[TFA] Frustratingly Simple Few-Shot Object Detection(ICML. 2020)
1. Contribution
分类任务上的few-shot研究较多,相比之前FSOD收到较少的关注。
-
Detecting rare objects from a few examples is an emerging problem.
-
However, much of this work has focused on basic image classification tasks. In contrast, few-shot object detection has received far less attention.
目前一些已经存在评估的问题阻碍了模型的对比。
-
Several issues with the existing evaluation protocols prevent consistent model comparisons.
-
In this work, we propose improved methods to evaluate few-shot object detection.
-
We adopt a two-stage training scheme for fine-tuning as shown in Figure 1
-
We find that this two-stage fine-tuning approach (TFA) out- performs all previous state-of-the-art meta-learning based methods by 2~20 points on the existing on the existing PASCAL VOC and COCO benchmarks.
-
We sample different groups of few-shot training examples for multiple runs of the experiments to obtain a stable accuracy estimation and quantitatively analyze the variances of different evaluation metrics.
2. Related Work
Meta-Learning
元学习是获取元知识从而来帮助模型更快的适应少样本标注的新任务。主要方法有通过学习fine-tune以及好的权重参数初始化;以及在novel tasks中使用权重生成的方法。
-
The goal of meta-learning is to acquire task-level meta knowledge that can help the model quickly adapt to new tasks and environments with very few labeled examples.
-
Some learn to fine-tune and aim to obtain a good parameter initialization that can adapt to new tasks with a few scholastic gradient updates.
-
Another popular line of research on meta-learning is to use parameter generation during adaptation to novel tasks.
Metric-Learning
度量学习是通过建模2张输入图片之前的距离度量,从而估计它们的相似度,然后泛华到少样本任务上。主要方法采用余弦相似度。
-
Intuitively, if the model can construct distance metrics to estimate the similarity between two input images, it may generalize to novel categories with few labeled instances.
-
Some adopt a cosine similarity based classifier to reduce the intra-class variance on the few-shot classification task.
-
However, we focus on the instance-level distance measurement rather than on the image level.
3. Method
- The goal is to optimize the detection accuracy measured by average precision (AP) of the novel classes as well as the base classes.
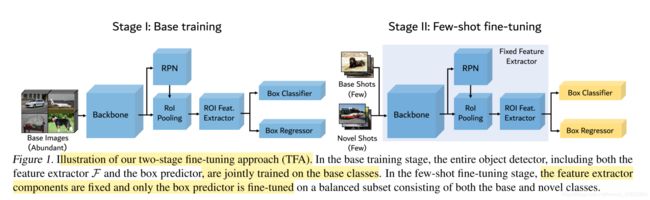
3.1 Two-stage fine-tuning approach
- The key component of our method is to separate the feature representation learning and the box predictor learning into two stages
few shot fine-tuning
- We assign randomly initialized weights to the box prediction networks for the novel classes and fine-tune only the box classification and regression networks, namely
Cosine similarity for box classifier
$w_j \in R^{ d \times 1} $, F ( x ) i ∈ R 1 × d F(x)_i \in R^{1\times d} F(x)i∈R1×d, 两者相乘,除以模,得到一个标量。
![[TFA] Frustratingly Simple Few-Shot Object Detection(ICML. 2020)_第1张图片](http://img.e-com-net.com/image/info8/21a4e6781b164119a571dbd38edadd2c.png)
本文使用余弦相似度来计算某个objects相对于class j的得分 s i , j s_{i,j} si,j。
本文认为使用余弦相似度可以减少intra-class的方差,改善模型的性能,相比于传统的FC 分类器,特别是在训练样本非常少的情况下效果明显。
3.2. Meta-learning based approaches
4. Experiment
4.1 Existing few-shot object detection benchmark
4.1 Results on PASCAL VOC
![[TFA] Frustratingly Simple Few-Shot Object Detection(ICML. 2020)_第2张图片](http://img.e-com-net.com/image/info8/47b7f51be9a94d00a8b5d7a99d8c6e4e.jpg)
4.1.2 Results on COCO
![[TFA] Frustratingly Simple Few-Shot Object Detection(ICML. 2020)_第3张图片](http://img.e-com-net.com/image/info8/0e80e5f159f74e8cbe8d1935e0438336.jpg) ### 4.1.3 Results on LVIS
### 4.1.3 Results on LVIS
4.2. Generalized few-shot object detection benchmark
- Additionally, we train our models for multiple runs on differ- ent random samples of training shots to obtain averages and confidence intervals.
4.3.1 Weight initialization
4.3.2 Scaling factor of cosine similarity
5. Code
# path few-shot-object-detection/configs/COCO-detection/faster_rcnn_R_101_FPN_ft_all_1shot.yaml
_BASE_: "../Base-RCNN-FPN.yaml"
MODEL:
WEIGHTS: "checkpoints/coco/faster_rcnn/faster_rcnn_R_101_FPN_ft_novel_1shot_combine/model_reset_combine.pth"
MASK_ON: False
RESNETS:
DEPTH: 101
ROI_HEADS:
NUM_CLASSES: 80
OUTPUT_LAYER: "CosineSimOutputLayers" # 在fine-tune阶段使用CosineSimOutputLayers,在第一阶段还是使用标准的FastRCNNConvFCHead
FREEZE_FEAT: True
# freeze 操作
BACKBONE:
FREEZE: True
PROPOSAL_GENERATOR:
FREEZE: True
DATASETS:
TRAIN: ('coco_trainval_all_1shot',) # 数据集的划分
TEST: ('coco_test_all',)
SOLVER:
IMS_PER_BATCH: 16
BASE_LR: 0.001
STEPS: (14400,)
MAX_ITER: 16000
CHECKPOINT_PERIOD: 1000
WARMUP_ITERS: 10
OUTPUT_DIR: "checkpoints/coco/faster_rcnn/faster_rcnn_R_101_FPN_ft_all_1shot"
freeze操作
if cfg.MODEL.BACKBONE.FREEZE:
for p in self.backbone.parameters():
p.requires_grad = False
print("froze backbone parameters")
if cfg.MODEL.PROPOSAL_GENERATOR.FREEZE:
for p in self.proposal_generator.parameters():
p.requires_grad = False
print("froze proposal generator parameters")
if cfg.MODEL.ROI_HEADS.FREEZE_FEAT:
for p in self.roi_heads.box_head.parameters():
p.requires_grad = False
print("froze roi_box_head parameters")
cos 相似度
@ROI_HEADS_OUTPUT_REGISTRY.register()
class CosineSimOutputLayers(nn.Module):
"""
Two outputs
(1) proposal-to-detection box regression deltas (the same as
the FastRCNNOutputLayers)
(2) classification score is based on cosine_similarity
"""
def __init__(
self, cfg, input_size, num_classes, cls_agnostic_bbox_reg, box_dim=4
):
"""
Args:
cfg: config
input_size (int): channels, or (channels, height, width)
num_classes (int): number of foreground classes
cls_agnostic_bbox_reg (bool): whether to use class agnostic for bbox regression
box_dim (int): the dimension of bounding boxes.
Example box dimensions: 4 for regular XYXY boxes and 5 for rotated XYWHA boxes
"""
super(CosineSimOutputLayers, self).__init__()
if not isinstance(input_size, int):
input_size = np.prod(input_size)
# The prediction layer for num_classes foreground classes and one
# background class
# (hence + 1)
self.cls_score = nn.Linear(input_size, num_classes + 1, bias=False)
self.scale = cfg.MODEL.ROI_HEADS.COSINE_SCALE
if self.scale == -1: # 可学习的scale
# learnable global scaling factor
self.scale = nn.Parameter(torch.ones(1) * 20.0)
num_bbox_reg_classes = 1 if cls_agnostic_bbox_reg else num_classes
self.bbox_pred = nn.Linear(input_size, num_bbox_reg_classes * box_dim)
nn.init.normal_(self.cls_score.weight, std=0.01)
nn.init.normal_(self.bbox_pred.weight, std=0.001)
for l in [self.bbox_pred]:
nn.init.constant_(l.bias, 0)
def forward(self, x):
'''
x: tensor of [512 x batch_size, 1024]
'''
if x.dim() > 2:
x = torch.flatten(x, start_dim=1)
# normalize the input x along the `input_size` dimension
x_norm = torch.norm(x, p=2, dim=1).unsqueeze(1).expand_as(x) # torch.norm(x, p=2, dim=1).size() --> [512 x bs]
x_normalized = x.div(x_norm + 1e-5) # 各元素相除 实现正则化
# normalize weight
temp_norm = (
torch.norm(self.cls_score.weight.data, p=2, dim=1)
.unsqueeze(1)
.expand_as(self.cls_score.weight.data)
)
self.cls_score.weight.data = self.cls_score.weight.data.div(
temp_norm + 1e-5
)
pdb.set_trace()
# 余弦相似度 的方法就是 cls_score的值就是 普通的fc层, 但是输入是除以正则化的特征值。 最后在cos_dist ×self.scale
cos_dist = self.cls_score(x_normalized) # 1024 x 21
scores = self.scale * cos_dist # [512 x bs, 21]
proposal_deltas = self.bbox_pred(x) # 1024 x 80
return scores, proposal_deltas
def ckpt_surgery(args):
"""
Either remove the final layer weights for fine-tuning on novel dataset or
append randomly initialized weights for the novel classes.
Note: The base detector for LVIS contains weights for all classes, but only
the weights corresponding to base classes are updated during base training
(this design choice has no particular reason). Thus, the random
initialization step is not really necessary.
"""
def surgery(param_name, is_weight, tar_size, ckpt, ckpt2=None):
pdb.set_trace()
weight_name = param_name + ('.weight' if is_weight else '.bias')
pretrained_weight = ckpt['model'][weight_name]
prev_cls = pretrained_weight.size(0)
if 'cls_score' in param_name:
prev_cls -= 1
if is_weight:
feat_size = pretrained_weight.size(1)
new_weight = torch.rand((tar_size, feat_size))
torch.nn.init.normal_(new_weight, 0, 0.01)
else:
new_weight = torch.zeros(tar_size)
if args.coco or args.lvis:
for i, c in enumerate(BASE_CLASSES):
idx = i if args.coco else c
if 'cls_score' in param_name:
new_weight[IDMAP[c]] = pretrained_weight[idx]
else:
new_weight[IDMAP[c]*4:(IDMAP[c]+1)*4] = \
pretrained_weight[idx*4:(idx+1)*4]
else:
new_weight[:prev_cls] = pretrained_weight[:prev_cls]
if 'cls_score' in param_name:
new_weight[-1] = pretrained_weight[-1] # bg class
ckpt['model'][weight_name] = new_weight
surgery_loop(args, surgery)
```