word2vec是如何得到词向量的?
前言
word2vec是如何得到词向量的?这个问题比较大。从头开始讲的话,首先有了文本语料库,你需要对语料库进行预处理,这个处理流程与你的语料库种类以及个人目的有关,比如,如果是英文语料库你可能需要大小写转换检查拼写错误等操作,如果是中文日语语料库你需要增加分词处理。这个过程其他的答案已经梳理过了不再赘述。得到你想要的processed corpus之后,将他们的one-hot向量作为word2vec的输入,通过word2vec训练低维词向量(word embedding)就ok了。不得不说word2vec是个很棒的工具,目前有两种训练模型(CBOW和Skip-gram),两种加速算法(Negative Sample与Hierarchical Softmax)。本答旨在阐述word2vec如何将corpus的one-hot向量(模型的输入)转换成低维词向量(模型的中间产物,更具体来说是输入权重矩阵),真真切切感受到向量的变化,不涉及加速算法。如果读者有要求有空再补上。
1 Word2Vec两种模型的大致印象
刚才也提到了,Word2Vec包含了两种词训练模型:CBOW模型和Skip-gram模型。
CBOW模型根据 中心词W(t)周围的词来预测中心词
Skip-gram模型则根据 中心词W(t)来预测周围词
抛开两个模型的优缺点不说,它们的结构仅仅是输入层和输出层不同。请看:
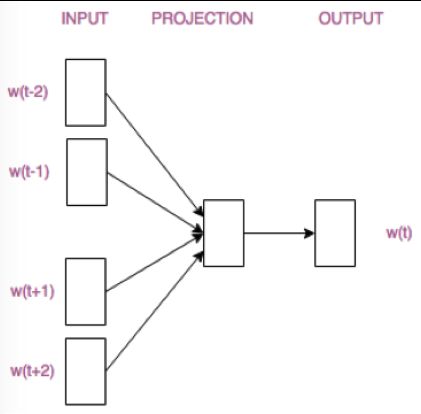
CBOW模型
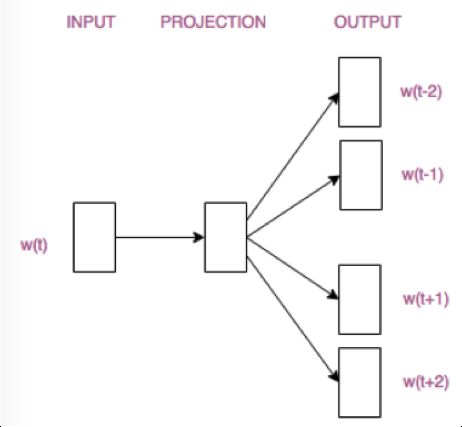
Skip-gram模型
这两张结构图其实是被简化了的,读者只需要对两个模型的区别有个大致的判断和认知就ok了。接下来我们具体分析一下CBOW模型的构造,以及词向量是如何产生的。理解了CBOW模型,Skip-gram模型也就不在话下啦。
2 CBOW模型的理解
其实数学基础及英文好的同学可以参照斯坦福大学Deep Learning for NLP课堂笔记。
当然,懒省事儿的童鞋们就跟随我的脚步慢慢来吧。
先来看着这个结构图,用自然语言描述一下CBOW模型的流程:
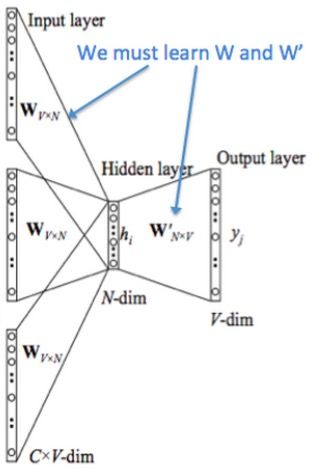
CBOW模型结构图
NOTE:花括号内{}为解释内容.
- 输入层:上下文单词的onehot. {假设单词向量空间dim为V,上下文单词个数为C}
- 所有onehot分别乘以共享的输入权重矩阵W. {V*N矩阵,N为自己设定的数,初始化权重矩阵W}
- 所得的向量 {因为是onehot所以为向量} 相加求平均作为隐层向量, size为1*N.
- 乘以输出权重矩阵W' {N*V}
- 得到向量 {1*V} 激活函数处理得到V-dim概率分布 {PS: 因为是onehot嘛,其中的每一维斗代表着一个单词},概率最大的index所指示的单词为预测出的中间词(target word)
- 与true label的onehot做比较,误差越小越好
所以,需要定义loss function(一般为交叉熵代价函数),采用梯度下降算法更新W和W'。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的词向量(word embedding),这个矩阵(所有单词的word embedding)也叫做look up table(其实聪明的你已经看出来了,其实这个look up table就是矩阵W自身),也就是说,任何一个单词的onehot乘以这个矩阵都将得到自己的词向量。有了look up table就可以免去训练过程直接查表得到单词的词向量了。
这回就能解释题主的疑问了!如果还是觉得我木有说明白,别着急!跟我来随着栗子走一趟CBOW模型的流程!
3 CBOW模型流程举例
假设我们现在的Corpus是这一个简单的只有四个单词的document:
{I drink coffee everyday}
我们选coffee作为中心词,window size设为2
也就是说,我们要根据单词"I","drink"和"everyday"来预测一个单词,并且我们希望这个单词是coffee。
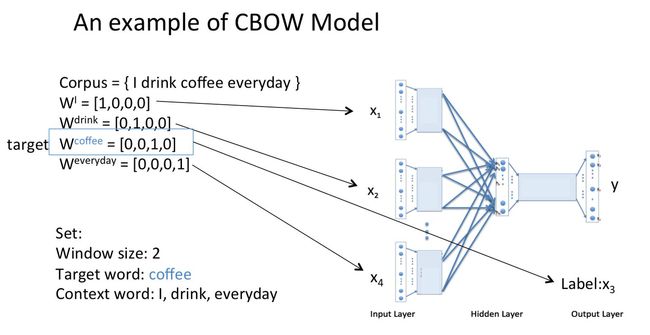
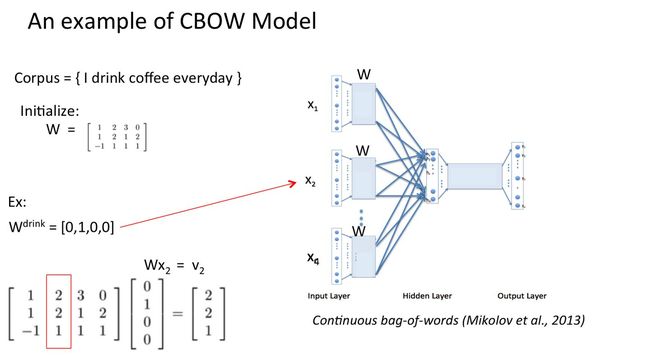
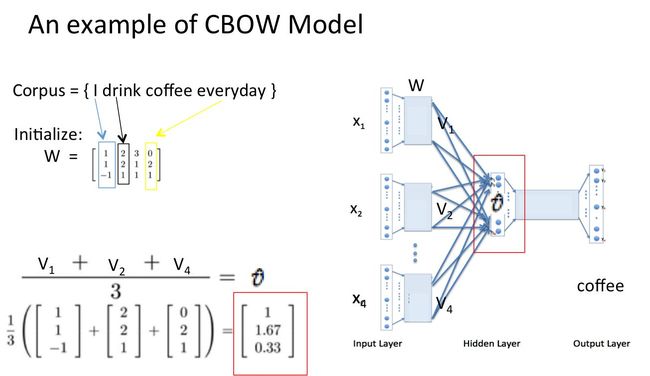
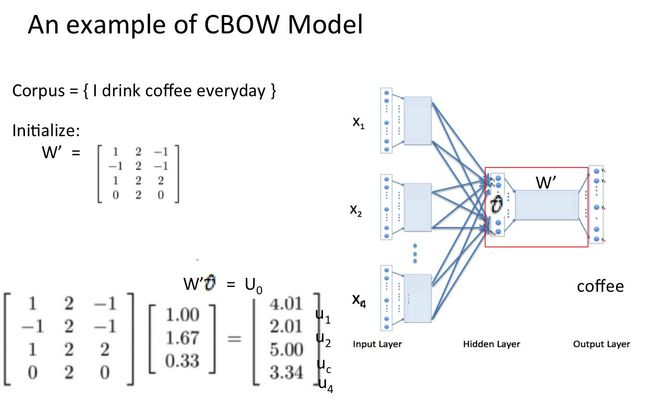
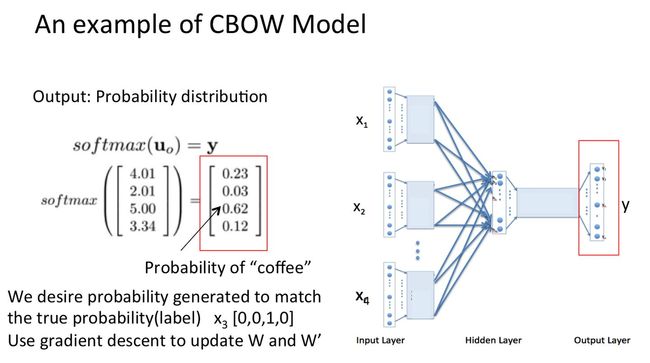
假设我们此时得到的概率分布已经达到了设定的迭代次数,那么现在我们训练出来的look up table应该为矩阵W。即,任何一个单词的one-hot表示乘以这个矩阵都将得到自己的word embedding。
如有疑问欢迎提问。
编辑于 2017-12-25
赞同 907158 条评论
分享
收藏喜欢收起
继续浏览内容

