PyTorch实现前馈神经网络(torch.nn)
PyTorch实现前馈神经网络(torch.nn)
- 1 回归任务
- 1.1 导入所需要的包
- 1.2 自定义数据集
- 1.3 构造数据迭代器
- 1.4 模型构建
- 1.5 参数初始化
- 1.6 损失函数和优化器
- 1.7 训练
- 1.7.1 定义训练函数
- 1.7.2 开始训练模型
- 1.7.3 绘制loss曲线
- 2 二分类任务
- 2.1 导入所需要的包
- 2.2 自定义数据集
- 2.3 构造数据迭代器
- 2.4 模型构建
- 2.5 参数初始化
- 2.6 损失函数和优化器
- 2.7 训练
- 2.7.1 定义训练函数
- 2.7.2 开始训练模型
- 2.7.3 绘制loss曲线
- 3 多分类任务
- 3.1 导入包
- 3.2 下载MNIST数据集
- 3.3 定义数据迭代器
- 3.4 模型构建
- 3.5 参数初始化
- 3.6 损失函数和优化器
- 3.7 定义准确率检验器
- 3.8 训练
- 3.8.1 定义训练函数
- 3.8.2 开始训练模型
- 3.8.3 绘制loss、acc曲线
回归任务
该回归问题为高维回归问题,涉及的自变量过多,因此不适合用之前的线性回归模型,因为模型过于简单,导致训练的效率太低。因此我们考虑利用前馈神经网络,增加隐藏层,并且为了避免梯度消失问题,在隐藏层采用relu激活函数。
导入所需要的包
import torch
from torch import nn
from torch.nn import init
import numpy as np
from IPython import display
import torch.utils.data as Data
自定义数据集
num_inputs = 500
num_examples = 10000
#
true_w = torch.ones(500,1)*0.0056
true_b = 0.028
#随机生成的数据样本
features = torch.tensor(np.random.normal(0, 1, (num_examples, num_inputs)), dtype=torch.float)#行*列=10000*500
labels = torch.mm(features,true_w) + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float) #扰动项
#训练集和测试集上的样本&标签数----真实的特征和样本
trainfeatures = features[:7000]
trainlabels = labels[:7000]
testfeatures = features[7000:]
testlabels = labels[7000:]
print(trainfeatures.shape,trainlabels.shape,testfeatures.shape,testlabels.shape)
torch.Size([7000, 500]) torch.Size([7000, 1]) torch.Size([3000, 500]) torch.Size([3000, 1])
构造数据迭代器
采用torch.utils.data.DataLoader读取小批量数据,分别定义关于训练集数据和测试集数据的迭代器iterate
batch_size是超参数,表示一轮放入多少个样本进行训练shuffle是否打乱数据,True表示打乱数据num_workers=0表示不开启多线程读取数据
注:利用Data.TensorDataset获取数据集,Data.DataLoader构建数据迭代器,从而实现数据的批量读取。
#获得数据迭代器
batch_size = 50 # 设置小批量大小
def load_array(data_arrays, batch_size, is_train=True): #自定义函数
"""构造一个PyTorch数据迭代器。"""
dataset = Data.TensorDataset(*data_arrays)#features 和 labels作为list传入,得到PyTorch的一个数据集
return Data.DataLoader(dataset, batch_size, shuffle=is_train,num_workers=0)#返回的是实例化后的DataLoader
train_iter = load_array([trainfeatures,trainlabels],batch_size)
test_iter = load_array([testfeatures,testlabels],batch_size)
# 测试:利用python内置函数next,从迭代器中获取第一项。
# next(iter(train_iter))
[tensor([[ 0.1302, -0.7244, 0.8331, ..., -0.0395, -1.7288, 0.5882],
[ 0.3992, 0.6459, 0.5747, ..., 2.7026, -0.2066, 0.0475],
[ 1.1758, 0.8725, 0.0554, ..., 1.3374, 0.4322, -0.1942],
...,
[-1.3619, 1.0502, -1.2361, ..., -1.2441, -1.1378, -0.1940],
[ 0.7635, 2.2856, -0.1588, ..., 0.4710, 1.3731, 0.6452],
[ 0.1177, -0.8012, -0.1541, ..., 0.5184, 0.1925, -0.1466]]),
tensor([[ 0.1838],
[ 0.0256],
[ 0.1098],
...
