APE:基于多文本的论辩对挖掘 — 任务、数据及模型

©作者 | 程丽颖、鲍建竹、邴立东、徐睿峰
单位 | 阿里巴巴达摩院、鹏城实验室
简介
大多数现有论辩挖掘的任务是基于单一文本进行抽取,如法律文件、议论文等。现有的基于多文本的论辩挖掘仅限于论坛上的在线讨论或辩论。近年来由于论文投稿量的增加,以及开源可供研究使用的审稿意见(review)数据的出现,针对审稿意见的论辩挖掘研究逐渐受欢迎。然而,作为在审稿周期中非常重要的作者回复(rebuttal),却没有被研究者充分重视。事实上,审稿意见与其回复在内容和结构上有着密不可分的联系,天然构成一对立论和反驳的文档对。
所以本文介绍的第一个工作,即 APE,提出了一个针对审稿意见与其回复的论辩对挖掘的新任务和新数据集。本文介绍的其他三篇工作又陆续针对该任务,在第一个工作的基准模型的基础上分别提出了新模型,在同一个数据集上取得了更好的结果。
该任务和数据集曾被用于阿里巴巴达摩院和复旦大学共同组织的 NLPCC 2021 “面向智能辩论的论辩文本理解”的评测任务比赛。另外,本文中介绍的几种针对论辩对挖掘的模型结果可参见以下链接。这些模型可以被广泛应用于辩论相关的场景、论辩挖掘以及篇章级别信息抽取的研究中。
https://paperswithcode.com/sota/argument-pair-extraction-ape-on-rr

APE任务和数据集介绍
1.1 APE任务介绍
论辩对抽取(Argument Pair Extraction,APE),是对话式论辩领域的一个新任务,目的是从两篇相关的文章中抽取互动的论点对。下图是一个 APE 的例子,来自 Review-Rebuttal 数据集,左边是论文的审稿意见(review),右边是作者的回复(rebuttal)。两篇文章在句子级别上被划分为论点和非论点。有颜色的为论点,没有颜色的为非论点。Review 中的论点可以与 rebuttal 中的论点形成论辩对,表示它们在讨论同一问题。在这个例子中,两个论点对分别用绿色和蓝色标注出。
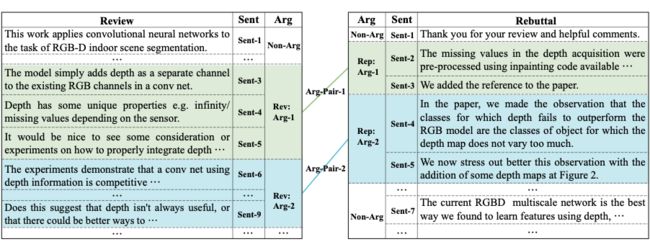
APE 是一项非常有挑战的任务,原因有两个:1)从数据的层面看,不同于常见的抽取任务,本任务所面对的文本非常长,并且是两篇文章。2)从任务定义的层面看,不同于传统的论辩关系预测任务,本任务需要首先抽取出论点,然后再判断论点间的关系。
1.2 Review-Rebuttal(RR)数据集介绍
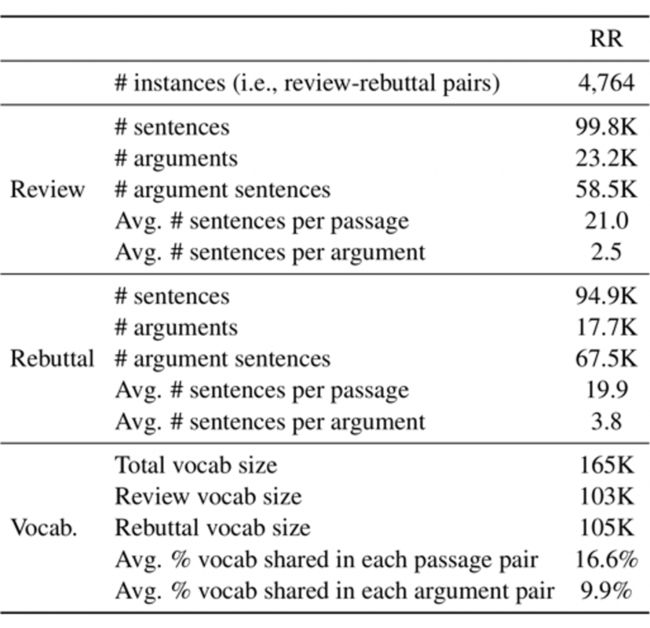
关于 Review-Rebuttal(RR)数据集,我们从 openreview.net 网站爬取了 ICLR会议 2013-2020 年间(2015 年除外)投稿的相关数据,并筛选出 4,764 对审稿意见和回复。数据统计如上图所示。我们共标注了 40831 条论点,其中审稿意见中的论点有 23150 条,作者回复的论点有 17681 条。每对论点的共享词汇的比例仅有 9.9%,进一步说明了该数据集的挑战性。
我们将 RR 数据集按每篇审稿和每篇论文两种粒度划分训练/验证/测试集,得到两个数据集,RR-passage 和 RR-submission。在本文提到的第二个工作中,我们在 RR-submission 做了一点小改动得到 RR-submission-v2 数据集。本文展示的实验结果主要是在 RR-submission 和 RR-submission-v2 上得到的。
数据集链接:
https://github.com/LiyingCheng95/ArgumentPairExtraction/tree/master/data

