A Detailed Investigation and Analysis of Using Machine Learning Techniques for Intrusion Detection译一
入侵检测是当今网络世界的重要安全问题之一。已经开发了大量的基于机器学习方法的技术。然而,它们在识别所有类型的入侵方面并不十分成功。在本文中,我们对各种机器学习技术进行了详细的调查和分析,以找到与各种机器学习技术在检测入侵活动方面的问题的原因。攻击分类和攻击特征的映射被提供给每个攻击对应。还讨论了与使用网络攻击数据集检测低频攻击有关的问题,并提出了可行的改进方法。机器学习技术在检测各类攻击的能力方面进行了分析和比较。还讨论了与每一类技术相关的局限性。本文还包括各种机器学习的数据挖掘工具。最后,提供了使用机器学习技术进行攻击检测的未来方向。
1.引言
随着技术的发展,黑客事件与日俱增。每年都有大量的黑客事件由公司报告。2007年,分布式拒绝服务(DDoS)攻击针对爱沙尼亚的网站,据说是由俄罗斯发起的[1]。2008年6月17日,亚马逊[2]开始在其一个地点收到来自多个用户的一些认证请求。这些请求开始明显增加,导致服务器速度减慢。2013年1月,欧洲网络和信息安全局(ENISA)[3]报告说,Dropbox受到DDoS攻击,遭受了超过15小时的大量服务损失,影响了全球所有用户。2014年9月28日,Facebook[4]遭到了疑似分布式拒绝服务攻击。Panjwani等人[5]报告说,在50%的针对网络系统的攻击之前,都有某种形式的网络扫描活动。攻击者不仅发动洪水和探测攻击,还以病毒、蠕虫、垃圾邮件的形式传播恶意软件文件,利用现有软件中存在的漏洞,对用户存储在机器上的敏感信息造成威胁。思科年度安全报告提到[6],2013年4月17日,与波士顿马拉松爆炸案有关的垃圾邮件占到全球所有垃圾邮件的40%。在思科公司2017年所做的一项最新调查中[7],木马被列为五大恶意软件之一,这些恶意软件被用来获得对用户电脑和组织网络的初始访问。因此,在这样一个复杂的技术环境中,安全问题是一个很大的挑战,需要智能地解决。
研究人员已经考虑了不同类别的攻击来进行入侵检测。例如,拒绝服务(DoS)攻击(带宽和资源耗尽)、扫描攻击(探测)和远程到本地(R2L)攻击以及用户到根(U2R)攻击,这些都是基于KDD'99数据集[12]。最近的一个攻击数据集(UNSW-NB[13]),将攻击分为九类。Fuzzer, Analysis, Reconnaissance, ShellCode, Worm, Generic, DoS, Exploit and Generic。所有这些攻击已经在第三节中进行了详细讨论。目前的安全解决方案包括使用中间箱,如防火墙、防病毒和入侵检测系统(IDS)。防火墙根据源地址或目的地址来控制进入或离开网络的流量。它根据防火墙的规则来改变流量。防火墙也受限于可用状态的数量和它们对接收内容的主机的了解。IDS是一种安全工具,它监测网络流量,扫描系统中的可疑活动,并向系统或网络管理员发出警报[14]。它是本文关注的主要焦点。
IDS主要有两种类型:
- 基于主机的:基于主机的入侵检测系统(HIDS)[15]监控单个主机或设备,如果检测到可疑的活动,如修改或删除系统文件、不需要的系统调用序列、不需要的配置变化,则向用户发出警报。
- 和基于网络的:基于网络的入侵检测系统(NIDS)[16]通常被放置在网络点,如网关和路由器,以检查网络流量中的入侵行为。
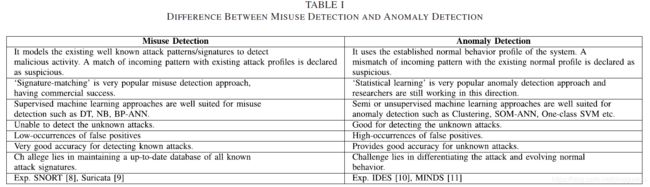
在高层次上,这些IDS使用的检测机制有三种类型:误用检测、异常检测和混合检测。
- 在误用检测方法中,IDS维护一套知识库(规则)以检测已知的攻击类型。误用检测技术可大致分为基于知识和基于机器学习的技术。
- 在基于知识的技术中,网络流量或主机审计数据(如系统调用痕迹)与预定义的规则或攻击模式进行比较。基于知识的技术可分为三种类型。(i) 签名匹配 (ii) 状态转换分析和 (iii) 基于规则的专家系统[17]。基于签名匹配的误用检测技术根据固定模式扫描传入的数据包。如果任何模式与数据包头相匹配,数据包就被标记为异常。基于状态转换分析的方法,为已知的可疑模式维持一个系统的状态转换模型。该模型的不同分支导致了机器的最终受损状态。基于规则的专家系统为不同的入侵情况维护一个规则数据库。基于知识的IDS需要以动态方式定期维护知识数据库,并可能无法检测到攻击的变体。
- 误用检测也可以使用监督下的机器学习算法,如反向传播人工神经网络(BP-ANN)[18],决策树(DT)C4.5[19]和多类支持向量机(SVM)[20]。基于机器学习的IDS提供了一个基于学习的系统,以发现基于学习的正常和攻击行为的攻击类别。基于机器学习的IDS(基于监督学习算法)的目标是生成已知攻击的一般代表。误用检测技术不能检测未知的攻击。然而,这些技术为检测已知的攻击提供了良好的检测精度。这些类型的IDS还需要定期维护签名数据库,这增加了用户的开销。基于误用检测的IDS,特别是基于签名的IDS非常流行,并取得了商业成功。与这些方法相关的优点和缺点在表I中显示。这些IDS维护一个已知攻击特征的数据库。攻击特征描述了一个攻击的特征。它可以是代码脚本的形式,也可以是系统调用模式的序列或行为特征,等等。IDS以一定的格式存储攻击特征。让我们考虑TCP-ping攻击来说明基于签名的误用检测系统(特别是SNORT[8])。如果一个攻击者想知道,一台机器是否处于活动状态,他/她会扫描该机器。攻击者发送ICMP ping数据包。如果机器被设置为不响应ICMP ECHO REQUEST ping数据包,攻击者可以使用nmap工具发送TCP ping数据包到80端口,并设置ACK标志,序列号为0。 这种攻击的特点是标志被设置为'A'值,确认被设置为0值[21]。由于这样的数据包在受害者一方是不被接受的;在收到数据包时,RST数据包被发送到攻击者的机器上,这表明机器是活的。检测TCP ping攻击的规则,针对居住在IP为192.168.1.0/24的网络中的受害者机器,如:alert TCP any ->192.168.1.0/24 any,(flags: A;ack: 0; msg: “TCP ping detected”;)基于签名的IDS的主要限制是,它需要定期更新系统,为最新的攻击添加签名规则。它对没有定义签名的新发展中的攻击产生更多的错误警报。
- 后来,异常检测方法被用于检测入侵行为。基于异常检测的IDS是基于攻击者的行为与正常用户的行为不同的假设[22]。它有助于检测不断变化的攻击。基于异常检测的IDS对系统的正常行为进行建模,并在一定时间内持续更新。例如,每个网络连接由一组特征识别,如协议、服务、登录尝试次数、每个流的数据包、每个流的字节、源地址、目标地址、源端口、目标端口等。这些特征的行为统计被记录在一个时期内。任何连接流的特征值的任何异常偏差将被异常检测引擎标记为异常。异常检测技术被广泛地分为三种类型。统计技术、基于机器学习的技术和基于有限状态机(FSM)的技术[23]。有限状态机(FSM)产生一个行为模型,该模型由状态、转换和动作组成。Kumar等人[24]提出了一种IDS,它利用隐马尔可夫模型来模拟用户在较长时间内的行为转换。异常检测也可以使用半监督和无监督的机器学习算法,如自组织图(SOM)神经网络[25],聚类算法[26]和一类支持向量机(SVM)[27]。基于机器学习的异常检测IDS提供一个基于学习的系统来发现零日攻击。零日攻击指的是利用一个早期不为人知的漏洞。然而,这些技术由于在区分攻击行为和演变中的正常行为方面的局限性,存在高误报现象。误用检测和异常检测方法的区别见表一。
- 混合检测方法整合了误用和异常检测方法来检测攻击。这些方法的细节和现有文献的例子将在第五节中介绍。
总的来说,使用基于机器学习的IDS比传统的基于签名的IDS的一些优势如下。
- - 通过对攻击模式的细微变化,很容易绕过基于签名的IDS,而基于监督技术的机器学习IDS可以很容易地检测到攻击变体,因为它们学习了流量的行为。
- - 在基于机器学习的IDS中,CPU负载是低到中等的,因为它们不象基于签名的IDS那样分析签名数据库的所有签名。
- - 一些基于机器学习的IDS,特别是基于无监督学习算法的IDS,可以检测到新的攻击。
- - 基于机器学习的IDS可以捕捉到攻击行为的复杂属性,并比传统的基于签名的IDS提高检测精度和速度。
- - 不同类型的攻击在不断演变。基于签名的IDS需要不时地维护签名数据库,并保持其最新状态,而基于机器学习的IDS基于聚类和离群点检测,不需要这种更新。
在本文中,我们主要关注机器学习在异常、误用或混合检测机制中的应用,并对其进行了详细的分析,研究了其在攻击检测方面的能力。对各种机器学习方法的详细研究有助于探索高级网络入侵检测的解决方案。基于机器学习的入侵检测方法已被分为四种类型。这些类型如下。(i) 具有数据集所有特征的单分类器 (ii) 具有数据集有限特征的单分类器 (iii) 具有数据集所有特征的多分类器和 (iv) 具有数据集有限特征的多分类器。在单分类器系统中,一个单独的分类器被用来检测入侵行为。多重分类器是一个广义的术语,它在学习和检测入侵时考虑一组ML算法。一组分类器被整合起来,为检测入侵提供一个共同的输出。例如,Kim等人[28]提出了多种分类器方法,该方法将误用检测模型与异常检测模型分层整合,而不仅仅是将它们的结果结合起来。DT C4.5作为误用检测模块,而一类SVM作为异常检测模块。基于多个分类器的方法降低了误报率,提高了检测率。这些方法中的每一个都是从可用的数据集中学习,这些数据集由一组连接特征描述,如源/目的端口号、源/目的IP地址、源字节和目的字节等。集成学习是多种学习算法的形式之一,其中一组分类器的预测以某种方式结合在一起,第四节将详细讨论。
我们的分析显示,用于分析某些特定类别的攻击行为的特征集,与另一类攻击的特征集不同;因为每一类攻击都拥有一些独特的特征。我们讨论了研究人员在不知道攻击领域知识的情况下使用的标准特征选择方法。本文的主要目标是对使用机器学习方法进行环境中的入侵检测进行详细调查和批判性分析。本文还对各类机器学习技术进行了性能分析,并就每一类技术提出了意见。我们的论文主要集中在有线网络传统网络中的入侵检测。
关于入侵检测应用的详细讨论 可以参考这里[29]-[31]。不同类型的基于机器学习的IDS可用于 移动设备。例如,AmoxID[32]是基于 SVM算法,并为iOS和Android操作系统实现。SMARTbot[33]是一个基于人工神经网络反向传播方法的设备外行为分析框架,用于移动僵尸网络检测,准确率达到99.49%。Shabtai等人提出了一个轻量级的Android恶意软件检测系统。Shabtai等人[34]提出了一个轻量级的安卓恶意软件检测系统,名为Andromaly,该系统也采用了 使用机器学习算法。Sikder等人[35]提出了 一个基于上下文感知的传感器的攻击检测器,称为6thSense 来检测绕过传感器管理系统缺陷的攻击。系统的缺陷。它利用了马尔可夫链、奈何贝叶斯。和Logistic Model Tree(LMT)。关于各种类型的基于机器学习的移动设备IDS的详细调查,特别是移动电话,可以在这里找到[36]。关于基于虚拟化的攻击的详细调查,如虚拟机逃逸、旁路攻击、超级劫持、对访客操作系统的攻击等,以及它们在云/虚拟化环境中的检测技术,已在我们最近的工作中单独解决[37]。更具体地说,Anwar等人[38]最近也发表了关于基于缓存的侧信道攻击和预防方法的调查。我们本次研究工作的主要贡献如下。
- - 提出了基于攻击特点的分类。讨论了使机器学习技术难以实现对低频攻击(如U2R和R2L、蠕虫、ShellCode等)检测的各种因素,并提出了提高其检测率的方法。
- - 对现有的各种入侵检测文献进行了讨论,强调了关键特征、检测机制、采用的特征选择、攻击检测能力。
- - 对各种入侵检测技术的攻击检测能力进行了关键性能分析。还讨论了其局限性以及与其他方法的比较。为每一类技术的改进提供了各种建议。
- - 为入侵检测应用提供了机器学习的未来方向。
本文分为十一部分。在第二节中,给出了与相关调查的比较,强调了我们的具体贡献,以比较我们的工作。在第三节中,详细描述了不同类型的攻击及其特点。在第四节中,描述了各种机器学习技术及其特点,并讨论了机器学习中特征选择的重要性。第五节详细而全面地总结了用于入侵检测的不同机器学习方法,第六节根据它们检测攻击的能力对其进行分类。第七节讨论了一些机器学习技术在检测不同安全攻击方面的性能分析。讨论了与每一类机器学习技术相关的安全问题,并提供了克服安全问题的解决方案。提供了各种有用的措施来提高他们的检测率,然后是第八节,描述了检测低频攻击的问题。在第九节中,讨论了机器学习和深度学习的各种数据挖掘工具。在第十节中,提供了未来的方向,简要介绍了正在进行的和未来的研究工作。最后,在第十一节中,提到了结语和未来工作的范围。
2.相关工作
有一些关于将机器学习应用于入侵检测的调查。对其中一些进行了讨论,以突出它们的贡献。还介绍了使我们的工作与其他工作不同的具体贡献。
- Agrawal和Agrawal[39]对使用数据挖掘技术进行入侵检测的异常检测进行了调查。他们根据三个因素对异常检测方法进行了分类:基于聚类的方法、基于分类的方法和混合方法。K-means。K-Meoids、EM聚类、异常值检测算法已经在基于聚类的方法下进行了描述。Naive Bayes算法、遗传算法、神经网络、支持向量机已经在基于分类的方法中被描述。混合方法描述了机器学习方法的组合。他们提供了使用集合方法的论文的简要比较。
- Haq等人[40]对机器学习技术在入侵检测中的应用作了调查。他们将这些技术大致分为三大类:监督学习、无监督学习和强化学习。在监督学习中,分类器是在标记的数据集上训练的。当我们没有标记的数据集时,就使用无监督学习。在强化学习中,领域专家可以对未标记的实例进行标记。他们提供了各种单一分类器和集合算法的简要描述,并提供了使用机器学习进行入侵检测的论文参考,但没有给出任何关键的分析或意见。
- Ahmed等人[22]对网络异常检测方法进行了调查。攻击被分为四类。DoS、探测、U2R和R2L,基于KDD'99数据集[12]。每一类都指向一种特定类型的异常情况。他们对不同类型的机器学习方法进行了讨论,即基于分类、基于聚类、基于统计和基于信息理论的方法。各种类型的机器学习方法在入侵检测中的应用,区分了正常实例和异常实例。对各种网络入侵检测数据集的问题进行了简要的讨论。建议将协作式IDS作为未来的研究方向。然而,在他们的调查中,缺乏对基于机器学习的各种现有IDS建议的详细深入描述和分析。作者也没有提供机器学习算法的未来方向。
- Buczak和Guven[41]对用于入侵检测的机器学习和数据挖掘技术进行了讨论。他们的调查描述了机器学习和数据挖掘技术在滥用和异常检测中的应用。他们澄清了机器学习(ML)和数据挖掘(DM)之间的区别,并指出ML是DM的一个兄弟姐妹。由于它们都使用相同的方法对数据进行分类或知识发现,他们对所研究的算法使用了ML/DM方法这一术语。在他们的调查中,他们描述了各种方法,并将它们与滥用、异常和混合检测技术联系起来。论文中还提到了关于算法的时间复杂性的描述。他们观察到,KDD'99和DARPA是最常用的数据集,因为这使得比较与作者有关。然而,一些研究人员也使用了NetFlow和tcpdump数据集。他们建议哪种ML/DM方法适合单独用于滥用和异常检测。
在我们的调查中,对各种机器学习技术进行了详细的调查和分析,以发现与各种机器学习技术在检测入侵活动方面的局限性。本工作与现有调查不同的关键因素是,它基于这样一个前提:没有一种特定的入侵检测技术,基于单一/多个分类器算法,可以帮助检测所有类型的攻击。因此,建议使用特定的入侵检测技术来检测一组特定的攻击。讨论了选择算法时各种因素的重要性。攻击分类也提供了攻击实例,并将具体的攻击特征映射到每个攻击上。还提到了检测低频攻击的各种问题,并提出了改进方法。我们讨论了各种入侵检测方法的总结,包括关于不同数据集的文献。与Buczak和Guven[41]一致,我们也发现人们大多使用KDD'99、DARPA数据集。现有的基于机器学习技术的入侵检测方法已被彻底分析,涉及各个攻击类别。对每个类别的方法的局限性进行了讨论,并提出了可行的解决方案。在对文献的详尽调查和利用研究人员报告的结果进行的批判性分析之后,报告和分析了各种意见。在入侵检测领域提供了未来的方向。未来的方向特别指向了深度学习和强化学习技术在入侵检测中的应用。论文中还讨论了与这些方法相关的各种挑战。

3.用相关的攻击特征对攻击进行分类
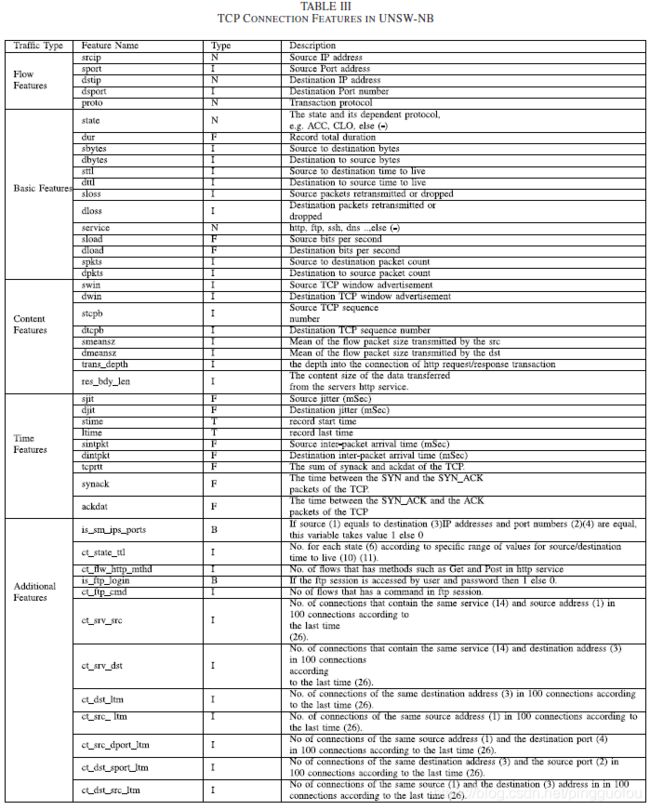
在当今世界,基于网络和主机的攻击已经普遍存在。攻击者试图通过利用网络中的现有漏洞来绕过网络的安全。他们通过破坏网络设备的功能,通过发送过多的数据包来充斥网络,在网络上进行扫描等,扰乱了网络的正常运作。它导致合法用户无法获得服务,并高度降低网络吞吐量。基于主机的攻击试图绕过主机的安全。攻击者获得了对机器的非特权访问,并试图获得root权限,这可能导致重要的系统文件被破坏,敏感数据被修改,用户的私人信息被泄露等。基于主机的攻击可以作为网络攻击后的下一步发起。网络上的任何机器都可以被能够进入网络的黑客破坏。在这种情况下,攻击者首先试图利用网络协议或安全设备(如防火墙[42]、入侵检测系统[43])的弱点,通过网络建立与目标机器的连接,然后试图通过网络复制恶意文件到主机。一旦用户执行了这些文件,系统就被破坏了,并处于攻击者的控制之下。现在,攻击者可以在这些被入侵的主机上进行任何活动,如执行恶意程序和破坏系统。黑客通过使用专门的工具,如Nmap、scapy、Metasploit、Armitage、Dsniff、Tcpdump、Net2pcap、Snoop、Ettercap、Nstreams、Argus、Karpski、Ethereal、Amap、Vmap、TTLscan和Paketto等,利用计算机或网络中的漏洞。[44]-[47]. 这些工具的详细描述可以在[48]中找到。在一个安全的环境中,基于网络和主机的安全都很重要。在本节中,我们描述了根据图1和图3所示的特点,将攻击分为三大类。在每个类别中,我们也描述了基于KDD'99数据集[12]和UNSW-NB数据集[13]的每个攻击的重要攻击特征。所有这些特征在表二和表三中都有详细描述。

3.1. 拒绝服务攻击(资源耗尽和带宽耗尽攻击)
这类攻击导致合法用户无法获得服务,因此也被称为DoS(拒绝服务)攻击[49]。例如,让我们来看看一个攻击场景。攻击者可以发送多个服务请求,要么在企业中注册,要么访问企业中运行的任何有效服务实例。在这种情况下,管理服务器将被许多服务请求淹没,无法向其他合法客户/用户提供服务。还有一种攻击情况,就是用多台机器来发动DoS攻击。大量的机器被连接到一个组织或企业网络。如果一个攻击者能够访问一个组织/企业的一台或多台机器。它可以滥用这一特权,并可以对同一网络子网中的其他机器发动DoS攻击。在这里,攻击面是非常广泛的,攻击者可以占据多台机器(僵尸),并可以利用它们来发动DoS攻击。这种DoS也被称为拒绝服务攻击(DDoS)。DoS攻击被分为两种类型。带宽耗尽和资源耗尽攻击。在带宽耗尽攻击中,攻击者试图通过网络数据包使网络过载。带宽耗尽攻击有两类。淹没式攻击和放大式攻击。在泛滥攻击中,攻击者试图通过发送过多的ICMP或UDP数据包来淹没网络,造成网络资源的过载。在放大攻击中,攻击者试图利用大多数路由器的IP地址广播功能。该功能允许发送系统指定一个广播IP地址作为目标地址,而不是一个特定的地址。这种攻击的例子是smurf和fraggle攻击[52]。在资源耗尽攻击中,攻击者占用了受害者系统的资源。这种攻击可以通过利用网络协议(如neptune,mailbomb)或通过形成畸形的数据包(如Land,Apche2,Back,teledrop,ping of death等),通过网络发送到受害者机器上。以下是对其中一些攻击[53]的简要解释。
Land: 在Land攻击中,攻击者发送欺骗性的SYN数据包,其中的源地址与目标地址相同。它在一些TCP/IP实现中是有效的。
Land攻击特征:攻击可以通过考虑 "Land"特征来检测。如果特征 "Land "的值为1,这意味着源地址和目的地址是相同的。因此,这个特征对识别这种攻击是最重要的。
Teardrop: 在这种攻击中,攻击者试图将碎片化的数据包发送到目标机。他以这样的方式设置碎片偏移,使随后的数据包相互重叠。如果接收目标操作系统的IP碎片重组代码中存在错误,机器就会因不适当地处理重叠的数据包而崩溃。这种攻击在不同的操作系统上是成功的,如Windows 3.1x、Windows 95、Windows NT和2.1.63之前的Linux内核版本。
Teardrop攻击特征: 错误片段 "这一特征是连接中坏的校验和数据包的总和,提供了一些关于畸形IP数据包的线索。因此,这个特征对识别这种攻击很重要。
蓝精灵(Smurf):蓝精灵攻击是一种基于放大的拒绝服务攻击,攻击者向一个广播IP地址发送大量的ICMP回波信息,并以受害者机器的欺骗地址作为源IP。收到数据包后,广播网络中的每台机器都会回复受害者的机器,使其资源无用地忙碌起来[54]。
Smurf攻击特征: 这种攻击可以通过查看大量的ICMP回波回复到受害者机器,而不需要从受害者机器发送任何ICMP回波请求数据包,就可以很容易地在受害者机器上发现。有一些特征,如 "服务"(ICMP),"持续时间","Dst主机相同srv率"(用于查找来自攻击者机器的相同服务和相同目标IP地址的连接的百分比)和 "相同srv率"(用于查找来自受害者机器的相同服务和相同目标IP地址的连接的百分比),这对确定在一定时间内到受害者机器的ICMP回波包总数和在一定时间内来自受害者机器的ICMP回复包总数很有用。
Ping of Death: Ping of Death (PoD)是一种拒绝服务(DoS)攻击。(DoS)攻击,由攻击者故意发送大于65,536个IP数据包造成。大于IP协议所允许的65,536字节的数据包。允许的最大IP数据包大小是65,535字节。包括通常为20字节长的数据包头。这将导致系统崩溃或冻结。许多操作系统 系统都容易受到这种攻击[55]。
PoD攻击特征: 可以通过注意所有ICMP数据包的大小来识别一个企图的死亡之平 通过注意所有ICMP数据包的大小和标记 那些长于65,535字节的数据包。特征 "Dst bytes (收到的字节总数)和连接中的 "持续时间"。可能有助于提供一些关于PoD攻击的线索。这意味着通过比较在短时间内收到的字节总数 这意味着通过比较短时间内收到的字节总数与一些阈值(65,535)。
邮件炸弹(Mailbomb): 在邮件炸弹攻击中,未经授权的用户向特定的邮件服务器发送大量带有大附件的电子邮件,填满磁盘空间,导致其他用户的电子邮件服务被拒绝[56]。
Mailbomb攻击特征:这种攻击可以通过在短时间内寻找来自特定用户的成千上万的邮件信息来识别。诸如 "目标IP"、"Dst字节"(收到的总字节数)、"服务"(SMTP/MIME)和 "Dst主机相同src端口率"(连接到相同端口和相同目标IP地址的百分比)是检测这种攻击行为的重要特征。
SYN泛滥: 在SYN洪流中,TCP/IP的实现被利用。攻击者向受害者机器发送SYN请求。受害者通过ACK回复,并等待回复。服务器将每个半开放连接的信息添加到待定连接队列中。受害者服务器系统上的半开放连接最终会填满队列,系统将无法接受任何新的传入连接[57]。
SYN攻击特征:SYN洪流攻击可以通过寻找来自无法到达的主机的、以特定机器为目的地的SYN数据包的数量来区别于正常的网络流量,或者为系统等待回复的时间长度设置一个阈值。因此,诸如 "持续时间"、"标志"(S0:"初始SYN但没有进一步通信 "等)、"Dst主机计数"(连接到同一目标IP(受害机器)的百分比)等特征对于识别这种攻击非常重要。因此,注意到那些在短时间内没有建立连接的SYN标志的连接,对检测攻击是很有用的。
3.2. 扫描攻击
扫描活动是一个日益增长的网络安全问题,因为它是入侵检测尝试的主要阶段,用于定位网络中的目标系统并随后利用已知的漏洞。攻击者发送大量的扫描数据包,以获得有关机器的详细描述,使用的扫描工具包括nmap、satan、saint、msscan等。Bou-Harb等人[58]对扫描技术进行了详细讨论。他们提供了一个网络扫描主题的分类,分为三个部分。性质、策略和方法。扫描攻击的性质可以是主动或被动的。攻击策略可以是远程到本地、本地到远程、本地到本地和远程到远程。他们还对19种网络扫描技术进行了分类,并说明其优点和缺点。在高层次上,所有19个类别被解释为五个主要类别。开放式扫描[59]、半开放式扫描[60]、隐蔽式扫描[61]、扫荡式扫描[62]和杂项式扫描[63]、[64]。例如,开放扫描和隐蔽扫描尤其是SYN-ACK扫描如图2所示[58]。开放式扫描使用TCP-握手连接。它通过使用SYN标志和TCP协议来检测TCP端口。一个关闭的端口以RST标志的设置进行回复(第i行),而开放的端口以ACK标志的设置进行回复(第ii行)。攻击者现在可以通过发送RST和ACK来重置连接。防火墙可以通过查看日志来检测这种简单的扫描。隐蔽扫描推进了开放扫描,也利用其他标志和SYN标志来避免被发现。对于隐蔽的SYN-ACK扫描,攻击者向目标发送SYN和ACK标志,关闭的端口发送RST标志(第三行),而开放的端口将产生任何响应(第四行)。这是一种相对快速的方法,不需要三方握手或单独的SYN标志。除了扫描场景外,作者还讨论了网络扫描活动的IP版本问题。对分布式检测技术进行了单独的文献回顾,这些技术是根据扫描活动一对一的方法、一对多的方法、多对一的方法和多对多的方法进行分类。这些探针在发起未来的攻击中很有用[65]。下面介绍一些扫描攻击:
Ipsweep。Ipsweep是通过发送许多ping数据包来确定哪些主机在网络上收听。如果目标主机回复,回复会向攻击者透露目标的IP地址。
攻击特征:网络入侵检测系统可以检查在短时间内出现的ping包的总数。诸如 "持续时间"、"服务"(ICMP)、"Dst主机相同srv率"(用于查找相同服务的连接)和 "标志"(用于查找连接状态)等特征对于查找短时间内的ping信息总数和当前连接状态以检测ipsweep攻击非常重要。
重置扫描。在重置扫描中,攻击者向受害者机器发送重置数据包(RST标志向上),以确定该机器是否处于活动状态。如果受害者机器没有对复位包发送任何响应,那么该机器是活的。
攻击特征:这些扫描可以通过检查短时间内进入具有相同服务的脆弱机器的各种RST数据包来检测。诸如 "持续时间"、"服务"、"标志"、"Dst主机计数"(用于查找到脆弱机器的连接总数)等特征对于查找在短时间内以相同服务协议启动RST数据包的连接总数非常重要。
SYN扫描。SYN扫描是一种半开放的扫描攻击,因为攻击者没有建立一个完整的TCP连接。攻击者向不同的端口发送大量的SYN数据包。开放的端口用SYN-ACK回应,关闭的端口用RST回应。
攻击特征:这些扫描可以通过检查由攻击者机器发起的带有REJ(连接被拒绝;初始SYN诱导,RST响应)或S1(SYN的交换没有进一步看到)标志的大型半开放连接来检测。因此,诸如 "持续时间"、"标志"、"Dst host diff srv rate"(连接到不同端口和同一目标IP的百分比)是检测这种攻击的重要特征。
3.3.用户到根攻击
用户到根(U2R)攻击指的是一组漏洞,这些漏洞被用来让无特权的本地用户获得对机器的根权限。这些漏洞以不同的方式获得对机器的根权限。例如,在缓冲区溢出攻击中,攻击者利用用户程序的漏洞,在静态缓冲区中复制了太多的数据,而没有检查以确保数据能很好地适应。攻击者试图操纵溢出缓冲区的数据,导致操作系统执行任意命令。在Ffbconfig攻击[66]中,攻击者利用了随某些操作系统分发的ffbconfig程序。攻击者覆盖了ffbconfigct程序的内部堆栈空间,该程序没有对参数进行充分的边界检查。ffbconfig程序是FFB(快速帧缓冲区)图形加速器的一部分。在loadmodule攻击中,试图利用一些操作系统中存在的漏洞[67]。loadmodule程序将动态加载的内核驱动程序加载到当前运行的系统中,并在/dev目录下创建特殊设备。攻击者利用loadmodule程序中存在的漏洞,获得对机器的root权限。Perl攻击利用了Suidperl版本的Perl中的set-user-ID和setgroup-ID脚本中的漏洞。在这个版本中,当改变有效的用户和组ID时,解释器不能正确地豁免root权限。另一个例子是rootkit攻击[68]。Rootkits是隐蔽的程序,用于为攻击者的系统安装后门或隐藏的入口,以绕过机器的根权限。Rootkits允许攻击者从机器上隐藏许多可疑的进程,并安装额外的软件,如嗅探器、键盘记录器,以破坏机器的资源[69]。
攻击特征。KDD'99的特征不足以观察攻击的行为。事实上,通过考虑KDD'99的特征,很难将这些攻击区分开来。然而,KDD'99中的一些特征,如 "Num failed login"、"Su attempted"、"Is hot login"、"Num shells"、"Root Shell "和 "Num root"、"Duration "和 "Service "提供了一些关于根用户异常行为的提示,因此有助于检测U2R攻击.