[-0.0794],
[ 0.1535],
[-0.0316],
[-0.1934],
[ 0.0309],
[ 0.1449],
[-0.3216],
[ 0.0894],
[-0.0281]])]
模型构建
其实,PyTorch提供了⼤量预定义的层,这使我们只需关注使⽤哪些层来构造模型。
⾸先,导⼊ torch.nn 模块。实际上,“nn”是neural networks(神经⽹络)的缩写。顾名思义,该模块定义了⼤量神经⽹的层。之前我们已经用过了autograd ,⽽ nn 就是利⽤ autograd 来定义模型。 nn 的核⼼数据结构是 Module ,它是⼀个抽象概念,既可以表示神经⽹络中的某个层(layer),也可以表示⼀个包含很多层的神经⽹络。
- 最常⻅的做法是继承
nn.Module,撰写⾃⼰的⽹络/层。⼀个nn.Module实例应该包含⼀些层以及返回输出的前向传播(forward)⽅法。 - 事实上我们还可以⽤
nn.Sequential来更加⽅便地搭建⽹络,Sequential是⼀个有序的容器,⽹络层将按照在传⼊Sequential的顺序依次被添加到计算图中。
此模型较简单,因此使用nn.Sequential可以更加简洁方便构建前馈神经网络。
#实现FlattenLayer层:将数据展平
class FlattenLayer (nn.Module):
def _init_ (self):
super(FlattenLayer,self)._init_()
def forward (self,x):
return x.view(x.shape[0],-1)
#模型定义和参数初始化
# num_inputs = 500
num_hiddens = 256
num_outputs = 1
net = nn.Sequential(
FlattenLayer(),#输入层
nn.Linear(num_inputs,num_hiddens),#隐藏层
nn.ReLU(),#隐藏层激活函数Relu
nn.Linear(num_hiddens,num_outputs),#输出层
)
参数初始化
由print输出的结果可知,param分别为[W1,b1,W2,b2]
- W1.shape =num_hiddens * num_inputs
- W2.shape =num_outputs * num_hiddens
因此,X与W做矩阵乘法时,需要对W进行转置。
for param in net.parameters():
print (param.shape)
init.normal_(param,mean=0,std=0.01)
net.parameters()
torch.Size([256, 500])
torch.Size([256])
torch.Size([1, 256])
torch.Size([1])
损失函数和优化器
回归问题决定了使用最小化均方误差,对于优化器,使用torch模块中的小批量梯度下降。
lr=0.01
loss = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(),lr)
训练
定义训练函数
对于每一轮次的训练;
- step1:在训练集上,进行小批量梯度下降更新参数
- step2 每经过一个轮次的训练, 记录训练集和测试集上的loss
#记录列表(list),存储训练集和测试集上经过每一轮次,loss的变化
def train1 (net,train_iter,test_iter,loss,num_epochs,batch_size,params = None,lr=None,optimizer=None):
train_loss=[]
test_loss=[]
for epoch in range(num_epochs):#外循环控制循环轮次
#step1在训练集上,进行小批量梯度下降更新参数
for X,y in train_iter:#内循环控制训练批次
y_hat = net(X)
l = loss(y_hat,y)#l.size = torch.Size([]),即说明loss为表示*标量*的tensor`
#梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
SGD(params,lr,batch_size)
else:
optimizer.step()
#step2 每经过一个轮次的训练, 记录训练集和测试集上的loss
train_labels = trainlabels.view(-1,1)
test_labels = testlabels.view(-1,1)
train_loss.append((loss(net(trainfeatures),train_labels)).item())#loss本身就默认了取平均值!