知乎
发现更大的世界
打开

Chrome
继续

斤木
PhD candidate@EdinburghNLP
87 人赞同了该回答
谢邀。这个问题没那么复杂,不用谈word2vec实现上的各种细枝末节。
--“后者的输入就貌似已经是词向量了”
-- 没错。
-- 输入?输入哪里来的词向量?
-- 随机初始化。
-- 但词向量不是模型训练的任务么?怎么变成了输入?好奇怪?
-- 词向量一般不是模型训练的任务,而是为完成任务顺带得到的附属品。就像90年代很多男生为了追女生而学吉他,出发点并不是自己热爱艺术,但也顺带提升了艺术气质,甚至留起了飘逸的长发:) 词向量是在训练过程中和模型参数一起被优化的。
-- 什么,输入也能优化?
-- 对。CBOW也好,Skip-gram也好,还是各种各样其他NNLM也好,简单来看,不过是模型任务的区别。通过建模,每个词与其上下文建立了联系;通过训练,参数和输入得到优化。最终,在实现损失函数minimization的同时,得到一份饱含semantic properties的词向量。
很简单吧 :)
编辑于 2016-07-23
赞同 8714 条评论
分享
收藏喜欢
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

Kizunasunhy
Life's about experience.
107 人赞同了该回答
确实,网上的很多资料好像并没有在一开始就阐明这个“词向量”到底是怎么来的,也有可能是简短说了一下但是并没有引起我们的注意,导致我们会问“生成的向量到底在哪儿呀”。那么word2vec向量到底在哪儿?其实这些词向量就是神经网络里的参数,生成词向量的过程就是一个参数更新的过程。那么究竟是什么参数呢?就是这个网络的第一层:将one-hot向量转换成低维词向量的这一层(虽然大家都不称之为一层,但在我看来就是一层),因为word2vec的输入是one-hot。one-hot可看成是1*N(N是词总数)的矩阵,与这个系数矩阵(N*M, M是word2vec词向量维数)相乘之后就可以得到1*M的向量,这个向量就是这个词对应的词向量了。那么对于那个N*M的矩阵,每一行就对应了每个单词的词向量。接下来就是进入神经网络,然后通过训练不断更新这个矩阵。这个部分在网上的资料里经常被简略的概括,输出层一般是重点解释的对象,所以需要仔细地理清这个思路。有了这个概念之后再去看word2vec网络具体是怎么实现的,就会容易很多。
发布于 2016-11-17
赞同 10721 条评论
分享
收藏喜欢
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续
 AppsFlyer
AppsFlyer
广告
不感兴趣知乎广告介绍
准备好应对iOS14 隐私新规带来的归因挑战了么?听听专家怎么说
Apple最新的隐私政策生效后,SKAdNetwork价值最大化将成为行业新挑战!AppsFlyerSK360系列新产品正式上线,突破SKAdNetwork局限,以丰富的衡量维度获取数据洞察,保护您的iOS端广告不受移动作弊的侵袭,实现持续增长查看详情

