基于简单协同过滤推荐算法职位推荐系统
基于简单协同过滤推荐算法的职位推荐系统。篇幅比较大需要分几次博客
文章目录第一篇1爬虫方面(我项目也叫信息采集器)
- 前言
- 一、用网络爬虫对51job网站进行爬取
- 二、信息采集器
-
- 2.爬虫
- 总结
前言
运用到python网络爬虫技术对51job网站进行爬取。爬下来的数据进行清理入库。然后再通过python的Django 这个web框架搭建出一个小网站,对职位信息信息进行展示。对注册用户行为信息,通过简单的协同过滤推荐算法算出用户相似度。根据用户相似程度推荐相似用户的职位信息。
一、用网络爬虫对51job网站进行爬取
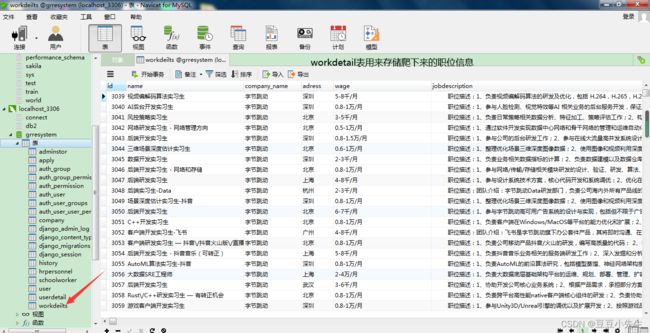
爬下来的数据存在数据库中,本项目有一个这样的功能:就是让管理员通过框选某大厂名称,相应爬取对应名称下载51job上的职位。就是管理员选择名称后进而点击采集按钮就开始爬取数据。图片实例如下。本人前端设计的比较丑。见谅

最终爬取数据入库展示
二、信息采集器
第三方库:
#信息采集器,负责采集招聘信息
import requests
import re
import random
from multiprocessing import Pool
from .models import workdeilts,company
from lxml import etree
import time
from django.shortcuts import render,redirect
2.爬虫
本人原本想爬取boss,奈何技术有限,在模拟登录后,用我自己账号的session,boss只给我爬取大概5页的机会,在试用别人账号session后也这样。没能解决boss的反爬放弃爬取boss。后爬取51job,51job职位名称等都是用到json格式。还比较简单。然后又深度爬虫,根据职位的url,爬下职位完整信息。由于爬虫具有一定分时效性,本系统在2021年3,4月份时还亲测有效。在这里给出我当初怎样进行爬虫的。
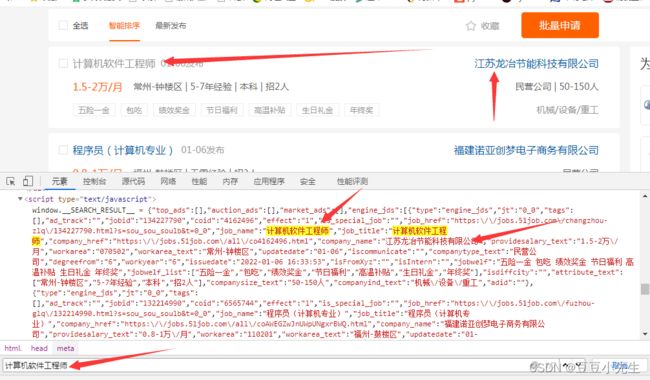
进项深度爬取,找到url,爬,将有用的信息爬下,在这里我不免吐槽一下,这个格式也太不规范了。有的是p标签有的是li标签反正嵌套的比较乱。
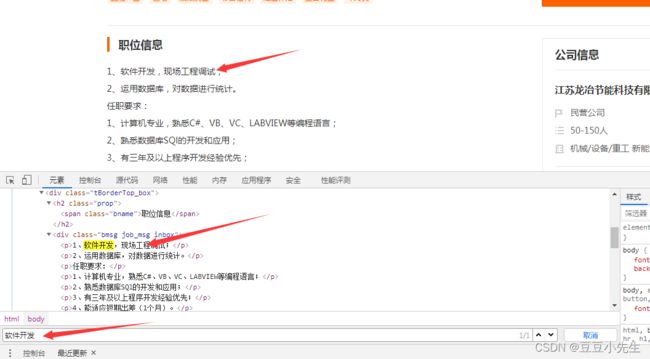
**下面贴代码,由于我这个是在web中做的所以那可能不能直接复制粘贴。理解就好。我会吧我的项目挂在博客需要自取。
# 爬取51job
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "guid=8766426d6a6e7cb73f5784127814feeb; nsearch=jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D; __guid=212605071.4274319711180497400.1594717185324.2678; _ujz=MTg3NTgzNTU3MA%3D%3D; ps=needv%3D0; 51job=cuid%3D187583557%26%7C%26cusername%3Demail_20210320_d7612b93%26%7C%26cpassword%3D%26%7C%26cname%3D%25C0%25B2%25C0%25B2%25C0%25B2%26%7C%26cemail%3D1283062150%2540qq.com%26%7C%26cemailstatus%3D0%26%7C%26cnickname%3D%26%7C%26ccry%3D.0v0O9eWnGAtg%26%7C%26cconfirmkey%3D12a4WxI%252FuvU0Y%26%7C%26cautologin%3D1%26%7C%26cenglish%3D0%26%7C%26sex%3D0%26%7C%26cnamekey%3D1246IFugsIKHc%26%7C%26to%3D08ee79b7343b47f6629abf87204ca02160686738%26%7C%26; adv=adsnew%3D0%26%7C%26adsnum%3D4858120%26%7C%26adsresume%3D1%26%7C%26adsfrom%3Dhttps%253A%252F%252Fwww.so.com%252Fs%253Fq%253D51job%2525E5%252589%25258D%2525E7%2525A8%25258B%2525E6%252597%2525A0%2525E5%2525BF%2525A7%2525E7%2525BD%252591%2526src%253Dsrp_suggst_revise%2526fr%253D360se7_addr%2526psid%253Dcff8a6a527fbe2af36a5885576c3039a%2526eci%253D%2526nlpv%253Dtest_dt_61%26%7C%26ad_logid_url%3Dhttps%253A%252F%252Ftrace.51job.com%252Ftrace.php%253Fadsnum%253D4858120%2526ajp%253DaHR0cHM6Ly9ta3QuNTFqb2IuY29tL3RnL3NlbS9MUF8yMDIwXzEuaHRtbD9mcm9tPTM2MGFk%2526k%253D7d16490a53bc7f778963fbe04432456c%2526qhclickid%253D38a22d9fefae38b3%26%7C%26; search=jobarea%7E%60000000%7C%21ord_field%7E%600%7C%21recentSearch0%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%BF%AA%B7%A2%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch1%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA01%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch2%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch3%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA01%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%BF%AA%B7%A2%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch4%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA01%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%B2%E2%CA%D4%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21collapse_expansion%7E%601%7C%21; slife=lastlogindate%3D20210406%26%7C%26; monitor_count=3",
