Apache Hudi 从入门到放弃(3) —— Flink Sql写过程分析(上)
背景介绍
上一期给大家讲述了Hudi中,MOR表的目录文件结构;本打算这一期讲一下COW表的目录文件,不过考虑到目前在实时读写入Hudi的场景下,用的最多的还是MOR表,所以暂时跳过COW表的文件分析,转而对hudi-flink模块进行深入理解;本次分析也仅涉及hudi-flink中的内容
另外,目前COW表已经支持Flink Streaming Read,有兴趣的可以试试看,我也会在之后的分享中从简单使用&原理分析来讲一讲COW表
欢迎大家指出我文章的不足,让我更进一步
源码分析
开始之前
Hudi从Release 0.7版本开始完成了写入层的解耦,添加了Flink客户端,可以使用HoodieFlinkStreamer来消费Kafka中的数据,以写入Hudi的COW表中。
在0.8版本,也就是最新Release版本,Hudi社区又进一步完善了Flink和Hudi的集成:
- 重新设计性能更好、扩展性更好、基于Flink状态索引的写入Pipeline
- Flink流式读写MOR表
- Flink批量读取COW和MOR表
我们从单独来看写的方面,这是0.7版本写入的Pipeline
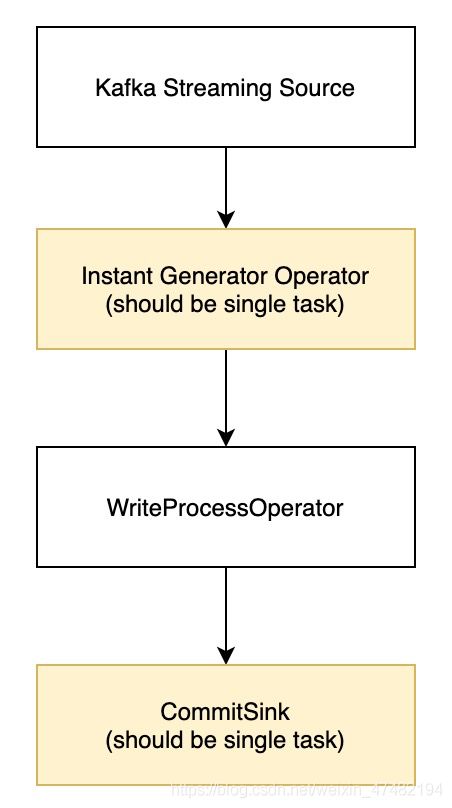
虽然说这个版本实现了对Hudi表的写入,但是存在一些性能瓶颈:
- InstantGeneratorOperator作为分配生成Instant的算子,全局只能有一个,也就是并行度必须为1;那么,所有上游算子的数据都会通过网络传输到该算子,将会带来大量的网络IO
- WriteProcessOperator算子根据分区处理输入数据,在单个分区处理每个Bucket的写入,磁盘IO也会有很大压力
- 通过Checkpoint缓存数据,但checkpoint应该比较轻量级并且不应该有一些IO操作
- FlinkHoodieIndex对per-job模式有效,不适用于Bootstrap数据或其他Flink作业
以上内容来自RFC-24更多细节可以参考该网站
该RFC由阿里Blink团队玉兆提出,以解决0.7版本中的一些瓶颈,代码在0.8版本正式放出
来看一下最新版本的流程图
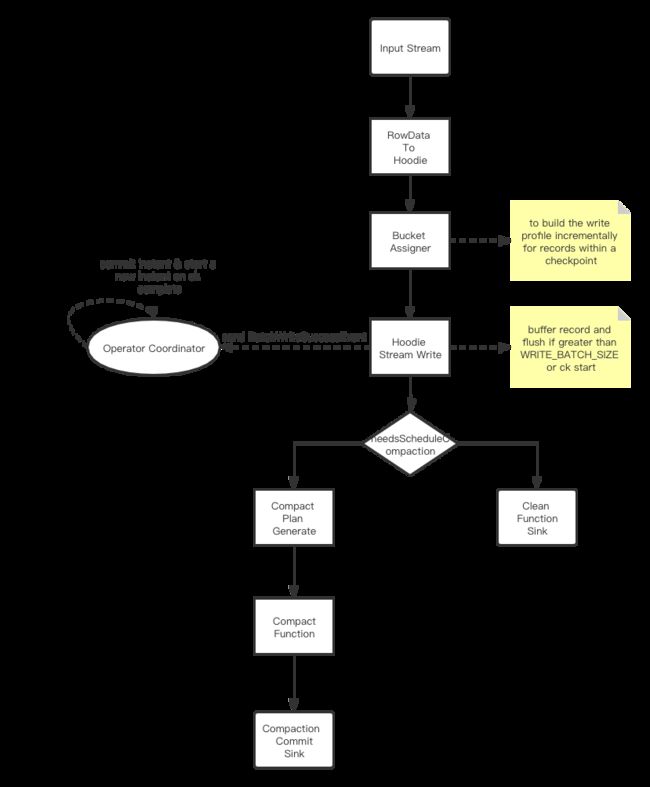
流程图是我根据HoodieTableSink.getSinkRuntimeProvider()画的
可以看出,为了解决上面提出的4个性能瓶颈,玉兆重构了整个Sink端的设计
接下来,让我们按照流程图,将每个算子的功能都给大家讲述一遍
友情提醒,我们在看源码的时候,可以利用单元测试进行Debug,这样既无需我们写代码,又能方便快捷的定位到指定断点处
RowDataToHoodieFunction
首先我们看看在算子被加载的时候,做了哪些事情;太细节的地方就不说了,大家自己看吧
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 根据parameters中参数,得到输入源对应的Avro Schema
this.avroSchema = StreamerUtil.getSourceSchema(this.config);
// 创建将Flink中Rowdata转换为Hudi中的GenericRecord 的converter
this.converter = RowDataToAvroConverters.createConverter(this.rowType);
// 根据指定的主键生成器类型获取主键生成器
this.keyGenerator = StreamerUtil.createKeyGenerator(FlinkOptions.flatOptions(this.config));
// 帮我们创建hoodie pay load 的工具,至于什么是playload,我们接下来会讲到
this.payloadCreation = PayloadCreation.instance(config);
// 创建限速器,当task消费速率超过阈值时,将会slee
long totalLimit = this.config.getLong(FlinkOptions.WRITE_RATE_LIMIT);
if (totalLimit > 0) {
this.rateLimiter = new RateLimiter(totalLimit / getRuntimeContext().getNumberOfParallelSubtasks());
}
}
在初始化完成之后,每来一条数据都会调用map()方法
@Override
public O map(I i) throws Exception {
if (rateLimiter != null) {
final O hoodieRecord;
if (rateLimiter.sampling()) {
long startTime = System.currentTimeMillis();
hoodieRecord = (O) toHoodieRecord(i);
long endTime = System.currentTimeMillis();
rateLimiter.processTime(endTime - startTime);
} else {
hoodieRecord = (O) toHoodieRecord(i);
}
rateLimiter.sleepIfNeeded();
return hoodieRecord;
} else {
return (O) toHoodieRecord(i);
}
}
限速器部分就不看了,不在我们主流程之类,我们来看一下toHoodieRecord()方法中的细节
private HoodieRecord toHoodieRecord(I record) throws Exception {
// 通过转换器将Rowdata转换为Hudi中的GenericRecord
GenericRecord gr = (GenericRecord) this.converter.convert(this.avroSchema, record);
// 获取hoodieKey,也就是表中主键+分区字段
final HoodieKey hoodieKey = keyGenerator.getKey(gr);
// 标记是否是删除数据
final boolean isDelete = record.getRowKind() == RowKind.DELETE;
// 创建payload
HoodieRecordPayload payload = payloadCreation.createPayload(gr, isDelete);
// 通过hoodieKey和payload组装成HoodieRecord
return new HoodieRecord<>(hoodieKey, payload);
}
看一下createPayload()方法,看看payload到底是个什么
public HoodieRecordPayload<?> createPayload(GenericRecord record, boolean isDelete) throws Exception {
if (shouldCombine) {
ValidationUtils.checkState(preCombineField != null);
Comparable<?> orderingVal = (Comparable<?>) HoodieAvroUtils.getNestedFieldVal(record,
preCombineField, false);
return (HoodieRecordPayload<?>) constructor.newInstance(
isDelete ? null : record, orderingVal);
} else {
return (HoodieRecordPayload<?>) this.constructor.newInstance(Option.of(record));
}
}
如果建表参数指定write.insert.drop.duplicates为True或write.operation为UPSERT则shouldCombine为True
在Hudi中,是按批写入数据,每批数据中,同一个Key可能存在多条记录,此时我们需要通过重读调用payload中的preCombine()方法,相同Key的所有数据合并成一条数据,会通过根据每条数据生成的orderingVal进行排序,默认取最大值的。当然这是针对于write.insert.drop.duplicates为True或write.operation为UPSERT的情况
对于INSERT或BULK_INSERT操作类型涞水,不会执行preCombine()。因此,当输入数据存在重复数据,则表中也会出现重复数据
回到代码中,所以很明显HoodieRecordPayload就是帮我们去执行preCombine()的类,另外HoodieRecordPayload还存放着Avro格式数据的Byte[]
HoodieRecordPayload与hoodieKey一起构成了RowDataToHoodieFunction发给下游的HoodieRecord
下游会通过keyBy算子进行一次Shuffle,避免同一个Key的数据在同一时刻被不同的线程写入同一个文件中
接下来,通过BucketAssignFunction去给每条数据分配对应的Bucket
BucketAssignFunction
老规矩,先看open()方法里面做了什么
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 用我们设置的Flink参数构建Hudi Write 参数
HoodieWriteConfig writeConfig = StreamerUtil.getHoodieClientConfig(this.conf);
// 获取Hadoop配置
this.hadoopConf = StreamerUtil.getHadoopConf();
// 将Hadoop配置和Flink RuntimeContext包装到一个对象中
this.context = new HoodieFlinkEngineContext(
new SerializableConfiguration(this.hadoopConf),
new FlinkTaskContextSupplier(getRuntimeContext()));
// 创建Bucket分配器
this.bucketAssigner = BucketAssigners.create(
getRuntimeContext().getIndexOfThisSubtask(),
getRuntimeContext().getNumberOfParallelSubtasks(),
WriteOperationType.isOverwrite(WriteOperationType.fromValue(conf.getString(FlinkOptions.OPERATION))),
HoodieTableType.valueOf(conf.getString(FlinkOptions.TABLE_TYPE)),
context,
writeConfig);
}
这里最关键的就是创建这个BucketAssigners.create(),我们来看看它的逻辑
public static BucketAssigner create(
int taskID,
int numTasks,
boolean isOverwrite,
HoodieTableType tableType,
HoodieFlinkEngineContext context,
HoodieWriteConfig config) {
if (isOverwrite) {
return new OverwriteBucketAssigner(taskID, numTasks, context, config);
}
switch (tableType) {
case COPY_ON_WRITE:
return new BucketAssigner(taskID, numTasks, context, config);
case MERGE_ON_READ:
return new DeltaBucketAssigner(taskID, numTasks, context, config);
default:
throw new AssertionError();
}
}
这里比较简单,因为我们是MOR表,所以给我们创建了DeltaBucketAssigner类得对象,我们进去看看这个类的作用
/**
* BucketAssigner for MERGE_ON_READ table type, this allows auto correction of small parquet files to larger ones
* without the need for an index in the logFile.
*
* Note: assumes the index can always index log files for Flink write.
*/
// 以上大意为,用于MOR表的BucketAssigner,允许自动将小的Parquet文件合并为大的parquet文件,并且不需要在Log File中建立Index;
public class DeltaBucketAssigner extends BucketAssigner {
}
再看一下父类的作用
/**
* Bucket assigner that assigns the data buffer of one checkpoint into buckets.
*
* This assigner assigns the record one by one.
* If the record is an update, checks and reuse existing UPDATE bucket or generates a new one;
* If the record is an insert, checks the record partition for small files first, try to find a small file
* that has space to append new records and reuse the small file's data bucket, if
* there is no small file(or no left space for new records), generates an INSERT bucket.
*
*
Use {partition}_{fileId} as the bucket identifier, so that the bucket is unique
* within and among partitions.
