FastDFS合并存储原理
目录
合并存储
为什么要合并存储
合并存储介绍
合并存储前后的fileid介绍
Trunk文件内部结构
合并存储配置
空闲空间概述
为什么产生空余空间
如何管理空余空间
如何使用空闲平衡树
TrunkServer空闲空间分配
TrunkFile同步
空闲平衡树重建
为什么要重建空闲平衡树?
TrunkBinlog压缩
-
合并存储
-
为什么要合并存储
-
在处理【海量小文件(LOSF)】问题上,文件系统处理性能会受到显著的影响,在读写次数(IOPS)与吞吐量(Throughput)这两个指标上会有不少的下降。
通常我们认为大小在【1MB以内】的文件称为小文件,【百万级数量及以上】称为海量,由此量化定义海量小文件问题,以下简称LOSF(全称lots of small files)
海量文件描述参考自:海量小文件问题综述_刘爱贵的博客-CSDN博客
海量小文件存储问题:
- 元数据管理低效

由于小文件数据内容较少,因此元数据的访问性能对小文件访问性能影响巨大。当前主流的磁盘文件系统基本都是面向大文件高聚合带宽设计的,而不是小文件的低延迟访问。磁盘文件系统中,目录项(dentry)、索引节点(inode)和数据(data)保存在存储介质的不同位置上。因此,访问一个文件需要经历至少3次独立的访问。这样,并发的小文件访问就转变成了大量的随机访问,而这种访问对于广泛使用的磁盘来说是非常低效的。同时,文件系统通常采用Hash树、 B+树或B*树来组织和索引目录,这种方法不能在数以亿计的大目录中很好的扩展,海量目录下检索效率会明显下降。正是由于单个目录元数据组织能力的低效,文件系统使用者通常被鼓励把文件分散在多层次的目录中以提高性能。然而,这种方法会进一步加大路径查询的开销
- 数据布局低效
磁盘文件系统使用块来组织磁盘数据,并在inode中使用多级指针或hash树来索引文件数据块。数据块通常比较小,一般为1KB、2KB或4KB。当文件需要存储数据时,文件系统根据预定的策略分配数据块,分配策略会综合考虑数据局部性、存储空间利用效率等因素,通常会优先考虑大文件I/O带宽。对于大文件,数据块会尽量进行连续分配,具有比较好的空间局部性。对于小文件,尤其是大文件和小文件混合存储或者经过大量删除和修改后,数据块分配的随机性会进一步加剧,数据块可能零散分布在磁盘上的不同位置,并且会造成大量的磁盘碎片(包括内部碎片和外部碎片),不仅造成访问性能下降,还导致大量磁盘空间浪费。对于特别小的小文件,比如小于4KB,inode与数据分开存储,这种数据布局也没有充分利用空间局部性,导致随机I/O访问,目前已经有文件系统实现了data in inode。
- IO访问流程复杂
对于小文件的I/O访问过程,读写数据量比较小,这些流程太过复杂,系统调用开销太大,尤其是其中的open()操作占用了大部分的操作时间。当面对海量小文件并发访问,读写之前的准备工作占用了绝大部分系统时间,有效磁盘服务时间非常低,从而导致小I/O性能极度低下。
因此一种【解决海量小文件】的途径就是将小文件【合并存储】成大文件,使用seek来定位到大文件的指定位置来访问该小文件。
-
-
合并存储介绍
-
FastDFS提供了【合并存储】功能,可以将【海量小文件】,合并存储为【大文件】。
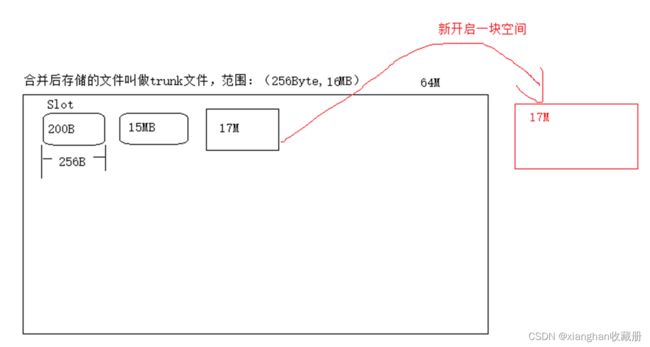