3.4远超到用户攻击
远程到用户(R2L)攻击是指那些用来获得对易受攻击机器的本地访问的一组漏洞,只要攻击者能够通过网络向受害机器发送数据包。有多种方法可以发动攻击,以获得对机器的非法权限。在字典/猜测密码攻击中,攻击者试图对可能的用户名和密码进行反复猜测。这种攻击可以使用许多提供登录设施的服务,如telnet, ftp, pop, rlogin和imap。在FTPwrite攻击中,攻击者试图利用ftp的错误配置[70]。在ftp配置中,如果ftp根目录或子目录没有被写入保护,并且在ftp账户的同一组中。攻击者可以向这些目录添加文件,如rhost文件,并获得对机器的访问。在Imap攻击中,攻击者试图利用Imap服务器的缓冲区溢出,这存在于登录交易的认证代码中[71]。攻击者发送精心制作的文本来执行任意指令。在Xlock攻击中,攻击者利用用户不受保护的X控制台来获得对机器的访问。攻击者向用户显示修改后的Xlock程序,并等待用户在该显示中输入密码。密码被木马版的xlock程序送回给攻击者[72]。在wazermaster攻击中,攻击者试图利用FTP服务器中存在的错误。如果FTP服务器给了访客账户写权限,攻击者可以在FTP服务器的公共领域登录到访客账户,并可以将 "warez"(非法软件的副本)上传到服务器。用户随后可以下载这些文件[73]。Warezclient攻击是在攻击者执行 warezmaster后,由合法用户在FTP连接期间发起的。用户从服务器上下载以前由warezmaster创建的文件(非法软件拷贝)[74]。
攻击特征:网络连接特征并不足以观察R2L攻击的行为。事实上,通过考虑网络连接特征来区分这些攻击是非常困难的。然而,KDD'99中的一些特征,如 "持续时间"、"服务"、"Src字节"、"Dst字节"、"Num failed login"、"Is guest login"、"Num compromised"、"Num File creation"、"Count"、"Dst host count "和 "Dst host srv count",可以提供一些关于本地连接中用户异常行为的提示,从而有助于检测R2L攻击。
R2L和U2R攻击之间有一点区别。在U2R攻击中,假定用户拥有受害者机器的本地权限(通过R2L攻击获得)。攻击者在进入机器后试图获得根权限。因此,在U2R的情况下,流量特征的值将与正常连接相似,是最不需要考虑的。在这种情况下,基本和内容特征很重要,而在R2L攻击中,攻击者试图获得对远程机器的本地访问。在R2L中,所有的功能都很重要。在DoS和Probe攻击中,流量特征与其他特征一起非常重要。在第八节中,我们已经描述了使用网络攻击数据集检测这些攻击的困难。在UNSW-NB攻击数据集的基础上,攻击被划分为9种类型,如图3所示。DoS在前面有详细描述。其他攻击将在下面描述。
3.5Fuzzers模糊器攻击
在模糊器攻击中,攻击者从命令行或以协议包的形式发送大量随机生成的输入序列。攻击者试图发现操作系统、程序或网络的安全漏洞,并使这些资源暂停一段时间,甚至可以使它们崩溃。
攻击特征:如果一个源在一段时间内连续发送大量的数据包,使用相同的服务协议和/或在相同的目标端口号。这可能是Fuzzer的迹象。事实上,其他一些特征,如来源到目的地的字节,来源和目的地的数据包计数和大量的变化(或 "抖动")可以是问题的迹象。对这类攻击非常有帮助的特征是:Dur、service、sbytes、spkts、srcjitter、synack、cf_srv_src、ct_src_dport_ltm,见表三。
3.6. 分析
这类攻击是指通过各种手段渗透到网络应用的各种入侵,如端口扫描、恶意网络脚本(如HTML文件渗透)和发送垃圾邮件等。
攻击特征:各种端口扫描攻击的攻击特征和检测这些攻击的各种重要特征将在III-B节中讨论。有邮件服务提供商提供的反垃圾邮件过滤器来过滤这种来自未经授权的来源的电子邮件。垃圾邮件可以被这种过滤器绕过。因此,除了源IP地址外,还可以通过考虑表III中列出的各种可能的特征来分析整个网络性能。特别是,网络应用攻击可以通过进行HTML头、电子邮件头分析或代码分析(脚本代码)来检测[75]。
3.7. 后门
在后门攻击中,攻击者可以绕过正常的认证,可以获得对系统的未经授权的远程访问。攻击者试图通过做欺诈性活动来绕过系统的安全,从而找到数据。黑客使用后门程序来安装恶意文件,修改代码或获得对系统或数据的访问。
攻击特征:在特征集中必须存在的一些重要特征如下。{sport, dsport, dur, sbytes, service, ackdat, sjit, djit, ct_flw_http_mthd, is_ftp_login, ct_srv_src, ct_dst_ltm}。要获得关于受害者机器上的后门尝试的确切信息并不容易。然而,通过分析网络特征,人们可以得到一些关于未经授权的网络尝试的线索。
3.8. 漏洞利用
漏洞利用类是指利用操作系统或软件中的软件漏洞、错误或故障的入侵行为。攻击者利用软件的知识来发动攻击,目的是对系统造成伤害。
攻击特征:各种重要的特征对于检测在被监控机器上启动漏洞的企图至关重要,这些特征如下。{srcip, dstip, sport, dsport, sinpkt, synack, is_sm_ips_ports, ct_ftp_cmd, res_bdy_len, ct_src_ltm, ct_src_ltm}。(参考表三)。这些特征可以提供一些关于启动漏洞的提示。然而,通过使用动态分析技术监测操作系统的行为,可以更恰当地检测出漏洞。这方面可以参考我们的工作[76],[77]。
3.9. 通用
针对加密系统的通用攻击,试图破解安全系统的密钥。它与密码系统的实施细节无关。区块密码的结构不被考虑。例如,生日攻击是一种通用攻击,它将哈希函数视为一个黑盒子。
攻击特征:最好能考虑到通用攻击的所有可能的网络特征。如果只考虑网络特征,系统的准确性可能不会很好。人们还可以对代码进行动态分析,以检查受害者机器中运行的代码的行为。UNSW-NB没有提供KDD'99规定的系统特定特征,如root_login、su_attempted、Hot、Num_Shell等。
3.10. 侦察
侦察是指收集有关目标计算机网络的信息,以绕过其安全控制的攻击。它可以被定义为一种探测,是发动进一步攻击的初步步骤。攻击者使用端口扫描、操作系统扫描、nslookup、dig、whois等来收集系统的信息。根据为每个精心制作的数据包收集的TCP响应,我们可以对操作系统进行智能猜测。在收集到足够的信息后,可以发起DDoS、蠕虫、缓冲区溢出漏洞等攻击。
攻击特征:各种重要的网络特征来检测此类攻击。{sport, dsport, srcip, dstip, dur, spkts, sinpkt, service, synack, ct_srv_src, ct_src_ltm, ct_dst_ltm}。所有的功能都提供了关于源和目的系统的关键网络信息。关于各种端口扫描攻击的细节,相应的特征和攻击特征已经在前面的III-B节中描述过了。
3.11. 壳代码
壳代码被用作有效载荷,在目标机器中执行,以利用软件的漏洞。它被称为shellcode,因为它启动一个由攻击者控制的命令外壳。本地贝壳代码试图利用本地机器上的高权限进程的漏洞,例如缓冲区溢出。远程shellcode的目标是运行在远程系统上的脆弱进程。一旦成功执行,攻击者就能获得对本地机器的远程访问。例如,bindshell将攻击者连接到受害者机器的某个端口。
