Frustratingly Simple Few-Shot Object Detection
第一篇关于小样本的学习,读完之后发现还比较简单,比较适合入门。
解决问题:机器学习模型在学习了一定类别的大量数据后,对于新的类别,只需要少量的样本就能快速学习,这就是 Few-shot Learning 要解决的问题。
研究现状:目前针对数据稀少问题,大多采用元学习的方法。大多利用先验经验进行数据平衡,然后在训练模型。
解决思路:这篇论文主要采用微调检测模型最后一层的方法解决。
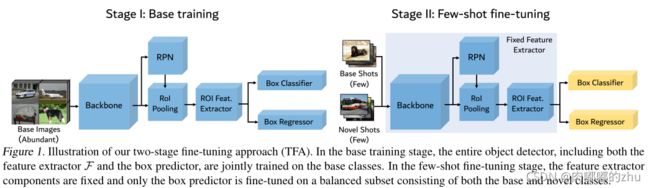
Stage 1:Base Training
这个阶段主要是利用大量的基本数据样本对普通的图像目标检测网络(如Faster-RCNN、)进行训练。这个阶段就是传统的训练方法。网络的loss有三部分构成:RPN网络、分类分支和边框回归。
![]()
Stage 2:Few-shot fine-tuning
第二阶段是基于小样本的微调。在保持整个特征提取器不变的情况下,将新类随机初始化的权值分配给box预测网络,只微调box分类和回归网络,即检测模型的最后一层。这个过程使用了和stage1相同的损失函数,并且缩小学习速率。
Cosine similarity for box classifier
分类器的设计是基于cosine相似度函数,式子如2所示。其中Si,j为输入x的第i个候选对象与类j的权向量之间的相似度评分。α是比例因子。和FC-base的d分类器相比,基于instance-level feature归一化的余弦相似度分类器,后者有助于减少Novel类的方差,提高检测精度和减少检测的准确性,特别是在训练样本的数量很小的时候。
结果分析: 这种简单的方法比元学习方法提高了大约2~20个点,有时甚至是以前方法的两倍精度。
实验阶段,用PASCAL VOC和COCO对现有的少镜头目标检测基准与之前的方法进行了广泛的比较,效果有了较大的提升。
和现有的benchmark比较:
对于PASCAL VOC数据集:训练集中将20个类随机分为15个base类和5个novel类,base类中每个类有K = 1,2,3,5,10个对象,这些对象是从2007年和2012年两个版本的训练集组合中抽取的。并用2007版本的测试集做为评估。
对于COCO数据集,60个与PASCAL VOC数据集不相交的类别被用作base类,其余20个类别被用作Novel类,每类有K = 10,30个对象。
对于评价指标PASCAL VOC使用AP50,COCO使用COCO-style AP。
创新:
修正的评估方法:
作者发现,现有的评估基准有两个问题:首先,现有的评估只关注网络对Novel类的性能。这忽略了base类中潜在的性能下降,从而忽略了网络的整体性能。其次,由于用于训练的样本较少,样本方差较大。这使得很难与其他方法的比较中得出结论,因为方差带来的误差影响着网络的精度,也就是分不清性能的提升是方差带来的还是网络自身的提高。
为了解决这个问题:作者修正了评估的方法,一方面评估base类的AP, 称为bAP。另一个是Novel类的AP (nAP)之外的整体AP。这样能够观察base类和Novel类的性能趋势,以及网络的总体性能。此外,模型在不同随机样本的训练样本上多次训练,以获得平均和置信区间。
思考:从实验结果可以看出,尽管效果得到了提升,但是还是较低,存在一定的改进空间。这篇论文是保持特征学习部分不变,只改动了预测网络部分。因此,特征学习部分对模型的影响值得思考。
参考博客如下:
Frustratingly simple few-shot object detection_Burtan的专栏-CSDN博客概述这篇文章比较简单,仅对稀有类现有检测器的最后一层进行微调对于小样本目标检测任务至关重要。在目前的基准测试中,这种简单的方法比元学习方法提高了大约2~20个点,有时甚至是以前方法的两倍精度。这里先介绍下基本概念小样本学习:1)标准小样本:给定一个大规模的训练集作为基类(base class),可以类比于人类的知识积累,对于从未见过的新类(novel class,与基类不重叠),借助每类少数几个训练样本,需要准确识别新类的测试样本。2)广义小样本:相比与小样本学习,广义小样本学习中测试样本https://blog.csdn.net/ljj583905183/article/details/115645852