默认创建的大文件为64MB,然后在该大文件中存储很多小文件。大文件中容纳一个小文件的空间称为一个Slot,规定Slot最小值为256字节,
最大为16MB,也就是小于256字节的文件也需要占用256字节,超过16MB的文件不会合并存储而是创建独立的文件。
当没有启动合并存储时fileid和磁盘上实际存储的文件一一对应;当采用合并存储时就不再一一对应,而是多个fileid对应的文件被存储成一个大文件。
注:下面将采用合并存储后的大文件统称为trunk文件,没有合并存储的文件统称为源文件;
请大家注意区分三个概念:
- trunk文件:
storage服务器磁盘上存储的合并后的实际文件,默认大小为64MB。
Trunk文件文件名格式:fdfs_storage1/data/00/00/000001 文件名从1开始递增,类型为int;
- 合并存储文件的fileid:
表示服务器启用合并存储后,每次上传返回给客户端的fileid,注意此时该fileid与磁盘上的文件没有一一对应关系;
- 没有合并存储的fileid:
表示服务器未启用合并存储时,Upload返回的fileid。
-
-
合并存储前后的fileid介绍
-
在启动合并存储时服务返回给客户端的fileid也会有所变化,具体如下:
- 合并存储时fileid:
group1/M00/00/00/CgAEbFQWWbyIPCu1AAAFr1bq36EAAAAAQAAAAAAAAXH82.conf
可以看出合并存储的fileid更长,因为其中需要加入保存的大文件id以及偏移量,具体包括了如下信息:
file_size:占用大文件的空间(注意按照最小slot-256字节进行对齐)
mtime:文件修改时间
crc32:文件内容的crc32码
formatted_ext_name:文件扩展名
alloc_size:文件大小与size相等
id:大文件ID如000001
offset:文件内容在trunk文件中的偏移量
size:文件大小
- 没有合并存储时fileid:
group1/M00/00/00/CmQPRlP0T4-AA9_ECDsoXi21HR0.tar.gz
CmQPRlP0T4-AA9_ECDsoXi21HR0.tar.gz,这个文件名中,除了.tar.gz 为文件后缀,CmQPRlP0T4-AA9_ECDsoXi21HR0 这部分是一个base64编码缓冲区,组成如下:
storage_id:ip的数值型
timestamp:文件创建时间戳
file_size:若原始值为32位则前面加入一个随机值填充,最终为64位
crc32:文件内容的检验码
-
-
Trunk文件内部结构
-
trunk内部是由多个小文件组成,每个小文件都会有一个trunkHeader(占用24个字节),以及紧跟在其后的真实数据,结构如下:
|||——————————————————— 24bytes———-----———-—————————|||
|—1byte —|— 4bytes —|—4bytes —|—4bytes—|—4bytes—|— 7bytes —|
|—filetype—|—alloc_size—|—filesize—|—crc32—|—mtime—|—formatted_ext_name—|
|||——————file_data filesize bytes————————————————— —————|||
|———————file_data———————————————————————— ————|
-
-
合并存储配置
-
FastDFS提供了合并存储功能的实现,所有的配置都在tracker.conf文件之中,具体摘录如下:
注意:开启合并存储只需要设置use_trunk_file = true和store_server=1
# which storage server to upload file
# 0: round robin (default)
# 1: the first server order by ip address
# 2: the first server order by priority (the minimal)
# Note: if use_trunk_file set to true, must set store_server to 1 or 2
store_server = 0
#是否启用trunk存储
use_trunk_file = false
#trunk文件最小分配单元
slot_min_size = 256
#trunk内部存储的最大文件,超过该值会被独立存储
slot_max_size = 16MB
#trunk文件大小
trunk_file_size = 64MB
#是否预先创建trunk文件
trunk_create_file_advance = false
#预先创建trunk文件的基准时间
trunk_create_file_time_base = 02:00
#预先创建trunk文件的时间间隔
trunk_create_file_interval = 86400
#trunk创建文件的最大空闲空间
trunk_create_file_space_threshold = 20G
#启动时是否检查每个空闲空间列表项已经被使用
trunk_init_check_occupying = false
#是否纯粹从trunk-binlog重建空闲空间列表
trunk_init_reload_from_binlog = false
#对trunk-binlog进行压缩的时间间隔
trunk_compress_binlog_min_interval = 0
-
-
空闲空间概述
-
为什么产生空余空间
-
-
Trunk文件为64MB(默认),因此每次创建一次Trunk文件总是会产生空余空间,比如为了存储一个10MB文件,
创建一个Trunk文件,那么就会剩下接近54MB的空间(TrunkHeader 会24字节,后面为了方便叙述暂时忽略其所占空间),
下次要想再次存储10MB文件时就不需要创建新的文件,存储在已经创建的Trunk文件中即可。
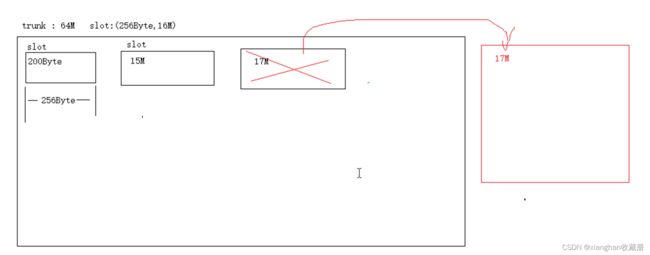
另外当删除一个存储的文件时,也会产生空余空间
-
-
-
如何管理空余空间
-
-
在Storage内部会为每个store_path构造一颗以空闲块大小作为关键字的空闲平衡树,相同大小的空闲块保存在链表之中。
-
-
-
如何使用空闲平衡树
-
-
每当需要存储一个文件时会首先到空闲平衡树中查找大于并且最接近的空闲块,然后试着从该空闲块中分割出多余的部分作为一个新的空闲块,
加入到空闲平衡树中。
例如:
要求存储文件为300KB,通过空闲平衡树找到一个350KB的空闲块,那么就会将350KB的空闲块分裂成两块,
前面300KB返回用于存储,后面50KB则继续放置到空闲平衡树之中。
假若此时找不到可满足的空闲块,那么就会创建一个新的trunk文件64MB,
将其加入到空闲平衡树之中,再次执行上面的查找操作(此时总是能够满足了)

-
-
TrunkServer空闲空间分配
-
假若所有的Storage都具有分配空闲空间的能力(upload文件时自主决定存储到哪个TrunkFile之中),
那么可能会由于同步延迟导致数据冲突。
例如:
Storage-A中上传了一个文件A.txt 100KB,将其保存到000001这个TrunkFile的开头,
与此同时,Storage-B也上传了一个文件B.txt 200KB,也将其保存在000001这个TrunkFile文件的开头,
当Storage-B收到Storage-A的同步信息时,他无法将A.txt 保存在000001这个trunk文件的开头,因此这个位置已经被B.txt占用。

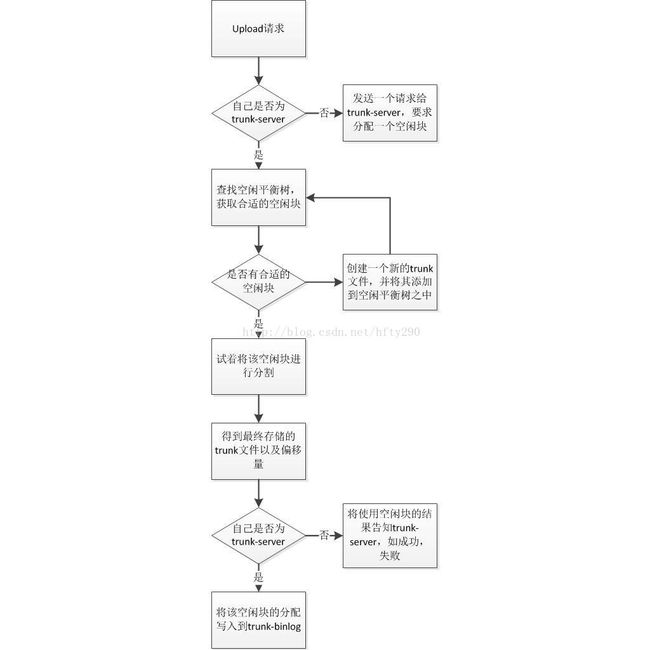
为了处理这种冲突,引入了TrunkServer概念,只有TrunkServer才有权限分配空闲空间,决定文件应该保存到哪个TrunkFile的什么位置。
TrunkServer由Tracker指定,并且在心跳信息中通知所有的Storage(此处也会存在问题,可以思考一下)。
引入TrunkServer之后,一次Upload请求,Storage的处理流程图如下:
-
-
-
TrunkFile同步
-
-
开启了合并存储服务后,除了原本的源文件(trunk文件和未合并文件)同步之外,TrunkServer还多了TrunkBinlog的同步(非TrunkServer没有TrunkBinlog同步)。源文件的同步与没有开启合并存储时过程完全一样,都是从binlog触发同步文件
TrunkBinlog记录了TrunkServer所有分配与回收空闲块的操作,由TrunkServer同步给同组中的其他Storage。TrunkServer为同组中的其他Storage各创建一个同步线程,【每秒】将TrunkBinlog的变化同步出去。同组的Storage接收到TrunkBinlog【只是保存到文件中,不做其他任何操作】
TrunkBinlog文件文件记录如下:
1410750754 A 0 0 0 1 0 67108864
1410750754 D 0 0 0 1 0 67108864
各字段含义如下(按照顺序):
时间戳
操作类型(A:增加,D:删除)
store_path_index
sub_path_high
sub_path_low
fileid(TrunkFile文件名,比如000001)
offset(在TrunkFile文件中的偏移量)
size(占用的大小,按照slot对齐)
-
-
空闲平衡树重建
-
当作为TrunkServer的Storage启动时可以从TrunkBinlog文件中中加载所有的空闲块分配与加入操作,这个过程就可以实现空闲平衡树的重建。
-
-
-
为什么要重建空闲平衡树?
-
-
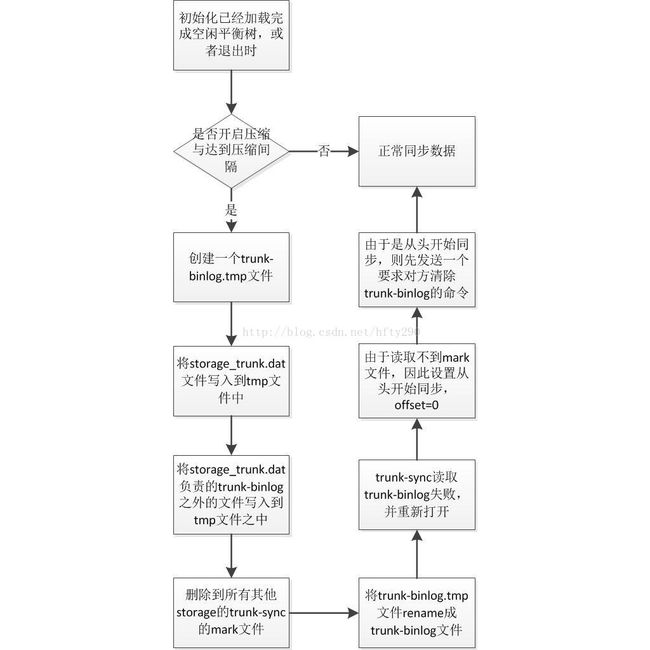
当长期运行时,随着空闲块的不断删除添加会导致TrunkBinlog文件很大,那么加载时间会很长,FastDFS为了解决这个问题,引入了检查点文件storage_trunk.dat,每次TrunkServer进程退出时,会将当前内存里的空闲平衡树导出为storage_trunk.dat文件,该文件的第一行为TrunkBinlog的offset,也就是该检查点文件负责到这个offset为止的TrunkBinlog。也就是说下次TrunkServer启动的时候,先加载storage_trunk.dat文件,然后继续加载这个offset之后的TrunkBinlog文件内容。
下面为TrunkServer初始化的流程图:
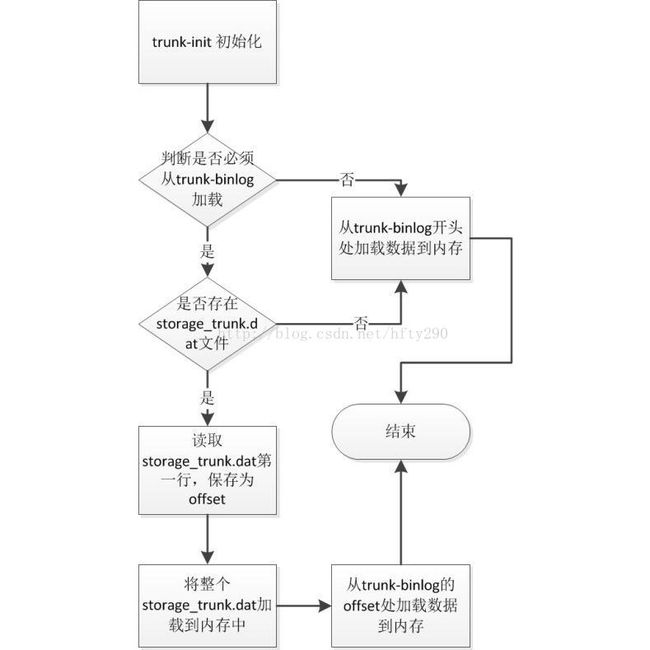
-
-
-
TrunkBinlog压缩
-
-
上文提到的storage_trunk.dat既是检查点文件,其实也是一个压缩文件,因为从内存中将整个空闲平衡树直接导出,没有了中间步骤
(创建、删除、分割等步骤),因此文件就很小。这种方式虽然实现了TrunkServer自身重启时快速加载空闲平衡树的目的,但是并没有实际上缩小TrunkBinlog文件的大小。
假如这台TrunkServer宕机后,Tracker会选择另外一台机器作为新的TrunkServer,这台新的TrunkServer就必须从很庞大的
TrunkBinlog中加载空闲平衡树,由于TrunkBinlog文件很大,这将是一个很漫长的过程
为了减少TrunkBinlog,可以选择压缩文件,在TrunkServer初始化完成后,或者退出时,可以将storage_trunk.dat与其负责偏移量之后的TrunkBinlog进行合并,产生一个新的TrunkBinlog。由于此时的TrunkBinlog已经从头到尾整个修改了,就需要将该文件完成的同步给同组内的其他Storage,为了达到该目的,FastDFS使用了如下方法:
1)TrunkServer将TrunkBinlog同步给组内其他Storage时会将同步的最后状态记录到一个mark文件之中,比如同步给A,则记录到A.mark文件(其中包括最后同步成功的TrunkBinlog偏移量)。
2)TrunkServer在将storage_trunk.dat与TrunkBinlog合并之后,就将本地记录TrunkBinlog最后同步状态的所有mark文件删除,如,一组有A、B、C,其中A为TrunkServer则A此时删除B.mark、C.mark。
3)当下次TrunkServer要同步TrunkBinlog到B、C时,发现找不到B.mark、C.mark文件,就会自动转换成从头开始同步文件。
4)当TrunkServer判断需要从头开始同步TrunkBinlog,由于担心B、C已经有旧的文件,因此就需要向B、C发送一个删除旧的TrunkBinlog的命令。
5)发送删除命令成功之后,就可以从头开始将TrunkBinlog同步给B、C了。
大家发现了么,这里的删除TrunkBinlog文件,会有一个时间窗口,就是删除B、C的TrunkBinlog文件之后,与将TrunkBinlog同步给他们之前,假如TrunkBinlog宕机了,那么组内的B、C都会没有TrunkBinlog可使用。
流程图如下: