机器学习笔记(24)一种简单的半监督目标检测框架(1)
早上起来洗漱,昨晚没睡好,晕晕乎乎的,洗着洗着脑子中突然出现了下面的图2,这是很久之前看到的论文了,可能是因为最近看了些半监督学习的东西,就想起了这篇论文。忙里偷闲,翻译一下。
首先指出:这是一种很朴素的半监督思想的应用,但是很work
流程
在第一阶段,使用所有标记的数据训练一个目标检测器(例如,Faster RCNN)直到收敛。然后使用训练过的检测器预测未标记图像的边界框和类标签(也就是生成初步的伪标签的过程),如图所示。然后,受FixMatch设计的启发,对每个高阈值的预测框(经过NMS)进行基于置信度的滤波,获得高精度的伪标签。第二阶段对每幅未标记图像进行强数据增强,利用第一阶段生成的标记数据训练出的模型和未标记数据及其伪标签进行训练。受RandAugment及其对SSL和目标检测的成功适应的鼓舞,我们设计了目标检测的增强策略,其中包括全局颜色变换、全局或box级几何变换和Cutout。其过程可表示为:
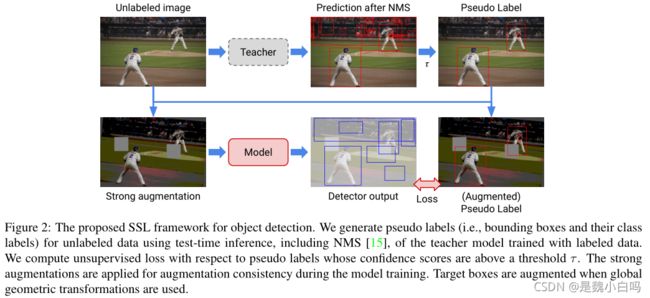
注意看解释文字,上面所述的只是一个大致流程,在实现STAC时还有一些细节。
首先是如何利用标记数据训练一个好的teacher网络。
然后是在生成伪标签的时候需要使用包括NMS在内的test-time inference。
还会设定一个阈值τ,用于过滤伪标签的置信度。
为了保持增强一致性(augmentation consistency),训练过程还会使用强增强(strong augmentations)。
当使用全局几何变换时,目标框也会得到增强。
最后,计算经τ阈值筛选后的伪标签的无监督损失。
简介
近几年来,半监督学习(SSL)受到了越来越多的关注,因为它提供了在无法获得大规模带注释数据时使用未标记数据来提高模型性能的方法。一类流行的SSL方法基于“基于一致性的自我训练”。其关键思想是首先为未标记的数据生成人工标签(就是传统意义上的伪标签的制作过程),并训练模型在向未标记的数据提供语义保留随机增强时预测这些人工标签(The key idea is to first generate the artificial labels for the unlabeled data and train the model to predict these artificial labels when feeding the unlabeled data with semanticity-preserving stochastic augmentations. )。人工标签可以是one-hot预测(硬)或模型的预测分布(软)。SSL成功的另一个支柱是数据增强方面的进步。数据增强提高了深层神经网络的鲁棒性,并已证明对基于一致性的自我训练特别有效。扩充策略可由一些手工的图像变换结合而来,例如旋转、平移、翻转或颜色抖动,用于神经图像合成和通过强化学习学习学习的策略。最近,RandAugment或CTAugment等复杂的数据增强策略已证明对图像分类上的SSL非常有效。
SSL方法在取得显著进展的同时,主要应用于图像分类。图像分类任务与计算机视觉中的其他重要问题(如目标检测)相比,SSL方法的标记成本相对较低。由于其昂贵的标记成本,目标检测要求更高级别的标记效率,因此需要开发强大的SSL方法。另一方面,关于目标检测的大多数现有工作都集中在训练一个更强的和更快的检测器,只要有足够的注释数据。用于目标检测的SSL的现有工作很少依赖于额外的上下文,例如目标的类别相似性。
在这项工作中,我们利用从图像分类的深度SSL方法中获得的经验来解决对象检测的SSL问题。为此,我们提出了一个用于目标检测的SSL框架,该框架结合了自训练(通过伪标签)和基于强数据增强的一致性正则化。受NoiseStudent中框架的启发,我们的系统包含两个培训阶段。
流程如上
在公共数据集:MSCOCO和PASCAL VOC上测试STAC的有效性。使用MS-COCO数据集设计了新的实验协议来评估半监督目标检测性能。我们使用1%、2%、5%和10%的标记数据作为标记集,其余数据作为未标记集来评估SSL方法在低标记区域(环境区域)中的有效性。此外参考之前的一些工作,使用所有标记数据作为标记集,使用MS-COCO提供的其他未标记数据作为未标记集进行评估。另外可以使用VOC07的trainval作为标记集,使用带有或不带有MS-COCO未标记数据的VOC12的trainval作为未标记集。虽然简单,但STAC带来了显著的mAPs的收益:5%方案中从18.47提升至了24.38,在10%方案中,从23.86提升至28.64,以及在PASCAL VOC中从42.60提升至了46.01。