Multiangle
什么都感兴趣
68 人赞同了该回答
不请自来~。从文本语料得到词向量的话,大概来讲有如下几个步骤:分词,统计词频,构建huffman树,输入文本训练词向量
第一步是分词。英文要好一些,单词之间有空格分隔,但是需要进行词干提取和词形还原预处理。中文的话,分词就要麻烦的多。我但是用的是jieba来进行分词的。
第二步骤,统计词频。首先统计出每个单词出现的次数,然后需要去掉停用词,非常高频的词和非常低频的词。去掉高频词是因为没有特殊性,去掉低频词是因为没有普适性
第三步,构建huffman树。所有的非叶节点存储有一个参数向量,所有的叶节点分别代表了词典中的一个词。参数向量初始值为0。构建完huffman树之后,将对应的huffman码分配给每个单词。此外,还需要随机初始化每个单词的词向量。
第四部,训练,也就是提到的比较多的CBOW和skip-gram模型了。word2vec采用的语言模型是n-gram模型+词袋模型(我不知道这样表述严不严谨),也就是说假设一个单词只与周围若干个单词有关且不考虑单词间的顺序关系。
CBOW中训练集的输入是周围几个单词的词向量之和,输出是中间那个单词。从根节点开始,沿着huffman树不停地进行logistic分类,每进行一次分类就沿着Huffman树往下一层并更正词向量,直到最后达到叶节点。(还记得之前提到过单词的huffman码吗,就是为每一层分类提供依据的,如果是1,则表示应当分到左节点,否则表示应当分到右节点,当然也可以反过来)
skip-gram模型与CBOW相反,输入是中间那个单词,输出是周围的单词。
主要就是这四个步骤了。另外word2vec中还有许多细节上有优化,比如对高频词按概率删除,自适应学习率,sigmoid的近似计算等等,就不详述了
发布于 2016-05-25
赞同 6821 条评论
分享
收藏喜欢
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

文兄
机器学习话题下的优秀答主
15 人赞同了该回答
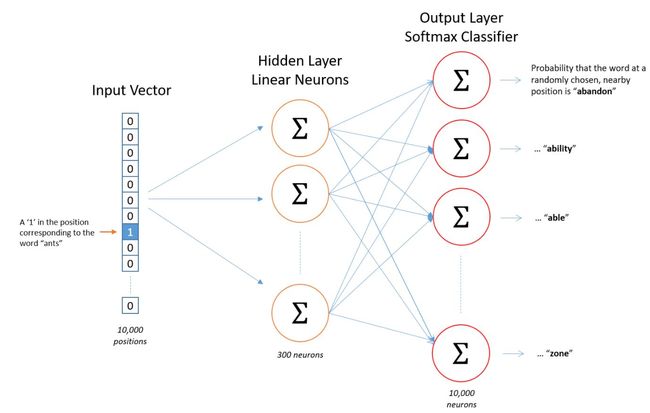
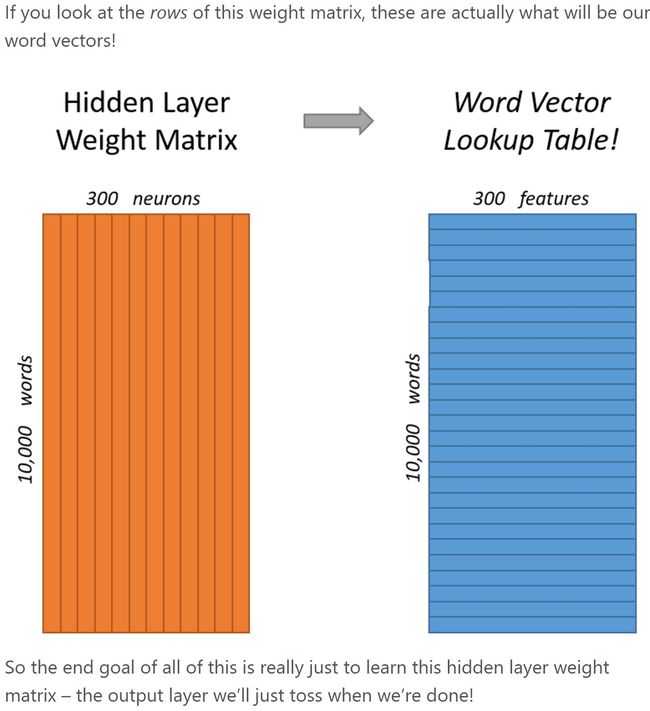
其实词向量就是训练神经网络时候的隐藏层参数或者说矩阵。
发布于 2017-09-03
赞同 15添加评论
分享
收藏喜欢收起
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

郑哲东
计算机科学博士在读
33 人赞同了该回答
其实原理上就是两层神经网络。用输入词去预测邻近的词。比如,如果你给出一个词苏联(Soviet),那么概率很高的输出 应该是 联合(Union)和俄罗斯(Russia)而不是西瓜或者袋鼠。通过这样的训练,我们最后把output layer去掉,就提取中间300维的特征,这就是我们要的word vector了。
那么什么词有相同的上下文(邻近的词)? 比如一些近义词 smart 和intelligent 再比如 一些相关的词 engine 和 transmission。这些词的word vector 就很接近。
推荐文章:Word2Vec Tutorial - The Skip-Gram Model
我自己在csdn上做了中文的翻译:Word2Vec教程 - Skip-Gram模型
如果想进一步了解,如何提高训练效率的trick,可以看关于Negative Sampling:Word2Vec教程(2)- Negative Sampling
最后感谢大家看完~欢迎关注分享点赞~也可以check我的一些其他文章
郑哲东:用CNN分100,000类图像zhuanlan.zhihu.com 郑哲东:NVIDIA/悉尼科技大学/澳洲国立大学新作解读:用GAN生成高质量行人图像,辅助行人重识别zhuanlan.zhihu.com
郑哲东:NVIDIA/悉尼科技大学/澳洲国立大学新作解读:用GAN生成高质量行人图像,辅助行人重识别zhuanlan.zhihu.com 郑哲东:利用Uncertainty修正Domain Adaptation中的伪标签zhuanlan.zhihu.com
郑哲东:利用Uncertainty修正Domain Adaptation中的伪标签zhuanlan.zhihu.com
编辑于 2020-05-13
赞同 334 条评论
分享
收藏喜欢
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

知乎用户
49 人赞同了该回答
看到这句“而后者的输入就貌似已经是词向量了”我猜题主真正想问的应该是“最初的词向量是哪来的”,因为对于这个问题我曾经也纠结了很久。
所以现在我来从实际的代码出发解释一下,我用的pytorch,用Keras或者TF的老铁可以自行查阅各自的框架API。
首先我们把语料读进来,然后要把作为文本信息的语料,转换为可以进行数学计算的数字形式。我们首先要统计语料中的所有词语(如果是中文的话还要先进行分词处理),然后建立一个字典,让每一个词语都唯一对应一个数字ID,最后再把每一句话都变成跟词语一一对应的一串数字ID,这个过程叫做tokenization,一般翻译成“标记化”或者“令牌化”。
配合pytorch使用,有一个库叫torchtext,可以完成这个操作:
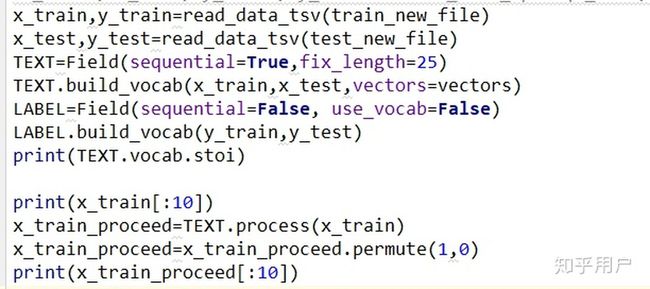
输出结果差不多是这样:
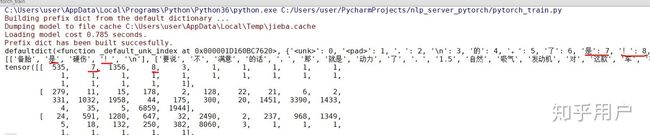
第一行那个defaultdict输出的是torchtext工具生成的字典,字典的key是词,value是对应的数字ID。
下面是输出的原始语料和tokenization之后的语料,可以看到第一个语料“备胎是硬伤!”,这里面“是”的ID为7,“!”(中文感叹号)的ID是8,然后下面经过tokenization的第一句话,对应这两个词的数字ID恰好也是7和8。
字典里的
然后在搭建模型的过程中,我们可以直接使用已经定义好的常见神经网络层——其中有一种embedding层,就是我们所说的词嵌入层。
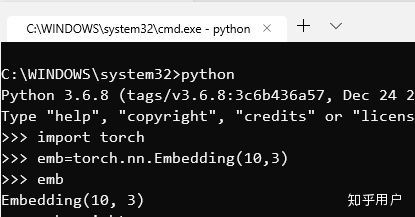
Embedding层的参数,是一个L X D大小的矩阵——L是上一步生成的词典的长度,d是词向量的维度。Embedding层接受数字作为输入,然后返回数字所对应的矩阵列下标的向量。
比如我们输入[0,1,2],Embedding层就会返回矩阵的第0列、第1列和第2列的列向量——实际返回的是这三个列向量拼成的一个3 X D大小的矩阵:
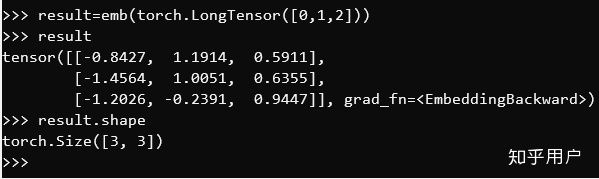
于是让我们回到最初的问题——“最初的词向量是哪来的”,这个Embedding层里已有的“词向量”数字是怎么出现的呢?
其实答案很简单:
瞎JB填的。
简单地说,包括Embedding层在内,torch.nn里提供的所有常用的神经网络层,刚建立的时候里面的参数都是随机生成的一堆没什么意义的随机数。
当然呢,我们也不能真的瞎JB填,具体怎么对模型参数进行初始化,也是有讲究的——不过这里我们先不讨论这些,继续往下看。
然后就是对模型进行训练了。有一点你一定要明确,词向量参数是瞎JB填的,完全不影响模型按照Skip-gram或者CBOW的方法来进行相应的计算。当然呢,计算出来的结果,就跟正确答案差得远了——所以我们才要用真实语料对模型进行训练。
具体的训练过程其他答案和网上的文章已经讲得非常清楚了,我就不再废话了——简而言之,通过真实语料的词与词之间的共现关系,计算出你现在的瞎JB填参数的模型错的有多离谱,也就是损失函数,然后对损失函数进行求导,通过反向传播求出你一开始瞎JB填的各个词向量参数的导数,然后更新这些参数的值。
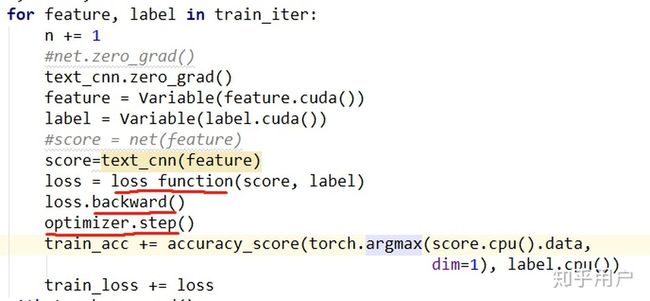
在pytorch里,训练的过程差不多是这样的:首先用模型进行一次预测,得到result,然后用损失函数(可以是事先定义好的,也可以是你自己写的)计算loss的值,再对loss进行求导,最后让事先准备好的优化器(现在比较常用的是Adam)根据求出的导数更新模型参数。pytorch已经实现了自动求导和反向传播,你直接调loss的backward方法就可以了:
这样一来,经过大量语料训练之后,你的Embedding层就已经是比较准确的词向量了。当然目前我们一般不会直接用自己的语料训练词向量,而是使用别人在超大量语料库上训好的词向量,直接用这些现成的词向量进行下游任务。除了w2v之外,比较常用的还有GloVe。至于ELMo和BERT,它的原理就跟w2v完全不同了,这个需要单独学习。
现在你明白了吗?
编辑于 2019-08-25
赞同 496 条评论
分享
收藏喜欢收起
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

