MLOps极致细节:18. Azure ML Pipeline(机器学习管道),Azure Container Instances (ACI)部署模型
MLOps极致细节:18. Azure ML Pipeline(机器学习管道),Azure Container Instances (ACI)部署模型
在之前的章节中,我们已经完成了数据预处理,机器学习模型训练,验证,打包,以及注册到Azure Machine Learning Workspace。从本章节开始,我们将尝试三种部署方式,分别是Azure Container Instances (ACI) ,Azure Kubernetes Service,以及MLFlow。
- Win10
- IDE:VSCode
- Anaconda
- 代码地址
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- MLOps极致细节:18. Azure ML Pipeline(机器学习管道),Azure Container Instances (ACI)部署模型
-
- 0 代码运行
- 0 模型部署流程
- 1 注册模型(model registration)
- 2 在本地验证模型
- 3 准备入口脚本(entry script)
- 4. ACI:准备推理配置(inference configuration)和部署配置(deployment configuration)
- 5. ACI:部署机器学习模型为Web服务
- 6. ACI:调用模型
0 代码运行
我们可以选择将我们的代码在Azure Compute Instance(Azure计算平台)上跑,或者在本地运行。建议在Azure的VM上跑,因为速度会快很多(本地环境跑比较慢的原因主要是Azure的一些服务器不在大陆,连接速度比较受限)。
本地运行:搭建虚拟环境:
我们在Windows的平台下使用Anaconda3新建虚拟环境。使用conda create -n [your_env_name] python=3.6。安装完默认的依赖后,我们进入虚拟环境:conda activate [your_env_name]。注意,如果需要退出,则输入conda deactivate。另外,如果Terminal没有成功切换到虚拟环境,可以尝试conda init powershell,然后重启terminal。然后,我们在terminal中进入文件夹6-模型部署ACI,虚拟环境中下载好相关依赖:pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple(此处依赖的版本基于python 3.6)。最后运行主代码:python modelDeployACI.py。
Azure Compute Instance(Azure计算平台):
我会比较建议这种,只需要在Azure Machine Learning Studio的Compute中新建一个VM就可以跑代码了。详细步骤参见之前的博客。
0 模型部署流程
Azure模型部署的流程如下:
- 注册模型(model registration)
- 在本地验证模型
- 准备入口脚本(entry script)。
- 准备推理配置(inference configuration)。
- 部署机器学习模型。
- 选择计算目标(compute target)。
- 将模型部署到云端。
- 测试生成的 Web 服务。
1 注册模型(model registration)
首先,我们和之前一样导入Azure Machine Vision Workspace。稍有不同的是,这次我们使用Workspace.from_config(),这就需要我们先从Azure Portal上的Machine Learning账号页面下下载一个config.json文件。其实道理和workspace = Workspace(subscription_id, resource_group, workspace_name)是一样的。(注意,如果你是使用Azure Compute Instance来跑代码的话,是不需要下载这个config.json文件的,直接运行即可)

关于模型注册,我们在上一个章节已经做了详细的介绍,这里就直接贴代码了:
model = Model.register(model_path = './outputs/rf.onnx', # this points to a local file
model_name = "random-forest-classifier", # this is the name the model is registered as
tags = {'dataset': self.dataset.name, 'version': self.dataset.version, 'hyparameter-C': '1', 'testdata-accuracy': '0.9548'},
model_framework='pandas==0.23.4',
description = "Random forest classifier to predict weather at port of Turku",
workspace = workspace)
注册完之后,我们在Azure Machine Learning Studio中的Models一栏就会看到对应的模型

2 在本地验证模型
当我们注册完模型后,需要在本地先验证一下这个模型是否建立正常。代码如下:
# 实例化Azure Machine Vision Workspace based on config file
ws = Workspace.from_config()
print("Load workspace: {0}".format(ws))
# 从工作区中下载所需的序列化文件以及之前使用Model函数训练的模型。Scaler 将用于将输入数据按照之前训练时候归一化的参数进行归一化
scaler = Model(ws,'scaler').download(exist_ok=True)
svc_model = Model(ws,'random-forest-classifier').download(exist_ok=True)
print("Load models")
with open('scaler.pkl', 'rb') as file:
scaler = pickle.load(file)
# 使用onnxruntime.InferenceSession("test.onnx")为模型创建一个推理会话。
sess = rt.InferenceSession("rf.onnx")
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
print('input name: {0}; label name: {1}.'.format(input_name,label_name))
# 测试一下生成的模型是否有问题,输入6个feature,就是一个训练数据的尺寸。
test_data = np.array([34.927778, 0.24, 7.3899, 83, 16.1000, 1])
# fit_transform()先拟合数据,再标准化,比如:ss = StandardScaler(),X_train = ss.fit_transform(X_train)
test_data = scaler.fit_transform(test_data.reshape(1, 6))