STAC的贡献归结为:1.开发了STAC,这是一个用于目标检测的SSL框架,它无缝地扩展了基于自训练和增强驱动的一致性正则化的最新SSL分类方法。2.STAC很简单,只引入了两个新的超参数:置信阈值τ和无监督损失权重λu,这不需要进行大量的额外调整。3.提出了使用MS-COCO进行SSL对象检测的新实验协议,并在Faster-RCNN框架中证明了STAC对MS-COCO和PASCAL VOC的有效性。
目标检测是一项基本的计算机视觉任务,得到了广泛的研究。流行的目标检测框架包括基于区域的CNN(RCNN)、YOLO、SSD等。现有工作所取得的进展主要是在提供足够数量的注释数据的情况下,训练更强或更快的目标检测器。研究者们对通过半监督目标检测框架,使用未标记的训练数据改进检测器的兴趣越来越大。在深入学习之前,这个想法已经被探索过了。最近有人提出了一种基于一致性的半监督目标检测方法,该方法强制执行未标记图像及其翻转对应图像的一致性预测。他们的方法需要更复杂的Jensen-Shannon散度来进行一致性正则化计算。在目标检测的主动学习设置中,也研究了一致性正则化的类似思想。还有人提出了一个自监督提案学习模块,用于从未标记数据中学习上下文感知和噪声鲁棒提案特征。也有人提出了一种数据提取方法,该方法通过对未标记数据的多次变换的预测进行置乱来生成标签。我们认为,更强的半监督检测器需要进一步研究无监督目标和数据增强。
半监督学习:近几年来,半监督学习(SSL)在图像分类中得到了很大的发展。一致性正则化是最近几种方法中比较流行的方法之一,并启发了之后的一些目标检测的研究。它想法是强制模型去生成一致的预测跨标签保留的数据扩展。一些例子包括Means-Teacher、UDA和MixMatch。SSL的另一个流行类别是伪标记,它可以被视为一致性正则化的硬版本:该模型执行自训练以生成未标记数据的伪标记,从而训练随机扩充的未标记数据以匹配相应的伪标记。如何使用伪标签是SSL成功的关键。例如,Noise-Students演示了一个迭代的teacher-student框架,该框架重复了使用教师模型标记作业,然后训练更大的学生模型的过程。该方法通过利用额外的未标记图像,实现了ImageNet分类的最先进性能。FixMatch展示了一个简单的算法,该算法优于以前的方法,并建立了最先进的性能,特别是在各种小标签数据机制上。FixMatch背后的关键思想是当弱扩充数据的模型置信度较高时,将强扩充未标记数据的预测与弱扩充数据的伪标签进行匹配。鉴于这些方法的成功,本文利用伪标记和伪box的有效使用以及数据扩充来改进目标检测器。
数据扩充(扩充)是提高模型泛化和鲁棒性的关键,逐渐成为半监督学习的主要推动力。找到合适的颜色变换和输入空间的几何变换已被证明是提高泛化性能的关键。然而,大多数增强算法主要是在图像分类方面进行研究。由于数据的全局几何变换影响边界框注释,因此用于目标检测的数据扩充的复杂性远远高于图像分类。一些工作已经提出了用于监督目标检测的增强技术,例如Mixup、CutMix或增强策略学习。最近的基于一致性的SSL对象检测方法利用全局水平翻转(弱增强)来构造一致性损失。就我们所知,密集的数据增长对半监督目标检测的影响还没有得到深入的研究。
方法论
STAC大体过程
基于自训练(通过伪标签)和增强驱动一致性正则化,我们提出了一个简单的SSL目标检测框架,称为STAC。首先,针对Noisy-Student的可扩展性和灵活性,我们采用了分阶段的训练。在第一阶段,使用所有可用的标记数据来训练教师模型,在第二阶段,我们使用标记数据和未标记数据来训练STAC。其次,在FixMatch的基础上提出了一种基于置信度的阈值来控制目标检测中由box及其类别标签组成的伪标签的质量。训练STAC的步骤总结如下:1.根据可用的标签图像训练teacher模型。2.利用训练好的teacher模型生成未标注图像的伪标签(即box及其类别标签)。3.对未标记的图像进行强数据增强,在进行全局几何变换时,相应地增加伪标签(即边界框)。4.计算非监督损失和监督损失,训练检测器。 下面详细介绍各部分。
训练teacher网络
我们基于Faster-RCNN开发,因为它已经成为最具代表性的检测框架之一。Faster-RCNN在共享主干网络之上有一个分类器(CLS)和一个区域建议网络(RPN)头部。每个head具有两个模块,即区域分类器(例如,用于CLS head的(K+1)路分类器或用于RPNhead的二进制分类器)和box回归器(REG)。为简单起见,下面给出了RPN head的Faster-RCNN的监督损失。
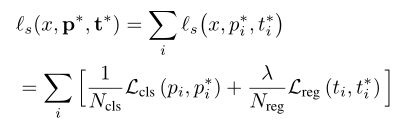
生成伪标签
从tescher模型对目标检测器进行test-time inference,以生成伪标签。也就是说,伪标签的生成不仅涉及骨干网、RPN和CLS网络的前向传递,而且还包括非最大抑制(NMS)等后处理。这不同于传统的分类方法,在传统方法中,置信度分数是根据原始预测概率计算的。使用NMS后返回的每个box的得分,聚合archor-box的预测概率。在NMS之后使用box预测比使用原始预测(在NMS之前)更有优势,因为其消除了重复预测。但是,这不会过滤出错误位置的box,因此需要应用基于置信度的阈值来进一步减少潜在的错误的pseudo-box。
无监督损失
注意无监督损失发生在伪标签生成后利用伪标签以及对应数据和训练好的teacher网络重新训练模型阶段。所以archor就是网络训练过程中的输出结果。
最先进的方法,例如无监督数据增强和修复匹配,将强数据增强A(例如随机增强或CTAugment)应用于模型预测p(A(X);θ)以提高鲁棒性。Noise-Students网络将不同形式的随机噪声应用于模型预测,包括通过随机增强增加输入,通过辍学和随机深度增加网络。虽然它们在模型预测上有相似之处,但在生成预测目标的方法上有所不同。与方程(2)和前述的许多算法不同,Noise-Students算法采用P(·,θ)以外的“教师”网络来生成伪标签q(X)。请注意,固定教师网络允许离线伪标签生成,这提供了对大型无标签数据的可扩展性以及选择架构或优化的灵活性。
给定一个无标记的图像x,一系列预测得到的边界框(box)以及他们的区域提议分数,对于所有锚,我们确定qi,即关于pseudo boxes的archor的二进制标签。注意简单的阈值机制w被应用在qi通过使用CLS head,如果archor与任一teacher模型的CLS预测置信度分数高于阈值τ的pseudo boxes相关,则为1,否则为0。让s表示pseudo的box置信度。那么,无监督STAC的RPN loss写为:
![]()
其中的变形A代表应用在无标签数据x的强数据增强。此处注意,由于一些变换操作不是长方体坐标不变的(例如,全局几何变换),因此数据增强也适用于伪长方体坐标,从而产生新值。(数据增强之后,相应的伪标签要随之变化。)
最后,通过结合最小化两个损失训练RPN:
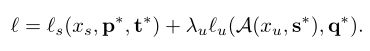
STAC引入了两个超参数τ和λu。实验表明,τ=0.9和λu∈[1,2]性能良好。请注意,以前的基于一致性的SSL对象目标方法需要对λ进行复杂的加权调度,包括时间ramp-up和ramp-down。取而代之的是,STAC的框架以一个简单的恒定时间表展示了有效性,这要归功于使用强大的数据增强和基于置信度的阈值的一致性正则化。
数据增强策略
基于一致性的SSL方法(如UDA和FixMatch)成功的关键因素是强大的数据增强。虽然监督和半监督图像分类的增强策略已经得到了广泛的研究,但在目标检测方面还没有做太多的工作。我们使用最近由[70]提出的扩充搜索空间(例如,盒级变换)和剪裁来扩展中用于目标检测的随机增强(RandAugment)。我们探索了变换运算的不同变体,并确定了一组有效的组合。每一次操作都有一个大小,这决定了强度的增强程度。
1.全局颜色转换(C):使用颜色转换操作和每个OP的建议幅度范围。2.全局几何变换(G):使用几何变换操作,即x-y平移、旋转和x-y剪切。3.框级变换(B):使用全局几何变换的三种变换操作,但幅度范围较小(限制在box内,可以观察图3,展示了几种数据增强的直挂效果)。
对于每个图像,我们按如下顺序应用变换操作。首先,我们应用从C中采样的一个操作。其次,我们应用从G或者B中采样的操作之一。最后,我们在整个图像的多个随机位置应用裁剪,以防止仅在边界框内应用无关紧要的解决方案。在图3中,我们使用前面提到的增强策略可视化转换后的图像。
对于以上内容可能存在的疑问的解答
无监督损失中的q,模型在未标记数据上做预测后的置信度值与一个阈值τ的对比状态量,大于就是1,小于就是0。无监督损失中的s是伪标签的box坐标值。
那这不是也利用了box吗,还是无监督吗。是的,因为伪标签不是手工标注的,是有teacher模型预测生成的,理论上同样属于无监督任务。而且这里所谓的无监督其实更偏向于上面所述的q状态量的作用。
teacher网络在训练时使用的单纯的监督loss,重新训练时使用的无监督loss和监督loss的结合,可以认为这是“STAC在试图探索如何更有效的利用伪标签”