li Eta
机器学习话题下的优秀答主
17 人赞同了该回答
谢邀。
参考这三个回答:
有谁可以解释下word embedding? - li Eta 的回答
有没有详细讲解word2vec的原理、具体应用、中文处理 方面的资料或教程? - li Eta 的回答
Skip-gram如何训练得到词向量( Distributed Representation)? - li Eta 的回答
编辑于 2016-05-24
赞同 17添加评论
分享
收藏喜欢
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续
知乎用户
26 人赞同了该回答
可以通过源码+数学原理结合的方式去探究一下。
在 github 找到一个有注释的源码,以及博客园和 CSDN 上两位大神分享的很不错的博文。
- word2vec 中的数学原理详解(作者:peghoty 完整看完对理解w2v很有帮助)
- 附带注释的 word2vec 源码(作者:chenbjin)
- word2vec源码解析(作者:google19890102)
word2vec顾名思义嘛,它的输出模型实际上就是:词和向量的映射关系 。
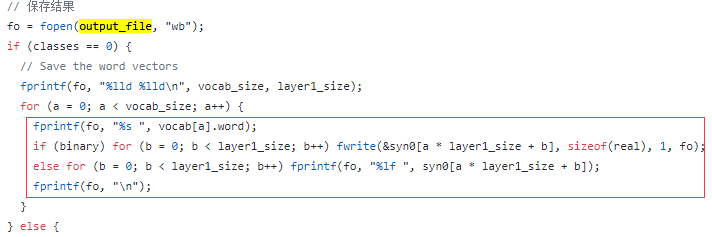
所以可以重点了解一下 syn0 这个数组(这里其实是把一个词*向量的矩阵转换为一个一维数组表示)是怎么得到的。
以基于 Hierarchical Softmax 的 cbow 模型为例,首先介绍一下它的模型网络结构。
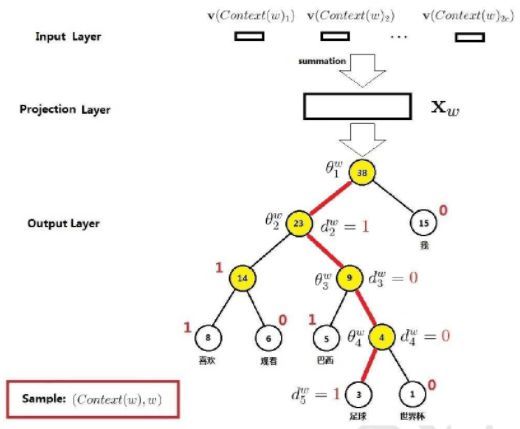
如图,该模型有三层结构构成:
- 输入层是当前词和它的相邻位置单词的向量
- 投影层是将输入矩阵映射一个向量(对应维度加和求平均)
- 输出层是一颗霍夫曼树(树中的叶子节点就是每个词,高频词到根节点的路径相对较短,词到根节点也只有一条路径,每一个中间节点就是一个 sigmoid 单元)
其中输出层是一颗二叉树,从根节点到指定词会经过多个中间节点。
每经过一个中间结点,其实就是一次二分类(sigmoid ),每个词到达根节点路径中的节点都会有一个对应的权重向量。
所以模型训练就是找到这个合适的权重向量,使得根节点到指定词的发生的概率最大,也就是 p(w|Context(w)) 最大。中间节点的权重向量求得之后,就可以知道原始词的向量了!
实际上,word2vec 求解模型的过程中用到的是梯度上升法,每输入一个样本就会刷新一遍相关的参数向量,直至所有样本读取完毕。
然后,简单来说一下源码中词向量(源码中对应 syn0)的训练步骤。
- 读取语料,统计词频信息
- 构建词典,并初始化霍夫曼树以及随机初始化每个词的对应向量(维度默认是200)
- 以行为单位训练模型(输入文件都在一行上,会按照最大1000个词切割为多行)
- 获取当前行中的一个输入样本(当前词向量以及相邻几个的词的词向量)
- 累加上下文词向量中每个维度的值并求平均得到投影层向量X(w)(neu1)
- 遍历当前词到根节点(输出层的霍夫曼树)经过的每个中间节点
- 计算中间节点对应的梯度 g * 学习速率(与中间节点的权重向量 syn1 和投影层向量 neu1 相关)
- 刷新投影层到该中间节点的误差向量(与梯度和中间节点向量相关)
- 刷新中间结点向量(与梯度和投影层向量相关)
- 刷新上下文词向量(其实就是将误差向量累加到初始向量中)
至于梯度值具体是如何求解的,简单来说就是得到对于整个模型的目标函数,然后对对应的随机变量求分导(废话...)。
具体的公式推导在peghoty 大神的博文word2vec 的数学原理 中已经有了很详细的说明,真的非常详细,完整看完对理解 word2vec 会有非常大的帮助!!!
没了......
编辑于 2017-09-13
赞同 268 条评论
分享
收藏喜欢收起
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

阿北
微软程序员,算法专家。公众号:Hello阿北
12 人赞同了该回答
word2vec有两种训练模型:CBOW模型和Skip-gram模型。CBOW模型根据上下文的词来预测中心词,而Skip-gram模型正好相反,根据中心词来预测上下文的词。
这里以CBOW模型来说明如何得到词向量。(Skip-gram训练过程原理类似)
假设我们现在的词典D={我,喜欢,到处,旅游}。在一次模型训练中,中心词为"喜欢",窗口大小为2,则上下文为"我"、"到处"、"旅游"。
CBOW模型训练过程
结合视频演示,CBOW的训练过程如下:
Step 1. 得到上下文词的onehot向量作为输入,同时得到预期的输出onehot向量(这个用来最后计算损失函数)。
Step 2. 输入层每个词的onehot与权重矩阵W相乘,得到对应的向量。(其实这就是对应词的词向量,矩阵的参数是网络通过训练得到的)。
Step 3. 将得到的三个向量相加求平均,作为输出层的输入。
Step 4. 将向量与输出层的权重矩阵U相乘,得到输出向量。
Step 5. 将softmax作用于输出向量,得到每个词的概率分布。
Step 6. 通过损失度量函数(如交叉熵),计算网络的输出概率分布与预期输出onehot向量的之间损失值。通过这个损失值进行反向传播,更新网络参数。
经过上述步骤的多次迭代后,矩阵W就是词向量矩阵,每个词通过onehot查询词向量矩阵就能得到其对应的词向量。
在实际应用中,word2vec会采用层次softmax和负采样方法优化训练过程,具体可参考:word2vec 中的数学原理详解
编辑于 2020-05-23
赞同 123 条评论
分享
收藏喜欢收起
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

shirley
暂无。
5 人赞同了该回答
发现上面的回答比较偏向于训练语言模型的网络结构,由于自己在开始看word2vec的时候也存在这样的疑问,所以试着从非技术细节方面回答一下,希望能帮到同样存在疑惑的刚入门的同学。
首先必须明确的是,word2vec的词向量(也就是论文里的word embedding)是基于某个特定语料的,单独拿出任一个词向量都没有什么意义,它的作用在于众多词向量之间的相对差异所表现出来的语义表达。
(1)关于向量的维数。这是事先设定的,这个值至于是多少目前并没有很严格的理论依据,如果你自己运行word2vec源码你自己设100,200都是可以,当然得到的词向量在做具体的NLP任务(比如题主说的文本聚类任务)时是效果也是会有差异的,可以多设几次,哪次效果好你就选哪个维数,而300这个常用数值也是mikovo在论文里提到的。有个专门的问题探讨这个维数值设计embedding维数的时候有什么讲究? - 知乎
(2)关于向量各元素值。正如上面某同学提到初始值是随机的,然后以语料中哪几个词离得近让这两个词对应的词向量的距离越近为目标不断地修改向量各元素值,从这个角度来看,实际上就是迭代过程。至于怎么迭代的,如何迭代这个修改过程就要提到神经语言模型了,如果想研究的话入门论文我建议yoshua bengio的 A Neural Probabilistic Language Model ,整篇论文娓娓道来,很详细也很容易懂,另外还有Mikovo的2013系列,再有时间甚至word2vec的源码也可以拿来研究一下。其他的辅助资上面的回答已经给出很好的材料了,我就不多赘述了。
希望有所帮助 :)
编辑于 2017-06-06
赞同 54 条评论
分享
收藏喜欢
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续

gggctgg
机器学习
7 人赞同了该回答
参考斋藤康毅的书《深度学习入门2自然语言处理篇》,这本书还没翻译成中文版,但写的很详细,首先介绍了one-hot编码,假设你的文本总共有100个词汇,那就用一个100维的矢量来表示一个词,其中的一维数字为1,其他维是0(这也叫稀疏的表示,仅有一维有实际的信息),这样就得到了最简单的一种用矢量表示单词的方法,然而这种方法有缺陷,就是词汇越多,维数越多,计算量也越大。我们希望用较低维的矢量来表示每个单词,这就是embedding的方法,embedding里表示每一个单词的维数比one-hot要小,而且每一维都表示了单词的某种内在特性,这种特性人类可能难以理解,但又是确实存在的。学习embedding的表达应该怎么做呢?首先你要知道一个单词的意思是由它的上下文(context,你可以理解为在它前后的单词)决定的,为了简单起见,我们假设一个单词(target)的意思可由它前一个单词(input1)和后一个单词(input2)决定(这里的target,input1,input2都是单词对应的one-hot编码矢量,而且是行矢量,元素数等于词汇数n),我们来训练这么一个神经网络,输入input1和input2,input1和input2分别乘以同一个矩阵w1(w1的行数等于n,列数是自己定的一个远小于词汇数的数m),得到两个相同维数的行矢量,这两个矢量相加取平均得到中间层行矢量(这一过程是encoder),这个行矢量的维数是m,表示被压缩进m维空间里的input1和input2的综合信息(具体每一维表示什么信息人类并不理解),我们再把这个中间层行矢量乘以另一个矩阵w2(w2的行数为m,列数为n),得到一个输出output(n维行矢量,这一过程是decoder),这个output我们希望它跟target越像越好,因此通过不断训练更新w1和w2,最终我们可以得到这样一个网络。此时w1和w2里就储存了我们想要的词编码信息,w1的第i行和w2的第i列都可用来表示one-hot里第i个单词,大多数用w1的第i行(m维行矢量)来表示,你也可以w1的i行与w2的i列的转置加起来取平均来表
发布于 2019-10-21
赞同 7添加评论
分享
收藏喜欢
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续
 扇贝编程
扇贝编程
广告
不感兴趣知乎广告介绍
0基础学python,4天快速上手,保姆级指导
0基础可学,4天即可入门,趣味学习方式,告别加班,告别低薪,你的同事都在学了,你还在等什么?查看详情

