目标检测算法——YOLOv5改进|增加小目标检测层

关注”PandaCVer“公众号
深度学习Tricks,第一时间送达
小目标检测一直以来是CV领域的难点之一,那么,YOLOv5该如何增加小目标检测层呢?

YOLOv5代码修改————针对微小目标检测
1.YOLOv5算法简介
YOLOv5主要由输入端、Backone、Neck以及Prediction四部分组成。其中:
(1) Backbone:在不同图像细粒度上聚合并形成图像特征的卷积神经网络。
(2) Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。
(3) Head: 对图像特征进行预测,生成边界框和并预测类别。
检测框架:
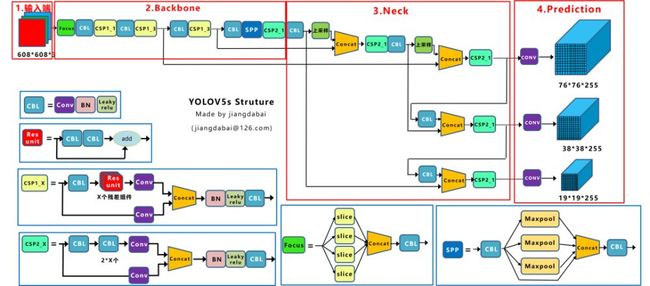
2.原始YOLOv5模型
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]若输入图像尺寸=640X640,
# P3/8 对应的检测特征图大小为80X80,用于检测大小在8X8以上的目标。
# P4/16对应的检测特征图大小为40X40,用于检测大小在16X16以上的目标。
# P5/32对应的检测特征图大小为20X20,用于检测大小在32X32以上的目标。
3.增加小目标检测层
# parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [5,6, 8,14, 15,11] #4
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]], #160*160
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]], #80*80
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]], #40*40
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9 20*20
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]], #20*20
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #40*40
[[-1, 6], 1, Concat, [1]], # cat backbone P4 40*40
[-1, 3, BottleneckCSP, [512, False]], # 13 40*40
[-1, 1, Conv, [512, 1, 1]], #40*40
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3 80*80
[-1, 3, BottleneckCSP, [512, False]], # 17 (P3/8-small) 80*80
[-1, 1, Conv, [256, 1, 1]], #18 80*80
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #19 160*160
[[-1, 2], 1, Concat, [1]], #20 cat backbone p2 160*160
[-1, 3, BottleneckCSP, [256, False]], #21 160*160
[-1, 1, Conv, [256, 3, 2]], #22 80*80
[[-1, 18], 1, Concat, [1]], #23 80*80
[-1, 3, BottleneckCSP, [256, False]], #24 80*80
[-1, 1, Conv, [256, 3, 2]], #25 40*40
[[-1, 14], 1, Concat, [1]], # 26 cat head P4 40*40
[-1, 3, BottleneckCSP, [512, False]], # 27 (P4/16-medium) 40*40
[-1, 1, Conv, [512, 3, 2]], #28 20*20
[[-1, 10], 1, Concat, [1]], #29 cat head P5 #20*20
[-1, 3, BottleneckCSP, [1024, False]], # 30 (P5/32-large) 20*20
[[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(p2, P3, P4, P5)
]
# 新增加160X160的检测特征图,用于检测4X4以上的目标。
改进后,虽然计算量和检测速度有所增加,但对小目标的检测精度有明显改善。
关于YOLOv5的其他改进方法可关注并私信博主的CSDN。