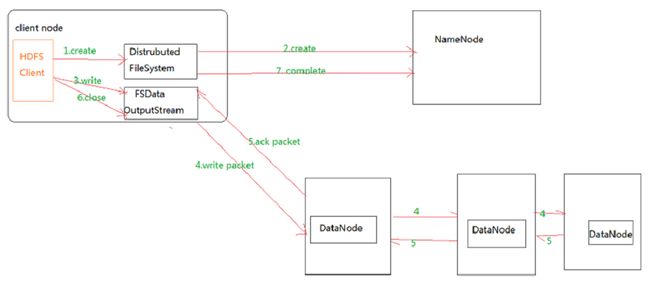
HDFS的文件写入原理详细步骤解析:
1.客户端通过调用 DistributedFileSystem 的create方法,创建一个新的文件。
2.DistributedFileSystem 通过 RPC(远程过程调用)调用 NameNode,去创建一个没有blocks关联的新文件。创建前,NameNode 会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,NameNode 就会记录下新文件,否则就会抛出IO异常。
3.前两步结束后会返回 FSDataOutputStream 的对象,和读文件的时候相似,FSDataOutputStream 被封装成 DFSOutputStream,DFSOutputStream 可以协调 NameNode和 DataNode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列 data queue。
4.DataStreamer 会去处理接受 data queue,它先问询 NameNode 这个新的 block 最适合存储的在哪几个DataNode里,比如重复数是3,那么就找到3个最适合的 DataNode,把它们排成一个 pipeline。DataStreamer 把 packet 按队列输出到管道的第一个 DataNode 中,第一个 DataNode又把 packet 输出到第二个 DataNode 中,以此类推。
5.DFSOutputStream 还有一个队列叫 ack queue,也是由 packet 组成,等待DataNode的收到响应,当pipeline中的所有DataNode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
6.客户端完成写数据后,调用close方法关闭写入流。
7.DataStreamer 把剩余的包都刷到 pipeline 里,然后等待 ack 信息,收到最后一个 ack 后,通知 DataNode 把文件标示为已完成。
FastDFS (开源,非国产,轻量级分布式文件系统)
(1)数据库介绍
-
FastDFS 是以C语言开发的一项开源轻量级分布式文件系统,他对文件进行管理,主要功能有:文件存储,文件同步,文件访问(文件上传/下载),特别适合以文件为载体的在线服务,如图片网站,视频网站等
-
分布式文件系统:
基于客户端/服务器的文件存储系统
对等特性允许一些系统扮演客户端和服务器的双重角色,可供多个用户访问的服务器,比如,用户可以“发表”一个允许其他客户机访问的目录,一旦被访问,这个目录对客户机来说就像使用本地驱动器一样
(2)适用场景
特别适合以中小文件( 建议范围: 4KB 到 500MB ) 为载体的在线服务, 如相册网站、 视频网站等等。
(3)性能估算
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lDir4yZn-1658461638292)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113164211721.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UPFJgF0U-1658461638293)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220113164240752.png)]
(4) 优缺点
优点:
海量的存储,主从型分布式存储,存储空间方便拓展,
fastDFS对文件内容做hash处理,避免出现重复文件;
fastDFS结合Nginx集成, 提高网站效率
(5)工作原理架构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qBcQfnRq-1658461638294)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220114163530440.png)]
- 客户端(Client)
客户端指的是访问FastDFS分布式存储的客户端设备,通常是应用服务器。
- 访问服务器(TrackerServer)
TrackerServer是访问(或者翻译为跟踪)服务器,是Client访问 StorageServer 的入口。
TrackerServer起到几个作用:
【服务注册】管理 StorageServer 存储集群, StorageServer 启动时,会把自己注册到TrackerServer上,并且定期报告自身状态信息,包括磁盘剩余空间、文件同步状况、文件上传下载次数等统计信息
【服务发现】Client访问 StorageServer 之前,必须先访问TrackerServer,动态获取到 StorageServer 的连接信息
TrackerServer高可用,为了保证高可用,一个FastDFS集群当中可以有多个TrackerServer节点,由集群自动选举一个leader节点。
- 存储服务器( StorageServer )
StorageServer 是数据存储服务器,文件和meta data都保存到存储服务器上。
可采用高可用的方式进行数据存储FastDFS集群当中 StorageServer 按组(Group/volume)提供服务,不同组的 StorageServer 之间不会相互通信,同组内的 StorageServer 之间会相互连接进行文件同步Storage server采用binlog文件记录文件上传、删除等更新操作。binlog中只记录文件名,不记录文件内容,文件同步只在同组内的Storage server之间进行,采用push方式,即源头服务器同步给目标服务器
- 文件存储
与大多数分布式文件系统类似,FastDFS可以将文件以及相关的描述信息(MetaData)保存到 StorageServer 当中。文件存储以后将返回唯一的“文件标识”,“文件标识”由"组名"和"文件名"两部分构成。
Ceph (开源,非国产,分布式对象存储系统)
(1) 数据库介绍
Ceph 是一种分布式对象存储系统,可以运行在几乎所有主流的Linux发行版(比如CentOS和Ubuntu)和其它类UNIX操作系统(典型如FreeBSD)。Ceph 的分布式基因使其可以轻易管理成百上千个节点、PB级及以上存储容量的大规模集群,同时基于计算的扁平寻址设计使得Ceph 客户端可以直接和服务端的任意节点通信,从而避免因为存在访问热点而导致性能瓶颈。Ceph 是一个统一存储系统,即支持传统的块、文件存储协议,例如SAN和NAS;也支持对象存储协议,例如S3和Swift。
特点:
- 高性能
- 高可用
- 高扩展
- 特性丰富
(2) 适用场景
Ceph 可以提供对象存储、块设备存储和文件系统服务,其对象存储可以对接网盘(owncloud)应用业务等;其块设备存储可以对接(IaaS),当前主流的IaaS运平台软件,如:OpenStack、CloudStack、Zstack、Eucalyptus等以及kvm等。
(3) 性能估算
Ceph 的分布式基因使其可以轻易管理成百上千个节点、PB级及以上存储容量的大规模集群,同时基于计算的扁平寻址设计使得Ceph 客户端可以直接和服务端的任意节点通信,从而避免因为存在访问热点而导致性能瓶颈。
(4) 优缺点
(5)工作原理架构
Ceph是一个分布式对象存储系统,通过它的对象网关(object gateway),也就是RADOS网关(radosgw)提供对象存储接口。RADOS网关利用librgw(RADOS网关库)和librados这些库,允许应用程序跟Ceph对象存储建立连接。Ceph通过RESTful API提供可访问且最稳定的多租户对象存储解决方案之一。RADOS网关提供RESTful接口让用户的应用程序将数据存储到Ceph集群中。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QjvTdoPD-1658461638295)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\image-20220114163014293.png)]
支持三种接口:
- Object:有原生的API,而且也兼容Swift和S3的API。
对象存储 :
通常意义的键值存储,其接口就是简单的GET、PUT、DEL 和其他扩展,代表主要有 Swift 、S3 以及 Gluster 等;
- Block:支持精简配置、快照、克隆。
块存储 :这种接口通常以 QEMU Driver 或者 Kernel Module 的方式存在,这种接口需要实现 Linux 的 Block Device 的接口或者 QEMU 提供的 Block Driver 接口,如 Sheepdog,AWS 的 EBS,阿里云的盘古系统,还有 Ceph 的 RBD(RBD是Ceph 面向块存储的接口)。在常见的存储中 DAS、SAN 提供的也是块存储;
- File :Posix 接口,支持快照。
文件系统存储 :
通常意义是支持 POSIX 接口,它跟传统的文件系统如 Ext4 是一个类型的,但区别在于分布式存储提供了并行化的能力,如 Ceph 的 Ceph FS (Ceph FS 是 Ceph 面向文件存储的接口),但是有时候又会把 GlusterFS ,HDFS 这种非POSIX接口的类文件存储接口归入此类。当然 NFS、NAS也是属于文件系统存储;
Ceph 核心组件,概念


-
Monitor :保存同步OSD元数据 (可以是OSD中的一员充当Monitor)
-
OSD :OSD全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph 集群一般都有很多个OSD。
-
MDS :MDS全称Ceph Metadata Server,是Ceph FS服务依赖的元数据服务。
-
