UDA/语义分割/ICCV2021:Dual Path Learning for Domain Adaptation of Semantic Segmentation语义分割领域自适应的双路径学习
UDA/语义分割/ICCV2021:Dual Path Learning for Domain Adaptation of Semantic Segmentation语义分割领域自适应的双路径学习
- 0.摘要
- 1.概述
- 2.相关工作
-
- 2.1.领域自适应
- 2.2.基于领域自适应的语义分割
- 3.方法
-
- 3.1.单路径预热 Single Path Warm-up
- 3.2. 双路径图像转换Dual Path Image Translation
- 3.3. 双路径自适应分割Dual Path Adaptive Segmentation
- 3.4.训练步骤
- 3.5.测试步骤
- 4.实验
-
- 4.1.数据集
- 4.2.网络架构
- 4.3.实现细节
- 4.4.实验
-
- 4.4.1.双路径图像翻译提高翻译质量
- 4.4.2.双路径伪标签生成的有效性
- 4.4.3.双路径自适应分割的有效性
- 4.4.4.标签校正策略的消融研究
- 4.4.5.与先进方法的比较
- 5.结论
- 参考文献
论文下载
开源代码
0.摘要
语义分割的域自适应可以缓解大规模像素级注释的需要。近年来,结合图像到图像转换的自监督学习(SSL)在自适应分割中显示出极大的效果。最常见的做法是执行SSL和图像转换,以很好地对齐单个域(源或目标)。然而,在这种单一领域的范式中,图像翻译引起的不可避免的视觉不一致可能会影响后续的学习。本文基于在源域和目标域中执行的域自适应框架在图像翻译和SSL方面几乎是互补的这一观察,我们提出了一种新的双路径学习(DPL)框架来缓解视觉不一致性。事实上,DPL包含两条互补的、交互的、分别在源域和目标域对齐的单域适配管道。DPL的推理非常简单,仅在目标域中使用一个分割模型。提出了双路径图像翻译和双路径自适应分割等新技术,使两条路径以交互方式相互促进。GTA5实验→Cityscapes和SYNTHIA→Cityscapes场景展示了我们的DPL模型相对于最先进方法的优越性
1.概述
在过去的几十年里,深度卷积神经网络在语义分割方面取得了重大进展[45,4,38,35,43,31,20]。经验性观察[25,39]表明,领先的表现部分归因于大量的培训数据,因此在监督学习中需要密集的像素级注释,这是费时费力的。为了避免这项艰巨的任务,研究人员求助于训练合成但具有照片真实感的大规模数据集上的分割模型,如GTA5[26]和SYNTHIA[27],带有计算机生成的注释。然而,由于跨领域的差异,这些训练有素的模型在真实数据集(例如,Cityscapes[6])上测试时,通常会出现显著的性能下降。因此,无监督域适配(UDA)方法被广泛采用,以调整丰富的标记源数据(合成图像)和未标记目标数据(真实图像)之间的域偏移。
无监督区域自适应分割中两种常用的范例是基于图像到图像翻译的方法[21,9]和基于自我监督学习(SSL)的方法[50,49,44,12]。基于图像到图像转换的方法最常见的做法是将合成数据从源域(表示为域-S)转换到目标域(表示为域-T)[9,2],以减少不同域之间的视觉差距。然后在翻译后的虚拟图像上自适应调整分割模型。然而,仅将图像到图像的转换应用于域自适应任务,结果总是不令人满意。其中一个主要因素是,图像到图像的转换可能会无意中改变图像内容,并在原始图像和翻译图像之间引入明显的一致性。对源图像未经校正的地面真值标签的翻译图像进行训练会引入噪声,干扰域自适应学习
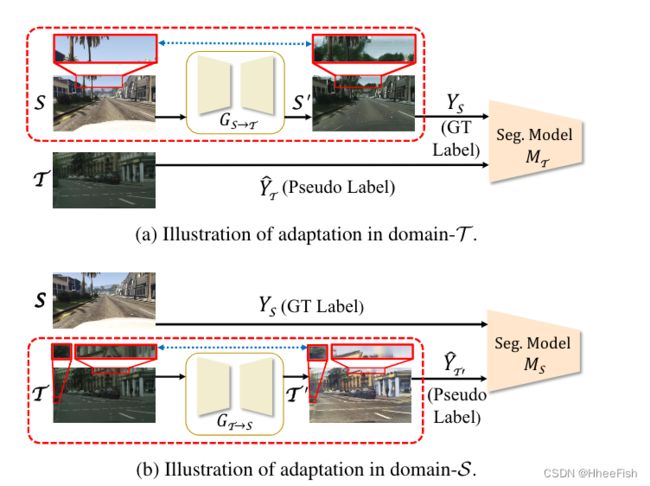
图1:单域自适应管道的说明。源图像与地真标签Ys,目标图像。GS→T表示图像从域到域的平移,反之亦然。S’ =GS→T(S)和T’ =GT→S(T)是对应域的平移图像。MSMT语义分割模型分别用于域S域T。文档中的 Y ^ T \hat{Y}_T Y^T和 Y ^ T ′ \hat{Y}_{T'} Y^T′对应的T和T’的伪标签。红色的横线矩形表示由图像转换引起的视觉不一致干扰了监督部分或SSL部分的域适应学习。
SSL和图像到图像转换[16,41,15]的结合在UDA领域已被证明非常有效。SSL利用一个训练有素的分段模型为未标记的目标数据生成一组具有高置信度的伪标签,然后自适应分段训练可以分为两个并行部分,即监督部分(训练在具有地面真值标签的源数据上进行)和SSL部分(训练是在具有伪标签的目标数据上进行的)。在这种范式中,最重要的实践是进行适应性调整,以很好地对齐单个域,即源域(命名为域Sadaptation)[16,15]或目标域(命名域Tadaption)[41]。然而,这两个域的沙地域自适应都严重依赖图像到图像转换模型的质量,其中视觉不一致总是可以避免的。对于域自适应(如图1.(a)所示),视觉不一致会导致翻译的源图像和未校正的地面真值标签之间出现偏差,这会干扰受监控部分。相反,域S自适应(如图1.(b)所示)避免了源图像上的图像翻译,但同时也引入了目标图像和相应翻译图像之间的视觉不一致性。未对齐图像生成的错误伪标签会干扰SSL部分。
请注意,就两个训练部分而言,上述单域适配管道是最为互补的,即图像翻译导致的视觉不一致干扰了域适配中受监督部分的训练和域适配的SSL部分。相反,域T自适应中的SSL部分和域S自适应的监督部分不受影响。人们自然会提出一个问题:我们是否可以将这两条互补的适应管道组合成一个单一的框架,以充分利用每一个优势,并使它们相互促进?基于这一思想,我们提出了双路径学习框架,该框架考虑了来自相反领域的两条管道,以减少图像翻译带来的不可避免的视觉不一致。我们将框架中使用的两条路径分别命名为path-T(自适应在domain-T中执行)和path-S(自适应在域S中执行)。Path-S协助Path-T从源数据学习精确监管。同时,Path-T指导Path-S生成高质量的伪标签,这些伪标签反过来对SSL很重要。值得注意的是,在我们的框架中,路径沙粒路径皮重不是两条分开的管道,两条路径之间的相互作用在整个训练过程中都会执行,这在我们的实验中证明是有效的。整个系统形成闭环学习。一旦训练完成,我们只保留一个在目标域中很好对齐的分割模型进行测试,不需要额外的计算。这项工作的主要贡献总结如下:
- 我们提出了一种新的双路径学习(DPL)框架,用于语义分段的领域自适应。DPL在培训阶段使用两个互补的交互式单域管道(即路径T和路径S)。在测试中,只使用目标域中对齐良好的单个分段模型。拟议的DPL框架在代表性场景中超越了最先进的方法
- 我们提出了两个交互模块,使两条路径相互移动,即双路径图像平移和双路径自适应分割
- 我们为分段模型引入了一种新的预热策略,有助于在早期训练阶段进行自适应分段
2.相关工作
2.1.领域自适应
领域自适应是计算机视觉领域的一个广泛研究课题。它旨在纠正跨域中的不匹配,并调整模型以在测试时更好地通用化[23]。已经提出了多种用于图像分类[28,3,33,13]和目标检测[5,1]的域适配方法。本文主要研究语义切分的无监督域自适应问题。