test_loss.append((loss(net(testfeatures),test_labels)).item())
print("epoch %d,train_loss %.6f,test_loss %.6f"%(epoch+1,train_loss[epoch],test_loss[epoch]))
return train_loss, test_loss
开始训练模型
lr=0.01
num_epochs = 50
#batch_size、params epc已经定义
train_loss, test_loss = train1 (net,train_iter,test_iter,loss,num_epochs,batch_size,net.parameters(),lr,optimizer)#每一给optimizer,默认None
epoch 1,train_loss 0.015031,test_loss 0.015377
epoch 2,train_loss 0.013855,test_loss 0.014311
epoch 3,train_loss 0.012677,test_loss 0.013246
epoch 4,train_loss 0.011430,test_loss 0.012137
epoch 5,train_loss 0.010103,test_loss 0.010897
epoch 6,train_loss 0.008683,test_loss 0.009595
...
epoch 48,train_loss 0.000411,test_loss 0.001012
epoch 49,train_loss 0.000404,test_loss 0.001008
epoch 50,train_loss 0.000396,test_loss 0.001003
绘制loss曲线
import matplotlib.pyplot as plt
x=np.linspace(0,len(train_loss),len(train_loss))
plt.plot(x,train_loss,label="train_loss",linewidth=1.5)
plt.plot(x,test_loss,label="test_loss",linewidth=1.5)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()
plt.show()

二分类任务
#在执行一个新的任务之前,先将之前的中间变量的结果全部清空,即之前的编译不作数
%reset
Once deleted, variables cannot be recovered. Proceed (y/[n])? y
导入所需要的包
import torch
import numpy as np
import random
from IPython import display
from matplotlib import pyplot as plt
from torch import nn
import torch.utils.data as Data
import torch.optim as optim
from torch.nn import init
自定义数据集
共生成两个数据集。
- 两个数据集的大小均为10000且训练集大小为7000,测试集大小为3000。
- 两个数据集的样本特征x的维度均为200,且分别服从均值互为相反数且方差相同的正态分布。
- 两个数据集的样本标签分别为0和1。
然后利用torch.cat()操作将两类的训练集和测试集分别合并,从而训练集的大小为14000,测试集的大小为6000。
num_inputs = 200
#1类
x1 = torch.normal(2,1,(10000, num_inputs))
y1 = torch.ones(10000,1) # 标签1
x1_train = x1[:7000]
x1_test = x1[7000:]
#0类
x2 = torch.normal(-2,1,(10000, num_inputs))
y2 = torch.zeros(10000,1) # 标签0
x2_train = x2[:7000]
x2_test = x2[7000:]
#合并训练集
trainfeatures = torch.cat((x1_train,x2_train), 0).type(torch.FloatTensor)
trainlabels = torch.cat((y1[:7000], y2[:7000]), 0).type(torch.FloatTensor)
#合并测试集
testfeatures = torch.cat((x1_test,x2_test), 0).type(torch.FloatTensor)
testlabels = torch.cat((y1[7000:], y2[7000:]), 0).type(torch.FloatTensor)
print(trainfeatures.shape,trainlabels.shape,testfeatures.shape,testlabels.shape)
torch.Size([14000, 200]) torch.Size([14000, 1]) torch.Size([6000, 200]) torch.Size([6000, 1])
构造数据迭代器
batch_size = 50
# 将训练数据的特征和标签组合
dataset = Data.TensorDataset(trainfeatures, trainlabels)
# 把 dataset 放入 DataLoader
train_iter = Data.DataLoader(