Object:Ceph 最底层的存储单元是Object对象,每个Object包含元数据和原始数据。
-
PG : PG是一个逻辑概念,我们linux系统中可以直接看到对象,但是无法直接看到PG。它在数据寻址时类似于数据库中的索引:每个对象都会固定映射进一个PG中,所以当我们要寻找一个对象时,只需要先找到对象所属的PG,然后遍历这个PG就可以了,无需遍历所有对象。而且在数据迁移时,也是以PG作为基本单位进行迁移,Ceph 不会直接操作对象。
PG全称Placement Grouops,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
-
RADOS :RADOS全称Reliable Autonomic Distributed Object Store,是Ceph 集群的精华,用户实现数据分配、Failover等集群操作。
-
Libradio :Librados是Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和Ceph FS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
-
CRUSH :CRUSH是Ceph 使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。 Ceph 的高性能/高可用就是采用这种算法实现。CRUSH 算法取代了在元数据表中为每个客户端请求进行查找,
作用:它通过计算系统中数据应该被写入或读出的位置。CRUSH能够感知基础架构,能够理解基础设施各个部件之间的关系。并CRUSH保存数据的多个副本,这样即使一个故障域的几个组件都出现故障,数据依然可用。CRUSH 算是使得 Ceph 实现了自我管理和自我修复。
-
RBD(块存储):RBD全称RADOS block device,是Ceph 对外提供的块设备服务。
-
RGW(对象存储):RGW全称RADOS gateway,是Ceph 对外提供的对象存储服务,接口与S3和Swift兼容
-
Ceph FS(文件系统):Ceph FS全称Ceph File System,是Ceph 对外提供的文件系统服务。
Ceph 数据存储过程
无论使用哪种存储方式(对象、块、文件系统),存储的数据都会被切分成Objects。Objects size大小可以由管理员调整,通常为2M或4M。每个对象都会有一个唯一的OID,由ino 与 ono 生成,虽然这些名词看上去很复杂,其实相当简单。

**ino :**即是文件的File ID,用于在全局唯一标识每一个文件
**ono:**则是分片的编号
一个文件FileID为A,它被切成了两个对象,一个对象编号0,另一个编号1,那么这两个文件的oid则为A0与A1。
File : 此处的file就是用户需要存储或者访问的文件。
对于一个基于Ceph 开发的对象存储应用而言,这个file也就对应于应用中的“对象”,也就是用户直接操作的“对象”。
**Ojbect: **此处的object是RADOS所看到的“对象”
Object与上面提到的file的区别是,object的最大size由RADOS限定(通常为2MB或4MB),以便实现底层存储的组织管理。因此,当上层应用向RADOS存入size很大的file时,需要将file切分成统一大小的一系列object(最后一个的大小可以不同)进行存储。为避免混淆,在本文中将尽量避免使用中文的“对象”这一名词,而直接使用file或object进行说明。
OSD —— 即object storage device,
OSD的数量事实上也关系到系统的数据分布均匀性,因此其数量不应太少。在实践当中,至少也应该是数十上百个的量级才有助于Ceph 系统的设计发挥其应有的优势。
PG(Placement Group),PG的用途是对object的存储进行组织和位置映射。
一个PG负责组织若干个object(可以为数千个甚至更多),但一个object只能被映射到一个PG中,即,PG和object之间是“一对多”映射关系。同时,一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG,即,PG和OSD之间是“多对多”映射关系。在实践当中,n至少为2,如果用于生产环境,则至少为3。一个OSD上的PG则可达到数百个。事实上,PG数量的设置牵扯到数据分布的均匀性问题。关于这一点,下文还将有所展开。
基于上述定义,便可以对寻址流程进行解释了。具体而言, Ceph 中的寻址至少要经历以下三次映射:
(1)File -> object映射
(2)Object -> PG映射,hash(oid) & mask -> pgid
(3)PG -> OSD映射,CRUSH算法9
参考文献:[1](Ceph介绍(一):基本原理_Yannick Jiang 的专栏-CSDN博客_ceph](https://blog.csdn.net/don_chiang709/article/details/89472242)