2.2.基于领域自适应的语义分割
语义分割需要大量的像素级标记训练数据,这是一项费时费力的标注工作。降低标记成本的一个很有希望的解决方案是,在对真实数据集(如Cityscapes[6])进行测试之前,用计算机生成的注释在合成数据集(例如GTA5[26]和SYNTHIA[27])上训练分割网络。虽然合成图像的外观与真实图像相似,但在布局、颜色和照明条件方面仍然存在领域差异,这始终会影响模型的性能。为了使合成数据集与真实数据集保持一致,需要进行域调整[37、50、46、14]。
基于对手的方法[10,19,32]广泛应用于无监督的领域自适应,在图像级别[21,9,37]或特征级别[32,11]对齐不同的领域。图像级自适应将域自适应视为图像合成问题,旨在减少在具有非成对图像到图像转换模型的跨域中[47,17,22]的视觉差异(例如,照明和物体纹理)。然而,通过简单地应用图像翻译来完成主要的自适应任务,性能总是令人满意的。一个原因是图像到图像的转换可能会无意中改变图像内容,并进一步干扰后续的分割训练[16]。
近年来,自我监督学习(SSL)[7,48]在自适应分割方面显示出巨大潜力[50,49,30,12]。这些方法的关键原理是为目标图像生成一组伪标签,作为对地面真值标签的近似,然后利用目标域数据和伪标签更新分割模型。CRST[50]是第一个将自我训练引入自适应分割的工作,它还通过控制每个类别中选择的伪标签的比例来缓解类别不平衡问题。最近的TPLD[12]提出了一种两阶段伪标签加密策略,以获取SSL的密集伪标签。
两部探索图像翻译和SSL结合的作品[16,41]与我们的作品密切相关。标签驱动[41]执行目标到源的转换,并使用标签驱动重建模块从相应的预测标签重新构造源和目标图像。相反,BDL[16]代表了一个双向学习框架,它交替训练图像翻译和目标函数中的自适应分割。同时,BDL利用单域感知损失来保持视觉一致性。我们将证明这种设计与第3.2节中提出的双路径图像翻译模块相比是次优的。这两项工作证明图像翻译和SSL的结合可以促进自适应学习。与这些单域自适应方法不同,提出的双路径学习框架以交互方式集成了两个完整的单域管道,通过以下方式解决视觉不一致问题:1)利用在不同域对齐的分割模型,为图像翻译提供跨域感知监督;2) 将源知识和目标知识相结合是实现自主学习的主要途径。
3.方法

图2:(a) DPL框架概述。输入用橙色矩形突出显示。DPL由两个互补的单域路径组成:path-S(在源域执行学习)和path-T(在目标域执行学习)。提出了双路径图像转换(DPIT)和双路径自适应分割(das)方法,使两种路径相互作用,相互促进。在DPIT中,非配对图像平移模型(GT→S,GS→T)由一般GAN损失和跨域感知损失监督。DPAS采用所提出的双路径伪标签生成(DPPLG)模块生成目标图像的伪标签材料/ / Y *,然后在具有地真标签的源图像(或翻译后的源图像)和具有伪标签的目标图像(或翻译后的目标图像)上训练分割模型(MSMT)。(b) DPL的测试。MT用于推断
给定源数据集S(合成数据)带有像素级分割标签YS,而目标数据集T(real data)没有标签。无监督域自适应(UDA)的目标是,仅通过使用S、YS和T,使得语义分割模型性能可以与在T对应的地面真值标签YT上训练的模型相当。S和T之间的领域差距使得网络很难立即学习可转移知识
为了解决这个问题,我们提出了一个新的双路径学习框架DPL。如图2.(a)所示,DPL由两条互补的交互式路径组成:path-S(自适应学习在源域中执行)和path-T(自适应学习在目标域中执行)。如何让这两条路径中的一条向另一条提供积极反馈是成功的关键。为了实现这一目标,我们提出了两个模块,即双路径图像翻译(DPIT)和双路径自适应分割(DPAS)。DPIT旨在减少不同领域之间的视觉差距,而不引入视觉不一致。在我们的设计中,DPIT将一般的非成对图像翻译模型与来自两个单域分割模型的双重感知监控结合起来。请注意,DPIT中可以使用任何未成对的图像转换模型,我们使用Cycle GAN[47]作为默认模型,因为它很受欢迎,并且它本身就提供了双向图像转换。我们使用T′=GT→S(T)和S′=GS→T(S)表示在path-S和path-T生成的翻译图像,其中GT→S和GS→T表示对应路径上的图像翻译模型。DPAS利用DPIT翻译后的图像和提出的双路径伪标签生成(DPPLG)模块为目标图像生成高质量的伪标签,然后利用源域内的转移知识和目标域内的隐式监督训练分割模型MS (path- S)和MT(path-T)。DPL的测试非常简单,我们只保留MT作为图2 (b)所示的推断。
DPL的训练过程分为两个阶段:单路径预热和DPL训练。DPL得益于初始化良好的MS和MT,因为DPIT和DPA都依赖于分割模型的质量。简单而有效的预热策略可以加速DPL的收敛。热身结束后,DPIT和DPAS将在DPL训练阶段按顺序进行训练。在本节中,我们首先在第3.1节中描述了我们的预热策略。然后,我们介绍了DPL的关键组件:第3.2节中的DPIT和第3.3节中的DAS。接下来,我们在第3.4节中回顾并总结了整个培训过程。最后,第3.5节中介绍了DPI的测试流程。
3.1.单路径预热 Single Path Warm-up

图3:标签校正策略的说明。输入用橙色矩形突出显示。
DPIT中的感知监控和DPAS中的伪标签生成依赖于分割模型的质量。为了加快DPL的收敛速度,需要对分割模型MS和MT进行预热。
MSWarm-up:通过使用带有真值标签YS源数据集,可以在完全监督的情况下轻松进行MS预热。
MTWarm-up:由于无法在目标数据集中访问任何标签,因此很难以全监督的方式直接训练MT。一个简单的方法是使用朴素的CycleGAN将源图像翻译到目标域,然后用近似真值标签YS对翻译后的图像进行训练。不幸的是,原始的CycleGAN没有应用任何约束来保持S和S′之间的视觉一致性,即当将S转换为S′时,视觉内容可能会发生变化。S′和YS之间的错位会干扰MT的训练
为了解决这个问题,我们提出了一种新的标签校正策略,如图3所示。核心原则是通过同时考虑地面真标签YS和S’的分割预测,找到经过S’修订的标签YS′。特别地,我们将S′输入MT(在开始时初始化为MS),以生成伪标签 Y ^ S ′ \hat{Y}_{S'} Y^S′。然后,标签校正模块通过将YS中的像素级标签替换为 Y ^ S ′ \hat{Y}_{S'} Y^S′中的高置信度像素级标签来修改原始地面真值标签YS,这意味着内容变化区域的标签已经通过可靠的预测进行了近似校正。定义修订标签: Y ^ S ′ = Y ^ S ′ ( i , j ) ( 1 ≤ i ≤ H , 1 ≤ j ≤ W ) \hat{Y}_{S'}=\hat{Y}_{S'}^{(i,j)}(1\leq i\leq H,1\leq j\leq W) Y^S′=Y^S′(i,j)(1≤i≤H,1≤j≤W)如下:
