卷积神经网络(CNN)基础
目录
1 卷积神经网络介绍
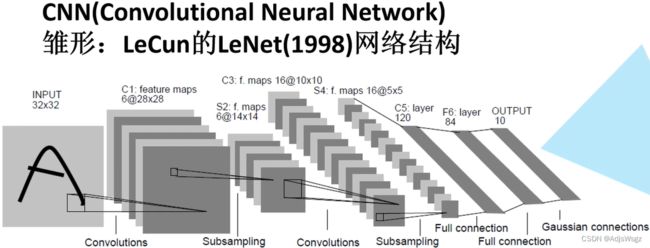
1.1 卷积神经网络的雏形
1.2 全连接层
1.2.1 BP神经网络的实例
1.3 卷积层
1.4 池化层
2 反向传播过程
2.1 误差的计算
2.2 误差的反向传播
2.3 权重的更新
1 卷积神经网络介绍
1.1 卷积神经网络的雏形
1.2 全连接层
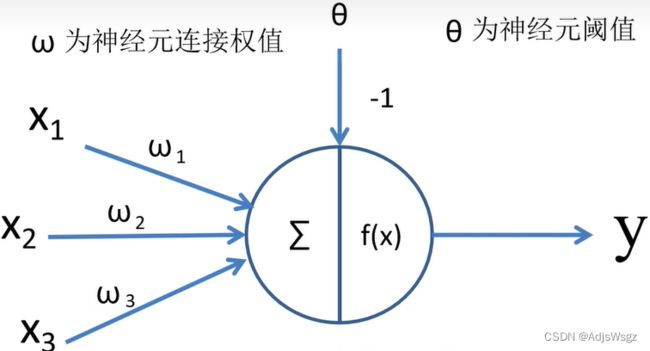
输入乘以权重求和加上偏置,通过一个激励函数即可得到输出:
![]()
将神经元按列排列,列与列之间进行全连接,即可得到一个BP神经网络。
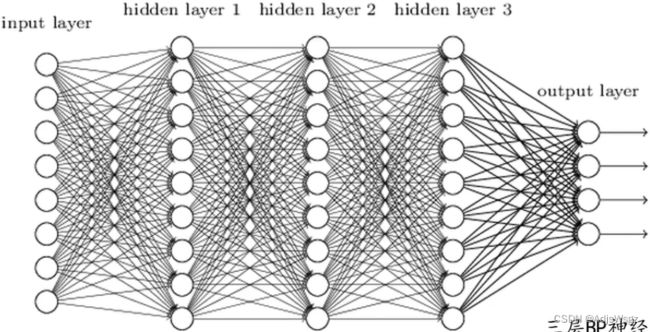
BP算法包括:
信号的向前传播:从输入到输出的方向计算误差;
误差的反向传播:根据误差从输出到输入的方向调整权值和阈值。
1.2.1 BP神经网络的实例
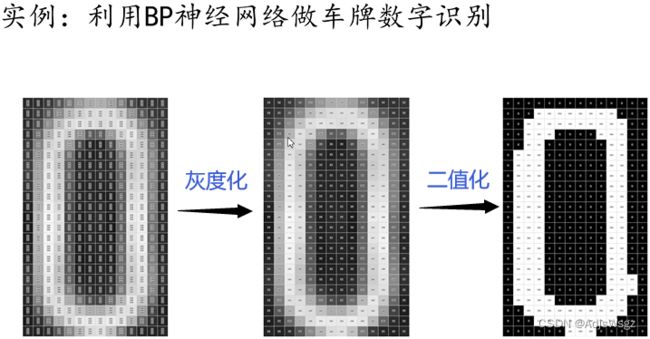
首先读入彩色图像,每一个像素都包含有三个值即R、G、B分量;再经过灰度化和二值化处理,得到一个黑白图像,每个像素只有一个分量。
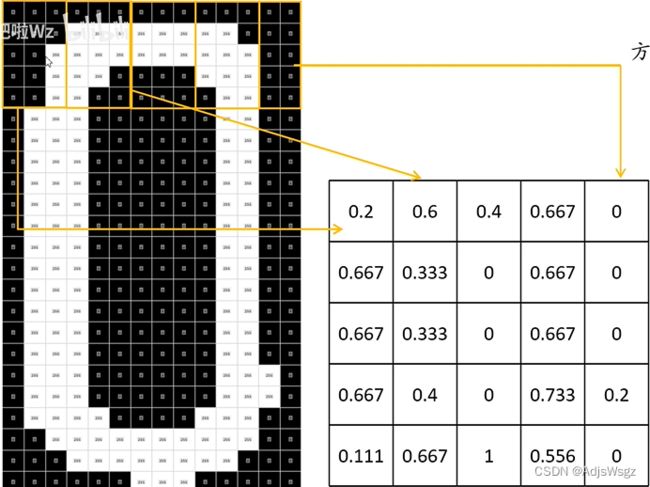
用一个5行3列的滑动窗口在图像上进行滑动,每滑动一次就计算白色像素占整个像素的比例。如果滑动到最右面越界了,可以在最右面补一列0,或者是滑倒最右面把窗口变成5行2列的。处理完后得到一个5×5的矩阵:
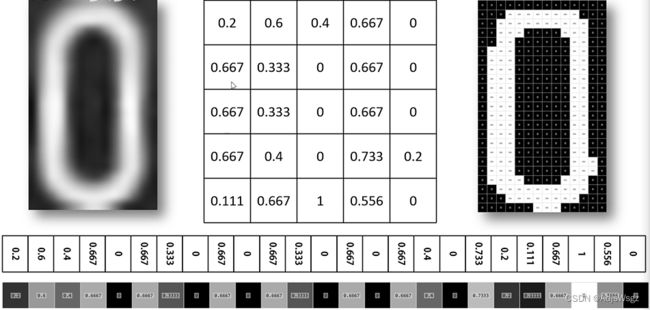
将矩阵按行展开拼接成一个行向量,该行向量作为神经网络的输入层。
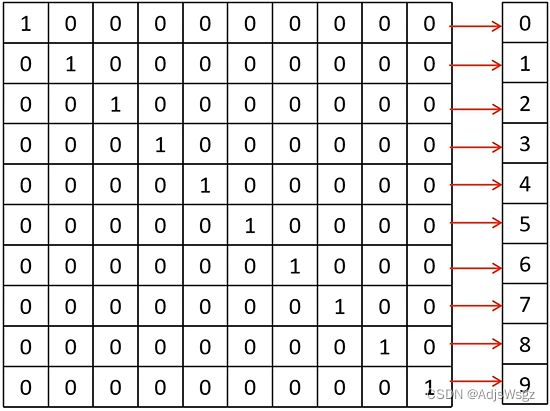
对输出层常采用独热编码(one-hot),有了输入和输出之后,就可以对神经网络进行训练了。
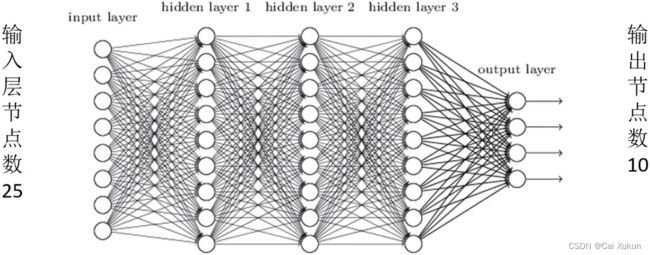
输入层节点个数和输入向量维数相同,设为25;输出层节点个数和输出分类个数相同,设为10。
1.3 卷积层
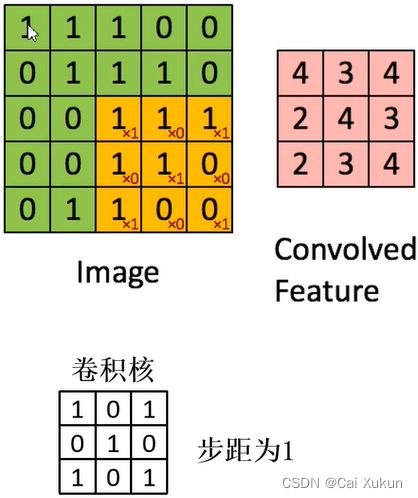
卷积目的是进行图像特征提取。将卷积核作为一个滑动窗口在特征层上面进行滑动,每次滑动的的距离由步长决定,每滑动一次就将特征层的值与卷积核的值对应相乘再相加,最终得到卷积结果。
对于卷积神经网络权值共享的理解:
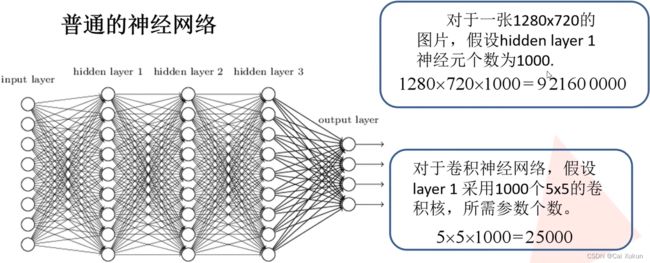
对于普通的神经网络,若要提取1000个特征,将1000个神经元和图片进行全连接,需要![]() 个权重参数;但对于卷积神经网络,若采用5×5的卷积核,所需权重为
个权重参数;但对于卷积神经网络,若采用5×5的卷积核,所需权重为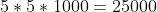 个权重参数。
个权重参数。
对于多层的输入,卷积核层数和输入层数相同,将卷积核的每一层放到输入对应层进行滑动卷积,最后对求出的三层进行求和操作就得到一个输出矩阵;输出的特征矩阵层数和卷积核个数相同,多个卷积核计算的方式是一样的。
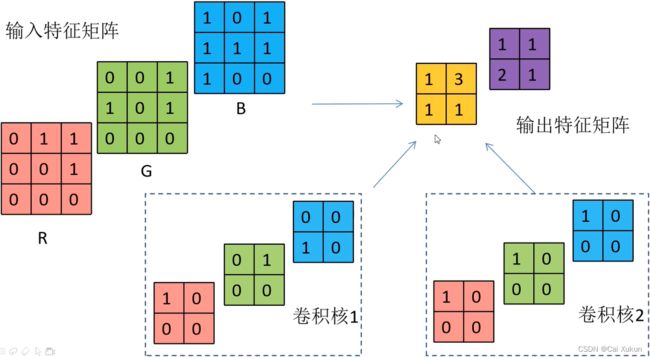
若要加上偏移量,比如卷积核1的偏移量为-1,则对黄色输出矩阵的每一个值都-1,有几个卷积核就有几个偏移量。
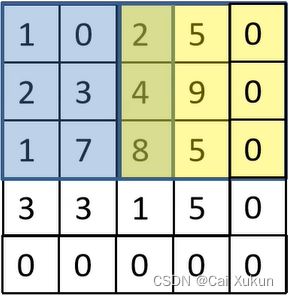
在卷积过程中出现越界,可以利用padding在越界出进行补0处理,矩阵经过卷积操作之后的大小由以下四个参数决定:
①输入图片大小W×W;
②卷积核大小F×F;
③步长S;
④padding的像素数P。
经卷积过后矩阵尺寸大小的计算公式为:
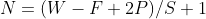
(注:实际操作都是左右上下都补0,所以一般加2P,图中只补了右下,所以计算时只加P)
1.4 池化层
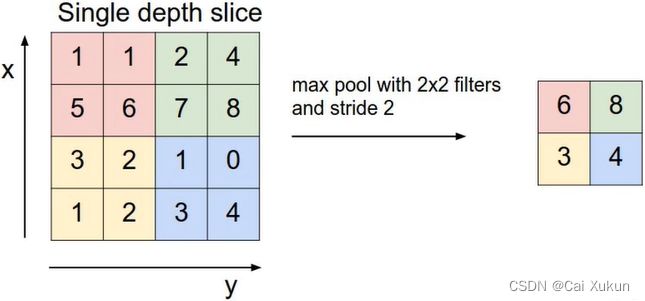
MaxPooling下采样层:图中是采用一个2×2的池化核,步长设为2进行池化操作,池化核每移动一次就找一次最大值,最后得到一个输出矩阵。
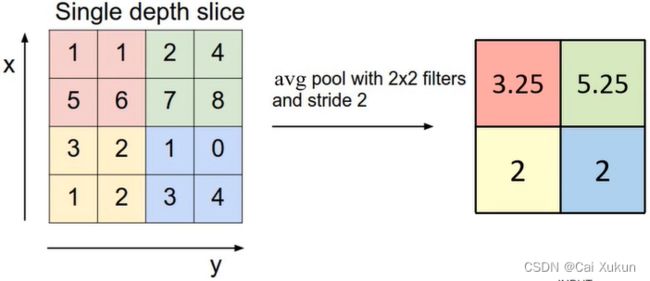
AveragePooling下采样层:和MaxPooling下采样层类似,只不过从找最大值改为求平均值。
池化层作用:对特征图进行稀疏处理,减少数据运算量。
池化层特点:①没有训练参数,可以和卷积核进行对比,卷积核中是带有参数的;②只改变特征矩阵的w和h,不改变深度,也可以和卷积对比,对输入进行卷积操作,不论输入的深度是多少,1个卷积核得到的输出矩阵深度就是1;③池化核大小一般和步长是相同的。
2 反向传播过程
2.1 误差的计算
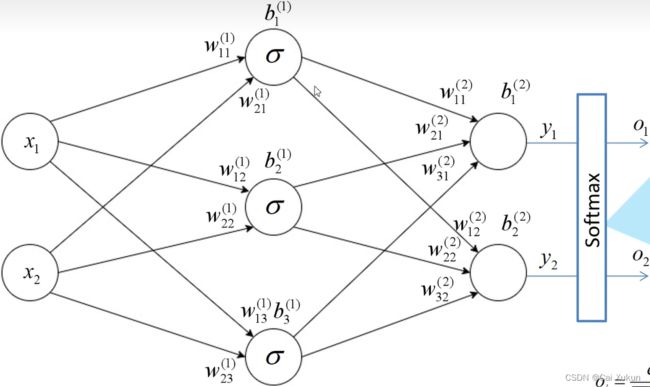
输出 和
和 分别为:
分别为:
其中![]() 的下标11分别指上一层的第1个节点和本层的第1个节点,上标(1)指第1层。
的下标11分别指上一层的第1个节点和本层的第1个节点,上标(1)指第1层。
最后一层统一用Softmax激活函数,这样能使输出能够满足一个分布:
![]() ,
,![]()
经过该处理后所有输出节点概率和为1。
一般计算损失都使用的是交叉熵损失(Cross Entropy Loss),针对多分类问题(softmax输出,所有输出概率和为1)使用:
![]()
针对二分类问题(sigmoid输出,每个输出节点之间互不相干)使用:
![H=-\frac{1}{N}\sum_{i=1}^{N}\left [ o_{i}^{*}log(o_{i})+\left ( 1-o_{i}^{*}log\left ( 1-o_{i} \right ) \right ) \right ]](http://img.e-com-net.com/image/info8/a550394654b949fe9d8a8f2be453691f.gif)
其中 为真实值标签,
为真实值标签, 为预测值,默认log以e为底。上面两者的区别在于某个输出是否只归于一个类别,若只归于一个类别就是多分类问题。
为预测值,默认log以e为底。上面两者的区别在于某个输出是否只归于一个类别,若只归于一个类别就是多分类问题。
该例子的损失为:
![]()
2.2 误差的反向传播
以求![]() 的误差梯度为例,首先对进行处理,可以把上一个节点的输入当成常数来处理:
的误差梯度为例,首先对进行处理,可以把上一个节点的输入当成常数来处理:
![]()
根据链式求导法则:
对其中的每一个表达式进行计算
![]() ,
,![]()
![]()
将求解的值代入到求![]() 的误差梯度的式子中可得
的误差梯度的式子中可得
2.3 权重的更新
![]()

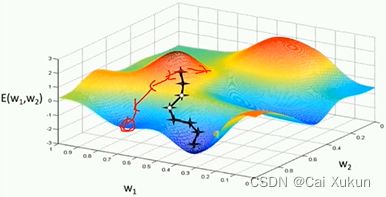
若采用整个样本进行求解,损失梯度会指向全局最优(如左图);但实际应用中不可能一次性将所有数据载入,一般会分批次(batch)训练,此时的损失梯度会指向当前批次最优方向。从图中可以看出,分批次样本训练过程不够平稳,因此需要使用优化器帮助网络更快收敛,通常采用SGD优化器(随机梯度下降法):
![]()
其中 为学习率,
为学习率,![]() 为
为 时刻对参数
时刻对参数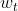 的误差梯度,该优化器有两个缺点:①易受样本噪声影响,若某样本的标注是错误的,那么所求梯度和我们理想中的梯度可能是相悖的;②根据不同批次所求的梯度方向是随机的,因此可能陷入局部最优解(如图中红线所示)。
的误差梯度,该优化器有两个缺点:①易受样本噪声影响,若某样本的标注是错误的,那么所求梯度和我们理想中的梯度可能是相悖的;②根据不同批次所求的梯度方向是随机的,因此可能陷入局部最优解(如图中红线所示)。
根据SGD优化器的缺点,引入了SGD+Momentum优化器:
![]()
![]()
其中 为动量系数,通常取0.9。与SGD优化器相比,多了动量(
为动量系数,通常取0.9。与SGD优化器相比,多了动量( )部分,除了计算当前梯度之外,还将之前的梯度加入进来,具体理解为
)部分,除了计算当前梯度之外,还将之前的梯度加入进来,具体理解为
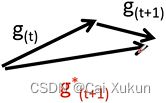
利用SGD优化器,当前梯度方向为![]() ,下一次梯度方向为
,下一次梯度方向为![]() ,但在动量的影响下,会考虑
,但在动量的影响下,会考虑![]() 的方向,
的方向,![]() 的方向可能如图中红标所示。
的方向可能如图中红标所示。