Elasticsearch:如何部署 Elasticsearch 来满足自己的要求
在我之前的文章:
-
Elasticsearch:我的 Elasticsearch 集群中应该有多少个分片?
-
Elasticsearch:管理 Elasticsearch 内存并进行故障排除
-
Elastic:Elasticsearch 的分片管理策略
我们涉及到一些分片管理,内存管理已经分片策略的一些知识。在实际的使用中,我们该如何对 Elasticsearch 集群做正确的 sizing。我们到底需要多少内存,多少个 CPU,多少个 shards 等等。在今天的文章中,我总结一些专家的建议,希望对于正确使用 Elasticsearch 提供一些参考的意见。在实际的使用中,可能需要根据自己的使用进行调整。如果你对分片(shard)的概念不是很熟悉的话,请阅读我之前的文章 “Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica”。
分片策略
在最新的 Elasticsearch 的默认部署中,每个创建的索引只是有一个 primary shard。这个是在索引创建的时候定义的。比如我们创建一个索引:
PUT twitter我们通过如下的命令来获得它的设置:
GET twitter/_settings上面的命令将返回如下的结果:
{
"twitter": {
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "twitter",
"creation_date": "1666154335009",
"number_of_replicas": "1",
"uuid": "eB0EHEBFRHeoAZjdXLnFeA",
"version": {
"created": "8040399"
}
}
}
}
}我们可以看到在默认的情况下, number_of_shards 的数值为 1,也即一个 primary shard。同时它的 number_of_replicas 的值为 1,也即一个 replica。你可以在创建索引的时候,指定 number_of_shards 为超过 1 的数值。最多可以达到 1024。比如:
PUT twitter
{
"settings": {
"number_of_shards": 4,
"number_of_replicas": 2
}
}如果你已经创建了索引,那么再重新定义 number_of_shards 时,你需要 reindex 才可以。
我们该如何计算多少个 shard 呢?如上所示,假如我们定义创建的索引 twitter 含有 4 个 primary shards 及 2 个 replica shards,那么:
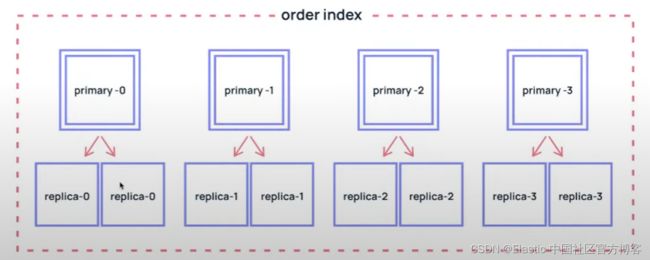
针对这个 twitter 索引,我们供需要 4 个 primary shards 以及 8 个 replica shards。这样我们供需要 8 + 4 = 12 个 shards。
如果我们为一个索引分配更多的 primary shards,则意味着:
- 跟多的并行处理 indexing。当我们向集群同时写入大量数据时,那么有更多的 primary shards 可以同时对写入的文档进行分词处理从而提高写入的速度
- 对搜索的速度可能稍微有些影响,尽管不是绝对的。这是因为 Elasticsearch 的搜索是一个分布式的,当一个请求发送到一个 coodinating 节点后,它会分发这个搜索到各个节点进行搜索。当每个节点在本地完成了搜索后,它们会把自己的结果一并发送到 coordinating 节点,并进行合并得出最后的结果,比如前十匹配的结果。Primary shard 的数量越多,那么合并的工作会更多。
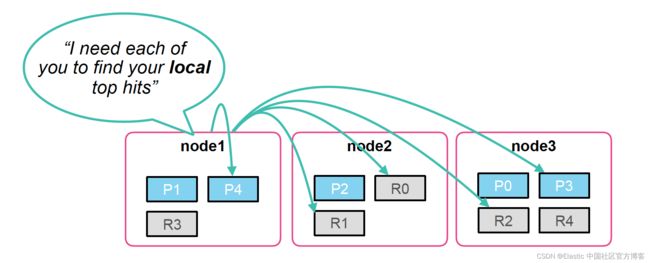
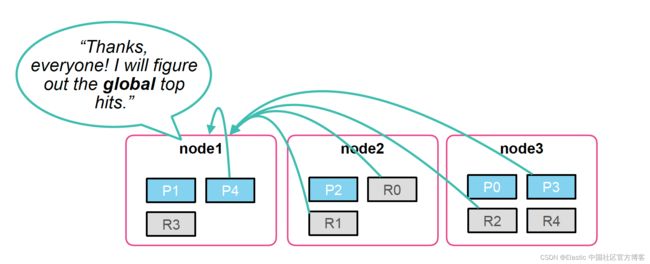
在实践中,为了更好的搜索效果,我们建议每个 shard 的大下位于 10 GB 到 50 GB 之间:
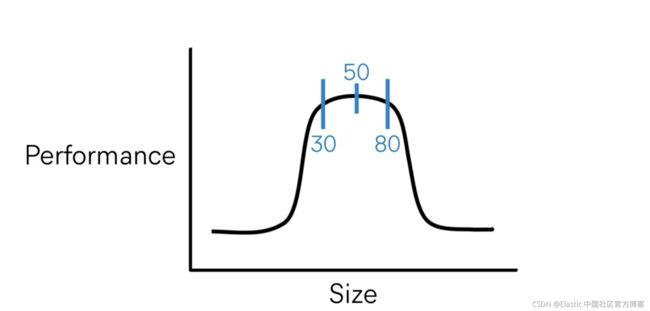
为了达到调优,一般可以考虑针对 search 使用案例时,shard 的大小为 25 GB。不要超过 50 GB。
更大的 shard 大小很难是一个集群在经历失败后恢复过来,这是因为更难把一个 shard 从一个节点移动到另外一个节点,特别是一个节点在进行维护时。
针对每个 GB 的 heap 内存,我们希望对于的 shard 数量是 20,尽管这个在 Elastic Stack 8.3 版本发布后有所改变。详细规则请阅读链接。依据这个原则,假如我们有 30 GB 的 heap 内存,那么我们理想的 shard 数量应该为 600 个。
分配多少个 shards 及多少个 nodes?
我们可以参考之前的文章 “Elasticsearch:我的 Elasticsearch 集群中应该有多少个分片?” 做更进一步的阅读。根据一些公司的经验,我们可以简单地做如下的表述:
Number of shards = (SourceData + Room to Grow) x (1 + 10% Indexing Overhead) / Desired Shard Size我们可以根据一下的公式计算出需要多少存储:
Minimum storage required = SourceData x (1+ Number of Replicas) x 1.45在上面,这个系数 1.45 包含 Elasticsearch, 索引以及 Linux kernel 的开销。
针对一个处理复杂聚合,搜索强求以及高输出,经常更新的集群来说,我们可以通过如下的公式来计算 CPU 以及内存的需求:
node config = 2 vCPU and 8GB memory for every 100 GB of storage重要的是,在设置 Elasticsearch 的节点 JVM heap 大小不要超过 50% 的机器物理内存,并且这个数值不可以超过 32 GB。
下面,我们以一个简单的例子来展示上面的公式。假设我们有 150 GB 的数据需要索引到 Elasticsearch 集群。假如你这个数据是静态的,并且将来不会有增长,那么我们可以可以计算出 primary shards 的数量:
Number of primary shards (starting from scratch or no growth) = (150+0) x 1.10 / 25 = 7在上面,我们假设每个 shard 的大小为 25 GB。上面的公式给出的结果为 7,也即我们需要有 7 个 primary shards。
假如,你在未来的一年,可能需要有 150 GB 的大小增长,那么我们可以使用如下的公式来算出 primary shards 的数量:
Number of primary shards (with 100% growth in a year) = (150+150) x 1.10 /25 = 13上面的公式给出的结果约为 13,也即我们需要有 13 个 primary shards。
这个在实际的使用中非常重要,因为一旦我们定义好 primary shards 的数量,那么我们就不能再改动了,除非我们创建一个新的索引,并使用 reindex 包数据重新写入。
我们再假设我们有一个比较小的 Elasticsearch 集群,它含有 3 个节点 (master + data)。同时,我们假设我们的每个 shard 有一个 replica。我们通过如下的公式来计算最小的存储空间:
Minimum storage required = 150 x (1+1) x 1.45 = 435 GB上面的公式给出的答案是 435 GB。
我们通过如下的公式来计算内存的要求:
Compute and Memory = 435 x (2 vCPU and 8 GB memory)/100 = 9 vCPUs and 35 GB of memory根据上面的计算,我们的3个节点,每个需要有 3 vCPUs,12 GB 内存 以及 150 GB 的磁盘存储。
我们的每个节点含有 12 GB 的内存,我们可以设置 JVM 的 heap 大小为 6GB 。这个相当于每个节点最多含有 120 个 shards。3 个节点总共最多含有 360 个shards。
如果你需要检测你的配置,你可以使用 Elastic 官方提供的工具 GitHub - elastic/rally: Macrobenchmarking framework for Elasticsearch。