【NLP】情感分析:BERT vs Catboost
作者 | Taras Baranyuk
编译 | VK
来源 | Towards Data Science

介绍
情感分析是一种自然语言处理(NLP)技术,用于确定数据是积极的、消极的还是中性的。
情感分析是基础,因为它有助于理解语言中的情感基调。这反过来又有助于自动排序评论、社交媒体讨论等观点,让你做出更快、更准确的决定。
虽然情感分析在近几年已经非常流行,但是从本世纪初开始,情感分析的研究就一直在进行中。
传统的机器学习方法,如朴素贝叶斯、Logistic回归和支持向量机(SVMs)由于其良好的可扩展性,被广泛应用于大规模情感分析。深度学习(Deep learning,DL)技术已被证明能为各种NLP任务(包括情绪分析)提供更好的准确性;然而,它们的学习速度和使用往往更慢、更昂贵。
在这个故事中,我想提供一个鲜为人知的结合了速度和质量的替代方案。对于推荐方法的结论和评估,我需要一个基线模型。我选择了久经考验的BERT。
数据
社交媒体是一个以前所未有的规模产生大量数据的来源。我将用于这个文章的数据集是冠状病毒tweets NLP:
https://www.kaggle.com/datatattle/covid-19-nlp-text-classification
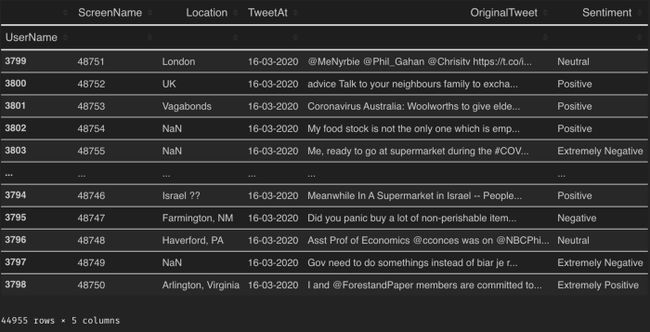
正如我所看到的,这个模型没有那么多的数据,乍一看,似乎没有一个预训练好的模型是不行的。
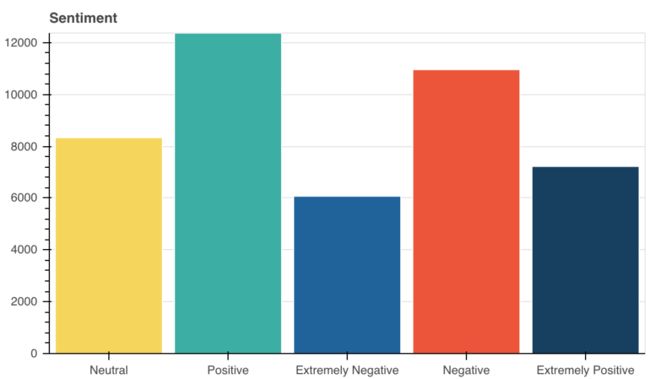
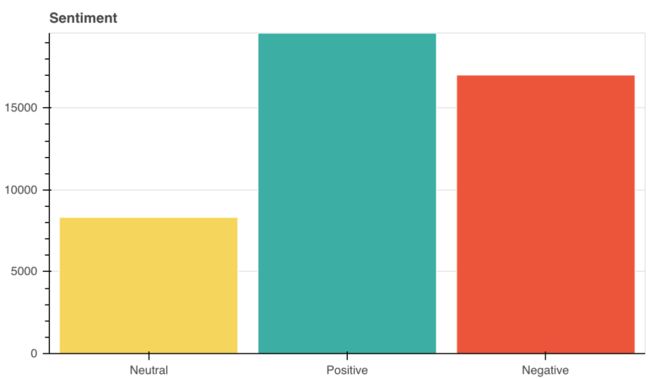
由于训练样本的数量较少,我们将它们结合起来,将类的数量减少到3个。
基线BERT模型
让我们使用TensorFlow Hub。TensorFlow Hub是一个经过训练的机器学习模型库,可以在任何地方进行微调和部署。只需几行代码就可以重用像BERT和Faster R-CNN这样的训练模型。
!pip install tensorflow_hub
!pip install tensorflow_text
small_bert/bert_en_uncased_L-4_H-512_A-8-Smaller BERT模型。这个是一个较小的BERT模型,论文(https://arxiv.org/abs/1908.08962)。
Smaller BERT模型适用于计算资源有限的环境。它们可以按照与原始BERT模型相同的方式进行微调。然而,它们在知识蒸馏的环境中是最有效的。
bert_en_uncased_preprocess-BERT的文本预处理。这个模型使用从维基百科和书库中提取的英语词汇。文本输入采用了“不区分大小写”的方式进行规范化,这意味着在将标记转换为单词片段之前,文本是小写的,并且去掉了任何重音标记。
tfhub_handle_encoder = \
"https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1"
tfhub_handle_preprocess = \
"https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3"