攻击特征:一些对攻击分析很重要的特征是。{sport, dsport, srcip, dstip, dur, service, sbytes, dbytes, state, res_bdy_len, synack, is_ftp_login}。(参考表三)。网络特征可能有助于检测远程shellcode。然而,为了提供较低的误报和良好的准确性,可以通过对程序进行行为分析来检测shellcode。这些类型的攻击属于低频攻击的范畴,在与远程机器进行网络连接的几次尝试中,就可以轻易地在远程机器上发起攻击。
3.12. 蠕虫
蠕虫是恶意程序或恶意软件,会自我复制并传播到其他计算机。它利用网络来传播攻击。大多数蠕虫被设计为复制,不试图改变系统文件。然而,它们可以通过增加网络流量造成服务中断。
攻击特征:重要的网络特征可能如下:srcip、dstip、sport、dsport、proto、spkts、dpkts、tcprtt、stcpb、dtcpb ct_srv_src、ct_flw_http_mthd、is_ftp_login等,(参考表三)这可以帮助分析在一段时间内使用特定服务和互联网协议(IP)的同一来源地址的数据包的传播。
攻击是蓄意破坏或未经授权访问一台机器或以未经授权的方式访问用户的数据。攻击以计算机网络和/或计算机为目标,损害资源。在我们的研究中,已经讨论了各种攻击。每种攻击都是以某种方式发起的,并带有一些独特的特征,我们已经讨论过。对检测特定类别的攻击至关重要的网络特征也被映射到特定的攻击类别中。KDD'99已经被大多数的研究使用。因此,我们已经考虑将其用于我们的攻击研究。然而,由于它非常古老,我们也考虑了一个非常新的IDS攻击数据集,即UNSW-NB[13],它包含了十个攻击类别。ISCX-IDS攻击数据集[78]没有公开提供。我们根据要求从新不伦瑞克大学(UNB)以PCAP文件的形式获得了这个数据集。作者没有提供攻击特征和它们的描述。因此,KDD'99和UNSW-NB已被考虑用于研究。
4.机器学习:技术和特征选择
在本节中,我们讨论了用于检测入侵的各种最流行的机器学习技术。这些技术具有不同的特点,为检测入侵提供了不同的结果。在这里,我们提到了这些技术的工作和它们的特点。我们进一步描述了各种特征选择方法及其优点和缺点,并为每种攻击提供了最佳特征集。
4.1机器学习中使用的技术
机器学习技术的工作分为两个阶段:训练和测试。在训练阶段,他们对训练数据集进行数学计算,并学习一段时期内的流量行为。在测试阶段,根据所学到的行为,将测试实例分类为正常或侵入性。下面描述了各种流行的机器技术。
1)决策树。决策树学习方法使用分支方法来说明决策的每个可能结果。它们也可以处理离散值属性和连续值属性。然后,学习的树以if-then规则的形式表示。如图4所示,树的三个基本元素是决策节点、分支和叶节点。决策节点指定了对某个属性的测试。每个分支代表该属性的一个可能值。最后,叶子节点代表对象所属的类别。存在各种决策树算法。
一些重要的决策树算法有ID3[79]、C 4.5[80]、CART[81]、LMT树等。ID3是昆兰开发的第一个DT算法。ID3算法使用贪婪的搜索方法。使用信息增益标准来选择测试。在ID3算法中,数据可能被过度拟合和过度归类。ID3不处理缺失值和数字属性。C4.5是ID3的一个改进版本,由Quinlan提供。它接受离散值和连续值,并根据增益比拆分树。它还通过使用基于错误的修剪技术来解决过拟合问题。J48是Weka中C4.5的一个开源实现。它减少了过拟合的几率。然而,对于嘈杂的数据,过拟合可能会发生。CART算法根据牵引标准对树进行分割。它还可以处理分类和数字值。它使用基于成本复杂度的修剪,并处理缺失值。Logistic模型树(LMT)使用具有线性回归模型的决策树。
这些算法大多从根部到叶子进行操作,以得出一些决定。在分类过程中,以下措施被用来选择最佳属性。熵和信息增益。熵表征了一个任意的例子集合的不确定性,而信息增益则衡量一个给定的属性根据其目标分类将训练例子分开的程度。决策树适用于以下问题:(a) 实例可以用属性-值对表示。每个属性都可以有一个不相交的可能值集。(b) 目标函数应该有离散的输出值(例如,是或不是)。(c) 训练数据可能有错误。决策树对错误是稳健的。(d) 训练数据可能包含缺失的属性值[82]。

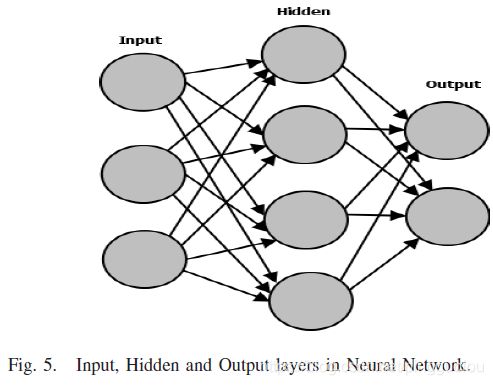
2)人工神经网络。神经网络学习方法为逼近实值、离散值和矢量值的目标函数提供了一种稳健的方法。多层感知器反向传播算法[83]、基于自适应共振理论[84]、基于径向基函数[85]、霍普菲尔兹网络[86]和神经树[87]是使用神经网络的一些分类算法的例子。ANN由三个主要元素组成:输入节点、隐藏节点(隐藏层的处理元素)和输出节点,如图5所示。由反向传播学习(BPL)训练的多层感知器(MLP)神经网络包括两个阶段:前馈和反向传播。在前馈阶段,输入数据被送入隐藏层的每个节点。每个隐藏节点和输出节点计算其激活值。输出目标和期望目标值之间的差异被用来产生误差。在反向传播阶段,误差从输出层传播回输入层,并在输出节点和隐藏节点之间调整权重。梯度下降法被用来更新权重。权重被更新,直到达到预定的阈值[88]。神经网络适用于以下问题:a) 实例由许多属性-价值对表示。b) 目标函数输出可能是离散值、实值或实值或离散值的矢量。d) 学习到的函数通常很难被人类理解,而这种理解学习到的目标函数的能力对人类来说并不重要[83]。
人工神经网络是一种非线性模型,很容易使用。BPL神经网络容易达到局部最小值,因此稳定性较低。特别是对于低频攻击,检测精度很低。由于神经网络的全局近似的非线性映射,需要较长的时间来训练。由于无法还原过去的事件,神经网络无法检测到暂时分散的和协作的攻击。很难找到准确的隐藏层数量和神经元数量。分类器的性能也取决于激活函数的选择。它需要更大的数据集,输出性能取决于训练参数和与训练相关的数据集。
3)Naive Bayes分类器。朴素贝叶斯分类器是基于贝叶斯学习方法的,它在许多应用中被认为是有用的。它被称为 "朴素",因为它是基于简化的假设,即属性值有条件地相互独立。它适用于学习任务,其中每个实例x可以由属性的组合来描述,目标函数f(x)可以从某个有限集合V(目标值的集合)中获取任何一个值。在学习步骤中,鉴于i个属性的训练数据{a1, a2, a3 ... ... ai },各种P(vj)和p(ai-vj)被估计。它估计从一组正常类和异常类标签中观察到一个类标签的后验概率。对于一个给定的测试实例,选择具有最大后验的类标签作为预测的类[82]。它适用于以下问题:a) 目标函数应该有离散的输出值(例如,是或不是)。b) 属性-值对可以代表实例。c) Naive Bayes的独立假设可以接受。有三种Naive Bayes(NB)算法。高斯朴素贝叶斯[89],伯努利朴素贝叶斯[90]和多项式朴素贝叶斯[91]。高斯NB用于根据高斯分布的连续数据值。Bernoulli NB是一个二项式模型,用于二进制特征向量,如Bag of words模型。多项式NB用于离散值,其中特征向量代表某些事件发生的频率。三种NB算法中的概率计算都是不同的。
Naive Bayes分类器实现了快速的检测速度,并且比其他分类器更简单。然而,它提出了一个假设,即特征是相互独立的。这种独立关系假设在检测各种类型的攻击时可能不成立。例如,在公开的KDD'99入侵检测数据集中,特征是高度相互依赖的。例如(参考表二的特征),特征P29(相同的srv率)是依赖于P23(计数)。P23指的是连接到同一目标IP地址的总和。P29指的是在P23(计数)汇总的连接中,连接到相同服务(tcp、http、icmp等)的百分比。同样,特征P28(srv错误率)也依赖于P23(计数)。P27(错误率)也依赖于P23等。对于所有类型的攻击,这样的假设可能不会得到理想的结果。隐蔽的Naive Bayes[92]是Naive Bayes的扩展,并放宽了这一假设。它对DoS攻击的检测达到了(99.6%)的准确性。

4)支持向量机。支持向量机是入侵检测中最成功的机器学习技术之一,与其他分类器一起应用。支持向量机[93]是基于超平面两边的边际概念,如图6所示,将两个数据类分开。通过最大化边际,在分离超平面和超平面两侧的实例之间建立尽可能大的距离,可以减少泛化误差。位于最佳分离超平面边缘上的数据点被称为支持向量点,解决方案被表示为这些点的线性组合。如果数据包含错误分类的实例,SVM可能无法找到分离超平面。解决这个问题的方法之一是将数据映射到一个称为 "特征空间 "的高维空间,并在那里定义分离超平面。核函数被用来将数据映射到一个新的特征空间进行分类。核函数的选择在这里是非常重要的[94]。径向基核(RBF)[95]可用于学习复杂区域。
因此,根据核函数的类型,SVM算法可以分为两种类型:线性SVM和非线性SVM。在线性SVM中,训练数据被线性核函数的超平面所分离。如果数据不是线性分离的,非线性SVM分类器给出的结果很差[96]。因此,非线性核将输入数据映射到一个更高维的特征空间,以找到线性平面。根据检测的类型(误用/异常),SVM可以分为两种类型:多类SVM和单类SVM。多类SVM是用于监督学习算法的。使用SVM的多类分类可以通过两种方式进行:一比所有(传统方式)和一对一。在一对一中,建立一组二进制SVM分类器,并选择被大多数分类器预测的类别。一类SVM是无监督的机器学习算法,用于新颖性检测[97]。SVM的缺点是需要大量的内存和算法的复杂性。其性能也取决于核函数的选择和核函数参数的选择。线性SVM产生的结果不太准确,而且产生过拟合。SVM的训练时间也很高,这在IDS中是不可取的,因为用户的行为一直在变化,需要不时地重新训练一个模型。尽管它对噪声有很强的稳定性。

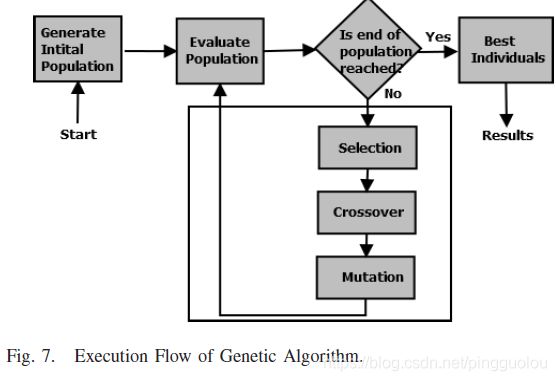
5) 遗传算法。遗传算法(GA)是基于自然选择和遗传学原理寻找近似解决方案的搜索算法[98]。这个过程中使用的四个运算符是初始化、选择、交叉和变异,如图7所示。GA从任意选择的初始群体开始,进化到高质量的个体群体。每个个体被称为染色体,由预定数量的基因组成。基因的质量由其健身函数和每个规则的适应性的定量表示来衡量[99]。在这个过程中,最初选择的种群被演化了几代。在每个迭代中,三个运算符:选择、交叉和变异以一定的概率依次应用于每个运算符。因此,只有适合的基因才能生存和繁殖。GA的一些特点是:a)它们本质上是平行的,它们可以同时在多个方向上探索解决方案的空间。b)它们非常适合潜在解决方案空间确实很大的问题。
入侵检测的三个重要因素是速度、准确性和适应性。据观察,当遗传算法与其他分类器一起应用于优化分类过程的参数和入侵检测系统中的特征选择时,表现良好。然而,它们在一些方面有所欠缺,如不能绝对保证遗传算法会找到一个全局最优。此外,在遗传算法中代表一个问题空间是很复杂的。他们需要大量的拟合函数演化。
6)K-均值聚类。K-means算法是一种基于聚类的异常检测算法。它们基于这样的假设:正常的数据实例靠近其最近的聚类中心点,而异常情况则远离其最近的聚类中心点[101]。在第一步中,假设任何K个数据点为不同聚类的中心点,将数据聚类到K个聚类。其他数据点根据其与中心点的最近距离测量被分配到各群组。在下一步,中心点被重新计算为每个簇的数据点的平均值。这个过程不断重复,直到达到某些停止标准,如图8所示,直到中心点没有变化。Kmean聚类已经被从事入侵检测技术的研究人员广泛采用,并与其他分类器相结合。一些研究人员将其作为分类器,从正常数据实例中分离出异常数据,而一些研究人员将其作为数据压缩技术,从训练数据中分离出异常值,为分类器提供精炼的训练数据集。在这两种情况下,检测结果都得到了改善[102]。如果数据中的异常值自己形成了聚类,那么这些技术就会失败。在这种情况下,这类技术将无法检测到入侵行为。
7)K-最近邻方法。K-NN是一种基于实例的学习算法。KNN属于非参数性的懒惰学习算法[82]。非参数意味着它不对基础数据分布做任何假设。懒惰的意思是它将泛化推迟到分类进行之后。训练阶段比其他分类器快得多,但在分类过程中会涉及更多的计算时间。它是基于这样的假设:数据集中的实例将与其他具有类似属性的实例紧密相邻地存在。它还假设正常的数据实例发生在密集的邻域,而异常的数据实例则发生在远离其最近邻域的地方。未分类的实例的标签可以通过查看其邻居实例的类别标签来确定。基于最近邻居的异常检测技术可以分为两大类。(1) 将数据点与第k个邻居之间的距离作为异常得分的技术。(2) 将每个数据点的相对密度计算为异常得分的技术[103]。k的选择会影响kNN的性能[104]。kNN有一些重要的特点,例如:a)它们是无监督的,不对数据的生成分布做任何假设。b)它们对用于比较实例的相似度函数的选择很敏感。基于距离的kNN被IDS的大多数研究人员用来对训练数据集中的异常情况进行初步的细化。然而,其性能在很大程度上取决于一对数据实例之间的距离测量。定义复杂数据的距离度量可能是一项具有挑战性的任务。如果正常的数据点没有足够的近邻,而异常点有足够的近邻,那么它就不能正确标记实例。
8) 模糊逻辑。模糊逻辑是多值逻辑的一种形式,它处理的是近似而非固定和精确的推理。模糊逻辑提供了正式方法的严谨性,而不要求过分的精确性。它还提供了处理政策偏好和冲突的替代方法[105]。模糊集合理论是用模糊逻辑来定义的。模糊运算符的语义是通过使用几何模型来理解的。模糊逻辑可以解释神经网络的属性,并且可以得到对其性能的精确描述。神经模糊在入侵检测领域非常流行。X中的模糊集A由成员函数fA(x)来描述,该函数将X中的每个点,即区间[0, 1]中的实数,与x处的fA(x)值联系起来,代表x在A中的 "成员等级"。模糊逻辑并不足以检测所有类型的攻击。当它与其他分类器集成时,它表现得很好。模糊逻辑技术已被用于与入侵检测系统相关联[107], [108]。模糊逻辑的主要特点如下[109]。(a) 模糊规则允许构建if-then规则,这些规则可以根据安全应用轻松修改。(b) 它们可以结合来自不同来源的输入。(d) IDS使用的量化措施,如连接间隔、CPU使用时间等,在本质上是模糊的。(e) 一个数值可以同时属于多个模糊集,也就是说,一个数值不必只用一个成员函数来模糊化。(f) IDS所能产生的警报程度往往是模糊的。模糊规则的缺点有以下几点。(i) 他们认为所有的因素都是同等重要的,要结合起来。(ii) 模糊系统在运行前需要更多的微调和模拟。(iii) 由于建立模糊模型的复杂性,与其他机器学习解决方案相比,很难从模糊系统中开发出一个模型。
9) 隐马尔可夫模型。马尔可夫模型产生一个由状态、转换和行动组成的行为模型。隐马尔可夫模型(HMM)和马尔可夫链都属于马尔可夫模型的范畴。在马尔可夫链中,过渡概率是已知的,决定了模型的拓扑结构。在HMM中,被建模的系统由一个具有未知参数的马尔科夫过程表示。HMM可以被定义为呈现序列的概率分布的工具。在HMM中,时间t的观测值Xt是由一个随机过程产生的。然而,该过程的状态Zt不能被直接观察到(隐藏)。HMM满足马尔科夫特性,其中状态Zt只取决于在t-1观察到的先前状态Zt-1[110]。HMM保持一个过渡矩阵K*K。矩阵的每个元素Aij描述了从Zt-1到Zt的过渡概率,可以写成。Aij = P(Zt ,j = 1|Zt ,i = 1)。Ariu和Giacinto[111]提出了一个基于HMM的IDS架构,称为HMMpayl,这是一个基于异常的IDS。HMMpayl的主要目标是保护网络服务器和服务器托管的应用程序免受攻击。从有效载荷的序列中随机选择n-grams的子集,并传递给HMM进行进一步分析。HMMpayl的优点是,与分析所有可能序列的其他n-gram模型相比,它减少了计算成本。作者使用DARPA'99数据集的HTTP流量模拟了该模型。它在随机产生的序列子样本上训练了k个不同的HMM。每个HMM产生的输出最后被组合起来以产生检测精度。HMM的组合被认为比单一的HMM分类器表现更好。HMM有一些优点:(i) HMM的参数调整得很好,比简单的马尔科夫模型提供更好的压缩。(ii) 该模型是相当可读的概率图模型。(iii) HMM很好地捕捉了连续序列之间的依赖关系。(iv) HMM的集合被认为在识别序列结构方面表现良好。HMM有一些缺点:(i)完全连接的HMM可能会导致过拟合问题,这发生在用大参数空间的数据集训练模型时。(ii) HMM用Viterbi算法实现时,在内存和计算时间方面都变得很昂贵。然而,Churbanov和Winters-Hilt[112]将EM聚类与Viterbi相结合,提供了线性内存要求。
