论文超详细精读|万字:2s-AGCN
文章目录
- 前言
- 总览
- 一、Introduction
-
- ST-GCN
-
- 缺点
- AGCN
- 主要贡献
- 二、Related work
-
- 2.1 Skeleton-based action recognition (骨架动作识别)
- 2.2 Graph convolutional neural networks(图卷积网络)
- 三、Graph Convolutional Networks
-
- 3.1 Graph construction(图的构建)
- 3.2 Graph convolution(图卷积)
- 3.3 Implementation (实现)
- 四、Two-stream adaptive graph convolutional network
-
- 4.1 Adaptive graph convolutional layer(自适应图卷积层)
- 4.2 Adaptive graph convolutional block(自适应图卷积块)
- 4.3 Adaptive graph convolutional network(自适应图卷积)
- 4.4 Two-stream networks
- 五、Experiments
-
- 5.1 Datasets
- 5.2 Training details
- 5.3 Ablation Study
-
- Ablation Study — Adaptive graph convolutional block
- Ablation Study — Two-stream framework
- 5.4 Comparison with the state-of-the-art
-
- Visualization of the learned graphs
- 六、Conclusion

前言
笔者从人工智能小白的角度,力求能够从原文中解析出最高效率的知识。
之前看了很多博客去学习AI,但发现虽然有时候会感觉很省时间,但到了复现的时候就会傻眼,因为太多实现的细节没有提及。而且博客具有很强的主观性,因此我建议还是搭配原文来看。
请下载原文《Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition》搭配阅读本文,会更高效哦!
若要更好地理解此篇文章,请参考其改进的前身:
【读前请读】:《论文超详细精读|六千字:ST-GCN》
以及,同样以ST-GCN为基础改进的:
【读后再读】:《论文超详细精读|八千字:AS-GCN》
总览
首先,看完标题,摘要和结论,我了解到了以下信息:
- 提出了一种新的双流自适应图卷积网络(2S-AGCN)用于基于骨架的动作识别。模型中的图的拓扑既可以统一地学习,也可以通过BP算法以端到端的方式单独学习。
- 提出了一种同时对一阶和二阶信息(骨架的长度与方向)建模的双流框架,在识别精度上有了显著的提高。 它将骨架数据的图结构参数化,并嵌入到网络中,与模型共同学习和更新。
- 文章主要创新点有两个,一个是双流网络,另外一个是自适应性。
一、Introduction
- 基于骨架数据的动作识别方法因其对动态环境和复杂背景具有较强的适应性而受到广泛研究和重视。
- 以往的方法不能充分利用骨架数据的图结构,很难推广到任意形式的骨架。
ST-GCN
基于人体关节的自然连接构建空间图,并在连续的帧中添加相应关节之间的时间边。提出了一种基于距离的采样函数来构造图卷积层,并将其作为基本模块构建最终的时空图卷积网络。
缺点
- ST-GCN中使用的骨架图是启发式预定义的,并且仅表示人体的物理结构。因此,不能保证它对于动作识别任务是最优的。例如,两只手之间的关系对于识别诸如“鼓掌”和“阅读”之类的动作非常重要。然而,ST-GCN很难捕捉到两只手之间的依赖关系,因为它们在预定义的基于人体的图形中距离彼此很远。
- GCNs的结构是层次化的,不同的层次包含多层语义信息。然而,ST-GCN应用的图的拓扑结构是固定在所有层上的,缺乏对所有层中包含的多层语义信息建模的灵活性和能力;
- 对于不同动作类的所有样本,一个固定的图结构不一定是最优的。对于一些动作来说,比如“擦脸”和“碰头”,手和头之间的联系应该更强一些,但对于其他一些动作,比如“跳起来”和“坐下来”,情况则相反。这一事实表明,图结构应该是数据相关的,然而,ST-GCN不支持这一点。
- 每个顶点附加的特征向量只包含关节的2D或3D坐标,可视为骨骼数据的一阶信息。然而,表示两个关节之间骨骼特征的二阶信息(骨骼长度和方向)没有得到充分利用,但骨骼的长度和方向自然更能提供信息和辨别动作。
AGCN
为改善上述问题,该论文提出一种新颖的 Adaptive graph convolutional network ( AGCN ),这种网路将 2 种不同的 Graph 做参数化,并与卷积参数一同于训练过程进行各自的优化。
这2种Graph分别为:
- Global graph:返回所有资料中常见的Pattern。
- Individual graph:针对每笔资料的特征做重现。
这两类图都针对不同的层分别进行了优化,可以更好地适应模型的层次结构。这种数据驱动的方法增加了图构建模型的灵活性,并具有更强的通用性,以适应各种数据样本。
主要贡献
1.提出了一种自适应图卷积网络,以端到端方式自适应学习不同GCN层和骨架样本的图的拓扑结构,能够更好地适应动作识别任务和GCN的层次结构。
2.将骨架数据的二阶信息显式表述,并采用双流框架将其与一阶信息相结合,显著提高了识别性能。
3.在基于骨骼的动作识别的两个大规模数据集上,提出的2s-AGCN显著优于现有的方法。
二、Related work
2.1 Skeleton-based action recognition (骨架动作识别)
1.CNN&RNN时代:传统的基于骨骼的动作识别方法通常设计人工选取特征来模拟人体。后来又有RNN与CNN的方法,基于rnn的方法通常将骨骼数据建模为一个坐标向量序列,每个坐标向量代表一个人体关节。基于cnn的方法基于手工选择的转换规则将骨架数据建模为伪图像。
2.图卷积网络时代:然而,rnn和cnn都不能完全表示骨架数据的结构,因为骨架数据自然地以图的形式嵌入,而不是向量序列或二维网格。时空图卷积网络(STGCN),将骨架数据直接建模为图结构。它消除了人工配置或遍历规则的需要,因此比以前的方法获得了更好的性能。
2.2 Graph convolutional neural networks(图卷积网络)
包括两个方法:空间视角和光谱视角。本文是空间视角法。
三、Graph Convolutional Networks
3.1 Graph construction(图的构建)
在 Graph 的建构上,该论文采用 ST-GCN 的逻辑。
空间上,以关节点当作 Vertexes ,而 Edges 则是人体生理上的连结 ( 上图橘色点、线 )。而时间轴上的 Edges 则是相同 Vertex 之间的连结 ( 上图同关节之间的蓝色线 ) 。
3.2 Graph convolution(图卷积)
在空间上对一个 Vertex ( v i v_i vi ) 做 Graph convolution 的公式定义如下:

f f f 指的是属于 $ v$ 的特征图, v v v 表示 Vertex 。 B i B_i Bi是 Convolution 采样的区域 ( 以邻近 v i v_i vi 1 个步长的范围作定义,而所包含的 Vertex 则表示为 v j v_j vj ) 。 w w w 则是相似于 Convolution 做加权的函数,会基于输入的特征图计算 Weight vectors 。为了给每个顶点映射一个唯一的权向量,ST-GCN专门设计了一个映射函数 l i l_i li 。

该过程可以表示成上面的图片:
在 Kernel size 的设定上其实是 3,会将 B i B_i Bi 切分成 3 个 Subset:
- S i 1 S_{i1} Si1:Convolution 关注的 Vertex ( 红色 )
- S i 2 S_{i2} Si2:距离中心较近的向心 Vertex ( 绿色 )
- S i 3 S_{i3} Si3:距离中心较远的离心 Vertex ( 蓝色 )
这边要留意的是,Weight vectors 是固定的,但邻近的 Vertexes 数量 ( B i B_i Bi ) 是浮动的,而为了要让每个 Vertex 都能匹配到独特的 Weight vector ,ST-GCN 有特别设计一个 Mapping function ( l i l_i li ) 。
而 Z i j Z_{ij} Zij 表示的是上述 Subset ( S i k S_{ik} Sik ) 的基数,也就是包含的 v j v_j vj数量 ,用意是要平衡每个 Subset 的贡献程度 。
3.3 Implementation (实现)
在实现上,整个网路的特征图是个 C × T × N C × T × N C×T×N 的 Tensor:
- C 表示 Channel 数量
- T 表示 Temporal 上的长度
- N 表示 Vertexes 的数量
而上个 ST-GCN 的公式可表述成:

K v K_v Kv表示空间维度上的 Kernel size ( 基于前述定义设定为 3 ) 。⊙ 则是 Dot product 。

- A k A_k Ak 近似于 N × N 的邻接矩阵,其元素 A ‾ k i j \overline{A}_k^{ij} Akij 表示顶点 v j v_j vj是否在顶点 v i v_i vi 的 S i k S_{ik} Sik 子集中。它用于从 f i n f_{in} fin 中提取特定子集中的连接顶点,以获得相应的权值向量。
- W k W_k Wk 则是通过 1 × 1 Convolution 的操作得到的 Weight vector ( 维度是 C o u t × C i n × 1 × 1 C_{out} × C_{in} × 1 × 1 Cout×Cin×1×1 ),也就是上一个公式中的 W ( ) W( ) W() 。
- M k M_k Mk 则是对每个 Vertex 做 Attention 得到的 N × N Attention map,用于表示每个 Vertex 的重要性 。
至于在时间轴上关注的范围则会设定为固定的 2 ( 也就是邻近的 2 个帧(frame) 的相同关节 ) ,近似于经典 Convolution 的操作 。对应到公式来说,就是在输出的特征图上,做一个 K t × 1 K_t × 1 Kt×1 的 Convolution 。
四、Two-stream adaptive graph convolutional network
4.1 Adaptive graph convolutional layer(自适应图卷积层)
在 Introduction 提到,采用人体骨架做 Predefined graph 并不见得最能表达各种行为,而该论文的对应解法是在 Graph convolution 上加入了 Attention,并提出 Adaptive graph convolutional layer,这使 Graph 的 Topology 可以随著网路的训练一起进行优化,让每个 Layer 变得更独特,借此扩大模型的弹性 。
根据前一章节的公式来看:
Topology 最终的样子其实取决于 A k A_k Ak和 M k M_k Mk, A k A_k Ak 决定的是两顶点之间是否有连结,而 M k M_k Mk 决定的是这些连结的强度 。为了让这个操作能具备 Adaptive 的特性,该论文改写上式为:

其对应示意图如下:
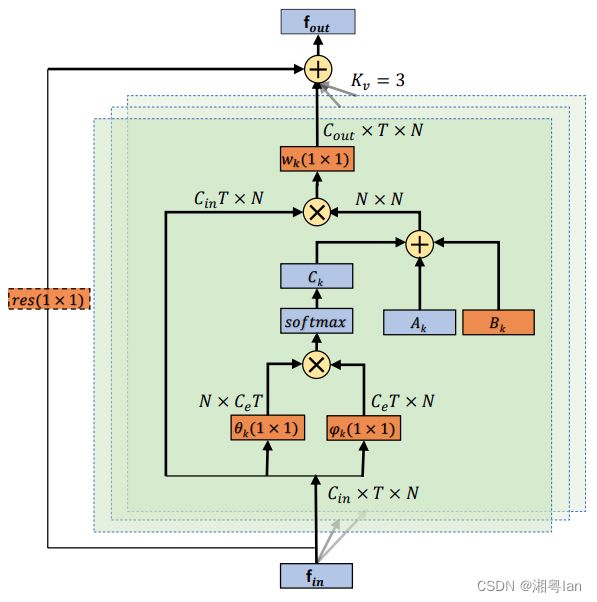
主要差异在于,Graph 的邻接矩阵被拆分为 A k A_k Ak 、 B k B_k Bk 、 C k C_k Ck ,这 3 部份的用意分别如下:
- A k A_k Ak:
这部分是原始经过 Normalized 的 N × N N × N N×N 邻接矩阵,决定的是两个顶点之间是否有连接。 - B k B_k Bk:
(1)尺寸上也是 N × N N × N N×N,但差异在于:这边每个参数都是可被训练的,因此没有任何的约束,所以最终这部分的表示会完全取决于训练资料,也就能依据不同行为类别而有所差异 。
(2)矩阵中的元素可以是任意值。它不仅表明两个节点之间是否存在连接,而且表明连接的强度。
(3)而且不同于前面的 A k A_k Ak 及 M k M_k Mk ,这边的连结性与强度是同时被学出来的,这边不直接在 M k M_k Mk 上做 Attention 的原因在于:若原本 A k A_k Ak 上有些地方是 0 ( 代表非骨架的连结 ) ,那从训练开始到结束都会是 0 ,那其实会没办法产生出新的连结 ( 限制模型去看骨架以外的关联性 ) 。从这观点来看, B k B_k Bk 的作法就比 M k M_k Mk 更具弹性。 - C k C_k Ck:
这部分是个 Data-dependent graph ,会针对 Graph 上的每个 Sample 去学习 。为了决定两个顶点之间的连结强度,这边使用 Dot product 计算两顶点在 Embedding space 的相似度,所以嵌入的是个 Gaussian function :

这边的 θ θ θ 和 φ φ φ 就是 Embedding function,经过 Embedding 的特征图会被 Reshape 成 N × C e T N×C_e T N×CeT 和 C e T × N C_e T × N CeT×N,这样两个向量相乘后就可以得到 N × N N ×N N×N 的相似度矩阵: C k C_k Ck 。若将 C k C_k Ck 上的每个点座标用 i , j i,j i,j 表示,那其实就是 C k i j C_k^{ij} Ckij代表 v i vi vi 与 v j vj vj 之间的相似度 。
而 C k C_k Ck 上的值由于经过 Normalized ,对两顶点来说算是个 Soft edge,若用 softmax 的操作来看,那 C k C_k Ck 的计算可表述成:
![]()
W θ W_θ Wθ 和 W φ W_φ Wφ 就是 Embedding function ( θ θ θ 和 φ φ φ ) 的参数。
而为了不使原来的表现退化,该论文并没有把 A k A_k Ak 取代为 B k B_k Bk 或 C k C_k Ck ,而是将两者的参数初始化为 0 ,并于训练过程中用加法的方式强化既有模型的弹性。
此外,就整体来看,每个 Layer 都有 Residual connection 的设计,这使该作法可被插入在任何现存的模型中,透过上图左边的 1 × 1 Convolution ( 橘色底虚线框 ) 对输入特征图的 Channel 维度做转换,使其适应输出该有的维度。
4.2 Adaptive graph convolutional block(自适应图卷积块)
在时间轴上的 Convolution 操作与 ST-GCN 相同,是在 C × T × N C ×T × N C×T×N 的特征图上做 K t × 1 K_t × 1 Kt×1 的 Convolution,不论在空间上或时间轴上的 Convolution 后面都接著 1 层 Batch normalization ( BN ) layer 和 ReLU layer,但在这两种组合之间有加入 Drop out layer ( Drop rate : 0.5 ),以上便构成一个 Basic block:

上图的 Convs 和 Convt 就是分别为空间上和时间轴上的 Convolution,另外为了训练过程的稳定性,在每个 Block 上会加入 Residual connection 。
4.3 Adaptive graph convolutional network(自适应图卷积)
整个 AGCN 是透过堆叠上述的 Basic block 而成:

一共有 9 个 Block ,最前面有先经过 BN 对输入数据做 Normalize ( 最左边的绿色层 ),透过一连串的特征抽取 ( B1 ~ B9 ) 后,会经过 Global average pooling layer ( GAP, 蓝色层 ),将不同 Sample 的特征图压回一样的尺寸,最后才通过 Softmax 做出分类的预测 。
4.4 Two-stream networks
如同 Introduction 所提到的,骨架信息对行为辨识任务来说是重要的,因此透过前面几个章节提到的方法抽取相关信息,并透过一个 Two-stream 的架构来增强模型的辨别能力:

- 为了在各顶点上带入方向性的信息,该论文特别将骨架中重心近的顶点定义为 Source joint ,相对的,较远的点就是Target joint,而每一段骨架都是一个从 Source 指向 Target 的向量,以此带入强度以外的方向性信息。
- 给定一个样本,论文首先根据关节的数据计算骨骼的数据。然后,将关节数据和骨骼数据分别输入J-Stream和B-Stream。
- 最后,将两个流的softmax分数相加,得到融合分数,并预测动作标签。
五、Experiments
5.1 Datasets
该论文为了与 ST-GCN 进行比较,所以采用的资料集是 NTU-RGBD 和 Kinetics-Skeleton 。
5.2 Training details
而实验所使用的相关设定如下:
- Framework:PyTorch
- Optimizer:SGD
- Momentum:0.9 ( Nesterov momentum )
- Weight decay:0.0001
- Loss function:Cross-entropy
- Batch-size:64
- Learning rate:
- NTU RGBD:初始为 0.1 ( 在第 10, 30, 40 Epoch 时分别除 10,最后中止在 50 个 Epoch )
- Kinetics-Skeleton:初始为 0.1 ( 在第 45, 55 Epoch 时分别除 10,最后中止在 65 个 Epoch )
5.3 Ablation Study
这边的 Baseline 是 ST-GCN ,它在 NTU-RGBD 资料集上以 X-View 评量标准测试的准确度为 88.3% ,经过该论文调整 Learning rate schedule 后,达到 92.7 % 。
Ablation Study — Adaptive graph convolutional block
在上个章节中,有提到 Adaptive graph convolutional block 有 3 种类型,分别是下表中的 A 、B 、C,这边就是要证明他们每个各自都有些作用:

Ablation Study — Two-stream framework
另一个造成模型成效便好的原因是 Two-stream 的架构,这边就分别把 2 个 Branch 的信息单独做测试得到以下结果:

而 2 种信息混用的状态是最好的 。
5.4 Comparison with the state-of-the-art
这边就是与其他当时主流的研究结果相比,在 NTU-RGBD 资料集的结果:

在 Kinetics-Skeleton 资料集的结果:

在当时表现不错 。
Visualization of the learned graphs
这边是将第二个 Subset 学到的特征做可视化,下图左边是原始的邻接矩阵,右边则是根据该类别学到的连接性与强度信息:

另外针对不同 Layer 学到的东西也做了以下的可视化:

由左至右分别对应到架构图的 B3 、B5 、B7 层,关节点上的圆半径则反应每个节点与右手拇指关节点 ( 编号为 25) 的强度。
这边是为了证明,传统生理上的骨架连结方式并不见得是最好的选择 。可以看到最右边的绿色骨架,当特征经过多层的抽取后,也就能看到较远的地方,这时左右手的关联性就比生理上邻近节点来的强,这就是与行为类别更具备相关性的信息 。
另外该论文也针对相同层数的特征做了可视化,下图为不同行为上的第 5 层信息:

这就证明了,相同网路架构、相同层数的参数,可以根据训练资料对不同类别的输入学到具有差异性的 Topology 。
六、Conclusion
该论文在当时提出了新颖的 Two-stream adaptive graph convolutional neural network ( 2s-AGCN ),对重现骨架的 Graph 做了参数化的动作,使模型具备更大的弹性来学习不同行为的特征 。
过去研究并未重视那些每段骨架上的信息 ( Bone information ),而在该论文中以 Two-stream 的架构用这些信息来增强模型对行为的识别能力,并达到当时的最好表现。