我不会选择参数和优化,以避免复杂的代码。同样,这是基准模型,不是SOTA。
def build_classifier_model():
text_input = tf.keras.layers.Input(
shape=(), dtype=tf.string, name='text')
preprocessing_layer = hub.KerasLayer(
tfhub_handle_preprocess, name='preprocessing')
encoder_inputs = preprocessing_layer(text_input)
encoder = hub.KerasLayer(
tfhub_handle_encoder, trainable=True, name='BERT_encoder')
outputs = encoder(encoder_inputs)
net = outputs['pooled_output']
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(
3, activation='softmax', name='classifier')(net)
model = tf.keras.Model(text_input, net)
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
metric = tf.metrics.CategoricalAccuracy('accuracy')
optimizer = Adam(
learning_rate=5e-05, epsilon=1e-08, decay=0.01, clipnorm=1.0)
model.compile(
optimizer=optimizer, loss=loss, metrics=metric)
model.summary()
return model
我已经创建了一个参数不到3000万的模型。
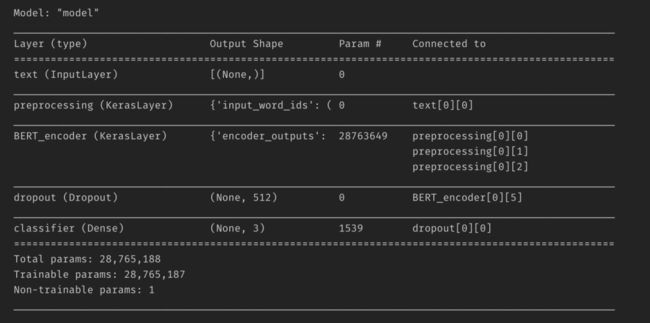
我分配了30%的训练数据用于模型验证。
train, valid = train_test_split(
df_train,
train_size=0.7,
random_state=0,
stratify=df_train['Sentiment'])
y_train, X_train = \
train['Sentiment'], train.drop(['Sentiment'], axis=1)
y_valid, X_valid = \
valid['Sentiment'], valid.drop(['Sentiment'], axis=1)
y_train_c = tf.keras.utils.to_categorical(
y_train.astype('category').cat.codes.values, num_classes=3)
y_valid_c = tf.keras.utils.to_categorical(
y_valid.astype('category').cat.codes.values, num_classes=3)
epoch的数量是凭直觉选择的
history = classifier_model.fit(
x=X_train['Tweet'].values,
y=y_train_c,
validation_data=(X_valid['Tweet'].values, y_valid_c),
epochs=5)

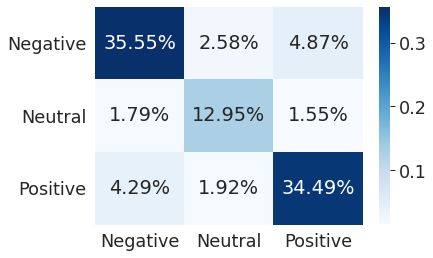
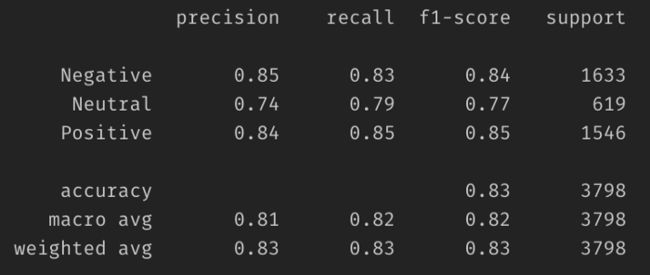
BERT Accuracy: 0.833859920501709
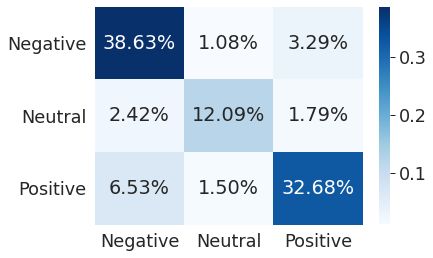
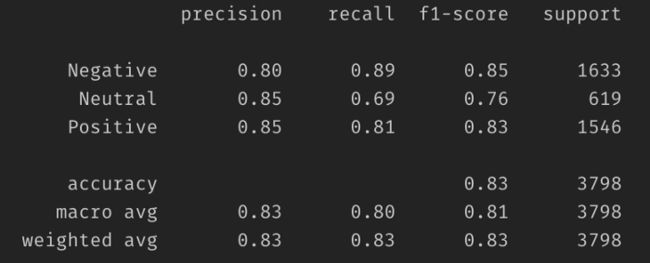
这里是基准模型。显然,该模型还可以进一步改进。但是让我们把这个任务作为你的家庭作业。
CatBoost模型
CatBoost是一个高性能的开源库,用于在决策树上进行梯度增强。从0.19.1版开始,它支持在GPU上进行文本分类。
主要优点是CatBoost可以在数据中包含分类函数和文本函数,而无需额外的预处理。对于那些重视推理速度的人来说,CatBoost预测的速度是其他开源梯度增强库的20到40倍,这使得CatBoost对于延迟关键任务非常有用。
!pip install catboost
我不会选择最佳参数,那是你的另一个作业。让我们编写一个函数来初始化和训练模型。
def fit_model(train_pool, test_pool, **kwargs):
model = CatBoostClassifier(
task_type='GPU',
iterations=5000,
eval_metric='Accuracy',
od_type='Iter',
od_wait=500,
**kwargs
)
return model.fit(
train_pool,
eval_set=test_pool,
verbose=100,
plot=True,
use_best_model=True)
使用CatBoost时,我建议使用池。这个池是一个方便的包装器,它结合了特征、标签和元数据,比如分类特征和文本特征。
train_pool = Pool(
data=X_train,
label=y_train,
text_features=['Tweet']
)
valid_pool = Pool(
data=X_valid,
label=y_valid,
text_features=['Tweet']
)
text_features -文本列索引(指定为整数)或名称(指定为字符串)的一维数组。参数是一个二维特征矩阵(有以下类型之一:list, numpy.ndarray, pandas.DataFrame, pandas.Series)。
如果将该数组中的任何元素指定为名称而不是索引,则必须提供所有列的名称。为此,可以使用该构造函数的feature_names参数显式地指定它们,或者在data参数中传递一个指定列名的pandas.DataFrame。
支持的训练参数:
tokenizers-tokenizer用于在创建字典之前预处理文本类型特征列。
dictionaries-用于预处理文本类型特征列的字典。
feature_calcers—特征分解器,用于根据预处理的文本类型特征列计算新特征。
我直观地设置了所有的参数;调整它们将再次成为你的作业。
model = fit_model(
train_pool, valid_pool,
learning_rate=0.35,
tokenizers=[
{
'tokenizer_id': 'Sense',
'separator_type': 'BySense',
'lowercasing': 'True',
'token_types':['Word', 'Number', 'SentenceBreak'],
'sub_tokens_policy':'SeveralTokens'
}
],
dictionaries = [
{
'dictionary_id': 'Word',
'max_dictionary_size': '50000'
}
],
feature_calcers = [
'BoW:top_tokens_count=10000'
]
)
准确率
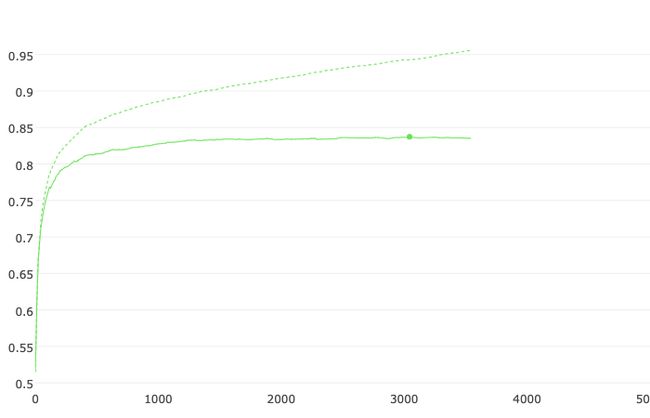
LOSS
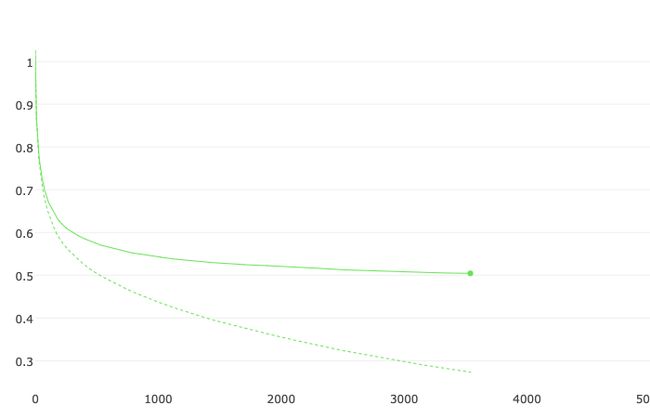
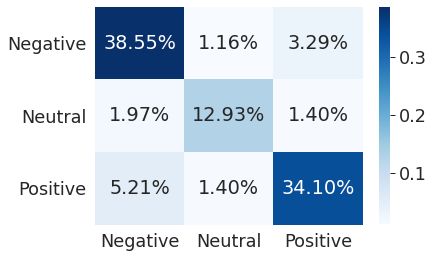
CatBoost model accuracy: 0.8299104791995787
结果非常接近于基线BERT模型所显示的结果。因为我几乎没有训练的数据,而且模型是从零开始学习的,所以在我看来,结果令人印象深刻。
额外
我得到了两个模型,结果非常相似。这能给我们提供什么有用的信息吗?这两种模式在核心上几乎没有共同点,这意味着它们的结合将产生协同效应。检验这一结论的最简单方法是将结果取平均值,然后看看会发生什么。
y_proba_avg = np.argmax((y_proba_cb + y_proba_bert)/2, axis=1)
提升很不错。
Average accuracy: 0.855713533438652
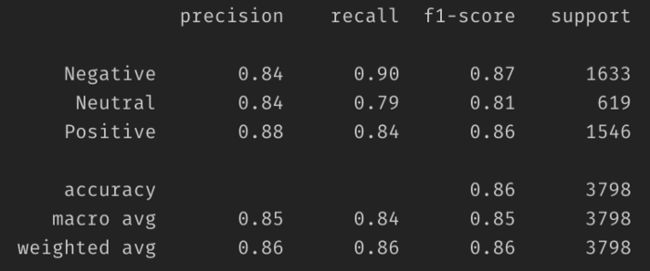
结尾
在这个故事中,我:
利用BERT建立基线模型;
创建了一个CatBoost模型;
平均两个模型的结果会发生什么。
在我看来,在大多数情况下,复杂和缓慢的SOTA是可以避免的,特别是在速度是一个关键需求的情况下。
CatBoost提供了很好的情感分析功能。对于Kaggle、DrivenData等竞赛爱好者来说,CatBoost可以提供一个好的模型,既可以作为基线解决方案,也可以作为模型集合的一部分。
本文中的代码可以在这里查看:
https://github.com/sagol/catboost_sentiment/blob/main/catboost_sentiment_analysis.ipynb
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑温州大学《机器学习课程》视频
本站qq群851320808,加入微信群请扫码: