【数据结构与算法】双向循环链表的实现
作者:@阿亮joy.
专栏:《数据结构与算法要啸着学》
座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根

目录
-
- 双向循环链表的引入
- 双向循环链表的实现
-
- List.h
- List.c
- Test.c
- 顺序表和带哨兵位双向循环链表的对比
- 总结
双向循环链表的引入
因为单向链表不能实现任意位置的插入和删除,所以今天我们来学习一个能够高效地在任意位置插入和删除数据的结构 —— 带哨兵位的双向循环链表。

什么是哨兵位?
哨兵位(DummyNode)也是一个节点,但是该节点不存储任何的有效数据。哨兵位的创建方便我我们进行头插数据。如果有了哨兵位的话,头插的时候,我们就不再需要改变头节点了。如果还是不是很理解的话,那么先看下面链表的实现。或许看完,你就能够理解了。
双向循环链表的实现
带哨兵位双向循环链表要实现的函数接口有:初始化链表、销毁链表、打印链表、申请节点、尾插数据、头插数据、判断链表是否为空链表、尾删数据、头插数据、链表节点的个数、查找数据、在pos位置之前插入数据和删除pos位置的数据。虽然带哨兵位双向循环链表的结构很复杂,但是其函数接口相当容易事项。来一起学习一下吧!
List.h
#pragma once
#include Test.c源文件里面是头文件的包含,类型的重命名、结构体的声明以及函数接口的声明。
List.c
List.c源文件负责实现函数接口。注意:因为phead是指向哨兵位的指针,phead不可能为NULL,所以都需要对phead进行断言assert(phead)。
#include "List.h"
// 链表初始化
//void ListInit(LTNode** pphead)
//{
// assert(pphead);
// *pphead = (LTNode*)malloc(sizeof(LTNode)); // 哨兵位
// if(*pphead == NULL)
// {
// perror("malloc fail");
// exit(-1);
// }
// (*pphead)->prev = *pphead;
// (*pphead)->next = *pphead;
//}
LTNode* ListInit()
{
LTNode* DummyNode = (LTNode*)malloc(sizeof(LTNode));// 哨兵位
if (DummyNode == NULL)
{
perror("malloc fail");
exit(-1);
}
DummyNode->prev = DummyNode;
DummyNode->next = DummyNode;
return DummyNode;
}
// 可以传二级,内部置空头结点
// 建议:也可以考虑用一级指针,让调用ListDestory的人置空(保持接口一致性)
// 销毁链表
void ListDestory(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
LTNode* next = cur->next;
free(cur);
cur = next;
}
free(phead);
//phead = NULL; // 对形参的修改不会影响实参
}
// 打印链表
void ListPrint(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
printf("phead<=>");
while (cur != phead)
{
if (cur->next != phead)
{
printf("%d<=>", cur->data);
}
else
{
printf("%d<=>phead", cur->data);
}
cur = cur->next;
}
printf("\n");
}
// 申请节点
LTNode* BuyListNode(LTDataType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->prev = NULL;
newnode->next = NULL;
return newnode;
}
// 在pos位置之前插入数据
void ListInsert(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* newnode = BuyListNode(x);
LTNode* prev = pos->prev;
// prev newnode pos
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = newnode;
}
// 尾插数据
void ListPushBack(LTNode* phead, LTDataType x)
{
assert(phead);
//LTNode* newnode = BuyListNode(x);
//LTNode* tail = phead->prev;
// phead ... tail newnode
//tail->next = newnode;
//newnode->prev = tail;
//newnode->next = phead;
//phead->prev = newnode;
ListInsert(phead, x); // 调用ListInsert函数完成尾插
}
// 头插数据
void ListPushFront(LTNode* phead, LTDataType x)
{
assert(phead);
// 考虑链接顺序
//LTNode* newnode = BuyListNode(x);
//newnode->next = phead->next;
//phead->next->prev = newnode;
//phead->next = newnode;
//newnode->prev = phead;
// 不需要考虑链接顺序
//LTNode* newnode = BuyListNode(x);
//LTNode* first = phead->next;
//phead->next = newnode;
//newnode->prev = phead;
//newnode->next = first;
//first->prev = newnode;
LTNodeInsert(phead->next, x); // 调用LTNodeInsert函数完成头插
}
// 判断链表是否为空链表
bool ListEmpty(LTNode* phead)
{
assert(phead);
return phead == phead->next; // 链表为空时,phead = phead->next
}
// 删除pos位置的数据
void ListErase(LTNode* pos)
{
assert(pos);
LTNode* prev = pos->prev;
LTNode* next = pos->next;
// prev pos next
prev->next = next;
next->prev = prev;
free(pos);
}
// 尾删数据
void ListPopBack(LTNode* phead)
{
assert(phead);
assert(!ListEmpty(phead));
// phead ... prev tail
//LTNode* tail = phead->prev;
//LTNode* prev = tail->prev;
//prev->next = phead;
//phead->prev = prev;
//free(tail);
//tail = NULL; // tail置不置空都可以,因为对形参的修改不会影响实参
ListErase(phead->prev); // 调用ListErase函数完成尾删
}
// 头删数据
void ListPopFront(LTNode* phead)
{
assert(phead);
assert(!ListEmpty(phead));
// phead first second
//LTNode* first = phead->next;
//LTNode* second = first->next;
//phead->next = second;
//second->prev = phead;
//free(first);
//first = NULL;
ListErase(phead->next); // 调用ListErase函数完成头删
}
// 链表节点的个数
size_t ListSize(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
size_t n = 0;
while (cur != phead)
{
n++;
cur = cur->next;
}
return n;
}
// 查找数据
LTNode* ListFind(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
初始化链表
初始化链表有两种方式,第一种方式是函数的参数为二级指针
LTNode** pphead,返回值为void;第二种方式是函数没有参数,返回值为LTNode*。以上两种方式均可实现链表的初始化,个人推荐第二种实现方式。
// 链表初始化
void ListInit(LTNode** pphead)
{
assert(pphead);
*pphead = (LTNode*)malloc(sizeof(LTNode)); // 哨兵位
if(*pphead == NULL)
{
perror("malloc fail");
exit(-1);
}
(*pphead)->prev = *pphead;
(*pphead)->next = *pphead;
}
LTNode* ListInit()
{
LTNode* DummyNode = (LTNode*)malloc(sizeof(LTNode));// 哨兵位
if (DummyNode == NULL)
{
perror("malloc fail");
exit(-1);
}
DummyNode->prev = DummyNode;
DummyNode->next = DummyNode;
return DummyNode;
}
打印链表
因为循环链表中的任何一个节点都会指向
NULL,所以循环链表的遍历就能想单向链表那样子遍历了。那该如何遍历呢?定义一个指针LTNode* cur = head->next,当cur == head时,循环遍历链表结束。
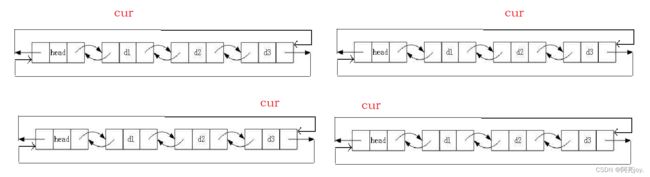
// 打印链表
void ListPrint(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
printf("phead<=>");
while (cur != phead)
{
if (cur->next != phead)
{
printf("%d<=>", cur->data);
}
else
{
printf("%d<=>phead", cur->data);
}
cur = cur->next;
}
printf("\n");
}
销毁链表
销毁链表的函数参数可以是一级指针
LTNode*,也可以是二级指针LTNode**。为了保持接口的一致性,本人采用一级指针的方式。如果销毁链表函数的参数为一级指针,则需要调用该函数的人将指向哨兵位的指针置为NULL。
// 可以传二级,内部置空头结点
// 建议:也可以考虑用一级指针,让调用ListDestory的人置空(保持接口一致性)
// 销毁链表
void ListDestory(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
LTNode* next = cur->next;
free(cur);
cur = next;
}
free(phead);
//phead = NULL; // 对形参的修改不会影响实参
}
申请节点
在插入数据时,需要申请新的节点
newnode来存储数据。如果申请节点失败,那就直接结束程序,没有必要继续往下执行代码了。如果申请节点成功,那么newnode->data = x, newnode->prev = NULL, newnode->next = NULL,最后将newnode的值返回。
LTNode* BuyListNode(LTDataType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->prev = NULL;
newnode->next = NULL;
return newnode;
}
判断链表是否为空链表
当
phead == phead->next时,链表为空
// 判断链表是否为空链表
bool ListEmpty(LTNode* phead)
{
assert(phead);
return phead == phead->next; // 链表为空时,phead = phead->next
}
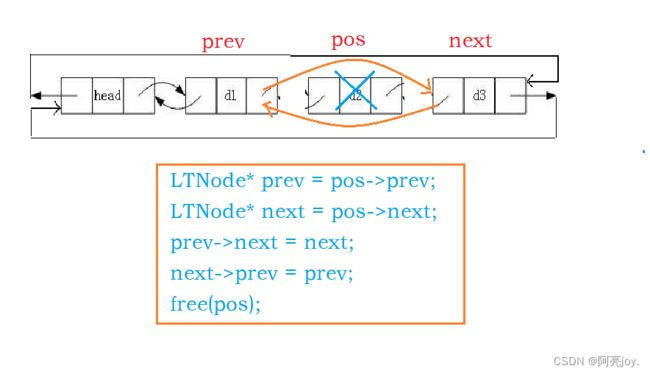
在pos位置之前插入数据
1.申请新节点
newnode
2.插入数据
3.注意:prev-next为头结点,prev->prev为尾结点。ListInsert(phead->next, x)为头插,ListInsert(phead, x)为尾插
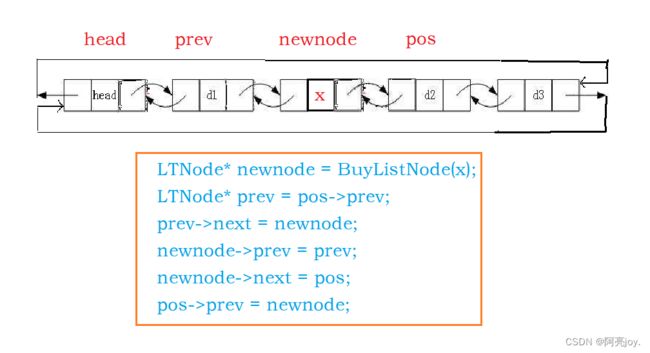
// 在pos位置之前插入数据
void ListInsert(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* newnode = BuyListNode(x);
LTNode* prev = pos->prev;
// prev newnode pos
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = newnode;
}
尾插数据
1.申请新节点
newnode
2.插入数据可调用函数ListInsert(phead, x)
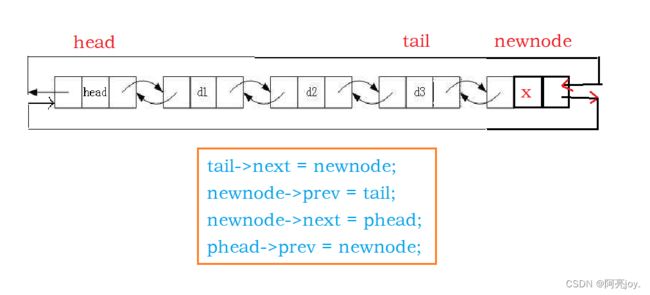
// 尾插数据
void ListPushBack(LTNode* phead, LTDataType x)
{
assert(phead);
//LTNode* newnode = BuyListNode(x);
//LTNode* tail = phead->prev;
// phead ... tail newnode
//tail->next = newnode;
//newnode->prev = tail;
//newnode->next = phead;
//phead->prev = newnode;
ListInsert(phead, x); // 调用ListInsert函数完成尾插
}
头插数据
1.申请新节点
newnode
2.插入数据可调用函数ListInsert(phead->next, x)
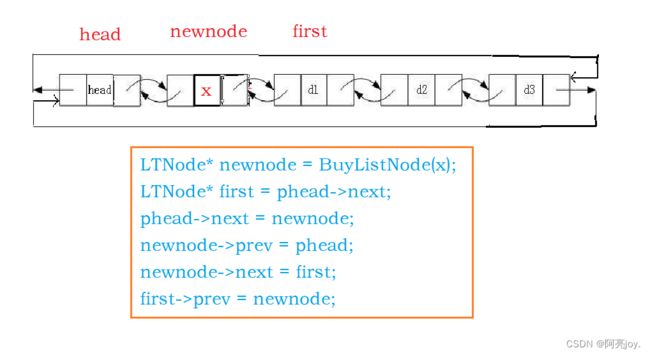
// 头插数据
void ListPushFront(LTNode* phead, LTDataType x)
{
assert(phead);
// 考虑链接顺序
//LTNode* newnode = BuyListNode(x);
//newnode->next = phead->next;
//phead->next->prev = newnode;
//phead->next = newnode;
//newnode->prev = phead;
// 不需要考虑链接顺序
//LTNode* newnode = BuyListNode(x);
//LTNode* first = phead->next;
//phead->next = newnode;
//newnode->prev = phead;
//newnode->next = first;
//first->prev = newnode;
LTNodeInsert(phead->next, x); // 调用LTNodeInsert函数完成头插
}
删除pos位置的数据
1.对
pos位置进行断言
2.删除数据
3.注意:prev-next为头结点,prev->prev为尾结点。ListErase(phead->next,)为头删,ListErase(phead->prev)为尾删
// 在pos位置之前插入数据
// 删除pos位置的数据
void ListErase(LTNode* pos)
{
assert(pos);
LTNode* prev = pos->prev;
LTNode* next = pos->next;
// prev pos next
prev->next = next;
next->prev = prev;
free(pos);
}
尾删数据
1.判断链表是否为空
assert(!ListEmpty(phead))
2.删除数据可调用函数ListErase(phead->prev)
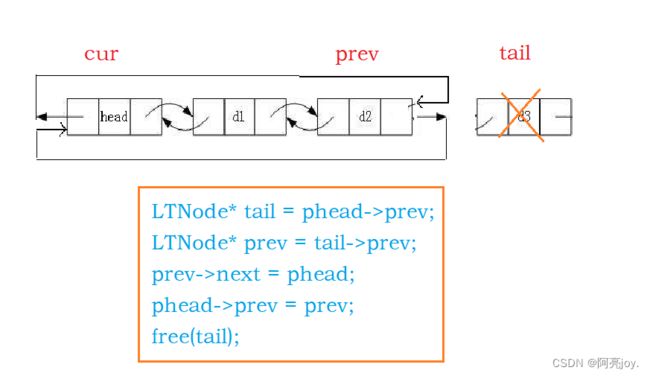
// 尾删数据
void ListPopBack(LTNode* phead)
{
assert(phead);
assert(!ListEmpty(phead));
// phead ... prev tail
//LTNode* tail = phead->prev;
//LTNode* prev = tail->prev;
//prev->next = phead;
//phead->prev = prev;
//free(tail);
//tail = NULL; // tail置不置空都可以,因为对形参的修改不会影响实参
ListErase(phead->prev); // 调用ListErase函数完成尾删
}
头删数据
1.判断链表是否为空
assert(!ListEmpty(phead))
2.删除数据可调用函数ListErase(phead->next,)
// 头删数据
void ListPopFront(LTNode* phead)
{
assert(phead);
assert(!ListEmpty(phead));
// phead first second
//LTNode* first = phead->next;
//LTNode* second = first->next;
//phead->next = second;
//second->prev = phead;
//free(first);
//first = NULL;
ListErase(phead->next); // 调用ListErase函数完成头删
}
链表节点的个数
利用
while循环遍历链表,就能算出链表节点的个数。
// 链表节点的个数
size_t ListSize(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
size_t n = 0;
while (cur != phead)
{
n++;
cur = cur->next;
}
return n;
}
查找数据
利用
while循环遍历链表,如果有节点的数据等于要查找的数据x,就返回节点的地址cur;如果在链表中找不到x,就返回空指针NULL。
// 查找数据
LTNode* ListFind(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
Test.c
Test.c源文件负责测试函数接口的功能是否达到我们的预期。以下是本人写的一些测试案例,大家可以参考一下。
#include "List.h"
// 测试尾插、打印链表、销毁链表
void ListTest1()
{
LTNode* plist = ListInit();
ListPushBack(plist, 1);
ListPushBack(plist, 2);
ListPushBack(plist, 3);
ListPushBack(plist, 4);
ListPushBack(plist, 5);
ListPrint(plist); // pehad<=>1<=>2<=>3<=>4<=>5<=>phead
ListDestory(plist);
plist = NULL; // 需要手动置空
}
// 测试头插、尾删、头删
void ListTest2()
{
LTNode* plist = ListInit();
ListPushFront(plist, 1);
ListPushFront(plist, 2);
ListPushFront(plist, 3);
ListPushFront(plist, 4);
ListPushFront(plist, 5);
ListPrint(plist); // pehad<=>5<=>4<=>3<=>2<=>1<=>phead
// 头删
ListPopFront(plist);
ListPopFront(plist);
ListPrint(plist); // pehad<=>3<=>2<=>1<=>phead
// 尾删
ListPopBack(plist);
ListPopBack(plist);
ListPrint(plist); // pehad<=>3<=>phead
ListDestory(plist);
plist = NULL;
}
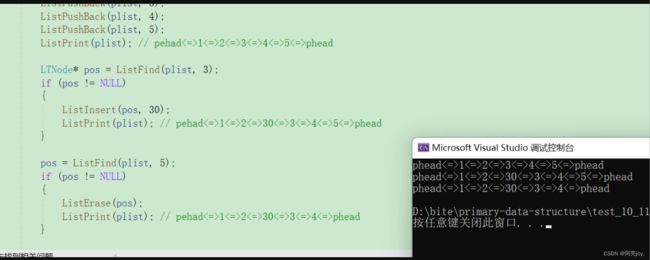
// 测试查找数据、在pos位置之前插入数据、删除pos位置的数据
void ListTest3()
{
LTNode* plist = ListInit();
ListPushBack(plist, 1);
ListPushBack(plist, 2);
ListPushBack(plist, 3);
ListPushBack(plist, 4);
ListPushBack(plist, 5);
ListPrint(plist); // pehad<=>1<=>2<=>3<=>4<=>5<=>phead
LTNode* pos = ListFind(plist, 3);
if (pos != NULL)
{
ListInsert(pos, 30);
ListPrint(plist); // pehad<=>1<=>2<=>30<=>3<=>4<=>5<=>phead
}
pos = ListFind(plist, 5);
if (pos != NULL)
{
ListErase(pos);
ListPrint(plist); // pehad<=>1<=>2<=>30<=>3<=>4<=>phead
}
ListDestory(plist);
plist = NULL;
}
int main()
{
//ListTest1();
//ListTest2();
ListTest3();
return 0;
}
顺序表和带哨兵位双向循环链表的对比
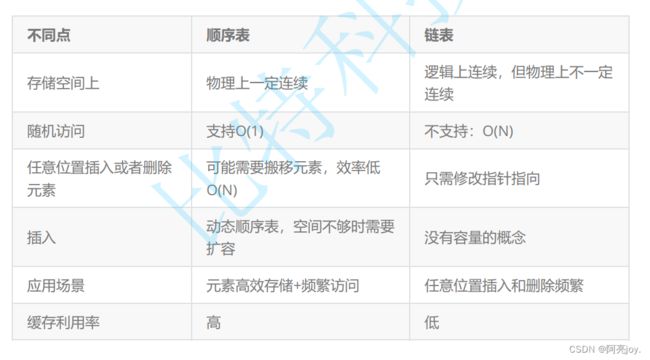

除了缓存利用率的区别比较难理解,我相信其它的区别都比较好理解。那现在我们就来学习一下上面是缓存利用率。学习这个之前,我们需要了解一下存储器的层次结构。

存储器层次结构还能用以下的图片来形象地表示。
为了了解高速缓存命中率,我们来对比一下顺序表的遍历打印和链表的遍历打印。程序经过编译转换成二进制指令,然后CPU会执行这些二进制指令。执行指令时,就需要相关的数据。而数据是存储在内存中的,并且CPU不会去直接访问内存。那么,CPU怎么拿到内存中的数据呢?这时候,就需要借助三级缓存。
CPU先看一下需要的数据在不在三级缓存中,在(专业术语为命中)就直接访问。如果不命中的话,先将需要的数据从内存加载到三级缓存,然后CPU再访问数据。缓存每次加载数据的多少取决于硬件。如果一个内存位置的数据被加载到三级缓存,那么这个位置的附近位置的数据也会被加载到三级缓存中,这是高速缓存的局部性原理。
因为顺序表的结构在物理上是连续的,而链表的结构在物理上是不一定连续的,所以顺序表的数据一次就能加载到三级缓存中去,而链表的数据需要好几次才能完全加载到三级缓存中。所以,顺序表的高速缓存命中率会比链表的高速缓存利用率高。

总结
有关于链表的内容已经全部讲解结束了,这里有一些经典的链表题,可以点击跳转:链表OJ题1、链表OJ题2、链表OJ题3以及经典的环形链表。以上就是本篇博客的全部内容了,如果大家觉得有收获的话,可以点个三连支持一下!谢谢大家啦!❣️