python scrapy 爬取steam游戏
目标网页:
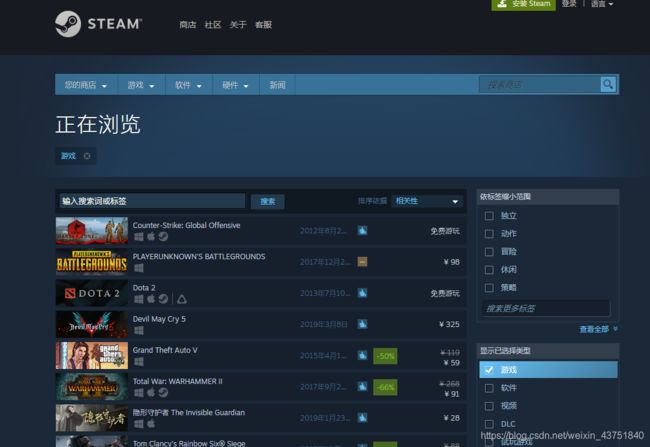
游戏列表页
游戏详情页

游戏评论

目标数据:
列表页:游戏标题,游戏价格,折扣,评论总数,好评比例,游戏发布时间
详情页:游戏图片,游戏简介,游戏评论
首先创建一个scrapy项目

根据规律构造列表页的请求地址


分析标签,抓取数据
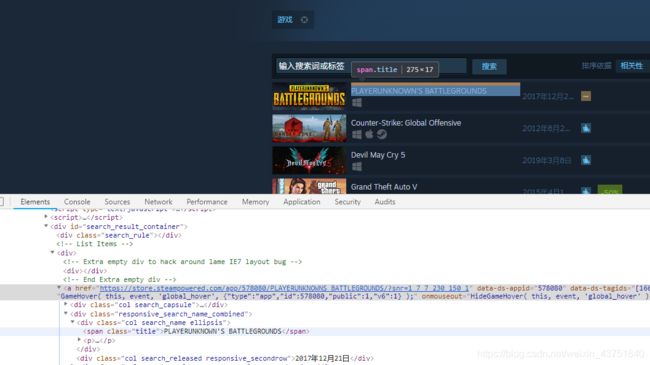
标题↑,价格↓
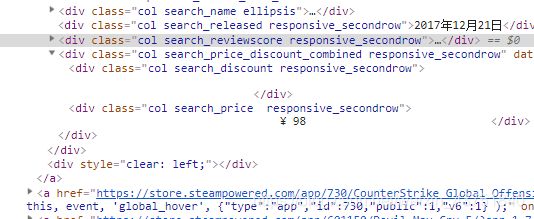
列表页解析函数
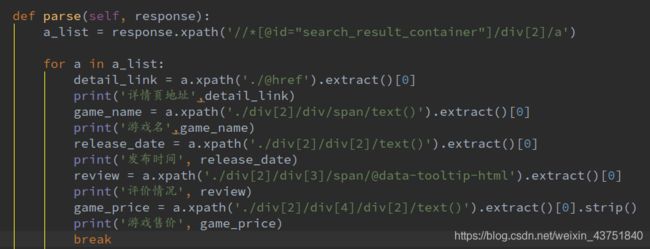
测试打印第一条数据

然后开始构建详情页请求(这里一定要加accept-language这个请求头,不然会返回英文页面)

详情页的解析函数

测试打印数据

接下来获取游戏评论
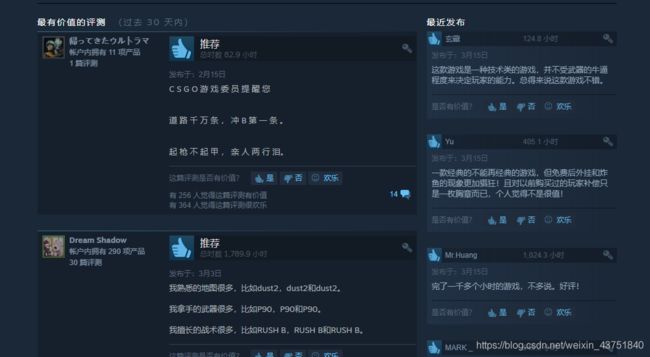
游戏评论没有和主页面一起加载,通过分析网络请求,发现了评论的请求地址
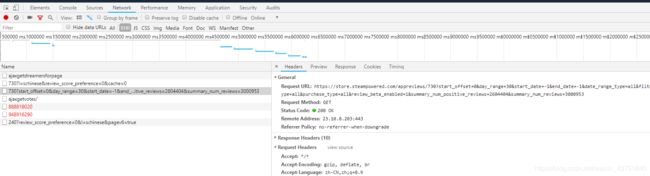
此地址需要传入参数,经过测试,至少需要这几个参数

里面的730为游戏id,可以通过正则从详情页地址中获取,后面两个参数设置为筛选中文评论
继续刚才的代码↓

发起评论页请求
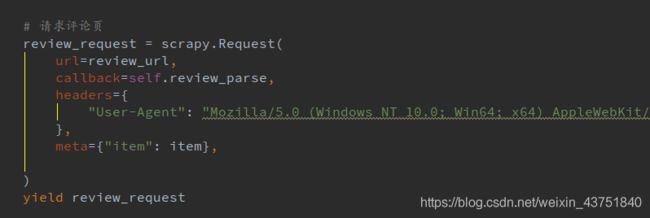
回调到评论的解析函数
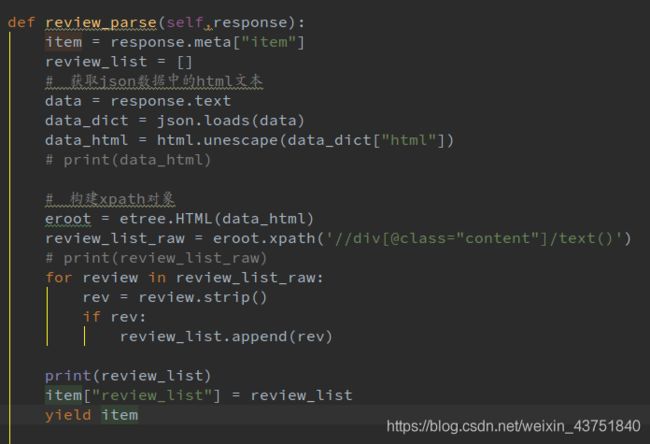
因为返回的是json数据,所以不能再用selector对象提取。这里的思路是先从response里获取内容,然后用json转成字典,从字典中取出html,再用xpath提取数据
这里直接用xpath提取出来的评论包含很多空格,有些还是空评论,所以加条件处理了一下。
打印一下评论列表

提取代码写完后,修修改pipline文件,把数据保存到mongodb
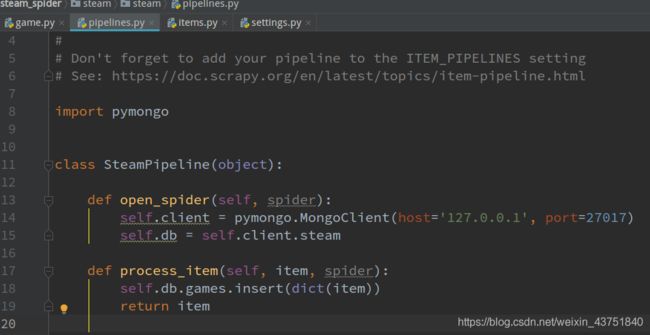
查看数据库