APE: 审稿意见与回复中的论辩对挖掘及多任务训练模型

论文标题:
APE: Argument Pair Extraction from Peer Review and Rebuttal via Multi-task Learning
收录会议:
EMNLP 2020
论文链接:
https://aclanthology.org/2020.emnlp-main.569.pdf
数据代码:
https://github.com/LiyingCheng95/ArgumentPairExtraction
2.1 简介
根据前文提到的背景,本篇论文提出了一个针对审稿意见与其回复的论辩对挖掘的新任务。同时我们基于此任务创建了一个完全标注的新数据集,可被应用于相关任务的研究。另外,我们针对此任务提出了一个多层长短期记忆结构的多任务训练模型,有效地结合了两个子任务。
2.2 模型结构
在本篇论文中,我们将论辩对挖掘的任务分成两个子任务:(1)论辩挖掘,(2)论辩配对。我们把论辩挖掘子任务看作一个句子级别的序列标注问题,用 IOBES 的标签区分抽取到的论点和非论点部分。而我们把论辩配对子任务当作一个句子级别的二分类问题。我们对审稿意见中的每句话和回复中的每句话两两配对并进行而分类。如果这两句话都是论点并且属于同一个论辩对,我们就标为1;否则标为 0。
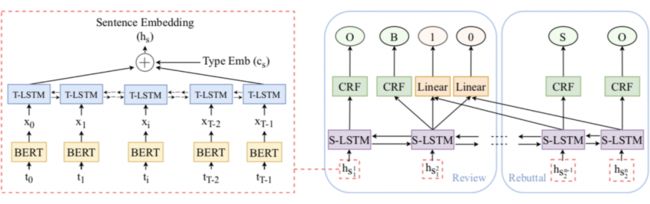
上图展示了本文提出的一个多层长短期记忆结构的多任务训练模型框架。左侧的红色虚线框展示了我们的句子编码器。该编码器使用 BERT 预训练的单词表示作为单词级别长短期记忆(T-LSTM)的输入来获取句子表示。然后,我们将得到的句子表示输入进句子级别长短期记忆(S-LSTM),以对整个段落的每句话进行序列标注。最后,根据 S-LSTM 生成的共享句子表示,同时预测两种类型的标签,即 IOBES 和 1/0。上述过程是一个多任务训练。
在预测过程中,经过训练的多任务模型将被分解为两个子模块,以流水线方式执行两个子任务,以提取最终的论辩对。此多任务训练模型很好地利用了辩论文本中一问一答相辅相成的内容与结构关系,相比于管道结构学到了更好的共享句子表示,从而达到更好的论辩对挖掘结果。
2.3 主要结果
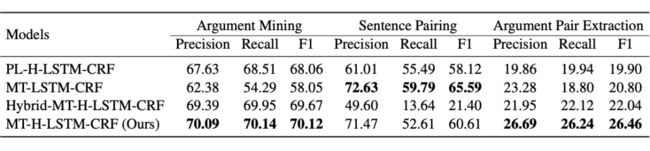
我们在 RR-submission 数据集上进行了实验。PL-H-LSTM-CRF 是一个管道结构模型,对两个子任务单独进行训练。虽然它在两个子任务上都有不错的表现,但是综合结果并不如我们提出的多任务训练模型(MT-H-LSTM-CRF)理想,从而验证了多任务训练的有效性和重要性。