dataset=dataset, # torch TensorDataset format
batch_size=batch_size, # mini batch size
shuffle=True, # 是否打乱数据 (训练集一般需要进行打乱)
num_workers=0, # 多线程来读数据, 注意在Windows下需要设置为0
)
# 将测试数据的特征和标签组合
dataset = Data.TensorDataset(testfeatures, testlabels)
# 把 dataset 放入 DataLoader
test_iter = Data.DataLoader(
dataset=dataset, # torch TensorDataset format
batch_size=batch_size, # mini batch size
shuffle=True, # 是否打乱数据 (训练集一般需要进行打乱)
num_workers=0, # 多线程来读数据, 注意在Windows下需要设置为0
)
模型构建
#实现FlattenLayer层
#完成将数据集展平的操作,保证一个样本的数据变成一个数组
class FlattenLayer(torch.nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x):
return x.view(x.shape[0],-1)
# #模型构建
num_hiddens,num_outputs = 256,1
net = nn.Sequential(
FlattenLayer(),
nn.Linear(num_inputs,num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens,num_outputs),
)
参数初始化
for params in net.parameters():
init.normal_(params,mean=0,std=0.01)
损失函数和优化器
# 定义二分类交叉熵损失函数
loss = torch.nn.BCEWithLogitsLoss()
# 定义sgd优化器
optimizer = torch.optim.SGD(net.parameters(),lr)
训练
定义训练函数
#定义模型训练函数
def train2(net,train_iter,test_iter,loss,num_epochs,batch_size,params=None,lr=None,optimizer=None):
train_ls = []
test_ls = []
for epoch in range(num_epochs): # 训练模型一共需要num_epochs个迭代周期
train_l_sum, train_acc_num,n = 0.0,0.0,0
# 在每一个迭代周期中,会使用训练数据集中所有样本一次
for X, y in train_iter: # x和y分别是小批量样本的特征和标签
y_hat = net(X)
l = loss(y_hat, y.view(-1,1)) # l是有关小批量X和y的损失
#梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward() # 小批量的损失对模型参数求梯度
if optimizer is None:
SGD(params,lr)
else:
optimizer.step()
#计算每个epoch的loss
train_l_sum += l.item()*y.shape[0]
#每一个epoch的所有样本数
n+= y.shape[0]
train_labels = trainlabels.view(-1,1)
test_labels = testlabels.view(-1,1)
train_ls.append(train_l_sum/n)
test_ls.append(loss(net(testfeatures),test_labels).item())
print("epoch %d,train_loss %.6f,test_loss %.6f"%(epoch+1,train_loss[epoch],test_loss[epoch]))
return train_ls,test_ls
开始训练模型
注:为什么重复运行train函数时,结果不一样,往往是第一次的结果较为合理。因为运行完一次train中,params已经更新,第二次运行时,计算得到的误差就会非常小!
因此,每次执行train之前,务必重新进行一次参数的初始化。
lr = 0.0001
num_epochs = 50
train_loss,test_loss = train2(net,train_iter,test_iter,loss,num_epochs,batch_size,net.parameters,lr,optimizer)
epoch 1,train_loss 0.668196,test_loss 0.635509
epoch 2,train_loss 0.603642,test_loss 0.571374
epoch 3,train_loss 0.538563,test_loss 0.505013
epoch 4,train_loss 0.470947,test_loss 0.436439
epoch 5,train_loss 0.402410,test_loss 0.368597
epoch 6,train_loss 0.336602,test_loss 0.305513
epoch 7,train_loss 0.277270,test_loss 0.250374
...
epoch 42,train_loss 0.010663,test_loss 0.010482
epoch 43,train_loss 0.010274,test_loss 0.010105
epoch 44,train_loss 0.009910,test_loss 0.009752
epoch 45,train_loss 0.009568,test_loss 0.009420
epoch 46,train_loss 0.009246,test_loss 0.009108
epoch 47,train_loss 0.008943,test_loss 0.008814
epoch 48,train_loss 0.008658,test_loss 0.008536
epoch 49,train_loss 0.008388,test_loss 0.008273
epoch 50,train_loss 0.008133,test_loss 0.008025
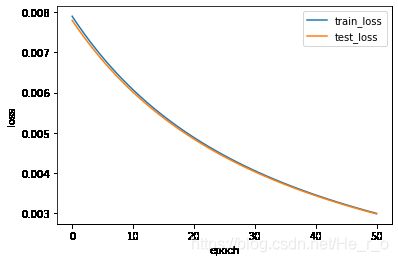
绘制loss曲线
import matplotlib.pyplot as plt
x=np.linspace(0,len(train_loss),len(train_loss))
plt.plot(x,train_loss,label="train_loss",linewidth=1.5)
plt.plot(x,test_loss,label="test_loss",linewidth=1.5)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()
plt.show()
多分类任务
#在执行一个新的任务之前,先将之前的中间变量的结果全部清空,即之前的编译不作数
%reset
Once deleted, variables cannot be recovered. Proceed (y/[n])? y
导入包
import torch
from torch import nn
import torch.utils.data as Data
import torch.optim as optim
from torch.nn import init
import torchvision
import torchvision.transforms as transforms
import numpy as np
import random
from IPython import display
from matplotlib import pyplot as plt
下载MNIST数据集
按实验要求,这里利用torchvision模块下载了数字手写数据集:
- 其中训练集为60000张图片,测试集为10000张图片,其每个图片对应的标签是0-9之间,分别代表手写数字0,1,2,3,4,5,6,7,8,9.
- 图像是固定大小(28x28像素),其值为0到1。为每个图像都被平展并转换为784(28 * 28)个特征的一维numpy数组。
#下载MNIST手写数据集 :包括训练集和测试集
train_dataset = torchvision.datasets.MNIST(root='./Datasets/MNIST', train=True, download=True, transform=transforms.ToTensor())
test_dataset = torchvision.datasets.MNIST(root='./Datasets/MNIST', train=False, download=True, transform=transforms.ToTensor())
定义数据迭代器
通过测试,输出X.shape为torch.Size([32, 1, 28, 28]) :
- 32个图像
- 1代表图像为黑白,只有一个通道
- 28*28为图像的大小
torch.Size([32]),则代表32个图像,每个图像有一个对应的标签
batch_size = 32
train_iter = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
test_iter = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
#测试:
for X, y in train_iter:
print(X.shape,y.shape)
break
torch.Size([32, 1, 28, 28]) torch.Size([32])
模型构建
#超参数初始化
num_inputs=784 #28*28
num_hiddens=256
num_outputs=10
#实现FlattenLayer层
class FlattenLayer(nn.Module):
def _init_(self):
super(FlattenLayer,self)._init_()
def forward(self, x):
return x.view(x.shape[0],-1)#不管是否有展平的需要,都要加上,在这个例子中,显然有。
#模型定义
net = nn.Sequential(
FlattenLayer(),
nn.Linear(num_inputs,num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens,num_outputs)
)
参数初始化
for param in net.parameters():
init.normal_(param,mean=0,std=0.01)
损失函数和优化器
lr=0.01
loss = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(),lr)
定义准确率检验器
加入了对测试集的准确率的判断,利用测试集的预测值和真实值进行比较,计算测试准确的概率。
FUN
其中y_hat.argmax(dim=1)返回矩阵y_hat每行中最大元素的索引,且返回结果与变量y形状相同。相等条件判断式(y_hat.argmax(dim=1) == y)是一个类型为ByteTensor的Tensor,即tensor.bool,我们用float()将其转换为值为0(相等为假)或1(相等为真)的浮点型Tensor,即tensor.float。或者通过sum()直接转为为torch.int类型,再通item转换为int类型。
对于本次的检验器,给定一个数据迭代器,两个功能:
- 计算准确率
- 计算loss
#返回准确率以及loss
flag=0
def evaluate_accuracy_loss(net, data_iter):
acc_sum=0.0
loss_sum=0.0
n=0
global flag
for X,y in data_iter:
y_hat = net(X)
if flag==0:print (y_hat)#测试一下y_hat是否已经softmax激活
flag = 1
acc_sum += (y_hat.argmax(dim=1)==y).sum().item()
l = loss(y_hat,y)
loss_sum += l.item()*y.shape[0]#由于loss(y_hat,y)默认为求平均,因此*y.shape[0]意味着求和。
n+=y.shape[0]
return acc_sum/n,loss_sum/n
#测试输出层是否被softmax函数激活
# for X,y in train_iter:
# y_hat = net(X)
# print (y_hat)#测试一下y_hat是否已经softmax激活
# break
训练
定义训练函数
#记录列表(list),存储训练集和测试集上经过每一轮次,loss的变化
def train3 (net,train_iter,test_iter,loss,num_epochs,batch_size,params = None,lr=None,optimizer=None):
train_loss=[]
test_loss=[]
for epoch in range(num_epochs):#外循环控制循环轮次---跑完一轮,也就把数据走了一遍
train_l_sum=0.0#记录训练集上的损失
train_acc_num=0.0#记录训练集上的准确数
n =0.0
#step1在训练集上,进行小批量梯度下降更新参数
for X,y in train_iter:#内循环控制训练批次
y_hat = net(X)
#保证y与y_hat维度一致,否则将会发生广播
l = loss(y_hat,y)#这里计算出的loss是已经求和过的,l.size = torch.Size([]),即说明loss为表示*标量*的tensor`
#梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
SGD(params,lr,batch_size)
else:
optimizer.step()
#每一个迭代周期中得到的训练集上的loss累积进来
train_l_sum += l.item()*y.shape[0]
#计算训练样本的准确率---将每个迭代周期中预测正确的样本数累积进来
train_acc_num += (y_hat.argmax(dim=1)==y).sum().item()#转为int类型
n += y.shape[0]
#step2 每经过一个轮次的训练, 记录训练集和测试集上的loss
#注意要取平均值,loss默认求了sum
train_loss.append(train_l_sum/n)#训练集loss
test_acc,test_l = evaluate_accuracy_loss(net,test_iter)
test_loss.append(test_l)
print("epoch %d,train_loss %.6f,test_loss %.6f,train_acc %.6f,test_acc %.6f"%(epoch+1,train_loss[epoch],test_loss[epoch],train_acc_num/n,test_acc))
return train_loss, test_loss
开始训练模型
lr = 0.01
num_epochs=30
train_loss,test_loss=train3(net,train_iter,test_iter,loss,num_epochs,batch_size,net.parameters(),lr,optimizer)
epoch 1,train_loss 1.176481,test_loss 0.477081,train_acc 0.734050,test_acc 0.876300
epoch 2,train_loss 0.414445,test_loss 0.348338,train_acc 0.887100,test_acc 0.903500
epoch 3,train_loss 0.341379,test_loss 0.305867,train_acc 0.903383,test_acc 0.914100
epoch 4,train_loss 0.307838,test_loss 0.280942,train_acc 0.912317,test_acc 0.920700
epoch 5,train_loss 0.283337,test_loss 0.261160,train_acc 0.920200,test_acc 0.926500
epoch 6,train_loss 0.262854,test_loss 0.245003,train_acc 0.925567,test_acc 0.931400
epoch 7,train_loss 0.244713,test_loss 0.229990,train_acc 0.931100,test_acc 0.935600
epoch 8,train_loss 0.228311,test_loss 0.214327,train_acc 0.935733,test_acc 0.939500
...
epoch 25,train_loss 0.102477,test_loss 0.111054,train_acc 0.971933,test_acc 0.966100
epoch 26,train_loss 0.099015,test_loss 0.108542,train_acc 0.972850,test_acc 0.967700
epoch 27,train_loss 0.095864,test_loss 0.106288,train_acc 0.973533,test_acc 0.968900
epoch 28,train_loss 0.092862,test_loss 0.103809,train_acc 0.974700,test_acc 0.969000
epoch 29,train_loss 0.089862,test_loss 0.101595,train_acc 0.975550,test_acc 0.970400
epoch 30,train_loss 0.087256,test_loss 0.100992,train_acc 0.976000,test_acc 0.970800
绘制loss、acc曲线
import matplotlib.pyplot as plt
x=np.linspace(0,len(train_loss),len(train_loss))
plt.plot(x,train_loss,label="train_loss",linewidth=1.5)
plt.plot(x,test_loss,label="test_loss",linewidth=1.5)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()
plt.show()