评论信息
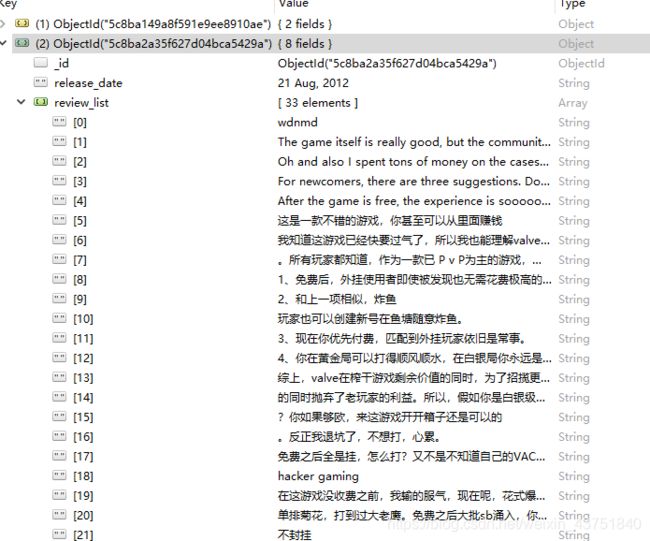
这里发现评论有点问题,本来是一条评论被拆成了好几条数据存,查看html源码
![]()
发现可能是标签套标签的缘故,xpath提取的不好,改用beautifulsoup
重写提取部分的代码

打印

大段评论成功合成一条数据
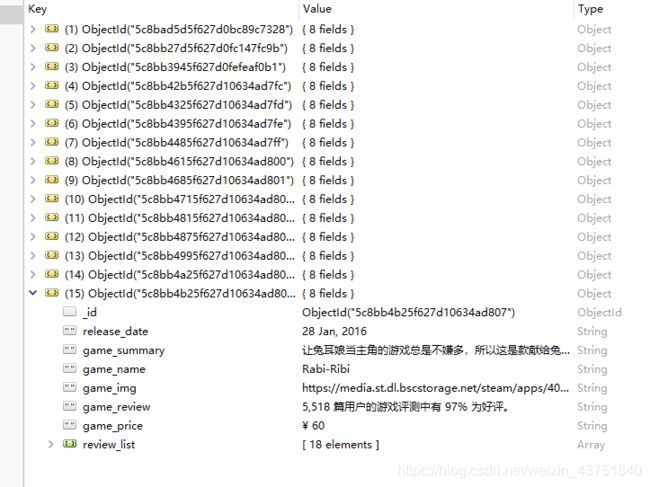
查看数据库

开始测试批量爬取
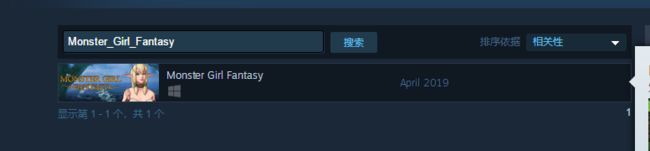
大部分没有问题,但是有些数据的价格没有爬到

查看原网页

发现可能是因为价格打折的原因,使得标签不一样了
修改提取规则,增加判断条件

这样价格有折扣的话,也可以正常获取了

爬取过程中还发现了其他问题,
这种情况,价格和评论缺失
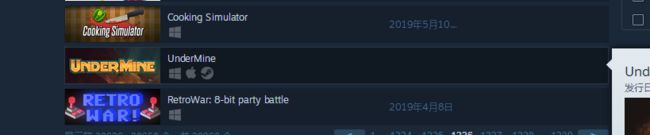
或者这种情况,只能提取到一个标题
为了防止因为数据缺失造成程序报错终止,在数据解析的部分加入了异常处理
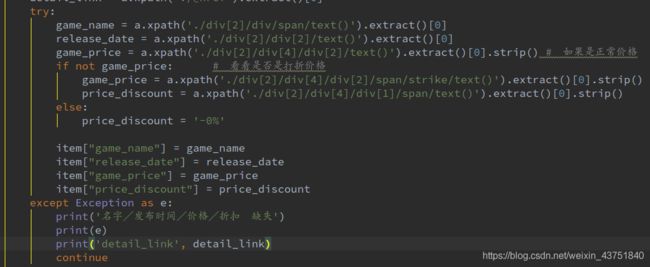
使用try-except捕获异常,打印异常原因。
爬取过程中,还出现了列表页的detail_url提取不到的情况,因此在发送详情页请求前加入了异常捕获。
如果请求异常,将request对象设置为空提交给引擎。
然后修改引擎的爬虫中间件,加一个判断,如果收到空置,就跳过,不交给解析组件。


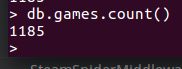
最后爬取完毕
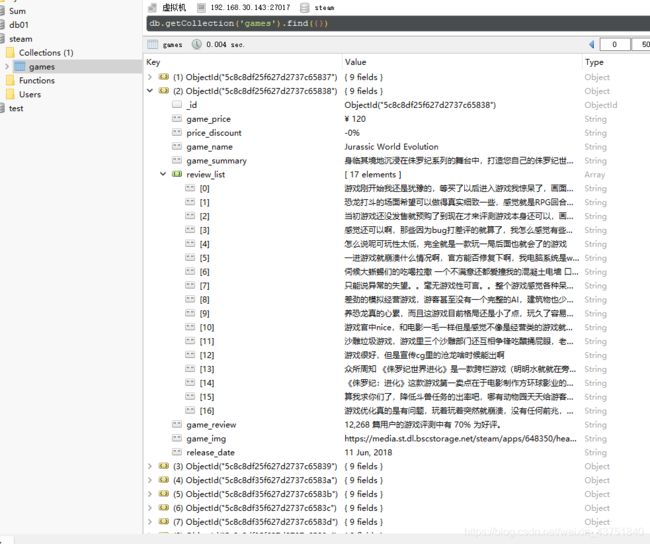
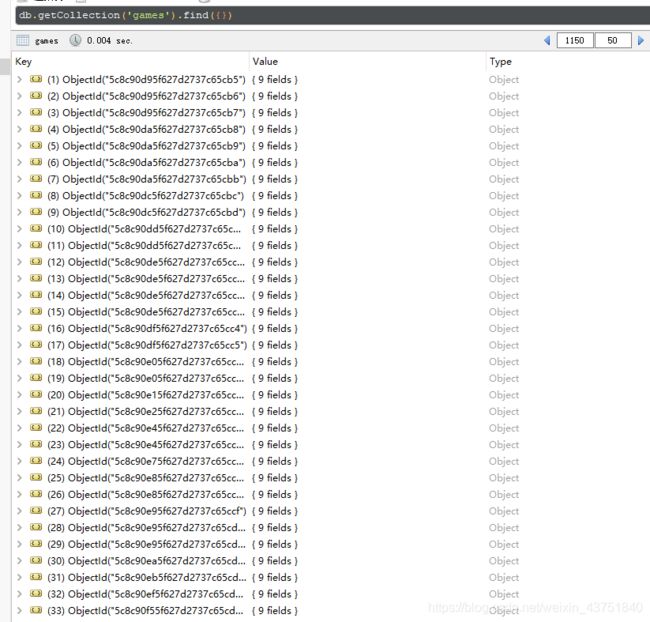
总共1185条数据
完整代码:
game.py
# -*- coding: utf-8 -*-
import html
import json
import scrapy
from ..items import SteamItem
import re
from bs4 import BeautifulSoup
class GameSpider(scrapy.Spider):
name = 'game'
allowed_domains = ['store.steampowered.com']
# 生成列表页url
start_urls = []
base_url = 'https://store.steampowered.com/search/?category1=998&page={}'
for page in range(1, 1239):
start_urls.append(base_url.format(page))
# break
def parse(self, response):
a_list = response.xpath('//*[@id="search_result_container"]/div[2]/a')
for a in a_list:
item = SteamItem()
# 统一设置默认值
item["game_name"] = ''
item["release_date"] = ''
item["game_price"] = ''
item["game_review"] = ''
item["game_summary"] = ''
item["game_img"] = ''
item["review_list"] = ''
detail_link = a.xpath('./@href').extract()[0]
try:
game_name = a.xpath('./div[2]/div/span/text()').extract()[0]
release_date = a.xpath('./div[2]/div[2]/text()').extract()[0]
game_price = a.xpath('./div[2]/div[4]/div[2]/text()').extract()[0].strip() # 如果是正常价格
if not game_price: # 看看是否是打折价格
game_price = a.xpath('./div[2]/div[4]/div[2]/span/strike/text()').extract()[0].strip()
price_discount = a.xpath('./div[2]/div[4]/div[1]/span/text()').extract()[0].strip() # 如果有打折,提取折扣力度
else:
price_discount = '-0%'
item["game_name"] = game_name
item["release_date"] = release_date
item["game_price"] = game_price
item["price_discount"] = price_discount
except Exception as e:
print('名字/发布时间/价格/折扣 缺失')
print(e)
print('detail_link', detail_link)
continue
# 请求详情页
detail_request = scrapy.Request(
url=detail_link,
callback=self.detail_parse,
headers={
"Accept-Language": "zh-CN,zh;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
},
meta={"item": item, 'detail_link': detail_link},
)
yield detail_request
break
def detail_parse(self, response):
item = response.meta["item"]
detail_link = response.meta["detail_link"]
try:
game_summary = response.xpath('//div[@class="game_description_snippet"]/text()').extract()[0].strip()
