大数据电信号分析项目
电信信号强度诊断项.
知识点1 项.背景
⼿机⽬前已经是⼈们⽣活必不可缺少的⼯具,给我们带来⽅便的同时,特带来⼀些困扰,例如:由于
信号强度差、⽹络速率低导致的抢红包慢,通话的质量较差。本项⽬主要⽤于分析⽤户附近的信号强
度,⽹络质量,为⽤户提供⼀些建议,例如:⽤户附近哪家运营商的⽹络质量好,信号强度⾼ ,例如,
⽤户的哪个⽅向⾃⼰使⽤的运营商信号好。
为运营商提供⼀些合理的建议,例如某⼀地理区域,某⼀地标(⾼校、居⺠区)信号强度排名。
知识点2 项.模块介绍
模块1 仪表盘:主要是领导关⼼的⼀些指标,有限展示在⾸⻚。
1、⽹络质量总数、信号覆盖总数、数据链接总数实时统计
2、上⾏、下⾏速率各个⽹络制式统计
3、⽤户分布,热⻔APP、热⻔⼿机统计等
模块2 信号覆盖: 与信号强度相关的报表。
1、信号强度分布图
2、典型地标信号强度跟踪
3、典型地标信号强度统计
模块3 ⽹络质量: 与⽹络质量相关的报表类别
1、 ⽹络质量分布
2、 ⽹络质量统计
3、 ⽹络质量排名
4、 典型地标⽹络质量跟踪
5、典型地标⽹络质量统计
模块4 数据连接:展示⽤户连接情况
1、 数据连接率分布
2、数据连接率统计
模块5 热⻔APP: 所有的与APP相关的报表业务
1、 热⻔APP流量分布
2、 热⻔APP地图
3、 热⻔APP流量排名
4、 热⻔APP流量跟踪图
5、典型地标热⻔APP流量排名
模块6 热⻔⼿机: 所有的与⼿机相关的和OS相关的报表业务
1、热⻔⼿机流量分布图
2、热⻔⼿机⽹络质量排名
3、热⻔⼿机流量排名
4、热⻔OS流量排名
5、热⻔⼿机分布图
6、⼿机OS分布图
模块7 连接点: 与数据连接相关的额所有业务
1、 连接点书排名(城市)
2、连接点地理分布
模块8 个⼈⽤户:所有的⽤户“附近”相关的业务,(以⽤户为中⼼进⾏相关的计算)
1、 ⽹络质量
2、 APP街景图
3、 OS街景图
4、信号覆盖
知识点3 后端模块介绍
模块1 后端数据导⼊:
将历史保留下来的离线数据,导⼊到⼤数据平台内。接⼊实时⽣成的最新数据,⽤于实现离线业
务。
模块2 数据存储:
⽤于存储已经⽣成的离线数据,将数据存储下来。⽤于离线分析。
将实时⽣成的最新数据进⾏临时存储(⽤于实现实时指标计算)和永久存储(做历史数据,离线数
据分析)。
模块3 数据的处理
根据离线所需的各个指标,进⾏相关的计算。
根据业务需求实时统计相关的指标,并将最新的额结果存储到结果数据库中。
模块4 :报表的⽣成
本项⽬不涉及报表开发(由前端⼯程已经开发好了),部分的数据展现过程需要带⼤家开⼀下代码
实现过程。
知识点4 数据处理流程
离线计算
1、通过命令⾏或脚本将数据上传到HDFS
2、将上传的数据加载到数据仓库内
3、根据⽬标数据的格式在数据仓库中对数据进⾏计算
4、通过⼯作流将计算后的数据进⼀步加⼯最终写⼊结果表
实时计算
5、解析开启binlog 的mysql⽇志
6、将解析后的数据写⼊本地⽬录,flume收集⽬录新增的数据
7-1、Flume将收集到的数据实时发送到消息总线,⽤于实时计算。
7-2、Flume将收集到的数据发送到HDFS,⽤于离线计算。
8、读取kafak内实时数据,实时计算相关指标。
9、将最终的指标写⼊结果数据库
知识点5 项⽬逻辑架构设计
实时上就是数据处理流程的另外⼀个纬度的解释
知识点6 原始数据(历史数据)介绍
第⼀张表:networkqualityinfo
作⽤是:⽤于⽀撑所有得与⽹路质量相关得报表(⽹络质量模块下得所有得表)
常⽤得字段:延迟(ms)、平均下载速度(kb/s)、平均上传速度(kb/s)、wifi/3G/2G、插⼊
服务器时间、(⽹络名称)
第⼆张表: app_traffic
作⽤是:⽤于⽀撑模块“热⻔APP”相关得报表。
常⽤得字段:应⽤程序名称、⽹络类型、详细类型(反推运营商)、数据成产时间、⽤户纬度、⽤
户经度、上传流量、下载流量、
第三张表 : cell_strength
作⽤是:⽤于⽀撑所有得与信号强度先关掉得业务需求⽀撑。
常⽤的字段:⽹络类型、GMS的信号强度、CDMA的信号强度、EVDO信号强度、⽤户的纬度、⽤
户的经度、信号强度收集时间
第四张表: data_connection
作⽤是:⽤于⽀撑和数据连接相关得所有得报表。
常⽤得字段:表示数据连接状态得字段,⽤户的纬度、⽤户的经度、插⼊服务器的时间
第五张表:device
作⽤是:⽤于⽀撑与设备属性相关得报表,相关得指标字段。
常⽤得字段:⼿机IMEI、⼿机品牌、⼿机型号、操作系统、操作系统版本、最后插⼊时间
第六张表:network
作⽤是:⽤于存储现在已有得⽹络得名称
常⽤得字段:⽹络ID、⽹络名称
知识点7 详细需求介绍
模块1 :⾸⻚⾯
⾸⻚⾯由实时业务和离线业务两部分组成。
模块2 :信号覆盖
⼀共有三个报表,信号强度分布图,典型地标信号强度跟踪图,典型地标信号强度统计图组成
图示
模块3 :⽹络质量
本模块共有5张报表,主要由⽹络质量分布图、⽹络质量统计图、⽹络速率排名、典型地标⽹络质
量跟踪图、典型地标⽹络质量统计图组成。
分别以⽹格图、柱状图、曲线图等形式统计不同地点的⽹络质量、各个⽹络制式的质量、以及对各
省市的⽹络质量进⾏排名等。
筛选条件有时间范围、时间粒度、典型地标、⽹络质量、⽹络制式、运营商等
图示
模块4 :数据连接
数据链接模块主要由两个报表组成,数据连接率分布图、数据连接率统计图组成。
主要以地图显示链接情况,柱状图形式展示各个⽹络制式下的链接量。
筛选条件有⽇期、运营商、⽹络制式等
图示
模块5 :热⻔APP
热⻔APP模块主要有5个报表。由热⻔App流量分布图、热⻔App地图、热⻔App流量排名、热⻔App
流量跟踪图、典型地标热⻔App流量排名组成。
展现形式为地图分布(热图)、柱状图、曲线图、饼状图等形式。
筛选条件包括时间范围、运营商、⽹络制式、APP流量、时间粒度典型地标等
图示
模块6:热⻔⼿机
热⻔⼿机模块主要有6个模块,由热⻔⼿机流量分布图、热⻔⼿机⽹络质量排名、热⻔⼿机流量排
名、⼿机OS流量排名、热⻔⼿机分布图、热⻔OS分布图等组成,
其中主要展现形式主要以地图分布、柱状图、曲线图、饼状图等形式。
筛选条件包括时间范围、运营商、⽹络制式、⼿机流量、时间粒度典型地标等
图示
模块7 连接点
连接点监控模块主要有两个报表。由连接点地理分布、连接点数排名组成。
其中主要展现形式主要以地图分布、柱状图。
查询条件为⽇期、运营商。
图示
模块8 个⼈⽤户
个⼈⽤户模块主要有四个报表,由⽹络质量、APP街景图、OS街景图、信号覆盖组成。
其中主要展现形式主要有地图分布、地图街景图。
查询条件为运营商、⽹络质量。
图示
知识点8 项.设计策略
设计⽅法使⽤⾯向对象得设计,界⾯的交互⽅式使⽤得是B/S结构。
前端使⽤的技术:柱状图,饼状图。曲线图使⽤的技术是Echarts.与地图闲逛的报表使⽤的是百度地
图提供的API.
后端使⽤的技术:实时业务使⽤的技术 canal + flume + kafka + sparkstreaming + mysql结果数据
存储 .
离线业务场景使⽤的HDFS + Hive +AZKABAN /oozie (编写⾃定义的业务逻辑)+
【hbase+phoenix】
知识点9 技术选型
表现层 SparingMVC 4.0.6(Spring)
持久层框架Hibernate 版本4.2.12
海量数据存储HADOOP 2.7.5
分布式实时计算使⽤Spark 2.1.0
消息总线 kafka 1.0.0
实时业务开发语⾔ scala 2.11
实时原始数据 mysql 5.1.73
mysql数据的解析使⽤canal 1.0.19
数据收集 Flume 1.6.0
数据仓库使⽤Hive 1.1
⼯作流调度Azkaban 或者oozie
结果数据存储: mysql (5.1.73) + [hbase 1.2+phoenix4.14]
知识点10 离线数据.库以及数据整理
离线数据库库的流程
离线数据的计算流程
知识点11 实时业务的数据.库以及数据计算
实时业务数据成产以及数据采集
实时业务数据计算
知识点12 结果数据创建索引的流程
创建索引不能.个需求创建.个,这样会有.量的数据冗余,所以在创建索引之前需要对所有业务需求的SQL进.整理,尽量整理出相似的SQL。尽量创建.个索引能够解决多个需求的查询效率问题
知识点13 地标的配置以及浏览器的兼容性
⾃⼰维护了⼀个地标与经纬度之间的关系。
左下⻆经度
左下⻆纬度
右上⻆经度
右上⻆纬度
⼀级地标(所属分类)
⼆级地标 (地标名称)
浏览器的兼容性
对IE8以上版本、⽕狐、⾕歌浏览器兼容。
知识点14 创建数据库、数据表及数据加载
创建数据库
create database Telecom;
创建数据表
create external table networkqualityinfo (id INT,ping
STRING,ave_downloadSpeed STRING,max_downloadSpeed STRING,ave_uploadSpeed
STRING,max_uploadSpeed STRING,rssi STRING,gps_lat STRING,gps_lon
STRING,location_type STRING,imei STRING,server_url STRING,ant_version
STRING,detail STRING,time_client_test STRING,time_server_insert
STRING,networkType STRING,operator_name STRING,wifi_bss_id STRING,cell_id
STRING,province STRING,city STRING,mobile_type STRING,street
STRING,location_detail STRING,upload_traffle STRING,download_traffic STRING) PARTITIONED
BY(DS STRING,DT STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY
'\t' ;
create external table app_traffic (id INT,package_name
STRING,app_name STRING,uid STRING,network_type STRING,mobile_type
STRING,cell_id STRING,wifi_bssid STRING,start_time STRING,end_time
STRING,upload_traffic STRING,download_traffic STRING,date STRING,time_index
STRING,imei STRING,sdk_version STRING,user_lat STRING,user_lon
STRING,location_type STRING) PARTITIONED
BY(DS STRING,DT STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
create external table cell_strength (id
INT,network_id STRING,network_type STRING,gsm_strength STRING,cdma_dbm
STRING,evdo_dbm STRING,gsm_bit_errorrate STRING,cdma_ecio STRING,evdo_ecio
STRING,user_lat STRING,user_lon STRING,user_location_info STRING,bs_lat
STRING,bs_lon STRING,time_index STRING,imei STRING) PARTITIONED BY(DS STRING,DT STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY
'\t' ;
create external table data_connection(id INT,imei
STRING,network_type STRING,wifi_bssid STRING,wifi_state STRING,wifi_rssi
STRING,mobile_state STRING,mobile_network_type STRING,network_id
STRING,gsm_strength STRING,cdma_dbm STRING,evdo_dbm STRING,internal_ip
STRING,web_url STRING,ping_value STRING,user_lat STRING,user_lon
STRING,user_location_info STRING,bs_lat STRING,bs_lon STRING,time_index_client
STRING,version STRING,time_server_insert STRING) PARTITIONED BY(DS STRING,DT STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY
'\t' ;
create external table device (id INT,imei STRING,company
STRING,model STRING,os STRING,os_version STRING,sdk_version STRING,cpu
STRING,total_memory STRING,free_memory STRING,display STRING,time_first
STRING,time_last STRING) PARTITIONED BY(DS STRING,DT STRING) ROW FORMAT DELIMITED
FIELDS TERMINATED BY
'\t' ;
create external table network (network_id INT,network_name
STRING) ROW FORMAT DELIMITED FIELDS
TERMINATED BY '\t' ;
数据⼊库
LOAD DATA INPATH '/HistoryDatas/networkqualityinfo_db.sql'
OVERWRITE INTO TABLE networkqualityinfo PARTITION (DS='local',DT='2017-2018');
LOAD DATA INPATH
'/HistoryDatas/app_traffic_data.sql' OVERWRITE INTO TABLE app_traffic PARTITION
(DS='local',DT='2017-2018');
LOAD DATA INPATH
'/HistoryDatas/cell_strength_data.sql' OVERWRITE INTO TABLE cell_strength
PARTITION (DS='local',DT='2017-2018');
LOAD DATA INPATH '/HistoryDatas/dataconnection.sql'
OVERWRITE INTO TABLE data_connection PARTITION (DS='local',DT='2017-2018');
LOAD DATA INPATH '/HistoryDatas/device_db.sql'
OVERWRITE INTO TABLE device PARTITION (DS='local',DT='2017-2018');
LOAD DATA INPATH '/HistoryDatas/networkid_name.sql' INTO TABLE network ;
知识点15 离线数据拆分需求及实现思路
需求:现有所有⽇期的数据都存储在⼀个⽂件内,业务需要将数据按照年⽉⽇将相同⽇期的数据整理
到⼀个⽂本中。
实现思路1:依次读取数据中的每条数据,获取数据中的⽇期字段,字段格式为“yyyy-MM-dd
HH:mm:ss”。截取出字段中的⽇期“yyyy-MM-dd”,将相同⽇期的数据存放在⼀个⽂件中,⽂件名称以
⽇期为⽂件名。
实现思路2 :利⽤mapreduce“先分后和”的思想来实现此需求
map 端操作思路:Map端获取每⼀条数据,截取出数据中的⽇期字段,根据⽇期字段再截取出其
中的⽇期。最后将⽇期作为key,将原始的⼀整⾏数据作为value,进⾏输出。
reduce端操作思路:reduce阶段获取的数据key 是⽇期,value List便是这个⽇期内的所有数据。
在reduce端每个key实现⼀个数据⽂件的创建及写⼊数据(value的list)
map开发的代码
protected void map(Object key, Text value, Context context) throws
IOException, InterruptedException {
//将数据转换成string
String linedata= value.toString().trim();
String[] linedatas= linedata.split("\\t");
//验证数据是否有第12个数据(.标是11)
if (linedatas.length>11 && linedatas[11]!=""){ // 2018-01-20 20:18:18 //获取数据中的.期字段(包含时分秒) String dateTime =linedatas[11]; //判断dateTime是否含有空格,若有则切分数据,获取.期,若没有空格,那么就跳过 if(dateTime.contains(" ")){
//获取.期字段中的.期(包含时分秒) String date=dateTime.substring(0,dateTime.indexOf(" ")); //将.期作为key 原始数据作为value进.输出 context.write(new Text(date),value);
}
}
}
reduce开发的代码
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//对数据的有效性进.验证若key 包含“-” 表示数据有效,反之.效。
if(key.toString().contains("-")){
//1拆分.期数据 key
//年
String year =key.toString().split("-")[0];
//.