*/
public class BucketAssigner {
}
Bucket分配器,用于将一个Checkpoint期间的缓存的数据分配到对应的桶中
Bucket分配器会将数据一条一条的分配
- 如果是Update数据,则检查对应的桶是否已经存在
- 如果是Insert数据,先检查数据对应的分区中,是否有小文件
- 如果小文件还有添加数据的空间,写到小文件对应的桶中
- 如果没有小文件或剩余空间不够,则生产一个Insert桶
使用{分区}_{文件Id}作为桶的Id,保证桶在一个分区里面是唯一的
介绍完了两个桶分配器,我们回到BucketAssignFunction类中
因为实现了接口CheckpointedFunction,所以接下来需要初始化状态
@Override
public void initializeState(FunctionInitializationContext context) {
MapStateDescriptor<HoodieKey, HoodieRecordLocation> indexStateDesc =
new MapStateDescriptor<>(
"indexState",
TypeInformation.of(HoodieKey.class),
TypeInformation.of(HoodieRecordLocation.class));
double ttl = conf.getDouble(FlinkOptions.INDEX_STATE_TTL) * 24 * 60 * 60 * 1000;
if (ttl > 0) {
indexStateDesc.enableTimeToLive(StateTtlConfigUtil.createTtlConfig((long) ttl));
}
indexState = context.getKeyedStateStore().getMapState(indexStateDesc);
if (bootstrapIndex) {
MapStateDescriptor<String, Integer> partitionLoadStateDesc =
new MapStateDescriptor<>("partitionLoadState", Types.STRING, Types.INT);
partitionLoadState = context.getKeyedStateStore().getMapState(partitionLoadStateDesc);
}
}
主要是两个状态的初始化
indexState- 将每条数据的Key记录在状态中,当有新数据进入时,会判断状态中是否包含本条数据的Key
- 如果有,则取出状态中该Key对应的位置信息
- 如果没有,则生成新的位置信息并存到状态中
- 如果
index.bootstrap.enabled配置为True,则会将表中的BloomFilter加载到状态中
- 将每条数据的Key记录在状态中,当有新数据进入时,会判断状态中是否包含本条数据的Key
partitionLoadState- 如果
index.bootstrap.enabled配置为True才会初始化该状态,用于标记每个分区的BloomFilter是否已被加载到状态中
- 如果
看完了前置工作,我们接着来看BucketAssignFunction是怎么处理每条进入的数据的
假设我们插入了以下的数据到Hudi表中,我们来看一下具体的过程是怎么样的
{"uuid": "id1", "name": "Danny", "age": 23, "ts": "1970-01-01T00:00:01", "partition": "par1"}
{"uuid": "id2", "name": "Stephen", "age": 33, "ts": "1970-01-01T00:00:02", "partition": "par1"}
{"uuid": "id3", "name": "Julian", "age": 53, "ts": "1970-01-01T00:00:03", "partition": "par2"}
{"uuid": "id4", "name": "Fabian", "age": 31, "ts": "1970-01-01T00:00:04", "partition": "par2"}
{"uuid": "id5", "name": "Sophia", "age": 18, "ts": "1970-01-01T00:00:05", "partition": "par3"}
{"uuid": "id6", "name": "Emma", "age": 20, "ts": "1970-01-01T00:00:06", "partition": "par3"}
{"uuid": "id7", "name": "Bob", "age": 44, "ts": "1970-01-01T00:00:07", "partition": "par4"}
{"uuid": "id8", "name": "Han", "age": 56, "ts": "1970-01-01T00:00:08", "partition": "par4"}
@Override
public void processElement(I value, Context ctx, Collector<O> out) throws Exception {
HoodieRecord<?> record = (HoodieRecord<?>) value;
final HoodieKey hoodieKey = record.getKey();
final BucketInfo bucketInfo;
final HoodieRecordLocation location;
if (bootstrapIndex && !partitionLoadState.contains(hoodieKey.getPartitionPath())) {
loadRecords(hoodieKey.getPartitionPath());
}
if (isChangingRecords && this.indexState.contains(hoodieKey)) {
location = new HoodieRecordLocation("U", this.indexState.get(hoodieKey).getFileId());
this.bucketAssigner.addUpdate(record.getPartitionPath(), location.getFileId());
} else {