game_review = response.xpath('//div[@class="user_reviews"]/div[2]/@data-tooltip-html').extract()[0]
game_img = response.xpath('//img[@class="game_header_image_full"]/@src').extract()[0]
item["game_review"] = game_review
item["game_summary"] = game_summary
item["game_img"] = game_img
except Exception as e:
print('简介/评论/图片 缺失')
print(e)
# 生成评论页url
try:
game_id = re.search('https://store.steampowered.com/app/(\d+)/.*?', detail_link).group(1)
review_url = "https://store.steampowered.com/appreviews/{}?filter=summary&language=schinese&l=schinese".format(game_id)
# 请求评论页
review_request = scrapy.Request(
url=review_url,
callback=self.review_parse,
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
},
meta={"item": item},
)
except Exception as e:
print('正则', detail_link)
print(e)
review_request = ''
yield review_request
def review_parse(self, response):
item = response.meta["item"]
review_list = []
try:
# 获取json数据中的html文本
data = response.text
data_dict = json.loads(data)
data_html = html.unescape(data_dict["html"])
# 构建bs4对象
soup = BeautifulSoup(data_html, 'lxml')
div_list = soup.select('div[class="content"]')
for div in div_list:
review = div.get_text()
rev = review.strip()
if rev:
review_list.append(rev)
except Exception as e:
print('评论缺失,无法解析')
print(e)
item["review_list"] = review_list
yield item
pipelines.py
import pymongo
class SteamPipeline(object):
def open_spider(self, spider):
self.client = pymongo.MongoClient(host='127.0.0.1', port=27017)
self.db = self.client.steam
def process_item(self, item, spider):
self.db.games.insert(dict(item))
return item
middlewars.py
from scrapy import signals
class SteamSpiderMiddleware(object):
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
if i: # 尝试跳过url为空的请求
yield i
items.py
import scrapy
class SteamItem(scrapy.Item):
# define the fields for your item here like:
game_name = scrapy.Field()
release_date = scrapy.Field()
game_review = scrapy.Field()
game_price = scrapy.Field()
game_summary = scrapy.Field()
game_img = scrapy.Field()
review_list = scrapy.Field()
price_discount = scrapy.Field()
settings.py
ITEM_PIPELINES = {
'steam.pipelines.SteamPipeline': 300,
}