更多模型,更强功能,快来开箱新一代图像分类开源框架
MMClassification 是 OpenMMLab 生态面向图像分类的开源算法库,主要涵盖了计算机视觉领域丰富的基础模型架构。
2020 年 10 月,MMClassification 发布了首个版本,集成了当时的主流分类模型;2021 年 9 月,MMClassification 发布了 v0.16.0 版本,提供了对下游检测,分割等任务的较为完善的支持;2022 年 9 月,我们发布了 MMClassification v1.0.0rc,全面升级了架构设计,适配全新的 OpenMMLab 2.0 体系。
我们接下来将从 全新架构设计,更完善的功能,更丰富的算法库,更易用的模型部署四个方面,对全新升级的 MMClassification 1.0 进行介绍。
全新架构设计
在 MMClassification 原有的架构设计中,对于一个典型的模型训练过程,我们可以发现各个模块的构建被分散在了脚本、MMClassification 库函数、MMCV 库函数中(如图 1 所示)模型的前向传播,反向更新分散在执行器和钩子中,这对于用户理解训练流程带来了很多困难,用户需要自定义修改时容易找不到位置。
在新的架构中,MMEngine 的执行器集中了所有的模块构建功能,训练脚本只用于最基本的配置解析(如图 2 所示),这样新的训练流程不仅逻辑更加清晰,大大减少了代码量,还能为用户带来更方便的模型调试体验,让用户灵活地定义模型的前向和方向过程。

图 1:原架构训练逻辑
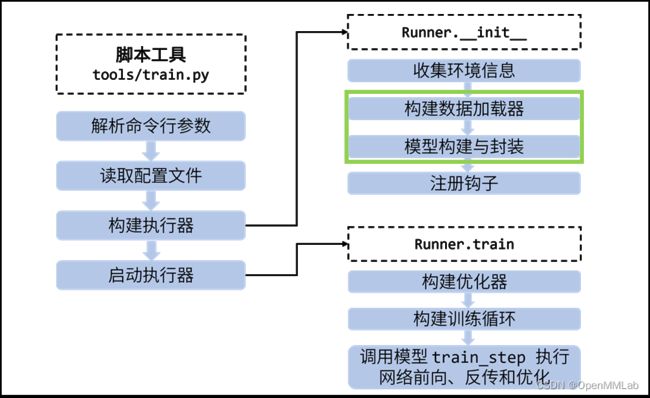
图 2:新架构训练逻辑
更完善的功能
跨项目引用配置文件
OpenMMLab 2.0 的配置文件支持跨仓库调用,这意味着只要你安装了对应的仓库,那么不需要复制任何文件就可以轻松调用 OpenMMLab 其他项目的配置文件。在基础模型的算法研究中,当我们开发了一个新的基础模型,并完成了模型在图像分类上的实验,想探索这个预训练模型在下游检测任务中的性能时,我们可以通过如下的简单配置,快速地训练起一个基于 MMDetection 的物体检测任务。
_base_ = 'mmdet::faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py'
custom_imports=dict(imports='mmcls.models') model = dict(
backbone=dict(
type='mmcls.SwinTransformer',
arch='tiny',
img_size=224,
out_indices=(0, 1, 2, 3),
init_cfg=dict(
type='Pretrained',
checkpoint=...,
prefix='backbone'
),
_delete_=True),
neck=dict(in_channels=[96, 192, 384, 768]))
可视化工具
在全新升级的 MMClassification 中,我们集成了完善的可视化工具,可以方便地查看图片和优化器的参数策略。在数据展示层面,我们支持多种模式的图片查看,如拼接和流水线。

图 3:拼接模式(左侧为原图,右侧为数据增强后的图片)

图 4 流水线模式(左侧为原图,右侧为依次变换的图片)
我们也提供了对优化器参数策略的可视化,支持用户在训练前就对学习率,动量等参数进行可视化,如下两张图所示。该功能能够方便用户提前进行 Debug,确保优化器参数设置的是合理的。

图 5:优化器动量曲线
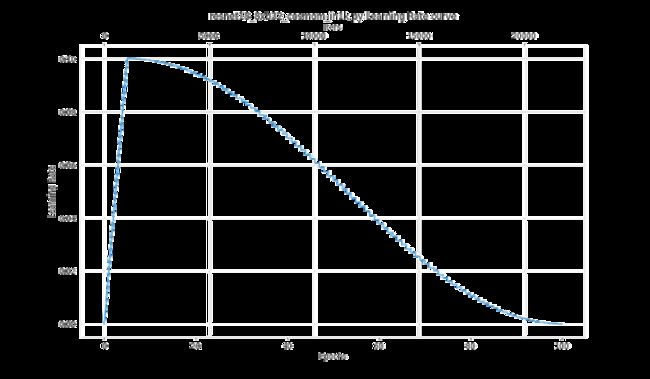
图 6 :学习率曲线
数据预处理模块
为了加速数据预处理过程,在 OpenMMLab 2.0 架构中,模型增加了 data_preprocessor 模块。这一模块在从 dataloader 获得数据后,对数据进行搬运和预处理。
- 和数据集的 transform 有何不同?
-
- 数据集 transform 每次调用只处理一张图片,而数据预处理模块每次调用处理一个 batch 的图片
- 数据集 transform 可以包含复杂逻辑,对每张图像执行不同操作,由 CPU 执行的,而数据预处理模块可以获取模型所在的设备,能够利用 GPU 加速对一个批次的图像进行批量处理。
为何能加速?
数据预处理模块包含归一化、通道转换操作,这些操作在 cpu 上逐张进行效率较低,使用 GPU 批量处理效率更高。实验测试:224 尺寸图像,batch size 128 条件下,每轮预处理迭代耗时从 31 ms 下降到 12ms(1660 Super,i7-8700)。
用法有何不同?
原先数据集 pipeline 中的 Normalize 变换操作可以移除,代之以单独的 data_preprocessor 配置字段。
data_preprocessor = dict(
# 将输入数据通道从 BGR 格式转换为 RGB 格式
to_rgb=True,
# RGB 格式的归一化参数
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
)
易用的推理接口
广大的研究员和工程师同学对基础模型的推理功能有着迫切的需求,我们提供了更易用的推理接口,方便大家能够能轻松地使用算法库的各个模型进行模型推理。
>>> from mmcls.apis import ImageClsInferencer
>>>
>>> inferencer = ImageClsInferencer(model='resnet50_8xb32_in1k')
>>> inferencer('./demo/demo.jpg')
{'pred_label': 65,
'pred_score': 0.6649363040924072,
'pred_class': 'sea snake'}
多后端可视化器
我们在新版本中引入了 ClsVisualizer , 它继承自 MMEngine 的 Visualizer 可视化器,可以用于在训练和测试过程中可视化以及存储需要的数据信息,其主要功能包括:
- 数据样本的可视化和存储;
- 图像的绘制、可视化和存储;
- 特征图的可视化和存储;
- 损失函数(Loss)和分类准确率(Accuracy)等标量数据存储;
我们也提供了多种后端存储支持,如: 本地存储、Tensorboard 后端存储、Wandb 后端存储。
可视化器不仅允许在代码库任意位置调用,还支持在其基础上对存储后端进行扩展。
我们提供如下的示例,展示如何使用 ClsVisualizer。
import torch
import mmcv
from pathlib import Path
from mmcls.visualization import ClsVisualizer
from mmcls.structures import ClsDataSample
# 构造可视化器
vis = ClsVisualizer(
save_dir="./outputs",
vis_backends=[dict(type='TensorboardVisBackend')],
)
vis.dataset_meta = {'classes': ['cat', 'bird', 'dog']}
# 可视化一个分类样本
img = mmcv.imread("./demo/bird.JPEG", channel_order='rgb')
data_sample = ClsDataSample()
data_sample.set_gt_label(1).set_pred_label(1).set_pred_score(torch.tensor([0.1, 0.8, 0.1]))
vis.add_datasample('res', img, data_sample)
# 可视化一系列标量信息
for i in range(10):
vis.add_scalar('loss', step=i, value=10-i)
我们也与 Wandb 进行了合作,提供了对 Wandb 的支持,这里对 Wandb 进行一个简单的介绍。Wandb 是一个易用的实验管理工具,支持对实验的各个环节进行监控和数据收集,同时也支持多个开源框架与系统环境,其主要特性如下图所示。
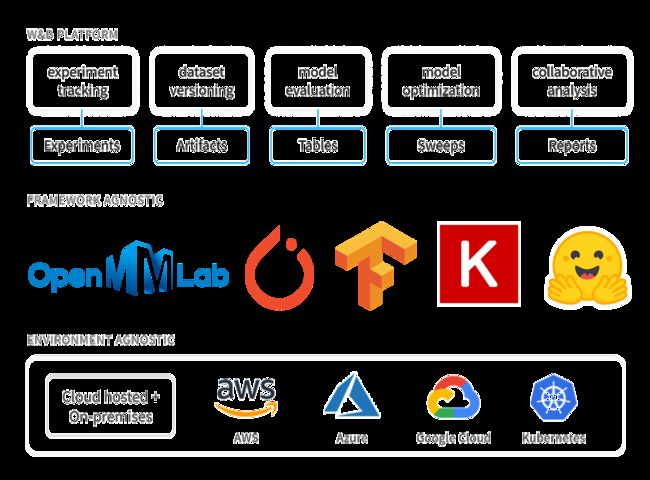
图7:Wandb 的特点
更丰富的算法库
MMClassification 目前涵盖了丰富的模型架构,包括 CNN 骨干网络和 Transformer 骨干网络,覆盖了从标准模型到轻量模型的不同类型算法,如下图所示。截至目前,我们共支持 34 个模型结构,提供 220 个预训练模型权重。

图 8:MMClassification 支持的各类模型
我们也在近期对一些前沿算法进行了支持,如 Swin-V2, MobileOne, EdgeNeXt, EfficientFormer 等,它们的基本结构如下图所示:
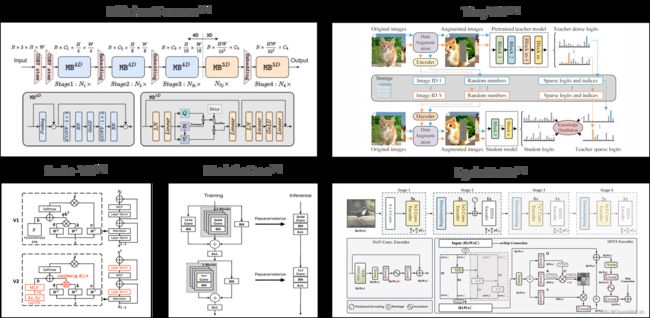
图 9:新支持模型的基本结构
更易用的模型部署
在 MMClassification 1.0 中,我们完善了对于模型部署的支持。用户可以借助 MMDeploy 工具快速获得可部署的的分类模型。我们这里给出一个简单的基于 MMDeploy 的分类模型部署流程。
- 首先下载 MMDeploy 代码
git clone --recursive -b dev-1.x https://github.com/open-mmlab/mmdeploy.git
cd mmdeploy
- 一键安装 MMDeploy 及 onnx 后端(Ubuntu 系统)
python3 tools/scripts/build_ubuntu_x64_ort.py $(nproc)
- 进行分类模型转换
# 下载模型和配置文件
mim download mmcls --config resnet18_8xb32_in1k --dest .
# 进行模型转换
python tools/deploy.py \
configs/mmcls/classification_onnxruntime_dynamic.py \ # 转换分类模型至 ONNX 后端
resnet18_8xb32_in1k.py \ # 指定模型配置文件
resnet18_8xb32_in1k_20210831-fbbb1da6.pth \ # 指定权重文件
tests/data/tiger.jpeg \ # 指定验证图片
--work-dir mmdeploy_models/mmcls/ort \ # 指定输出位置
- 使用 ONNX 后端验证转换后的模型
首先配置 ONNX 后端运行所需的环境变量
export PYTHONPATH=$(pwd)/build/lib:$PYTHONPATH
export LD_LIBRARY_PATH=$(pwd)/../mmdeploy-dep/onnxruntime-linux-x64-1.8.1/lib/:$LD_LIBRARY_PATH
然后使用可部署模型执行推理任务
>>> from mmdeploy_python import Classifier
>>> import cv2
>>>
>>> img = cv2.imread('tests/data/tiger.jpeg')
>>> # 构建 ONNX 分类推理器
>>> classifier = Classifier(model_path='./mmdeploy_models/mmcls/ort', device_name='cpu', device_id=0)
>>> # 执行推理
>>> classifier(img)
[(292, 17.54273223876953)]
小结
我们对 MMClassification 1.0 进行一个简单的总结,作为 OpenMMLab 2.0 的基础模型库,目前我们已经在整个开源社区获得广泛使用。基于全新的架构和生态,我们可以轻松支持多个下游任务,具有可扩展易配置的特性。同时,我们也提供丰富的算法模型,方便的研究工具,以及便捷的模型推理。

图 10:MMClassification 1.0 特点总结
后续规划
未来,我们也将不断地迭代更新,为社区带来更好用的基础模型库。我们计划在未来推出更易用的推理接口,更丰富的模型库,更完善的训练支持,以及更强大的特征分析工具。同时我们也将不断拓展 MMClassification 的能力,支持更多的分类数据集,更广泛的任务(如检索任务,不平衡分布分类,半监督分类,弱监督分类等)。我们也欢迎社区用户来试用新版本的 MMClassification,提出宝贵建议,以及为 MMClassification 贡献代码。