Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
Axis-DeepLab:用于全景分割的独立轴注意
Abstract
卷积利用局部性来提高效率,但代价是丢失长范围上下文。自我注意被用来通过非局部的相互作用来增强CNN。最近的研究证明,通过将注意力限制在局部区域来堆叠自我注意层来获得完全注意网络是可能的。在本文中,我们试图通过将二维自我注意分解为两个一维自我注意来消除这一限制。这降低了计算复杂度,并允许在更大甚至全局区域内进行注意。同时,我们还提出了一种位置敏感型自我注意设计。两者结合在一起产生了位置敏感的轴向注意力层,这是一种新的积木,人们可以将其堆叠起来,形成用于图像分类和密度预测的轴向注意力模型。我们在四个大规模数据集上验证了我们的模型的有效性。特别是,我们的模型比ImageNet上现有的所有独立自我注意模型都要好。我们的Axial-DeepLab在COCO测试开发上比自下而上的最先进水平提高了2.8%的PQ。以前的最先进技术是通过我们的小变体实现的,它的参数效率是3.8倍,计算效率是27倍。Axis-DeepLab还在地图景观和城市景观上取得了最先进的结果。
Introduction
卷积是计算机视觉中的核心构件。早期的算法使用卷积滤波器来模糊图像、提取边缘或检测特征。与完全连接的模型相比,它的效率和泛化能力在现代神经网络[47,46]中得到了很大的开发[2]。卷积的成功主要来源于两个性质:平移等价性和局部性。平移等价,虽然不是精确的[93],但很好地符合成像的性质,从而将模型推广到不同位置或不同大小的图像。另一方面,局部性减少了参数计数和M-Adds。然而,这给建立长期关系模型带来了挑战。
大量文献讨论了卷积神经网络(CNN)中长程相互作用的建模方法。有些采用扩张卷积[33,74,64,12]、更大的核[67]或图像金字塔[94,82],它们要么是手工设计的,要么是用算法[99,11,57]搜索的。另一类作品采用注意机制。注意机制在语言建模[80,85]、语音识别[21,10]和神经字幕[88]中显示了其对远程交互进行建模的能力。自那以后,人们的注意力已经扩展到视觉上,大大促进了图像分类[6]、目标检测[36]、语义分割[39]、视频分类[84]和对抗性防御[86]。这些工作丰富了CNN的非局部或远程注意模块。
最近,没有任何空间卷积的注意层堆叠模型已经被提出[65,37],并显示出令人振奋的结果。然而,简单的注意力在计算上是昂贵的,特别是在大输入的情况下。由[65,37]提出的将局部约束应用于注意,降低了成本,并使完全注意模型的建立成为可能。然而,局部约束限制了模型的接受范围,这对于分割等任务至关重要,特别是在高分辨率输入上。在这项工作中,我们建议采用轴注意[32,39],它不仅可以进行高效的计算,而且可以恢复独立注意模型中较大的感受野。其核心思想是将二维注意力依次分解为沿高度轴和宽度轴方向的两个一维注意力。它的效率使我们能够在大范围内参加,并建立模型来学习远程甚至全局范围内互动。此外,大多数先前的注意力模块没有利用位置信息,这降低了注意力在建模与位置相关的交互时的能力,例如多尺度的形状或对象。最近的著作[65,37,6]引入了值得注意的位置术语,但是以一种上下文不可知的方式。在本文中,我们将位置项增加为上下文相关的,使得我们的注意力对位置敏感,并且具有边际代价。
我们在ImageNet[70]上展示了我们的轴向注意模型在分类上的有效性,并在三个数据集(Coco[56]、Mapillary vistas[62]和CitySees[22])上展示了我们的轴向注意模型对于全景分割[45]、实例分割和语义分割的有效性。具体地说,在ImageNet上,我们用我们的位置敏感轴向关注层取代了所有残差块[31]中的3×3卷积,从而构建了一个轴向共振网,并通过在“茎”中采用轴向关注层进一步使其完全注意[65]。因此,我们的Axial-ResNet在ImageNet上的独立注意力模型中获得了最先进的结果。对于细分任务,我们通过替换PanOpo-DeepLab[18]中的主干,将Axial-ResNet转换为Axial-DeepLab。在COCO[56]上,我们的Axial-DeepLab在测试开发集上的表现比目前自下而上的最先进的全景-DeepLab[19]高出2.8%的PQ。我们还展示了在Mapillary Vistas[62]和City Scenes[22]上的最先进的分割结果。