Y S ′ ( i , j ) = { Y ^ S ′ ( i , j ) , i f P i , j , c ^ ( S ′ ) − P i , j , c ( S ′ ) > δ Y S ( i . j ) , e l s e , ( 1 ) Y_{S'}^{(i,j)}=\left\{ \begin{aligned} \hat{Y}_{S'}^{(i,j)},if P^{i,j,\hat{c}}(S')- P^{i,j,c}(S')>\delta\\ Y^{(i.j)}_S,else \\ \end{aligned} ,(1)\right. YS′(i,j)=⎩ ⎨ ⎧Y^S′(i,j),ifPi,j,c^(S′)−Pi,j,c(S′)>δYS(i.j),else,(1)
其中H和W分别表示输入图像的高度和宽度,P(·)是分割模型预测的概率图, c ^ \hat{c} c^和c可以分别表示 Y ^ S ′ ( i , j ) \hat{Y}_{S'}^{(i,j)} Y^S′(i,j)和 Y S ( i , j ) Y_S^{(i,j)} YS(i,j)的类别指数,δ控制校正率,经验上我们设置δ=0.3。
此外,我们还使用MT为T生成伪标签 Y ^ T \hat{Y}_T Y^T。现在我们有成对的训练数据 ( S ′ , Y S ′ ) (S',Y_{S′}) (S′,YS′)和 ( T , Y ^ T ) (T,\hat{Y}_T) (T,Y^T),它们大致位于MT训练所需的的目标域。总损失定义为
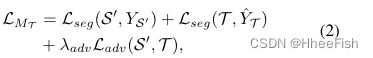
其中Ladv表示用于进一步对齐目标域的典型对抗损失[32,16,41],Lseg表示常用的逐像素分割损失:

其中,I和Y分别表示输入图像(原始图像或翻译后的图像)和相应的标签(地真标签或伪标签)。热身过程完成后,我们得到了在相应区域近似对齐的初步分割模型。这些良好初始化的模型有助于训练DPIT和DPAS,这将在下一节中进行描述
3.2. 双路径图像转换Dual Path Image Translation
图像间的转换旨在缩小源域和目标域之间在视觉外观(例如,物体纹理和照明)上的差距。正如第1节所讨论的,图像翻译导致的不可避免的视觉不一致可能会误导后续的自适应分割学习,因此需要额外的约束来保持视觉一致性
BDL[16]引入了一种感知损失,以保持成对图像(即原始图像和相应的翻译图像)之间的视觉一致性。感知损失测量感知特征1从一个训练良好的分割模型中提取的距离。在BDL中,区域自适应只在目标区域进行,因此用相同的分割模型计算成对图像(S,S’)和(T,T’)的感知损失。注意成对图像来自两个不同的域(S和T’在源域中,而T和S’在目标域中),使用对齐在单个域的分割模型提取特征进行感知损失计算可能是次优的
现在我们介绍双路径图像平移(DPIT),如图2 (a)所示。DPIT是一种具有跨域感知监督的双向图像翻译模型。我们分别用Gs→T,GT→S表示path-T和path-S中的图像平移。CycleGAN作为我们的默认模型,因为它本身就提供了双向的图像翻译,然而,任何非配对的图像翻译算法都可以在DPIT中使用。与BDL不同的是,DPIT利用在相反域对齐的两条路径,从对应的路径中提取成对图像的感知特征,以更好地保持视觉一致性。具体来说,DPIT分别利用MS提取S,T’的感知特征,MTT,S’的感知特征。然后我们就可以描述我们的双感知损失LDualPer
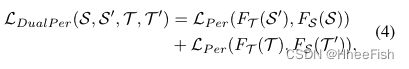
LPer即[16]中的感知损失,FS(·)和FT(·)分别代表MS,MT提取的感知特征。
除了双重感知损失的监督,DPIT还受一般对抗损失和重建损失的监督。DPIT的总损失可表示为:

其中 L G A N S L^S_{GAN} LGANS ( L G A N T L^T_{GAN} LGANT )和 L R e c o n S L^S_{Recon} LReconS ( L R e c o n T L^T_{Recon} LReconT )分别为GAN损耗和重建损耗,如[47],λRecon,λDualPer分别表示重建损耗和双感知损耗的权重。我们默认设置λRecon= 10, λDualPer= 0.1
3.3. 双路径自适应分割Dual Path Adaptive Segmentation
对DPIT进行对称训练后,将翻译后的图像S’=GS→T(S)和T’ =GT→S(T)送入双路径自适应分割(DPAS)模块进行后续学习。如图2所示(a), DPAS利用自监督学习结合训练良好的图像翻译进行自适应分割学习,即对带地真标签的源图像(或翻译后的源图像)和带伪标签的目标图像(或翻译后的目标图像)进行分割模型训练。DPAS的核心是结合两种路径的预测结果生成高质量的目标图像伪标签。DPAS的训练过程可分为两个步骤:1)双路径伪标签生成;2)双路径分割训练。
- 双路径伪标签生成

图4:双路径伪标签生成(DPPLG)的说明。输入用橙色矩形突出显示
在无监督域适应任务中,目标数据集的标签不可用。自监督学习(SSL)在数据集标签不足或噪声较大的情况下取得了良好的效果。生成伪标签的方法在SSL中起着重要作用。如第1节所述,在Path-T中,视觉不一致导致平移后的源图像S’和未校正的真标签YS之间的不对齐,从而干扰了MT的训练。在Path-S中也存在类似的问题(见图1)。受观察到来自相反领域的两条路径几乎是互补的启发,我们充分利用两条路径的优势,提出了新的双路径伪标签生成(DPPLG)策略,以生成高质量的伪标签,如图4所示。
其中,令 P S ( ⋅ ) = S o f t m a x ( F S ( ⋅ ) ) P_S(·)=Softmax(F_S(·)) PS(⋅)=Softmax(FS(⋅))和 P T ( ⋅ ) = S o f t m a x ( F T ( ⋅ ) ) P_T(·)=Softmax(F_T(·)) PT(⋅)=Softmax(FT(⋅))分别表示 M S , M T M_S,M_T MS,MT预测的概率图。在路径T中,目标图像可以直接输入MT生成PT(T)。而path-S需要图像平移生成T’ =GT→S(T),将T '输入MS即可得到Ps(T’)。最后,增强概率图P*(用于生成目标图像的伪标签)可以通过两个单独的概率图PT(T)和pPS(T’)的加权和获得。
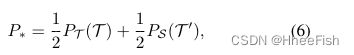
按照惯例[16,12],我们使用最大概率阈值(MPT)来选择P*的置信度较高的像素作为未标记目标图像的伪标签。具体,定义伪标签 Y ^ ∗ = { Y ^ ∗ ( i , j , c ) } ( 1 ≤ i ≤ H , 1 ≤ j ≤ W , 1 ≤ c ≤ C ) \hat{Y}_*=\{\hat{Y}_*^{(i,j,c)}\}(1\leq i\leq H,1\leq j\leq W,1\leq c\leq C) Y^∗={Y^∗(i,j,c)}(1≤i≤H,1≤j≤W,1≤c≤C)

其中λ为过滤预测置信度低的像素点的阈值。我们根据[16]设置λ= 0.9为默认值
虽然path-S和path-T可以使用各自的由它们自己生成的伪标签,但我们将在4.4节中通过使用共享伪标签 Y ^ ∗ \hat{Y}_* Y^∗来演示其好处
- 双路径分割训练
现在我们介绍双路径分割训练的过程。具体地说,对于path-T,目标是在目标域上训练一个良好的广义分割模型。MT训练数据包括两部分,一个是带有地面真实标签YS的翻译源图像S’=GS→T(S),另一个是由DPPLG生成的带有伪标签 Y ^ ∗ \hat{Y}_* Y^∗的原始目标图像T。相比之下,path-S需要在源域有良好的泛化能力。类似地,MS用真实标签YS对源图像S进行训练,并用共享伪标签(public redpseudo)实现图像T’ =GT→S(T)的翻译。除了来自分割损失的监督,我们还在分割模型的特征之上使用了一个鉴别器,以进一步减小领域间隙(如[9,16])。双路径分割的总损失函数可以定义为
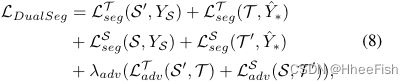
其中, L a d v S L^S_{adv} LadvS和 L a d v T L^T_{adv} LadvT表示典型的对抗损耗, L s e g S L^S_{seg} LsegS和 L s e g T L^T_{seg} LsegT表示公式3中定义的逐像素分割损耗,λadv控制对抗损耗的贡献。
3.4.训练步骤
算法1总结了DPL的整个训练过程。首先,MS,MT由提议的热身策略初始化。接下来,我们训练DPIT为后续的学习提供良好的翻译图像。最后,遵循迭代进行自监督学习的惯例[16,49,12],对DPAS进行N次训练,以进行领域适应。我们用上标(n)表示第n次迭代

3.5.测试步骤
如图2.(b)所示,DPL的推断非常简单,我们只在测试目标时间时保留MT。尽管DPL已经显示了其优于最先进方法的优越性,但我们探索了一种名为DPL- Dual的可选双路径测试管道,通过考虑来自两条路径的预测来提高性能。具体来说,我们首先从两个训练良好的分割模型MT,MS分别生成概率图PT(T)和PS(T’),然后使用平均函数生成最终概率图PF= (PS(T’)+PT(T))/2。虽然DPL-Dual提高了性能,但引入了额外的计算量。当计算成本是次要的时候,我们推荐使用DPL-Dual作为可选的测试方法
4.实验
4.1.数据集
按照惯例,我们在两个常见场景中评估我们的框架,GTA5[26]→cityscenes[6]和synthia[27]→cityscenes。GTA5包含24,996张图像,分辨率of1914×1052and,我们使用GTA5和城市景观之间的19个共同类别进行训练和测试。对于SYNTHIA数据集,我们使用thesthia - rand - Cityscapes集合,它包含9400张图片,resolution1280×760and 16个城市景观的公共类别。将城市景观划分为训练集、验证集和测试集。训练集包含2,975张图片,使用resolution2048×1024。按照惯例,我们报告了包含500张相同分辨率图像的验证集的结果。所有的消融研究都在GTA5→Cityscapes上进行,并在GTA5→Cityscapes和SYNTHIA→Cityscapes上进行与先进的比较。我们使用分类欠条和mIoU来评估性能。
4.2.网络架构
按照通常的做法,我们使用带有ResNet-101[8]的DeepLab-V2[4]和带有VGG16[29]的fc -8s[18]作为我们的语义分割模型。对抗学习中使用的鉴别器与[24]类似,[24]有5个卷积层,内核为size4×4with通道号{64,128,256,512,1},步距为2。对于除最后一个卷积层外的每一个卷积层,都跟随一个参数化为0.2的泄漏ReLU[40]层。该鉴别器在分割模型的软最大输出上实现。对于DPIT,在[16]之后,我们采用了具有9块的CycleGAN体系结构,并使用提出的双重感知损失来保持视觉一致性
4.3.实现细节
训练DPIT时,将输入图像随机裁剪到512×256,训练40 epoch。前20课时的学习率为0.0002,20课时后线性下降至0。公式5中,λRecon设为10,λDualPer设为0.1。对于DPAS训练,输入图像的大小被调整到1024×512批处理大小为4。对于带有ResNet-101的deeplab - v2,我们采用SGD作为优化器,并设置初始学习率5×10−4,在使用’ poly '学习率策略时,该学习率降低,幂为0.9。对于VGG16的fc -8s,我们使用动量为{0.9,0.99}的Adam优化器,初始学习率设置为2×10−5。步长为50000,下降系数为0.1时,学习率降低。对于对抗学习,对于式2和式8中的DeepLab-V2,λadv设置为1×10−3 ,1×10−4。用adam优化器训练鉴别器,初始学习为2×10−4。动量参数设置为0.9和0.99。所有的消融研究都在第一次迭代中进行(N= 1)。当与最先进的方法进行比较时,我们将N= 4。
4.4.实验
4.4.1.双路径图像翻译提高翻译质量

DPIT通过分割模型MSMT计算的双感知损失来鼓励视觉一致性。为了证明DPIT的有效性,我们将其与以下两种方法进行了比较:1)未使用知觉损失来保持视觉一致性的朴素CycleGAN;2) BDL[16]中使用的单路径图像翻译(Single Path Image Translation, SPIT),它应用了CycleGAN和目标域对齐的单分割模型计算的感知损失。注意,这项消融研究的唯一区别是DPL中使用了不同的图像翻译方法。表1显示了比较结果。通过使用感知损失来保持视觉一致性,与单纯的CycleGAN相比,SPIT和DPIT都能显著提高自适应性能。OurDPIT在两种分割模型(MSandMT)中都优于SPIT,表明提取对齐的感知特征可以进一步缓解图像平移引起的视觉不一致
4.4.2.双路径伪标签生成的有效性
在我们提出的DPPLG模块中,来自两种路径的预测共同参与伪标签的生成。我们将DPPLG与单路径伪标签生成(SPPLG)方法进行了比较,即path- sand path- t自行生成各自的伪标签。同时,我们研究了DPPLG的三种不同策略:1)DPPLG- max,选择两条路径概率最大的预测;2) DPPLG-Joint,其中两条路径分别生成伪标签,并选择交集作为最终伪标签;3) DPPLG-Weighted,这是3.3节中描述的缺省策略。表2显示了结果。DPPLG策略的性能均优于SPPLG策略,说明两条互补路径的联合决策可以提高伪标签的质量。由于实验结果优异,我们使用DPPLG-Weighted作为伪标签生成策略。
4.4.3.双路径自适应分割的有效性
我们在表3中显示了DPAS的阶段性结果。当热身结束时, M S ( 0 ) M^{(0)}_S MS(0)和 M T ( 0 ) M^{(0)}_T MT(0)分别达到mIoU的43.7和48.5。第一次迭代后, M S ( 1 ) M^{(1)}_S MS(1)达到49.6(+13.5%的改进), M T ( 1 ) M^{(1)}_T MT(1)达到51.8(+6.8%的改进)。两种细分模型的较大改进表明,两种互补路径之间的相互作用有利于相互适应。后续迭代 M S ( 2 ) − M S ( 4 ) , M T ( 2 ) − M T ( 4 ) M^{(2)}_S-M^{(4)}_S,M^{(2)}_T-M^{(4)}_T MS(2)−MS(4),MT(2)−MT(4)虽然仍能提高性能,但改进有限。
4.4.4.标签校正策略的消融研究

在3.1节中,我们提出了一种为MT设计的暖场标签修正策略。现在我们研究不同的热身策略以及表4中的超参数。回想一下,标签校正 Y S ′ Y_{S'} YS′是通过同时考虑地真标签 Y S Y_S YS和伪标签 Y ^ S ′ \hat{Y}_{S'} Y^S′来找到修正后的标签YS '(见公式1)。我们消除了两种极端情况:1)直接利用不带标签校正的地真标签 Y S Y_S YS;2)直接利用伪标签 Y ^ S ′ \hat{Y}_{S'} Y^S′,无需标签校正。表4的结果显示了我们的标签校正模块的优越性。我们还研究了不同的\delta,它控制着改正率,从表中我们发现\delta是一个不太敏感的超参数,可以默认设置为0.3
4.4.5.与先进方法的比较
我们在GTA5→城市景观和SYNTHIA→城市景观这两个常见场景上,用最先进的方法评估了pl和DPL-Dual。对于每个场景,我们报告了ResNet101和VGG16两个分割模型的结果。表5显示了GTA5→城市场景的结果,DPL在两个模型上都实现了最先进的性能(在ResNet101上mIoU为52.8,在VGG16上为46.2)。在resnet101和VGG16上分别实现了53.3和46.5的mIoU。synthia和Cityscapes的领域差距要比GTA5和Cityscapes大得多,而且它们的类别并没有完全重叠。我们列出了13类和16类的结果,以便与最先进的方法进行公平的比较。结果如表6所示,mIoU(13)和mIoU(16)分别代表对13个常见品类和16个常见品类的适应方法进行评价。再一次,在13类度量下,DPL在ResNet101和VGG16上都实现了最先进的结果,DPL- dual进一步提高了性能。对于16类度量,带有ResNet101的DPL性能略差,因为{wall, fence, pole}类的畴移要大得多,而带有VGG16的DPL仍然超过了mIoU 42.7的最先进DPL, DPL- dual进一步将性能提升到43.0。
5.结论
在本文中,我们提出了一种新的双路径学习框架DPL,该框架利用两条互补的交互式路径进行分割的领域自适应。提出了双路径图像转译和双路径自适应分割等新技术,使两路径相互作用,相互促进。同时,在热身阶段提出了一种新的标签校正策略。DPL的推理非常简单,只使用一个分割模型,很好地对齐目标域。在常见场景GTA5→Cityscape和synthia→Cityscape上的实验证明了我们的DPL方法优于最先进的方法。
参考文献
[1] Deblina Bhattacharjee, Seungryong Kim, Guillaume Vizier,and Mathieu Salzmann. Dunit: Detection-based unsuper-vised image-to-image translation.InProceedings of theIEEE/CVF Conference on Computer Vision and PatternRecognition, pages 4787–4796, 2020. 2
[2] Wei-Lun Chang, Hui-Po Wang, Wen-Hsiao Peng, and Wei-Chen Chiu. All about structure: Adapting structural infor-mation across domains for boosting semantic segmentation.InProceedings of the IEEE Conference on Computer Visionand Pattern Recognition, pages 1900–1909, 2019. 1
[3] Chaoqi Chen, Weiping Xie, Wenbing Huang, Yu Rong,Xinghao Ding, Yue Huang, Tingyang Xu, and JunzhouHuang. Progressive feature alignment for unsupervised do-main adaptation. InThe IEEE Conference on Computer Vi-sion and Pattern Recognition (CVPR), June 2019. 2
[4] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos,Kevin Murphy, and Alan L Yuille. Deeplab: Semantic imagesegmentation with deep convolutional nets, atrous convolu-tion, and fully connected crfs.IEEE transactions on patternanalysis and machine intelligence, 40(4):834–848, 2018. 1,6
[5] Yuhua Chen, Wen Li, Christos Sakaridis, Dengxin Dai, andLuc Van Gool. Domain adaptive faster r-cnn for object de-tection in the wild. InProceedings of the IEEE conference oncomputer vision and pattern recognition, pages 3339–3348,2018. 2
[6] Marius Cordts, Mohamed Omran, Sebastian Ramos, TimoRehfeld, Markus Enzweiler, Rodrigo Benenson, UweFranke, Stefan Roth, and Bernt Schiele.The cityscapesdataset for semantic urban scene understanding. InProceed-ings of the IEEE conference on computer vision and patternrecognition, pages 3213–3223, 2016. 1, 2, 6
[7] Yves Grandvalet and Yoshua Bengio.Semi-supervisedlearning by entropy minimization. InAdvances in neuralinformation processing systems, pages 529–536, 2005. 3
[8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Deep residual learning for image recognition. InProceed-ings of the IEEE conference on computer vision and patternrecognition, pages 770–778, 2016. 6, 8
[9] Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu,Phillip Isola, Kate Saenko, Alexei Efros, and Trevor Darrell.Cycada: Cycle-consistent adversarial domain adaptation. InInternational conference on machine learning, pages 1989–1998. PMLR, 2018. 1, 2, 6
[10] Judy Hoffman, Dequan Wang, Fisher Yu, and Trevor Darrell.Fcns in the wild: Pixel-level adversarial and constraint-basedadaptation.arXiv preprint arXiv:1612.02649, 2016. 2
[11] Jiaxing Huang, Shijian Lu, Dayan Guan, and XiaobingZhang. Contextual-relation consistent domain adaptation forsemantic segmentation.arXiv preprint arXiv:2007.02424,2020. 2, 8
[12] Fei Pan Inkyu, Sanghyun Woo and In So Kweon. Two-phase pseudo label densification for self-training based do-main adaptation. InIn European Conference on ComputerVision (ECCV), 2020.1, 3, 5, 6, 8
[13] Guoliang Kang, Lu Jiang, Yi Yang, and Alexander G Haupt-mann. Contrastive adaptation network for unsupervised do-main adaptation. InProceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition, pages 4893–4902, 2019. 2
[14] Guoliang Kang, Yunchao Wei, Yi Yang, Yueting Zhuang,and Alexander Hauptmann. Pixel-level cycle association:A new perspective for domain adaptive semantic segmenta-tion.Advances in Neural Information Processing Systems,33, 2020. 2
[15] Myeongjin Kim and Hyeran Byun. Learning texture invari-ant representation for domain adaptation of semantic seg-mentation. InProceedings of the IEEE/CVF Conferenceon Computer Vision and Pattern Recognition, pages 12975–12984, 2020. 2, 8
[16] Yunsheng Li, Lu Yuan, and Nuno Vasconcelos. Bidirec-tional learning for domain adaptation of semantic segmen-tation.arXiv preprint arXiv:1904.10620, 2019. 2, 3, 4, 5, 6,7, 8
[17] Ming-Yu Liu, Thomas Breuel, and Jan Kautz. Unsupervisedimage-to-image translation networks. InAdvances in neuralinformation processing systems, pages 700–708, 2017. 3
[18] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fullyconvolutional networks for semantic segmentation. InPro-ceedings of the IEEE conference on computer vision and pat-tern recognition, pages 3431–3440, 2015. 6
[19] Mingsheng Long, Yue Cao, Zhangjie Cao, Jianmin Wang,and Michael I Jordan. Transferable representation learningwith deep adaptation networks.IEEE transactions on patternanalysis and machine intelligence, 41(12):3071–3085, 2018.2
[20] Rohit Mohan and Abhinav Valada. Efficientps: Efficientpanoptic segmentation.International Journal of ComputerVision (IJCV), 2021. 1
[21] Zak Murez, Soheil Kolouri, David Kriegman, Ravi Ra-mamoorthi, and Kyungnam Kim. Image to image translationfor domain adaptation. InProceedings of the IEEE Con-ference on Computer Vision and Pattern Recognition, pages4500–4509, 2018. 1, 2
[22] Taesung Park, Alexei A Efros, Richard Zhang, and Jun-Yan Zhu. Contrastive learning for unpaired image-to-imagetranslation. InEuropean Conference on Computer Vision,pages 319–345. Springer, 2020. 3
[23] Vishal M Patel, Raghuraman Gopalan, Ruonan Li, and RamaChellappa. Visual domain adaptation: A survey of recentadvances.IEEE signal processing magazine, 32(3):53–69,2015. 2
[24] Alec Radford, Luke Metz, and Soumith Chintala.Un-supervised representation learning with deep convolu-tional generative adversarial networks.arXiv preprintarXiv:1511.06434, 2015. 6
[25] Colin Raffel, Noam Shazeer, Adam Roberts, KatherineLee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li,and Peter J. Liu.Exploring the limits of transfer learn-ing with a unified text-to-text transformer.arXiv preprintarXiv:1910.10683, 2019. 1
[26] Stephan R Richter, Vibhav Vineet, Stefan Roth, and VladlenKoltun.Playing for data: Ground truth from computergames. InEuropean Conference on Computer Vision, pages102–118. Springer, 2016. 1, 2, 6
[27] German Ros, Laura Sellart, Joanna Materzynska, DavidVazquez, and Antonio M Lopez. The synthia dataset: A largecollection of synthetic images for semantic segmentation ofurban scenes. InProceedings of the IEEE conference oncomputer vision and pattern recognition, pages 3234–3243,2016. 1, 2, 6
[28] Kuniaki Saito, Kohei Watanabe, Yoshitaka Ushiku, and Tat-suya Harada. Maximum classifier discrepancy for unsuper-vised domain adaptation.arXiv preprint arXiv:1712.02560,2017. 2
[29] Karen Simonyan and Andrew Zisserman. Very deep convo-lutional networks for large-scale image recognition.arXivpreprint arXiv:1409.1556, 2014. 6, 8
[30] M Naseer Subhani and Mohsen Ali. Learning from scale-invariant examples for domain adaptation in semantic seg-mentation.arXiv preprint arXiv:2007.14449, 2020. 3
[31] Andrew Tao, Karan Sapra, and Bryan Catanzaro. Hierarchi-cal multi-scale attention for semantic segmentation.arXivpreprint arXiv:2005.10821, 2020. 1
[32] Yi-Hsuan Tsai, Wei-Chih Hung, Samuel Schulter, Ki-hyuk Sohn, Ming-Hsuan Yang, and Manmohan Chandraker.Learning to adapt structured output space for semantic seg-mentation. InProceedings of the IEEE Conference on Com-puter Vision and Pattern Recognition, pages 7472–7481,2018. 2, 4
[33] Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell.Adversarial discriminative domain adaptation. InProceed-ings of the IEEE conference on computer vision and patternrecognition, pages 7167–7176, 2017. 2
[34] Haoran Wang, Tong Shen, Wei Zhang, Lingyu Duan, andTao Mei. Classes matter: A fine-grained adversarial ap-proach to cross-domain semantic segmentation.arXivpreprint arXiv:2007.09222, 2020. 8
[35] Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang,Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, MingkuiTan, Xinggang Wang, Wenyu Liu, and Bin Xiao. Deephigh-resolution representation learning for visual recogni-tion.TPAMI, 2019. 1
[36] Zhonghao Wang, Mo Yu, Yunchao Wei, Rogerio Feris, Jin-jun Xiong, Wen-mei Hwu, Thomas S Huang, and HonghuiShi. Differential treatment for stuff and things: A simple un-supervised domain adaptation method for semantic segmen-tation. InProceedings of the IEEE/CVF Conference on Com-puter Vision and Pattern Recognition, pages 12635–12644,2020. 8
[37] Zuxuan Wu, Xintong Han, Yen-Liang Lin, MustafaGokhan Uzunbas, Tom Goldstein, Ser Nam Lim, and Larry SDavis. Dcan: Dual channel-wise alignment networks for un-supervised scene adaptation. InProceedings of the Euro-pean Conference on Computer Vision (ECCV), pages 518–534, 2018. 2
[38] Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, andJian Sun. Unified perceptual parsing for scene understand-ing. InProceedings of the European Conference on Com-puter Vision (ECCV), pages 418–434, 2018. 1
[39] Qizhe Xie, Eduard Hovy, Minh-Thang Luong, and Quoc V.Le. Self-training with noisy student improves ImageNet clas-sification.arXiv preprint arXiv:1911.04252, 2019. 1
[40] Bing Xu, Naiyan Wang, Tianqi Chen, and Mu Li. Empiricalevaluation of rectified activations in convolutional network.arXiv preprint arXiv:1505.00853, 2015. 6
[41] Jinyu Yang, Weizhi An, Sheng Wang, Xinliang Zhu,Chaochao Yan, and Junzhou Huang. Label-driven recon-struction for domain adaptation in semantic segmentation.arXiv preprint arXiv:2003.04614, 2020. 2, 3, 4, 8
[42] Yanchao Yang and Stefano Soatto. Fda: Fourier domainadaptation for semantic segmentation. InProceedings ofthe IEEE/CVF Conference on Computer Vision and PatternRecognition, pages 4085–4095, 2020. 8
[43] Yuhui Yuan, Xilin Chen, and Jingdong Wang.Object-contextual representations for semantic segmentation. 2020.1
[44] Qiming Zhang, Jing Zhang, Wei Liu, and Dacheng Tao. Cat-egory anchor-guided unsupervised domain adaptation for se-mantic segmentation. InAdvances in Neural InformationProcessing Systems, pages 435–445, 2019. 1
[45] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, XiaogangWang, and Jiaya Jia. Pyramid scene parsing network. InCVPR, 2017. 1
[46] Sicheng Zhao, Bo Li, Xiangyu Yue, Yang Gu, Pengfei Xu,Runbo Tan, Hu, Hua Chai, and Kurt Keutzer. Multi-sourcedomain adaptation for semantic segmentation. InAdvancesin Neural Information Processing Systems, 2019. 2
[47] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei AEfros.Unpaired image-to-image translation using cycle-consistent adversarial networks. InComputer Vision (ICCV),2017 IEEE International Conference on, 2017. 3, 5, 7
[48] Xiaojin Zhu. Semi-supervised learning tutorial. InInterna-tional Conference on Machine Learning (ICML), pages 1–135, 2007. 3
[49] Yang Zou, Zhiding Yu, Xiaofeng Liu, BVK Kumar, and Jin-song Wang. Confidence regularized self-training. InPro-ceedings of the IEEE International Conference on ComputerVision, pages 5982–5991, 2019. 1, 3, 6
[50] Yang Zou, Zhiding Yu, BVK Vijaya Kumar, and JinsongWang. Unsupervised domain adaptation for semantic seg-mentation via class-balanced self-training. InProceedings ofthe European conference on computer vision (ECCV), pages289–305, 2018. 1, 2, 3