NLP冻手之路(1)——中文/英文字典与分词操作(Tokenizer)
✅ NLP 研 0 选手的学习笔记
文章目录
- 一、需要的环境
- 二、字典的使用
- 三、简单的编码与解码
- 四、增强的编码与解码
- 五、批量的编码与解码
- 五、批量成对的编码与解码
- 六、补充说明
一、需要的环境
● python 需要 3.6+,pytorch 需要 1.10+
● 本文使用的库基于 Hugging Face Transformer,官网链接:https://huggingface.co/docs/transformers/index 【一个很不错的开源网站,针对于 transformer 框架做了很多大集成,目前 github 72.3k ⭐️】
● 安装 Hugging Face Transformer 的库只需要在终端输入 pip install transformers【这是 pip 安装方法】;如果你用的是 conda,则输入 conda install -c huggingface transformers
二、字典的使用
● 首先,我们导入 transformers 库的 BertTokenizer 类,并 print 一下它的 help 信息,待会我们要用它来做分词。
from transformers import BertTokenizer
print("BertTokenizer:", help(BertTokenizer))
● 结果非常的大,有 6 万多字的说明,你可以将其作为参考说明书来 ctrl+F 使用:
● 我们调用 BertTokenizer 类里面的 from_pretrained 函数,来构造一个 字典。
# 不同模型的分词方法是不同的
my_tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='bert-base-chinese', # 下载基于 BERT 模型的分词方法的中文字典包
cache_dir='./my_vocab', # 字典的下载位置
force_download=False # 不会重复下载
) # 执行这条语句时会加载一点时间
● 然后多出一个名为 my_vocab 的文件夹,里面装有我们的 字典。记事本打开如下,其中 行号-1 代表的是一个中文分词的对应的 token。
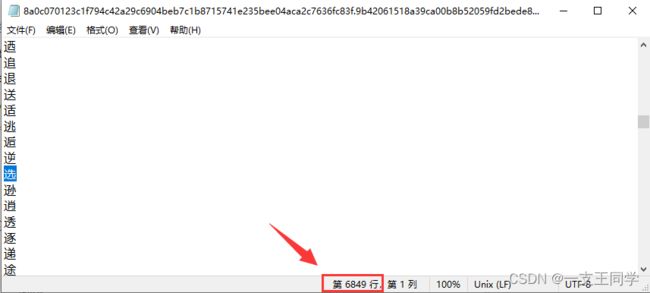
● 我们可以获取 字典 ,并看看 选 这个字所对应的 token 是多少?如下框所示,6848 正好是上图的 行号-1。为什么这样呢?因为 txt 文本的行是从 1 开始的,而 字典 的 token 的是从 0 开始算的。
# 获取字典
zidian = my_tokenizer.get_vocab()
print(type(zidian), len(zidian), zidian['选'])
输出结果为:
<class 'dict'> 21128 6848 # 21128 是字典的大小(即字的个数)
● 字典 里的中文 token 一般都是一个字儿一个字儿的,并没有像 哈喽 这样的词语,那我们其实也可以添加进去:【注:这个添加是在缓存中添加,并没有在那个下载下来的 txt 中添加】
print('哈喽' in zidian) # 查看 '哈喽' 这个东西是否在字典中
my_tokenizer.add_tokens(new_tokens=['哈喽', '蓝天']) # 添加新词
my_tokenizer.add_special_tokens({'eos_token': '[EOS]'}) # 添加新符号, EOS: end of sentence
zidian = my_tokenizer.get_vocab() # 再次获取字典
print('哈喽' in zidian, zidian['哈喽'], zidian['[EOS]']) # zidian['哈喽']: 可查看 '哈喽' 这个东西在字典中位置
输出结果为:
False
True 21128 21130
三、简单的编码与解码
● 首先,我们定义一个装有三个句子且名为 test_sentences 的 list 。
test_sentences = [
'这笔记本打游戏很爽!',
'i like to eat apple.',
'研0的日子也不好过啊,呜呜呜。',
'一二三四五,12 345.'
]
● 调用 BertTokenizer 类中的简单编码函数 encode 和 解码函数 decode 如下。编码:即把每一个 字 在 字典 中所对应的 token 找到,然后替换掉,并且加入 special_tokens。解码:即把所有的 token 转换为原来的 字(注意:像 [EOS]、[PAD] 这样的东西可理解为广义的 字;另外,英文的话,一个单词才是一个 字)。
# 简单的编码
encode_output = my_tokenizer.encode(
text=test_sentences[0], # 第一个句子, 即 '选择珠江花园的原因就是方便。'
text_pair=test_sentences[1], # 第二个句子, 即 '这笔记本打游戏很爽!'
