MTCNN目标检测实战—基于PyTorch的人脸检测算法实战
目录
一、MTCNN简介:
1、什么是MTCNN
2、MTTCNN的作用
3、MTCNN的优缺点
1优点
2缺点
二、人脸检测
三、MTCN的网络模型
四、准备训练样本
1、获取原始数据集
2、准备训练样本
1、训练样本的构成
2、建立数据集样本
3.生成样本数据代码
五、创建网络模型
1PNet
2RNet
3ONet
六、小工具IOU和NMS的创建
IOU(Intersection over Union)交并比
NMS(Non-maximum suppression)非极大值抑制
七、创建采样器
八、创建训练文件
九、检测训练效果
一、MTCNN简介:
1、什么是MTCNN
MTCNN的“MT”是指多任务学习(Multi-Task),CNN(Convolutional Neural Networks, CNN)是指卷积神经网络。MTCNN多任务级联卷积神经网络,基于级联的特定目标检测器,在人脸识别中有着出色的表现。
2、MTTCNN的作用
在目标检测中,MTCNN可以用来检测和识别学习到的目标,这个目标是有一定讲究的,比如对于同类外观相差不大的不同目标可以很好地区分,如果用来区分不同种类的不同目标可能会有些大材小用。
3、MTCNN的优缺点
1优点
1、设备要求低:使用了级联思想,将复杂问题分解,使得模型能够在小型设备上运行,比如人脸监测模型可以在没有GPU的设备上运行。
2、容易训练:三个级联网络都较小,训练模型时容易收敛。
3、精度较高:使用了级联思想,逐步提高精度。
2缺点
1、误检率较高:因为采用了级联的思想,使得模型在训练过程中的负样本偏少,学到的模型不够100%准确。
2、改进空间大:MTCN原论文模型在发表时距今已过去好几年了,随着技术的不断进步,对于原模型可以做出很多优化。
二、人脸检测
人脸检测是指对于任意一幅给定的图像,采用一定的策略对其进行搜索以确定其中是否含有人脸,如果是则返回一脸的位置、大小和姿态。(来源:百度百科)
人脸识别与人脸检测的关系
人脸识别包含三个阶段:
第一阶段人脸检测;第二阶段:特征提取;第三阶段:人脸对比
常用人脸检测架构:MTCNN、yolo系列、SSD、RCNN系列,FastRCNN系列
三、MTCN的网络模型
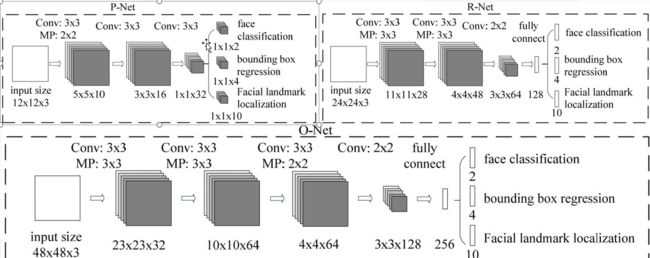
在MTCNN中主要有三层网络分别是:
P网络:模型训练过程中输入12x12的图像,输出置信度和人脸偏移量。
R网络:输入图像的大小为24x24,对R网络的输出图像和偏移值作进一步处理,处理货的图像和偏移值输入到R网络
O网络:输入的图像的大为48x48,对R网络输出的图像进行最终的判别,最终确定人脸的位置。
四、准备训练样本
1、获取原始数据集
本次模型训练采用Celeba数据集,
下载好Celeba的数据集是一个压缩包,解压之后得到以下文件夹,
打开第img\img_celeba.7z文件夹,一次性选中所有的的文件夹,一次性选中所有的压缩包解压到指定位置,笔者存放的路径为E:\CelebA\Img\img_celeba.7z\img_celeba
解压完成如图:
2、准备训练样本
1、训练样本的构成
1.种类
本项目需要准备三种样本:正样本:负样本:部分样本约等于1:1:3,之所以部分样本比较多是因为在级联处理中负样本会大量丢失,这样做的目的是为了保证最后进入R网络 和O网络三种样本的比例均衡。
正样本:整张图全是人脸
负样本:图像为背景
部分样本:一张图中有部分是人脸,另外一部分是非人脸。
2.形状
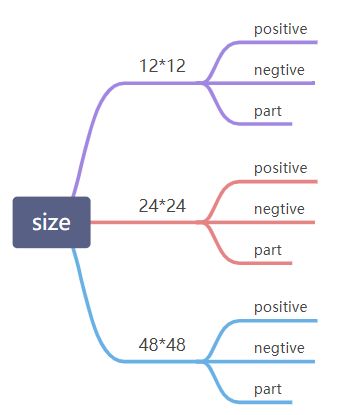
本项目的训练样本共涉及三种大小:12x12(用于P网络训练),24x24(用于R网络训练),48x48(用于O网络训练)
2、建立数据集样本
建立数据集样本应注意以下几点:
1:图片路径和标签一一对应,方便训练时读取数据
2:三个网络是分开训练,不同大小的图片各自有各自的正样本,负样本和部分样本。
3:部分和负样本样本是在正样本附近偏移得到得到
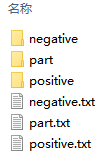
最终得到数据样本是这个样子:

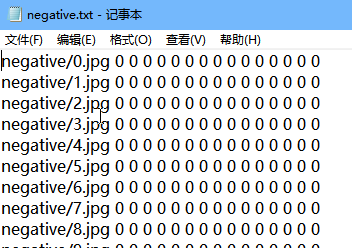
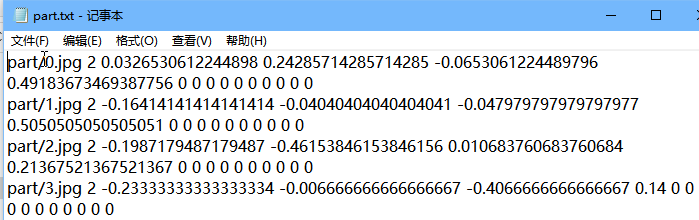
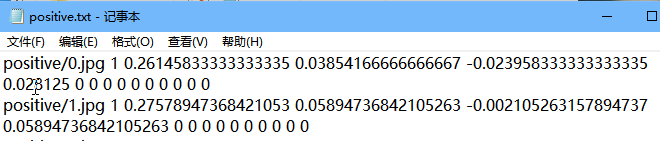
3.生成样本数据代码
import os
from PIL import Image
import numpy as np
from MTCNN.tool import utils
import traceback
anno_src = r"E:\CelebA\Anno\list_bbox_celeba.txt" #原来的样本数据(在生成样本时使用)
img_dir = r"E:\CelebA\Img\img_celeba.7z\img_celeba" #源图片(用于生成新样本)
save_path = r"E:\CelebA\MTCN\dataSet" #生成样本的总的保存路径
float_num = [0.1, 0.5, 0.5, 0.5, 0.9, 0.9, 0.9, 0.9, 0.9] #控制正负样本比例,(控制比例?)