bucketInfo = this.bucketAssigner.addInsert(hoodieKey.getPartitionPath());
switch (bucketInfo.getBucketType()) {
case INSERT:
location = new HoodieRecordLocation("I", bucketInfo.getFileIdPrefix());
break;
case UPDATE:
location = new HoodieRecordLocation("U", bucketInfo.getFileIdPrefix());
break;
default:
throw new AssertionError();
}
if (isChangingRecords) {
this.indexState.put(hoodieKey, location);
}
}
record.unseal();
record.setCurrentLocation(location);
record.seal();
out.collect((O) record);
}
首先,会校验是否允许从文件中加载BloomFilter,如果允许则取加载;这部分内容我们稍后再说,我们接着往下看
因为write.operation配置的为Upsert,所以isChangingRecords为True,但此时indexState刚刚初始化完毕,且我们刚进入第一条数据,所以我们来到else的逻辑中;
我们进入this.bucketAssigner.addInsert(hoodieKey.getPartitionPath());中,看看做了什么事情
上面我们有说过:如果是Insert数据,先检查数据对应的分区中,是否有小文件
所以进入该方法之后,第一行代码就是List很明显,就是在寻找这条数据对应的分区中,是否存在小文件;我们继续深入这个方法
if (partitionSmallFilesMap.containsKey(partitionPath)) {
return partitionSmallFilesMap.get(partitionPath);
}
partitionSmallFilesMap是在当前分桶器被创建的时候初始化的,是一个HashMap,用于存放对应分区中的小文件;很明显,当前肯定不存在,我们继续往下走
List
重点还是在getSmallFiles()中,我们继续深入,这里要注意,因为我们一开始创建的是DeltaBucketAssigner,所以不要进错了方法
进去之后,先是获取当前表的已提交的Instant;此时因为表是我们第一次写入,所以根本没有已经提交的Instant,所以直接返回;也就是说,我们目前根本不存在小文件,所以我们一路回退至BucketAssigner.addInsert()中
if (newFileAssignStates.containsKey(partitionPath)) {
NewFileAssignState newFileAssignState = newFileAssignStates.get(partitionPath);
if (newFileAssignState.canAssign()) {
newFileAssignState.assign();
}
final String key = StreamerUtil.generateBucketKey(partitionPath, newFileAssignState.fileId);
return bucketInfoMap.get(key);
}
这段逻辑主要是这样:如果newFileAssignStates中包含当前分区,则取出对应的newFileAssignState,如果它还有写数据的空间就分配一下空间,无论有无空间,都会根据分区和它的FileId获取到对应的BucketInfo也就是当前数据对应的分桶信息;
不过这里我不能理解的是,这个分配空间的作用是什么?后续也没有用到这个东西
因为我们当前还是第一条数据,所以newFileAssignStates肯定是不包含当前分区的,所以我们接着来看
BucketInfo bucketInfo = new BucketInfo(BucketType.INSERT, FSUtils.createNewFileIdPfx(), partitionPath);
final String key = StreamerUtil.generateBucketKey(partitionPath, bucketInfo.getFileIdPrefix());
bucketInfoMap.put(key, bucketInfo);
newFileAssignStates.put(partitionPath, new NewFileAssignState(bucketInfo.getFileIdPrefix(), insertRecordsPerBucket));
return bucketInfo;
因为没有小文件,并且当前数据对应的Key也没有被分配过桶,所以新建一个BucketInfo对象,指定桶类型为Insert、桶的FileId为随机数、以及分区值
并将对应的NewFileAssignState和BucketInfo分别放入Map中
做完这些之后,回到BucketAssignFunction中,接下来再根据BucketInfo类型,分配不同的HoodieRecordLocation
然后再将HoodieRecordLocation放到数据中,最后将数据发往下游
其实BucketAssignFunction中还有很多的内容,但是为了连贯性,我们先看下游的算子,其余内容我们将在下一篇进行揭秘
StreamWrite*
这边其实有四个类
- StreamWriteOperatorFactory
- 负责创建StreamWriteOperator算子
- 注册StreamWriteOperatorCoordinator
- StreamWriteOperator
- 指定处理数据的Function为StreamWriteFunction
- 给Function设置OperatorEventGateway
- StreamWriteFunction
- 真正处理缓存数据、写出数据的类
- 在写出数据之后,发送写出完毕事件给StreamWriteOperatorCoordinator
- StreamWriteOperatorCoordinator
- 在每个Checkpoint开始时调度一个Instant
- 在所有算子完成Checkpoint之后,提交当前的Instant
我们主要来看一下StreamWriteFunction和StreamWriteOperatorCoordinator这两个类
StreamWriteFunction
我们来看看它是怎么处理每条数据的:在每条数据来了之后,直接丢到bufferRecord()方法中
private void bufferRecord(I value) {
final String bucketID = getBucketID(value);
DataBucket bucket = this.buckets.computeIfAbsent(bucketID,
k -> new DataBucket(this.config.getDouble(FlinkOptions.WRITE_BATCH_SIZE)));
boolean flushBucket = bucket.detector.detect(value);
boolean flushBuffer = this.tracer.trace(bucket.detector.lastRecordSize);
if (flushBucket) {
flushBucket(bucket);
this.tracer.countDown(bucket.detector.totalSize);
bucket.reset();
} else if (flushBuffer) {
// find the max size bucket and flush it out
List<DataBucket> sortedBuckets = this.buckets.values().stream()
.sorted((b1, b2) -> Long.compare(b2.detector.totalSize, b1.detector.totalSize))
.collect(Collectors.toList());
final DataBucket bucketToFlush = sortedBuckets.get(0);
flushBucket(bucketToFlush);
this.tracer.countDown(bucketToFlush.detector.totalSize);
bucketToFlush.reset();
}
bucket.records.add((HoodieRecord<?>) value);
}
先是根据数据中的分区路径、FileId算出桶Id
再根据桶Id去获取DataBucket
检测是否需要刷新桶数据
- 是
- 获取当前Pending的Instant
- 如果数据需要写入之前去重,则先去重
- 将数据写入底层文件中
- 将写入成功事件发送给StreamWriteOperatorCoordinator
- 否
- 检测是否需要刷新缓存数据
- 否则跳出
- 是则找到当前缓存数据最多的桶,并重复上面的写入过程
- 检测是否需要刷新缓存数据
都不满足则将当前数据缓存
有些细节部分没有说,这里大家可以自己看看,接下来我们再看看StreamWriteOperatorCoordinator中的内容
StreamWriteOperatorCoordinator
先看看接收到StreamWriteFunction发送的事件后,如何处理的
@Override
public void handleEventFromOperator(int i, OperatorEvent operatorEvent) {
executor.execute(
() -> {
// no event to handle
ValidationUtils.checkState(operatorEvent instanceof BatchWriteSuccessEvent,
"The coordinator can only handle BatchWriteSuccessEvent");
BatchWriteSuccessEvent event = (BatchWriteSuccessEvent) operatorEvent;
// the write task does not block after checkpointing(and before it receives a checkpoint success event),
// if it it checkpoints succeed then flushes the data buffer again before this coordinator receives a checkpoint
// success event, the data buffer would flush with an older instant time.
ValidationUtils.checkState(
HoodieTimeline.compareTimestamps(instant, HoodieTimeline.GREATER_THAN_OR_EQUALS, event.getInstantTime()),
String.format("Receive an unexpected event for instant %s from task %d",
event.getInstantTime(), event.getTaskID()));
if (this.eventBuffer[event.getTaskID()] != null) {
this.eventBuffer[event.getTaskID()].mergeWith(event);
} else {
this.eventBuffer[event.getTaskID()] = event;
}
if (event.isEndInput() && allEventsReceived()) {
// start to commit the instant.
commitInstant();
// no compaction scheduling for batch mode
}
}, "handle write success event for instant %s", this.instant
);
}
这边的逻辑比较简单,如果事件是来自有界输入流则isEndInput()返回True,并且如果所有的Event事件都被接收,则提交当前Instant
截止到这里,本篇内容就结束了,剩余的内容比如Checkpoint发生时的处理、Update数据处理将会放在下期来讲
另外,大家在看的时候可能出现代码和Master分支对不上的情况,其实很正常,这几个类的内容都隔着好几天写的,社区迭代的比较快,所以会出现代码不一致的情况,问题不大,只要主流程没变就OK
写在最后
- 本期的内容依旧很多,希望大家看完能有所收货
- 剩余的写过程分析内容,将在下期写完
- 最后,点个赞呗