MLMC: 注意力机制引导的多层多交编码

论文标题:
Argument Pair Extraction via Attention-guided Multi-Layer Multi-Cross Encoding
收录会议:
ACL 2021
论文链接:
https://aclanthology.org/2021.acl-long.496.pdf
数据代码:
https://github.com/TianyuTerry/MLMC
3.1 简介
上一节中提出的论辩对挖掘任务的处理方法,包括管道结构的模型以及基于多层长短期记忆结构的多任务训练模型 [1]。两种模型均在基准数据集上取得了一定的结果。管道结构按先后顺序依次单独训练两个子任务,不能很好地结合两个相辅相成的子任务之间的联系。
而后提出的多任务训练模型也有两个主要缺点。第一,多任务训练模型会把两个文本连在一起当作一个长文本,去用序列标注的方法训练论辩挖掘的子任务。然而两个文本自身通常是不同的风格和结构,所以把它们连在一起当作同一个文本进行训练不够合理。第二,两个子任务仅仅是通过长短期记忆结构进行交互,这样的结构使得两个子任务交互能力相对较弱,同时两者间共享的信息也只是被隐性地去学习。
针对现有模型中的缺陷,同时受到 [2][3][4] 等工作的启发,我们提出了一个注意力机制引导的多层多交编码器模型(MLMC)。此模型用两个序列编码器单独处理两个文本,并利用彼此的信息通过注意力机制进行更新每个文本的表示,同时利用表格填充的方法设计了一个表格编码器学习两个文本之间的关系。我们在同样基准数据集上进行验证,得到更好的表现结果。
3.2 模型结构
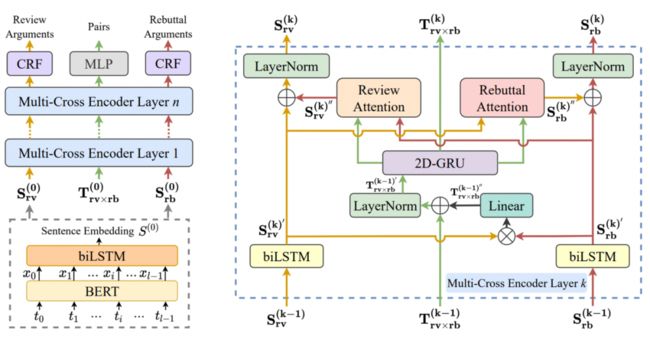
我们的模型的整体框架如图中左边所示。它可以被简单地分为三个主要组成部分:句子嵌入器、多层多交编码器、论辩对预测器。
首先,左下角灰色虚线框内展示了句子嵌入器。我们把句子中每个词通过 BERT 得到每个词的表示,进一步通过一个长短期记忆结构得到句子的表示。于是,我们可以得到两个文本各自的句子序列表示;同时,我们用两个序列的笛卡尔积作为表格的表示。
接着,两个序列表示和表格表示进入多层多交编码器。每一层的多交编码器如图中右边部分所示。两个序列表示会通过两个序列编码器利用彼此的信息进行更新。表格表示会借助于两个序列表示以及上一层的表格表示通过表格编码器进行更新。在序列编码器中,我们应用了交互注意力机制,有效连接了表格表示和两个序列表示,两个序列之间的信息也在交互注意力机制中进行了一定的交换。
最后,多层多交编码器得到的两个序列表示会通过条件随机场(CRF)来预测论辩挖掘子任务的序列标注结果,而表格表示会通过多层感知器(MLP)来预测论辩配对情况。我们会综合两个子任务的结果得到论辩对挖掘任务的结果。与此同时,我们设计了辅助注意力机制的损失函数,去进一步增强注意力机制的作用。
3.3 主要结果
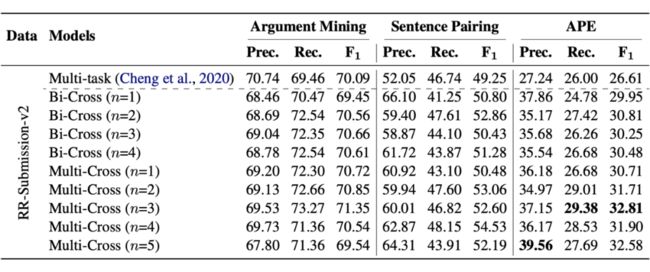
我们在 RR-Submission 数据集上进行了实验。Multi-task 模型是第二小节工作中的多任务模型。在 Bi-Cross 模型中,我们把 rebuttal 的内容接在 review 后面当作一个长句子序列进行训练。Multi-Cross 是本文提出的 MLMC 模型。
通过结果我们发现,Bi-Cross 和 Multi-Cross 模型都比上一篇工作的多任务模型表现要好,而 Multi-Cross 模型的表现会在 Bi-Cross 模型的基础上有进一步提高。这样的结果,一方面说明了要把两个序列单独处理的重要性,另一方面也说明了这样的模型结构有助于不同组成部分之间更好的交互。
更多实验结果分析可以参见我们的论文。

结合互指导与句间关系图的论点对抽取

论文标题:
Argument Pair Extraction with Mutual Guidance and Inter-sentence Relation Graph
收录会议:
EMNLP 2021
论文链接:
https://aclanthology.org/2021.emnlp-main.319.pdf
代码链接:
https://github.com/HLT-HITSZ/MGF
4.1 简介
前人 [5] 的工作将 APE 分解为两个子任务去解决,一个是句子级别的序列标注任务,另一个是句子关系分类任务,两个子任务在一个多任务学习的框架中共同被优化。然而,虽然效果不错,但这种方法仅仅通过两个子任务的预测结果来间接得到论点对,缺少对于论点级别互动信息的明确建模。同时,两个子任务在学习过程中可能不能很好地相互适应。
本文中,我们通过一个互指导的框架来解决论辩对抽取任务,该方法能够利用一篇文章中的论点信息去指导另一篇文章中能够与其配对的论点的识别。用这种方式,两篇文章能够在抽取论辩对的过程中相互指导。此外,受 [6]、[7] 等工作的启发,我们还提出了一个句间关系图来高效建模句子之间的关系,从而辅助论点对抽取。实验结果显示我们的方法大幅超过了现有的 sota 模型。进一步的分析显示了互指导框架和句间关系图的有效性。另外,我们的方法在抽取一对多的 argument pair 时更有优势。
4.2 模型结构
我们提出结合句间关系图的互指导框架,用于解决论点对抽取任务。下图是总体的模型图。我们首先将句子进行编码,然后使用一个无指导的序列标注器去识别 review 和 rebuttal 中所有潜在的论点。之后,在通过图卷积得到关系增强的句子表示后,两个相互指导的序列标注器被用来抽取论点对。我们的方法能够更好地建模整体的论点级别的语义信息,从而显示地捕捉论点对之间的复杂联系。
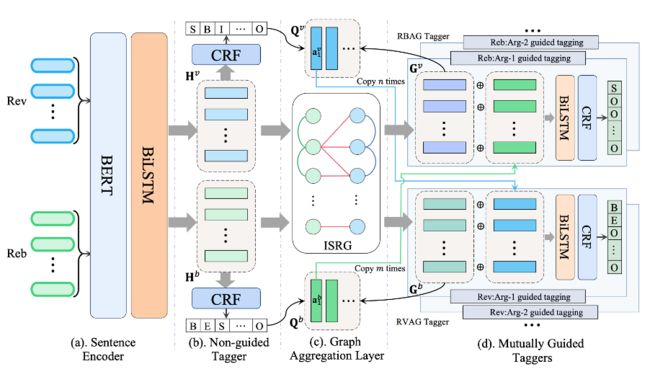
句间关系图:
首先介绍句间关系图的构建。我们使用这个句间关系图的目的是捕捉句子之间的潜在关系。该图将 review 和 rebuttal 中的每个句子视作节点,然后从两个角度来构图。从文章内的角度来看,我们基于句子间的相对位置关系来构建边。从跨文章的角度来看,我们基于句子间的共现词信息来连接边。
互指导框架:
我们使用 BERT 来编码每个句子,然后使用 LSTM 来捕捉句子间的上下文联系。用这种方式,可以得到 review 和 rebuttal 的上下文句子表示矩阵 和 。
此后,我们使用一个序列标注器来识别所有的潜在论点,称作无指导的标注器。它可以为接下来的论点对抽取显示地提供论点 span 信息。这样我们便可以得到 review 和 rebuttal 中的潜在论点 span,即 和 。
下一步,我们将之前得到的句子表示作为句间关系图的节点,然后使用 GCN 来进行信息交换。GCN 最后一层的输出被作为关系增强的句子表示,即 和 。
最后,我们通过两个互指导的序列标注器来抽取论点对,即 review 论点指导的标注器和 rebuttal 论点执导的标注器。对于 review 论点指导的标注器,我们通过平均池化的方式得到每个 review 论点的表示。
为了使 review 论点能够指导 rebuttal 中能够与之配对的论点的识别,我们将该review论点的表示拼接到rebuttal每个句子表示的后面,然后通过一个 LSTM+CRF 序列标注出配对的论点。相似的,rebuttal 论点指导的标注器的可以用同样的方式来进行。
4.3 主要实验结果
我们在 RR-submission 数据集上进行了实验,我们的模型在 APE 任务上比之前的 sota 模型提高了 7.94 个百分点。
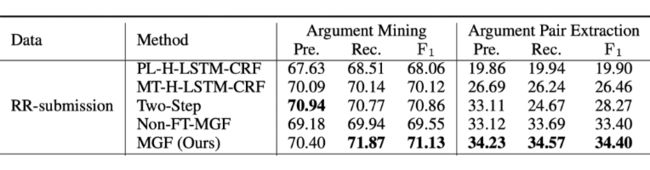
之后,我们进行了消融实验。可以看到,如果没有互指导,性能会大幅下降。此外,还能够看到,句间关系图对于模型的性能贡献也是很大的。
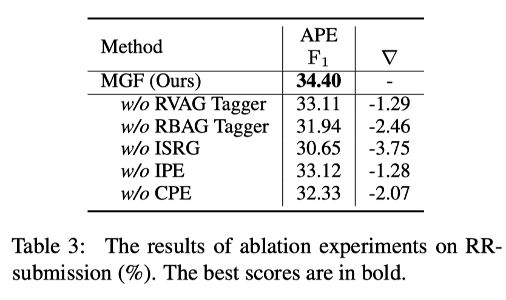
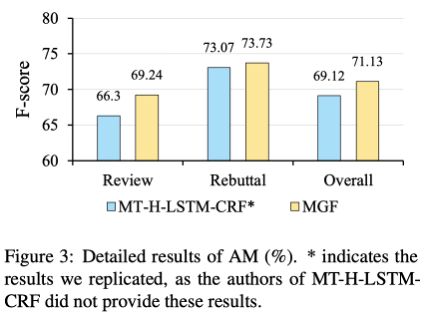
下图显示了论点识别任务的详细结果。由于一般来说 rebuttal 文章的结构和安排更加清晰,模型对于 rebuttal 的论点识别效果更好。尽管我们的模型针对 rebuttal 文章的效果与之前 sota 模型类似,但是我们的模型在更加复杂的 review 文章上取得了明显更高的效果。

基于阅读理解的论点对抽取

论文标题:
Have my arguments been replied to? Argument Pair Extraction as Machine Reading Comprehension
收录会议:
ACL 2022
5.1 简介
以往的用于论点对抽取的模型,将该问题建模为两个句子级别的子问题解决,首先通过序列标注判断每个句子是否属于一个论点,然后判断文章间所有论点中的句子关系,根据句子是否成对来推断论点是否成对 [8] [9]。这类方法忽视了论点级别的关联。
受 [10] [11] 等工作的启发,我们提出了一个两阶段的阅读理解(MRC)模型来解决APE问题,通过将论点作为查询来直接捕获论点与另一篇文章的交互关系,以实现论点级别的论点对抽取。我们在两个阶段中联合训练了一个 MRC 模型,以使两个阶段的训练能相互增益。我们设计的 MRC 模型主要包括两个模块,编码模块和跨度预测模块。由于专利申请原因,论文全文将稍后在 ACL-2022 大会论文集中公布。
5.2 模型结构
论点对抽取任务的目标是从两篇相关的论辩文章中抽取论点对,即,给定两篇互相联系的文档 和 ,目的是抽取出其中讨论同一方面问题的论点对。本方法将论点对抽取(APE)任务建模为机器阅读理解(MRC)任务。我们的 MRC 框架分别在两个阶段使用两种类型的查询,包括论点挖掘(AM)查询和论点对抽取(APE)查询,来解决 APE 问题。
我们提出的方法可以更好地模拟论点级别的交互来进行篇章间的论点对抽取。本方法可从两个方向进行,即,可以用文章 A 中的论点作为查询去寻找文章 B 中的配对论点,反之亦然。后文将以从文章 A 的角度寻找文章B中的配对论点的过程为例,介绍本文方法的两阶段的详细流程。
由于要处理的文章很长,我们采用 Longformer 作为基编码器。在第一阶段中,我们构造 AM 查询来识别文章 A 中的所有论点。具体而言,我们将特殊符号“[AM]”与文章 A 中的 token 拼接来作为 AM 查询 ,其目标是识别出文章A中所有的论点 ,此处, 表示文章 A 中的第 k 个论点。
之后,在第二阶段中,我们将文章 A 中的所有被抽取出论点分别作为 APE 查询,与文章 B 中的 token 拼接输入 Longformer,获得文章 B 中所有 token 的表示,用于寻找文章 B 中与这些论点匹配的论点。具体来说,每个被识别出的论点 将会被作为 APE 查询 。训练过程中,使用真实的论点作为 APE 查询。有了这些查询,将 AM 查询 与文章 A 拼接,作为论点挖掘任务的输入:
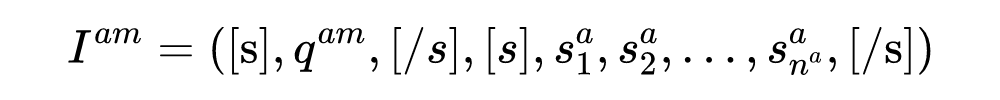
同时,将每个 APE 查询和文章 B 拼接,得到多个针对 APE 任务的输入:
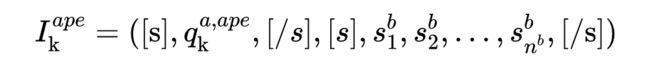
然后,对于上述的每个输入序列,我们都将其输入到 Longformer 中以得到每个 token 的上下文表示。对于每次 Longformer 的输入,我们都对查询部分施加全局注意力,以更好地捕捉查询部分与目标文章间的联系。此后,通过平均池化得到的每个句子的向量表示将会被输入进 LSTM,从而得到最终的上下文句子表示。
对于每阶段阅读理解模型的输入,都可能抽取一到多个句子作为答案跨度。其中,第一阶段阅读理解抽取到的是一篇文章中所有可能的论点,第二阶段阅读理解抽取的是另一篇文章中与目标论点成对的论点。我们分别使用两个二分类器来预测论点在文章中所有可能的开始句位置和结束句位置。然后使用一个跨度分类器来判断任一对开始位置和结束位置是否能组成一个答案论点跨度。这样,有三个交叉熵损失函数作为训练目标,包括开始损失、结束损失和跨度匹配损失。此外,我们使用同一个 MRC 模型在 AM 阶段和 APE 阶段联合训练。
5.3 主要实验结果

对于 AM 任务和 APE 任务,我们的 MRC-APE 模型在 RR-Submission 数据集上取得了最佳性能。此外,在没有使用 Longformer 作为基础编码器的情况下,使用 BERT 作为编码器的 MRC-APE-Bert 也取得了较优秀的表现,表明我们模型的性能提升不仅仅是 Longformer 带来的。此外,在 AM 和 APE 任务上我们的 MRC-APE 模型比两阶段单独训练的 MRC-APE-Sep 模型取得了更好的结果,表明在两个阶段联合训练单个 MRC 模型,可以使模型在两个阶段的表现相互增益。

总结
论辩挖掘作为自然语言处理领域一个较新的领域,近年来受到了不少关注,有着很大的潜力。本文中介绍的针对审稿意见与其回复的论辩对挖掘的新任务是一个重要且值得关注的研究方向,同时我们公布了一个完全标注的数据集以支持该方向的研究。希望和有兴趣的同行一起来推动论辩挖掘任务的发展。

参考文献
[1] Liying Cheng, Lidong Bing, Qian Yu, Wei Lu, and Luo Si. 2020. APE: Argument Pair Extraction from Peer Review and Rebuttal via Multi-task Learning. In Proceedings of EMNLP.
[2] Makoto Miwa and Yutaka Sasaki. 2014. Modeling joint entity and relation extraction with table representation. In Proceedings of EMNLP.
[3] Jue Wang and Wei Lu. 2020. Two are better than one: Joint entity and relation extraction with table-sequence encoders. In Proceedings of EMNLP.
[4] Zhen Wu, Chengcan Ying, Fei Zhao, Zhifang Fan, Xinyu Dai, and Rui Xia. 2020. Grid tagging scheme for aspect-oriented fine-grained opinion extraction. In Findings of EMNLP.
[5] Liying Cheng, Lidong Bing, Qian Yu, Wei Lu, and Luo Si. 2020. APE: Argument Pair Extraction from Peer Review and Rebuttal via Multi-task Learning. In Proceedings of EMNLP.
[6] Gaku Morio and Katsuhide Fujita. 2019. Syntactic graph convolution in multi-task learning for identifying and classifying the argument component. In Proceedings of IEEE.
[7] Kuo Yu Huang, Hen-Hsen Huang, and Hsin-Hsi Chen. 2021. HARGAN: heterogeneous argument attention network for persuasiveness prediction. In Proceedings of AAAI.
[8] Liying Cheng, Lidong Bing, Qian Yu, Wei Lu, and Luo Si. 2020. APE: argument pair extraction from peer review and rebuttal via multi-task learning. In Proceedings of EMNLP.
[9] Liying Cheng, Tianyu Wu, Lidong Bing, and Luo Si. 2021. Argument pair extraction via attention-guided multi-layer multi-cross encoding. In Proceedings of ACL-IJCNLP.
[10] Shaowei Chen, Yu Wang, Jie Liu, and Yuelin Wang. 2021. Bidirectional machine reading comprehension for aspect sentiment triplet extraction. In Proceedings of AAAI.
[11] Yue Mao, Yi Shen, Chao Yu, and Longjun Cai. 2021. A joint training dual-mrc framework for aspect based sentiment analysis. In Proceedings of AAAI.

直播预告

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