def gen_sample(face_size,stop_value):
print("gen size:{} image" .format(face_size))
positive_image_dir = os.path.join(save_path, str(face_size), "positive") #仅仅生成路径名
negative_image_dir = os.path.join(save_path, str(face_size), "negative")
part_image_dir = os.path.join(save_path, str(face_size), "part")
for dir_path in [positive_image_dir, negative_image_dir, part_image_dir]: #生成路径
if not os.path.exists(dir_path):
os.makedirs(dir_path)
positive_anno_filename = os.path.join(save_path, str(face_size), "positive.txt")
negative_anno_filename = os.path.join(save_path, str(face_size), "negative.txt")
part_anno_filename = os.path.join(save_path, str(face_size), "part.txt")
positive_count = 0
negative_count = 0
part_count = 0
try: #抛出异常
positive_anno_file = open(positive_anno_filename, "w")
negative_anno_file = open(negative_anno_filename, "w")
part_anno_file = open(part_anno_filename, "w")
for i, line in enumerate(open(anno_src)): #txt开头的两行文件不是路径和标签,需要跳过
if i < 2:
continue
try:
strs = line.split() #列表,包含路径和坐标值
image_filename = strs[0].strip() #置信度 #Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
# print(image_filename)
image_file = os.path.join(img_dir, image_filename)
with Image.open(image_file) as img:
img_w, img_h = img.size #原图
x1 = float(strs[1].strip())
y1 = float(strs[2].strip())
w = float(strs[3].strip()) #人脸框
h = float(strs[4].strip())
x2 = float(x1 + w)
y2 = float(y1 + h)
px1 = 0#float(strs[5].strip())
py1 = 0#float(strs[6].strip())
px2 = 0#float(strs[7].strip())
py2 = 0#float(strs[8].strip())
px3 = 0#float(strs[9].strip())
py3 = 0#float(strs[10].strip())
px4 = 0#float(strs[11].strip())
py4 = 0#float(strs[12].strip())
px5 = 0#float(strs[13].strip())
py5 = 0#float(strs[14].strip())
if x1 < 0 or y1 < 0 or w < 0 or h < 0: #跳过坐标值为负数的
continue
boxes = [[x1, y1, x2, y2]] #当前真实框四个坐标(根据中心点偏移), 二维数组便于IOU计算
#求中心点坐标
cx = x1 + w / 2
cy = y1 + h / 2
side_len = max(w, h)
seed = float_num[np.random.randint(0, len(float_num))] #取0到9之间的随机数作为索引 #len(float_num) = 9 #float_num = [0.1, 0.5, 0.5, 0.5, 0.9, 0.9, 0.9, 0.9, 0.9]
count = 0
for _ in range(4):
_side_len = side_len + np.random.randint(int(-side_len * seed), int(side_len * seed)) #生成框
_cx = cx + np.random.randint(int(-cx * seed), int(cx * seed)) #中心点作偏移
_cy = cy + np.random.randint(int(-cy * seed), int(cy * seed))
_x1 = _cx - _side_len / 2 #左上角
_y1 = _cy - _side_len / 2
_x2 = _x1 + _side_len #右下角
_y2 = _y1 + _side_len
if _x1 < 0 or _y1 < 0 or _x2 > img_w or _y2 > img_h: #左上角的点是否偏移到了框外边,右下角的点大于图像的宽和高
continue
offset_x1 = (x1 - _x1) / _side_len #得到四个偏移量
offset_y1 = (y1 - _y1) / _side_len
offset_x2 = (x2 - _x2) / _side_len
offset_y2 = (y2 - _y2) / _side_len
offset_px1 = 0#(px1 - x1_) / side_len #offset偏移量
offset_py1 = 0#(py1 - y1_) / side_len
offset_px2 = 0#(px2 - x1_) / side_len
offset_py2 = 0#(py2 - y1_) / side_len
offset_px3 = 0#(px3 - x1_) / side_len
offset_py3 = 0#(py3 - y1_) / side_len
offset_px4 = 0#(px4 - x1_) / side_len
offset_py4 = 0#(py4 - y1_) / side_len
offset_px5 = 0#(px5 - x1_) / side_len
offset_py5 = 0#(py5 - y1_) / side_len
crop_box = [_x1, _y1, _x2, _y2]
face_crop = img.crop(crop_box) #图片裁剪
face_resize = face_crop.resize((face_size, face_size)) #对裁剪后的图片缩放
iou = utils.iou(crop_box, np.array(boxes))[0]
if iou > 0.65: #可以自己修改
positive_anno_file.write(
"positive/{0}.jpg {1} {2} {3} {4} {5} {6} {7} {8} {9} {10} {11} {12} {13} {14} {15}\n".format(
positive_count, 1, offset_x1, offset_y1,
offset_x2, offset_y2, offset_px1, offset_py1, offset_px2, offset_py2, offset_px3,
offset_py3, offset_px4, offset_py4, offset_px5, offset_py5))
positive_anno_file.flush() #flush() 方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区
face_resize.save(os.path.join(positive_image_dir, "{0}.jpg".format(positive_count)))
# print("positive_count",positive_count)
positive_count += 1
elif 0.65 > iou > 0.4:
part_anno_file.write(
"part/{0}.jpg {1} {2} {3} {4} {5} {6} {7} {8} {9} {10} {11} {12} {13} {14} {15}\n".format(
part_count, 2, offset_x1, offset_y1,offset_x2,
offset_y2, offset_px1, offset_py1, offset_px2, offset_py2, offset_px3,
offset_py3, offset_px4, offset_py4, offset_px5, offset_py5))
part_anno_file.flush()
face_resize.save(os.path.join(part_image_dir, "{0}.jpg".format(part_count)))
# print("part_count", part_count)
part_count += 1
elif iou < 0.1:
negative_anno_file.write(
"negative/{0}.jpg {1} 0 0 0 0 0 0 0 0 0 0 0 0 0 0\n".format(negative_count, 0))
negative_anno_file.flush()
face_resize.save(os.path.join(negative_image_dir, "{0}.jpg".format(negative_count)))
# print("negative_count", negative_count)
negative_count += 1
count = positive_count+part_count+negative_count
print(count)
if count >= stop_value:
break
except:
traceback.print_exc() #返回错误类型
finally:
positive_anno_file.close()
negative_anno_file.close()
part_anno_file.close()
gen_sample(12, 50000)
gen_sample(24, 50000)
gen_sample(48, 50000)
五、创建网络模型
1PNet
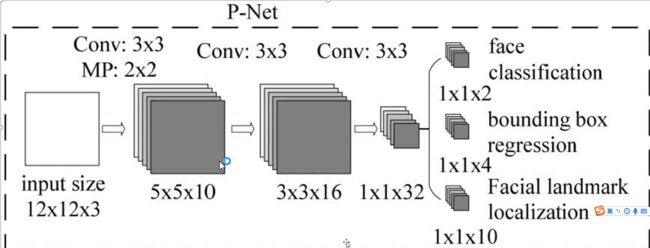
class PNet(nn.Module):
def __init__(self):
super(PNet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=10, kernel_size=3, stride=1,
padding=0, dilation=1, groups=1), #10*10*10
nn.BatchNorm2d(10),
nn.ReLU(),
nn.MaxPool2d((2, 2), 2) #5*5*10
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=10, out_channels=16, kernel_size=3, stride=1,
padding=0, dilation=1, groups=1), #3*3*16
nn.BatchNorm2d(16),
nn.ReLU()
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1,
padding=0, dilation=1, groups=1), #1*1*32
nn.BatchNorm2d(32),
nn.ReLU()
)
self.conv4 = nn.Conv2d(in_channels=32, out_channels=5, kernel_size=1, stride=1,
padding=0, dilation=1, groups=1)
def forward(self, x):
y = self.conv1(x)
# print(y.shape)
y = self.conv2(y)
y = self.conv3(y)
# y = torch.reshape(y, [y.size(0), -1])
y = self.conv4(y)
# print(y)
# print()
category = torch.sigmoid(y[:, 0:1])
offset = y[:, 1:]
# print(category.shape)
# print(offset.shape)
# print("--------------------")
return category, offset2RNet
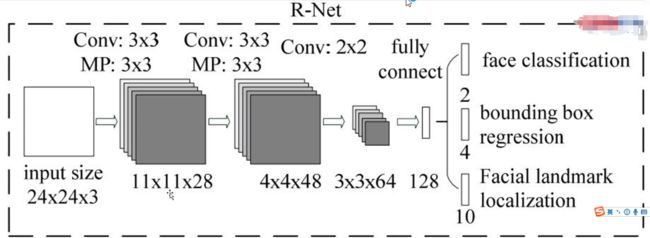
class RNet(nn.Module):
def __init__(self):
super(RNet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=28, kernel_size=3, stride=1,
padding=0, dilation=1, groups=1), #22*22*28
nn.BatchNorm2d(28),
nn.ReLU(),
nn.MaxPool2d((3, 3), 2, 1) #11*11*28
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=28, out_channels=48, kernel_size=3, stride=1,
padding=0, dilation=1, groups=1), #9*9*48
nn.BatchNorm2d(48),
nn.ReLU(),
nn.MaxPool2d((3, 3), 2, 0) #4*4*48
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=48, out_channels=64, kernel_size=2, stride=1,
padding=0, dilation=1, groups=1), #3*3*64
nn.BatchNorm2d(64),
nn.ReLU()
)
self.fc1 = nn.Linear(3*3*64, 128)
self.fc2 = nn.Linear(128, 5)
def forward(self, x):
y = self.conv1(x)
# print(y.shape)
y = self.conv2(y)
# print(y.shape)
y = self.conv3(y)
# print(y.shape)
y = torch.reshape(y, [y.size(0), -1])
# print(y.shape)
y = self.fc1(y)
# print(y.shape)
y = self.fc2(y)
# print(y.shape)
category = torch.sigmoid(y[:, 0:1])
offset = y[:, 1:]
return category, offset3ONet
class ONet(nn.Module):
def __init__(self):
super(ONet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1,
padding=0, dilation=1, groups=1), #46*46*32
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d((3, 3), 2, 1) #23*23*32
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1,
padding=0, dilation=1, groups=1), #21*21*64
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d((3, 3), 2) #10*10*64
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1,
padding=0, dilation=1, groups=1), #8*8*64
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d((2, 2), 2) #4*4*64
)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=2, stride=1,
padding=0, dilation=1, groups=1), #3*3*128
nn.BatchNorm2d(128),
nn.ReLU()
)
self.fc1 = nn.Sequential(
nn.Linear(3*3*128, 256),
nn.BatchNorm1d(256),
nn.ReLU()
)
self.fc2 = nn.Linear(256, 5)
def forward(self, x):
y = self.conv1(x)
# print(y.shape)
y = self.conv2(y)
# print(y.shape)
y = self.conv3(y)
# print(y.shape)
y = self.conv4(y)
# print(y.shape,"==========")
y = torch.reshape(y, [y.size(0), -1])
# print(y.shape)
y = self.fc1(y)
# print(y.shape)
y = self.fc2(y)
# print(y.shape)
category = torch.sigmoid(y[:, 0:1])
offset = y[:, 1:]
return category, offset六、小工具IOU和NMS的创建
IOU(Intersection over Union)交并比
情况一:
IOU的计算是指两张重叠的图,交集和并集的比值,如图:
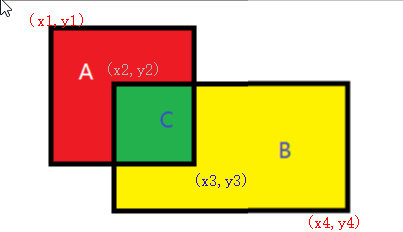
在神经网络中得到的是的是一系类坐标值:预测框一:(x1,y1,x3,y3)和预测框二(x2,y2,x4,y4),如何计算IOU?
第一步:求重叠区域的面积:
需要条件为重叠区的坐标值:取A,B左上角中坐标值大的值为C左上角的坐标值,取A,B右下角中坐标值较小的为C右下角的坐标值得到(x2, y2, x3, y3)
第二步:分别求ABC的面积,计算IOU的值
情况二:
如果出现人脸比较密集可能会出现大框套小框的情况
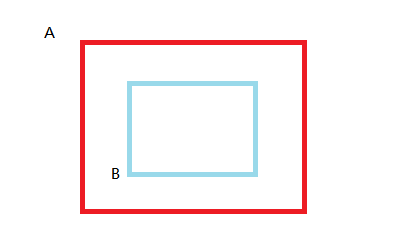
为了简化计算:IOU直接取值为交集与最小之的比值,即
NMS(Non-maximum suppression)非极大值抑制
NMS广泛应用在目标检测中,目的是去出多余的预测框。
如图:在寻找人脸时可能会出现多个预测框,首先按照置信度对预测结果按照置信度(与目标的相似程度)进行排序,保留置信度最高那个预测值,接着取出置信度第二高的和第一个做IOU计算,当IOU大于一定值(经验值为0.3)可能预测的是同一张人脸直接去掉;如果置信度相差不大,但IOU相差较大则可能是不同的人脸,需要保留该预测值:接着在剩下的预测值中重新重复以上操作,直到最后剩余的预测值为0。

请看下面的例子:
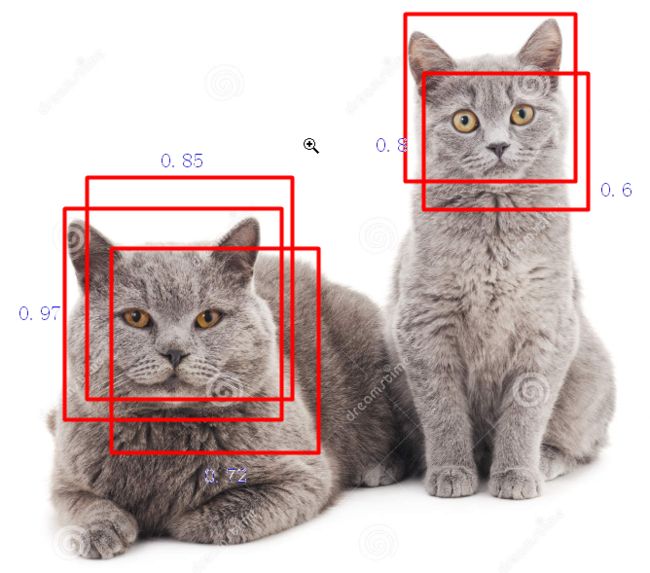
如图:人脸可以直接分辨出有两个目标,但对于神经网络而言得到的是一组置信度和对应的坐标值,如何从一组数字中寻找出我们需要的那个建议框?如果直接取两个置信度最大的框作为预测框?结果会保留0.95,和0.8,显然这是同一个目标,那还有什么方法呢?这就需要用到上面的IOU计算值了:
方法一:
第一步:按照置信度大小排序:0.97>0.85>0.8>0.72>0.6
第二步:挑出0.97的框,置信度最大,肯定是预测的目标保留这个预测框(如果有预测框,必然是神经网络预测此处至少有一个目标物体,置信度越大越可能是目标物体)
第三步:0.85>0.8>0.72>0.6,0.85最大,将0.85的框与0.97的框做IOU计算,发现IOU计算值为大于阈值(此处设定一个阈值,当IOU大于这个阈值的时候认为他们预测的是同一个目标),直接去掉0.85
第四步:0.8>0.72>0.6,比较0.8与0.97的IOU的值发现为0,认为他们预测是不同的目标则保留0.8
第五步:分别比较0.72和0.97的IOU值。0.72和0.8的IOU值,发现大于阈值,认为和之前预测目标有重复且置信度小于之前预测框的置信度,直接去掉0.72
第六步:分别比较0.6和0.97的IOU值。0.6和0.8的IOU值,发现大于阈值,认为和之前预测目标有重复且置信度小于之前预测框的置信度,直接去掉0.72,最终只剩下了置信度0.97和0.8的预测框也就找到了两个真实目标。
方法二:
第一步:按照置信度大小排序:0.97>0.85>0.8>0.72>0.6
第二步:保留0.97的值,将0.97与剩余的预测框做IOU计算,去掉0.85和0.72的预测框,保留0.8和0.6的预测框
第三步:将0.8与0.6做IOU计算,去掉0.6的框,最终保留置信度为0.97和0.8的预测框
import numpy as np
def iou(box, boxes, isMin = False):
box_area = (box[2] - box[0]) * (box[3] - box[1])
area = (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
xx1 = np.maximum(box[0], boxes[:, 0])
yy1 = np.maximum(box[1], boxes[:, 1])
xx2 = np.minimum(box[2], boxes[:, 2])
yy2 = np.minimum(box[3], boxes[:, 3])
w = np.maximum(0, xx2 - xx1)
h = np.maximum(0, yy2 - yy1)
inter = w * h #重合部分的面积
if isMin:
ovr = np.true_divide(inter, np.minimum(box_area, area)) #真正除法的运算结果 #大框套小框
else:
ovr = np.true_divide(inter, (box_area + area - inter)) #正常的交并比
return ovr #返回结果
def nms(boxes, thresh=0.3, isMin = False):
if boxes.shape[0] == 0: #防止程序出错
return np.array([])
_boxes = boxes[(-boxes[:, 4]).argsort()] #返回的是数组值从小到大的索引值
r_boxes = []
while _boxes.shape[0] > 1:
a_box = _boxes[0]
b_boxes = _boxes[1:]
r_boxes.append(a_box)
# print(iou(a_box, b_boxes))
index = np.where(iou(a_box, b_boxes,isMin) < thresh) #返回满足条件的索引
_boxes = b_boxes[index]
if _boxes.shape[0] > 0:
r_boxes.append(_boxes[0])
return np.stack(r_boxes)
#https://blog.csdn.net/wgx571859177/article/details/80987459
# 对于axis = 1,就是横着切开,对应行横着堆
# 对于axis = 2,就是横着切开,对应行竖着堆
# 对于axis = 0,就是不切开,两个堆一起
def convert_to_square(bbox):
# print(bbox)
square_bbox = bbox.copy()
if bbox.shape[0] == 0:
return np.array([])
h = bbox[:, 3] - bbox[:, 1]
w = bbox[:, 2] - bbox[:, 0]
max_side = np.maximum(h, w)
square_bbox[:, 0] = bbox[:, 0] + w * 0.5 - max_side * 0.5
square_bbox[:, 1] = bbox[:, 1] + h * 0.5 - max_side * 0.5
square_bbox[:, 2] = square_bbox[:, 0] + max_side
square_bbox[:, 3] = square_bbox[:, 1] + max_side
return square_bbox七、创建采样器
本次训练共分为三类样本
from torch.utils import data
import torch
import os
from torch.utils.data import Dataset, DataLoader
from PIL import Image
from torchvision import transforms
from torchvision import transforms
import numpy as np
class FaceDataset(Dataset):
def __init__(self,data_path, is_train=True):
self.dataset = []
# f1 = os.listdir(os.path.join(data_path, "negative"))
# f2 = os.listdir(os.path.join(data_path, "positive"))
# f3 = os.listdir(os.path.join(data_path, "part"))
l1 = open(os.path.join(data_path, "negative.txt")).readlines()
for l1_filename in l1:
self.dataset.append([os.path.join(data_path, l1_filename.split(" ")[0]), l1_filename.split(" ")[1:6]])
# print(self.dataset)
# exit()
l2 = open(os.path.join(data_path, "positive.txt")).readlines()
for l2_filename in l2:
self.dataset.append([os.path.join(data_path, l2_filename.split(" ")[0]), l2_filename.split(" ")[1:6]])
l3 = open(os.path.join(data_path, "part.txt")).readlines()
for l3_filename in l3:
self.dataset.append([os.path.join(data_path, l3_filename.split(" ")[0]), l3_filename.split(" ")[1:6]])
# print(self.dataset.shape())
def __len__(self):
return len(self.dataset)
def __getitem__(self, item):
data = self.dataset[item]
# print(data[0])
img_tensor = self.trans(Image.open(data[0]))
category = torch.tensor(float(data[1][0])).reshape(-1)
# print(category.shape,"9999999999999999999999")
offset = torch.tensor([float(data[1][1]), float(data[1][2]), float(data[1][3]), float(data[1][4])])
return img_tensor, category, offset
def trans(self, x):
return transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, ], [0.5, ])
])(x)
#测试是否可用
if __name__ == '__main__':
data_path = r"E:\CelebA\MTCN\12"
mydata = FaceDataset(data_path)
data = data.DataLoader(mydata, 2, shuffle=True)
for i, (x1, y1, y2) in enumerate(data):
print(x1)
print(x1.shape)
print(y1)
print(y2.shape)
print()
exit()八、创建训练文件
import os
from torch.utils.data import DataLoader
import torch
from torch import nn
import torch.optim as optim
from MTCNN.simpling import FaceDataset
import thop
from tensorboardX import SummaryWriter
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error, r2_score,explained_variance_score
class Trainer:
def __init__(self, net, save_path, dataset_path):
if torch.cuda.is_available():
self.device = torch.device("cuda") #判断是否有gpu
else:
self.device = torch.device("cpu")
self.net = net.to(self.device) #通用的属性加self
self.save_path = save_path
self.dataset_path = dataset_path
self.cls_loss_fn = nn.BCELoss() #置信度损失函数
self.offset_loss_fn = nn.MSELoss() #坐标偏移量损失函数
self.optimizer = optim.Adam(self.net.parameters())
if os.path.exists(self.save_path): #是否有已经保存的参数文件
net.load_state_dict(torch.load(self.save_path, map_location='cpu'))
else:
print("NO Param")
def trainer(self, stop_value):
faceDataset = FaceDataset(self.dataset_path) #实例化对象
dataloader = DataLoader(faceDataset, batch_size=512, shuffle=True, num_workers=0, drop_last=True)
loss = 0
self.net.train()
while True:
loss1 = 0
epoch = 0
cla_label = []
cla_out = []
offset_label = []
offset_out = []
plt.ion()
e = []
r = []
for i, (img_data_, category_, offset_) in enumerate(dataloader):
img_data_ = img_data_.to(self.device) #得到的三个值传入到CPU或者GPU
category_ = category_.to(self.device)
offset_ = offset_.to(self.device)
_output_category, _output_offset = self.net(img_data_) #输出置信度和偏移值
# print(_output_category.shape) #torch.Size([10, 1, 1, 1])
# print(_output_offset.shape,"=================") #torch.Size([10, 4, 1, 1])
output_category = _output_category.view(-1, 1) #转化成NV结构
output_offset = _output_offset.view(-1, 4)
# print(output_category.shape)
# print(output_offset.shape, "=================")
#正样本和负样本用来训练置信度
category_mask = torch.lt(category_, 2) #小于2 #一系列布尔值 逐元素比较input和other , 即是否 \( input < other \),第二个参数可以为一个数或与第一个参数相同形状和类型的张量。
category = torch.masked_select(category_, category_mask) #取到对应位置上的标签置信度 #https://blog.csdn.net/SoftPoeter/article/details/81667810
#torch.masked_select()根据掩码张量mask中的二元值,取输入张量中的指定项( mask为一个 ByteTensor),将取值返回到一个新的1D张量,
#上面两行等价于category_mask = category[category < 2]
output_category = torch.masked_select(output_category, category_mask) #输出的置信度
# print(output_category)
# print(category)
cls_loss = self.cls_loss_fn(output_category, category) #计算置信度的损失
offset_mask = torch.gt(category_, 0)
offset = torch.masked_select(offset_,offset_mask)
output_offset = torch.masked_select(output_offset,offset_mask)
offset_loss = self.offset_loss_fn(output_offset, offset) #计算偏移值的损失
loss = cls_loss + offset_loss
writer.add_scalars("loss", {"train_loss": loss}, epoch) # 标量
self.optimizer.zero_grad() #更新梯度反向传播
loss.backward()
self.optimizer.step()
cls_loss = cls_loss.cpu().item() #将损失转达CPU上计算,此处的损失指的是每一批次的损失
offset_loss = offset_loss.cpu().item()
loss = loss.cpu().item()
print("epoch:", epoch, "loss:", loss, " cls_loss:", cls_loss, " offset_loss", offset_loss)
epoch += 1
cla_out.extend(output_category.detach().cpu())
cla_label.extend(category.detach().cpu())
offset_out.extend(output_offset.detach().cpu())
offset_label.extend(offset.detach().cpu())
# print("cla :")
# print("r2 :", r2_score(cla_label, cla_out))
# print("offset :")
# print("r2 :", r2_score(offset_label, offset_out))
# print("total :")
# print("r2 :", r2_score(offset_label + cla_label, offset_out + cla_out))
# e.append(i) #画出r2
# r.append(r2_score(offset_label+cla_label, offset_out+cla_out))
# plt.clf()
# plt.plot(e, r)
# plt.pause(0.01)
#
# cla_out = list(map(int, cla_out)) #map方法可以将列表中的每一个元素转为相对应的元素类型
# cla_label = list(map(int, cla_label))
# offset_out = list(map(int, offset_out))
# offset_label = list(map(int, offset_label))
#
# print("accuracy_score :", accuracy_score(offset_label + cla_label, offset_out + cla_out)) #求的是每一批里面的
# print("confusion_matrix :")
# print(confusion_matrix(offset_label + cla_label, offset_out + cla_out))
# print(classification_report(offset_label + cla_label, offset_out + cla_out))
cla_out = []
cla_label.clear()
offset_out.clear()
offset_label.clear()
# flops, params = thop.profile_origin(self.net, (img_data_,)) # 查看参数量
# flops, params = thop.clever_format((flops, params), format=("%.2f"))
# print("flops:", flops, "params:", params)
print()
torch.save(self.net.state_dict(), self.save_path)
#保存模型的推理过程的时候,只需要保存模型训练好的参数,
# 使用torch.save()保存state_dict,能够方便模型的加载
print("save success")
if loss < stop_value:
break
九、训练网络模型
本次训练模型工需要训练三个网络,可以并行训练。由于网络较小,可以直接在CPU上训练,如果设备有GPU的话放到GPU上速度会快一些、
训练P网络
from MTCNN import net
from MTCNN import train
import os
if __name__ == '__main__':
net = nets2.PNet()
if not os.path.exists("./param"):
os.makedirs("./param")
trainer = train.Trainer(net, './param/p_net.pth', r"D:\CelebA\MTCN\64w\12")
trainer.trainer(0.01)
训练R网络
from MTCNN import net
from MTCNN import train
import os
if __name__ == '__main__':
net = nets2.RNet()
if not os.path.exists("./param"):
os.makedirs("./param")
trainer = train.Trainer(net, './param/r_net.pth', r"D:\CelebA\MTCN\64w\\24")
trainer.trainer(0.001)训练O网络
from MTCNN import net
from MTCNN import train
import os
if __name__ == '__main__':
net = nets2.ONet()
if not os.path.exists("./param"):
os.makedirs("./param")
trainer = train.Trainer(net, './param/o_net.pth', r"D:\CelebA\MTCN\64w\48")
trainer.trainer(0.0003)九、检测训练效果
import torch
from PIL import Image, ImageDraw, ImageFont
import numpy as np
from MTCNN.tool import utils
from MTCNN import nets
from torchvision import transforms
import time
import os
class Detector:
def __init__(self, pnet_param="./param/p_net.pth", rnet_param="./param/r_net.pth", onet_param="./param/o_net.pth",
isCuda=False):
# def __init__(self, pnet_param=r"C:\Users\Administrator\Desktop\Learnn\DL\MTCNN\60k\p_net.pth", rnet_param=r"C:\Users\Administrator\Desktop\Learnn\DL\MTCNN\60k\r_net.pth",
# onet_param=r"C:\Users\Administrator\Desktop\Learnn\DL\MTCNN\60k\o_net.pth",
# isCuda=False):
self.isCuda = isCuda
self.pnet = nets2.PNet()
self.rnet = nets2.RNet()
self.onet = nets2.ONet()
if self.isCuda:
self.pnet.cuda()
self.rnet.cuda()
self.onet.cuda()
self.pnet.load_state_dict(torch.load(pnet_param, map_location='cpu'))
self.rnet.load_state_dict(torch.load(rnet_param, map_location='cpu'))
self.onet.load_state_dict(torch.load(onet_param, map_location='cpu'))
self.pnet.eval()
self.rnet.eval()
self.onet.eval()
#记住一定要使用model.eval()来固定dropout和归一化层,否则每次推理会生成不同的结果
self.__image_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])
])
def detect(self, image):
start_time = time.time()
# print("===================")
pnet_boxes = self.__pnet_detect(image)
# print("***********************")
if pnet_boxes.shape[0] == 0:
return np.array([])
end_time = time.time()
t_pnet = end_time - start_time
start_time = time.time()
rnet_boxes = self.__rnet_detect(image, pnet_boxes) #p网络输出的框和原图像输送到R网络中,O网络将框扩为正方形再进行裁剪,再缩放
# print( rnet_boxes)
if rnet_boxes.shape[0] == 0:
return np.array([])
end_time = time.time()
t_rnet = end_time - start_time
start_time = time.time()
onet_boxes = self.__onet_detect(image, rnet_boxes)
if onet_boxes.shape[0] == 0:
return np.array([])
end_time = time.time()
t_onet = end_time - start_time
t_sum = t_pnet + t_rnet + t_onet
print("total:{0} pnet:{1} rnet:{2} onet:{3}".format(t_sum, t_pnet, t_rnet, t_onet))
return onet_boxes
# return rnet_boxes
def __pnet_detect(self, img):
boxes = []
w, h = img.size
min_side_len = min(w, h)
scale = 1
while min_side_len >= 12:
img_data = self.__image_transform(img)
# img_data = img_data.unsqueeze_(0)
if self.isCuda:
img_data = img_data.cuda()
img_data.unsqueeze_(0) #升维度(新版pytorch可以删掉)
_cls, _offest = self.pnet(img_data) #NCHW
# print(_cls.shape) #torch.Size([1, 1, 1290, 1938])
# print(_offest.shape) #torch.Size([1, 4, 1290, 1938])
cls, offest = _cls[0][0].cpu().data, _offest[0].cpu().data
#_cls[0][0].cpu().data去掉NC, _offest[0]去掉N
# print(_cls.shape) #torch.Size([1, 1, 1290, 1938])
# print(_offest.shape) #torch.Size([1, 4, 1290, 1938])
idxs = torch.nonzero(torch.gt(cls, 0.6)) #取出置信度大于0.6的索引
# print(idxs.shape) #N2 #torch.Size([4639, 2])
for idx in idxs: #idx里面就是一个h和一个w
# print(idx) #tensor([ 102, 1904])
# print(offest)
boxes.append(self.__box(idx, offest, cls[idx[0], idx[1]], scale)) #反算
scale *= 0.709
_w = int(w * scale)
_h = int(h * scale)
img = img.resize((_w, _h))
# print(min_side_len)
min_side_len = np.minimum(_w, _h)
return utils.nms(np.array(boxes), 0.3)
def __box(self, start_index, offset, cls, scale, stride=2, side_len=12): #side_len=12建议框大大小
_x1 = int(start_index[1] * stride) / scale#宽,W,x
_y1 = int(start_index[0] * stride) / scale#高,H,y
_x2 = int(start_index[1] * stride + side_len) / scale
_y2 = int(start_index[0] * stride + side_len) / scale
ow = _x2 - _x1 #偏移量
oh = _y2 - _y1
_offset = offset[:, start_index[0], start_index[1]] #通道层面全都要[C, H, W]
x1 = _x1 + ow * _offset[0]
y1 = _y1 + oh * _offset[1]
x2 = _x2 + ow * _offset[2]
y2 = _y2 + oh * _offset[3]
return [x1, y1, x2, y2, cls]
def __rnet_detect(self, image, pnet_boxes):
_img_dataset = []
_pnet_boxes = utils.convert_to_square(pnet_boxes)
for _box in _pnet_boxes:
_x1 = int(_box[0])
_y1 = int(_box[1])
_x2 = int(_box[2])
_y2 = int(_box[3])
img = image.crop((_x1, _y1, _x2, _y2))
img = img.resize((24, 24))
img_data = self.__image_transform(img)
_img_dataset.append(img_data)
img_dataset =torch.stack(_img_dataset)
if self.isCuda:
img_dataset = img_dataset.cuda()
_cls, _offset = self.rnet(img_dataset)
_cls = _cls.cpu().data.numpy()
offset = _offset.cpu().data.numpy()
boxes = []
idxs, _ = np.where(_cls > 0.6)
for idx in idxs: #只是取出合格的
_box = _pnet_boxes[idx]
_x1 = int(_box[0])
_y1 = int(_box[1])
_x2 = int(_box[2])
_y2 = int(_box[3])
ow = _x2 - _x1
oh = _y2 - _y1
x1 = _x1 + ow * offset[idx][0]
y1 = _y1 + oh * offset[idx][1]
x2 = _x2 + ow * offset[idx][2]
y2 = _y2 + oh * offset[idx][3]
cls = _cls[idx][0]
boxes.append([x1, y1, x2, y2, cls])
# print(len(utils.nms(np.array(boxes), 0.3)))
print("""""""""""""""""""""""""""""""""""""""""")
return utils.nms(np.array(boxes), 0.3)
def __onet_detect(self, image, rnet_boxes):
_img_dataset = []
_rnet_boxes = utils.convert_to_square(rnet_boxes)
for _box in _rnet_boxes:
_x1 = int(_box[0])
_y1 = int(_box[1])
_x2 = int(_box[2])
_y2 = int(_box[3])
img = image.crop((_x1, _y1, _x2, _y2))
img = img.resize((48, 48))
img_data = self.__image_transform(img)
_img_dataset.append(img_data)
img_dataset = torch.stack(_img_dataset)
if self.isCuda:
img_dataset = img_dataset.cuda()
_cls, _offset = self.onet(img_dataset)
_cls = _cls.cpu().data.numpy()
offset = _offset.cpu().data.numpy()
boxes = []
idxs, _ = np.where(_cls > 0.97)
for idx in idxs:
_box = _rnet_boxes[idx]
_x1 = int(_box[0])
_y1 = int(_box[1])
_x2 = int(_box[2])
_y2 = int(_box[3])
ow = _x2 - _x1
oh = _y2 - _y1
x1 = _x1 + ow * offset[idx][0]
y1 = _y1 + oh * offset[idx][1]
x2 = _x2 + ow * offset[idx][2]
y2 = _y2 + oh * offset[idx][3]
cls = _cls[idx][0]
boxes.append([x1, y1, x2, y2, cls])
return utils.nms(np.array(boxes), 0.3, isMin=True)
if __name__ == '__main__':
x = time.time()
with torch.no_grad() as grad:
path = r"D:\MTCNN\MTCNN\图片1" #遍历文件夹内的图片
for name in os.listdir(path):
img = os.path.join(path, name)
image_file = img
# image_file = r"1.jpg"
# print(image_file)
detector = Detector()
with Image.open(image_file) as im:
boxes = detector.detect(im)
# print(im,"==========================")
# print(boxes.shape)
imDraw = ImageDraw.Draw(im)
for box in boxes:
x1 = int(box[0])
y1 = int(box[1])
x2 = int(box[2])
y2 = int(box[3])
# print(x1)
# print(y1)
# print(x2)
# print(y2)
# print(box[4])
cls = box[4]
imDraw.rectangle((x1, y1, x2, y2), outline='red')
font = ImageFont.truetype(r"C:\Windows\Fonts\simhei", size=20)
# imDraw.text((x1, y1), "{:.3f}".format(cls), fill="red", font=font)
y = time.time()
print(y - x)
im.show()
效果如图:

视频版
import torch
from PIL import Image, ImageDraw, ImageFont
import numpy as np
from MTCNN_facetest.tool import utils
from MTCNN_facetest import nets
from torchvision import transforms
import time
import os
import cv2
class Detector:
def __init__(self, pnet_param=r"./mtcnn_params\p_net.pth", rnet_param=r"./mtcnn_params\r_net.pth",
onet_param=r"./mtcnn_params\o_net.pth",
isCuda=True):
self.isCuda = isCuda
self.pnet = nets.PNet()
self.rnet = nets.RNet()
self.onet = nets.ONet()
if self.isCuda:
self.pnet.cuda()
self.rnet.cuda()
self.onet.cuda()
self.pnet.load_state_dict(torch.load(pnet_param, map_location='cuda'))
self.rnet.load_state_dict(torch.load(rnet_param, map_location='cuda'))
self.onet.load_state_dict(torch.load(onet_param, map_location='cuda'))
self.pnet.eval()
self.rnet.eval()
self.onet.eval()
self.__image_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5,0.5,0.5])
])
def detect(self, image):
start_time = time.time() #p网络开始时间
pnet_boxes = self.__pnet_detect(image)
if pnet_boxes.shape[0] == 0:
return np.array([])
end_time = time.time() #p网络结束时间
t_pnet = end_time - start_time #计算图像进出p网络所花的时间
start_time = time.time() #r网络开始时间
rnet_boxes = self.__rnet_detect(image, pnet_boxes) #p网络输出的框和原图像输送到R网络中,O网络将框扩为正方形再进行裁剪,再缩放
# print( rnet_boxes)
if rnet_boxes.shape[0] == 0:
return np.array([])
end_time = time.time() #r网络结束时间
t_rnet = end_time - start_time #计算图像进出r网络所花的时间
start_time = time.time() #o网络开始时间
onet_boxes = self.__onet_detect(image, rnet_boxes)
if onet_boxes.shape[0] == 0:
return np.array([])
end_time = time.time() #o网络结束时间
t_onet = end_time - start_time #计算图像进出o网络所花的时间
# t_sum = t_pnet + t_rnet + t_onet #计算三个网络总共花费的时间
# print("total:{0} pnet:{1} rnet:{2} onet:{3}".format(t_sum, t_pnet, t_rnet, t_onet))
return onet_boxes
# return pnet_boxes
# return rnet_boxes
def __pnet_detect(self, img, stride=2, side_len=12):
boxes = []
w, h = img.size
min_side_len = min(w, h)
scale = 1
# while min_side_len >= 12:
while min_side_len >= 60:
img_data = self.__image_transform(img)
img_data = img_data.unsqueeze_(0)
if self.isCuda:
img_data = img_data.cuda()
_cls, _offest = self.pnet(img_data) #NCHW
cls, offset = _cls[0][0].cpu().data, _offest[0].cpu().data
idxs = torch.nonzero(torch.gt(cls, 0.6), as_tuple=False) #取出置信度大于0.6的索引
_x1 = (idxs[:, 1] * stride) // scale
_y1 = (idxs[:, 0] * stride) // scale
_x2 = _x1 + side_len // scale
_y2 = _y1 + side_len // scale
_w = _x2 - _x1
_h = _y2 - _y1
x1 = offset[0, idxs[:, 0], idxs[:, 1]] * _w + _x1
y1 = offset[1, idxs[:, 0], idxs[:, 1]] * _h + _y1
x2 = offset[2, idxs[:, 0], idxs[:, 1]] * _w + _x2
y2 = offset[3, idxs[:, 0], idxs[:, 1]] * _h + _y2
_cls = cls[idxs[:, 0], idxs[:, 1]]
box = torch.stack([x1, y1, x2, y2, _cls], dim=1)
boxes.extend(box.numpy())
scale *= 0.709
_w = int(w * scale)
_h = int(h * scale)
img = img.resize((_w, _h))
min_side_len = np.minimum(_w, _h)
return utils.nms(np.array(boxes), 0.3)
def __rnet_detect(self, image, pnet_boxes):
_pnet_boxes = utils.convert_to_square(pnet_boxes)
_x1 = _pnet_boxes[:,0]
_y1 = _pnet_boxes[:,1]
_x2 = _pnet_boxes[:,2]
_y2 = _pnet_boxes[:,3]
_box = np.stack((_x1, _y1, _x2, _y2), axis=1)
_img_dataset = [self.__image_transform(image.crop(x).resize((24, 24))) for x in _box]
img_dataset = torch.stack(_img_dataset)
if self.isCuda:
img_dataset = img_dataset.cuda()
_cls, _offset = self.rnet(img_dataset)
_cls = _cls.cpu().data.numpy()
offset = _offset.cpu().data.numpy()
idxs, _ = np.where(_cls > 0.7)
_box = _pnet_boxes[idxs]
_x1 = _box[:, 0]
_y1 = _box[:, 1]
_x2 = _box[:, 2]
_y2 = _box[:, 3]
ow = _x2 - _x1
oh = _y2 - _y1
x1 = _x1 + ow * offset[idxs, 0]
y1 = _y1 + oh * offset[idxs, 1]
x2 = _x2 + ow * offset[idxs, 2]
y2 = _y2 + oh * offset[idxs, 3]
cls = _cls[idxs, 0]
boxes=np.stack([x1, y1, x2, y2, cls], axis=1)
return utils.nms(np.array(boxes), 0.3)
def __onet_detect(self, image, rnet_boxes):
_img_dataset = []
_rnet_boxes = utils.convert_to_square(rnet_boxes)
_x1 = _rnet_boxes[:,0]
_y1 = _rnet_boxes[:,1]
_x2 = _rnet_boxes[:,2]
_y2 = _rnet_boxes[:,3]
_box = np.stack((_x1, _y1, _x2, _y2), axis=1)
_img_dataset = [self.__image_transform(image.crop(x).resize((48, 48))) for x in _box]
img_dataset = torch.stack(_img_dataset)
if self.isCuda:
img_dataset = img_dataset.cuda()
_cls, _offset = self.onet(img_dataset)
_cls = _cls.cpu().data.numpy()
offset = _offset.cpu().data.numpy()
idxs, _ = np.where(_cls > 0.99)
_box = _rnet_boxes[idxs]
_x1 = _box[:, 0]
_y1 = _box[:, 1]
_x2 = _box[:, 2]
_y2 = _box[:, 3]
ow = _x2 - _x1
oh = _y2 - _y1
x1 = _x1 + ow * offset[idxs, 0]
y1 = _y1 + oh * offset[idxs, 1]
x2 = _x2 + ow * offset[idxs, 2]
y2 = _y2 + oh * offset[idxs, 3]
cls = _cls[idxs, 0]
boxes = np.stack([x1, y1, x2, y2, cls], axis=1)
return utils.nms(np.array(boxes), 0.3, isMin=True)
if __name__ == '__main__':
cap = cv2.VideoCapture(0)
cap.set(4, 720)
cap.set(3, 480)
fps = int(round(cap.get(cv2.CAP_PROP_FPS)))
w = int(cap.get(3))
h = int(cap.get(4))
while True:
ret, im = cap.read()
if cv2.waitKey(int(1000 / fps)) & 0xFF == ord("q"):
break
elif ret == False:
break
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = Image.fromarray(np.uint8(im))
with torch.no_grad() as grad:
t0 = time.process_time()
t3 = time.time()
detector = Detector()
boxes = detector.detect(im)
for box in boxes:
x1 = int(box[0])
y1 = int(box[1])
x2 = int(box[2])
y2 = int(box[3])
# cls = box[4]
cv2.rectangle(im, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 3)
im = np.array(im).astype('uint8')
cv2.rectangle(im,(x1, y1,), (x2, y2), (255,0, 0), 3)
# im = np.array(im).astype('uint8')
# im = cv2.cvtColor(np.array(im), cv2.COLOR_RGB2BGR)
t4 = time.time()
print(1 / (t4 - t3))
im = cv2.cvtColor(np.uint8(im), cv2.COLOR_RGB2BGR)
cv2.imshow("", np.uint8(im))以上是实战部分的内容,关于MTCNN中的一些问题,欢迎浏览下一篇:MTCNN常见问题总结