总而言之,我们的贡献有四个方面:
- 该方法首次尝试建立具有较大或全局接受场的独立注意模型。
- 我们提出了位置敏感的关注层,在不增加太多计算代价的情况下更好地利用了位置信息。
- 实验结果表明,轴向注意力不仅可以作为图像分类的独立模型,而且可以作为全景分割、实例分割和分段分割的基础。
- 我们的Axial-DeepLab在COCO上显著改进了自下而上的最先进技术,实现了与两阶段方法相当的性能。我们在地图景观和城市景观上也超过了以前最先进的方法。
Related Work
自上而下的全景分割:
大多数最先进的全景分割模型采用两阶段方法,其中首先生成对象建议,然后对每个建议进行顺序处理。我们将这些方法称为自上而下或基于建议的方法。在实例分割中,Mask R-CNN[30]通常部署在管道中,与轻质材料分割分支配对。例如,全景FPN[44]将语义分割头合并到Mask R-CNN[30],而Porzi等人则是如此,[68]将受DeepLab启发的轻量级模块[13]附加到来自FPN[55]的多尺度特征。此外,还设计了一些额外的模块来解决Mask R-CNN的重叠实例预测问题。TASCNet[49]和AUNet[52]提出了一个模块来指导‘Thing’和‘Stuff’预测之间的融合,而Liu等人也提出了一个空间排序模块。[61]采用空间排名模块。UPSNet[87]开发了一种有效的无参数全光头,用于融合“Thing”和“Stuff”,李等人对此进行了进一步的探索。[50]用于全景分割模型的端到端训练。AdaptIS[77]使用点建议来生成实例掩码。
UPSNet[87]开发了一种有效的无参数全景头,用于融合“Thing”和“Stuff”,李等人对此进行了进一步的探索。[50]用于全景分割模型的端到端训练。AdaptIS[77]使用点建议来生成实例掩码。
自下而上的全景分割:
与自上而下的方法不同,用于全景分割的自下而上或无建议的方法通常从语义分割预测开始,然后将‘things’像素分组成簇以获得实例分割。DeeperLab[89]预测用于类别无关实例分割的边界框四个角和对象中心。SSAP[28]利用由有效的图形划分方法[43]实现的像素对亲和力金字塔[60]。BBFNet[7]通过分水岭变换[81,4]和Hough投票[5,48]得到实例分割结果。最近,Panoptic-DeepLab[19],一种简单、快速且强大的自下而上全景分割方法,采用了一种与类无关的实例分割分支,包括简单实例中心回归[42,79,63],以及DeepLab语义分割输出[12,14,15]。Panoptic-DeepLab已经在几个基准测试上取得了最先进的结果,我们的方法建立在它的基础上。
自注意:
由[3]为神经序列到序列模型中的编码器-解码器引入的注意机制被发展为捕获两个序列之间的标记的对应关系。相比之下,自我关注被定义为将注意力集中在单一背景下,而不是跨越多个通道。它能够直接编码远程交互及其并行性,为各种任务带来了最先进的性能[80,38,25,66,72,24,53]。最近,自我注意已经被应用于计算机视觉,通过使用非局部或远程模块来增强CNN。非局部神经网络[84]表明,自我注意是非局部方法的实例化[9],并在许多视觉任务(如视频分类和目标检测)中获得收益。此外,文献[17,6]通过结合自我注意和卷积的特征,显示了图像分类的改进。视频动作识别任务[17]的最新结果也是以这种方式实现的。