泛型的优势
假设需要一个两个整形变量交换的函数,我们很快就可以嗒嗒嗒嗒的敲出下面的 Swap 函数:
void Swap(ref int lhs, ref int rhs)
{
int temp = lhs;
lhs = rhs;
rhs = temp;
}
随着项目进展,我们发现,需要用到 Swap 函数的不仅是整形,变量 还有字符串,于是我们我又嗒嗒嗒嗒的重载 Swap 函数如下:
void Swap(ref string lhs, ref string rhs)
{
string temp = lhs;
lhs = rhs;
rhs = temp;
}
接下来的开发中,我们又发现还有自定义的结构体,类等等等等都要用到 Swap 函数。如果我们为每一种类型都实现一个相应的 Swap 函数的话,各个版本的 Swap 函数数据类型不同外,其它完完全全一样。也就是说,项目中存在大量的代码重复。能不能之实现一个能够适用于不同数据类型的 Swap 函数,消除这种代码冗余,从而减少工作量,提高开发效率呢?
类型转换
在 C# 中 所有的类型都直接或间接的继承自 System.Object 类。换句话说,所有的类型都可以转换为 Object 类。这为我们前面的问题提供了一个解决方案——实现一个以 Object 为类型参数的 Swap 函数。其实现如下:
void Swap(ref object lhs, ref object rhs)
{
object temp = lhs;
lhs = rhs;
rhs = temp;
}
调用的代码如下:
//a, b 为要传入 Swap 函数的变量
object objA = a;
object objB = b;
Swap(ref objA, ref objB);
//T 为变量 a 和 b 的数据类型
a = (T)objA;
b = (T)objB;
这一实现利用类型转换有效的重用了 Swap 的代码,但有两点不足。
首先是性能问题。每次调用 Swap 函数前,需要对其参数进行一次向上的转型;调用完之后,又要对其进行一次向下的转型。如果需要多次调用 Swap 函数(比如在一个很大的循环中),转型带来的开销是想当可观的,特别是当参数为值类型的时候。
第二是,无法提供编译时类型检查。下面的例子虽然能通过编译,但运行时会出现异常:
string a = “This is a string”;
int b = 0;
object objA = a;
object objB = b;
Swap(ref objA, ref objB); //可以编译
a = (string)objA; //出现运行时异常
b = (ing)objB;
针对以上两点不足,C# 2.0 提出了泛型。
泛型
泛型是C# 2.0 提供的延迟类和函数中数据类型的定义,直到客户代码声明或实例化该数据类型。
泛型版的 Swap 函数实现如下
void Swap<T>(ref T lhs, ref T rhs)
{
T temp = lhs;
lhs = rhs;
rhs = temp;
}
泛型集合中的 <T>是obj类型
上例中的类型参数 T 可以实例化为任意数据类型。相对于通过类型转换重用 Swap 函数,它且不需要类型转换,有效的提高性能。而且,它还能提供编译时类型检查。调用语法与普通函数调用完全一样。
泛型的优势
从上面例子可以看出,使用泛型具有如下三点优势:
? 避免重复代码,最大化代码重用
? 避免无谓的类型转换,提高性能
? 提供编译时类型检查,具有类型安全性
- C# code
-
// 在三角符号里写入类型参数T
public class GenericList < T >
{
// Node为非泛型类,作为GenericList<T>的嵌套类
private class Node
{
// 在非泛型构造函数中使用T
public Node(T t)
{
next = null ;
data = t;
}
private Node next;
public Node Next
{
get { return next; }
set { next = value; }
}
// T作为私有成员的数据类型
private T data;
// T作为属性的返回类型
public T Data
{
get { return data; }
set { data = value; }
}
}
private Node head;
// 构造函数
public GenericList()
{
head = null ;
}
// T 作为方法的参数类型
public void AddHead(T t)
{
Node n = new Node(t);
n.Next = head;
head = n;
}
public IEnumerator < T > GetEnumerator()
{
Node current = head;
while (current != null )
{
yield return current.Data;
current = current.Next;
}
}
}
下面的代码示例演示客户端代码如何使用泛型 GenericList <T> 类来创建整数列表。只需更改类型参数,即可方便地修改下面的代码示例,创建字符串或任何其他自定义类型的列表:
- C# code
-
泛型也在用在类里,可以对参数进行约束而对于new约束而言有点特殊
class TestGenericList
{
static void Main()
{
// int 是类型变量
GenericList < int > list = new GenericList < int > ();
for ( int x = 0 ; x < 10 ; x ++ )
{
list.AddHead(x);
}
foreach ( int i in list)
{
System.Console.Write(i + " " );
}
System.Console.WriteLine( " \n完成 " );
}
}
 public
class
Dictionary
<
K,V
>
where K: IComparable
public
class
Dictionary
<
K,V
>
where K: IComparable {
{
 public void Add(K key, V value)
public void Add(K key, V value) {
{
 if (key.CompareTo(x) < 0) {}
if (key.CompareTo(x) < 0) {} 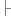 }
}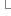 }
}
这样就保证了任何为K类型参数提供的类型都实现了IComparable接口。所以我们的key就可以使用CompareTo方法了。
如果我们在使用时提供了没有实现IComparable接口的类型,就会出现编译时错误。
-
对于new()约束,大家可能有一个误解,以为使用了new约束之后,在创建对象时与非泛型的版本是一致的:
publicclassTester<T>
whereT:new()
{
publicTester()
{
t=newT();//等同于非泛型版本的new?例如objecto=newobject();?
}
privateTt;
}
事实上,使用new关键字的作用只是让编译器在泛型实例化之处,检查所绑定的泛型参数是否具有无参构造函数:
Tester<SomeType>t=newTester<SomeType>();
//此处编译器会检查SomeType是否具有无参构造函数。若没有则会有compileerror -