max_length=30, # 编码一个句子的最大长度
truncation=True, # 当句子长度大于 max_length 时, 截断
add_special_tokens=True, # 加入特殊的 token, 例如 [CLS]、[SEP]
padding='max_length', # 一律补 pad 到 max_length 长度
return_tensors=None, # 默认用 list 形式返回
)
print("encode_output:", encode_output)
decode_output = my_tokenizer.decode(encode_output)
print("decode_output:", decode_output)
输出结果为:
encode_output: [101, 6821, 5011, 6381, 3315, 2802, 3952, 2767, 2523, 4272, 8013, 102, 151, 8993, 8228, 9714, 8165, 8350, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
decode_output: [CLS] 这 笔 记 本 打 游 戏 很 爽 ! [SEP] i like to eat apple. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
四、增强的编码与解码
● 调用 BertTokenizer 类中的增强的编码函数 encode_plus 和 解码函数 decode 如下。增强的功能见注释。
# 增强的编码函数
encode_plus_output = my_tokenizer.encode_plus(
text=test_sentences[0],
text_pair=test_sentences[1],
truncation=True,
max_length=30,
padding='max_length',
add_special_tokens=True,
return_tensors=None,
return_token_type_ids=True, # 返回 token_type_ids
return_attention_mask=True, # 返回 attention_mask
return_special_tokens_mask=True, # 返回 special_tokens_mask
return_length=True, # 返回合并后的整个句子长度
)
for k, v in encode_plus_output.items():
print(k, ':', v)
decode_output = my_tokenizer.decode(encode_plus_output['input_ids'])
print("decode_output:", decode_output)
# input_ids: 编码后的 token
# token_type_ids: 第一个句子和特殊符号的位置是 0 , 第二个句子的位置是 1
# special_tokens_mask:特殊符号的位置是 1 , 其他位置是 0
# attention_mask: 其中 pad 的位置是 0 , 其他位置是 1
# length: 合并后的整个句子长度
输出:
input_ids : [101, 6821, 5011, 6381, 3315, 2802, 3952, 2767, 2523, 4272, 8013, 102, 151, 8993, 8228, 9714, 8165, 8350, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
token_type_ids : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
special_tokens_mask : [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
attention_mask : [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
length : 30
decode_output: [CLS] 这 笔 记 本 打 游 戏 很 爽 ! [SEP] i like to eat apple. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
五、批量的编码与解码
● 调用 BertTokenizer 类中的批量增强编码函数 batch_encode_eplus 和 批量解码函数 batch_decode 如下。批量的功能见注释。
# 批量的编码函数
encode_plus_output = my_tokenizer.batch_encode_plus(
batch_text_or_text_pairs=[test_sentences[0], test_sentences[1], test_sentences[2]], # 批量的 batch_size 为 3
truncation=True,
max_length=20,
padding='max_length',
add_special_tokens=True,
return_tensors=None,
return_token_type_ids=True,
return_attention_mask=True,
return_special_tokens_mask=True,
return_length=True,
)
for k, v in encode_plus_output.items():
print(k, ':', v)
decode_output = my_tokenizer.batch_decode(encode_plus_output['input_ids']) # 批量解码函数
print("decode_output:", decode_output)
输出:
input_ids : [[101, 6821, 5011, 6381, 3315, 2802, 3952, 2767, 2523, 4272, 8013, 102, 0, 0, 0, 0], [101, 151, 8993, 8228, 9714, 8165, 8350, 119, 102, 0, 0, 0, 0, 0, 0, 0], [101, 4777, 121, 4638, 3189, 2094, 738, 679, 1962, 6814, 1557, 8024, 1449, 1449, 1449, 102]]
token_type_ids : [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
special_tokens_mask : [[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]]
length : [12, 9, 16]
attention_mask : [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
decode_output: ['[CLS] 这 笔 记 本 打 游 戏 很 爽 ! [SEP] [PAD] [PAD] [PAD] [PAD]', '[CLS] i like to eat apple. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]', '[CLS] 研 0 的 日 子 也 不 好 过 啊 , 呜 呜 呜 [SEP]']
五、批量成对的编码与解码
● 为什么要 批量成对 呢?因为后续在实际的模型训练中要用到这个方法,所以得学习一下。与 “四、批量的编码与解码” 不同的一点在于 batch_text_or_text_pairs 的设置。
# 批量成对的编码函数
encode_plus_output = my_tokenizer.batch_encode_plus(
# 在一个 batch 中, 有 2 个 tuple, 每个 tuple 中有 2 个句子(这两个句子就是 "成对" 的意思)
batch_text_or_text_pairs=[(test_sentences[0], test_sentences[1]), (test_sentences[2], test_sentences[3])],
truncation=True,
max_length=30,
padding='max_length',
add_special_tokens=True,
return_tensors=None,
return_token_type_ids=True,
return_attention_mask=True,
return_special_tokens_mask=True,
return_length=True,
)
for k, v in encode_plus_output.items():
print(k, ':', v)
decode_output = my_tokenizer.batch_decode(encode_plus_output['input_ids']) # 批量解码函数
print("decode_output:", decode_output)
输出:
input_ids : [[101, 6821, 5011, 6381, 3315, 2802, 3952, 2767, 2523, 4272, 8013, 102, 151, 8993, 8228, 9714, 8165, 8350, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 4777, 121, 4638, 3189, 2094, 738, 679, 1962, 6814, 1557, 8024, 1449, 1449, 1449, 511, 102, 671, 753, 676, 1724, 758, 8024, 8110, 11434, 119, 102, 0, 0, 0]]
token_type_ids : [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]]
special_tokens_mask : [[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]]
length : [20, 27]
attention_mask : [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]]
decode_output: ['[CLS] 这 笔 记 本 打 游 戏 很 爽 ! [SEP] i like to eat apple. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]', '[CLS] 研 0 的 日 子 也 不 好 过 啊 , 呜 呜 呜 。 [SEP] 一 二 三 四 五 , 12 345. [SEP] [PAD] [PAD] [PAD]']
# 注意:对于 “12 345” 这句话而言,中间的 空格 相当于把 “12345” 分成了两个 字,分别是 “12” 和 “345”,而那个 空格,是不算 字 的。
六、补充说明
● 若有写得不对的地方,或有疑问,欢迎评论交流。
● 参考视频:HuggingFace简明教程,BERT中文模型实战示例.NLP预训练模型,Transformers类库,datasets类库快速入门.
⭐️ ⭐️