【论文导读】- GraphFL: A Federated Learning Framework for Semi-Supervised Node Classification on Graphs
文章目录
- 论文信息
- 摘要
- 主要工作
- Model-agnostic meta learning (MAML)
- GraphFL Framework
-
- 1. GraphFL用于联合GraphSSC和非IID图数据
- 2. GraphFed用于联合GraphSSC和新标签
- 3. 通过自训练来利用未标记节点
论文信息

原文地址:https://arxiv.org/abs/2012.04187
摘要
Graph-based semi-supervised node classification (GraphSSC) has wide applications, ranging from networking and security to data mining and machine learning, etc. However, existing centralized GraphSSC methods are impractical to solve many real-world graph-based problems, as collecting the entire graph and labeling a reasonable number of labels is time-consuming and costly, and data privacy may be also violated. Federated learning (FL) is an emerging learning paradigm that enables collaborative learning among multiple clients, which can mitigate the issue of label scarcity and protect data privacy as well. Therefore, performing GraphSSC under the FL setting is a promising solution to solve real-world graph-based problems. However, existing FL methods 1) perform poorly when data across clients are non-IID, 2) cannot handle data with new label domains, and 3) cannot leverage unlabeled data, while all these issues naturally happen in real-world graph-based problems. To address the above issues, we propose the first FL framework, namely GraphFL, for semi-supervised node classification on graphs. Our framework is motivated by meta-learning methods. Specifically, we propose two GraphFL methods to respectively address the non-IID issue in graph data and handle the tasks with new label domains. Furthermore, we design a self-training method to leverage unlabeled graph data. We adopt representative graph neural networks as GraphSSC methods and evaluate GraphFL on multiple graph datasets. Experimental results demonstrate that GraphFL significantly outperforms the compared FL baseline and GraphFL with self-training can obtain better performance.
基于图的半监督节点分类(GraphSSC)具有广泛的应用,从网络和安全到数据挖掘和机器学习等。然而,现有的集中式GraphSSB方法无法解决许多现实世界中基于图的问题,因为收集整个图并标记合理数量的标签既耗时又昂贵,数据隐私也可能受到侵犯。**联邦学习(FL)**是一种新兴的学习模式,可实现多个客户之间的协作学习,可以缓解标签稀缺的问题,并保护数据隐私。因此,在FL设置下执行GraphSSC是解决现实世界基于图形的问题的一个很有前景的解决方案。然而,现有的FL方法:
1)当跨客户端的数据为非IID数据时性能不佳,
2)无法处理具有新标签域的数据,
3)无法利用未标记的数据,
而所有这些问题都会在基于图形的现实问题中自然发生。
为了解决上述问题,我们提出了第一个FL框架,即GraphFL,用于图上的半监督节点分类。我们的框架是由元学习方法驱动的。具体来说,我们提出了两种GraphFL方法,分别解决图形数据中的非IID问题,并使用新的标记域处理任务。此外,我们还设计了一种利用未标记图形数据的自训练方法。我们采用具有代表性的图形神经网络作为GraphSSC方法,并在多个图形数据集上评估GraphFL。实验结果表明,GraphFL显著优于比较的FL基线,并且GraphFL通过自我训练可以获得更好的性能。
主要工作
- 设计了一个新的FL框架,即GraphFL,来执行基于图的半监督节点分类并解决上述挑战。
- 采用两种具有代表性的图神经网络,即图卷积网络( Graph Convolutional Network,GCN ) 和简单图卷积( Simple Graph Convolution,SGC ) 作为Graph SSC方法,并将Graph FL融入到GCN和SGC中进行联合半监督节点分类。
- GraphFL解决了图数据中的非IID问题;处理具有新标签域的测试节点;并通过自训练利用未标记节点。
- 在多个图数据集上为联邦GraphSSC评估GraphFL;并展示了Graph FL相对于FL基线的优越性。
Model-agnostic meta learning (MAML)
基于基本任务分布T,抽取的一组训练任务{ Ti },相比学习一个在所有任务上都表现良好的模型,MAML更倾向于在经过几步梯度更新后学习一个在所有任务上都表现良好的与任务无关的初始化θ。
具体来说,每个任务Ti 将其标记的训练集L(i)分割成一个支持集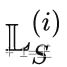
和一个不相交的查询集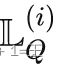 。
。
在内部优化中,对于每个任务Ti ,MAML通过初始化θ在支持集上训练一个模型![]() ,并输出一个任务特定的模型参数
,并输出一个任务特定的模型参数![]() 。然后,MAML将每个
。然后,MAML将每个![]() 作为初始化,并在相应的查询集上评估模型
作为初始化,并在相应的查询集上评估模型![]() 的任务损失。在元优化中,MAML同时最小化所有任务的查询集上的总损失,以学习与任务无关的初始化。
的任务损失。在元优化中,MAML同时最小化所有任务的查询集上的总损失,以学习与任务无关的初始化。
形式上,MAML的目标函数如下:
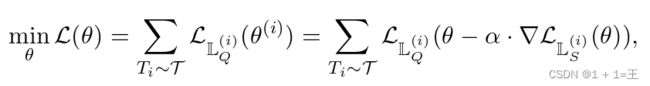
在支持集和查询集上的特定于任务的损失分别为:
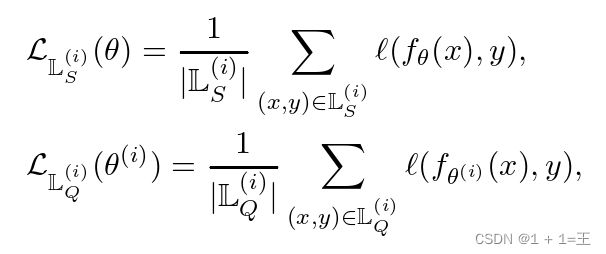
GraphFL Framework
提出了一种新颖的用于图上半监督节点分类的FL框架(GraphFL),旨在实现上述目标。
GraphFL主要是将MAML融入到FL中。首先,开发了两个GraphFL方法,旨在解决图数据中的非IID问题,并分别使用新的标签域处理测试节点。然后,我们设计了一种自训练方法来利用客户端图中的未标记节点。
1. GraphFL用于联合GraphSSC和非IID图数据

GraphFL由两个阶段组成:
阶段I: 通过遵循MAML的训练方案在服务器上学习一个全局模型,从而可以减轻非IID图形数据引起的问题。
阶段II: 利用已有的FL方法进一步更新全局模型,使其具有良好的泛化能力。
对于每个客户端C(i)将训练集L(i)分割成一个支持集和一个查询集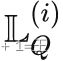
假设在第t轮,服务器端S拥有全局模型![]() 服务器端C(i)持有本地模型
服务器端C(i)持有本地模型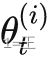 。定义在C(i)的支持集和查询集上的损失分别为:
。定义在C(i)的支持集和查询集上的损失分别为:
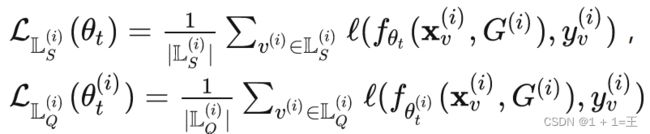 其中
其中 分别为支持集和查询集学习得到的模型权重。
分别为支持集和查询集学习得到的模型权重。
在第t轮,服务器端可以通过以下步骤学习全局模型权重![]() :
:
- 服务器随机发送全局模型权重
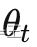 给以概率ρ采样的客户端C(i);
给以概率ρ采样的客户端C(i); - 每一个参与的客户端,首先通过最小化支持集的损失 ,基于梯度下降法学习本地模型权重。基于此,每个本地客户端在查询集上验证本地模型参数,得到损失的梯度 ,并将梯度发送回服务器。
- 服务器端通过收集本地客户端上传的梯度更新全局模型参数,之后进一步更新全局模型,使其在所有客户端上都能达到良好的泛化能力。
- 每一个参与的客户端下载全局模型权重通过梯度下降对支持节点的局部模型进行更新。
- 服务器端采用现有的 FL 方法,最终的全局模型用来预测全新标签域的测试节点 。
2. GraphFed用于联合GraphSSC和新标签

为Graph SSC设计了一种新颖的Graph FL方法,可以推广到具有新标签域的测试节点。
具体来说,提出在FL框架中重新定义MAML,并在服务器上为所有客户机学习一个共享的全局模型,这样每个客户机在经过几个步骤的梯度更新后都能很好地完成特定GraphSSC方法定义的损失。
形式上,定义目标函数如下:
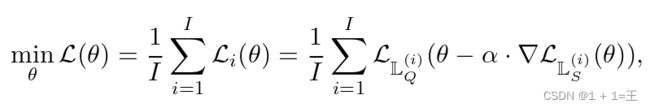 其中
其中![]() 代表我们希望学习到的共享权重。
代表我们希望学习到的共享权重。
总体过程为:首先根据指定的客户端损失来更新本地模型,然后通过汇总本地模型来更新全局模型。
3. 通过自训练来利用未标记节点
提出了一种自训练方法来利用客户端图中的未标记节点。
具体来说,给定一个基于图的半监督节点分类方法,
首先使用该方法在每个客户机中使用客户机的少量标记节点训练一个本地模型。
接下来,在每个客户机中,我们使用其本地模型来预测未标记节点,并选择一组预测最可信的未标记节点。
然后,我们将所选节点的预测标签作为其伪标签,并将每个客户端的所选节点(以及它们的伪标签)添加到客户端的训练集中。
最后,在联邦半监督节点分类的增广训练集上训练本文的Graph FL方法。