String month=key.toString().split("-")[1];
//.
String day=key.toString().split("-")[2];
//使.年..拼接路径
Path dfs =new
Path("/DeviceDatas/"+year+"/"+month+"/"+day+"/"+key.toString()+".txt");
//2写出数据需要输出流
//实例.个.件系统(集群)
FileSystem
hdfs=FileSystem.get(URI.create("hdfs://node01:8020/"),conf);
//FSOutputStream outputStream =hdfs.create(dfs);
FSDataOutputStream outputStream=hdfs.create(dfs);
//3遍历当前key对应的所有的数据,将多个数据拼接在.起,为写.HDFS 做准备
String alldatas="";
for (Text tmpdata: values) {
alldatas=alldatas+tmpdata.toString()+"\r\n";
}
//将string 类型的数据转换成byte
byte[] buff=alldatas.getBytes();
//4将数据写.HDFS
outputStream.write(buff);
//5 关闭数据流
outputStream.close();
dfs=null;
alldatas="";
buff=null;
}
}
实际效果截图
知识点16 第.阶段总结
原始数据上传,(上传到LINUX ,上传到HDFS)
创建数据库,创建数据库表(需要根据项⽬的实际表结构)
数据加载,将已经⽣产的历史数据加载到数据表内
数据拆分,根据需求将相同⽇期下的数据整理到⼀个⽂件内
知识点17 离线数据整理
本阶段的最终.标是在原始表中根据业务需求抽取数据,对数据进行加.,最终将处理完的数据添加到结果表中。
- 1、实现业务⽬标的SQL语句整理,和编写。
- 2、在所有的业务SQL中提取相同表的字段,形成最终结果表的表结构。
- 3、在原始表中,抽取数据(抽取需要根据业务需求定制化抽取。例如系统类型与版本号拼接)
- 4、对抽取后的数据进…次加.,最终将数据写.结果表。
- 5、创建结果表的二级索引结果表的说明:
- 这里的结果表并不是经过计算后的汇聚数据,而是有明细数据的结果表(数据量会很多)。原始表有6张,结果表有5张

知识点18 实时业务查询的SQL
业务需求1:Dashboard – 关键数据汇总
-
业务.标表:tb_counts
- 查询语句:SELECT NWQuality_count,Signal_Strength_count,DataConnection_count FROM
tb_counts where NWOperator =‘ALL’:
- 查询语句:SELECT NWQuality_count,Signal_Strength_count,DataConnection_count FROM
业务需求2:Dashboard – 连接点地理分布
- 业务目标表: NWQuality (phoneix上面)
- 查询语句: select GpsLat,GpsLon,NWOperator from NWQuality where NWOperator in(‘CMCC’,‘CUCC’,‘CTCC’) and dayTime >=? and dayTime <=?
业务需求3:Dashboard –网络速率(上行)
- 业务.标表: NWQuality(phoneix上面)
- 查询语句: SELECT AVG(ULSpeed) AS speed ,NWOperator,NWType FROM NWQuality WHERE daytime>=? AND daytime<=? AND NWOperator in (‘CMCC’,‘CUCC’,‘CTCC’) AND NWType!=‘null’ GROUP BY NWOperator,NWType order by speed desc
业务需求4: Dashboard –网络速率(下行)
- 业务目标表: NWQuality(phoneix上面)
- 查询语句:SELECT AVG(DLSpeed) AS speed ,NWOperator,NWType FROM NWQuality WHERE daytime>=? AND daytime<=? AND NWOperator in (‘CMCC’,‘CUCC’,‘CTCC’) AND NWType!=‘null’ GROUP BY NWOperator,NWType order by speed desc
业务需求5: Dashboard –热们App流量排名
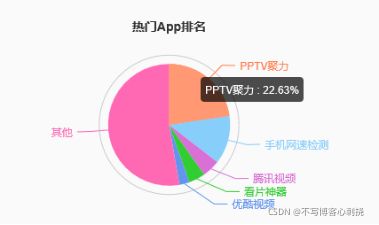
- 业务目标表: App_traffic(phoneix上面)
- 查询语句: select sum(download_traffic + upload_traffic) as speed,app_name from App_traffic where date >= ? and date <= ? and network_name = ? and network_type <> ‘WI-FI’ and app_name <> ‘phoneTotalTra.c’ group by app_name order by speed desc limit 5
业务需6: Dashboard –热们手机流量排名
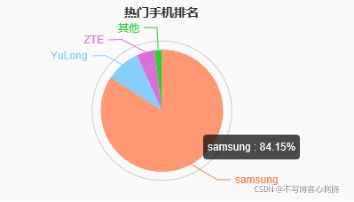
- 业务目标表: App_traffic
- 查询语句select sum(upload_traffic +download_traffic) as speed,company from App_traffic where date >= ? and date <= ? and network_name = ? and company <> ‘NULL’ and network_type <> ‘NULL’ group by company order by speed desc limit 5:
业务需7:信号覆盖 -信号强度分布图
- 业务目标表: Signal_Strength
查询语句select rssi,user_lon,user_lat,network_type from Signal_Strength where
user_lon> smalllng and user_lon< biglng
and user_lat> smalllat and user_lat< boglat
and time_index> ? and time_index < ? and
rssi>=-120 and rssi<=1 and
network_name = ? and network_type = ?:
业务需8:信号覆盖 -典型地标信号强度跟踪
- 业务.标表: Signal_Strength
- 查询语句
- SELECT AVG(rssi) rssi,SUBSTR(TO_CHAR(time_index,’#’), “+startPos+”,2) AS x_rate,network_name FROM signal_strength WHERE rssi>-120 AND rssi<0 AND time_index>=? AND time_index<=? AND network_type=? AND network_name=? AND landmark=? GROUP BY x_rate,network_name:
… …(.表格)
整理完毕的报表
最终整理完毕的业务需求查询SQL,共33个报表,有40个SQL
知识点19 相同结果表的SQL整理到一起

详情参考sql整理表.excel
知识点20 整理后的最终的结果表结构
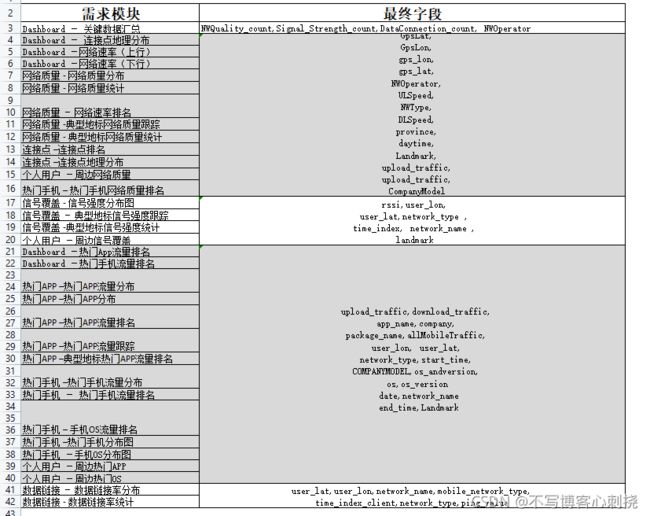
详情参考sql整理表.excel
知识点21 业务所需的特定的字段处理
原始数据没有,得自己提取出来.
NWQuality: dayTime、NWType、landmark、CompanyModel
Signal_Strength: rssi,network_type,time_index,landmark
app_tra.c:start_time,end_time, network_type allMobileTra.c, date,
Landmark,companyModel, OS_ANDVERSION DataConnection: mobile_network_type,time_index_client每个字段的详细业务逻辑查看讲义最终总结的特定的业务处理类型处理逻辑1、将.期格式为yyyy-MM-dd 的数据改成yyyyMMdd格式的数据
处理逻辑2、将.期格式为yyyy-MM-dd HH:mm:ss的数据改成yyyyMMddHH格式的数据
处理逻辑3、信号数值转化
处理逻辑4、network_type转化
处理逻辑5、经纬度信息转化为landmark
处理逻辑6、.机品牌与型号拼接
处理逻辑7、.机操作系统与版本号拼接
处理逻辑8、判断应.程序包名称是否为all
知识点22 信号强度转化
业务需求:
1、若gsm_strength.于0并且不等于99,那么rssi的计算公式为2*gsm_strength-113。
2、若gsm_strength.于0,那么rssi等于gsm_strength。
3、在原始字段cdma_dbm、evdo_dbm均不等于-1、-120的前提下。若network_type字段包含 “EVDO”,那么rssi等于evdo_dbm,反之rssi等于cdma_dbm。
4、若evdo_dbm不等于-1、-120,那么rssi等于evdo_dbm。
5、若cdma_dbm不等于-1、-120,那么rssi等于cdma_dbm。
6、其他情况rssi等于0。
项.代码:
public static int getRssi(String gsm_strength,String cdma_dbm,String
evdo_dbm,String network_type){
//将参数传换成int
int gsm=Integer.valueOf(gsm_strength);
int cdma=Integer.valueOf(cdma_dbm);
int evdo=Integer.valueOf(evdo_dbm);
//实例rssi 信号强度值得变量
int rssi=0;
//1 若gsm_strength.于0并且不等于99,那么rssi的计算公式为2gsm_strength-113。 if (gsm>0 && gsm!=99){ rssi=2gsm-113; }else if (gsm<0){// 2、若gsm_strength.于0,那么rssi等于gsm_strength。 rssi=gsm; }else if(cdma!=-1 && cdma!=-120 && evdo!=-1 && evdo!=-120){//在原始字段
cdma_dbm、evdo_dbm均不等于-1、-120的前提下。 //若network_type字段包含“EVDO”,那么rssi等于evdo_dbm,反之rssi等于cdma_dbm if(network_type.contains(“EVDO”)){
rssi=evdo;
知识点23 :networktype转化
情况.:两个参数的(mobile_type,networktype)
- 需求:
- 1、若 mobile_type等于“None”并且networktype不等于“None”。那么返回networktype。
- 2、反之,若mobile_type等于“LTE”,那么结果表network_type等于4G。若mobile_type等于UMTS或CDMA或EVDO_0或EVDO_A或HSDPA或HSUPA或HSPA或EVDO_B
或eHRPD或HSPA+那么结果表network_type等于3G。 - 3若mobile_type等于GPRS或EDGE或1xRTT或IDEN那么结果表network_type等于2G。其他返回network_type
实现代码:
String[] G2={"GPRS","EDGE","1xRTT","IDEN"}; //若mobile_type等于“LTE”,那么结果表network_type等于4G。
//添加.个表示是否匹配得标记
boolean flag=false;
if(mobile_type.equals("LTE")){
network_Type="4G";
flag=true;
}
//若没有匹配成功,继续匹配
if (!flag){
//若mobile_type等于UMTS或CDMA或EVDO_0或EVDO_A或HSDPA或HSUPA或HSPA或 EVDO_B或eHRPD或HSPA+那么结果表network_type等于3G for (String str :G3) {
if(mobile_type.equals(str)){ network_Type="3G"; break;
}
}
}
//若没有匹配成功,继续匹配
if (!flag){
//若mobile_type等于GPRS或EDGE或1xRTT或IDEN那么结果表network_type等于2G for (String str :G2) {
if(mobile_type.equals(str)){ network_Type="2G"; break;
}
}
}
}
return network_Type;
}
情况.:一个参数(network_type)
- 需求:
- 1、若原始表network_type等于“LTE”,那么结果表network_type等于4G。
- 2、若network_type等于UMTS或CDMA或EVDO_0或EVDO_A或HSDPA或HSUPA或HSPA或 EVDO_B或eHRPD或HSPA+那么结果表network_type等于3G。
- 3、若network_type等于GPRS或EDGE或1xRTT或IDEN那么结果表network_type等于2G。
实现代码:
public static String getNetworkType(String networktype){
String network_Type="";
//将所有3G得可能情况组装成数组
String[] G3= {"UMTS","CDMA","EVDO_0","EVDO_A","HSDPA","HSUPA","HSPA","EVDO_B","eHRPD","HSPA +"};
//将所有2G得可能情况组装成数组
String[] G2={"GPRS","EDGE","1xRTT","IDEN"};
//若mobile_type等于“LTE”,那么结果表network_type等于4G。
//添加.个表示是否匹配得标记
boolean flag=false;
//1、若原始表network_type等于“LTE”,那么结果表network_type等于4G。
if(networktype.equals("LTE")){
network_Type="4G";
flag=true;
}
//若没有匹配成功,继续匹配
if (!flag){
//若network_type等于UMTS或CDMA或EVDO_0或EVDO_A或HSDPA或HSUPA或HSPA或
EVDO_B或eHRPD或HSPA+那么结果表network_type等于3G
for (String str :G3) {
if(networktype.equals(str)){
network_Type="3G";
break;
}
}
}
//若没有匹配成功,继续匹配
if (!flag){
//若network_type等于GPRS或EDGE或1xRTT或IDEN那么结果表network_type等于2G for (String str :G2) {
if(networktype.equals(str)){
network_Type="2G";
break;
}
}
}
return network_Type;
}
知识点24 地标得转化
需求:
读取LandMark.xml地标配置.件,读取出.件中左下.经纬度、右上.经纬度(范围可以组成.个矩形)。遍历所有的地标配置判断.户上报的经纬度数据属于哪.个地标范围。最终返回所属地标。
实现代码:
public static String getLandmark(Double lon,Double lat) throws
DocumentException {
String landMark="unkown";
//取LandMark.xml地标配置.件,
List<LandMark> landkarks=LandMarkUtil.parseLandMark();
//遍历所有得矩形,与用户得数据匹配
for (LandMark landmark:landkarks) {
//获取.个矩形得左下.经纬度和右上.经纬度,获取.级.级地标 //若.户数据经度在地标范围,并且纬度也在同.个地标范围,表示这个点属于此地标 if(landmark.getLowerLeftLon()<=lon && landmark.getTopRightLon()>=lon
&&
landmark.getLowerLeftLat()<=lat && landmark.getTopRightLat()>=lat ){ // 返回.级地标 landMark=landmark.getCategory();
}
}
return landMark;
}
public static String getLandmark(String lon,String lat) throws
DocumentException {
//将string 类型得数据转换成double
double dlon=Double.valueOf(lon);
double dlat=Double.valueOf(lat);
//调.getLandmark()double 参数得方法
return getLandmark(dlon,dlat) ;
}
知识点25 .机.商与型号拼接
需求:
1、若model(型号)中包含company(.商)那么直接返回model(型号)
2、若model中不包含company那么将company和model使.“ ”空格进.拼接,最终返回拼接后的结果
实现代码:
public static String getCompanyModel(String company,String model){
String companyModel=null;
//若model(型号)中包含company(⼚商)那么直接返回model(型号)
if (model.toLowerCase().contains(company.toLowerCase())){
companyModel=model;
}else{
//若model中不包含company那么将company和model使⽤“ ”空格进⾏拼接,最终返回
拼接后的结果
companyModel=company+" "+model;
}
return companyModel;
}
知识点26 OS与版本拼接
需求:
在os、os_version均不等于null, “”, unknown的前提下,将os与os_version进.拼接并返回实现代码:
public static String getOsVersion(String os,String version){
String osVersion=null;
//在os、os_version均不等于null, “”, unknown的前提下,将os与os_version进⾏拼接并
返回
if (os!="" && os!=null && os!="unknown" && version!="" &&
version!=null && version!="unknown" ){
osVersion=os+" "+version;
}
return osVersion;
}
知识点27 判断应.程序包名称是否为all
需求:
判断应.程序包名称是否等于all, 若等于all,返回yes。反之返回no。
实现代码:
public static String getAllMobileTraffic(String package_name){
//判断应⽤程序包名称是否等于all, 若等于all,返回yes。反之返回no
if(package_name.equals("all")){
return "yes";
}
return "no";
}
知识点28 抽取NWQuality数据的字段
第一步:编写抽取数据的SQL
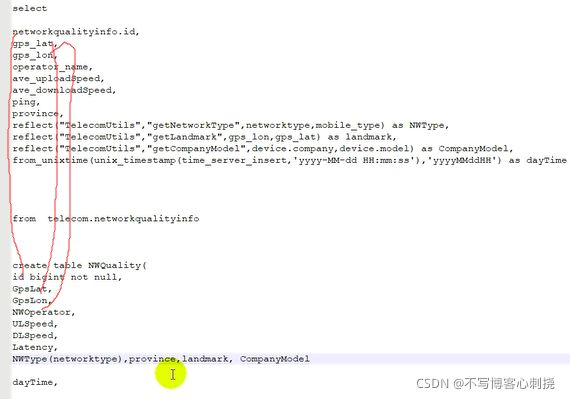
select
networkqualityinfo.id,gps_lat,gps_lon,operator_name,ave_uploadSpeed,ave_downloadSpeed,ping
,province,
refect("TelecomUtils","getNetworkType",networktype,mobile_type) as NWType,
refect("TelecomUtils","getLandmark",gps_lon,gps_lat) as landmark,
refect("TelecomUtils","getCompanyModel",device.company,device.model) as CompanyModel,
from_unixtime(unix_timestamp(time_server_insert,'yyyy-MM-dd HH:mm:ss'),'yyyyMMddHH') as
dayTime
from telecom.networkqualityinfo left join telecom.device on
(networkqualityinfo.imei=device.imei)
where
gps_lat<> ''
and gps_lat<>'0.0'
and gps_lon<>''
and gps_lon<>'0.0'
第二步:将前.编写好的业务处理代码打包上传到集群。
第三步:编辑sql.件,文件内添加jar包,添加SQL
add jar /root/TelecomUtils-1.0-SNAPSHOT.jar;
select 。。。。
第四步:执行抽取sql文件,将抽取的最终结果写. /export/phoenixdatas/内
hive -f NWQualit.sql /export/phoenixdatas/NWQualit.csv
知识点29 抽取Signal_Strength数据的字段
第.步:编写抽取数据的SQL
select
user_lon,user_lat,network_name,
refect("TelecomUtils","getRssi",gsm_strength,cdma_dbm,evdo_dbm,network_type) as rssi,
refect("TelecomUtils","getLandmark",user_lon,user_lat) as landmark,
refect("TelecomUtils","getNetworkType",network_type) as network_type,
from_unixtime(unix_timestamp(time_index,'yyyy-MM-dd HH:mm:ss'),'yyyyMMddHH') as
time_index
from telecom.cell_strength left join telecom.network on
(network.network_id=substring(cell_strength.network_id,0,5))
第二步:将前面编写好的业务处理代码打包上传到集群。
第三步:编辑sql文件,文件内添加jar包,添加SQL
add jar /root/TelecomUtils-1.0-SNAPSHOT.jar;
select 。。。。
第四步:执行抽取sql.件,将抽取的最终结果写. /export/phoenixdatas/内
hive -f Signal_Strength.sql > /export/phoenixdatas/Signal_Strength.csv
知识点30 抽取app_tra.c数据的字段
第一步:编写抽取数据的SQL
select
app_tra.c.id,user_lon,user_lat,upload_tra.c,download_tra.c,package_name,network_name
,app_name,os,os_version,company,
from_unixtime(unix_timestamp(start_time,'yyyy-MM-dd HH:mm:ss'),'yyyyMMddHH') as start_time,
from_unixtime(unix_timestamp(end_time,'yyyy-MM-dd HH:mm:ss'),'yyyyMMddHH') as end_time,
re.ect("TelecomUtils","getNetworkType",network_type, mobile_type) as network_type,
re.ect("TelecomUtils","getAllMobileTra.c",app_tra.c.package_name) AS AllMobileTra.c,
from_unixtime(unix_timestamp(date,'yyyy-MM-dd'),'yyyyMMdd') as date,
re.ect("TelecomUtils","getLandmark",user_lon,user_lat) as landmark,
re.ect("TelecomUtils","getCompanyModel",device.company,device.model) as companyModel ,
re.ect("TelecomUtils","getOsVersion",device.os, device.os_version) as os_andversion
from telecom.app_tra.c
left outer join telecom.device on ( app_tra.c.imei=device.imei)
left join telecom.network on ( network.network_id = substring(app_tra.c.cell_id,0,5))
where user_lon <>'0.0'
and user_lat <>'0'
and user_lon <>'0'
and user_lat <>'0.0'
and user_lon <>''
and user_lat <>''
and app_tra.c.app_name <> 'phoneTotalTra.c'
and app_tra.c.network_type <> 'null'
第二步:将前.编写好的业务处理代码打包上传到集群(没有变化.需重新打包)。
第三步:编辑sql.件,.件内添加jar包,添加SQL
add jar /root/TelecomUtils-1.0-SNAPSHOT.jar;
select 。。。。
第四步:执.抽取sql.件,将抽取的最终结果写
/export/phoenixdatas/内hive -f app_tra.c.sql > /export/phoenixdatas/app_tra.c.csv
知识点31 抽取DataConnection数据的字段
现在的所有操作都还是在hive表中
第一步:编写抽取数据的SQL
select data_connection.id, user_lat,user_lon,network_name,network_type,ping_value, re.ect('TelecomUtils', 'getNetworkType', network_type, mobile_network_type) as
mobile_network_type ,
from_unixtime(unix_timestamp(data_connection.time_index_client,'yyyy-MM-dd'),'yyyyMMdd') as time_index_client from telecom.data_connection left join telecom.network on ( network.network_id = substring(data_connection.network_id,0,5))
第二步:将前.编写好的业务处理代码打包上传到集群(没有变化.需重新打包)。
第三步:编辑sql.件,文件内添加jar包,添加SQL
add jar /root/TelecomUtils-1.0-SNAPSHOT.jar;
select 。。。。(代表省略)
第四步:执.抽取sql文件,将抽取的最终结果写. /export/phoenixdatas/内
hive -f data_connection.sql /export/phoenixdatas/data_connection.csv
知识点32 抽取tb_counts数据的字段
第一步:创建mysql 结果数据库,结果表
第二步:计算管理员登录时使.的数据
select
#'ALL没有太大的意义,展示的时候会多加一行字段'
count(*) as NWQuality_count ,'ALL' from telecom.networkqualityinfo;
select count(*) as Signal_Strength_count,'ALL' from telecom.cell_strength;
select count(*) as DataConnection_count,'ALL' from telecom.data_connection;
第三步:计算普通.户(cmcc,cucc,ctcc)登录时使.的数据
select count(*) as NWQuality_count,operator_name from telecom.networkqualityinfo where operator_name in ('CMCC','CUCC','CTCC') group by operator_name;
select count(*) as Signal_Strength_count,network.network_name as network_name from telecom.cell_strength left join telecom.network on (substring(cell_strength.network_id,0,5)=network.network_id) where network_name in ('CMCC','CUCC','CTCC') group by network_name;
select count(*) as DataConnection_count,network.network_name as network_name from telecom.data_connection left join telecom.network on ( network.network_id = substring(data_connection.network_id,0,5)) where network_name in ('CMCC','CUCC','CTCC') group by network_name;
第四步:将计算结果写.数据表
由于这次的计算只会使用一次(历史数据只算一次),所以可以将计算结果直接手动添加到结果表。
这个结果表.于实现实时业务的数据存储,实时业务将读取历史数据综合与新增数据求和。最终将合并的结果更新到数据表
知识点33 中间结果转换成最终结果
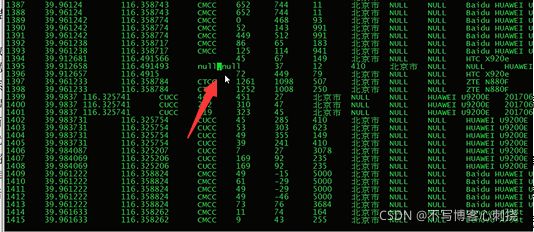
phoneix识别数据就是用逗号分割的 原本的制表符要换成逗号原本的逗号要换成其他符代替
第一步:将数据中原有的逗号替换成顿号
# 原 , 变成 、
sed -e 's/,/、/g' /export/phoenixdatas/NWQualit.csv > /export/phoenixdatas/NWQualit1.csv
sed -e 's/,/、/g' /export/phoenixdatas/Signal_Strength.csv >
/export/phoenixdatas/Signal_Strength1.csv
sed -e 's/,/、/g' /export/phoenixdatas/app_tra.c.csv > /export/phoenixdatas/app_tra.c1.csv
sed -e 's/,/、/g' /export/phoenixdatas/data_connection.csv >
/export/phoenixdatas/data_connection1.csv
第二步:将数据列与列的分隔符“\t” 替换成逗号
sed -e 's/\t/,/g' /export/phoenixdatas/NWQualit1.csv /export/phoenixdatas/NWQualit2.csv
sed -e 's/\t/,/g' /export/phoenixdatas/Signal_Strength1.csv /export/phoenixdatas/Signal_Strength2.csv
sed -e 's/\t/,/g' /export/phoenixdatas/app_tra.c1.csv /export/phoenixdatas/app_tra.c2.csv
sed -e 's/\t/,/g' /export/phoenixdatas/data_connection1.csv
/export/phoenixdatas/data_connection2.csv
知识点34 phoenix 介绍及安装部署
-
介绍
- phoenix是一个底层基于hbase 的SQL查询引擎,接收sql 语句,将sql转换成hbase 的api,进行数据的查询与计算.其优势,支持二级索引,对in、 like、or查询有相应的优化.案,对key也有优化策略。
安装部署
- phoenix是一个底层基于hbase 的SQL查询引擎,接收sql 语句,将sql转换成hbase 的api,进行数据的查询与计算.其优势,支持二级索引,对in、 like、or查询有相应的优化.案,对key也有优化策略。
-
第一步:下载安装包,将安装包上传到集群,并解压
-
第二步:将phoenix的server jar包,拷.到hbase 的lib.录下。(所有的hbase节点都要添加)
-
第三步:修改hbase 的hbase-site.xml添加.下内容
hbase.regionserver.wal.codec org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
zookeeper.znode.parent
/hbase -
第四步:将hbase-site.xml同步到所有hbase节点
-
第五步:将hbase-site.xml拷.到phoenix的bin.录下
-
第六步:重启hbase
知识点35 phoenix 的使用方式 (略)
1、批处理方式
2、命令行方式
3、可视化工具方式
4、JDBC链接方式
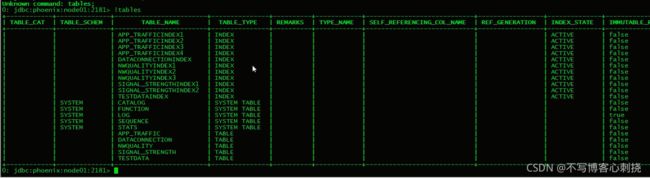
知识点36 phoenix 常用命令及索引
创建phoenix表
create table if not exists testtable(
A bigint not null,
B double,
C varchar(200),
D varchar(200)
CONSTRAINT testtable PRIMARY KEY(A));
查看表结构
!desc testtable;
删除表
drop table testable;
向表添加数据
python /export/servers/phoenix-4.14.0-cdh5.14.2/bin/psql.py -t testable node01 /opt/xxx.csv
数据查询
Select * from testable where A> 100;
索引类型
1、覆盖索引:使.场景所有的查询都要基于索引进.查询
2、全局索引:查询多(多读),写.少(少写)
3、本地索引:写.多(多写),查询少(少读)
知识点37:索引有序性总结
1、若索引字段的数量和顺序与查询条件的数量和顺序完全相同,那么查询效率最.。
2、创建索引的首个字段,作为查询条件的首个字段,效率较高。(其他条件的数据也在索引里)
3、查询字段越少,查询效率较好。
4、除此之外其他的查询效率都较差。
创建索引
CREATE INDEX testdataindex ON testdata (B,C,D,E,F)
知识点38 结果表的创建
创建phoneix表的字段顺序,必须与查询字段顺序一一对应
create table IF NOT EXISTS DataConnection ( id bigint not null, user_lat double, user_lon double, network_name varchar(200), network_type varchar(200), ping_value varchar(200), mobile_network_type varchar(200), time_index_client bigint CONSTRAINT DataConnection PRIMARY KEY(id) );
create table if not exists app_tra.c( id bigint not null, user_lon varchar(200),
user_lat varchar(200),
upload_tra.c double,
download_tra.c double,
package_name varchar(200),
network_name varchar(200),
app_name varchar(200),
os varchar(200),
os_version varchar(200),
company varchar(200),
start_time varchar(200),
end_time varchar(200),
network_type varchar(200) ,
allMobileTra.c varchar(200),
date bigint,
Landmark varchar(200),
companyModel varchar(200),
os_andversion varchar(200)
CONSTRAINT app_tra.c PRIMARY KEY(id));
create table Signal_Strength(
id bigint not null,
user_lon varchar(200),
user_lat varchar(200),
network_name varchar(200),
rssi bigint,
landmark varchar(200),
network_type varchar(200),
time_index bigint
CONSTRAINT Signal_Strength PRIMARY KEY(id)
); create table NWQuality(
id bigint not null,
GpsLat varchar(200),
GpsLon varchar(200),
NWOperator varchar(200),
ULSpeed double,
DLSpeed double,
Latency double,
province varchar(200),
NWType varchar(200),
landmark varchar(200),
CompanyModel varchar(200),
dayTime bigint
CONSTRAINT NWQuality PRIMARY KEY(id)
);
知识点39:创建NWQUALITY 索引
第一步:整理基于NWQUALITY表的查询语句
第二步:整理查询语句条件
第三步:整理索引条件

最终的创建索引的语句
CREATE INDEX nwQualityindex1 ON NWQUALITY (GpsLat,GpsLon,daytime,NWOperator,NWType) include (DLSPEED,ULSPEED,LATENCY);
CREATE INDEX nwQualityindex2 ON NWQUALITY (daytime,NWOperator,NWType,CompanyModel,landmark,Province)include (ULSpeed,DLSpeed,LATENCY);
CREATE INDEX nwQualityindex3 ON NWQUALITY (NWOperator,CompanyModel,dayTime, NWType)include (GpsLat,GpsLon,ULSpeed,DLSpeed,LATENCY);
详细过程.《所有SQL.xlsx》
知识点40 :索引创建

查看索引信息
最终索引查询


Signal_Strength, DataConnection, APP_TRAFFIC 这三张表的创建思路与NWQUALITY创建索引的顺序是相同的。同样详细的过程.《所有SQL.xlsx》
知识点41:业务报表的类型
1、柱状图、饼状图、曲线图(这类报表数据展示使.的技术方案案为百度的Echarts。)

- “信号覆盖 -典型地标信号强度跟踪”
- “信号覆盖 -典型地标信号强度统计”
- “.络质量 -.络质量统计”
- “.络质量 -.络速率排名”
- “.络质量 -典型地标.络质量跟踪”
- “.络质量 -典型地标.络质量统计”
- “数据链接 -数据链接率统计”
- “热.APP –热.APP流量跟踪”
- 热.APP –热.APP流量排名”
- “热.APP –典型地标热.APP流量排名”
- “热…机 – 热…机.络质量排名”
- “热…机 – 热…机流量排名”
- “热…机 – .机OS流量排名”
- “连接点 –连接点排名”
2、热力图(这类报表数据展示使用的技术方案为百度地图提供的“热力图”API。)
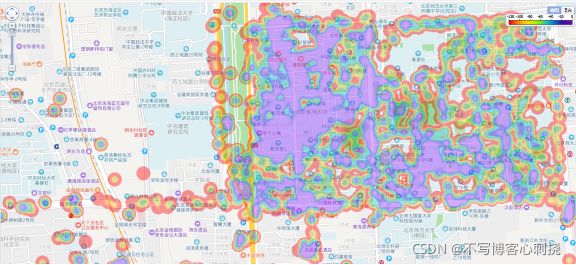
- “信号覆盖 -信号强度分布图”
- 热门APP –热.APP流量分布”
- “热门手机 –热…机流量分布”
- “个人用户 –周边网络质量”
3、瓷砖图(这类报表数据展示使.的技术.案为百度地图提供的“覆盖物”API (覆盖物使.了矩形、添加图标)。)
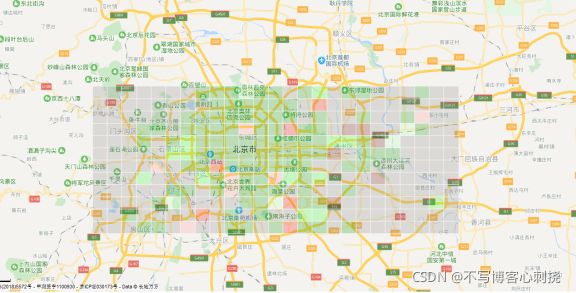
计算瓷砖图每个方块内平均信号质量,再去方块中心经纬度为坐标
- “网络质量 -.络质量分布”
- “热门APP –热.APP分布”
- “热门手机 –热门手机分布图”
- “热门手机 –.热门手机OS分布图”
4、街景图(这类报表数据展示使用的技术方案为百度地图提供的“全景图”API )

- 个⼈⽤户 –周边热⻔APP”
- “个⼈⽤户 –周边热⻔OS”
- “个⼈⽤户 –周边信号覆盖”
5、散点图(这类报表数据展示使用的技术方案为百度地图提供的“覆盖物”API )
- “数据链接 -数据链接率分布”
- “连接点 –连接点地理分布”
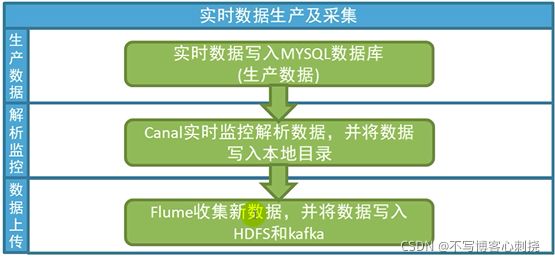
知识点42 实时业务数据生产及采集介绍
- 第一步:向业务系统的MYSQL数据库写.数据(MYSQL数据节点使.192.168.52.120)
mysql 需要预先开启binlog日志 - 第二步:安装canal 编写canal 监控mysql 实时变化数据的代码(解析binlog.志实现监控)
- 第三步:编写.ume 收集canal 解析后的数据,将.份数据写.HDFS.于离线计算,.份数据写.
kafka.于实现实时业务数据计算
知识点43 mysql 开启binlog及建表
开启binlog :
- 查看binlog是否开启 show variables like ‘log_bin’;
- on表示开启 off表示关闭
开启方方式:在my.cn内添加如下配置
- [mysqld]
- binlog配置
- log-bin = /usr/local/var/mysql/logs/mysql-bin.log
- binlog-format=ROW
- expire-logs-days = 14
- max-binlog-size = 500M
- server-id = 1
重启mysql生效,若重启失败请检查/usr/local/var/mysql/下logs.录的权限,若权限为root root,那么期待会失败,需要将权限改成mysql mysql。创建数据库及数据表
CREATE DATABASE IF NOT EXISTS APP DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
创建数据表
CREATE TABLE
networkqualityinfo (
id int(11) DEFAULT NULL,
ping varchar(200) DEFAULT NULL,
ave_downloadSpeed varchar(200) DEFAULT NULL,
max_downloadSpeed varchar(200) DEFAULT NULL,
ave_uploadSpeed varchar(200) DEFAULT NULL,
max_uploadSpeed varchar(200) DEFAULT NULL,
rssi varchar(200) DEFAULT NULL,
gps_lat varchar(200) DEFAULT NULL,
gps_lon varchar(200) DEFAULT NULL,
location_type varchar(200) DEFAULT NULL,
imei varchar(200) DEFAULT NULL,
server_url varchar(200) DEFAULT NULL,
ant_version varchar(200) DEFAULT NULL,
detail varchar(200) DEFAULT NULL,
time_client_test varchar(200) DEFAULT NULL,
time_server_insert varchar(200) DEFAULT NULL,
networkType varchar(200) DEFAULT NULL,
operator_name varchar(200) DEFAULT NULL,
wifi_bss_id varchar(200) DEFAULT NULL,
cell_id varchar(200) DEFAULT NULL,
province varchar(200) DEFAULT NULL,
city varchar(200) DEFAULT NULL,
) ENGINE=MyISAM DEFAULT CHARSET=utf8
id int(11) DEFAULT NULL,
imei varchar(200) DEFAULT NULL,
network_type varchar(200) DEFAULT NULL,
wifi_bssid varchar(200) DEFAULT NULL,
wifi_state varchar(200) DEFAULT NULL,
wifi_rssi varchar(200) DEFAULT NULL,
mobile_state varchar(200) DEFAULT NULL,
mobile_network_type varchar(200) DEFAULT NULL,
network_id varchar(200) DEFAULT NULL,
gsm_strength varchar(200) DEFAULT NULL,
cdma_dbm varchar(200) DEFAULT NULL,
evdo_dbm varchar(200) DEFAULT NULL,
internal_ip varchar(200) DEFAULT NULL,
web_url varchar(200) DEFAULT NULL,
ping_value varchar(200) DEFAULT NULL,
user_lat varchar(200) DEFAULT NULL,
user_lon varchar(200) DEFAULT NULL,
user_location_info varchar(200) DEFAULT NULL,
bs_lat varchar(200) DEFAULT NULL,
bs_lon varchar(200) DEFAULT NULL,
version varchar(200) DEFAULT NULL,
time_server_insert varchar(200) DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=utf8
CREATE TABLE
cell_strength (
id int(11) DEFAULT NULL,
network_id varchar(200) DEFAULT NULL,
network_type varchar(200) DEFAULT NULL,
gsm_strength varchar(200) DEFAULT NULL,
cdma_dbm varchar(200) DEFAULT NULL,
evdo_dbm varchar(200) DEFAULT NULL,
gsm_bit_errorrate varchar(200) DEFAULT NULL,
cdma_ecio varchar(200) DEFAULT NULL,
evdo_ecio varchar(200) DEFAULT NULL,
user_lat varchar(200) DEFAULT NULL,
user_lon varchar(200) DEFAULT NULL,
user_location_info varchar(200) DEFAULT NULL,
bs_lat varchar(200) DEFAULT NULL,
bs_lon varchar(200) DEFAULT NULL,
time_index varchar(200) DEFAULT NULL,
imei varchar(200) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8
知识点44 canal安装配置
- 1、创建/export/servers/canal目录
- 2、解tar zxvf canal.deployer-1.0.19.tar.gz -C /export/servers/canal/压
- 3、配置1 canal.properties内设置ID 和port(/export/servers/canal/conf)
canal.id= 1 canal.port= 11111配置2 设置instance.properties配置(/export/servers/canal/conf/example)
canal.instance.mysql.slaveId = 1234(不能与address节点的mysql id 相同)
canal.instance.master.address = 192.168.52.120:3306 (被监控的mysql所在服务器的IP) - 4、bin/startup.sh
canal并不是把数据直接给flume,而是存到文件里,让flume自己采集.
知识点45实时数据成产与实时数据收集
流程
与进行数据实时生产,实时收集的过程
- mysql 实时数据生成
java -classpath TelecomRealtimeBusiness-1.0-SNAPSHOT.jar 'makedata.MakeData'192.168.52.120 root 123456 APP data_connection 10
- canal 实时解析mysql
java -classpath TelecomRealtimeBusiness-1.0-SNAPSHOT.jar 'canal.CanalClient'
- fume 实时收集canal解析后的数据(前提kafka 有可.的topic,HDFS可.)
bin/flume-ng agent -c conf -f conf/spooldir2kafka2.conf -n a1 -.ume.root.logger=INFO,console
>bin/flume-ng agent -c conf -f conf/spooldir2kafka.conf -n a1 -D.ume.root.logger=INFO,console
实时采集流程的梳理:在linux中启动生产数据进程,这时canal也会启动实时采集,一批是五个文件,存到每张表对应的文件夹下,等待flume采集,分别到hdfs和kafka,第一个采集配置会有三个source,两个channu,两个sink,被采集过的canal指定文件会被打上后缀标签.
知识点46 实时数据计算
计算流程
实时代码处理流程
- 1、读取数据库内原始的数据量(程序初始化时读取一次)
- 2、Spark Streaming实时读取kafka新增数据(每个2秒钟一次拉取kafka数据)
- 3、根据业务需求统计出每个业务场景的新增数据量(“网络质量”、“信号覆盖”、“数据连接”)
- 4、每个迭代周期,将历史数据数量与新增的数据数量求总和并更新到数据库。
线上业务系统每隔1秒钟在数据库内查询一次结果,展示在前端界面。
最后项目打包,将程序包上传到集群,在集群上提交实时计算任务
bin/spark-submit \
--class Updatas \
--master spark://node01:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/root/RealtimeComput-1.0-SNAPSHOT.jar \