10) 蜂群智能。蜂群可以被认为是一群合作的代理,它们一起工作以实现某些目的和任务。蜂群优化是一种先进的机器学习算法,它以进化计算为基础。Kolias等人[113]对入侵检测的群集智能(SI)方法进行了调查。他们提供了各种基于SI的IDS系统的详细比较,指出了它们的优点和缺点。已经描述了用于监督分类的基于SI的核心技术。作者所描述的大多数IDS是异常检测IDS。基于SI的IDS方法利用了多个代理,它们相互协作来解决问题并提供最佳解决方案。一个代理可以用来寻找滥用检测的分类规则或寻找异常检测的集群。他们主要将基于SI的方法分为三种类型。(i) 基于蚁群优化(ACO)的IDS,(ii) 基于粒子群优化(PSM)的IDS (iii) 基于蚁群聚类(ACC)的IDS。ACO算法的动机是蚂蚁寻找从它们的巢穴到食物的最短路径的行为。AntNag[114]是第一个用于入侵检测的ACO算法,它是基于为攻击制作有向图。PSO算法的动机是动物群体的协调运动动力学。ACC算法是以蚂蚁的聚类和排序行为为动机,自主地工作。详细的研究可以参考他们的文献。蜂群优化有一些优势。(i) 基于SI的系统是可适应的,可以根据新的刺激因素进行调整。(ii) 这些系统是可扩展的,因为相同的控制结构可以应用于一组代理。(iii) 它们是灵活的,因为可以很容易地删除或添加代理而不影响结构,等等。基于SI的系统也有一些缺点。(i) 与蜂群相关的复杂性提供了不可预知的结果。(ii) 基于蜂群的丰富层次的系统需要时间来转移到状态。(iii) 没有中央控制,这使得系统变得多余和不可控,等等。[115]
在本小节中,我们讨论了各种机器学习技术。其中一些是有监督的,如各种DT算法、多类SVM、MLP BP-ANN、NB和KNN等。有监督的机器学习算法可以检测已知的攻击模式。他们需要一个标记的攻击数据集。而一些ML算法,如单类SVM、K-Mean聚类、自组织图(SOM)、DBSCAN等,是一些无监督机器学习算法的例子。无监督学习有助于分析未标记的攻击数据集并找到异常值。异常值可以是噪音,也可以是在正常情况下很少发现的异常值。对异常值进行进一步的统计探索,从中提取有用的信息,这有助于从数据中找到明显的特征。模糊逻辑可以应用于分类和聚类算法,以提高其学习能力和攻击检测率。例如,神经模糊和模糊c-means聚类是模糊逻辑在不同ML技术中的一些流行应用。诸如粒子群优化(PSO)等群集智能技术在非线性优化问题上很有帮助。HMM可以用来捕捉使用概率方法的序列之间的依赖关系。蜂群智能和HMM都可以用于监督和无监督的学习问题。不同的分类算法有不同的特点。正如前面所讨论的,每一种都有一些优点和缺点。集合学习提供了相同/不同的监督和非监督算法的组合,用于解决目标问题。它通常可以减少单一分类器的过拟合问题,并提高分类率。
4.2特征选择
高度影响分类器性能的两个主要重要因素是。分类器的技术和选择的特征子集。研究人员已经提出了各种分类器和特征选择方法的组合(在第四节详细讨论)。特征选择的目的是选择最重要和最理想的特征子集。特征选择可以提高泛化性能,降低分类器的计算成本,使分类器在检测未见数据时更快,并简化对数据处理的理解。在检测技术中考虑所有的特征有各种缺点,例如:(i)它会增加系统的计算开销,使训练和测试时间变慢。(ii) 它还会导致更多的存储需求,因为数据库包含的特征数量越多,它需要更多的空间来存储每个特征。(iii) 它限制了使用数据挖掘技术检测入侵行为的分类器的概括能力。(iv) 它增加了分类器的错误率,因为不相关的特征削弱了相关特征的辨别能力。
特征选择方法可分为三种类型[50]。(i) 筛选方法 (ii) 包裹方法 (iii) 混合/嵌入方法。筛选方法是独立于分类器的。它们计算数据的内在属性。与其他方法相比,过滤器的速度足够快。它们对过度拟合相对稳健。主要的缺点是它们不考虑分类器对所选特征的表现结果。因此,它们不能为分类提供最佳的特征子集。基于包络器的方法使用特征子集搜索算法和分类器算法的组合。性能是根据分类率来衡量的。最后选择具有良好分类率的特征子集。分类率阈值被考虑作为特征选择的停止标准。因此,基于包装器的方法是依赖于分类器的。这种方法的主要缺点是,分类器的连续学习可能导致过拟合问题。计算时间通常很高,因为它涉及子集选择算法和分类器的连续迭代。混合方法是在训练阶段与分类器的设计相结合。数据利用被优化,这将减少对每个新子集的分类器的重新训练次数。混合方法的计算成本比基于过滤器的方法高。这里已经详细介绍了各种特征选择算法对入侵检测应用的重要性[119]。
让我们以KDD'99网络攻击数据集的特征为例。一共有41个特征。表二(见第三节)将所有特征分为四大类。
- - 基本特征(1-9)。它指的是单个TCP连接的基本特征,如P3("服务")、P1("持续时间")、P4("标志")等。
- - 内容特征(10-22)。内容特征是从数据包的数据部分提取的,如P11(登录失败次数),P14(Root Shell),P10('Hot')和P13('Num Compromised')。这些特征对于检测U2R和R2L等低频攻击非常重要。这是因为DoS和Probe通常在较短的时间内涉及大量的连接,而R2L和U2R通常涉及单一的连接,并被嵌入到数据包的数据部分。
- - 流量特征(23-31)。流量特征使用2s的时间窗口计算,如P23("计数"),P24("Srv计数"),P29("相同Srv速率")等。这些对于检测高频攻击(DoS和Probe)非常重要。
- - 流量特征(32-41)。流量特征是使用从目的地到主机的2s时间窗口来计算的,如P32('Dst主机计数')、P33('Dst主机srv计数')、P34('Dst主机同一srv速率')和P39('Dst主机srv serror速率')等。这些对于检测高频攻击(DoS、Probe)非常重要。
我们概述了不同类型的机器学习算法,即基于规则的、基于概率的、基于聚类的、集合学习的、基于遗传学的、基于群集智能的等等。还讨论了各种机器学习算法的主要特点、优点和缺点。如果说一种类型的机器学习算法在所有类型的数据集中都能发挥最佳效果,那是不恰当的。一个分类器的准确性并不是唯一重要的因素。许多因素会影响到适当的分类模型的选择,比如我们的数据是由分类的,还是数字的,还是两者都有?数据集的大小是多少? 我们是否需要经常重新训练分类器?我们需要快速部署模型吗?我们有标记的数据还是无标记的数据?数据的复杂性是什么?因此,在选择一堆分类器进行性能分析之前,必须知道机器学习算法的关键特征。
同时,还介绍了特征选择的重要性和可用于机器学习算法的特征选择方法的类型。特征选择有助于识别重要的、非冗余的和相关的属性,有助于预测模型的准确性。同时,考虑到较少和重要的特征,可以加快分类器的速度。