# Prediction.
pred_onx = sess.run([label_name], {input_name: test_data.astype(numpy.float32)})[0]
print("Prediction result: {0}".format(pred_onx[0]))
我们实例化了workspace(Workspace.from_config())之后,我们将这个workspace里面的两个模型下载到本地(Model(ws,'scaler').download(exist_ok=True),Model(ws,'random-forest-classifier').download(exist_ok=True)),对于测试数据test_data,我们首先对它进行归一化(scaler.fit_transform(test_data.reshape(1, 6))),然后输入到训练好的onnx模型中(sess.run([label_name], {input_name: test_data.astype(numpy.float32)})[0]),最后得到结果pred_onx。需要确保整个流程没有问题,并且得到的输出是我们预期的,然后再往下走。
3 准备入口脚本(entry script)
入口脚本接收提交到已部署Web服务的数据,并将此数据传递给模型。然后,其将模型的响应返回给客户端。这里,score.py就是我们所说的入口脚本。一般需要在score.py中完成两项操作:
- 加载模型(使用名为
init()的函数):下载所需的模型,并将其反序列化为变量以用于预测 - 对输入数据运行模型(使用名为
run()的函数)
init()函数的代码如下:
def init():
'''
下载所需的模型,并将其反序列化为变量以用于预测
'''
global model, scaler, input_name, label_name, inputs_dc, prediction_dc
# AZUREML_MODEL_DIR is an environment variable created during service deployment.
# You can use this environment variable to find the location of the deployed model(s).
scaler_path = os.path.join(os.getenv('AZUREML_MODEL_DIR'), 'scaler/3/scaler.pkl')
# deserialize the model file back into a sklearn model
scaler = joblib.load(scaler_path)
model_onnx = os.path.join(os.getenv('AZUREML_MODEL_DIR'), 'random-forest-classifier/5/rf.onnx')
# print(os.listdir(model_onnx))
# 使用onnxruntime.InferenceSession("test.onnx")为模型创建一个推理会话。
model = onnxruntime.InferenceSession(model_onnx, None)
input_name = model.get_inputs()[0].name
label_name = model.get_outputs()[0].name
'''
variables to monitor model input and output data
The ModelDataCollector class enables you to define a data collector for your models in
Azure Machine Learning AKS deployments. The data collector object can be used to collect
model data, such as inputs and predictions, to the blob storage of the workspace. When
model data collection is enabled in your deployment, collected data will show up in the
following container path as csv files:
/modeldata/{workspace_name}/{webservice_name}/{model_name}/{model_version}/{designation}/{year}/{month}/{day}/{collection_name}.csv
'''
inputs_dc = ModelDataCollector("Support vector classifier model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"])
prediction_dc = ModelDataCollector("Support vector classifier model", designation="predictions", feature_names=["weatherprediction"])
run()函数的代码如下:
@input_schema('data', NumpyParameterType(np.array([34.927778, 0.24, 7.3899, 83, 16.1000, 1])))
@output_schema(NumpyParameterType(np.array([0])))
def run(data):
try:
# fit_transform()先拟合数据,再标准化,比如:ss = StandardScaler(),X_train = ss.fit_transform(X_train)
data = scaler.fit_transform(data.reshape(1, 6))
inputs_dc.collect(data)
# model inference
result = model.run([label_name], {input_name: data.astype(np.float32)})[0]
# this call is saving model output data into Azure Blob
prediction_dc.collect(result)
except Exception as e:
result = 'error'
prediction_dc.collect(result)
return result.tolist()
4. ACI:准备推理配置(inference configuration)和部署配置(deployment configuration)
推理配置描述了初始化 Web 服务时要使用的 Docker 容器和文件。 在部署 Web 服务时,源目录(包括子目录)中的所有文件都将经过压缩并上传到云端。在测试阶段,我们使用Azure Container Instance (ACI),将所有环境以及服务“封装”其中。
Environment(name="myenv")
#env = Environment.get(workspace=ws, name="AzureML-Minimal")
env = Environment.get(workspace=ws, name="AzureML-Minimal").clone('myenv')
for pip_package in ["numpy", "onnxruntime", "joblib", "azureml-core", "azureml-monitoring", \
"azureml-defaults", "azureml-model-management-sdk", "azureml-model-management-sdk", \
"scikit-learn==0.24.2", "inference-schema", "inference-schema[numpy-support]"]:
env.python.conda_dependencies.add_pip_package(pip_package)
inference_config = InferenceConfig(entry_script='score.py', environment=env)
部署配置指定运行 webservice 所需的内存和核心数。
deployment_config = AciWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1, collect_model_data=True)
5. ACI:部署机器学习模型为Web服务
将模型model1和model2装载到变量后,我们将继续将它们部署为Web服务。我们使用Model.deploy()函数,在ACI上将装载的模型部署为Web服务
model1 = Model(ws, 'scaler')
model2 = Model(ws, 'random-forest-classifier')
service_name = 'weather-aci-prediction'
service = Model.deploy(
ws,
service_name,
models=[model1, model2],
inference_config=inference_config,
deployment_config=deployment_config,
overwrite=True)
service.wait_for_deployment(show_output = True)
'''
enable Azure Application Insights
Application Insights 是 Azure Monitor 的一项功能,此功能提供可扩展应用程序性能管理 (APM)
和实时 Web 应用监视。
'''
service.update(enable_app_insights=True)
需要注意,service_name即Enpoints的名字。所以如果我们需要新建一个Endpoints,那么这个service_name不能和之前的重复。另外,Model.deploy这个函数跑起来比较慢,大概要10分钟。如果过了很长时间,比如20分钟,还没有出结果,那么建议重新换一个service_name名字,然后重跑一遍。如果部署成功,terminal中会有类似记录:
Tips: You can try get_logs(): https://aka.ms/debugimage#dockerlog or local deployment: https://aka.ms/debugimage#debug-locally to debug if deployment takes longer than 10 minutes.
Running
2022-03-23 14:41:47+00:00 Creating Container Registry if not exists.
2022-03-23 14:41:47+00:00 Registering the environment.
2022-03-23 14:41:47+00:00 Use the existing image.
2022-03-23 14:41:47+00:00 Generating deployment configuration.
2022-03-23 14:41:48+00:00 Submitting deployment to compute.
2022-03-23 14:41:52+00:00 Checking the status of deployment weather-aci-prediction15..
2022-03-23 14:44:01+00:00 Checking the status of inference endpoint weather-aci-prediction15.
Succeeded
ACI service creation operation finished, operation "Succeeded"
Healthy
service.get_logs()很有用。如果部署失败,或者以后调用失败,会有对应的日志记录,使用这条命令就可以返回这些日志。
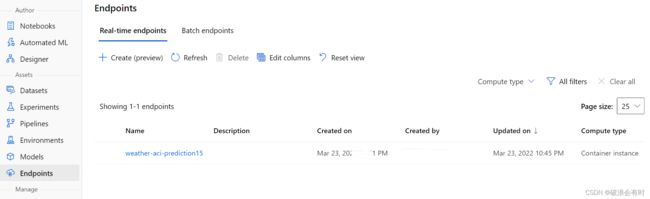
在Azure Machine Learning Workspace中,我们在EndPoints中发现这个新建的记录:
6. ACI:调用模型
我们可以通过service.run调用这个服务,输入的是一个json格式的变量。理论上,这里的输出output和在本地验证模型的结果是一样的。
input_payload = json.dumps({
'data': [[34.927778, 0.24, 7.3899, 83, 16.1000, 1016.51, 1]],
})
# Run function in score.py
output = service.run(input_payload)