在语义分割方面,自我注意被开发为一个上下文聚合模块,可以捕获多尺度的上下文[39,26,98,95]。为了降低算法的复杂度,提出了有效的注意方法[73,39,53]。此外,用非局部方法增强的CNN[9]显示出更强的抗敌意攻击能力[86]。除了辨别性任务,自我注意也被应用于图像的生成建模[91,8,32]。最近,文献[65,37]表明,通过将自我注意的接受范围限制在一个局部正方形区域,单独的自我注意层可以堆叠起来,形成一个完全注意的模型。在图像分类和目标检测方面都取得了令人振奋的结果。在本研究中,我们遵循这一研究方向,提出了一个独立的、具有较大或全局接受场的自我注意模型,使自我注意模型再次非局部化。我们的模型在自下而上的全景分割上进行了评估,并显示出显著的改进。
Method
我们首先正式介绍我们的位置敏感型自我注意机制。然后,我们讨论了如何将其应用于轴注意,以及如何用轴关注层构建独立的Axial-ResNet和Axial-DeepLab。
3.1 Position-Sensitive Self-Attention
Self-Attention:
自我注意机制通常应用于视觉模型,作为增加CNN输出的附加功能[84,91,39]。给定高度为h、宽度为w、通道为din的输入要素地图x∈Rh×w×din,位置o=(i,j),yo∈Rdout处的输出通过将投影后的输入池化计算得到

其中N是整个位置点阵,并且查询Qo=WQxo、键Ko=WKxo、值Vo=WVxo都是输入xo, ∀o∈N的线性投影。WQ、WK∈Rdq×din和WV∈Rdout×din都是可学习矩阵。Softmaxp表示应用于所有可能的p=(a,b)位置的softmax函数,在这种情况下,该位置也是整个2D点阵。(N是整张特征图的位置点阵,是二维的,p∈N代表p是这张特征图上的所有位置,o(i, j)代表这张特征图上的某个位置,类似qo, Ko, Vo的计算,可以计算得到Kp和Vp, 上面这个式子就是自我注意机制。)
这种机制全局地基于亲和度(亲和度到底是什么?)XToWTQWKxp将vp值进行池化,允许我们在整个特征映射中捕获相关但非局部的上下文,而不是仅捕获局部关系的卷积。
然而,当输入的空间维度很大时,自我注意的计算非常昂贵(O(H2w2)),仅限于高水平的CNN(即,下采样的特征地图)或小图像。另一个缺点是,全局池化没有利用位置信息,而位置信息对于捕捉视觉任务中的空间结构或形状至关重要。
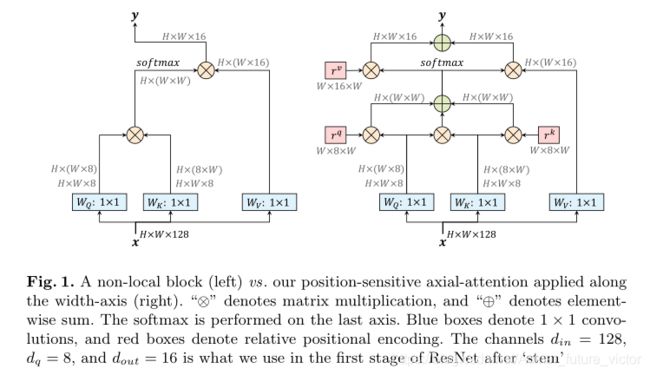
在[65]中,通过将局部约束和位置编码添加到自我关注中,缓解了这两个问题。对于每个位置o,提取局部m×m正方形区域以用作用于计算输出yo的存储体。这大大减少了到O(Hwm2)的计算量,使得自我注意模块可以作为独立的层部署,从而形成一个完全自我注意的神经网络。此外,学习到的相对位置编码项被合并到亲和度中,从而产生在感受野(即,局部m×m正方形区域)中查看的位置的动态先验。正式地,[65]提出

其中,Nm×m(o)是以位置o=(i,j)为中心的局部m×m正方形区域,并且可学习向量rp−o∈Rdq是添加的相对位置编码(rp-o是怎么计算的呢?)。内积qTorp-o度量从位置p=(a,b)到位置o=(i,j)的相容性。我们不考虑绝对位置编码qTorp,因为与相对对应的编码[65]相比,它们不能很好地推广。在接下来的段落中,为了简明起见,我们去掉了相对一词。(这个式子是在自我注意的基础上添加了局部约束和相对位置编码,其中N的范围由公式1中的整张特征图变为了m*m的正方形区域,这就是局部约束的实现,相对位置编码就是括号内的最后一项)
在实践中,dq和dout比din小得多,人们可以在等式(2)中扩展单头注意到多头注意,捕捉混合亲和力。特别地,通过在xo(具有不同的WnQ,WnK,WnV,∀n∈{1,2,…N.)上并行应用N个单头注意来计算多头注意,然后通过连接来自每个头部的结果来获得最终的输出Zo,即,zo=concatn(yno)。请注意,位置编码通常在头之间共享,因此它们引入了额外的边缘参数(上述就是自我注意机制,一种Wq, Wk, Wv对应着一头自我注意机制,多种Wq, Wk, Wv对应着多头自我注意机制)。
Position-Sensitivity:
我们注意到,先前的位置偏差仅取决于查询像素xo,而不取决于键像素xp(查询像素就是用xo计算出的qo,键像素就是用xp计算出的kp?)。然而,键xp还可以具有关于关注哪个位置的信息。因此,除了查询相关的偏差qTo rq p−o之外,我们还增加了关键字相关的位置偏差项kTp rkp−o。
类似地,值vp不包含等式(2)中的任何位置信息。在大的感受野或存储体的情况下,y(o)不太可能包含vp所来自的确切位置。因此,以前的模型不得不在使用较小的感受野(即较小的m×m区域)和丢弃精确的空间结构之间进行权衡。在这项工作中,我们使输出yo能够基于query-key亲和度qToKp来检索除内容vp之外的相对位置rvp−o。正式地说,

其中,可学习的rkp−o∈Rdq是key的位置编码,rvp−o∈Rdout是值的位置编码。这两个矢量都没有引入很多参数,因为它们在层中的注意力头部之间共享,并且局部像素的数量|Nm×m(O)|通常很小。
我们称这种设计为位置敏感型自我注意,它以合理的计算开销捕捉到了具有精确位置信息的长距离交互,这一点在我们的实验中得到了验证。
3.2 Axial-Attention
由独立的自我注意模型[65]提出的局部约束显著降低了视觉任务的计算成本,并使完全自我注意模型的建立成为可能。然而,这样的约束牺牲了全局连接,使得注意力的接受场不会大于相同核大小的纵深卷积。此外,在局部正方形区域中执行的局部自我注意仍然具有与区域长度平方的复杂度,从而引入了另一个超参数来权衡性能和计算复杂度。在这项工作中,我们建议在独立的自我注意中采用轴注意[39,32],以确保全局连接和高效计算。具体地说,我们首先将图像宽度轴上的轴向注意层定义为简单的一维位置敏感型自我注意,并对高度轴使用类似的定义。具体地说,沿宽度轴的轴向关注层定义如下

一个轴向关注层沿着一个特定的轴向传播信息。为了捕捉全局信息,我们分别在高轴和宽轴上连续使用了两个轴向关注层。如上所述,两个轴向注意层都采用多头注意机制。
轴向注意将复杂度降低到O(hwm)。这启用了全局接受场,这是通过将跨度m直接设置到整个输入特征来实现的。或者,也可以使用固定的m值,以减少巨大特征图上的内存占用。
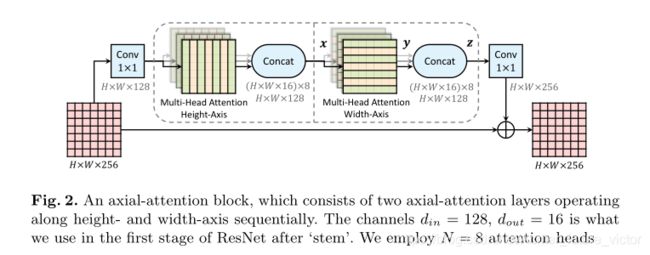
Axial-ResNet:
为了将ResNet[31]转换为Axial-ResNet,我们用两个多头轴关注层(一个用于高轴,另一个用于宽轴)代替残差瓶颈块中的3×3卷积。在对应的轴向关注层之后的每个轴上执行可选的striding。保留两个1×1卷积以打乱特征。这形成了我们的(残差)轴向注意块,如图2所示,它被堆叠多次以获得轴向-ResNet。请注意,由于矩阵乘法(WQ、WK、WV)紧随其后,因此我们不在两个轴向关注层之间使用1×1卷积。此外,保留了原始ResNet中的茎(即第一个strided为7×7的卷积和3×3的最大池化),从而形成了一种卷积在第一层使用,其他地方都使用注意层的卷积模型。在卷积模型中,我们将跨度m设置为从第一个块开始的整个输入,其中特征映射为56×56。
在我们的实验中,我们还建立了一个完整的轴向注意模型,称为Full Axial-ResNet,它进一步将轴向注意应用到茎上。我们不是设计一个特殊的空间变化的注意力主干[65],而是简单地堆叠三个轴向注意力瓶颈块。此外,为了减少计算量,我们在全轴-ResNet的前几个块中采用了局部约束(如[65]中的局部m×m正方形区域)。
Axial-DeepLab:
为了进一步将Axial-ResNet转换为Axial-DeepLab以执行分段任务,我们进行了几项更改,如下所述。
首先,为了提取密集的特征图,DeepLab[12]改变了ResNet[31]中最后一到两个阶段的stride和扩张比率。类似地,我们去掉了最后一个阶段的stride,但是我们没有实现‘Arous’注意力模块,因为我们的轴向注意力已经捕获了整个输入的全局信息。在这项工作中,我们提取具有输出步幅(即输入分辨率与最终主干特征分辨率之比)为16的特征映射。我们不追求输出步幅8,因为它的计算量很大。
其次,我们没有采用扩张空间金字塔池化模块(ASPP)[13,14],因为我们的轴注意块也可以有效地编码多尺度或全局信息。我们在实验中表明,我们的Axial-DeepLab在不使用ASPP的情况下比Panoptic-DeepLab[19]在使用和不使用ASPP的情况下都有更好的性能。
最后,在Panoptic-DeepLab[19]之后,我们采用完全相同的三卷积、双解码器和预测头的主干[78]。头部产生语义分割和类别不可知的实例分割,并且它们通过多数投票[89]合并以形成最终的全景分割。
在输入非常大(例如,2177×2177)并且存储受限的情况下,我们在所有轴注意块中求助于大跨度m=65。请注意,我们不将轴向跨度视为超参数,因为它已经足以覆盖多个数据集上的长范围甚至全局上下文,并且设置较小的跨度不会显著减少M-Adds。
Experimental Results
我们在四个大规模数据集上进行了实验。我们首先在ImageNet[70]上报告我们的Axial-ResNet的结果。然后,我们将ImageNet预先训练的Axial-ResNet转换为Axial-DeepLab,并报告关于COCO[56]、Mapillary Vistas[62]和CitysSees[22]的全景分割结果,通过全景质量(PQ)[45]进行评估。我们还报告了例如分割的平均精度(AP),以及在地图景观和城市景观上的语义分割的mIOU。我们的模型使用TensorFlow[1]在128个TPU核(用于ImageNet)和32个核(用于全景分割)上进行训练。
Training protocal:
在ImageNet上,为了进行公平的比较,我们采用了与[65]相同的训练方案,只是我们对完整的AxialResNet使用了批次大小512,对所有其他模型使用了1024,并相应地调整了学习率[29]。
对于全景图像分割,除了使用线性预热Radam[58]Lookhead[92]优化器(具有相同的学习率0.001)外,我们严格遵循PanopoDeepLab[19]。我们所有关于全景分割的结果都使用这个设置。我们注意到这一改变并没有改善结果,而是平滑了我们的训练曲线。全景-DeepLab在此设置中产生类似的结果。
4.1 ImageNet
对于ImageNet,我们从ResNet-50[31]构建Axial-ResNet-L。==具体来说,我们为‘茎’之后的第一级设置din=128,dout=2dq=16。当空间分辨率降低2倍[76]时,我们将其翻倍。此外,我们将所有通道[35,71,34]分别乘以0.5、0.75和2,得到AxialResNet-{S,M,XL}。最后,用三个轴向注意块替换“茎”进一步生成Stand-Alone Axial-ResNet,其中第一个块stride为2。由于早期层引入的计算代价,我们在所有Stand-Alone Axial-ResNet块中设置轴向跨度m=15。我们总是使用N=8个头[65]。为了避免WQ、WK、WV、rq、rk、rv的仔细初始化,我们在所有关注层中使用批归一化[40]。
表1总结了我们的ImageNet结果。还列出了基线ResNet-5031和Conv-Stem+Attify[65]。在转换设置中,在[65]的关注层中加入BN略微提高了0.3%的性能。
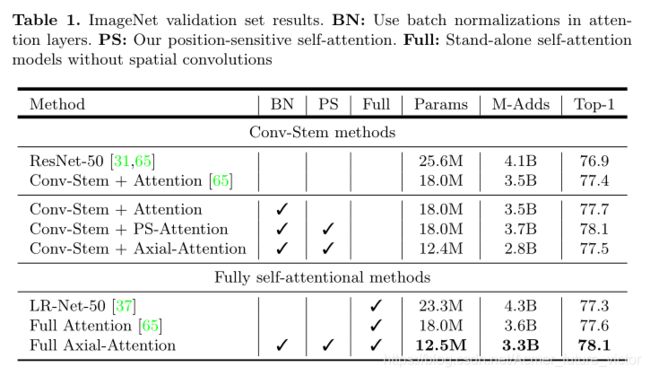
我们提出的位置敏感型自我注意(Conv-Stem+PS-Attribute)以额外的边缘计算为代价,进一步提高了0.4%的性能。我们的Conv-Stem+Axial-Attendence的性能与Conv-Stem+Attendence不相上下[65],同时参数效率和计算效率都更高。与其他完全自我注意模型相比,我们的完全轴向注意模型比完全注意模型的性能提高了0.5%,同时参数效率提高了1.44倍,计算效率提高了1.09倍。
在[65]之后,我们用不同的网络宽度(即AxialResNets-{S,M,L,XL})进行实验,探索精度、模型参数和计算成本(就M-ADDS而言)之间的权衡。如图3所示,我们提出的Conv-Stem+PS-Attify和Conv-Stem+Axial-Attify在所有设置下的表现都已经超过ResNet-50[31,65]和注意模型[65](Conv-Stem+Attendence和Full Attribute)。我们的全轴向注意力进一步达到了最佳精度参数和精度复杂度的折衷。

4.2 COCO
然后,将ImageNet预先训练的Axial-ResNet模型变体(具有不同通道)转换为Axial-DeepLab模型变体,用于全景分割任务。我们首先展示了我们的Axial-DeepLab在具有挑战性的CoCo数据集[56]上的有效性,该数据集包含不同尺度(从小于32×32到大于96×96)的对象。
Val set:
在表2中,由于我们的方法也属于自下而上的全景分割,所以我们报告了我们的验证集结果,并与其他自下而上的全景分割方法进行了比较。如表所示,我们的单尺度Axial-DeepLab-S比DeeperLab[89]高出8%的PQ,比多尺度SSAP[28]高出5.3%的PQ,比单尺度全景实验室高出2.1%的PQ。有趣的是,我们的单尺度AxialDeepLab-S在参数效率和计算效率(在M-ADDS中)分别是3.8倍和27倍的同时,性能也比多尺度Panoptic-DeepLab高0.6%。增加主干容量(通过大通道)不断提高性能。具体地说,我们的多尺度Axial-DeepLab-L达到了43.9%的PQ,比全景-DeepLab[19]高出2.7%的PQ。

Test-dev set:
如表3中所示,我们的Axial-DeepLab变种在更大的主干上显示出一致的改进。我们的多尺度Axial-DeepLab-L达到了44.2%的PQ,比DeeperLab[89]高出9.9%的PQ,比SSAP[28]高出7.3%的PQ,比全景-DeepLab[19]高出2.8%的PQ,在自下而上的方法中创造了新的最先进的水平。我们还在表中列出了采用自上而下方法的几种性能最好的方法,以供参考。
Scale Stress Test:
为了验证我们的模型能够学习远程交互,除了标准测试外,我们还执行了一次规模压力测试。在压力测试中,我们用标准设置训练PanOptional-DeepLab(X-71)和我们的Axial-DeepLab-L,但在分布外分辨率上测试它们(即,将输入调整为不同的分辨率)。图4总结了我们在PQ、PQ(Thing)和PQ(Stuff)上相对于Panopo-DeepLab的相对改进。当在巨大的图像上测试时,Axial-DeepLab显示出很大的增益(30%),表明它比卷积编码更好地编码长程关系。此外,Axial-DeepLab在小图像上提高了40%,表明轴向注意对尺度变化的鲁棒性更强。

4.3 Mapillary Vistas
我们在大规模Mapillary Vistas数据集上评估我们的Axial-DeepLab[62]。我们只报告验证集结果,因为测试服务器不可用。
Val set:
如表4中所示,我们的Axial-DeepLab-L在单尺度和多尺度情况下都优于所有最先进的方法。我们的单比例尺Axial-DeepLab-L的PQ比之前最好的单比例尺全景深实验室(X-71)[19]高出2.4%。在多尺度设置下,我们的轻量级AxialDeepLab-L的性能要好于Panoight-DeepLab(Auto-DeepLab-XL++),不仅在全景分割(0.8%PQ)和实例分割(0.3%AP)上,而且在语义分割(0.8%Mou)上,这也是AutoDeepLab[57]搜索的任务。此外,据我们所知,我们的Axial-DeepLab-L获得了最好的单模型语义分割结果。

4.4 Cityscapes
Val set:
在表5(a),我们报告我们的城市景观验证集结果。在不使用额外数据的情况下(即,仅使用城市景观精细注释),我们的Axial-DeepLab达到了65.1%的PQ,比目前最好的自下而上的PanopticDeepLab[19]提高了1%,比基于建议的AdaptIS[77]提高了3.1%。当使用额外数据(例如Mapillary Vistas[62])时,我们的多尺度Axial-DeepLab-XL达到68.5%的PQ,比全景-DeepLab[19]高1.5%,比Seamless高3.5%[68]。我们的实例切分和语义切分结果分别比泛视-DeepLab[19]提高了1.7%和1.5%。
Test set:
表5(b)显示了我们的测试集结果。在没有额外数据的情况下,AxialDeepLab-XL达到了62.8%的PQ,创造了一个新的最先进的结果。在Mapillary Vistas预训练中,我们的模型进一步达到了66.6%的PQ、39.6%的AP和84.1%的MIU。值得注意的是,PanOpo-DeepLab[19]在测试集上的推理中采用了输出步长8的技巧,使得他们的M-Adds可以与我们的XL模型相媲美。
4.5 Ablation Studies
我们在城市景观验证集上进行了消融研究。


Importance of Position-Sensitivity and Axial-Attention:
在表1中在ImageNet上对注意力模型进行了实验。在这项消融研究中,我们将它们转移到城市景观分割任务中。如表6中所示,所有变种的表现都优于ResNet-50[31]。位置敏感注意力比之前的自我注意表现更好[65],这与表1中的ImageNet结果一致。然而,使用与ImageNet上的位置敏感注意相当的轴向注意,在没有ASPP的情况下,对所有三个分割任务(在PQ、AP和MIEU中)都有超过1%的提升,并且使用更少的参数和M-ADD,这表明对轴注意的长范围上下文进行编码的能力显著提高了对大输入图像的分割任务的性能。

Importance of Axial-Attention Span:
在表7中,我们改变跨度m(即,轴线区块中局部区域的空间范围),而不是ASPP。我们观察到,更大的跨度会以边际成本持续提高性能。
Conclusion and Discussion
在这项工作中,我们展示了所提出的位置敏感轴注意在图像分类和分割任务中的有效性。在ImageNet上,我们的Axial-ResNet由堆叠的轴向注意块组成,在独立的自我注意模型中取得了最先进的结果。我们进一步将AxialResNet转换为Axial-DeepLab,用于自下而上的细分任务,还展示了几个基准测试的最新性能,包括COCO、Mapillary Vistas和CityScenes。我们希望我们有希望的结果能够确立轴注意是现代计算机视觉模型的有效构件。
我们的方法与解耦卷积[41]有相似之处,后者将纵卷积[75,35,20]分解为列卷积和行卷积。该操作在理论上也可以获得较大的感受野,但其卷积模板匹配特性限制了对多尺度交互作用的建模能力。另一种相关的方法是可变形卷积[23,96,27],其中每个点动态地关注图像上的几个点。但是,可变形卷积不利用关键字相关的位置偏差或基于内容的关系。此外,轴向注意沿着高度轴和宽度轴依次密集且更有效地传播信息。
尽管我们的轴注意模型节省了M-ADDS,但它的运行速度比卷积模型慢,这也可以从[65]中观察到。这是由于各种加速器上暂时缺乏专门的内核。如果社会认为轴心是一个看似合理的方向,这种情况可能会得到很好的改善。