"Host": "jobs.51job.com",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
}
params = {
"VerType": "3",
"webId": "2",
"logTime": "1617756869425",
"ip": "111.61.205.194",
"guid": "8766426d6a6e7cb73f5784127814feeb",
"domain": "jobs.51job.com",
"pageCode": "10201",
"cusParam": "118758355751job_web0",
"vt": "1617756869524",
"logType": "pageView"
}
def get_data(url):
response = requests.get(url, headers=headers)
status = response.status_code
data = response.content.decode('gbk')
return data, status
def get_job(url):
data, status = get_data(url)
if status == 200:
job_name_p = re.compile('job_name":"(.*?)","job_title')
job_name = job_name_p.findall(data) # 工作名称
job_url_p = re.compile('job_href":"(.*?)","')
job_url = job_url_p.findall(data) # url中获取详细职位描述
attribute_text_p = re.compile('attribute_text":\["(.*?)"\],"companysize_text')
attribute_text = attribute_text_p.findall(data)#
company_name_p = re.compile('company_name":"(.*?)","')
company_name = company_name_p.findall(data) # 公司名称
saily_p = re.compile('providesalary_text":"(.*?)","')
saily = saily_p.findall(data) # 工资
address_p = re.compile('workarea_text":"(.*?)","')
address = address_p.findall(data) # 工作地点
updatadate_p = re.compile('updatedate":"(.*?)","')
updatadate = updatadate_p.findall(data) # 更新日期
company_text_p = re.compile('companytype_text":"(.*?)","')
company_text = company_text_p.findall(data) # 公司类型
companysize_text_p = re.compile('companysize_text":"(.*?)","')
companysize_text = companysize_text_p.findall(data) # 公司规模
companyind_text_p = re.compile('companyind_text":"(.*?)","')
companyind_text = companyind_text_p.findall(data) # 公司行业
for i in range(len(job_name)):
try:
job_name1=job_name[i]# 工作名称
company_name1=company_name[i]# 公司名称
saily1=saily[i].replace('\\', '')# 工资
address1=address[i]# 工作地点
exper_req=attribute_text[0].split('","')[1].replace('/',"")#经验要求
edu_req=attribute_text[0].split('","')[2]#学历要求
need_num=attribute_text[0].split('","')[3]#招工人数
updatadate1=updatadate[i]# 更新日期
companyind_text1=companyind_text[i].replace('\\', '')# 公司行业
company_text1=company_text[i]# 公司类型
companysize1=companysize_text[i] # 公司规模
end_url = job_url[i].replace('\\', '')
response = requests.get(url=end_url, headers=headers, params=params)
data = response.content.decode('gbk')
selector = etree.HTML(data)
content_xml = selector.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div/*')
br = selector.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div/text()')
str = ""
for p in content_xml:
span = p.xpath('span')
li = p.xpath('li')
p_p = p.xpath('strong')
if span != [] or li != [] or p_p != []:
if span != []:
for i in span: # 如果是p标签套span标签,则依次取出span
if i.text == None:
span1 = i.xpath('span')
for j in span1:
str = str + j.text
else:
# print(i.text)
str = str + i.text
elif li != []:
for i in li: # 如果是p标签套li标签,则依次取出li
# print(i.text)
str = str + i.text
else:
for i in p_p: # 如果是p标签套p标签,则依次取出p
# print(i.text)
str = str + i.text
else: # 如果是单独的p标签,则无须取span
if p.text != None and p != []:
# print(p.text)
str = str + p.text
else:
for i in br:
str = str + i
# print(str)
break
#try:
list1 = ['任职资格', '任职要求', '岗位要求', '职位要求', '岗位职责', '要求']
for i in list1:
if i in str:
job_description, job_requirements = str.split(i)[0], '任职资格' + \
str.split(i)[1]
#print(job_description)
#print(job_requirements)
if job_description and job_requirements:
company1=company.objects.filter(name=company_name1)
if company1.exists():
#print('公司存在!')
company_name2=company.objects.get(name=company_name1)
data = workdeilts.objects.filter(name=job_name1, company_name=company_name1,adress=address1, update=updatadate1)
if data.exists():
#print('职位存在!')
continue
else:
workdeilts.objects.create(company_id=company_name2,name=job_name1, company_name=company_name1,exper_req=exper_req,edu_req=edu_req,need_num=need_num,adress=address1, wage=saily1,jobdescription=job_description,jobrequirements=job_requirements,update=updatadate1)
#print('插入职位成功')
else:
#print('公司不存在!')
company.objects.create(name=company_name1, people=companysize1,nature_of_bissiness=company_text1,industry=companyind_text1)
#print('添加公司成功')
company2=company.objects.get(name=company_name1)
workdeilts.objects.create(company_id=company2,name=job_name1, company_name=company_name1,exper_req=exper_req,edu_req=edu_req,need_num=need_num,adress=address1, wage=saily1,jobdescription=job_description,jobrequirements=job_requirements,update=updatadate1)
#print('插入职位成功')
continue
else:
continue
#except:
#pass
except:
pass
else:
j = 19
return j
def collect(request):
if request.method=='POST':
data=request.POST
zhiwei_post_list=data.getlist('company')
#print(zhiwei_post_list)
# zhiwei_list=['开发','python','java','c++','']
zhiweilist = ['web', '前端', '嵌入式', '大数据', 'python', 'java', 'c++', 'linux', 'IT实习', '机器学习','后端', '人工智能', '测试', '运维']
zhiwei_list=zhiwei_post_list+zhiweilist
random.shuffle(zhiwei_list)
#print(zhiwei_list)
#p=Pool(1)想利用异步多进程实现爬取,存储,没实现,有空了解决
for i in zhiwei_list:
for j in range(1, 6):
#https://search.51job.com/list/000000,000000,0100%252c7700%252c7200%252c7300,01,9,99,+,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
#https://search.51job.com/list/000000,000000,0000,00,9,99,字节跳动,2,1.html?lang=c&postchannel=0000&workyear=99
url = "https://search.51job.com/list/000000,000000,0000,00,9,99," + i + ",2," + str(
j) + ".html?lang=c&postchannel=0000&workyear=99"
get_job(url)
#p.apply_async(get_job, args=(url,))
time.sleep(0.5)
#p.close()
#p.join()
print('数据采集结束!!!!')
return render(request,'index.html')
总结
接下来我会把我的项目完整更上。我也是个小白。哈哈哈就随手写写。我把我的项目挂上。本文是我原创。未经本人同意不得作为商业价值进行传播。