计算文本相似度的常用算法
文章目录
-
-
-
- 1. 余弦相似度
- 2. TF-IDF模型
-
- 2.1 词频TF的计算方法
- 2.2 反文档频率IDF的计算方法
- 2.3 TF-IDF的计算方法
- 3. 基于语义相似度的计算 —— DSSM
- 4. LSI/LSA模型
- 5. LDA模型
- 6. 编辑距离计算
- 7. 杰卡德系数计算
- 8. Word2Vec计算
- 9. BM25
-
-
NLP、数据挖掘领域中,文本分析是一个很重要的领域,这有助于我们去让计算机理解语言的作用和使用。文本分析是数据挖掘的重要手段,利用文本分析,我们将很快的读取到一本书、一篇文章、一段话中的关键词和核心思想,而文本相似度就是我们用来剔除无用信息或者重复信息的重要手段,让计算机去找文本中的不同。
在生活中,信息检索、数据挖掘、机器翻译、文档复制检测等领域都应用到“文本相似度”。文本不仅仅是文字,文本相似度的应用更广,除了文字的匹配,还可以是图片、音频等,因为它们的实质都是在计算机中都是以二进制的方式存在的。相似度,实质就是计算个体间相似程度。
关于NLP语义相似度的计算模型可以分为传统计算模型和基于神经网络的计算模型两大类。传统的计算模型主要是以TF-IDF、BM25、simhash等为代表的计算模型,它们的共同特点是不借助神经网络,而是利用传统的统计词频和相似度计算公式实现。
接下来就介绍几种计算文本相似度的常用算法。
1. 余弦相似度
详细介绍
- 余弦相似度定义
余弦相似度就是通过一个向量空间中两个向量夹角的余弦值作为衡量两个个体之间差异的大小。 把1设为相同,0设为不同,那么相似度的值就是在0~1之间,所有的事物的相似度范围都应该是0 ~ 1。余弦相似度的特点是余弦值接近于1,夹角趋于0,表明两个向量越相似。
但是,文本的相似度计算只是针对字面量来计算的,也就是说只是针对语句的字符是否相同,而不考虑它的语义。比如,
句子1:你真好看。
句子2:你真难看。
这两句话相似度75%,但是它们的语义相差十万八千里,可以说是完全相反。又比如,
句子1:真好吃。
句子2:很美味。
两个句子相似度为0,但是语义在某个场景下是一致的。
所以在实际中,没有很完美的解决方案。每个公司会针对业务要求来调节相似度算法,使其在某些场合能够精确计算。
这种方法类似于编辑距离计算,通过计算将它转换为特定句子最少编辑操作次数,如果它们的距离越大,说明它们越是不同。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符,但是当词义的重要性超过了句子结构时,就会出现上面相似的问题。
- 计算相似度步骤
通过计算模型公式可以明确的求出余弦相似度的值。那么对于我们写程序实现这个算法,就是把两个个体转换为向量,然后通过这个公式求出最终解。
比如向量 a ( x 1 , x 2 , x 3 , x 4 , x 5 ) a(x1, x2, x3, x4, x5) a(x1,x2,x3,x4,x5),向量 b ( y 1 , y 2 , y 3 , y 4 , y 5 ) b(y1, y2, y3, y4, y5) b(y1,y2,y3,y4,y5)。分子为 ( x 1 ∗ y 1 ) + ( x 2 ∗ y 2 ) + ( x 3 ∗ y 3 ) + ( x 4 ∗ y 4 ) + ( x 5 ∗ y 5 ) (x1*y1) +(x2*y2) + (x3*y3) +(x4*y4)+(x5*y5) (x1∗y1)+(x2∗y2)+(x3∗y3)+(x4∗y4)+(x5∗y5),分母 x 1 2 + x 2 2 + x 3 2 + x 4 2 + x 5 2 \sqrt{x1^2+x2^2+x3^2+x4^2+x5^2} x12+x22+x32+x42+x52
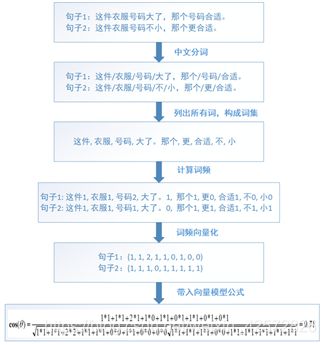
那么计算两个句子相似度的步骤如下:
- 通过中文分词,把完整的句子根据分词算法分为独立的词集合
- 求出两个词集合的并集(词包);
- 计算各自词集的词频并把词频向量化;
- 带入向量计算模型就可以求出文本相似度。
举个栗子:
- 改进方式
在计算步骤中有一个关键词——词频TF。词频是一个词语在文章或句子中出现的次数。如果一个词很重要,很明显是应该在一个文章中出现多次的,但是这也不是绝对的,比如“地”,“啊”等词,它们出现的次数对一篇文章的中心思想没有一点帮助,只是中文语法结构的一部分而已。这类词也被称为**“停用词”**。所以,在计算一篇文章的词频时,停用词是应该过滤掉的。
但是仅仅过滤掉停用词就能接近问题? 也不一定的,比如如果想分析近期的十九届中央纪委二次全会等新闻文章,很明显出现“中国”这个词语必定会出现在每篇文章,但是对于每个新闻的主干思想有帮助吗?对比“反腐反败”,“人工智能”,“大数据”等词语,“中国”这个词语在文章中应该是次要的。
因此进一步假设,如果某个词比较少见(在我们准备的文章库中的占比较低),但是它在这篇文章中多次出现,那么它很可能反映了这篇文章的特性,正是我们所需要的关键词。
在此,在词频TF的基础上又引出了反文档频率IDF的概念。这既是下面要介绍的方法TF-IDE计算,既要考虑词频,也要赋予每个词的权重,体现某个词的重要性。
2. TF-IDF模型
阮一峰
TF-IDF(Term Frequency-Inverse Document Frequency) 是一种统计方法,用以评估某一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化,以防止它偏向长的文件。 逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TF-IDF的主要思想是: 某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
2.1 词频TF的计算方法
一般来说,在一篇文章或一个句子来说,对于每个词都有不同的重要性,这也就是词的权重。在词频的基础上,赋予每一个词的权重,进一步体现该词的重要性。
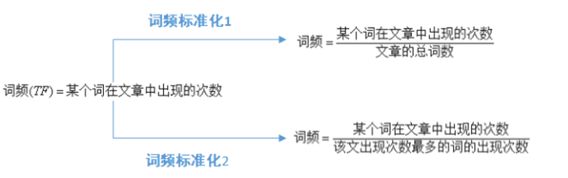
词频标准化的目的是把所有的词频在同一维度上分析。 词频的标准化有两个标准,第一种情况,得出词汇较小,不便于分析。一般情况下,第二个标准更适用,因为能够使词频的值相对大点,便于分析。比如一本书出现一个词语100次,但整本书10万字,但是词频在一句话中只有5次。
TF计算
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
from scipy.linalg import norm
def tf_similarity(s1, s2):
def add_space(s):
return ' '.join(list(s))
# 将字中间加入空格
s1, s2 = add_space(s1), add_space(s2)
# 转化为TF矩阵
cv = CountVectorizer(tokenizer=lambda s: s.split())
corpus = [s1, s2]
vectors = cv.fit_transform(corpus).toarray()
# 计算TF系数
return np.dot(vectors[0], vectors[1]) / (norm(vectors[0]) * norm(vectors[1]))
s1 = '你在干嘛呢'
s2 = '你在干什么呢'
print(tf_similarity(s1, s2))
在在这里我们使用了 np. dot() 方法获取了向量的点乘积,然后通过 norm() 方法获取了向量的模长,经过计算得到二者的 TF 系数。
2.2 反文档频率IDF的计算方法

在这个公式中,有一些需要解释的地方:
- 为什么+1?是为了处理分母为0的情况。假如所有的文章都不包含这个词,分子就
为0,所以+1是为了防止分母为0的情况。 - 为什么要用log函数?log函数是单调递增,求log是为了归一化,保证反文档频率不会过大。
- 会出现负数?肯定不会,分子肯定比分母大。
2.3 TF-IDF的计算方法
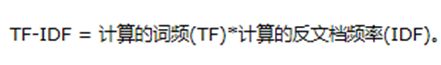
通过公式可以知道,TF-IDF与在该文档中出现的次数成正比,与包含该词的文档数成反比。
- 利用TF-IDF计算文章相似度
- 使用TF-IDF算法,找出两篇文章的关键词
- 每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频)
- 生成两篇文章各自的词频向量
- 计算两个向量的余弦相似度,值越大就表示越相似
我们可以借助于Sklearn中的模块TfidfVectorizer来实现,代码如下:
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
from scipy.linalg import norm
def tfidf_similarity(s1, s2):
def add_space(s):
return ' '.join(list(s))
# 将字中间加入空格
s1, s2 = add_space(s1), add_space(s2)
# 转化为TF矩阵
cv = TfidfVectorizer(tokenizer=lambda s: s.split())
corpus = [s1, s2]
vectors = cv.fit_transform(corpus).toarray()
# 计算TF系数
return np.dot(vectors[0], vectors[1]) / (norm(vectors[0]) * norm(vectors[1]))
s1 = '你在干嘛呢'
s2 = '你在干什么呢'
print(tfidf_similarity(s1, s2))
我们可以发现,余弦相似度作为最基础的算法,计算欧几里得距离,但是就是文本处理中的词频处理,也就是TF法,再优化衍生出了TF-IDF法。
3. 基于语义相似度的计算 —— DSSM
详细介绍
优缺点
- 优点:DSSM 用字向量作为输入既可以减少切词的依赖,又可以提高模型的范化能力,因为每个汉字所能表达的语义是可以复用的。另一方面,传统的输入层是用 Embedding 的方式(如 Word2Vec 的词向量)或者主题模型的方式(如 LDA 的主题向量)来直接做词的映射,再把各个词的向量累加或者拼接起来,由于 Word2Vec 和 LDA 都是无监督的训练,这样会给整个模型引入误差。DSSM 采用统一的有监督训练,不需要在中间过程做无监督模型的映射,因此精准度会比较高。
- 缺点:上文提到 DSSM 采用词袋模型(BOW),因此丧失了语序信息和上下文信息。另一方面,DSSM 采用弱监督、端到端的模型,预测结果不可控。
4. LSI/LSA模型
LSI(Latent Semantic Indexing)又称为潜在语义分析(LSA),是在信息检索领域提出来的一个概念。主要用于解决一词多义(如 “bank” 一词,可以指银行,也可以指河岸)和一义多词(如 “car” 和 “automobile”具有相同的含义)。依靠余弦相似性的方法并不能很好地解决上述问题,所以提出了潜在语义索引的方法,利用SVD降维的方法将词项和文本映射到一个新的空间。
5. LDA模型
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
6. 编辑距离计算
详细介绍
编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个装换成另一个所需的最少编辑操作次数,如果它们的距离越大,说明它们越是不同。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
例如我们有两个字符串:string 和 setting,如果我们想要把 string 转化为 setting,需要这么两步:
- 第一步,在 s 和 t 之间加入字符 e;
- 第二步,把 r 替换成 t
所以它们的编辑距离差就是 2,这就对应着二者要进行转化所要改变(添加、替换、删除)的最小步数。
Python实现
import distance
def edit_distance(s1, s2):
return distance.levenshtein(s1, s2)
s1 = 'string'
s2 = 'setting'
print(edit_distance(s1, s2))
# 这里我们直接使用 distance 库的 levenshtein() 方法,传入两个字符串,即可获取两个字符串的编辑距离了
# 如果我们想要获取相似的文本的话可以直接设定一个编辑距离的阈值来实现,如设置编辑距离为2:
def edit_distance(s1, s2):
return distance.levenshtein(s1, s2)
strings = [
'你在干什么',
'你在干啥子',
'你在做什么',
'你好啊',
'我喜欢吃香蕉'
]
target = '你在干啥'
results = list(filter(lambda x: edit_distance(x, target) <= 2, strings))
print(results) # ['你在干什么', '你在干啥子']
通过这种方式我们可以大致筛选出类似的句子,但是发现一些句子例如“你在做什么” 就没有被识别出来,但他们的意义确实是相差不大的,因此,编辑距离并不是一个好的方式,但是简单易用。
7. 杰卡德系数计算
杰卡德系数(Jaccard Index),又称为Jaccard相似系数,用于比较有限样本集之间的相似性与差异性。Jaccard系数值越大,样本相似度越高。
实际上它的计算方式非常简单,就是两个样本的交集除以并集得到的数值,当两个样本完全一致时,结果为1,当两个样本完全不同时,结果为0。
算法十分简单,就是交集除以并集,Python实现如下
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
def jaccard_similarity(s1, s2):
def add_space(s):
return ' '.join(list(s))
# 将字中间加入空格
s1, s2 = add_space(s1), add_space(s2)
# 转化为TF矩阵
cv = CountVectorizer(tokenizer=lambda s: s.split())
corpus = [s1, s2]
# fit_transform() 方法可以将字符串转化为词频矩阵
vectors = cv.fit_transform(corpus).toarray()
# 求交集
numerator = np.sum(np.min(vectors, axis=0))
# 求并集
denominator = np.sum(np.max(vectors, axis=0))
# 计算杰卡德系数
return 1.0 * numerator / denominator
s1 = '你在干嘛呢'
s2 = '你在干什么呢'
print(jaccard_similarity(s1, s2))
这里我们使用了Sklearn库中的CountVectorizer来计算句子的TF矩阵,然后利用Numpy来计算二者的交集和并集,随后计算杰卡德系数
详细解释
8. Word2Vec计算
Word2Vec,顾名思义,其实就是将每一个词转换为向量的过程。
9. BM25
详细介绍
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
参考的文章
- NLP——计算文本相似度的常用算法
- 自然语言处理入门(1)——文本相似度计算
- 自然语言处理中句子相似度计算的几种方法