陈君
5 人赞同了该回答
word2vec(2013年)以一种更加高效的方式训练表征语义信息的词向量。常见采用三层网络结构:输入层、单层隐藏层、输出层。训练流程包含CBOW和skip-gram
CBOW的训练过程
CBOW每一轮是以上下文词语作为输入,去训练拟合得到中心词。词汇表大小设为V,CBOW的单次迭代过程如下:
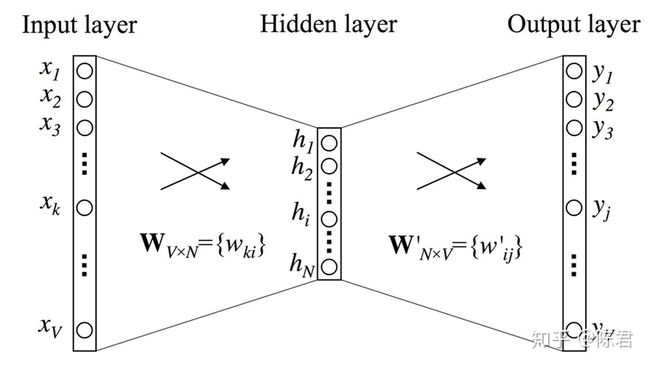
图1 只有一个上下文词语的简易版CBOW模型
- 选定中心词,将中心词前后位置的词作为这一轮模型迭代输入信息,信息输入格式是上下文词语的one-hot格式编码。问题简化一下,假设就选中心词的上一个词作为上下文词。那么输入的数据是一个shape=(1,V)的input vector。
- 输入层和隐藏层之间的权重矩阵标记为W。input vector乘W就得到了隐藏层状态hidden vector,shape=(1, N),在隐藏层中不需要做任何其他操作。从输入层到隐藏层的数据流向其实就是输入的上下文词在输入权重W中找到对应的embedding向量。
- 隐藏层和输出层之间的权重标记为W'。hidden vector乘W',然后再使用softmax激活函数。输出层输出的是大小为V的softmax概率向量。
- 参数优化过程常用交叉熵作为损失函数。通过反向传播算法更新W和W'。
一轮的训练过程是这样的,而接下来就接着选择另外一个中心词,重复步骤1~4不断更新W和W'。细心的同学已经发现输入权重矩阵W就是所有词向量的集合,每一行对应着一个词。
Q:如果是每次训练选定多个上下文词语该怎么训练?跟前面会有什么不同嘛?
A:没有不同,只是在隐藏层处理的时候,将多个上下文词的对应向量(输入权重权重矩阵的某几行)做平均计算即可,其他同理。
Skip-gram的训练过程
skip-gram每一轮训练是将中心词作为输入,去训练拟合得到上下文词。单次迭代过程如下:
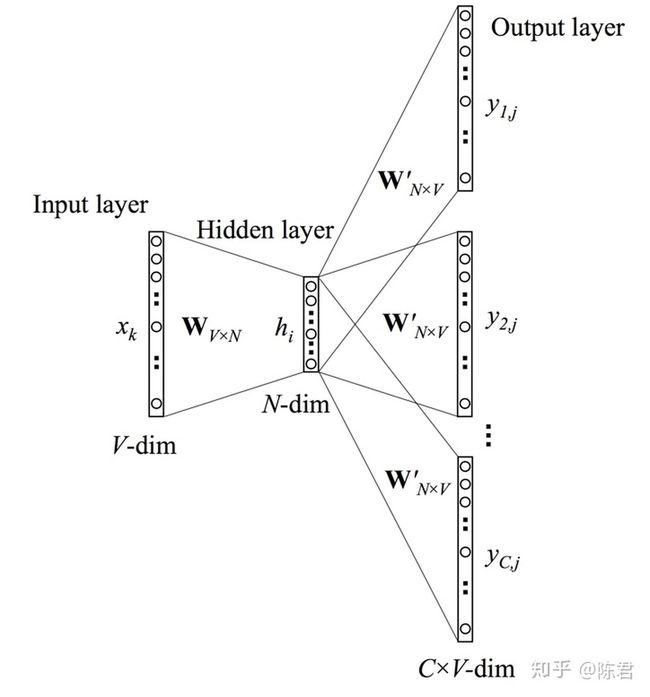
图2 skip-gram模型
- 输入层:选定中心词,输入中心词的one-hot编码;
- 输入层=>隐藏层:输入层到隐藏层之间同样设有输入层权重矩阵W,shape=(V, N)。中心词的one-hot乘W,得到此时中心词对应的向量表示h,shape=(1, N);
- 隐藏层=>输出层:这里要手动敲黑板~图2中的结构是经典的网络结构画法,却容易给人带来费解:”为什么一次训练中的隐藏层向量h,可以同时输出多个shape=(1, V)的softmax概率向量”。其实skip-gram在训练W和W'的时候一次输入和输出都只有一个词。从网络结构上来看skip-gram和CBOW是一样的,只是中心词和上下文词的输入输出顺序颠倒了一下。所以一次迭代应该拆分成多对“中心词-上下文词”的单独训练过程。
重复1~3更新W和W',W就是最后的词向量集合。
CBOW和skip-gram的差异
- Skip-gram效果比CBOW好;
- Skip-gram训练时间长,但是对低频词(生僻词)效果好;CBOW训练时间短,对低频词效果比较差。
(以上结论我还没有验证过,感兴趣的同学有想法可以一起交流一下,手动笔芯~)
写在后面
说到word2vec还需要了解工程实际应用需要进行的训练优化,例如:层次softmax和负采样。
参考:
- Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013a). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and Dean, J. (2013b). Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems, pages 3111–3119.
- Xin Rong (2016). Word2vec Parameter Learning Explained.arXiv preprint arXiv:1411.2738
- Ning Lee:推荐系统从零单排系列(五)—Word2Vec理论与实践(下)
发布于 2020-02-07
赞同 52 条评论
分享
收藏喜欢收起
继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续
知乎用户
5 人赞同了该回答
以下是一个及其易懂的example,希望可以帮助你理解word2vec的整个过程。
强烈推荐这篇文章:Quick Notes: Useful Terms & Concepts in NLP: BOW, POS, Chunking, Word Embedding,里面以语料"I drink coffee everyday."为例,提供CBOW和Skip-gram两个模型的训练过程图,超级通俗易懂。
假设我们现在的Corpus是这一个简单的只有四个单词的document:
{I drink coffee everyday}
我们选coffee作为中心词,window size(上下文窗口大小)设为2
也就是说,我们要根据单词"I", "drink"和"everyday"来预测一个单词,我们希望这个单词是coffee

Step 1:对所有词进行one-hot编码,确定window size等一系列参数
I = [1 0 0 0]
drink = [0 1 0 0]
coffee = [0 0 1 0]
everyday = [0 0 0 1]
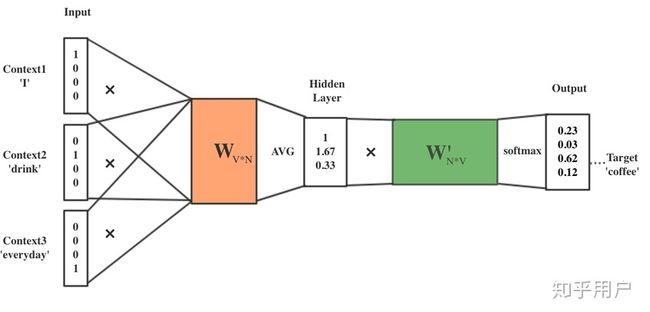
Step 2:初始化输入层到隐藏层的权重矩阵W(V行N列)
V表示语料库中词的个数,即one-hot词向量的维数是V
N表示隐藏层神经元的数量,即希望最后得到的词向量维数为N
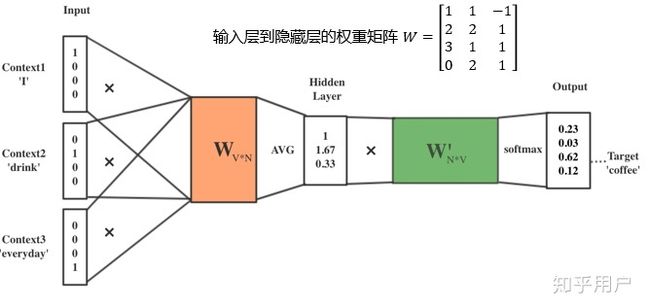
Step 3:得到每个词的词向量
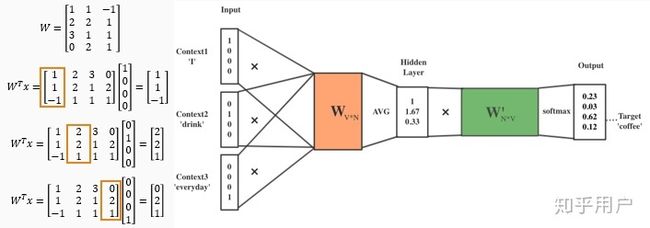
Step 4:求平均值得到隐藏层向量

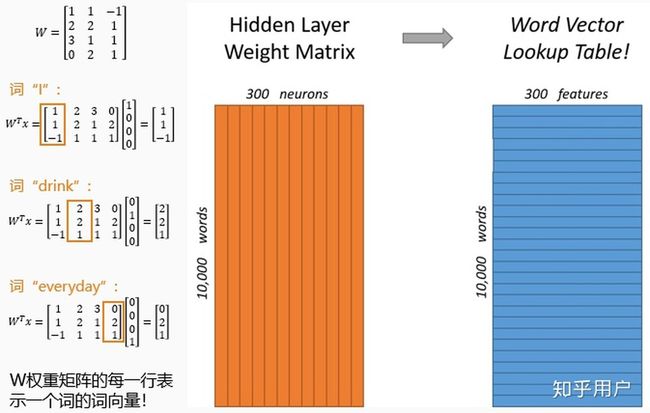
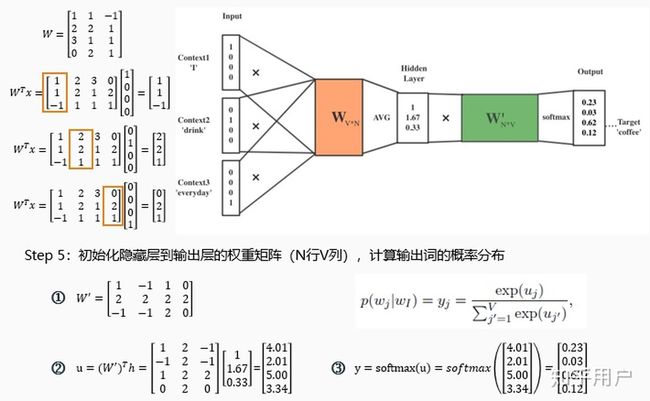
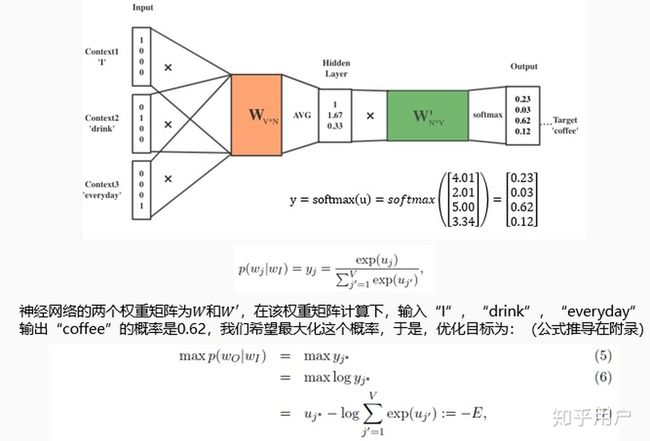
当然,源码实现是基于Negative Sampling或Hierarchical Softmax这两个优化方法的,实现不完全是上面描述所示,但是基本思想是不变的。